3dgs train.py详解
目录
参数解释
1. datase
2. opt
3. pipe
4. testing_iterations
5. saving_iteration
6. checkpoint_iterations
7. checkpoint
8. debug_from
tb_writer = prepare_output_and_logger(dataset)。
1. 确定并创建输出目录
2. 保存训练配置
3. 初始化 TensorBoard 日志记录器
GaussianModel
方法参数 (传入的配置)
实例属性 (创建的“容器”)
核心高斯参数
训练与优化相关的属性
self.setup_functions()
参数解释
1. dataset
-
来源: 这个参数对象来自于
ModelParams类的实例,并通过lp.extract(args)创建。ModelParams定义了所有与数据加载和模型结构相关的参数。 -
作用: 它像一个“数据说明书”,告诉训练函数所有关于输入数据的信息。
-
包含的核心属性:
-
dataset.source_path: 必需,指向包含sparse/0文件夹的数据集根目录。 -
dataset.model_path: 本次训练的模型和日志的输出路径。 -
dataset.sh_degree: 球谐函数(SH)的最高阶数,决定了模型能表示的颜色细节的复杂度,默认为3。 -
dataset.white_background: 是否使用白色背景,对于像 NeRF synthetic 这样的数据集是必需的。 -
dataset.eval: 是否启用评估模式,即从训练集中分出一部分作为测试集。
-
2. opt
-
来源: 这个参数对象来自于
OptimizationParams类的实例,并通过op.extract(args)创建。OptimizationParams定义了所有与训练过程和超参数相关的设置。 -
作用: 它是“训练策略指南”,规定了模型应该如何被优化。
-
包含的核心属性:
-
opt.iterations: 总训练迭代次数,默认为30_000。 -
学习率: 包括
position_lr_init,feature_lr,scaling_lr等一系列学习率,分别控制高斯球不同属性(位置、颜色、大小等)的更新速度。 -
致密化参数: 包括
densify_from_iter,densify_until_iter,densification_interval,densify_grad_threshold等,精确控制了高斯球何时开始、何时结束以及如何进行增殖和分裂。 -
opt.lambda_dssim:L1损失和DSSIM损失之间的权重,默认为0.2。
-
3. pipe
-
来源: 这个参数对象来自于
PipelineParams类的实例,并通过pp.extract(args)创建。PipelineParams定义了与渲染管线行为相关的参数。 -
作用: 它是“渲染器配置单”,用于控制渲染过程中的一些底层行为。
-
包含的核心属性:
-
pipe.convert_SHs_python: 是否使用纯 Python(PyTorch)而不是自定义的 CUDA 内核来计算球谐函数。这通常用于调试,速度会慢很多。 -
pipe.compute_cov3D_python: 同上,是否用纯 Python 计算3D协方差。 -
pipe.debug: 是否开启渲染器的调试模式。
-
4. testing_iterations
-
来源: 来自于命令行的
--test_iterations参数,它是一个整数列表。 -
作用: 它告诉训练函数在哪些迭代时刻需要进行一次评估。
-
具体行为: 在主训练循环中,当
iteration的值出现在这个列表里时(例如,第7000次),程序会暂停训练,在测试集上渲染所有图像,计算PSNR和L1等指标,并将结果打印出来或记录到 TensorBoard。 -
默认值:
[7_000, 30_000]。
5. saving_iteration
-
来源: 来自于命令行的
--save_iterations参数,也是一个整数列表。 -
作用: 它告诉训练函数在哪些迭代时刻需要保存一次完整的模型快照。
-
具体行为: 当
iteration的值出现在这个列表里时,程序会调用scene.save(iteration)方法,将当前所有高斯球的状态保存为一个.ply文件,存放在output/.../point_cloud/iteration_.../目录下。 -
默认值:
[7_000, 30_000],并且在程序启动时会自动追加上总迭代次数args.iterations。
6. checkpoint_iterations
-
来源: 来自于命令行的
--checkpoint_iterations参数,一个整数列表。 -
作用: 它告诉训练函数在哪些时刻需要保存一个可用于续训的检查点。
-
与
save_iterations的区别:-
saving_iterations保存的是最终用于渲染的模型(.ply文件),它只包含高斯球的参数。 -
checkpoint_iterations保存的是一个包含模型参数和优化器状态的完整 PyTorch 文件(.pth文件)。只有这个文件才能让你在中断训练后,从完全相同的状态(包括动量等优化器内部状态)无缝地继续训练。
-
-
默认值: 空列表
[]。
7. checkpoint
-
来源: 来自于命令行的
--start_checkpoint参数,它是一个字符串,指向一个.pth文件的路径。 -
作用: 如果这个参数被提供,它告诉训练函数不要从头开始,而是从指定的检查点文件加载模型和优化器状态,然后继续训练。
-
具体行为: 在
training函数的开头,会有一个if checkpoint:的判断,如果为真,则会执行torch.load(checkpoint)和gaussians.restore(...)来恢复训练状态。 -
默认值:
None。
8. debug_from
-
来源: 来自于命令行的
--debug_from参数,是一个整数。 -
作用: 这是一个调试工具,它告诉渲染管线从第几次迭代之后才开始开启调试模式。
-
具体行为: 在训练循环中,会检查
if (iteration - 1) == debug_from:,如果条件满足,就会设置pipe.debug = True。这在调试后期出现的 bug 时非常有用,可以避免在程序前期就因开启 debug 模式而导致运行速度过慢。 -
默认值:
-1(表示默认不开启)。
tb_writer = prepare_output_and_logger(dataset)。
这行代码是训练开始前的一个重要准备步骤,它负责**“创建本次训练的工作区并设置一个强大的可视化日志工具”**。
我们可以将 prepare_output_and_logger 函数 的功能分解为三个核心任务:
1. 确定并创建输出目录
-
作用:为本次训练创建一个专属的文件夹,用来存放所有产物,包括最终的模型、配置文件、日志等。
-
代码逻辑:
Python# train.py -> prepare_output_and_logger function if not args.model_path:# ... (creates a unique string)args.model_path = os.path.join("./output/", unique_str[0:10])print("Output folder: {}".format(args.model_path)) os.makedirs(args.model_path, exist_ok = True)-
首先,它检查用户是否通过
-m或--model_path参数指定了输出目录 (args.model_path)。 -
如果用户没有指定,它会自动在项目根目录下的
output/文件夹中,创建一个以随机字符串命名的子文件夹(例如./output/a1b2c3d4e5)。这确保了每次运行都有一个不重复的工作区。 -
如果用户指定了,它就使用用户提供的路径。
-
os.makedirs(...): 确保这个目录被创建在硬盘上。exist_ok=True表示如果目录已存在,则不会报错。
-
2. 保存训练配置
-
作用:将本次训练使用的所有参数(学习率、迭代次数、数据集路径等)保存到一个文件中,以便未来的查阅和复现。
-
代码逻辑:
Python# train.py -> prepare_output_and_logger function with open(os.path.join(args.model_path, "cfg_args"), 'w') as cfg_log_f:cfg_log_f.write(str(Namespace(**vars(args))))-
它会在刚刚创建的输出目录中,新建一个名为
cfg_args的文件。 -
然后,它将
args这个包含了所有配置参数的对象,转换成字符串形式,并写入到这个文件中。 -
这是一个极其重要的好习惯!它意味着你以后随时可以查看这个文件,确切地知道某个成功的模型是用什么样的参数训练出来的。
-
3. 初始化 TensorBoard 日志记录器
-
作用:创建一个
SummaryWriter对象,它是与 TensorBoard 这个强大的可视化工具交互的接口。 -
代码逻辑:
Python# train.py -> prepare_output_and_logger function tb_writer = None if TENSORBOARD_FOUND:tb_writer = SummaryWriter(args.model_path) else:print("Tensorboard not available: not logging progress") return tb_writer-
TENSORBOARD_FOUND是一个布尔值,在文件开头检查torch.utils.tensorboard是否能被成功导入。 -
如果 TensorBoard 可用:
-
tb_writer = SummaryWriter(args.model_path): 这行代码创建了一个SummaryWriter的实例。关键在于,它将日志的输出路径指定为我们刚刚创建的模型输出目录。 -
这意味着,所有通过
tb_writer记录的数据都会被保存在这个文件夹里。
-
-
如果 TensorBoard 不可用:
