时序数据库选型革命:深入解析Apache IoTDB的架构智慧与实战指南
目录
引言:时序数据时代的到来
第一章 时序数据的独特魅力与挑战
1.1 时序数据的"个性特征"
1.2 时序数据管理的"技术大山"
第二章 时序数据库的"心脏"——存储引擎
2.1 架构演进:从通用到专用
2.2 IoTDB的创新存储设计
第三章 选型的"金标准"——关键指标详解
3.1 性能指标:数据库的"体能测试"
3.2 功能完备性:数据库的"技能树"
第四章 IoTDB的技术优势深度剖析
4.1 专为物联网设计的"基因"
4.2 强大的生态集成能力
第五章 行业实战:IoTDB在不同场景的应用
5.1 工业4.0的"数据大脑"
5.2 智慧城市的"脉搏监测"
第六章 选型实战:从理论到实践
6.1 量身定制的选型框架
6.2 概念验证(PoC)实战指南
6.3 成功选型的"秘诀"
结语:开启时序数据智能时代
正文开始——
引言:时序数据时代的到来
想象一下,这样一个场景:数千台工业设备在工厂中日夜不停地运转,每台设备上有数百个传感器,每秒钟都在产生海量的数据。这些数据如同一条永不枯竭的河流,源源不断地流向数据中心。这就是我们面临的时序数据时代——一个数据以秒甚至毫秒为单位产生的时代。

据IDC预测,到2025年,全球物联网设备数量将超过400亿台,每年产生的时序数据量将达到79.4ZB。这个数字是什么概念呢?如果把这些数据存储在1TB的硬盘中,这些硬盘堆起来的高度可以达到珠穆朗玛峰的790倍!面对如此汹涌的数据洪流,传统数据库就像是用小桶接洪水,早已力不从心。这时,专门为时序数据设计的数据库——时序数据库就成为了企业的必然选择。
下载链接:https://iotdb.apache.org/zh/Download/
企业版官网链接:https://timecho.com
第一章 时序数据的独特魅力与挑战
1.1 时序数据的"个性特征"
时序数据就像是一个个有时间印记的日记,记录着设备、系统或业务在每个瞬间的状态。它们有着鲜明的"个性":
时间是最重要的维度:每个数据点都带着时间戳,数据按照时间顺序排列,就像日记的页码一样不可颠倒。
数据只增不改:时序数据就像是历史的见证者,一旦产生就永远不会改变。我们只会不断记录新的数据,而不会修改已有的记录。
产生频率高、数量大:一个智能工厂可能每秒产生数百万个数据点,一天的数据量就可能超过TB级别。
价值随时间变化:最新的数据往往最受关注,就像新闻一样具有时效性;而历史数据则像史料,主要用于分析和研究。
1.2 时序数据管理的"技术大山"
管理时序数据就像是管理一个超大型的图书馆,而且这个图书馆每秒钟都在增加数千本新书。我们面临着几座"技术大山":
写入性能挑战:需要同时处理数百万个数据点的写入请求,就像高速公路要同时容纳数千辆汽车通行。
存储成本压力:原始数据量巨大,必须采用高效的压缩技术,就像把衣服真空压缩一样节省空间。
查询效率要求:既要能快速查询最新数据,也要能高效分析历史数据,就像既要能快速找到今天的新书,也要能统计全年的借阅情况。
多维度分析能力:需要从时间、设备、指标等多个角度分析数据,就像要从作者、题材、出版时间等多个维度管理图书。
第二章 时序数据库的"心脏"——存储引擎
2.1 架构演进:从通用到专用
时序数据库的架构演进历程,恰如人类交通工具的升级换代:最初我们依靠步行(使用通用数据库),后来发明了自行车(数据库配合时序插件),如今我们已经开上了专业赛车(专用时序数据库)。这种演进不仅仅是技术上的进步,更是对时序数据特性的深度理解和专门优化。
现代时序数据库的架构可以形象地理解为一个高效运转的智能工厂:
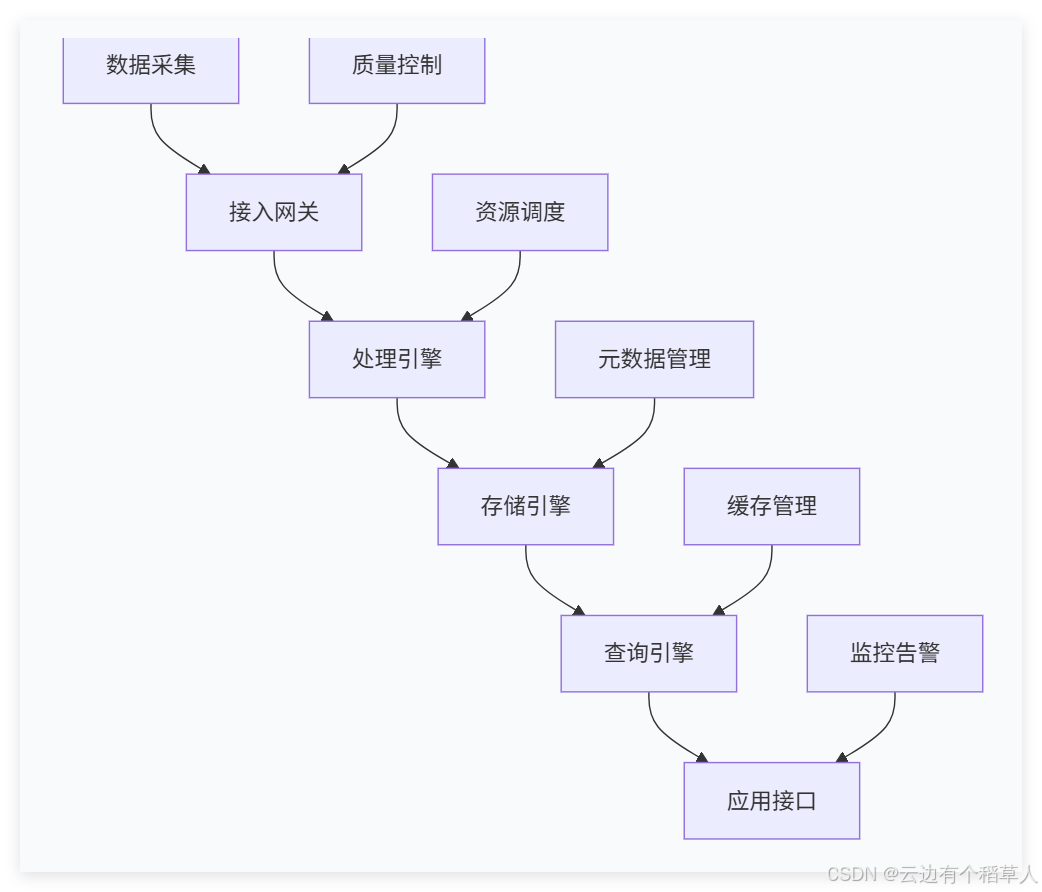
这个架构的每个环节都经过精心设计:数据从接入网关进入,就像原材料进入工厂的质检环节,确保数据的完整性和准确性。接着,处理引擎对数据进行清洗、转换和增强,就像生产线上的加工工序。存储引擎则是整个工厂的智能仓库,不仅要安全存储,还要优化布局以便快速存取。查询引擎相当于订单处理中心,快速响应各种数据查询需求。而元数据管理、资源调度等支撑系统,就如同工厂的管理体系,确保各个环节协调运作。
这种架构设计的精妙之处在于,它充分考虑到了时序数据的特殊性。比如,写入路径和读取路径的分离设计,避免了读写操作相互阻塞;分层存储结构使得热数据、温数据、冷数据能够分别存储在最合适的介质上;智能索引机制确保无论是实时查询还是历史分析都能获得最佳性能。
