oracle数据库 ZHS16GBK 数据库 VARCHAR2字段无法存储生僻字解决方案、如“䶮”生僻字、oracle utl_raw函数解释
由于数据库一直都是延期最开始的 ZHS16GBK字符集,实际使用中发现字段类型为varchar2时,
生僻字无法保存,存进去查询出来是?号。
一、终极解决方案(改数据库编码级,弊端很大)-不推荐
将数据库字符集改为 AL32UTF8(UTF-8 编码),VARCHAR2 也能直接支持所有 Unicode 字符。
这样就不必依赖 NVARCHAR2,统一使用 VARCHAR2 即可。
但这是一个重大变更,需要迁移数据,评估应用兼容性。
因为数据库改为UTF-8 编码 每个中文占用3个字节、而ZHS16GBK 数据库每个汉字占用两字节;而varchar的最大长度为4000字节;改为UTF-8会导致原有字段的内容可能长度不够而被截断,所以这个方式根本不适应已经上线的项目。
二、后台解决方案(碰到需手动处理)-推荐
2.1 字段类型 从VARCHAR2转为NVARCHAR2
首先需要把字段类型 从VARCHAR2转为NVARCHAR2 ,已验证PLSQL可以直接修改,并且对java程序等都不影响,不用改代码。

2.2 后台执行sql修改
改成NVARCHAR2 后 ,比如 用户姓名 “金䶮” ,其中“䶮” 为偏僻字保存后显示 “?”,
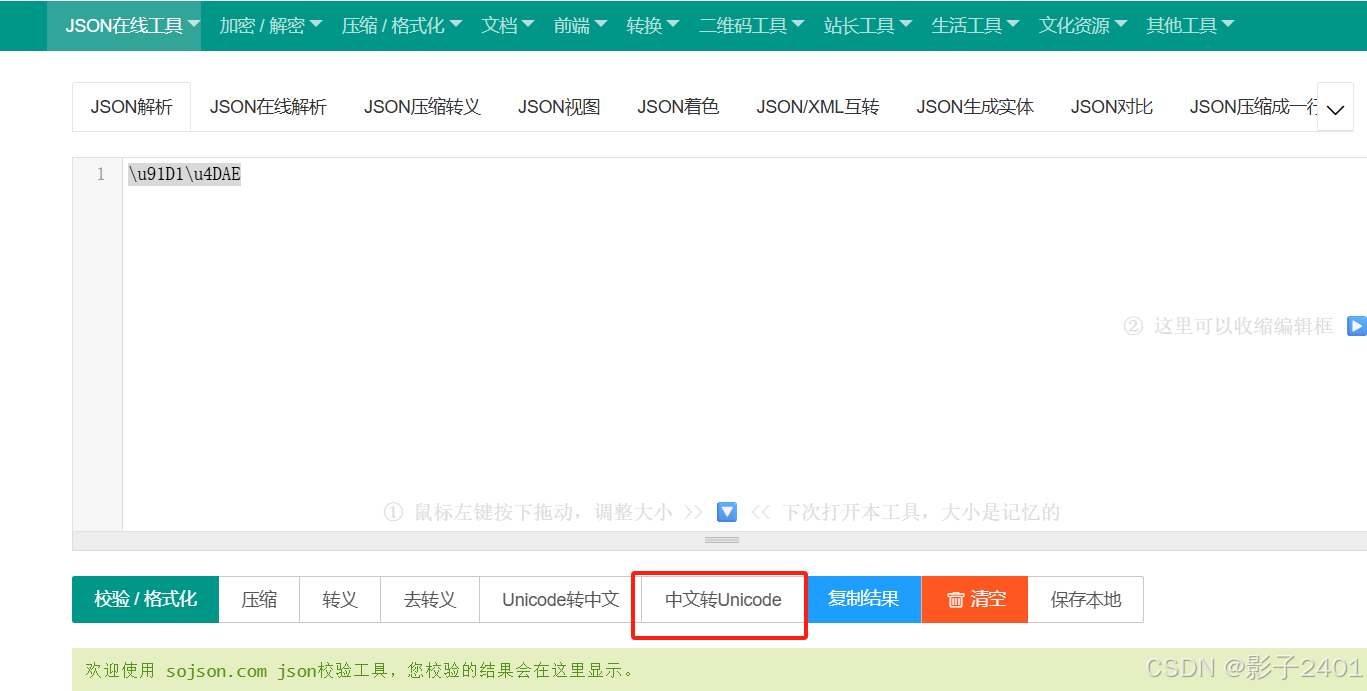
我们先查询到 “金䶮”的unicode编码
java有方法可以中文转unicode,我是直接使用在线网站工具
https://www.sojson.com/
金䶮 转为unicode编码为 \u91D1\u4DAE (Unicode 码点用十六进制表示)
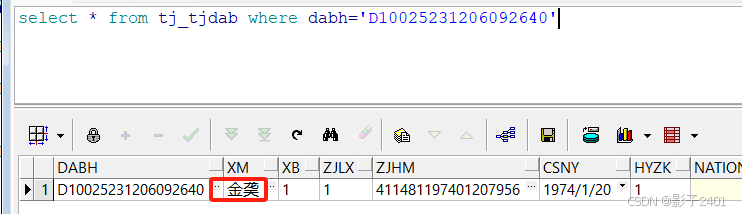
然后数据库后台执行sql修改姓名, \不需要
update tj_tjdab set xm=(select utl_raw.cast_to_nvarchar2('91D14DAE') from dual) where dabh='D10025231206092640'
执行后再次查询发现数据库已经保存正常了
oracle utl_raw函数解释
UTL_RAW.CAST_TO_NVARCHAR2(raw_value)
- 功能:将一个 RAW 类型的字节序列,按照国家字符集(NCHAR Character Set)的编码方式,转换为 NVARCHAR2 字符串。
- 输入:RAW 类型(通常是一个十六进制字符串,如 ‘91D14DAE’)。
- 输出:NVARCHAR2 字符串。
- 关键点:这个转换是 按字节解释,不是按数据库字符集(如 ZHS16GBK),而是按 国家字符集(通常是 AL16UTF16)来解码。