YOLOv3:高效精准的实时目标检测算法
随着人工智能技术的飞速发展,目标检测作为计算机视觉领域的核心任务之一,在自动驾驶、安防监控、智能机器人等众多场景中发挥着至关重要的作用。在众多目标检测算法中,YOLO(You Only Look Once)系列因其卓越的速度与精度平衡而备受关注。其中,YOLOv3 作为该系列的重要升级版本,进一步提升了模型性能,成为工业界和学术界广泛应用的经典模型。
一、YOLOv3的核心思想
YOLOv3延续了YOLO系列“将目标检测问题转化为回归问题”的核心理念。与传统的两阶段检测器(如Faster R-CNN)不同,YOLOv3属于单阶段(one-stage)检测器,它通过一个端到端的卷积神经网络,直接从输入图像中预测出目标的类别和位置信息。这种设计避免了复杂的候选框生成和筛选过程,极大地提升了检测速度,使其能够满足实时性要求较高的应用场景。
二、YOLOv3的网络架构
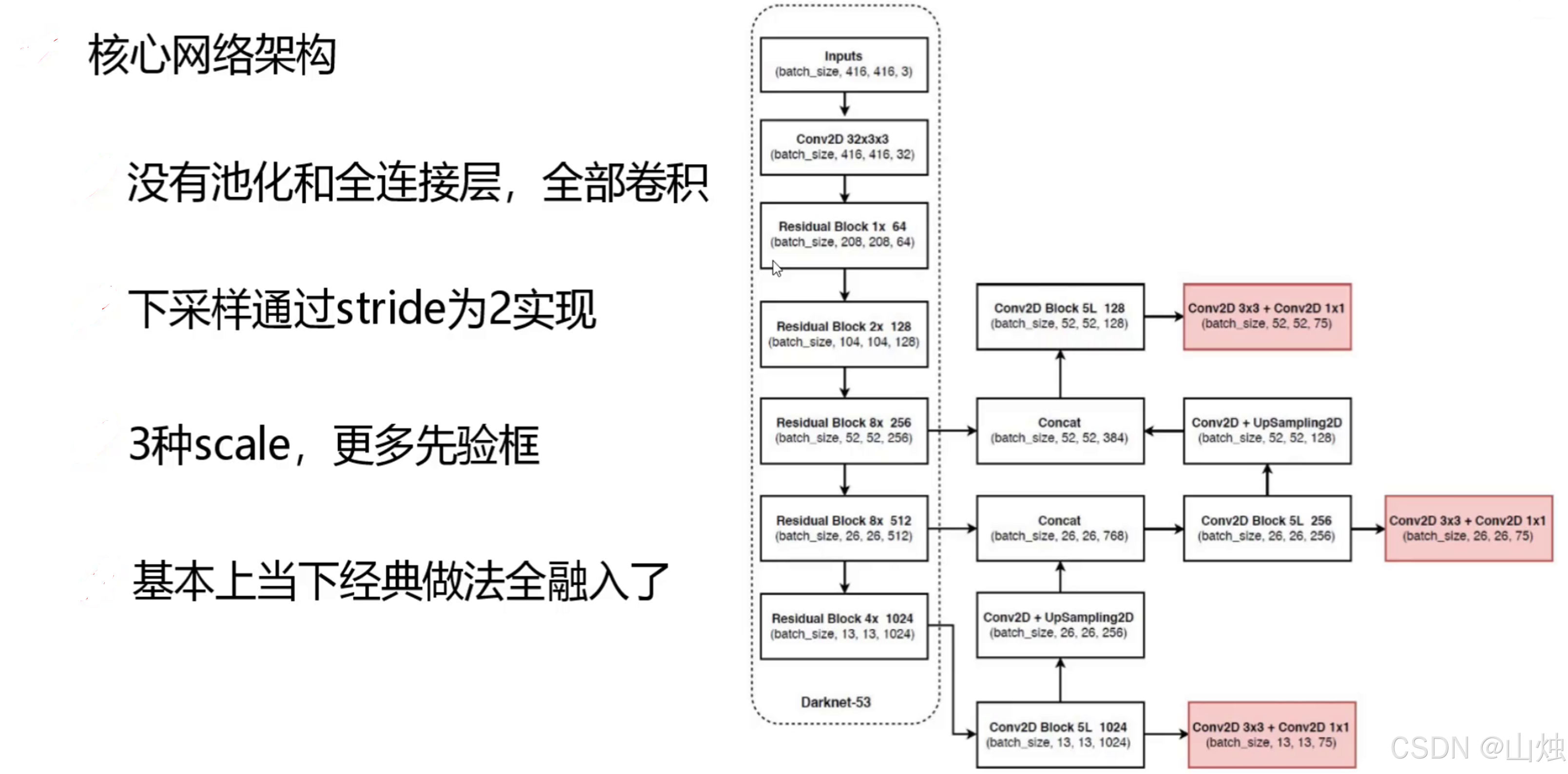
YOLOv3的骨干网络(Backbone)采用了Darknet-53,该网络融合了残差网络(Residual Network)的思想,包含多个Conv Block(普通卷积模块)和Residual Block(残差模块)。这种结构有效缓解了深层网络中的梯度消失问题,使得模型能够学习到更深层次的特征,同时保持较高的训练效率。
YOLOv3最显著的改进之一是引入了**多尺度预测(Multi-Scale Prediction)**机制。模型在三个不同尺度的特征图上进行预测:
- 13×13:用于检测大尺寸目标
- 26×26:用于检测中等尺寸目标
- 52×52:用于检测小尺寸目标
通过这种“特征金字塔”结构,YOLOv3能够有效应对不同尺度的目标,显著提升了对小目标的检测能力。
