C++内存管理模板深度剖析
目录
一、写在前面
二、C++内存管理
1、内存区域划分
2、new、delete
(1)内置类型
(2)自定义类型
(3)new/delete和malloc/free区别
(4)定位new表达式
三、模板
1、模板产生的必要性
2、模板的概念
3、函数模板
4、类模板
四、结语
一、写在前面
C/C++相比Java、python、go等其他编程语言更贴近底层,例如C中的指针就与内存地址紧密关联,贴近底层是C/C++的一大特点,因此在学习C/C++的过程中,应该学会将其与内存联系起来,这样能更好促进C/C++的学习,二者相辅相成,相得益彰。本文将围绕C++内存管理方式和模板展开介绍,C++内存管理与C的内存管理方式总体类似,但也有一些不同,C++在C的基础上引入了new、delete的内存管理方式,此外,C++还引入了模板的概念,模板用于解决在C中参数类型不同、但功能相同的函数、类在C中需要重复定义的问题,下文我们将逐一进行剖析。
二、C++内存管理
1、内存区域划分
C++内存区域划分与C的内存区域划分一致,具体可分为6个区域:内核空间、栈、内存映射段、堆、数据段(静态区)、代码段(常量区),内核空间区域用户代码不能读写,栈往内存向下的方向生长,内存映射段包括文件映射、动态库、匿名映射,堆往内存向上的方向生长,数据段的数据主要包括全局数据、静态数据,代码段的内容包括可执行代码、只读常量。
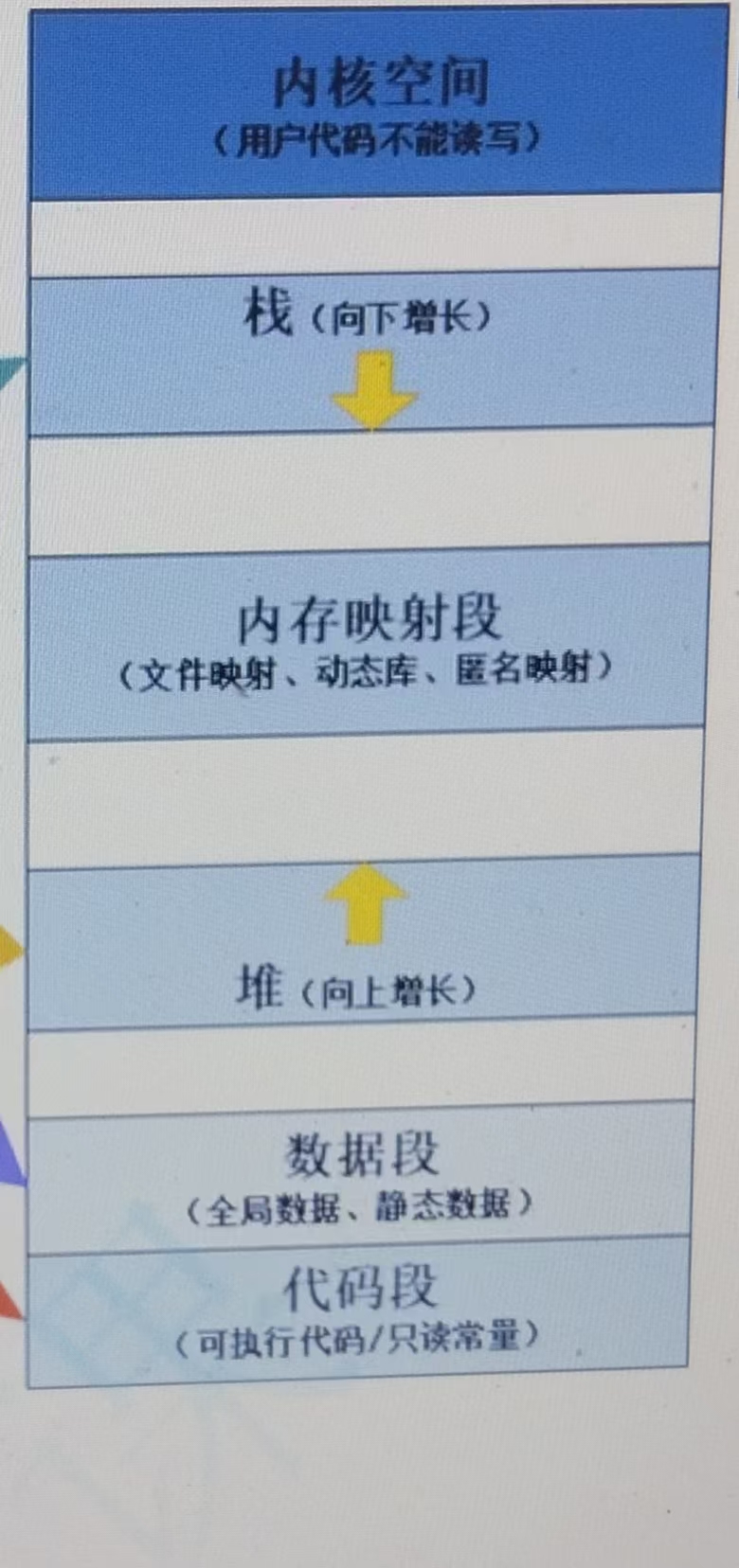
(1)
栈又叫堆栈,主要用于存储非静态局部变量、函数参数、返回值等,栈是向下增长的。
内存映射段是高效的I/O映射方式,用于装载一个共享的动态内存库,用户可使用系统接口创建共享共享内存,做进程间通信。
堆用于程序运行时动态内存分配,堆是可以向上增长的。
数据段用于存储全局数据和静态数据。
代码段用于存储可执行的代码和只读常量。
int globalVar = 1;
static int staticGlobalVar = 1;
void Test()
{static int staticVar = 1;int localVar = 1;int num1[10] = { 1, 2, 3, 4 };char char2[] = "abcd";const char* pChar3 = "abcd";int* ptr1 = (int*)malloc(sizeof(int) * 4);int* ptr2 = (int*)calloc(4, sizeof(int));int* ptr3 = (int*)realloc(ptr2, sizeof(int) * 4);free(ptr1);free(ptr3);
}
(2)
如(2)所示,globalVar为全局变量,故在静态区,staticGlobalVar、staticVar均为static修饰的静态变量,故也在静态区,localVar为局部变量,故在栈中,num1为数组名,即数组首元素的地址,即num1为局部指针变量,也在栈中,同理char2也在栈中,*char2即为数组首元素,为局部变量,故也在栈中,pChar3为局部指针变量,故也在栈中,*pChar3为常量字符串,为只读常量,故在常量区,ptr1为局部指针变量,故在栈中,*ptr1为malloc动态开辟的空间,故在堆上。