tb_writer将是None,并且程序会打印一条提示信息。 -
return tb_writer: 函数最后返回这个创建好的tb_writer对象(或者None)。
-
GaussianModel
方法参数 (传入的配置)
首先,我们解释传入 __init__ 方法的两个参数:
-
sh_degree:-
类型:
int(整数) -
含义: 这是球谐函数 (Spherical Harmonics, SH) 的最高阶数。球谐函数是用来表示高斯球颜色的,阶数越高,能表示的颜色就越复杂,特别是能更好地表现出随视角变化的反射和光泽效果。
-
作用: 这个值被赋给
self.max_sh_degree,作为模型能够学习到的颜色复杂度的上限。通常设置为3。
-
-
optimizer_type="default":-
类型:
str(字符串) -
含义: 指定在训练时要使用的优化器类型。
-
作用: 这个值被赋给
self.optimizer_type。代码支持"default"(标准的 PyTorch Adam 优化器) 和"sparse_adam"(一个为高斯溅射优化的稀疏版本 Adam 优化器,可以提升训练速度)。
-
实例属性 (创建的“容器”)
接下来是 self.xxx 这一系列属性,它们是构成 GaussianModel 实例的核心。
核心高斯参数
这些属性直接定义了每个3D高斯球的物理特性。它们以下划线 _ 开头,表示它们是“原始”的、未经激活函数处理的内部参数。它们都被初始化为空的张量 (torch.empty(0)), 等待 create_from_pcd 方法从点云数据中填充。
-
self._xyz: 存储所有高斯球中心点的 XYZ 坐标。 -
self._features_dc: 存储球谐函数的直流(DC)分量。这可以理解为每个高斯球的基础颜色 (不随视角变化的部分)。 -
self._features_rest: 存储球谐函数的交流(AC)分量,即除了DC之外的所有高阶系数。它们负责表现颜色随视角变化的细节。 -
self._scaling: 存储每个高斯球在三个轴上的缩放因子。它们决定了高斯椭球的大小和形状。 -
self._rotation: 存储每个高斯球的旋转,通常以四元数的形式表示。它们决定了高斯椭球在空间中的朝向。 -
self._opacity: 存储每个高斯球的不透明度。它决定了这个高斯球是更接近透明还是实体。
训练与优化相关的属性
这些属性是在训练过程中用来辅助模型优化和自适应控制的。
-
self.active_sh_degree: 当前训练中实际使用的球谐函数阶数。它从0开始,在训练过程中会逐步增加,直到达到self.max_sh_degree。这种渐进式的方法有助于训练的稳定。 -
self.max_sh_degree: 从sh_degree参数传入,定义了球谐函数的最高阶数上限。 -
self.max_radii2D: 一个张量,用来记录每个高斯球在被投影到屏幕上时,曾经达到过的最大半径。这个值在“剪枝”步骤中被用来移除那些在屏幕上占据面积过大的高斯球。 -
self.xyz_gradient_accum: 梯度累加器。它累加每个高斯球在多次迭代中的位置梯度的大小。这个累加的梯度是判断一个高斯球是否需要被“致密化”(分裂或复制)的核心依据。 -
self.denom: 分母 (denominator)。它记录了每个高斯球被观测到(即对渲染有贡献)的次数。xyz_gradient_accum / denom就能得到平均梯度。 -
self.optimizer: 用来存放 PyTorch 优化器对象(例如torch.optim.Adam)的变量。初始时为None,在调用training_setup方法后才会被真正创建。 -
self.percent_dense: 一个与致密化相关的参数,用于处理场景边缘的特殊情况,此处初始化为0。 -
self.spatial_lr_scale: 空间学习率缩放因子。这是一个用于调整位置学习率的参数,与场景的大小有关,此处初始化为0。
training_setup
初始化密度相关参数与梯度累积变量
self.percent_dense = training_args.percent_dense # 用于后续筛选需要增密的高斯点(与场景尺度相关)
self.xyz_gradient_accum = torch.zeros((self.get_xyz.shape[0], 1), device="cuda") # 累积高斯位置的梯度
self.denom = torch.zeros((self.get_xyz.shape[0], 1), device="cuda") # 梯度累积的分母(用于平均)定义优化器的参数组
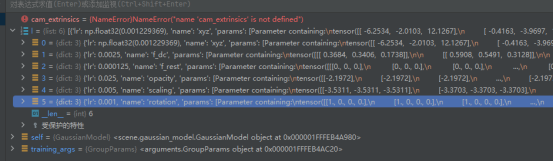
l = [{'params': [self._xyz], 'lr': training_args.position_lr_init * self.spatial_lr_scale, "name": "xyz"},{'params': [self._features_dc], 'lr': training_args.feature_lr, "name": "f_dc"},{'params': [self._features_rest], 'lr': training_args.feature_lr / 20.0, "name": "f_rest"},{'params': [self._opacity], 'lr': training_args.opacity_lr, "name": "opacity"},{'params': [self._scaling], 'lr': training_args.scaling_lr, "name": "scaling"},{'params': [self._rotation], 'lr': training_args.rotation_lr, "name": "rotation"}
]- 为模型的不同参数(位置、颜色特征、不透明度、缩放、旋转)分配不同的学习率:
- 位置参数(
_xyz)的学习率乘以spatial_lr_scale(空间尺度因子),适配场景大小; _features_dc形状为(N, 1, 3),其中N是高斯点数量,1对应 0 阶球谐分量,3对应 RGB 三个颜色通道。学习率设置:使用training_args.feature_lr(基础特征学习率),因为直流分量对基础颜色影响显著,需要相对较快的更新速度以确保基础颜色快速收敛- 高阶球谐特征(
_features_rest)的学习率是基础特征学习率的 1/20,避免更新过于剧烈; - 其他参数(如不透明度、缩放、旋转)使用独立的学习率,根据其重要性和更新敏感性调整。
- 位置参数(
初始化优化器
if self.optimizer_type == "default":self.optimizer = torch.optim.Adam(l, lr=0.0, eps=1e-15) # 默认使用 Adam 优化器
elif self.optimizer_type == "sparse_adam":try:self.optimizer = SparseGaussianAdam(l, lr=0.0, eps=1e-15) # 稀疏高斯专用优化器(需特殊渲染器支持)except:self.optimizer = torch.optim.Adam(l, lr=0.0, eps=1e-15) # fallback 到普通 Adam- 根据配置选择优化器,默认使用 Adam,也支持针对稀疏高斯分布优化的
SparseGaussianAdam(若环境支持)。 - 初始学习率设为 0,后续通过学习率调度器动态更新。
Adam 的处理机制分解如下:
-
遍历列表
l: 优化器拿到列表l后,会逐个处理里面的元素。 -
解析字典: 当它看到第一个元素是一个字典
{'params': [self._xyz], 'lr': ..., "name": ...}时,它会做两件事:-
识别参数: 它会找到键为
'params'的值,也就是[self._xyz]。优化器就知道self._xyz这个张量是需要它来管理的、需要计算梯度并更新的参数。 -
应用特定设置: 它会检查字典里其他的键,比如
'lr'。它发现这里为'params'里的参数指定了一个特定的学习率。这个学习率会覆盖torch.optim.Adam(..., lr=0.0)中设置的全局默认学习率。其他的键如"name"会被优化器忽略,但可以用于我们自己代码的逻辑判断。
-
-
构建参数组: 优化器会为列表中的每一个字典创建一个内部的“参数组”。在这个例子中,
Adam优化器内部维护了6个独立的参数组,每个组包含一种高斯球的属性(位置、颜色、缩放等),并且每个组都有自己独立的学习率。 -
执行更新: 当
optimizer.step()被调用时,优化器会遍历它内部所有的参数组。对于每一个组,它会用该组特定的学习率(以及其他可能的设置,如weight_decay)来更新该组内的所有参数。
始化曝光参数优化器
self.exposure_optimizer = torch.optim.Adam([self._exposure]) # 单独为曝光参数创建优化器配置学习率调度策略
# 位置参数的学习率调度(指数衰减)
self.xyz_scheduler_args = get_expon_lr_func(lr_init=training_args.position_lr_init*self.spatial_lr_scale,lr_final=training_args.position_lr_final*self.spatial_lr_scale,lr_delay_mult=training_args.position_lr_delay_mult,max_steps=training_args.position_lr_max_steps
)# 曝光参数的学习率调度(指数衰减)
self.exposure_scheduler_args = get_expon_lr_func(training_args.exposure_lr_init, training_args.exposure_lr_final,lr_delay_steps=training_args.exposure_lr_delay_steps,lr_delay_mult=training_args.exposure_lr_delay_mult,max_steps=training_args.iterations