三、先验框(Anchor Boxes)的设计
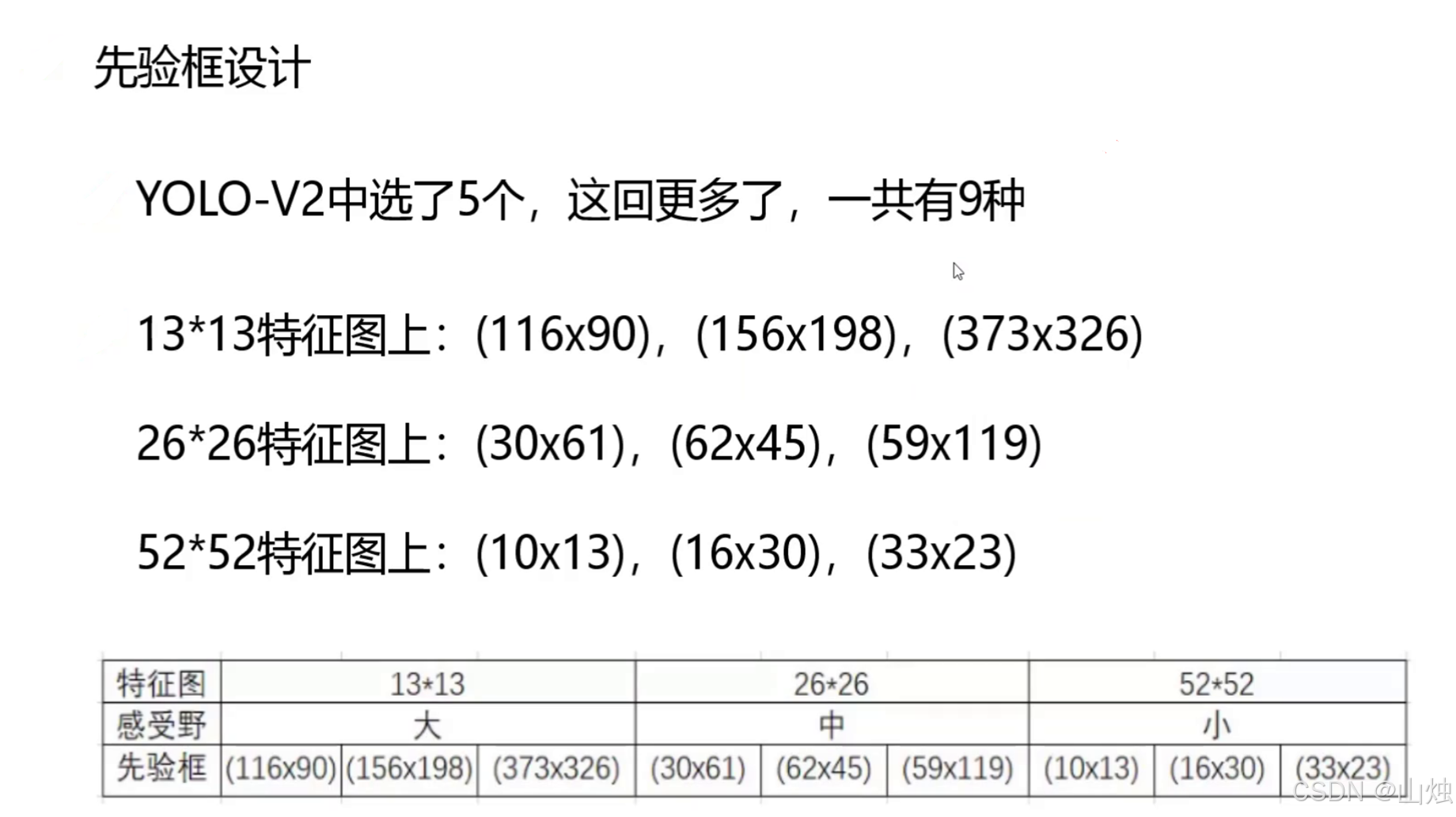
为了提高定位精度,YOLOv3沿用了K-means聚类的方法,从训练集的标注框中学习出最优的先验框尺寸。在COCO数据集上,YOLOv3共聚类出9种先验框,并将其平均分配到三个尺度的特征图上,每个尺度对应3个先验框:
- 大尺度(13×13):(116×90), (156×198), (373×326) —— 检测大物体
- 中尺度(26×26):(30×61), (62×45), (59×119) —— 检测中等物体
- 小尺度(52×52):(10×13), (16×30), (33×23) —— 检测小物体
这种设计使得每个尺度的特征图都能专注于特定尺寸范围的目标,提高了检测的针对性和准确性。
四、分类机制的革新:从Softmax到Logistic
YOLOv3在分类策略上做出了重要改进:使用多个独立的Logistic分类器替代了传统的Softmax分类层。
传统的Softmax函数假设每个目标只属于一个类别,这在多标签场景下存在局限性。而YOLOv3采用Sigmoid函数为每个类别独立计算概率,使得一个目标可以同时被识别为多个类别(例如,“人”和“行人”)。这种机制增强了模型的表达能力,使其更适应复杂的现实场景。
设有一个图像分类任务,需要识别图像中是否包含“猫”、“狗”和“动物”三种。使用Logistic分类器时,模型会为每个类别(猫、狗、动物)分别计算一个概率值。例如:
- 图像A:猫的概率=0.8,狗的概率=0.3,动物的概率=0.1
- 图像B:猫的概率=0.2,狗的概率=0.7,动物的概率=0.6
设定阈值为0.5,则:
- 图像A会被标记为“猫”(因为猫的概率>0.5),而不会被标记为“狗”或“动物”(因为它们的概率<0.5)。
- 图像B会被标记为“狗”和“动物”(因为它们的概率都>0.5),而不会被标记为“猫”(因为猫的概率<0.5)。
五、YOLOv3的实战流程
基于YOLOv3的目标检测项目通常遵循以下步骤:
1.数据标注:使用如labelme等工具对图像进行标注,生成包含目标位置和类别的JSON格式标签文件。
2.标签格式转换:将标注工具生成的JSON文件转换为YOLOv3所需的文本格式(txt),其中包含类别索引和归一化的边界框坐标。
3.模型配置:
- 创建自定义的模型配置文件(如
yolov3-custom.cfg)。 - 修改
classes.names文件,定义任务中的类别名称。 - 配置
custom.data文件,指定训练集、验证集路径及类别数量。
4.模型训练:使用train.py脚本,加载预训练权重(如darknet53.conv.74),并设置模型定义和数据配置参数,开始训练。
5.模型测试:使用detect.py脚本,加载训练好的模型权重,对新图像进行推理,输出检测结果。
六、YOLOv3的优势与局限
优势:
- 速度快:单阶段检测,实时性好,适合视频流处理。
- 精度高:多尺度预测和改进的分类机制显著提升了检测性能。
- 工程友好:代码结构清晰,易于部署和二次开发。
局限:
- 对于极度密集或严重遮挡的小目标,检测效果仍有提升空间。
- 相比后续版本(如YOLOv4、v5),在极端复杂场景下的鲁棒性稍弱。
结语
YOLOv3凭借其简洁高效的架构、出色的检测性能和良好的工程实用性,成为目标检测领域的一个里程碑式模型。它不仅推动了实时目标检测技术的发展,也为后续YOLO系列的演进奠定了坚实的基础。对于希望快速构建目标检测应用的开发者而言,YOLOv3依然是一个极具价值的选择。