在Amazon Athena中轻松在线解密Glue DataBrew加密数据:一种无缝的数据安全实践
引言:数据安全与便捷分析的完美平衡
在大数据时代,数据安全与数据使用便捷性如同天平的两端,常常让我们陷入两难。作为数据工程师或分析师,你是否遇到过这样的场景:
-
业务同事通过 Amazon Glue DataBrew 对敏感数据(如用户手机号、身份证号)进行了清洗和转换,并出于安全合规要求,使用数据加密功能生成了加密数据集。
-
现在,你需要使用 Amazon Athena 对这些已加密的数据进行即席查询(Ad-hoc Query)和深度分析。
-
传统的做法可能是将数据导出,用独立脚本解密后再加载,但这流程繁琐、效率低下,且增加了安全风险。
那么,能否直接在 Athena 中“在线”查询,并实时看到解密后的明文数据呢? 答案是肯定的!本文将手把手带你实践这一无缝、安全的数据工作流。
一、 技术架构与核心原理
在深入步骤之前,我们先理解其背后的“魔法”是如何实现的。
核心服务:
-
Amazon Glue DataBrew: 一个可视化的数据准备工具,可以轻松地对数据进行清洗、规整和加密。
-
Amazon Athena: 无服务器的交互式查询服务,使用标准 SQL 直接分析 S3 中的数据。
-
AWS Key Management Service (KMS): 用于创建和管理加密密钥的核心服务。
工作原理:
当你在 Glue DataBrew 中对某一列(例如 phone_number)启用加密时,DataBrew 并不会将整个文件加密,而是使用你指定的 KMS 密钥,对该列的每一个值进行单独的加密处理。加密后的结果是一串密文。DataBrew 将加密后的数据集(通常是 Parquet 格式)写回到 Amazon S3。
关键在于,Athena 支持通过 AWS 用户自定义函数(UDF) 来扩展其功能。我们可以创建一个简单的 Lambda UDF,在 Athena 执行查询时,调用这个 UDF。该 UDF 内部则使用 AWS KMS 的 Decrypt API,将密文字段实时解密为明文,最终呈现在查询结果中。
流程简图:
DataBrew加密数据 (S3)->Athena发起SQL查询->Lambda UDF被调用->KMS服务解密->Athena返回明文结果
二、 实践步骤详解
下面我们通过一个具体的例子(对 customer_phone 列进行解密)来走通整个流程。
步骤一:在 Glue DataBrew 项目中配置列级加密
-
创建或打开项目: 在 DataBrew 控制台,创建或打开一个指向源数据的数据准备项目。
-
选择加密列: 在配方(Recipe)中,找到需要加密的列(例如
customer_phone)。 -
添加加密操作:
-
点击该列,选择 “管理列” -> “加密”。
-
在加密对话框中,选择一个已有的 KMS 密钥(Customer Managed Key 或 AWS Managed Key)。请务必记录下该密钥的 ARN 或 Alias,后续在 UDF 中会用到。
-
应用此配方。
-
-