)- 使用
get_expon_lr_func生成指数衰减的学习率函数,使学习率随迭代次数逐渐从初始值衰减到最终值,避免训练后期参数震荡。 - 位置参数和曝光参数的调度策略独立设置,适配各自的优化需求。
训练准备
设置背景颜色:根据数据集参数选择白色或黑色背景,并转换为 CUDA 张量
bg_color = [1, 1, 1] if dataset.white_background else [0, 0, 0]background = torch.tensor(bg_color, dtype=torch.float32, device="cuda")创建 CUDA 事件对象,用于记录每轮迭代的时间
iter_start = torch.cuda.Event(enable_timing = True)iter_end = torch.cuda.Event(enable_timing = True) use_sparse_adam = opt.optimizer_type == "sparse_adam" and SPARSE_ADAM_AVAILABLE depth_l1_weight = get_expon_lr_func(opt.depth_l1_weight_init, opt.depth_l1_weight_final, max_steps=opt.iterations)- 初始化辅助变量:
use_sparse_adam:标记是否使用稀疏 Adam 优化器depth_l1_weight:深度损失的权重调度函数(从初始值指数衰减到最终值)
viewpoint_stack = scene.getTrainCameras().copy()viewpoint_indices = list(range(len(viewpoint_stack)))ema_loss_for_log = 0.0ema_Ll1depth_for_log = 0.0- 初始化训练相机队列和日志变量:
viewpoint_stack:训练相机列表的副本(用于随机选取视角)viewpoint_indices:相机索引列表(辅助随机选取)ema_loss_for_log和ema_Ll1depth_for_log:损失和深度损失的指数移动平均值(用于日志显示)
progress_bar = tqdm(range(first_iter, opt.iterations), desc="Training progress")first_iter += 1创建进度条(tqdm),范围从起始迭代到总迭代次数;first_iter 自增 1,确保迭代从正确次数开始
训练循环
for iteration in range(first_iter, opt.iterations + 1):开始循环,默认一共30000次
while network_gui.conn != None:try:net_image_bytes = Nonecustom_cam, do_training, pipe.convert_SHs_python, pipe.compute_cov3D_python, keep_alive, scaling_modifer = network_gui.receive()if custom_cam != None:net_image = render(custom_cam, gaussians, pipe, background, scaling_modifier=scaling_modifer, use_trained_exp=dataset.train_test_exp, separate_sh=SPARSE_ADAM_AVAILABLE)["render"]net_image_bytes = memoryview((torch.clamp(net_image, min=0, max=1.0) * 255).byte().permute(1, 2, 0).contiguous().cpu().numpy())network_gui.send(net_image_bytes, dataset.source_path)if do_training and ((iteration < int(opt.iterations)) or not keep_alive):breakexcept Exception as e:network_gui.conn = None- GUI 交互逻辑:
- 接收 GUI 发送的指令(如自定义相机视角、是否继续训练等)
- 若收到自定义相机,渲染该视角的图像并发送回 GUI
- 当满足训练条件时(
do_training为真且未达最大迭代),退出 GUI 交互循环,继续训练
如何使用GUI
一、GUI 工具介绍
根据代码和文档,有两个核心 GUI 工具:
- 网络 viewer(SIBR_remoteGaussian_app)用于连接正在运行的训练进程,实时查看训练中的渲染效果,支持调整视角、参数等。
- 实时 viewer(SIBR_gaussianViewer_app)用于加载训练完成的模型,进行高帧率交互式渲染和场景探索。
二、网络 viewer(训练时实时可视化)
1. 前提条件
- 已安装 SIBR_viewers(GUI 依赖框架):
- Windows 可直接下载预编译 binaries。
- 源码安装:参考README.md,需编译
SIBR_viewers(支持 Windows 和 Ubuntu)。
2. 使用步骤
(1)启动训练进程(带 GUI 服务)
训练脚本train.py默认会启动 GUI 服务器(通过network_gui.py实现),默认 IP 为127.0.0.1,端口6009。启动命令示例:
python train.py -s <你的数据集路径> --ip 127.0.0.1 --port 6009(2)启动网络 viewer 客户端
打开 SIBR_viewers 的可执行文件SIBR_remoteGaussian_app(Windows 在bin目录下,Linux 需编译后运行):
# Windows示例(假设解压到viewers目录)
./viewers/bin/SIBR_remoteGaussian_app.exe --ip 127.0.0.1 --port 6009
# Linux示例(编译后)
./SIBR_viewers/build/install/bin/SIBR_remoteGaussian_app --ip 127.0.0.1 --port 6009(3)交互功能
- 实时渲染:viewer 会连接训练进程,显示当前模型的渲染结果。
- 调整视角:通过鼠标 / 键盘控制相机位置,实时生成新视角的渲染图。
- 参数控制:在 viewer 界面中可调整
scaling_modifier、是否继续训练等(通过network_gui.receive()与训练进程通信)。
三、实时 viewer(训练后可视化)
1. 前提条件
- 已完成训练,得到模型输出目录(如
./output/xxx)。
2. 使用步骤
(1)启动实时 viewer
运行SIBR_gaussianViewer_app,指定训练好的模型路径:
# Windows示例
./viewers/bin/SIBR_gaussianViewer_app.exe -m ./output/xxx # 替换为你的模型目录
# Linux示例
./SIBR_viewers/build/install/bin/SIBR_gaussianViewer_app -m ./output/xxx2)交互功能
- 高帧率渲染:支持实时旋转、缩放场景,帧率可达数百 FPS。
- 可视化选项:可切换显示高斯椭球体、点云等模式(通过浮动菜单选择)。
- 分辨率调整:通过
--rendering-size <width> <height>指定渲染分辨率
iter_start.record()记录迭代开始时间
gaussians.update_learning_rate(iteration)更新学习率:根据当前迭代次数,通过调度函数更新各参数组的学习率(如 3D 位置参数的学习率衰减)
def update_learning_rate(self, iteration):''' Learning rate scheduling per step '''# 检查是否使用预训练的曝光参数,如果没有(即需要训练曝光参数)if self.pretrained_exposures is None:# 遍历曝光优化器的参数组(通常只有一个参数组对应曝光变换矩阵)for param_group in self.exposure_optimizer.param_groups:# 根据当前迭代次数更新曝光参数的学习率,使用预定义的曝光学习率调度函数param_group['lr'] = self.exposure_scheduler_args(iteration)# 遍历主优化器的所有参数组(包含xyz、features、opacity等参数)for param_group in self.optimizer.param_groups:# 找到名称为"xyz"的参数组(对应3D高斯的位置参数)if param_group["name"] == "xyz":# 根据当前迭代次数计算位置参数的学习率,使用预定义的位置学习率调度函数lr = self.xyz_scheduler_args(iteration)# 更新位置参数的学习率param_group['lr'] = lr# 返回更新后的位置参数学习率(其他参数组的学习率在此函数中不更新,使用固定值)return lr# Every 1000 its we increase the levels of SH up to a maximum degreeif iteration % 1000 == 0:gaussians.oneupSHdegree()每 1000 次迭代提升球谐函数阶数:逐步增加高斯点颜色特征的频率复杂度(最高不超过 max_sh_degree
if not viewpoint_stack:viewpoint_stack = scene.getTrainCameras().copy()viewpoint_indices = list(range(len(viewpoint_stack)))rand_idx = randint(0, len(viewpoint_indices) - 1)viewpoint_cam = viewpoint_stack.pop(rand_idx)vind = viewpoint_indices.pop(rand_idx)随机选择训练相机:
- 若相机队列为空,重新填充训练相机列表
- 随机选择一个相机并从队列中移除(避免重复选择)
例子:
if (iteration - 1) == debug_from:pipe.debug = True启用调试模式:当迭代次数达到 debug_from 时,开启渲染流水线的调试模式
bg = torch.rand((3), device="cuda") if opt.random_background else background确定当前迭代的背景:若启用随机背景,则生成随机 RGB 值;否则使用固定背景
注:0 0 0对应背景是纯黑色
渲染
render_pkg = render(viewpoint_cam, gaussians, pipe, bg, use_trained_exp=dataset.train_test_exp, separate_sh=SPARSE_ADAM_AVAILABLE)image, viewspace_point_tensor, visibility_filter, radii = render_pkg["render"], render_pkg["viewspace_points"], render_pkg["visibility_filter"], render_pkg["radii"]渲染当前视角的图像:
render函数返回渲染结果包,包含渲染图像(image)、高斯点在视图空间的位置(viewspace_point_tensor)、可见性掩码(visibility_filter)、图像空间半径(radii)等
render函数详解:
参数:
viewpoint_camera:当前渲染视角的相机对象,包含相机内外参(如视场角、位姿、图像宽高、相机中心等),用于确定渲染时的视角。pc : GaussianModel:GaussianModel类的实例,代表场景中的 3D 高斯点云,包含高斯的位置、颜色、尺度、旋转等核心参数。pipe:渲染管道配置对象,存储渲染相关的全局设置(如是否在 Python 中计算协方差、是否将球谐函数转换为 RGB 等)。bg_color : torch.Tensor:背景颜色张量(需在 GPU 上),用于填充渲染图像中无高斯覆盖的区域。scaling_modifier = 1.0:尺度修正因子,用于临时调整高斯的尺度大小(例如调试时放大 / 缩小高斯以观察效果)。separate_sh = False:是否将球谐函数(SH)的直流分量(DC)与高阶分量分离处理,用于优化渲染效率或特定场景。override_color = None:若不为None,则使用该张量强制覆盖高斯的原始颜色(用于调试或特殊渲染需求)。use_trained_exp=False:是否使用训练好的曝光参数对渲染结果进行颜色校正(通常在训练阶段启用,用于调整图像曝光)。
函数功能:
- 根据相机参数和 3D 高斯模型,配置光栅化参数(如视场角、图像尺寸、投影矩阵等)。
- 准备高斯点云的相关数据(位置、透明度、尺度、旋转、颜色等),其中颜色可能通过球谐函数计算或直接使用预计算值。
- 调用光栅化器(
GaussianRasterizer)将 3D 高斯投影到 2D 图像平面,生成渲染结果。 - 可选地应用曝光校正,并返回渲染图像、可见性掩码等信息。
逐行解释细节:
# 创建与高斯点3D位置同形状的屏幕空间点张量,初始化为0并启用梯度跟踪# 用于后续计算2D屏幕空间坐标的梯度(反向传播时需要)screenspace_points = torch.zeros_like(pc.get_xyz, dtype=pc.get_xyz.dtype, requires_grad=True, device="cuda") + 0try:# 强制保留梯度(即使在推理模式下也可能需要)screenspace_points.retain_grad()except:pass如下图所示,形状和高斯点数量相同
# 配置光栅化参数# 计算相机水平和垂直视场角的正切值(用于将3D坐标投影到2D屏幕)tanfovx = math.tan(viewpoint_camera.FoVx * 0.5)tanfovy = math.tan(viewpoint_camera.FoVy * 0.5) raster_settings = GaussianRasterizationSettings(image_height=int(viewpoint_camera.image_height), # 渲染图像高度image_width=int(viewpoint_camera.image_width), # 渲染图像宽度tanfovx=tanfovx, # 水平视场角正切值tanfovy=tanfovy, # 垂直视场角正切值bg=bg_color, # 背景颜色scale_modifier=scaling_modifier, # 高斯尺度修正因子viewmatrix=viewpoint_camera.world_view_transform, # 世界坐标系到相机坐标系的变换矩阵projmatrix=viewpoint_camera.full_proj_transform, # 相机坐标系到裁剪坐标系的投影矩阵sh_degree=pc.active_sh_degree, # 当前激活的球谐函数阶数campos=viewpoint_camera.camera_center, # 相机在世界坐标系中的位置prefiltered=False, # 是否预过滤高斯(通常为False)debug=pipe.debug, # 是否启用调试模式antialiasing=pipe.antialiasing # 是否启用抗锯齿)
初始化光栅化设置对象,包含渲染所需所有相机参数和配置
# 创建光栅化器实例,传入光栅化设置rasterizer = GaussianRasterizer(raster_settings=raster_settings)# 从高斯模型中获取3D位置、不透明度等核心参数means3D = pc.get_xyz # 高斯点的3D位置means2D = screenspace_points # 高斯点的2D屏幕空间坐标(初始为0,由光栅化器计算)opacity = pc.get_opacity # 高斯点的不透明度(经过sigmoid激活)# 初始化高斯的尺度、旋转和预计算的3D协方差矩阵(根据配置选择计算方式)scales = Nonerotations = Nonecov3D_precomp = Noneif pipe.compute_cov3D_python:# 若配置为在Python中计算3D协方差,则直接调用高斯模型的方法计算cov3D_precomp = pc.get_covariance(scaling_modifier)else:# 否则,获取尺度和旋转参数,由光栅化器在CUDA中计算协方差scales = pc.get_scalingrotations = pc.get_rotation-
缩放矩阵(Scales)
- 论文中,每个 3D 高斯通过缩放参数控制其在 3D 空间中的大小和形状(如沿 X、Y、Z 轴的拉伸)。
- 代码中,
pc.get_scaling返回经过激活函数处理的缩放值(通过self.scaling_activation = torch.exp计算,确保缩放为正数)。这些值定义了高斯在局部坐标系下的轴对齐缩放因子(即缩放矩阵为对角矩阵,对角线元素为这些缩放值)。
-
旋转矩阵(Rotations)
- 论文中,旋转参数用于将高斯从局部坐标系旋转到世界坐标系,以适应场景中物体的姿态。
- 代码中,
pc.get_rotation返回经过归一化的四元数(通过self.rotation_activation = torch.nn.functional.normalize处理),后续会通过build_rotation函数转换为 3x3 的旋转矩阵(见 utils/general_utils.py 中的build_scaling_rotation函数)。
# 处理高斯点的颜色(根据配置选择球谐函数转换方式或使用预定义颜色)shs = None # 球谐函数系数colors_precomp = None # 预计算的RGB颜色if override_color is None:# 未指定覆盖颜色时,使用高斯模型自身的颜色(通过球谐函数计算)if pipe.convert_SHs_python:# 若配置为在Python中转换球谐函数为RGB# 调整球谐系数的形状,准备计算shs_view = pc.get_features.transpose(1, 2).view(-1, 3, (pc.max_sh_degree+1)**2)# 计算高斯点到相机中心的方向向量(用于球谐函数评估)dir_pp = (pc.get_xyz - viewpoint_camera.camera_center.repeat(pc.get_features.shape[0], 1))dir_pp_normalized = dir_pp / dir_pp.norm(dim=1, keepdim=True) # 归一化方向向量# 将球谐系数转换为RGB颜色(+0.5是为了抵消训练时的中心化,clamp_min确保非负)sh2rgb = eval_sh(pc.active_sh_degree, shs_view, dir_pp_normalized)colors_precomp = torch.clamp_min(sh2rgb + 0.5, 0.0)else:# 不在Python中转换球谐函数,直接传递系数给光栅化器,由CUDA计算RGBif separate_sh:# 分离直流分量(DC)和高阶球谐分量(用于优化渲染效率)dc, shs = pc.get_features_dc, pc.get_features_restelse:# 不分离,直接使用所有球谐系数shs = pc.get_featureselse:# 使用指定的颜色覆盖高斯点的原始颜色(调试用)colors_precomp = override_color
这里我有一个疑问,高斯球的颜色是用球谐系数来表示的,为什么还要计算colors_precomp呢?