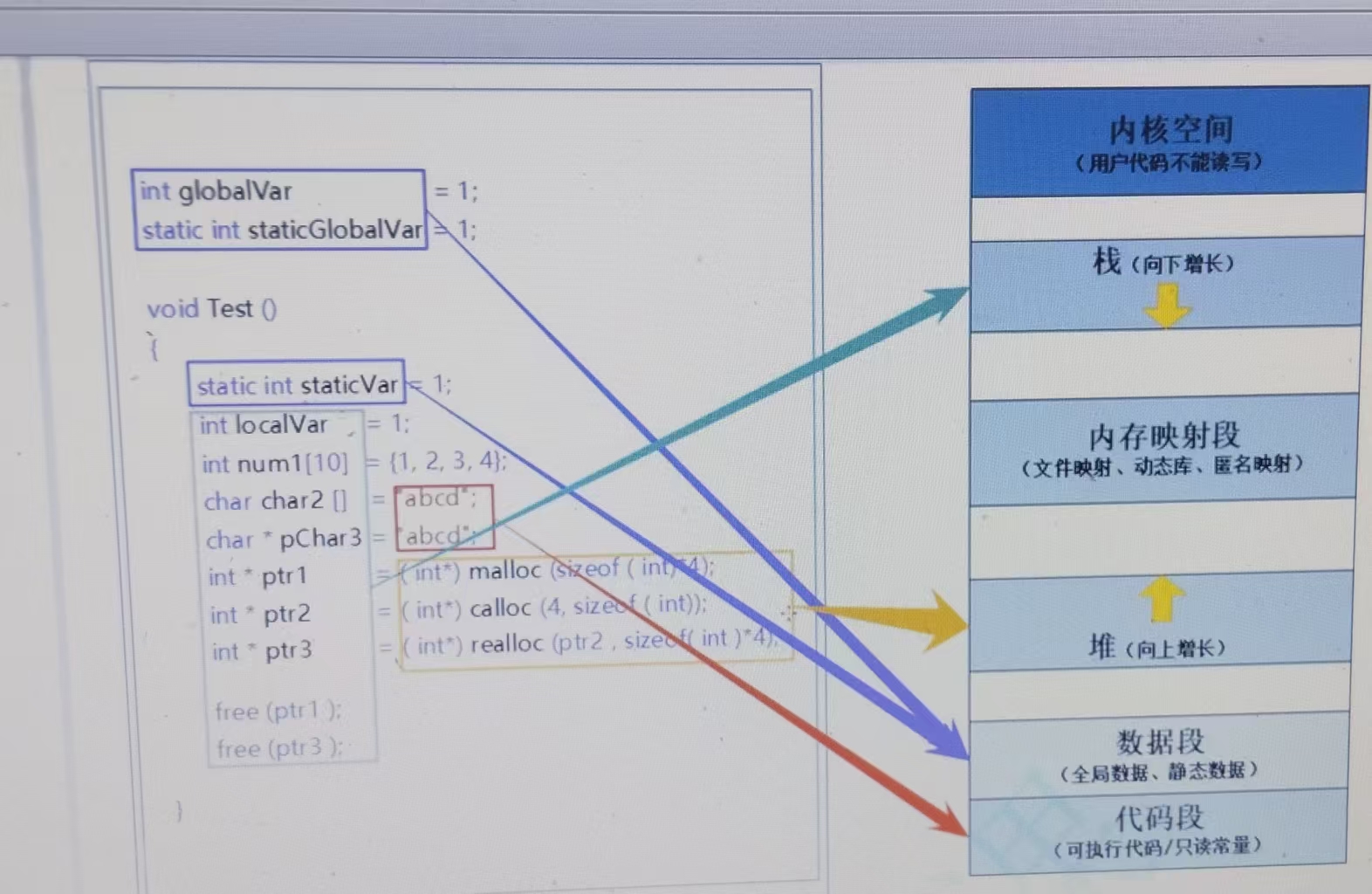
(3)
变量与其所在内存段的具体对应关系可参考(3)所示。
2、new、delete
(1)内置类型
C语言中动态内存管理方式是通过malloc、calloc、realloc、free来实现的,C语言内存管理方式在C++中可以继续使用,但有些地方就无能为力,而且使用起来比较麻烦,比如自定义类型的动态内存申请,因此C++又提出了自己的内存管理方式,通过new和delete操作符进行动态内存管理。
如果new申请的是内置类型的空间,new和malloc,delete和free基本类似,不同在于new/delete申请和释放的是单个元素的空间,new[]和delete[]申请和释放的是连续空间,且new在申请空间失败时会抛异常,malloc会返回NULL。

(4)
new操作符后面跟申请空间对象的类型,可对其进行初始化,如new int(3),delete操作符对指针进行操作,完成对空间的释放。此外,new、delete也可申请数组空间,如new int[3],int[3]为整形数组,3为数组元素个数,这时delete释放需要[]操作符,即delete[] ,完成多个元素的释放,如(4)中的delete[] ptr6,申请和释放单个元素的空间,使用new和delete操作符,申请和释放连续的空间,使用new[]和delete[]。
int* p1 = new int;int* p2 = new int[10];delete p1;delete[] p2;int* p3 = new int(0);int* p4 = new int[10] {0};int* p5 = new int[10] {1, 2, 3, 4, 5};delete p3;delete[] p4;delete[] p5;p1、p3申请的是单个元素的空间,p3进行了初始化,初始化为0,p2、p4、p5采用new[]申请连续空间,p4、p5对数组进行了初始化,p4将数组全初始化为0,p5将数组前5个元素初始化为1,2,3,4,5,剩余元素初始化为0。delete释放单个元素的空间,delete[]用于释放连续空间。
(2)自定义类型
对于自定义类型,new的实现原理为先调用operator new函数申请空间,operator new实际也是通过malloc来申请空间,之后在申请的空间上执行构造函数,完成对象的构造。delete的原理为先在空间上执行析构函数,完成对象中资源的清理工作,之后调用operator delete函数释放对象的空间,operator delete最终也是通过free来释放空间的。
struct Listnode
{int val;Listnode* next;Listnode(int x):val(x),next(nullptr){}
