高频使用RocksDB DeleteRange引起的问题及优化
背景
我们的分布式文件存储系统(polefs)中,元数据子系统部分功能使用到RocksDB。在元数据数据结构设计中,我们基于inode作为主键构建了表模型。一行数据位:
inode为主键,cf1:列1,列2... cf2,:列1,列2,...
但是我们的一行数据是schema-less的。有的列名不是可预测的,他使用用户启用的某些功能或者信息记录。例如:客户端打开文件信息:
inode->clientId(系统分配的值)记录哪个个client打开了这个inode,因此部分列,不是可预测的
这样删除一个文件时,我们只知道一个prefix,并不清楚列名,先scan拿到所有列,然后delete他们是一个方法。
但为了高效支持大量删除文件的场景下,我们为了加速,大量使用了rocksdb的Delete Range功能,是对一个inode内部进行的列删除。因此属于高频操作
RocksDB Delete Range介绍
kv存储实践中,范围删除是一个常见需求。比如我们需要删除所有以特定prefix开头的记录。在RocksDB引入DeleteRange功能之前,实现这样的操作异常繁琐,例如大意:
// DeleteRange之前的实现:低效的Scan+Delete
void delete_by_prefix_old(std::string prefix) {rocksdb::Iterator* it = db->NewIterator(read_options);for (it->Seek(prefix); it->Valid() && it->key().starts_with(prefix); it->Next()) {db->Delete(write_options, it->key()); // 逐个删除}delete it;// 时间复杂度:O(N),性能随数据量线性下降
}而有了DeleteRange之后,同样的操作变得极其高效:
// 使用DeleteRange的实现
void delete_by_prefix_new(std::string prefix) {std::string end = prefix + "\xff"; // 计算范围结束键db->DeleteRange(write_options, db->DefaultColumnFamily(), prefix, end);// 时间复杂度:O(1),无论数据量多大都快速完成
}性能提升对比:
传统方式:10万条数据需要10万次删除操作
DeleteRange:只需1次范围删除操作
但是,正如当前工程师们得到的经验:没有银弹。DeleteRange这个在解决上述问题的同时,也伴随着这风险,如果使用不当,会带来严重的负面作用,下面分享下我们的实践。
直接说结论:DeleteRange不可以大量频繁使用,否则会产生两个问题:
Get延迟异常升高。在我们的环境中,他是不断升高,延迟呈现一条直线在上升
内存不断升高
误用delete range导致的两个问题
问题1:Get延迟异常升高
现象:
在大量持续delete range环境中(即使查询的key明确存在于MemTable或BlockCache中),我们的环境下,get的延迟不断增加
原因容易理解,delete range是范围标记。一个key是否失效了,基本上要遍历一遍所有这样的数据。数据越多,get越多越耗时
Get的执行路径,下面代码只描述大意(注意不是严格的):
每个数据本身version(sequence number),基于这个值,有happen before关系。只有新的delete range值,可以作用于老的base值,
下面的伪代码,没有体现这一点。
// RocksDB内部查询路径的复杂性增加
Status Get(const Slice& key) {// 首先检查MemTable中的范围墓碑for (auto* memtable : memtable_list_) {// MemTable也可能包含范围墓碑if (memtable->range_tombstones_.Covers(key)) { // 迭代遍历进行判断 O(n) 算法return Status::NotFound(); // 在MemTable层就被墓碑标记删除} // 检查MemTable中的常规数据Status s = memtable->Get(key, value, &found);if (found) {return s;}}// 然后检查Immutable MemTables(省略...)// 最后检查SST文件层级中的范围墓碑for (auto& level : levels_) {for (auto& file : level.files) {// 每个SST文件都有自己的范围墓碑列表// 额外的范围检查,即使key存在也要执行!if (file->range_tombstones.Covers(key)) {return Status::NotFound(); // 被SST文件中的墓碑标记删除}// ... 正常的SST文件查询逻辑if (found) {return s;}}}
}每个Get操作都需要遍历所有可能覆盖查询键的范围墓碑,即使数据就在内存中!