1. colors_precomp的本质:预计算的颜色值
colors_precomp是预先计算好的 RGB 颜色值(形状为[N, 3],N为高斯球数量),用于直接传递给光栅化器作为高斯球的颜色,避免在光栅化过程中实时计算 SH 到 RGB 的转换。
2. 为什么需要colors_precomp?
球谐系数本身并不直接是颜色,而是方向相关的颜色基函数参数。要得到最终的 RGB 颜色,需要根据观察方向(从高斯球到相机的向量)对 SH 系数进行解码(即eval_sh函数的计算)
# 调用光栅化器渲染图像,返回渲染结果、高斯点在屏幕上的半径和深度图if separate_sh:# 分离球谐分量时,传入dc和shsrendered_image, radii, depth_image = rasterizer(means3D = means3D, # 3D位置means2D = means2D, # 2D屏幕坐标(初始为0)dc = dc, # 球谐直流分量shs = shs, # 球谐高阶分量colors_precomp = colors_precomp, # 预计算颜色(若有)opacities = opacity, # 不透明度scales = scales, # 尺度参数(若在CUDA中计算协方差)rotations = rotations, # 旋转参数(若在CUDA中计算协方差)cov3D_precomp = cov3D_precomp # 预计算的3D协方差(若在Python中计算))else:# 不分离球谐分量时,直接传入shsrendered_image, radii, depth_image = rasterizer(means3D = means3D,means2D = means2D,shs = shs,colors_precomp = colors_precomp,opacities = opacity,scales = scales,rotations = rotations,cov3D_precomp = cov3D_precomp)# 若启用训练好的曝光参数,对渲染结果进行颜色校正(仅训练阶段使用)if use_trained_exp:# 获取当前视角对应的曝光参数exposure = pc.get_exposure_from_name(viewpoint_camera.image_name)# 应用曝光变换:矩阵乘法(颜色调整)+ 偏移(亮度调整)rendered_image = torch.matmul(rendered_image.permute(1, 2, 0), exposure[:3, :3]).permute(2, 0, 1) + exposure[:3, 3, None, None]# 将渲染结果裁剪到[0, 1]范围(确保颜色值合法)rendered_image = rendered_image.clamp(0, 1)# 整理输出字典,包含渲染图像、屏幕空间点、可见性掩码、半径和深度图out = {"render": rendered_image, # 最终渲染图像"viewspace_points": screenspace_points, # 屏幕空间点(带梯度)"visibility_filter": (radii > 0).nonzero(), # 可见高斯点的掩码(半径>0)"radii": radii, # 高斯点在屏幕上的半径"depth": depth_image # 渲染的深度图}return outout["viewspace_points"] 中的 screenspace_points 保持全零是正常现象,因其设计目的是传递梯度而非存储实际坐标。



visibility_filter
在 3D Gaussian Splatting 中,“可见高斯点的掩码”(即代码中 visibility_filter)是一个布尔张量或索引列表,用于标记在当前视角下实际参与渲染的高斯点。它的核心含义和作用如下:
1. 含义
visibility_filter 由光栅化过程生成,具体通过判断每个高斯点的屏幕空间半径(radii)是否大于 0 得到:
# 代码中生成可见性掩码的逻辑
visibility_filter = (radii > 0).nonzero()
radii > 0:表示该高斯点在当前视角下有实际的屏幕空间投影(即对最终渲染图像有贡献)。radii = 0:表示该高斯点被视锥体剔除(不在相机视野内)或投影后尺寸为 0(过小无法可见),未参与渲染。
2. 核心作用
(1)优化计算效率
- 稀疏更新:在训练过程中,只有可见的高斯点需要参与梯度计算和参数更新(如位置、缩放、旋转等)。不可见的高斯点对当前视角的渲染结果无影响,忽略它们可以减少冗余计算。
- 示例:在 train.py 中, densification(增密)和 pruning(剪枝)操作仅针对可见高斯点:
# 跟踪可见高斯点的最大半径,用于后续剪枝 gaussians.max_radii2D[visibility_filter] = torch.max(gaussians.max_radii2D[visibility_filter], radii[visibility_filter]) # 仅对可见高斯点统计增密所需的梯度信息 gaussians.add_densification_stats(viewspace_point_tensor, visibility_filter)
(2)控制高斯点的生命周期
- 剪枝(Pruning):持续不可见或半径过小的高斯点会被从场景中移除,避免冗余存储和计算。
- 增密(Densification):对可见但梯度较大的高斯点进行分裂,增加细节(仅对可见区域细化,避免无意义的增密)。
(3)梯度计算的准确性
- 反向传播时,只有可见高斯点的参数(如 3D 位置
means3D)需要计算梯度,不可见高斯点的梯度会被忽略,确保优化方向仅由当前视角的有效信息引导。

为什么能从三位高斯中渲染出任意视角?