};
Listnode* p8 = new Listnode(1);Listnode* p9 = new Listnode(1);Listnode* p10 = new Listnode(1);Listnode* p11 = new Listnode(1);p8->next = p9;p9->next = p10;p10->next = p11;上图所示代码是通过new创建一个单链表,定义了链表结点结构体Listnode,构造函数采用初始化列表进行初始化,之后通过new构造并初始化链表结点p8、p9、p10、p11,再将p8、p9、p10、p11通过next指针连接起来,从而创建出单链表。
#include<iostream>
using namespace std;
class K
{
public:K(int a1=0,int a2=0):_a1(a1),_a2(a2){ cout << "K(int a1=0,int a2=0)" << endl;}K(const K& a):_a1(a._a1),_a2(a._a2){cout << "K(const K& a)" << endl;}~K(){cout << "~K()" << endl;}
private:int _a1;int _a2;
};
int main()
{K* p12 = new K;K* p13 = new K(1);K* p14 = new K(1, 2);K* p15 = new K[3];K aa1(1, 1);K aa2(2, 2);K aa3(3, 3);K aa4 = { 4,4 };K* p16 = new K[3]{ aa1,aa2,aa3 };K* p17 = new K[3]{ K(1,1),K(2,2),K(3,3) };//匿名对象K* p18 = new K[3]{ {1,1},{2,2},{3,3} };//隐式转化return 0;
}new K[n]的原理:先调用operator new[]函数,在operator new[]中调用operator new函数完成N个对象空间的申请,之后在申请的空间上执行N次构造函数。
delete[]的原理:在释放的对象空间上执行N次析构函数,完成N个对象中资源的清理,之后调用operator delete[]释放空间,operator delete[]中调用operator delete来释放空间。
此外,通过new对自定义类型变量或数组进行初始化时,支持隐式转化,如K aa4={4,4},就为隐式转化,中间会产生临时变量,再将临时变量拷贝构造到aa4中,对数组K[3]进行初始化时,有3种方式,第1种是直接将实例化的对象拷贝到数组K[3]中,如new K[3]{aa1,aa2,aa3},第2种是通过匿名对象来初始化数组K[3],如new K[3]{K(1,1),K(2,2),K(3,3)},,第3种是通过变量隐式转化来初始化,如new K[3]{{1,1},{2,2},{3,3}}。
malloc申请空间失败时,返回NULL,因此使用时必须判空,new不需要,但是new需要捕获异常。