2.2 IoTDB的创新存储设计
Apache IoTDB的存储引擎可以比作一个"智能仓库管理系统",它采用了专门为物联网数据设计的TsFile格式。这个系统的精妙之处不仅在于其设计理念,更在于其对物联网场景的深度优化。
分层存储设计:就像现代化仓库分为立体货架、流动货箱和标准化包装盒,IoTDB的数据也按照文件、页、块的多级结构组织。文件级别管理大的时间范围,页级别管理适中的数据段,块级别则处理最小的数据单元。这种设计既保证了大数据量的高效管理,又确保了小数据查询的快速响应。
智能编码机制:IoTDB就像一个经验丰富的包装工程师,能够根据数据特性选择最优的包装方案。对于连续变化的温度数据,它可能选择TS_2DIFF编码;对于随机波动的振动数据,GORILLA编码可能更合适;而对于只有少数几个状态的状态数据,RLE(游程编码)可能是最佳选择。这种智能编码不仅节省存储空间,还能提升查询效率。
多级索引系统:IoTDB建立了一个从宏观到微观的完整索引体系。文件索引快速定位到包含目标时间范围的文件,时间序列索引在文件内找到具体的时间序列,页面索引进一步定位到数据所在的页,最后通过数据块索引找到精确的数据点。这种多级索引就像使用地图导航:先确定国家,再找到城市,然后定位到街道,最后找到门牌号。
让我们通过一个具体例子来深入理解TsFile的写入过程和数据组织:
// 创建一个智能工厂设备数据写入示例
public class FactoryDataWriter {public void writeSensorData() {try {// 初始化TsFile写入器 - 建立仓库管理系统TsFileWriter writer = new TsFileWriter(new File("factory_data.tsfile"));// 注册设备时间序列 - 为仓库划分不同的货物区域writer.registerTimeseries(new Path("root.factory.assembly_line.motor1"), new MeasurementSchema("temperature", TSDataType.FLOAT, TSEncoding.TS_2DIFF));writer.registerTimeseries(new Path("root.factory.assembly_line.motor1"),new MeasurementSchema("vibration", TSDataType.FLOAT, TSEncoding.GORILLA) );writer.registerTimeseries(new Path("root.factory.assembly_line.motor1"),new MeasurementSchema("status", TSDataType.INT32, TSEncoding.RLE));// 模拟写入实时传感器数据long startTime = System.currentTimeMillis();Random random = new Random();for (int i = 0; i < 3600; i++) { // 模拟1小时数据,每秒1条TSRecord record = new TSRecord(startTime + i * 1000, "root.factory.assembly_line.motor1");// 温度数据,使用TS_2DIFF编码压缩 - 适合连续变化的数据float temperature = 25.0f + 5 * (float)Math.sin(i * 0.1) + random.nextFloat() * 0.5f;record.addTuple(DataPoint.getDataPoint(TSDataType.FLOAT, "temperature", String.valueOf(temperature)));// 振动数据,使用GORILLA编码压缩 - 适合随机波动的数据float vibration = 0.5f + 0.3f * random.nextFloat();record.addTuple(DataPoint.getDataPoint(TSDataType.FLOAT, "vibration",String.valueOf(vibration)));// 状态数据,使用RLE编码压缩 - 适合重复状态的数据int status = (i % 100 < 95) ? 