创建任务并运行: 创建一个任务,将处理后的(即包含加密列的)数据集发布到指定的 S3 路径(例如
s3://my-bucket/databrew-output/)。
步骤二:创建用于解密的 Lambda UDF
这是整个流程的核心。我们需要创建一个 Python 版本的 Lambda 函数。
-
创建 Lambda 函数:
-
进入 Lambda 控制台,创建新函数,选择 Python 运行时。
-
为函数分配合适的执行角色,该角色必须拥有
kms:Decrypt权限(针对步骤一中使用的 KMS 密钥)。
-
-
编写函数代码:
import boto3
import base64# 初始化 KMS 客户端
kms = boto3.client('kms')# 替换为你在DataBrew中使用的KMS密钥ARN
KMS_KEY_ARN = 'arn:aws:kms:us-east-1:123456789012:key/your-key-id'def lambda_handler(event, context):# 输出处理结果output_rows = []for row in event['rows']:# 读取输入行,假设加密列是第一个输入列 (index=0)# DataBrew加密后的数据是Base64编码的字符串encrypted_data_b64 = row['data'][0]try:# 对Base64编码的密文进行解码encrypted_bytes = base64.b64decode(encrypted_data_b64)# 调用KMS解密decrypt_response = kms.decrypt(CiphertextBlob=encrypted_bytes)plaintext = decrypt_response['Plaintext'].decode('utf-8')except Exception as e:# 如果解密失败(例如,该字段本身为空或非加密值),返回原值plaintext = encrypted_data_b64# 将解密后的明文作为输出output_rows.append({'data': [plaintext]})# 返回JSON格式的处理结果return {'rows': output_rows}-
注意:请务必将
KMS_KEY_ARN替换为你自己的密钥 ARN。此代码是一个简化示例,实际生产中应考虑更完善的错误处理。 -
发布函数版本: 代码编写完成后,发布一个新的函数版本。Athena 需要调用已发布的版本,而不是
$LATEST。
步骤三:在 Athena 中注册并使用 UDF
现在,我们告诉 Athena 如何使用刚才创建的 Lambda 函数。
-
连接到 Athena 查询编辑器。
-
创建 UDF 函数:
执行以下 SQL 语句,将 Lambda 函数注册为 Athena 中的一个 SQL 函数。
CREATE FUNCTION decrypt_phone (phone_string VARCHAR)
RETURNS VARCHAR
LAMBDA 'your-lambda-function-arn' -- 替换为你的Lambda函数ARN(包括版本号,如:my-function:1)-