问题2:内存不可控增长
进程中的内存使用时间持续上升,配置的BlockCache和WriteBufferManager无法限制住内存
测试发现31%的内存被 处理DeleteRange记录的Iterator持有。
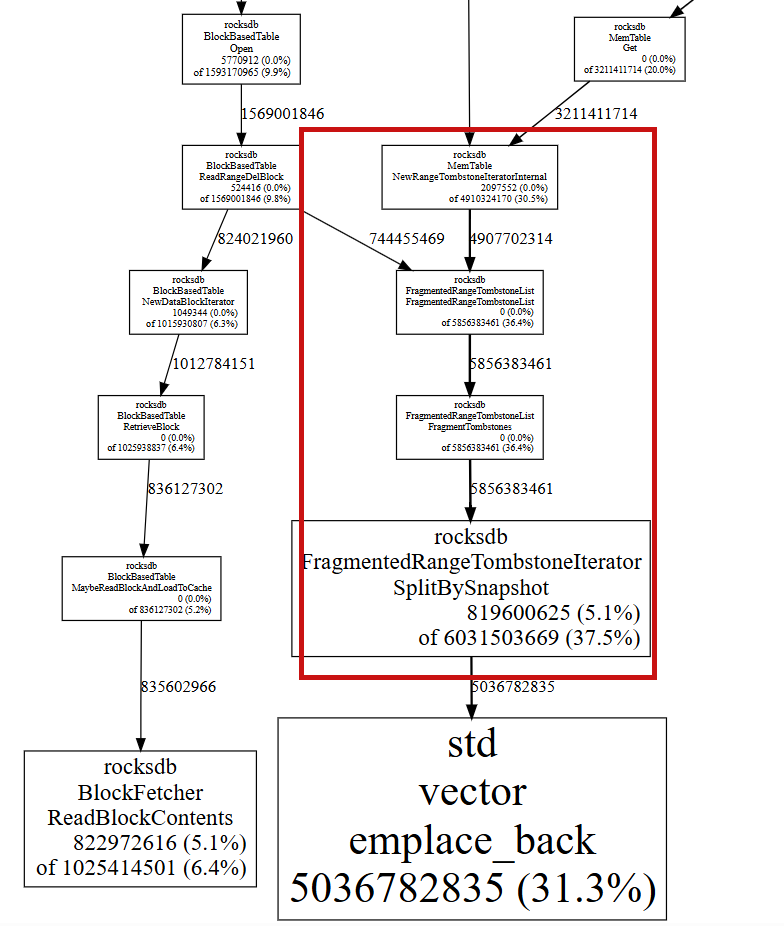
内存增长机制:
class RangeTombstoneSet {std::vector<RangeTombstone> tombstones_;// 每个DeleteRange操作都会添加新的范围墓碑// 这些墓碑在Compaction前会一直占用内存
};// 内存中的层级结构
class VersionStorageInfo {std::vector<FileMetaData*> level_files_;// 每个SST文件都包含RangeTombstoneList// 大量DeleteRange导致这些列表不断膨胀
};问题复现的一个例子:例如
// 不好的用法:频繁的DeleteRange
class MetadataManager {void cleanup_expired_metadata() {while (true) {auto expired_ranges = find_expired_ranges();for (auto& range : expired_ranges) {// 重点是这里:频繁的小范围DeleteRangedb_->DeleteRange(options_, cf_, range.start, range.end);}std::this_thread::sleep_for(60s);}}
};这种大量执行delete range 使用模式会导致:
范围墓碑碎片化:大量小范围墓碑分散在各个SST文件
查询路径复杂化:每个查询都要检查众多范围墓碑
内存累积效应:墓碑数据在Compaction前无法释放,如上图。 理论上,执行compaction会释放,但是我们的例子里,没有释放,这是我们的一个待研究的点,是rocksdb本身有bug还是我们在使用rocksdb的方式上(如配置选项)上还有问题? TODO
优化
找到了问题,我们的解决方法很简单,消灭所有的delete range操作
我们梳理和分析自身的系统,把所有delete本身精细的分散到具体的操作上,最终把delete range操作全部换成了delete,同时不影响性能
总结
DeleteRange是一个强大的工具,但必须谨慎使用,它不适合高频操作
最上,不使用delete range是最好的
其次,低频使用
最下,无法避免,需要控制使用,同时需要定期Compaction:帮助清理范围墓碑碎片