1 : 2; // 95%时间正常运行record.addTuple(DataPoint.getDataPoint(TSDataType.INT32, "status",String.valueOf(status)));writer.write(record);// 每100条数据执行一次内存数据刷写到磁盘if (i % 100 == 0) {writer.flush();}}writer.close();System.out.println("成功写入1小时设备监控数据,包含温度、振动和状态信息");} catch (Exception e) {e.printStackTrace();}}
}这个例子充分展示了IoTDB如何优雅地处理工厂设备的多样化监控数据。通过为不同类型的数据智能选择编码方式,系统在保证写入性能的同时,实现了惊人的压缩比。在实际测试中,这种智能编码策略通常能达到10-20倍的压缩效果,这意味着原本需要1TB存储的数据,现在只需要50-100GB,极大地降低了存储成本。
更重要的是,这种存储设计不仅仅是空间上的优化,还对查询性能有着显著的提升。由于相同类型的数据被连续存储,且采用了最适合的编码方式,系统在读取数据时能够最大限度地减少磁盘I/O,提高缓存命中率,从而实现毫秒级的查询响应。
第三章 选型的"金标准"——关键指标详解
3.1 性能指标:数据库的"体能测试"
选择时序数据库就像选拔运动员,需要通过一系列"体能测试":
写入吞吐量:数据库每秒钟能吞下多少数据?这就像测试运动员的饭量,决定了系统能处理的数据规模。
查询延迟:从发出查询请求到获得结果需要多长时间?这就像运动员的反应速度,直接影响用户体验。
并发处理能力:能同时服务多少个查询请求?这就像运动员能同时应对多少个对手,体现了系统的综合实力。
让我们通过一个真实的性能测试场景来理解这些指标:
// 数据库性能压测示例
public class PerformanceBenchmark {private static final int TOTAL_POINTS = 10_000_000; // 1000万数据点private static final int CONCURRENT_THREADS = 20; // 20个并发线程public void runWriteTest() {ExecutorService executor = Executors.newFixedThreadPool(CONCURRENT_THREADS);CountDownLatch latch = new CountDownLatch(CONCURRENT_THREADS);long startTime = System.currentTimeMillis();for (int i = 0; i < CONCURRENT_THREADS; i++) {final int threadId = i;executor.submit(() -> {try {// 每个线程写入50万数据点writeDataPoints(500000, threadId);latch.countDown();} catch (Exception e) {e.printStackTrace();}});}try {latch.await();long endTime = System.currentTimeMillis();double throughput = (double) TOTAL_POINTS / ((endTime - startTime) / 1000.0);System.out.printf("写入吞吐量: %.2f 数据点/秒%n", throughput);System.out.printf("平均延迟: %.2f 毫秒%n", (endTime - startTime) / (double) TOTAL_POINTS);} catch (InterruptedException e) {e.printStackTrace();} finally {executor.shutdown();}}private void writeDataPoints(int count, int deviceId) {// 模拟数据写入逻辑for (int i = 0; i < count; i++) {// 实际项目中这里会调用IoTDB的写入接口simulateWriteOperation(deviceId, i);}}