#include<iostream>
using namespace std;
int main()
{try{void* p1 = new char[1024 * 1024 * 1024];cout << p1 << endl;void* p2 = new char[1024 * 1024 * 1024];cout << p2 << endl;void* p3 = new char[1024 * 1024 * 1024];cout << p3 << endl;}catch (const exception& e){cout << e.what() << endl;}return 0;
}
new通过try、catch来捕获异常,当new空间申请失败时,通过catch捕获,输出异常信息e.what()。
(3)new/delete和malloc/free区别
new/delete和malloc/free的共同点是:都是从堆上申请空间,并且需要手动释放。
不同点:1、malloc和free是函数,new和delete是操作符。
2、malloc申请的空间不会初始化,new可以初始化。
3、malloc申请空间时,需要手动计算空间大小并传递,new只需在其后跟上空间的类型即可,如果是多个对象,[]中指定对象个数即可。
4、malloc的返回类型为void*,在使用时必须强转,new不需要,因为new后面跟的是空间的类型。
5、申请自定义类型对象时,malloc/free只会开辟空间,不会调用构造函数和析构函数,而new在申请空间后会调用构造函数完成对象的初始化,delete在释放空间前会调用析构函数完成空间中资源的清理释放。
(4)定位new表达式
定位new表达式是在已分配的原始内存空间中调用构造函数初始化一个对象。
#include<iostream>
using namespace std;
class K
{
public:K(int k = 0):_k1(k){cout << "K()" << this << endl;}~K(){cout << "~K()" << this << endl;}
private:int _k1;
};
int main()
{K* p1 = new K(1);delete p1;K* p2 = (K*)operator new(sizeof(K));new(p2)K(1);p2->~K();operator delete(p2);return 0;
}定位new的使用方式:一般先是使用operator new创建空间,再通过定位new调用构造函数来初始化对象,使用格式为new(指针)类型,例如上面所示的new(p2)K(1),new先定位指针p2,再通过构造函数初始化对象K(1),完成初始化。delete p2也可拆解成两步,先调用析构函数,即p2->~K(),完成析构,再通过operator delete释放p2指向的空间。
定位new的使用场景:定位new在实际中一般是配合内存池使用,因为内存池分配出的内存没有初始化,所以如果是自定义类型的对象,需要使用定位new来进行显示调构造函数来完成初始化。