这里,我们创建了一个名为
decrypt_phone的 UDF,它接受一个VARCHAR参数,并返回一个VARCHAR值。Athena 会在调用此函数时,自动触发后端的 Lambda。 -
在 SQL 查询中使用 UDF 进行解密:
假设你的加密数据表名为encrypted_customer_table,包含customer_id和加密的customer_phone列。
-- 直接查询,看到的是密文
SELECT customer_id, customer_phone
FROM encrypted_customer_table
LIMIT 10;-- 使用UDF解密查询,看到的是明文!
SELECTcustomer_id,decrypt_phone(customer_phone) AS decrypted_phone -- 关键步骤:调用UDF
FROM encrypted_customer_table
LIMIT 10;-
执行第二条查询,你将会看到,原本是一串乱码的
customer_phone列,现在神奇地变回了可读的手机号码。
三、 方案优势与最佳实践
-
无缝集成: 整个流程完全在 AWS 生态内完成,无需数据落地或额外工具,实现了安全与分析效率的统一。
-
按需解密: 数据在 S3 中始终以加密形式存储,只有在 Athena 查询被触发时,特定的数据才会被临时解密,极大降低了数据泄露风险。
-
权限管控精细: 解密能力通过 IAM 角色和 KMS 密钥策略进行严格控制。只有被授权的用户/角色(以及 Lambda 函数)才能执行解密操作。
最佳实践建议:
-
密钥管理: 强烈建议使用 客户管理密钥(CMK) 而非 AWS 管理密钥,以便拥有更大的控制权。
-
性能与成本: UDF 每次调用都会涉及 Lambda 和 KMS 的交互。对于海量数据的全表扫描,请注意 Lambda 的并发限制和成本。建议通过
WHERE子句过滤数据,减少不必要的解密操作。 -
UDF 优化: 可以考虑在 Lambda 函数中加入简单的缓存机制(如缓存最近解密过的密文),以优化重复查询的性能。
方案场景
为了演示整个数据加密和解密流程,我们需要提前准备一份包含敏感信息的样例数据。我们从 DLPTEST (https://dlptest.com) 下载名为 sample_data.csv 的示例数据集。这个文件包含模拟的个人身份信息(PII)例如姓名、地址、电话号码、电子邮件地址和社会安全号码(SSN)等。该方案执行流程如下图所示,无论在亚马逊云科技的中国区域还是全球区域都可实现:
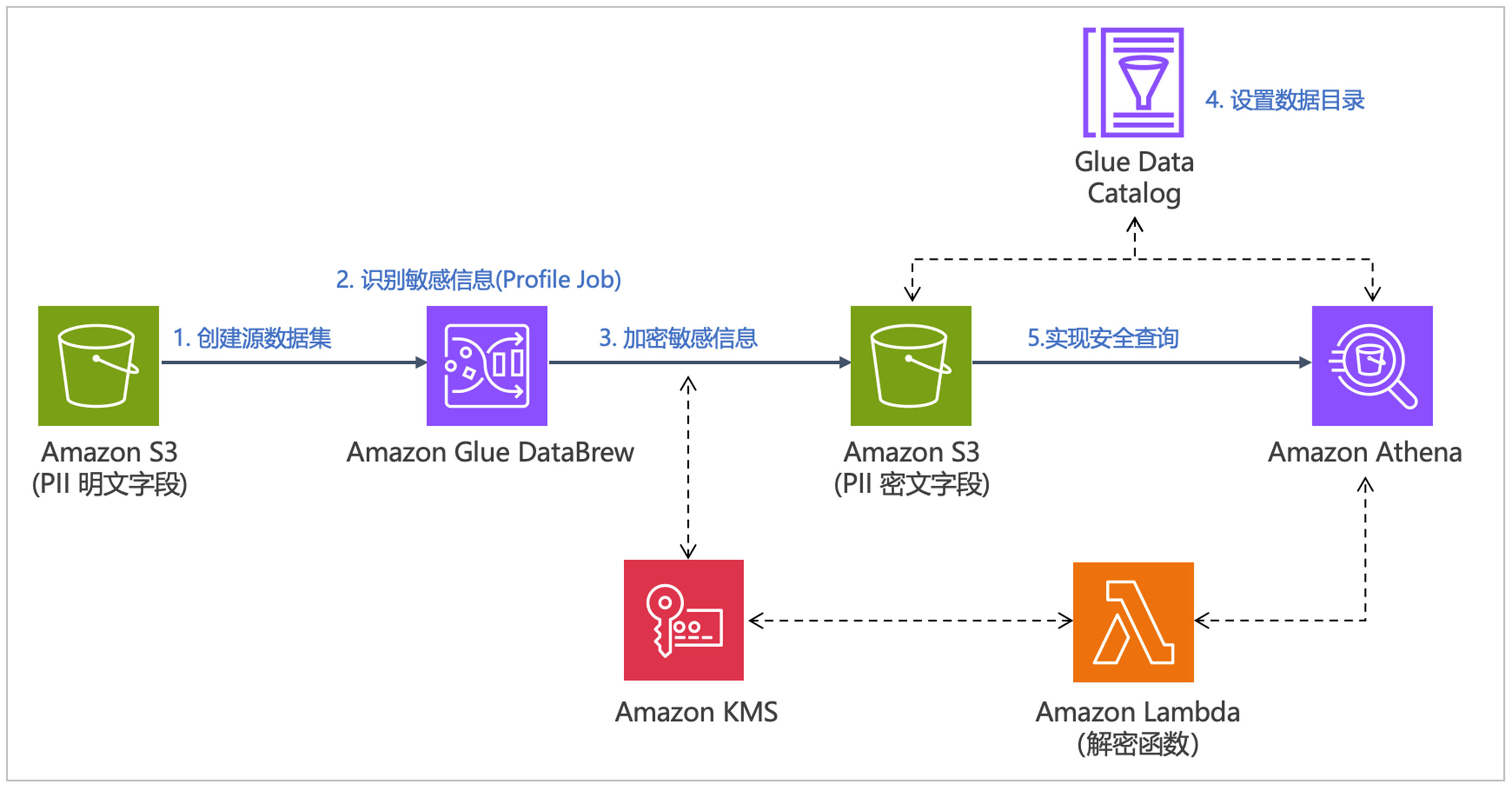
四、 结语
通过结合 Amazon Glue DataBrew 的便捷数据准备、AWS KMS 的强大加密能力以及 Amazon Athena 的可扩展 UDF,我们成功地构建了一个既安全又高效的数据分析管道。这套方案完美诠释了“安全左移”和“内嵌安全”的理念,让数据安全不再是数据分析的绊脚石,而是其坚实的基石。
现在,就去你的 AWS 控制台尝试一下吧!让数据在加密的盾牌下,依然能够自由地舞蹈。