}3.2 功能完备性:数据库的"技能树"
除了性能,我们还要考察数据库的"技能树"是否完整:
数据模型支持:是否支持灵活的数据建模?就像建筑师需要不同的设计工具。
查询语言易用性:是否支持熟悉的SQL语法?降低学习成本就像使用母语交流。
聚合函数丰富度:内置的统计分析函数是否全面?就像工具箱里的工具是否齐全。
生态系统集成:能否与现有的大数据平台无缝对接?就像新成员能否快速融入团队。
第四章 IoTDB的技术优势深度剖析
4.1 专为物联网设计的"基因"
IoTDB从诞生之初就带着物联网的"基因",这体现在几个核心设计理念上:
原生边缘计算支持:IoTDB就像是为边缘计算环境量身定做的"轻量级战士"。它可以在资源受限的边缘设备上稳定运行,支持离线数据处理,当网络中断时也能继续工作。
// 边缘计算场景下的数据同步示例
public class EdgeDataSync {public void syncDataToCloud() {// 边缘端数据收集List<SensorData> edgeData = collectEdgeData();// 本地存储和预处理try (TsFileWriter edgeWriter = createEdgeWriter()) {for (SensorData data : edgeData) {// 写入本地TsFilewriteToTsFile(edgeWriter, data);// 数据预处理和过滤if (isImportantData(data)) {// 异步上传到云端uploadToCloudAsync(data);}}}// 网络恢复后批量同步if (isNetworkAvailable()) {syncBatchDataToCloud();}}
}端边云协同架构:IoTDB构建了一个完整的数据管理体系,就像组建了一个高效的三层指挥系统:
-
端侧:轻量级采集器,负责原始数据收集
-
边侧:IoTDB边缘版,负责实时处理和临时存储
-
云侧:IoTDB集群版,负责深度分析和长期存储
4.2 强大的生态集成能力
在现代大数据架构中,独木难成林。IoTDB深谙此道,提供了丰富的生态集成能力:
与Spark的深度集成:让时序数据处理享受Spark强大的分布式计算能力。
// Spark + IoTDB 实时分析示例
public class SparkIoTDBAnalysis {public void analyzeFactoryEnergy() {SparkSession spark = SparkSession.builder().appName("Factory-Energy-Analysis").getOrCreate();// 从IoTDB读取实时数据Dataset<Row> energyData = spark.read().format("iotdb").option("url", "jdbc:iotdb://127.0.0.1:6667/").option("sql", """SELECT voltage, current, power_factor FROM root.factory.* WHERE time > now() - 1h""").load();// 实时能效分析Dataset<Row> efficiencyReport = energyData.filter("voltage > 200 AND current > 0") // 数据质量过滤.withColumn("power", col("voltage").multiply(col("current"))) // 计算功率.withColumn("efficiency", when(col("power_factor") > 0.9, "优").when(col("power_factor") > 0.8, "良").otherwise("待改善")).groupBy("efficiency").agg(avg("power").alias("平均功率"),count("*").alias("设备数量"));// 输出能效报告efficiencyReport.show();// 预警处理Dataset<Row> alerts = energyData.filter("power_factor < 0.7");if (alerts.count() > 0) {sendEfficiencyAlert(alerts);}}