三、模板
1、模板产生的必要性
先来看下面Swap函数的实现
void Swap(int& left, int& right)
{int temp = left;left = right;right = temp;
}
void Swap(double& left, double& right)
{double temp = left;left = right;right = temp;
}
void Swap(char& left, char& right)
{char temp = left;left = right;right = temp;
}在C中,若想交换任意类型的两个数,例如int、double、char类型,我们需要手动实现3个类型的函数,这3个函数的功能都相同,都是交换两个数,只是函数参数类型不同,显然这样实现就显得有点麻烦、重复了,因此为了解决这个问题,C++中引入了模板这个工具,用于解决C中函数重复定义的问题。
2、模板的概念
在C++中,通过模板能填充多种数据类型,来生成具体类型的代码。
模板即编写与类型无关的通用代码,是代码复用的一种手段,模板是泛型编程的基础。
模板分为函数模板和类模板。
3、函数模板
函数模板代表了一个函数家族,该函数模板与类型无关,在使用时被参数化,根据实参类型产生函数的特定类型版本。
函数模板格式可参考如下
template<class K>
void Swap(K& x, K& y)
{K tmp = x;x = y;y = tmp;
}template为定义模板的关键字,定义格式为template<class K>,K代表具体类型,用于Swap函数参数的类型名,引用作为参数可以减少拷贝,Swap函数内部完成两个数的交换,这就是Swap的函数模板,该模板可以完成两个任意类型的数据交换。
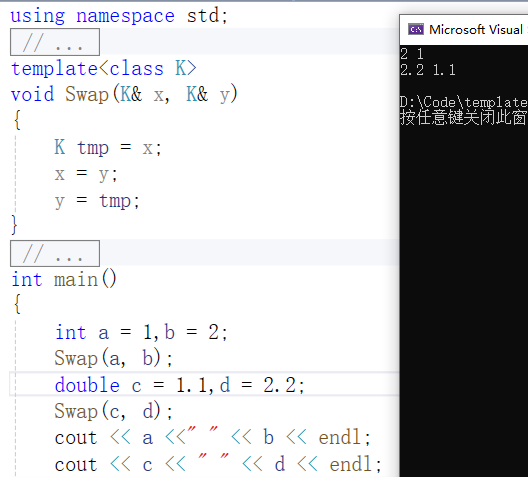
(5)
如(5)所示,调用Swap函数模板均可直接完成int、double类型数据的交换。
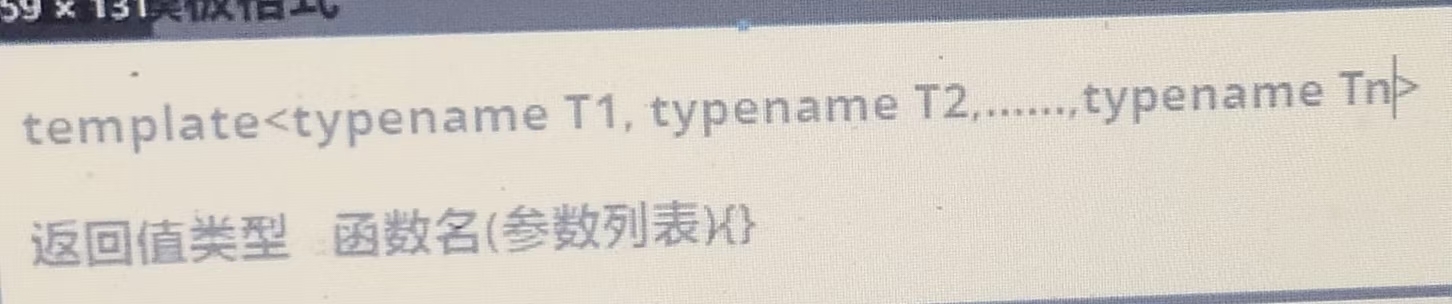
(6)
函数模板的定义格式可参考(6)所示,typename也可用class代替,二者都表示类型,但不能用struct代替class。
template<class K>
K add(const K& x, const K& y)
{return x + y;
}
template<class K1,class K2>
K1 add(const K1& x, const K2& y)
{return x + y;
}函数模板与函数相似,函数可以有多个函数参数,函数模板也可以有多个类形参。
函数模板是一个蓝图,它本身并不是函数,是编译器使用方式产生特定具体类型函数的模具。
模板其实就是将本来应该我们做的重复的事情交给了编译器。
在编译器编译阶段,对于模板函数的使用,编译器需要根据传入的实参类型来推演生成对应类型的函数以供调用。
