linux 系统压力测试工具stress使用
一、stress 工具简介
stress 是一款 Linux 系统下的压力测试工具,通过模拟 CPU、内存、磁盘 I/O 等系统负载,帮助用户评估系统在高负载情况下的性能表现和稳定性。它通过创建多个进程来消耗系统资源,可用于:
- 测试硬件承载能力
- 验证系统稳定性
- 评估应用在高负载下的表现
- 测试监控告警系统的有效性
二、在线安装步骤
1. 安装 EPEL 源
yum install epel-release -y
原理:EPEL (Extra Packages for Enterprise Linux) 是 Fedora 项目维护的额外软件仓库,包含许多不在默认仓库中的实用工具,stress 就是其中之一。
验证安装:
rpm -q epel-release
如果成功安装,会显示类似epel-release-8-11.el8.noarch的版本信息。
可能遇到的问题:
- 网络连接失败:检查网络设置和 yum 源配置
- 权限不足:使用
sudo或切换到 root 用户执行 - 找不到包:清理 yum 缓存后重试
yum clean all && yum makecache
2. 安装 stress 工具
yum install stress -y
原理:通过 yum 包管理器从 EPEL 仓库下载并安装 stress 软件包及其依赖。
验证安装:
rpm -q stress
成功安装会显示类似stress-1.0.4-24.el8.x86_64的版本信息。
可能遇到的问题:
- 依赖冲突:尝试
yum install --skip-broken stress跳过冲突的依赖 - 仓库同步问题:执行
yum update更新仓库信息后重试
三、离线安装步骤
1. 下载合适的 rpm 包
根据系统架构选择对应的安装包:
- x86_64 架构:https://www.rpmfind.net/linux/epel/8/Everything/x86_64/Packages/s/stress-1.0.4-24.el8.x86_64.rpm
- aarch64 架构:https://www.rpmfind.net/linux/epel/8/Everything/aarch64/Packages/s/stress-1.0.4-24.el8.aarch64.rpm
验证系统架构:
uname -m
- x86_64:显示
x86_64 - aarch64:显示
aarch64
2. 安装下载的 rpm 包
rpm -ivh stress-1.0.4-24.el8.x86_64.rpm
参数说明:
-i:安装软件包-v:显示详细安装过程-h:显示安装进度条
验证安装:
rpm -q stress-1.0.4-24.el8.x86_64
或检查版本:
stress --version
可能遇到的问题:
- 依赖缺失:根据提示手动下载并安装缺失的依赖包
- 架构不匹配:确认下载的包与系统架构一致
- 权限问题:使用 root 权限安装
四、stress 工具使用详解
1. CPU 压力测试
查看 CPU 核心数
# 方法1:显示CPU详细信息
lscpu# 方法2:只显示CPU核心数
nproc
原理:了解系统 CPU 核心数可以帮助我们设置合适的压力测试参数,通常建议测试进程数不超过 CPU 核心数的 2 倍。
执行 CPU 压力测试
# 运行8个进程占用CPU,持续60秒
stress --cpu 8 --timeout 60s# 简写形式
stress -c 8 -t 60s
后台运行方式:
# 后台运行,关闭终端不影响
nohup stress --cpu 8 &
原理:stress 通过创建指定数量的进程,每个进程循环计算平方根来消耗 CPU 资源,从而达到压力测试的目的。
验证压力测试效果:
# 实时查看CPU使用率
top# 或使用htop(需额外安装)
htop
在 top 命令中,按P键可以按 CPU 使用率排序,应能看到多个 stress 进程占用较高 CPU 资源。
结束 CPU 压力测试
# 方法1:根据进程ID结束
ps aux | grep stress # 查找进程ID
kill 进程ID# 方法2:结束所有stress进程
pkill stress
可能遇到的问题:
- 系统无响应:测试时不要设置过多进程,保留部分系统资源用于管理操作
- 无法结束进程:使用
pkill -9 stress强制终止
2. 内存压力测试
执行内存压力测试
# 启动1个线程,分配4GB内存,持续60秒
stress --vm 1 --vm-bytes 4G --vm-keep -t 60s# 后台持续运行,分配7GB内存
