pyspark并行性能提升经验
pyspark并行性能提升经验
- 前言
- 一、数据问题
-
- 1、分区均衡
- 2、数据读取优化
- 二、函数差异
- 三、资源配置
前言
在pyspark实践过程中遇到了形形色色的性能瓶颈问题,有的是数据问题,有的是资源配置问题,有的是函数使用差异,有的是参数配置.下面就一一对这些问题进行阐述与经验总结,以便为后续的应用提供宝贵意见参考.
一、数据问题
数据问题应该是最常见的问题了,但总是没有办法一网打净,因为每次遇到的数据可能都不一样,因此具体情况具体分析,下面呈现的是目前遇到过的几种数据导致运行性能问题的情况.
1、分区均衡
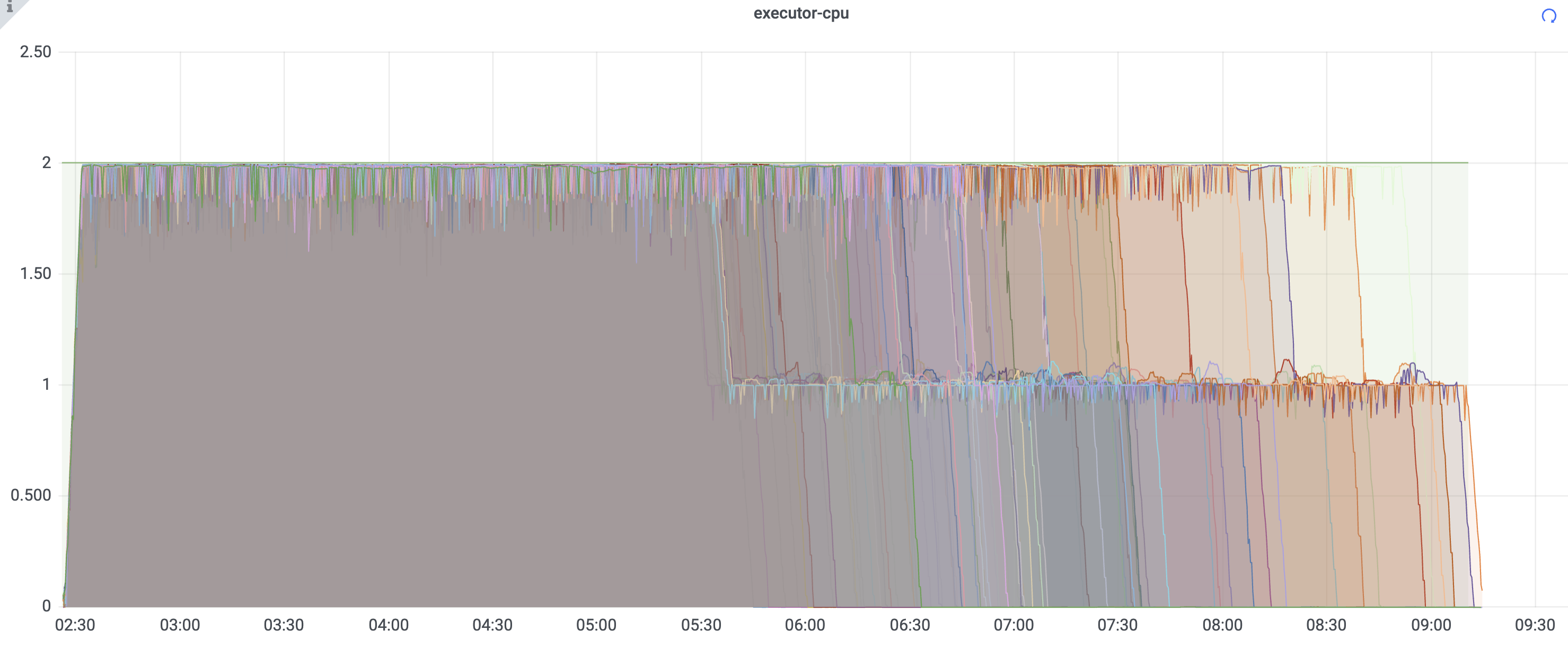
下方表是核心耗时task运行在不同executor的情况分布,图是整个任务运行在excutor上的分布,首先从图上可以看到各executor的结束时间差异很大,最早的在5点多结束,最晚的在9点多结束,最慢与最快差了4个小时,同时查看其日志,核心耗时的task在各excutor上的运行情况,可以看到表最后一行读取的数据大小,差出来两倍.

定位到原因后,梳理代码,定位其优化位置,下面是核心耗时task执行代码,可以看到sql读取数据后写入临时表,然后按’zone_code’分区进行模型预测.这里首先要确定原始分区数,其分区字段,以及zone_code目标数有多少,方便重新进行分区.
data = spark.sql(df_sq