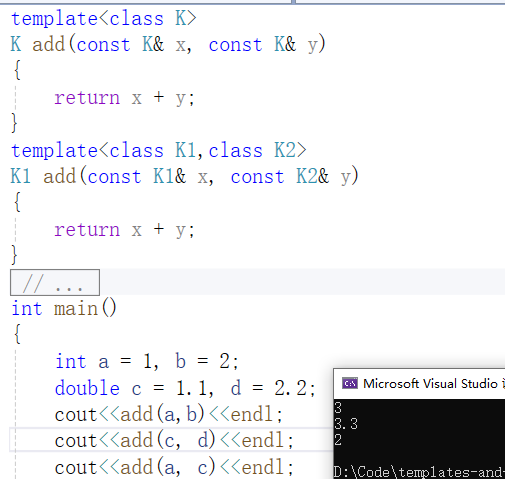
(7)
如(7)所示,编译器在编译阶段会根据传入的实参类型来调用相应的函数模板,比如当用double类型使用函数模板时,编译器通过对实参类型的推演,将K确定为double类型,然后产生一份专门处理double类型的代码。add(a,b)、add(c,d)都为相同类型的数据,故编译器会调用第1个函数模板,add(a,c)为不同类型的数据,故编译器会调用第2个函数模板,add(a,c)涉及了类型转化,结果会转成int类型,故结果为2,这个过程编译器根据传入的实参类型来调用相应的函数模板,然后推演生成具体的代码,称为函数模板推演的实例化。
此外,模板函数不允许自动类型转换,需要用户手动进行类型转换。
template<class K>
K add(const K& x, const K& y)
{return x + y;
}
int main()
{int a = 1, b = 2;double c = 1.1, d = 2.2;cout << add(a, (int)c) << endl;cout << add((double)a, c) << endl;cout << add<int>(a, c) << endl;cout << add<double>(a, c) << endl;return 0;
}如上面代码所示,我们需要手动进行类型转化,如add(a,(int)c),add((double)a,c),也可显式实例化模板,需要<>操作符,如add<int>(a,c)、add<double>(a,c),这时编译器就会自动进行类型转化,将变量转化成相应的数据类型。
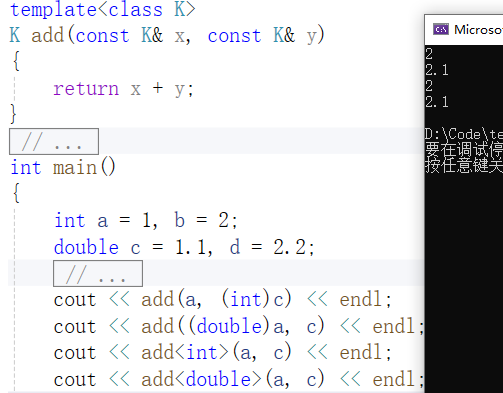
(8)
如(8)所示,add(a,(int)c)、add((double)a,c)、add<int>(a,c)、add<double>(a,c)的结果分别为2、2.1、2、2.1,。
用不同类型的参数使用函数模板时,称为函数模板的实例化,模板参数实例化分为:隐式实例化和显式实例化。
隐式实例化:让编译器根据实参推演模板参数的实际类型,上面涉及的函数模板大多是隐式实例化,编译器根据传入的实参类型来调用相应的函数模板,推演生成具体的函数代码。
显式实例化:用户手动实例化函数模板,如上面的add<int>(a,c),add<double>(a,c),都是显式实例化。
template<class K>
K* func(int n)
{return new K[n];
}
int main()
{double* p1 = func<double>(10);return 0;
}func函数模板只能进行显式实例化,因为模板的参数没有类类型,编译器无法根据传入的实参类型来判断,因此func函数模板只能进行显式实例化,如double*p1=func<double>(10)。
template<class K>
K add(const K& x, const K& y)
{return x + y;
}