三维高斯模型是对整个场景的三维表示(包含空间中所有点的位置、颜色、形状等信息)。由于高斯球体是连续的三维几何体,而非离散的像素,因此只要给定任意相机的视角参数(位置、朝向、内参等),就能通过投影和光栅化过程,生成该视角下的图像。这也是 3D Gaussian Splatting 能实现 “自由视角渲染” 的核心原因
渲染和光栅化的关系和区别
| 维度 | 渲染(Rendering) | 光栅化(Rasterization) |
|---|---|---|
| 定义 | 从三维场景生成二维图像的完整流程 | 渲染流程中,将三维几何转换为二维像素的核心步骤 |
| 范围 | 包含数据准备、光栅化、后处理等多个步骤 | 仅负责三维到二维的投影与像素融合 |
| 在代码中 | 对应 render 函数的全部逻辑 | 对应 GaussianRasterizer 类的调用及内部计算 |
| 输入输出 | 输入:相机、三维模型、配置;输出:最终图像 | 输入:三维高斯属性、相机参数;输出:像素颜色、深度等 |
回到train.py循环中来
if viewpoint_cam.alpha_mask is not None:alpha_mask = viewpoint_cam.alpha_mask.cuda()image *= alpha_mask应用 alpha 掩码:若相机有 alpha 掩码(如遮挡区域),则用掩码过滤渲染结果
gt_image = viewpoint_cam.original_image.cuda()Ll1 = l1_loss(image, gt_image)if FUSED_SSIM_AVAILABLE:ssim_value = fused_ssim(image.unsqueeze(0), gt_image.unsqueeze(0))else:ssim_value = ssim(image, gt_image)- 计算图像损失:
Ll1:渲染图像与真实图像的 L1 损失ssim_value:结构相似性指数(优先使用融合版实现fused_ssim,否则使用普通版)
loss = (1.0 - opt.lambda_dssim) * Ll1 + opt.lambda_dssim * (1.0 - ssim_value)总损失计算:L1 损失和 SSIM 损失的加权和(lambda_dssim 控制 SSIM 的权重)
Ll1depth_pure = 0.0if depth_l1_weight(iteration) > 0 and viewpoint_cam.depth_reliable:invDepth = render_pkg["depth"]mono_invdepth = viewpoint_cam.invdepthmap.cuda()depth_mask = viewpoint_cam.depth_mask.cuda()Ll1depth_pure = torch.abs((invDepth - mono_invdepth) * depth_mask).mean()Ll1depth = depth_l1_weight(iteration) * Ll1depth_pure loss += Ll1depthLl1depth = Ll1depth.item()else:Ll1depth = 0- 深度正则化损失(可选):
- 若当前迭代的深度权重 > 0 且相机深度可靠,计算渲染深度与真实深度的 L1 损失(
Ll1depth_pure),并加权后加入总损失 - 否则深度损失为 0
- 若当前迭代的深度权重 > 0 且相机深度可靠,计算渲染深度与真实深度的 L1 损失(
loss.backward()反向传播:计算损失对所有可训练参数的梯度
iter_end.record()记录迭代结束时间
with torch.no_grad():进入无梯度上下文:后续操作不计算梯度(提升效率)
ema_loss_for_log = 0.4 * loss.item() + 0.6 * ema_loss_for_logema_Ll1depth_for_log = 0.4 * Ll1depth + 0.6 * ema_Ll1depth_for_log更新损失的指数移动平均值(用于平滑进度条显示)
if iteration % 10 == 0:progress_bar.set_postfix({"Loss": f"{ema_loss_for_log:.{7}f}", "Depth Loss": f"{ema_Ll1depth_for_log:.{7}f}"})progress_bar.update(10)if iteration == opt.iterations:progress_bar.close()更新进度条:每 10 次迭代更新显示损失;迭代结束时关闭进度条
training_report(tb_writer, iteration, Ll1, loss, l1_loss, iter_start.elapsed_time(iter_end), testing_iterations, scene, render, (pipe, background, 1., SPARSE_ADAM_AVAILABLE, None, dataset.train_test_exp), dataset.train_test_exp)训练报告:记录日志(如损失、迭代时间),并在测试迭代点(testing_iterations)评估模型性能(计算测试集 L1 和 PSNR)
if (iteration in saving_iterations):print("\n[ITER {}] Saving Gaussians".format(iteration))scene.save(iteration)保存模型:当迭代次数在 saving_iterations 中时,保存当前高斯模型的状态(如点云、参数等)
if iteration < opt.densify_until_iter:gaussians.max_radii2D[visibility_filter] = torch.max(gaussians.max_radii2D[visibility_filter], radii[visibility_filter])gaussians.add_densification_stats(viewspace_point_tensor, visibility_filter)第一行代码作用:
gaussians.max_radii2D:高斯模型中存储的每个高斯点在图像空间中的最大半径(张量),用于判断高斯点是否需要被剪枝(半径过小的点可能贡献有限)。visibility_filter:布尔掩码(张量),标记当前视角下可见的高斯点(True表示可见,False表示不可见)。radii:当前渲染过程中计算出的每个高斯点在图像空间中的实际半径(张量)
第二行代码作用:
- 收集高斯点的增密统计信息,为后续新增高斯点(增密)提供依据。
- 关键变量解析:
viewspace_point_tensor:高斯点在当前视角相机空间中的坐标(张量),包含位置信息。visibility_filter:同上,标记可见的高斯点。
- 逻辑:调用高斯模型的
add_densification_stats方法,记录可见高斯点的空间分布和密度相关信息(例如,哪些区域的高斯点数量不足、分布稀疏)。这些统计信息会在后续的增密步骤(gaussians.densify_and_prune)中被使用,用于在稀疏区域生成新的高斯点,提升模型对细节的表达能力。
if iteration > opt.densify_from_iter and iteration % opt.densification_interval == 0:size_threshold = 20 if iteration > opt.opacity_reset_interval else Nonegaussians.densify_and_prune(opt.densify_grad_threshold, 0.005, scene.cameras_extent, size_threshold, radii)- 密度化与剪枝:
- 当迭代次数超过起始密度化次数且达到密度化间隔时,对高斯点进行操作:
- 对梯度较大的点进行分裂(密度化)
- 对半径过小或不透明的点进行删除(剪枝)
- 当迭代次数超过起始密度化次数且达到密度化间隔时,对高斯点进行操作:
if iteration % opt.opacity_reset_interval == 0 or (dataset.white_background and iteration == opt.densify_from_iter):gaussians.reset_opacity()- 重置不透明度:每
opacity_reset_interval次迭代,或白色背景下首次密度化时,重置高斯点的不透明度(避免过早收敛为 0)。
梯度下降
if iteration < opt.iterations:gaussians.exposure_optimizer.step()gaussians.exposure_optimizer.zero_grad(set_to_none = True)更新曝光参数优化器:执行曝光参数的梯度下降步骤,并清空梯度
if use_sparse_adam:visible = radii > 0gaussians.optimizer.step(visible, radii.shape[0])gaussians.optimizer.zero_grad(set_to_none = True)else:gaussians.optimizer.step()gaussians.optimizer.zero_grad(set_to_none = True)- 更新主优化器:
- 若使用稀疏 Adam,仅对可见的高斯点(
radii > 0)执行更新 - 否则对所有参数执行更新,随后清空梯度
- 若使用稀疏 Adam,仅对可见的高斯点(
if (iteration in checkpoint_iterations):print("\n[ITER {}] Saving Checkpoint".format(iteration))torch.save((gaussians.capture(), iteration), scene.model_path + "/chkpnt" + str(iteration) + ".pth")- 保存检查点:当迭代次数在
