OpenBMB开源组织介绍
概述
官网,GitHub主页,Open Lab for Big Model Base缩写,开源社区由清华大学自然语言处理实验室和面壁智能共同支持发起。
面壁智能
官网,Model Best,
ChatDev
论文,开源(GitHub,27.6K Star,3.5K Fork)。
4层架构
| 层级 | 功能 | 关键点 |
|---|---|---|
| Agent | 角色:CEO、CTO、开发、测试、文档 | 每人有Prompt+职责,用自然语言沟通 |
| Chat Chain | 会话流程控制器 | 决定谁在什么时候说啥,防止跑偏 |
| Execution | 生成代码+运行测试 | 输出真实文件(.py/.js),可执行 |
| Visualizer | 对话可视化 | 看清每个agent说了什么、进度如何 |
部署
git clone https://github.com/OpenBMB/ChatDev.git && cd ChatDev
conda create -n chatdev python=3.13 -y && conda activate chatdev
pip install -r requirements.txt
vim config.py
# 生成一个TODO应用
python main.py --task "Build a simple TODO app in Python with CLI"
MiniCPM-V
开源(GitHub,22.1K Star,1.7K Fork)多模态小模型。
Android部署:https://github.com/Achazwl/mlc
iOS部署:https://github.com/OpenSQZ/MiniCPM-V-CookBook/blob/main/demo/ios_demo/ios.md
模型地址以HuggingFace为例,在ModelScope也能搜到,版本如下:
- 4.5:论文,HF
- 4.0:HF
- 2.6:HF
- MiniCPM-Llama3-V 2.5:技术报告,HF
- 2:HF
- 1:最初版本,论文,HF
架构
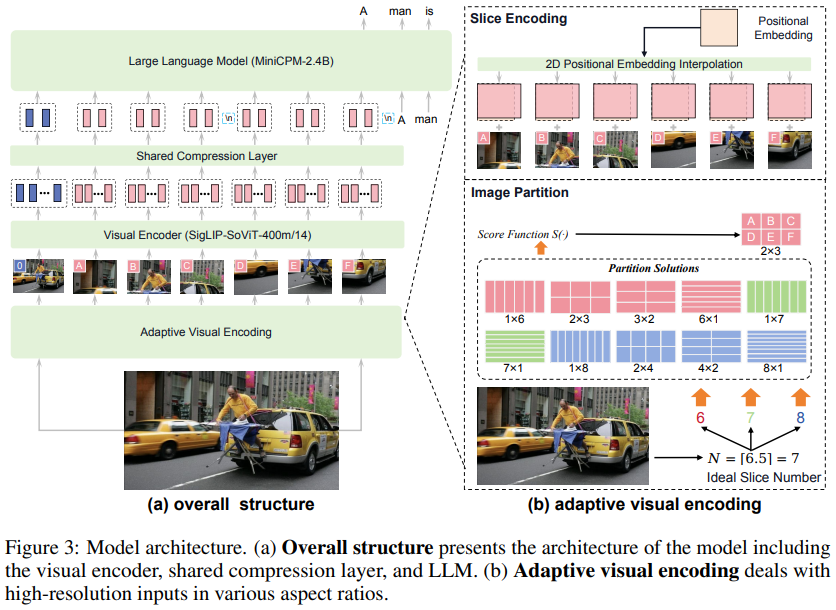
图来自初代论文。
以SigLIP2-400M与MiniCPM4-3B为核心构建。全面兼容llama.cpp、Ollama、vLLM、SGLang等主流框架,推出适用于iPhone和iPad的开源iOS应用。官方提供详尽的部署指南CookBook。
核心亮点
- 专为端侧设备优化,实现流畅体验:开创性地实现在移动端设备(智能手机和个人电脑)上的高性能本地化运行。在保持强大功能的同时,显著提升运行效率和稳定性。
- 高效的推理速度:官方测试显示,在iPhone 16 Pro Max上,使用开源的iOS应用运行MiniCPM-V 4.0时,首次出词的延迟低于2秒,解码速度超过每秒17个词元(Token),且不会出现设备过热问题。
- 强大的并发处理能力: 在对并发量和吞吐量的测试中,MiniCPM-V 4.0表现出色。在256个并发用户请求下,其吞吐量高达13856 tokens/s,远超其他同类模型,展现其强大的处理能力和广泛的应用潜力。
- 强大的多模态能力:如单图像、多图像、视频理解能力,还拥有强大的OCR功能,能够精准识别和处理图像中的文字信息。
模型推理示例:
from PIL import Image
import torch
from transformers import AutoModel, AutoTokenizermodel_path = 'openbmb/MiniCPM-V-4'
model = AutoModel.from_pretrained(model_path,trust_remote_code=True,# sdpa or flash_attention_2, no eagerattn_implementation='sdpa',torch_dtype=torch.bfloat16)
model = model.eval().cuda()
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
image = Image.open('./assets/single.png').convert('RGB')
# First round chat
question = "What is the landform in the picture?"