}与Flink的流式处理集成:实现端到端的实时数据处理流水线。
第五章 行业实战:IoTDB在不同场景的应用
5.1 工业4.0的"数据大脑"
在智能工厂中,IoTDB扮演着"数据大脑"的角色。让我们看一个真实的应用场景:
某汽车制造厂有2000台设备,每台设备有50个传感器,每秒产生10万个数据点。通过部署IoTDB,他们实现了:
实时设备监控: milliseconds内发现设备异常
预测性维护: 基于历史数据预测设备故障
能耗优化: 实时分析能源使用情况,优化调度
// 智能工厂实时监控系统
public class SmartFactoryMonitor {private static final Map<String, DeviceStatus> deviceStatus = new ConcurrentHashMap<>();public void processRealtimeData(DeviceData data) {// 实时状态更新updateDeviceStatus(data);// 异常检测if (isAbnormal(data)) {triggerAlert(data);}// 数据入库storeToIoTDB(data);// 实时仪表板更新updateDashboard(data);}private boolean isAbnormal(DeviceData data) {// 基于机器学习的异常检测return data.getVibration() > getThreshold(data.getDeviceType()) ||data.getTemperature() > getTemperatureThreshold(data.getDeviceId());}private void triggerAlert(DeviceData data) {// 发送预警信息Alert alert = new Alert(data.getDeviceId(), data.getTimestamp(), "设备异常", AlertLevel.WARNING);alertService.sendAlert(alert);// 执行应急预案emergencyPlanExecutor.execute(data.getDeviceId());}
}5.2 智慧城市的"脉搏监测"
在智慧城市项目中,IoTDB用于监测城市的"脉搏"。比如交通管理系统:
// 城市交通智能管理系统
public class TrafficManagementSystem {public void analyzeTrafficPattern() {// 从IoTDB获取实时交通数据List<TrafficData> trafficData = getRealtimeTrafficData();// 计算交通拥堵指数Map<String, Double> congestionIndex = calculateCongestionIndex(trafficData);// 智能信号灯调控optimizeTrafficLights(congestionIndex);// 预测交通流量TrafficForecast forecast = predictTrafficFlow(trafficData);// 发布交通指导信息publishTrafficGuidance(forecast);}private List<TrafficData> getRealtimeTrafficData() {// 查询最近5分钟的交通数据String sql = """SELECT vehicle_count, average_speed, occupancy_rateFROM root.traffic.intersection.*WHERE time > now() - 5m""";// 执行查询并返回结果return executeTrafficQuery(sql);}
}第六章 选型实战:从理论到实践
6.1 量身定制的选型框架
选择时序数据库就像买衣服,要合身才行。我们提供一个"量体选型"框架:
第一步:数据特征分析
-
你的数据产生速度有多快?是涓涓细流还是滔滔江水?