checkpoint_iterations中时,保存模型参数和当前迭代次数(用于断点续训)。
training_report
参数解释:
tb_writer:TensorBoard 的写入器,用于记录训练日志和可视化内容(若 TensorBoard 可用)。iteration:当前训练迭代次数。Ll1:当前迭代的 L1 损失张量(用于衡量渲染图像与真实图像的像素差异)。loss:当前迭代的总损失张量(通常是 L1 损失和 SSIM 损失的加权和)。l1_loss:计算 L1 损失的函数(用于后续评估)。elapsed:当前迭代的耗时(毫秒)。testing_iterations:需要进行测试评估的迭代次数列表。scene:场景对象,包含训练好的高斯模型和相机信息。renderFunc:渲染函数(如render函数),用于生成新视角的图像。renderArgs:传递给渲染函数的参数(如渲染管道配置、背景色等)。train_test_exp:布尔值,指示是否使用曝光补偿相关的训练 / 测试模式。
if tb_writer:tb_writer.add_scalar('train_loss_patches/l1_loss', Ll1.item(), iteration)tb_writer.add_scalar('train_loss_patches/total_loss', loss.item(), iteration)tb_writer.add_scalar('iter_time', elapsed, iteration)- 若 TensorBoard 可用(
tb_writer不为空),记录当前迭代的关键指标:- 训练集的 L1 损失(
Ll1.item())。 - 训练集的总损失(
loss.item())。 - 当前迭代的耗时(
elapsed)。
- 训练集的 L1 损失(
- 这些指标会在 TensorBoard 中以标量形式展示,便于跟踪训练趋势。
查看渲染指标
python render.py -m data\output生成真实图片和渲染图片
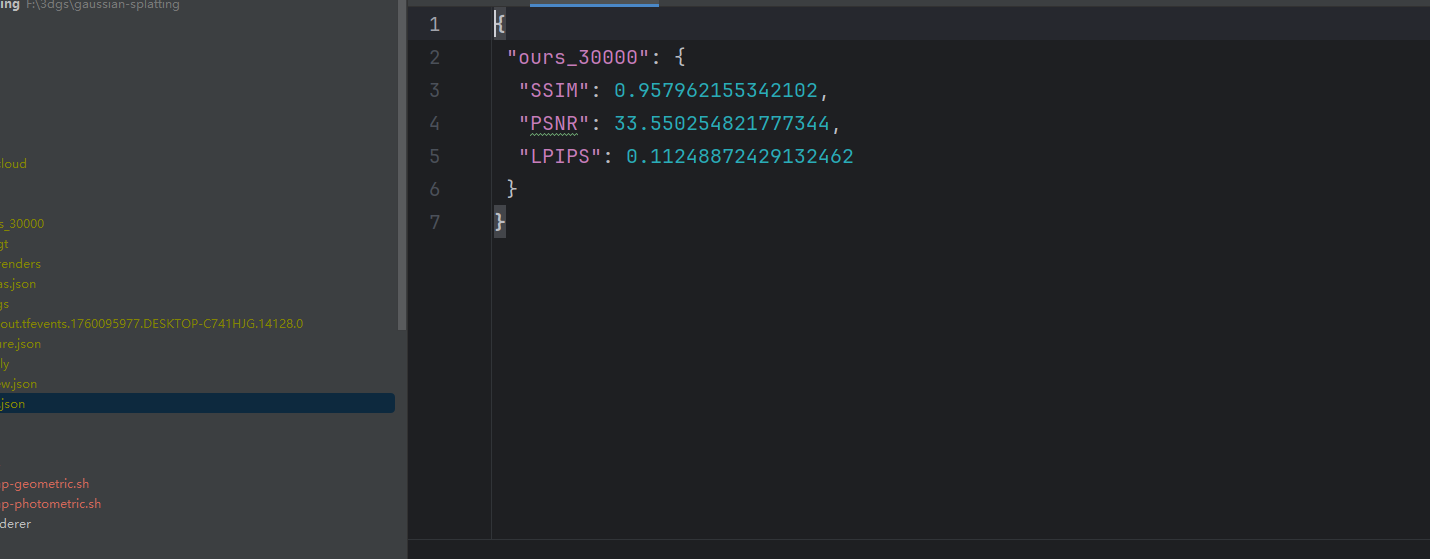
python metrics.py -m data\output
生成指标
自适应性密度控制
# Densificationif iteration < opt.densify_until_iter:# Keep track of max radii in image-space for pruninggaussians.max_radii2D[visibility_filter] = torch.max(gaussians.max_radii2D[visibility_filter], radii[visibility_filter])-
对于当前可见(由
visibility_filter选出的)那些高斯点,更新它们在图像空间的历史最大半径max_radii2D。 -
radii:当前视角下每个高斯的屏幕空间半径(通常是 2D 投影半径)。 -
torch.max(a, b):逐元素取较大值,保证max_radii2D保存训练过程中看到的最大投影尺寸。 -
目的:后续 prune(剪枝)时,如果某个高斯在所有视角下始终很小或不显眼,就有理由删掉它;反之如果曾经很大则保留依据更宽松。
gaussians.add_densification_stats(viewspace_point_tensor, visibility_filter)
-
调用函数累积用于判断 densify 的统计量(一般是位置梯度的累积、计数等)。
-
目的:统计哪些高斯对图像误差敏感(梯度大),这些点就是 densify 的候选。
此函数如下:
#将每个可见高斯点的位置梯度做L2范式
def add_densification_stats(self, viewspace_point_tensor, update_filter):self.xyz_gradient_accum[update_filter] += torch.norm(viewspace_point_tensor.grad[update_filter,:2], dim=-1, keepdim=True)self.denom[update_filter] += 1if iteration > opt.densify_from_iter and iteration % opt.densification_interval == 0:size_threshold = 20 if iteration > opt.opacity_reset_interval else Nonegaussians.densify_and_prune(opt.densify_grad_threshold, 0.005, scene.cameras_extent, size_threshold, radii)-
根据当前迭代决定是否给
densify_and_prune传入size_threshold参数:-
如果已经过了
opt.opacity_reset_interval,就设置size_threshold = 20(表示某种尺寸阈值,通常用来限制只 densify 尺寸小于该阈值的高斯或限制生成的新高斯大小)。 -
否则设置为
None(不应用这个尺寸阈值)。
-
-
目的是在训练更稳定或更晚期时,施加额外约束避免生成过大/不合适的高斯。
densify_and_prune
grads = self.xyz_gradient_accum / self.denomgrads[grads.isnan()] = 0.0
xyz_gradient_accum:累积的高斯点位置梯度(反映位置优化的 "活跃度")。denom:梯度累积的次数。- 两者相除得到平均梯度,用于判断哪些点需要增密(梯度大的点表示位置需要更精细调整)。
- 处理可能的
NaN值(避免计算错误)。

self.tmp_radii = radii缓存当前帧的高斯点在屏幕空间的半径(radii),用于后续增密逻辑
self.densify_and_clone(grads, max_grad, extent)self.densify_and_split(grads, max_grad, extent)两种增密策略,针对不同场景:
densify_and_clone:对梯度大但尺度较小的点进行克隆(复制自身),适用于需要增加点数量但保持分布的区域。densify_and_split:对梯度大且尺度较大的点进行分裂(生成多个子点),适用于需要更精细表示的区域(如边缘或细节丰富处)。- 触发条件:梯度大于
max_grad,且结合点的尺度(extent为场景范围)判断是否需要增密
densify_and_clone
# 筛选满足梯度条件的点:梯度范数 >= 梯度阈值,且尺度最大值 <= 场景范围的指定比例(percent_dense) selected_pts_mask = torch.where(torch.norm(grads, dim=-1) >= grad_threshold, True, False) selected_pts_mask = torch.logical_and(selected_pts_mask, torch.max(self.get_scaling, dim=1).values <= self.percent_dense*scene_extent)torch.norm(grads, dim=-1) >= grad_threshold:计算梯度向量的 L2 范数,筛选出梯度足够大(需要更精细建模)的点。torch.max(self.get_scaling, dim=1).values <= self.percent_dense*scene_extent:筛选出尺度较小的点(尺度用get_scaling获取,经过激活函数处理后的实际尺度),percent_dense是场景范围的百分比阈值(默认 1%)。- 两者通过
logical_and结合,仅保留 “梯度大且尺度小” 的点,这类点适合克隆(而非分裂)。
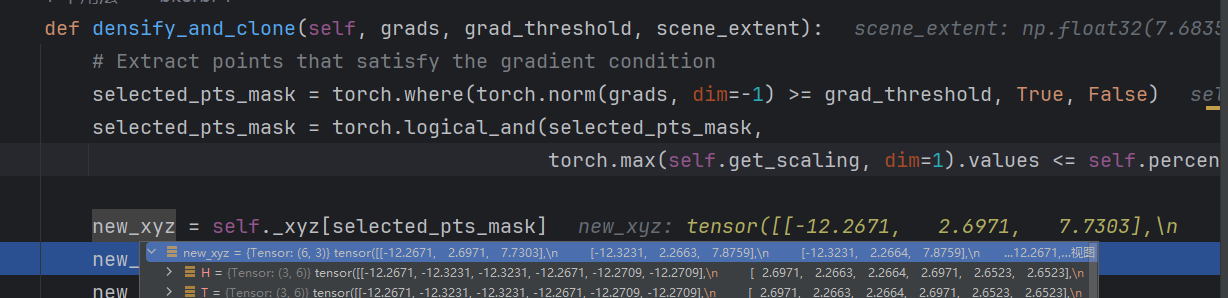
这次选出6个需要克隆的点
# 为选中的点创建克隆(复制属性)
new_xyz = self._xyz[selected_pts_mask]
new_features_dc = self._features_dc[selected_pts_mask]
new_features_rest = self._features_rest[selected_pts_mask]
new_opacities = self._opacity[selected_pts_mask]
new_scaling = self._scaling[selected_pts_mask]
new_rotation = self._rotation[selected_pts_mask]- 从原始高斯点中提取选中点的所有属性:位置(
_xyz)、SH 特征的 DC 分量(_features_dc)、SH 特征的其余分量(_features_rest)、不透明度(_opacity)、尺度(_scaling)、旋转(_rotation)。 - 这些属性将被直接复制,作为新克隆点的初始值。
# 克隆点的临时半径(来自当前帧渲染结果)
new_tmp_radii = self.tmp_radii[selected_pts_mask]- 复制选中点在当前帧的屏幕空间半径(
tmp_radii,由densify_and_prune传入,来自渲染结果),用于新点的半径初始化。
# 将克隆点添加到现有高斯点集中
self.densification_postfix(new_xyz, new_features_dc, new_features_rest, new_opacities, new_scaling, new_rotation, new_tmp_radii)- 调用
densification_postfix方法,将克隆点的属性与原始点集合并,更新优化器状态(如动量项),并重置梯度累积等临时变量。 - 最终实现点云的增密:选中的点被复制,增加该区域的高斯点数量,提升局部细节的建模能力。
densify_and_split
