使用llamaindex实现RAG时 的常见使用框架或工具
前面我们使用了一些框架和工具来实现一个RAG系统,但是,我们首先需要了解这些工具的作用到底是什么。下面我会将一些常用的框架或者工具来详细说明,并附带类比语言,让你更加容易的看懂。
首先我们来了解RAG是什么?
1.RAG
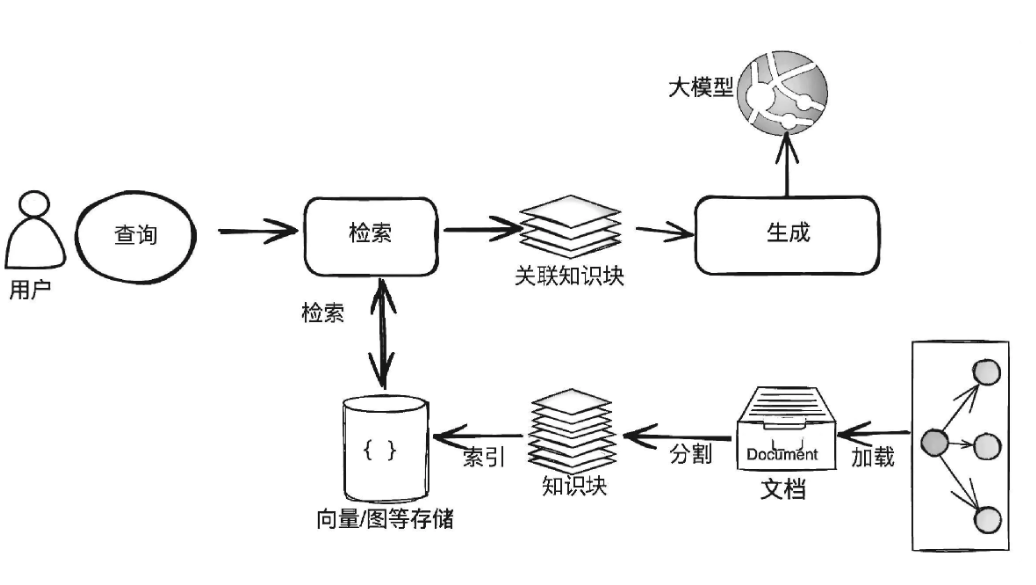
RAG (Retrieval-Augmented Generation):检索增强生成
- 核心作用:一种架构范式/模式,而非具体工具。它是整个应用的“大脑”和“方法论”。
- 详细解释:RAG 解决了大语言模型(LLM)的三大核心痛点:知识滞后、幻觉现象、无法溯源。它的核心思想不是让LLM凭空生成答案,而是先从一个外部知识库(如你的文档、数据库)中检索出最相关的信息,然后将这些信息作为上下文提供给LLM,让LLM在此基础上生成答案。
- 工作流程(两部分):
- 检索(Retrieval):
-
- 数据准备(离线):将你的私有文档(Word, PDF, PPT等)通过 LlamaIndex 等工具进行读取、分块、编码成向量,并存入向量数据库(如 Milvus)。元数据存入 PostgreSQL。
- 用户查询(在线):当用户提问时,将问题也编码成向量,并在向量数据库中进行相似性搜索,找到最相关的文本片段。
2.增强生成(Augmented Generation):
-
- 将检索到的相关文本片段(作为上下文)和用户的原始问题组合成一个精心设计的提示(Prompt)。
- 将这个Prompt发送给LLM(如 GPT-4),要求它基于提供的上下文来回答问题。
- 类比:RAG 就像一个顶尖的顾问。他不会只凭自己的记忆做决策,而是会先让助理团队(检索部分) 从庞大的公司档案库(你的知识库)中找出所有相关的历史资料和案例,然后他再基于这些资料(增强部分) 撰写一份完美的报告(生成部分)。
2.chainlit
网址:https://github.com/Chainlit/
Chainlit:应用开发框架
- 核心作用:快速构建类似 ChatGPT 的交互式用户界面(UI)的工具。它是应用的“脸面”和“交互层”。
- 详细解释:Chainlit 是一个专为 AI 应用设计的 Python 库,用于快速构建聊天机器人界面。它的目标是让开发者用最少的代码,创建出功能丰富、体验优秀的 Web 应用。
- 核心功能:
- 极简开发:用很少的 Python 代码就能创建一个功能完整的聊天界面,支持实时消息流式传输(streaming)。
- 可视化元素:不仅支持文本,还可以轻松地在聊天窗口中嵌入图片、文件、PDF、代码块、图表等元素,极大地丰富了交互体验。
- 调试与溯源(Crucial for RAG):这是 Chainlit 最强大的功能之一。在开发模式下,它提供了一个侧边栏,可以清晰地展示每一步的执行过程:
-
- 用户发送了什么消息?
- 检索到了哪些文本片段?(并高亮显示)
- 发送给 LLM 的最终 Prompt 长什么样?
- LLM 返回了什么原始响应?
- 整个调用链路花了多长时间?