int add(const int& x, const int& y)
{return (x + y)*10;
}
int main()
{int k1 = 1, k2 = 2;cout << add(k1, k2) << endl;return 0;
}当函数模板与具体函数同名时,这时编译器会优先选择调用函数,如上所示的函数模板add与函数add同名,这时编译器会选择调用函数add。
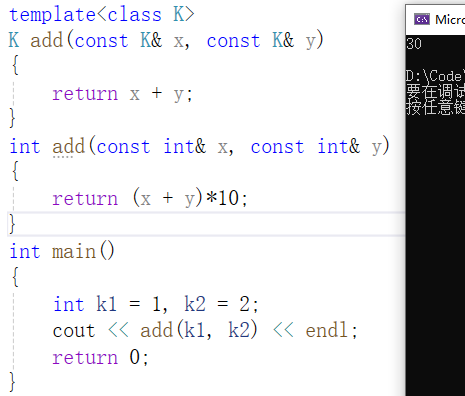
(9)
如(9)所示,编译器选择调用函数add,故结果为(1+2)*10=30。
4、类模板
模板除了函数模板,还有类模板,类模板的定义格式如下:
template<class K1,class K2,...class Kn>
class 类模板名
{//类内成员定义
};
例如我们可以实现一个栈的类模板:
template<class K>
class Stack
{
public:Stack(int n=4):_arr(new K[n]),_size(0),_capacity(n){}~Stack(){delete[] _arr;_arr = nullptr;_size = _capacity = 0;}void Push(const K& x);{if (_size == _capacity){K* tmp = new K[_capacity * 2];memcpy(tmp, _arr, _size * sizeof(K));delete[] _arr;_arr = tmp;_capacity *= 2;}_arr[_size++] = x;}void Pop(){--_size;}
private:K* _arr;size_t _capacity;size_t _size;
};该栈类模板的实现包含了对栈的初始化,栈的析构,入栈、出栈操作,该模板可以实现存放任意数据类型的栈。
类模板也支持成员函数的声明和定义分离,但一般要求需要在同一个源文件中。
template<class K>
class Stack
{
public:Stack(int n=4):_arr(new K[n]),_size(0),_capacity(n){}~Stack(){delete[] _arr;_arr = nullptr;_size = _capacity = 0;}void Push(const K& x);void Pop(){--_size;}
private:K* _arr;size_t _capacity;size_t _size;
};
template<class K>
void Stack<K>::Push(const K& x)
{if (_size == _capacity){K* tmp = new K[_capacity * 2];memcpy(tmp, _arr, _size * sizeof(K));delete[] _arr;_arr = tmp;_capacity *= 2;}_arr[_size++] = x;
