自然语言处理笔记
自然语言处理笔记
- 自然语言处理主要环节
- 分词
自然语言处理主要环节

分词

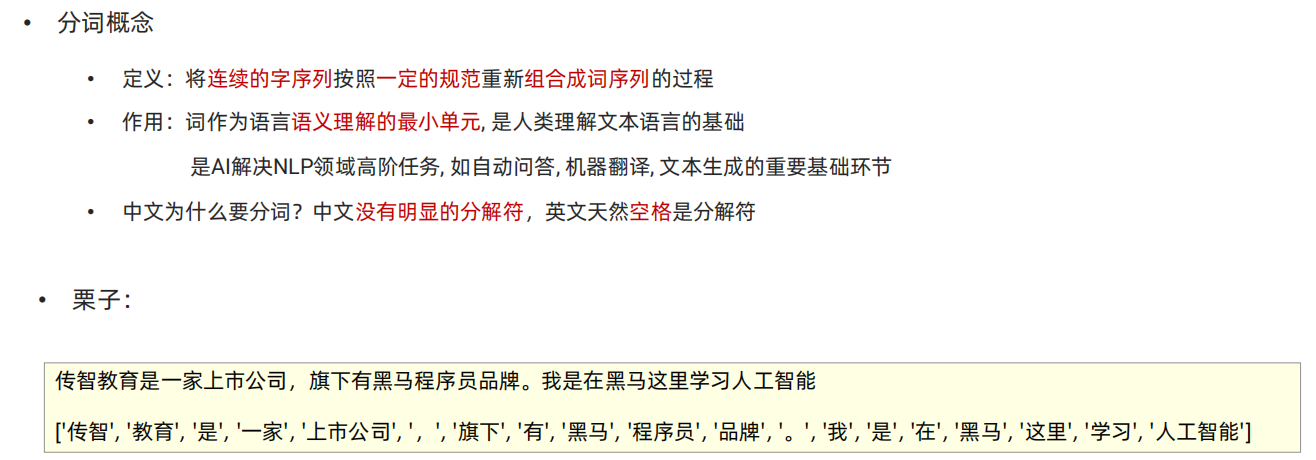
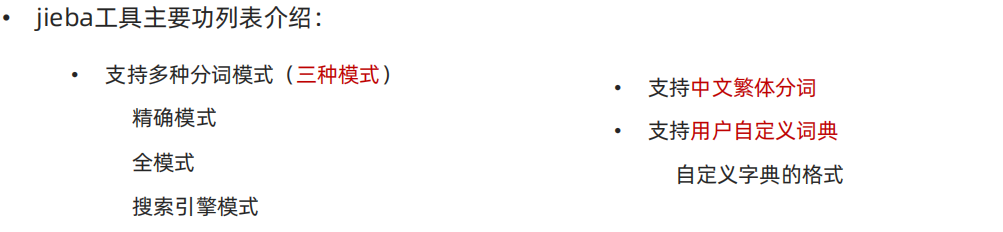
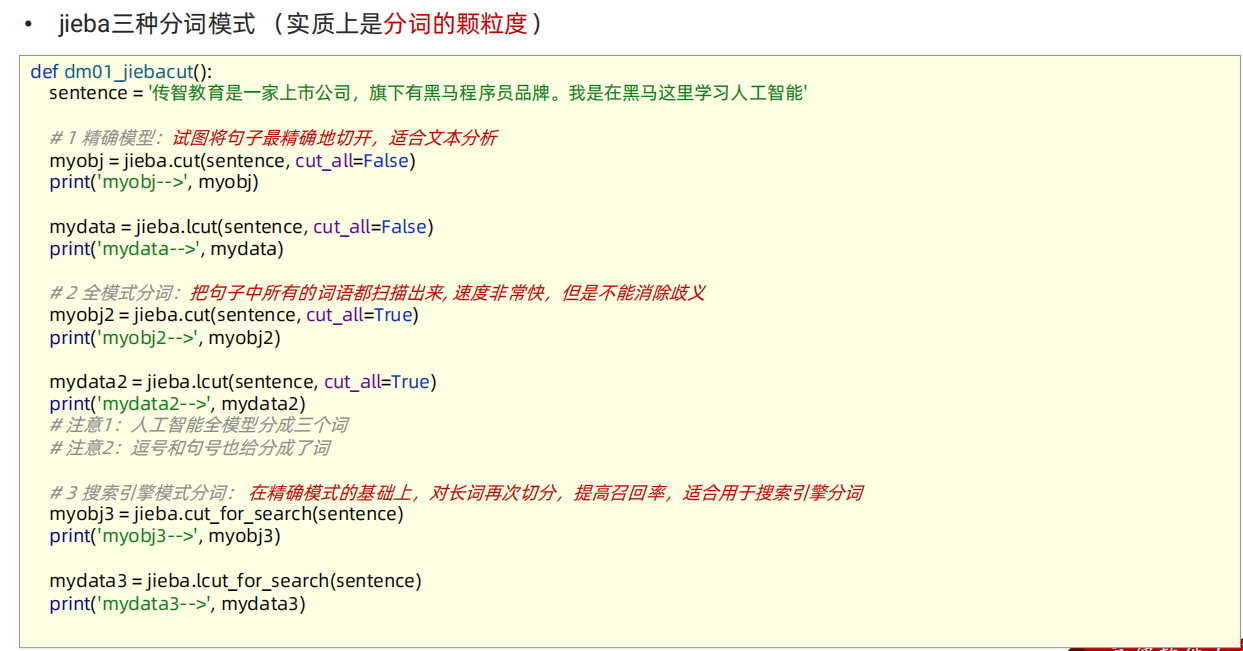



"""
结巴分词 使用 pip install jieba
精确模式
全词模式
搜索引擎模式
# 本质: 对分词的颗粒度进行控制
"""
import jieba# def cut(self, sentence, cut_all = False, HMM = True,use_paddle = False):
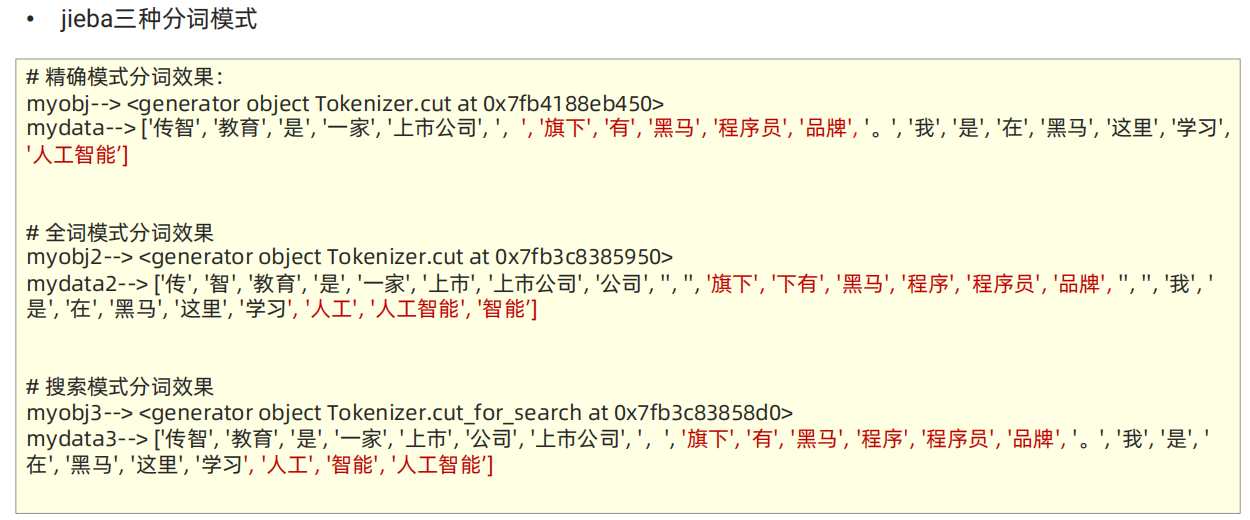
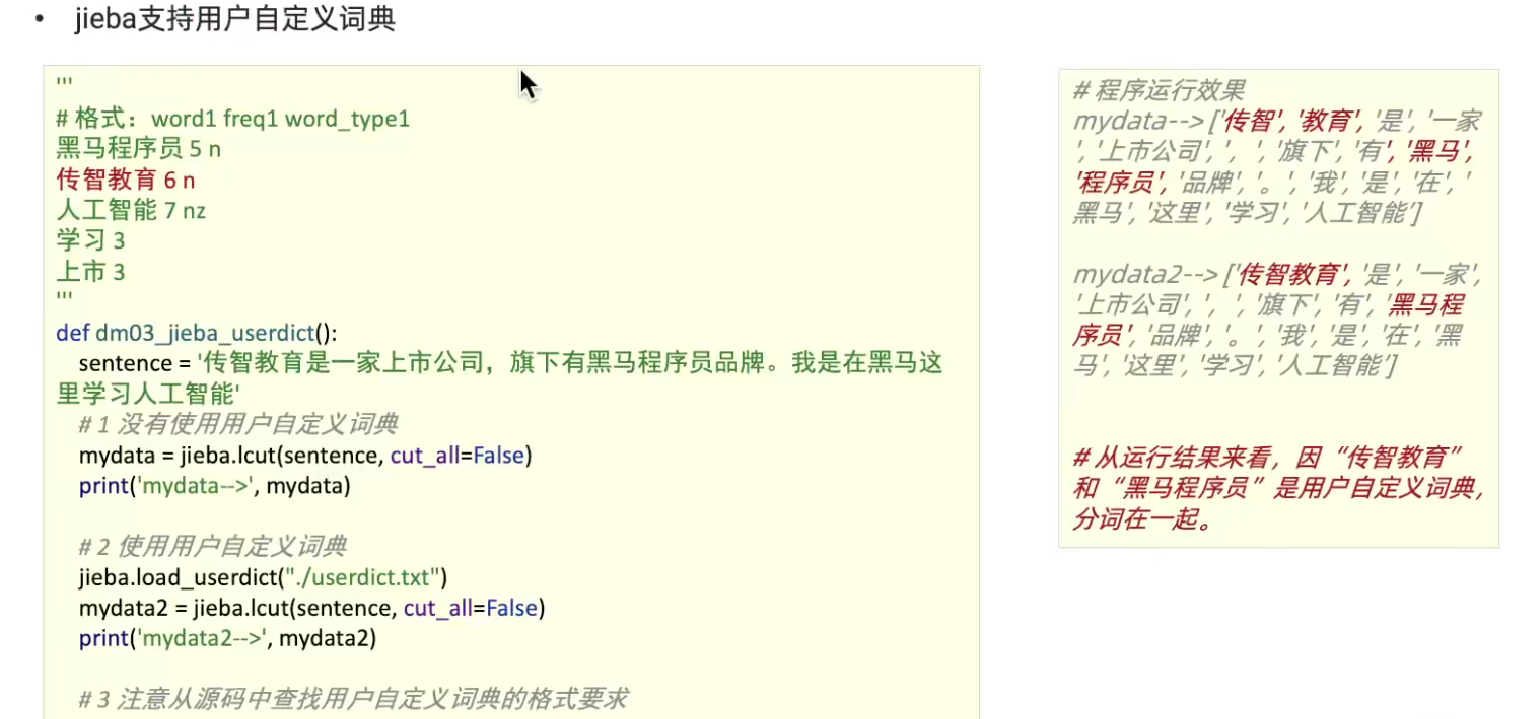
def dm01_jiebase_base():content = "传智教育是一家上市公司,旗下有黑马程序员品牌。我是在黑马这里学习人工智能"# 精确模式: 按照句子的语义对文本,尽量精准的进行分词myobj1 = jieba.cut(sentence=content, cut_all= False)print('myobj1-->', myobj1)mydata1 = jieba.lcut(sentence=content, cut_all=False)print('mydata1-->', mydata1)# 全词模式: 把所有的词都分出来myobj2 = jieba.cut(sentence=content, cut_all=True)print('myobj2-->', myobj2)mydata2 = jieba.lcut(sentence=content, cut_all=True)print('mydata2-->', mydata2)# 搜索引擎模式: 是在精确模式的基础之上, 对长词再做切分!!# def lcut_for_search(self, *args, **kwargs):myobj3 = jieba.cut_for_search(sentence=content)print('myobj3-->', myobj3)mydata3 = jieba.lcut_for_search(sentence=content)print('mydata3-->', mydata3)"""mydata1--> ['传智', '教育', '是', '一家', '上市公司', ',', '旗下', '有', '黑马', '程序员', '品牌', '。', '我', '是', '在', '黑马', '这里', '学习', '人工智能']myobj2--> <generator object Tokenizer.cut at 0x7f2b6f61c970>mydata2--> ['传', '智', '教育', '是', '一家', '上市', '上市公司', '公司', ',', '旗下', '下有', '黑马', '程序', '程序员', '品牌', '。', '我', '是', '在', '黑马', '这里', '学习', '人工', '人工智能', '智能']myobj3--> <generator object Tokenizer.cut_for_search at 0x7f2b6da7cac0>mydata3--> ['传智', '教育', '是', '一家', '上市', '公司', '上市公司', ',', '旗下', '有', '黑马', '程序', '程序员', '品牌', '。', '我', '是', '在', '黑马', '这里', '学习', '人工', '智能', '人工智能']"""'''' 1 用户字典格式
名字 + 词频 + 词性 ;注意 词频 + 词性是可以省略
上市
黑马程序员 5 n
传智教育 6 n
人工智能 7 nz
学习 32 流程3 用户字典的作用: 的确可以增加jieba分词的准确性'''def dm02_jiebase_用户字典():""" 字典内容:上市黑马程序员 5 n传智教育 6 n人工智能 7 nz学习 3"""# 1 不使用用户字典content = "传智教育是一家上市公司,旗下有黑马程序员品牌。我是在黑马这里学习人工智能"# 精确模式: 按照句子的语义对文本,尽量精准的进行分词mydata1 = jieba.lcut(sentence=content, cut_all=False)print('mydata1-->', mydata1)# 2 使用用户字典jieba.load_userdict('./userdict.txt')mydata2 = jieba.lcut(sentence=content, cut_all=False)print('mydata2-->', mydata2)pass"""输出如下mydata1--> ['传智', '教育', '是', '一家', '上市公司', ',', '旗下', '有', '黑马', '程序员', '品牌', '。', '我', '是', '在', '黑马', '这里', '学习', '人工智能']mydata2--> ['传智教育', '是', '一家', '上市公司', ',', '旗下', '有', '黑马程序员', '品牌', '。', '我', '是', '在', '黑马', '这里', '学习', '人工智能']"""# 支持繁体字
def dm03_jieba_base():content = "煩惱即是菩提,我暫且不提"mydata1 = jieba.lcut(content)print('mydata1--->', mydata1)# 中文词性标注
import jieba.posseg as pseg
def dm04_jieba_词性标注():mydata1 = pseg.lcut("我爱北京天安门")print('mydata1-->', mydata1)# 输出如下: mydata1--> [pair('我', 'r'), pair('爱', 'v'), pair('北京', 'ns'), pair('天安门', 'ns')]passif __name__ == '__main__':# dm01_jiebase_base()# dm02_jiebase_用户字典()# dm03_jieba_base()dm04_jieba_词性标注()