会话管理、用户管理等。
- 类比:Chainlit 就是那个顾问的豪华办公室和前台接待。它提供了一个舒适的环境(漂亮的UI)让客户(用户)前来咨询。客户在这里提出问题、查看报告(答案),并且如果客户有疑问,还可以通过办公室的监控回放(溯源功能)查看顾问的整个决策过程。
3.llamaindex
LlamaIndex:数据连接框架
网址:https://developers.llamaindex.ai/python/framework/
- 核心作用:LLM 和你的外部数据之间的“桥梁”和“连接器”。专为 RAG 流程中的数据处理而设计。
- 详细解释:LlamaIndex(原名 GPT Index)是一个强大的 Python 框架。它的主要任务是高效地连接你的私有数据与大语言模型。它提供了各种工具来注入、结构化、和访问私有数据,以便在 RAG 应用中使用。
- 核心功能:
- 数据连接器(Data Loaders):提供了超过 100 种开箱即用的连接器,可以轻松地从各种来源读取数据,包括 PDF、PPT、MySQL、Slack、Notion,甚至 YouTube。你之前手动做的 OCR 和文件解析,LlamaIndex 可以通过集成这些工具(如 UnstructuredIO)来帮你自动化完成。
- 索引(Indexing):这是其核心。它能将加载的文档自动进行智能分块(Chunking),并为这些文本块创建向量嵌入(Embeddings),然后可以帮你存储到各种向量数据库(如 Milvus、Chroma、Pinecone)和传统数据库(如 PostgreSQL)中。它极大地简化了数据准备流程。
- 查询接口(Query Interface):提供了一个高级的API,你只需要输入问题,它内部会自动完成检索(从向量库找相关片段)、组装Prompt(将上下文和问题组合)、调用LLM、以及返回结果的整个RAG流程。
- 类比:LlamaIndex 就像是那个顾问的助理团队负责人。他负责管理所有资料(加载数据),将资料整理成易于查找的格式(建立索引),并在顾问需要时,快速地从档案库中找出最相关的资料(检索),并整理好递给顾问。
4.MinIO:
MinIO:分布式对象存储
官网:https://www.minio.org.cn/
核心作用:
MinIO是一个高性能的分布式对象存储系统。在RAG流程中,他主要用于存储原始的,未经处理的文档文件,这些文件可以是任何格式:
1.支持OCR的文件:图片(JPG,PNG)、扫描的PDF文档等。
2.可直接解析的文件:Word(.docx)、PPT,Excel,文本pdf,txt,Markdown等
在RAG流程中的工作:
1.用户将需要注入到知识库的各种文件上传到MinIO的一个存储桶(Bucket)中
2.存储阶段:MinIO为每个文件生成一个唯一的可访问链接(URL)
3.读取阶段:当需要处理文件时(例如进行OCR或文本解析),系统会从MinIO获取这个文件链接,从而下载并处理文件。
类比:就像一个公司的共享网盘或云存储(类似 AWS S3),所有原始资料都安全地存放在这里,随时可取用。
5.milvus
Milvus:向量数据库
官网;https://milvus.io/zh
- 这个问题同样被相同的嵌入模型转换为一个向量。
- 这个查询向量被发送给 Milvus。
- Milvus 在其庞大的向量库中,快速执行“相似性搜索”(Similarity Search),找到与问题向量最相似的几个向量(即语义上最相关的文本片段)。
- Milvus 返回这些相似向量对应的唯一ID。
- 这个查询向量被发送给 Milvus。
6.postgresql
PostgreSQL:关系型数据库
核心作用:存储所有结构化元数据和关联信息----元数据是关于数据的数据
详细解释:PostgreSQL是一个强大的开源关系型数据库。在RAG系统中,他通常不直接存储被检索的文本内容本身,而是存储这些内容的目录和索引卡
在RAG流程中的工作:
1.关联向量数据库:为milvus中的每一个向量数据条目存储唯一一个id,当milvus执行向量搜索返回最相似的向量id列表后,应用系统会拿着这些id到postgresql中查找对应的原始文本片段和文件来源信息
2.查询流程:向量用户先将查询文本使用嵌入模型转为向量,在milvus中查询与查询向量相似的向量的id后返回这些向量的id(是文档的唯一标识符),然后通过这些相似的向量id到postgresql中查找与这些id对应的元数据和索引信息,因为postgresql中存储了每个文本的元数据和索引信息,通过元数据里面的路径和其他信息可以快速定位到原始文本的相关片段
7.OCR
OCR:光学学符标识
核心作用:将图像中的文字识别并提取成为机器可读的语言文本
详细解释:
OCR不是软件,而是一种技术,在技术栈中通常是一个服务或库,例如使用一些服务商(Tesseract、PaddleOCR 或云服务商(如阿里云、Azure))提供的OCR API
在RAG流程中的作用:
- 触发:当发现minio中存入的文件是图片或者扫描版pdf后,就会调用OCR服务
- 处理:OCR引擎读取图片,分析其中的像素布局,识别出文字内容
- 输出:将识别出的文本输出为纯文本或结构化的JSON数据
- 下游:输出的文本会被送入到后续的“切分”和“嵌入”流程,最终存入向量数据库
- 重要性:没有OCR,图片和扫描文档中的知识无法被RAG系统利用,会造成信息盲区。