msgs = [{'role': 'user', 'content': [image, question]}]
answer = model.chat(msgs=msgs,image=image,tokenizer=tokenizer
)
print(answer)
# Second round chat, pass history context of multi-turn conversation
msgs.append({"role": "assistant", "content": [answer]})
msgs.append({"role": "user", "content": ["What should I pay attention to when traveling here?"]})
answer = model.chat(msgs=msgs,image=None,tokenizer=tokenizer
)
print(answer)
MiniCPM-CookBook
GitHub,MiniCPM和MiniCPM-V系列小模型部署指南。
XAgent
开源(GitHub,8.5K Star,893 Fork)
AgentVerse
开源(GitHub,4.8K Star,474 Fork)。
MiniCPM
开源(GitHub,8.4K Star,519 Fork)。
模型地址以ModelScope为例,在HuggingFace也能搜到,版本如下:
- 4.1:包括8B
- 4:包括0.5B,8B,
- 3:包括4B
- 2:
MiniCPM-o 2.6
https://modelscope.cn/models/OpenBMB/MiniCPM-2B-128k
https://modelscope.cn/models/OpenBMB/MiniCPM-Embedding
https://modelscope.cn/models/OpenBMB/MiniCPM-Embedding-Light
https://modelscope.cn/models/OpenBMB/MiniCPM-Reranker
https://modelscope.cn/models/OpenBMB/MiniCPM-Reranker-Light
http://modelscope.cn/models/OpenBMB/AgentCPM-GUI
BitCPM
极端三值量化技术。
系列模型包括:
- BitCPM4-0.5B:将极端三值量化应用于 MiniCPM4-0.5B,将模型参数压缩为三值,实现90%的位宽减少;
- BitCPM4-1B:将极端三值量化应用于 MiniCPM3-1B,将模型参数压缩为三值,实现90%位宽减少
4.0
面壁智能推出的预训练模型——MiniCPM 4.0,以更轻量的体量、极低的计算与存储成本,实现媲美主流大模型的语言理解与生成能力,真正做到端侧可运行、边缘可部署。从智能家居、移动办公到车载智能,端侧AI正加速向千家万户千行百业渗透。
包括8B、0.5B两种参数规模,延续以小博大特性,实现同级最佳的模型性能:
- 8B:适用于需要处理复杂长文本的任务。相较于Qwen3-8B、Llama3-8B、GLM4-9B等同体量模型实现长文本推理速度稳定5倍,极限场景下最高220倍加速,实现同级最佳模型性能。进一步实现长文本缓存的大幅锐减,在128K长文本场景下,相较于Qwen3-8B仅需1/4的缓存存储空间;
- 0.5B:适合资源受限的端侧设备,相较更大的Qwen3-0.6B、Llama 3.2,仅2.7%的训练开销,一半参数性能翻倍,并实现每秒600 token的高速推理,性能也超越Qwen-3 0.6B。
在应用上,端侧长文本的突破带来更多可能。基于8B版本,团队微调出两个特定能力模型,分别可以用做MCP Client和纯端侧性能比肩Deep Research的研究报告神器MiniCPM4-Surve。
在MiniCPM-4的技术报告中,介绍其对于端侧模型架构、训练数据、训练算法和推理系统四个关键维度的系统性创新。
在模型架构方面,面壁提出InfLLM v2,一种可训练的稀疏注意力层,能同时加速长上下文处理的预填充和解码阶段,在保持模型性能的同时,实现高效的长文本处理。InfLLM v2通过将稀疏度从行业普遍的40%-50%,降至极致的5%,注意力层仅需1/10的计算量即可完成长文本计算。