}Stack类模板中成员函数Push声明与定义进行了分离,那么在类外定义时,也需template关键字,同时需要指明所在类域。即template<class K>,void Stack<K>::Push(const K& x)。
类模板都需要显式实例化
template<class K>
class Stack
{
public:Stack(int n=4):_arr(new K[n]),_size(0),_capacity(n){}~Stack(){delete[] _arr;_arr = nullptr;_size = _capacity = 0;}void Push(const K& x);void Pop(){--_size;}
private:K* _arr;size_t _capacity;size_t _size;
};
template<class K>
void Stack<K>::Push(const K& x)
{if (_size == _capacity){K* tmp = new K[_capacity * 2];memcpy(tmp, _arr, _size * sizeof(K));delete[] _arr;_arr = tmp;_capacity *= 2;}_arr[_size++] = x;
}
int main()
{Stack<int> st1;st1.Push(1);st1.Push(2);st1.Push(3);Stack<double> st2;st2.Push(1.1);st2.Push(2.2);st2.Push(3.3);Stack<double>* st3 = new Stack<double>;delete st3;return 0;
}如Stack<int> st1,为显式实例化一个数据类型为int的栈,st1.push执行入栈操作,Stack<double>为显式实例化一个数据类型为double的栈,st2.Push也同样执行入栈操作,也可以通过new来构造并初始化栈,如Stack<double>*st3=new Stack<double>,之后通过delete完成释放即可。
四、结语
本文主要围绕C++的内存管理方式以及模板展开介绍,C++的内存管理与C类似,可划分为6个区域:内核空间,栈,内存映射段,堆,数据段(静态区),代码段(常量区),栈用于存放非静态局部变量、函数参数、返回值等,动态开辟的空间在堆上,静态、全局变量在静态区,常量字符串、只读常量在常量区,此外,C++在C的基础上使用了new、delete的内存管理方式,对于自定义类型,new和delete会调用相应的构造函数和析构函数,相比malloc、free更加灵活。同时C++也引入了模板的概念,函数模板用于解决C中数据类型不同、但功能相同的函数需要重复定义的问题,此外模板还包括类模板,类模板也是将数据类型本身参数化,使得一套代码逻辑可以适用于多种不同的数据类型,实现代码复用。当然C++真正的威力在于将二者融合,深入理解内存管理和模板,正是开始用C++构建高效、强大软件系统的关键一步!