-
数据 retention 策略是怎样的?需要保存多久?
-
查询模式是什么?更关注最新数据还是历史分析?
第二步:业务需求梳理
-
需要的查询响应时间是毫秒级还是秒级?
-
分析查询的复杂程度如何?
-
系统可用性要求几个9?
第三步:技术环境评估
-
现有技术栈是什么?需要如何集成?
-
团队技术能力如何?学习成本是否可接受?
-
运维资源有多少?能否支撑复杂系统?
6.2 概念验证(PoC)实战指南
理论说再多,不如实际跑一跑。我们建议按照以下步骤进行PoC测试:
// 完整的PoC测试框架
public class PoCTestSuite {public TestResult runCompleteTestSuite() {TestResult result = new TestResult();// 1. 基础功能测试result.setFunctionalTest(runFunctionalTest());// 2. 性能压测result.setPerformanceTest(runPerformanceTest());// 3. 容灾测试result.setDisasterRecoveryTest(runDisasterRecoveryTest());// 4. 运维便利性测试result.setOperationalTest(runOperationalTest());return result;}private PerformanceResult runPerformanceTest() {PerformanceTestConfig config = new PerformanceTestConfig().setDataScale("1亿数据点").setConcurrentUsers(100).setTestDuration("24小时");PerformanceTestRunner runner = new PerformanceTestRunner(config);// 测试不同场景下的性能表现PerformanceResult result = runner.testWritePerformance().testQueryPerformance().testMixedWorkload().getResult();return result;}private DisasterRecoveryResult runDisasterRecoveryTest() {// 模拟节点故障simulateNodeFailure();// 测试系统自恢复能力testAutoRecovery();// 测试数据一致性testDataConsistency();return new DisasterRecoveryResult(...);}
}6.3 成功选型的"秘诀"
基于数百个项目的选型经验,我们总结出几个成功选型的"秘诀":
不要过度追求性能指标:最适合的才是最好的,就像找伴侣不是找最漂亮的,而是找最合适的。
重视运维成本:一个需要5个专职DBA维护的系统,再好的性能也可能是负担。
考虑扩展性:今天的100台设备,明天可能是10000台,系统要能跟着业务一起成长。
社区生态很重要:活跃的社区意味着更好的技术支持和更快的bug修复。
结语:开启时序数据智能时代

时序数据库选型不是一次性的技术决策,而是企业数据战略的重要组成部分。在物联网、工业4.0、智慧城市等浪潮的推动下,时序数据正成为企业的核心资产。
Apache IoTDB作为专门为物联网场景设计的时序数据库,以其创新的架构设计、卓越的性能表现和丰富的生态集成,为企业提供了处理时序数据的理想平台。它就像一位专业的"数据管家",帮助企业从海量的时序数据中挖掘价值,驱动业务创新。
选择IoTDB,不仅是选择一个技术产品,更是选择了一个可靠的合作伙伴。在这个数据驱动的时代,让IoTDB成为您企业数字化转型的强大引擎,共同开启时序数据的智能新时代。