针对单一架构难以兼顾长、短文本不同场景的技术难题,MiniCPM 4.0-8B采用「高效双频换挡」机制,能够根据任务特征自动切换注意力模式:
- 在处理高难度的长文本、深度思考任务时,启用稀疏注意力以降低计算复杂度;
- 在短文本场景下切换至稠密注意力以确保精度与速度,实现长、短文本切换的高效响应。
在最近一系列研究中,面壁研究人员已经总结出大模型的密度定律「Densing Law」,认为随着技术的不断演进,语言模型的能力密度平均每100天翻一番,人们还可以不断训练出计算更加高效,性能更加强大的基础大模型。
特性:
- 高效推理速度提升:通过自研CPM.cu推理框架、BitCPM极致低位宽量化、自研ArkInfer跨平台部署框架等技术,实现在极限场景下实现最高220倍的提速,常规场景下也能达到5倍的速度提升。
- 模型瘦身:采用创新的稀疏架构和极致低位宽量化技术,实现模型体积缩小90%,同时保持卓越的性能;
- 多平台适配:适配Intel、高通、MTK、华为昇腾等主流芯片;
- 高效部署:支持在vLLM、SGLang、LlamaFactory等开源框架上部署。
原理
- 稀疏注意力机制:可训练稀疏注意力机制(InfLLM v2),在处理长文本时,每个词元仅需与不到5%的其他词元进行相关性计算,极大地降低长文本处理的计算开销,提高计算效率,保持模型精度。
- 高效双频换挡机制:能够根据任务特征自动切换注意力模式。在处理长文本时启用稀疏注意力以降低计算复杂度,在处理短文本时切换至稠密注意力以确保精度。使得模型在不同任务场景下都能发挥最佳性能。
- 极致量化技术:BitCPM量化版本,通过将模型参数压缩为三进制值,实现90%的位宽减少,同时保持卓越性能。减少模型存储需求,进一步提升推理速度。
- 高效训练工程:采用FP8低精度计算技术,结合多词元预测(Multi-token Prediction)训练策略,提升训练效率。模型风洞2.0技术通过引入下游任务的Scaling预测方法,能够更精准地搜索并确定最佳的模型训练配置。
评测
参考:https://www.modelscope.cn/models/OpenBMB/MiniCPM4-8B
实战
pip install transformers torch modelscope
modelscope download --model OpenBMB/MiniCPM4-8B README.md --local_dir ./dir
Transformers推理示例:
from transformers import AutoModelForCausalLM, AutoTokenizer
import torchtorch.manual_seed(0)
path = 'openbmb/MiniCPM4-8B'
device = "cuda"
tokenizer = AutoTokenizer.from_pretrained(path)
model = AutoModelForCausalLM.from_pretrained(path, torch_dtype=torch.bfloat16, device_map=device, trust_remote_code=True)# User can directly use the chat interface
responds, history = model.chat(tokenizer, "Write an article about AI.", temperature=0.7, top_p=0.7)
print(responds)# User can also use the generate interface
messages = [{"role": "user", "content": "Write an article about AI."},]
prompt_text = tokenizer.apply_chat_template(messages,tokenize=False,add_generation_prompt=True,
)