grads:高斯点位置的梯度(反映渲染误差敏感度)grad_threshold:梯度阈值(筛选需要分裂的点)scene_extent:场景范围(用于判断点的尺度是否过大)N:每个选中的点分裂出的新点数(默认值为 2)
n_init_points = self.get_xyz.shape[0]
padded_grad = torch.zeros((n_init_points), device="cuda")padded_grad[:grads.shape[0]] = grads.squeeze()获取当前高斯点的总数(get_xyz 返回所有点的位置,其形状第 0 维为点数量)
创建与点数量相同长度的零张量 padded_grad,用于补齐梯度张量(避免梯度数量与点数量不匹配的问题),并指定在 GPU 上运算。
将输入的梯度 grads 压缩维度(squeeze() 移除单维度)后,填充到 padded_grad 的前半部分,确保梯度张量长度与点数量一致
selected_pts_mask = torch.where(padded_grad >= grad_threshold, True, False)
selected_pts_mask = torch.logical_and(selected_pts_mask,torch.max(self.get_scaling, dim=1).values > self.percent_dense*scene_extent)生成掩码 selected_pts_mask,标记出梯度大于等于阈值的点(这些点对渲染误差敏感,需要细化)
进一步筛选掩码:仅保留 “梯度达标 且 尺度最大值超过场景范围指定比例” 的点。
self.get_scaling是经过激活函数处理后的实际尺度(3D 空间大小)torch.max(..., dim=1).values取每个点在 3 个维度上的最大尺度self.percent_dense*scene_extent是判断 “大尺度点” 的阈值(默认场景范围的 1%)这一步确保分裂操作仅作用于大尺度且高梯度的点(需要分解为更小的点来提升细节)
stds = self.get_scaling[selected_pts_mask].repeat(N,1)为选中的点生成新点的尺度标准差:
- 提取选中点的实际尺度(
self.get_scaling[selected_pts_mask]) - 每个点重复
N次(repeat(N,1)),得到N×选中点数个标准差张量(用于后续生成新点的位置偏移)
means = torch.zeros((stds.size(0), 3), device="cuda")创建均值为 0 的张量 means,形状与 stds 一致(用于高斯分布采样)
samples = torch.normal(mean=means, std=stds)从高斯分布中采样,生成新点相对于原始点的位置偏移量:
- 均值为 0(围绕原始点分布)
- 标准差为原始点的尺度(
stds),确保新点分布范围与原始点大小匹配。
rots = build_rotation(self._rotation[selected_pts_mask]).repeat(N,1,1)new_xyz = torch.bmm(rots, samples.unsqueeze(-1)).squeeze(-1) + self.get_xyz[selected_pts_mask].repeat(N, 1)new_scaling = self.scaling_inverse_activation(self.get_scaling[selected_pts_mask].repeat(N,1) / (0.8*N))new_rotation = self._rotation[selected_pts_mask].repeat(N,1)new_features_dc = self._features_dc[selected_pts_mask].repeat(N,1,1)new_features_rest = self._features_rest[selected_pts_mask].repeat(N,1,1)new_opacity = self._opacity[selected_pts_mask].repeat(N,1)new_tmp_radii = self.tmp_radii[selected_pts_mask].repeat(N) self.densification_postfix(new_xyz, new_features_dc, new_features_rest, new_opacity, new_scaling, new_rotation, new_tmp_radii)调用 densification_postfix 方法,将新分裂出的点与原始点集合并,更新模型参数和优化器状态
prune_filter = torch.cat((selected_pts_mask, torch.zeros(N * selected_pts_mask.sum(), device="cuda", dtype=bool)))创建修剪掩码:
- 前半部分为原始点的选中掩码(
selected_pts_mask),标记需要被移除的原始点 - 后半部分为新点的掩码(全为
False),表示新点不被修剪总长度为原始点数 + N×选中点数(合并后点集的总数量)
self.prune_points(prune_filter)调用 prune_points 方法,移除被选中的原始点(只保留新分裂出的点),完成 “分裂 - 替换” 过程
# 基础剪枝条件:透明度低于阈值的点(几乎不可见)
prune_mask = (self.get_opacity < min_opacity).squeeze()# 额外剪枝条件(若设置了max_screen_size):
if max_screen_size:# 屏幕空间半径过大的点(可能导致渲染模糊)big_points_vs = self.max_radii2D > max_screen_size# 世界空间尺度过大的点(超过场景范围的10%,可能冗余)big_points_ws = self.get_scaling.max(dim=1).values > 0.1 * extent# 合并所有剪枝条件(任意满足其一则剪枝)prune_mask = torch.logical_or(torch.logical_or(prune_mask, big_points_vs), big_points_ws)# 执行剪枝(移除prune_mask标记的点)
self.prune_points(prune_mask)- 剪枝目的:移除对渲染贡献极小或冗余的点,减少计算量。
- 核心逻辑:通过
prune_mask标记需要删除的点,最终调用prune_points方法移除这些点。
valid_points_mask = ~mask取反,得到要保留的点
optimizable_tensors = self._prune_optimizer(valid_points_mask)调用 _prune_optimizer 方法,根据 valid_points_mask 修剪优化器中存储的参数(如动量、二阶动量等),并返回修剪后的可优化张量(高斯点的位置、特征、尺度等)。
self._xyz = optimizable_tensors["xyz"]self._features_dc = optimizable_tensors["f_dc"]self._features_rest = optimizable_tensors["f_rest"]self._opacity = optimizable_tensors["opacity"]self._scaling = optimizable_tensors["scaling"]self._rotation = optimizable_tensors["rotation"]用修剪后的张量更新当前高斯模型的核心参数:
_xyz:3D 位置_features_dc:球谐函数特征的 DC 分量_features_rest:球谐函数特征的其余分量_opacity:不透明度(原始参数,未激活)_scaling:尺度(原始参数,未激活)_rotation:旋转(原始参数,未激活)
self.xyz_gradient_accum = self.xyz_gradient_accum[valid_points_mask]self.denom = self.denom[valid_points_mask]self.max_radii2D = self.max_radii2D[valid_points_mask]self.tmp_radii = self.tmp_radii[valid_points_mask]修剪梯度累积张量 xyz_gradient_accum(存储每个点的位置梯度累积值),只保留有效点的梯度信息。
修剪梯度累积的分母张量 denom(用于计算平均梯度),只保留有效点的分母信息。
修剪 max_radii2D(每个点在屏幕空间的最大半径),只保留有效点的半径信息。
修剪临时半径张量 tmp_radii(用于增密过程中的临时计算),只保留有效点的临时半径。
tmp_radii = self.tmp_radii
self.tmp_radii = None- 释放临时存储的半径信息,避免占用内存。
if iteration % opt.opacity_reset_interval == 0 or (dataset.white_background and iteration == opt.densify_from_iter):gaussians.reset_opacity()
-
决定是否要重置所有高斯的不透明度(opacity)。触发条件有两种情形:
-
iteration % opt.opacity_reset_interval == 0:每隔opacity_reset_interval步周期性重置(例如防止 opacity 长期饱和)。 -
(dataset.white_background and iteration == opt.densify_from_iter):如果数据集使用白背景,并且刚好到达densify_from_iter(densify 启动点),则在启动 densify 的那一步先 reset 一次(白背景情形下,初始 opacity 常常要特殊处理)。
-
-
目的是避免 opacity(alpha)陷入极端值 0/1 导致训练僵化。