model_inputs = tokenizer([prompt_text], return_tensors="pt").to(device)model_outputs = model.generate(**model_inputs, max_new_tokens=1024, top_p=0.7, temperature=0.7)output_token_ids = [model_outputs[i][len(model_inputs[i]):] for i in range(len(model_inputs['input_ids']))
]responses = tokenizer.batch_decode(output_token_ids, skip_special_tokens=True)[0]
print(responses)
CPM.cu
开源、集合高效稀疏、投机采样、量化等技术的CUDA推理框架,能够完全发挥MiniCPM4的效率优势。
安装:
git clone https://github.com/OpenBMB/CPM.cu.git --recursive
cd CPM.cu
python3 setup.py install
实例:
python3 tests/long_prompt_gen.py # 生成prompt.txt
python3 tests/test_generate.py --prompt-file prompt.txt
VoxCPM
官网,开源(GitHub,1.7K Star,176 Fork),HF,在线体验
VoxCPM是一个端到端的扩散自回归语音生成模型,旨在从输入文本直接合成高质量的连续语音表征,并且支持流式地实时输出生成音频片段。
与当前CosyVoice、FireRedTTS及SparkTTS等普遍遵循将连续的语音信号转换为离散的声学词元(Speech token)序列进行处理的方法不同,VoxCPM采用融合层次化语言建模和局部扩散生成的端到端TTS方案。以MiniCPM 4.0文本基座模型为基础进行初始化,通过引入有限标量约束构建结构化的中间表征,巧妙地实现语义-声学生成过程的隐式解耦,显著提升语音生成的表现力与自然度,有效改善生成稳定性。
模型核心架构由局部音频编码模块(LocEnc Module)、文本-语义语言模型(Text-Semantic LM,TSLM)、残差声学语言模型(Residual Acoustic LM,RALM)、局部扩散生成模块(LocDiT Module)四大模块组成,整个模型以端到端方式联合训练,通过最终VAE语音连续特征上的Diffusion Loss优化上述所有模块。FSQ层建立的半离散中间表示作为一种结构性约束,隐式地引导TSLM和RALM分别专注于语义主干建模和声学细节细化,从而形成高效的分工协作。系统还包含一个因果式VAE编解码器,用于将原始音频波形压缩至低帧率的隐空间,并将生成的语音表征重构回波形信号。
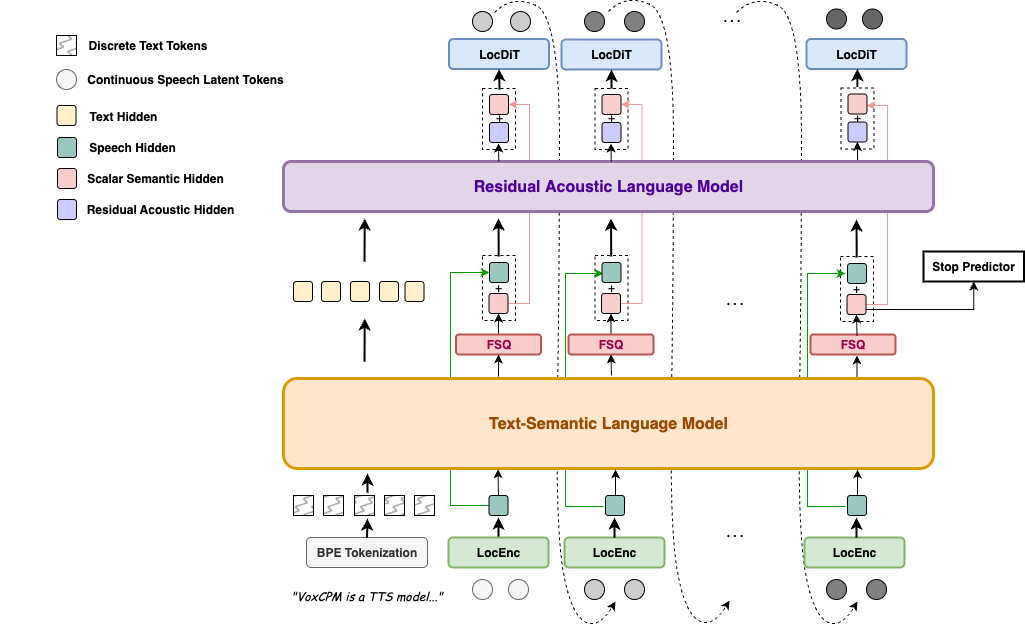
亮点
- 上下文感知、富有表现力的语音生成:能够理解文本并推断、生成合适的韵律,使语音具有出色的表现力和自然的流畅度。能够根据内容自发调整说话风格,生成高度契合的声音表达,其训练数据规模高达180万小时的双语语料库。
- 逼真语音克隆:只需一小段参考音频,就能实现高精度的零样本语音克隆,不仅能捕捉说话者的音色,还能细致还原其口音、情感语气、节奏与语速,生成自然、真实的声音副本。
- 高效合成:支持流式合成,在消费级4090上的实时因子(RTF)低至0.17,可满足实时应用场景的需求。
测评,Seed-TTS-EVAL。
指标:RTF,Real-Time Factor,模型生成音频所花费的时间/生成音频的实际时长,数字越小,生成速度和效率越快。RTF<0.2属于极好的推理水平,完全满足甚至远超高质量实时交互的需求,且成本及负载低。
安装:pip install voxcpm
示例
from huggingface_hub import snapshot_download
snapshot_download("openbmb/VoxCPM-0.5B", local_files_only=local_files_only)from modelscope import snapshot_download
snapshot_download('iic/speech_zipenhancer_ans_multiloss_16k_base')
snapshot_download('iic/SenseVoiceSmall')import soundfile as sf
from voxcpm import VoxCPMmodel = VoxCPM.from_pretrained("openbmb/VoxCPM-0.5B")wav = model.generate(text="VoxCPM is an innovative end-to-end TTS model from ModelBest, designed to generate highly expressive speech.",prompt_wav_path=None, # 语音克隆提示词wav文件路径,可选prompt_text=None, # 提示词文本,可选cfg_value=2.0, # LM guidance on LocDiT, higher for better adherence to the prompt, but maybe worseinference_timesteps=10, # LocDiT inference timesteps, higher for better result, lower for fast speednormalize=True, # enable external TN tooldenoise=True, # enable external Denoise toolretry_badcase=True, # 重试开关retry_badcase_max_times=3, # 最大重试次数retry_badcase_ratio_threshold=6.0, # maximum length restriction for bad case detection (simple but effective), it could be adjusted for slow pace speech
)
sf.write("output.wav", wav, 16000)
print("saved: output.wav")
CLI使用:
voxcpm --help python -m voxcpm.cli --help
# 直接合成
voxcpm --text "..." --output out.wav
# 语言克隆
voxcpm --text "..." --prompt-audio path/to/voice.wav --prompt-text "reference transcript" --output out.wav --denoise
# 批处理
voxcpm --input examples/input.txt --output-dir outs # (optional) Batch + cloning
voxcpm --input examples/input.txt --output-dir outs --prompt-audio path/to/voice.wav --prompt-text "reference transcript" --denoise
# 推理参数
voxcpm --text "..." --output out.wav --cfg-value 2.0 --inference-timesteps 10 --normalize
# 模型加载
voxcpm --text "..." --output out.wav --model-path /path/to/VoxCPM_model_dir
voxcpm --text "..." --output out.wav --hf-model-id openbmb/VoxCPM-0.5B --cache-dir ~/.cache/huggingface --local-files-only
# 去噪声控制
voxcpm --text "..." --output out.wav --no-denoiser --zipenhancer-path iic/speech_zipenhancer_ans_multiloss_16k_base
启动Web UI:python app.py
工具包
包括:
- BMTrain:
- BMCook
- BMInf
- OpenPrompt
- OpenDelta
- ModelCenter
参考/推荐资源
- 飞书知识库