stress --vm 1 --vm-bytes 7G --vm-keep &
参数详解:
--vm N:启动 N 个内存压测线程--vm-bytes SIZE:每个线程分配的内存大小,支持 K、M、G 等单位--vm-keep:保持内存分配不释放-t/--timeout:测试持续时间
原理:stress 通过不断分配内存并写入数据,然后保持这些内存不释放,从而测试系统内存管理能力和在内存不足时的表现。
验证内存压力测试效果:
# 查看内存使用情况(GB为单位)
free -g# 实时监控内存使用
top # 按M键按内存使用率排序
结束内存压力测试
# 结束所有stress进程
pkill stress
可能遇到的问题:
- 内存分配失败:设置的内存大小超过系统实际可用内存,会导致测试失败
- 系统 OOM (内存溢出):系统可能会自动终止其他进程来释放内存,测试时要谨慎设置内存大小
- 测试后内存未释放:确保正确终止所有 stress 进程,必要时重启系统
五、综合压力测试
可以同时对 CPU 和内存进行压力测试:
# 同时测试CPU(4个进程)和内存(2个线程,每个分配2GB),持续5分钟
stress --cpu 4 --vm 2 --vm-bytes 2G --timeout 300s
六、常见问题及解决方法
-
安装失败
- 检查网络连接和 yum 源配置
- 确认系统架构与安装包匹配
- 手动解决依赖关系
-
测试过程中系统响应缓慢
- 减少压力测试的进程数或资源分配量
- 避免在生产环境进行高强度压力测试
- 提前做好系统备份
-
stress 命令找不到
- 检查是否正确安装
- 确认安装路径是否在系统 PATH 环境变量中
-
内存测试无法达到预期效果
- 检查系统是否开启了 swap 分区
- 确认分配的内存大小在系统承受范围内
-
进程无法正常终止
- 使用
pkill -9 stress强制终止 - 检查是否有僵尸进程,必要时重启系统
- 使用
七、使用注意事项
- 压力测试可能导致系统性能严重下降,建议在非生产环境或维护窗口期进行
- 逐步增加压力强度,避免一次性施加过大压力导致系统崩溃
- 测试过程中密切监控系统状态,发现异常立即终止测试
- 记录测试过程中的系统指标,便于分析系统性能瓶颈
- 长时间压力测试可能影响硬件寿命,需谨慎使用
八、扩展
1.为什么要做压力测试
压力测试的本质不是 “折磨系统”,而是 **“提前暴露系统的潜在问题”**,避免这些问题在生产环境爆发(比如双 11 卡顿、支付失败)。它的核心价值体现在 3 个方面:
1. 验证系统 “极限能力”,避免 “ Capacity 不足”
- 比如你搭建了一个电商服务器,想知道它最多能同时处理多少用户下单(这就是 “并发容量”)。
- 没有压力测试,你可能误以为服务器能扛 1 万并发,实际只能扛 3000,双 11 当天就会直接崩溃。
- 典型场景:新系统上线前、业务峰值(如 618、春节)前,必须测 “最大能扛多少”。
2. 发现 “隐性瓶颈”,优化系统性能
- 很多问题在 “低负载” 下不会出现,只有压力上来才会暴露:
- 比如 CPU 单核负载过高(可能是代码没做好多核优化);
- 内存泄漏(压力持续 1 小时后,内存占用越来越高,最终 OOM);
- 磁盘 I/O 瓶颈(比如数据库写入压力大时,磁盘读写速度跟不上,导致请求超时)。
- 压力测试能帮你定位 “到底是 CPU、内存、磁盘还是网络拖了后腿”,针对性优化。
补充磁盘瓶颈的判断方式:
a.查看磁盘I/O相关指标


b.结合系统响应和业务场景判断
- 系统响应变慢:当磁盘 I/O 出现瓶颈时,依赖磁盘读写的应用程序响应时间会明显增加。比如数据库操作变得缓慢,查询语句的执行时间从原来的几毫秒增加到几百毫秒甚至几秒;文件读写操作也变得迟缓,打开或保存文件需要很长时间 。
- 业务场景分析:在一些特定的业务场景下,更容易出现磁盘 I/O 瓶颈。例如,在电商大促期间,订单数据的大量写入和读取,对数据库所在磁盘的 I/O 性能要求极高。如果此时磁盘无法满足业务的 I/O 需求,就会出现瓶颈,表现为订单提交缓慢、查询订单状态延迟等问题。又比如,在数据备份场景中,大量数据需要写入备份磁盘,如果磁盘性能不足,也会导致备份时间过长,甚至备份失败 。
c.对比磁盘性能标称
将磁盘的实际读写速度与厂商提供的性能标称值进行对比。如果在压力测试或高负载情况下,磁盘的实际读写速度远低于标称值,比如机械硬盘的实际写入速度只有标称值的 30% - 50% ,且排除了磁盘故障等其他因素,很可能是磁盘 I/O 出现了瓶颈,可能是由于系统配置不合理、驱动问题或者负载过高导致磁盘无法发挥正常性能 。
3. 验证系统 “稳定性”,避免 “长时间运行崩溃”
- 有些系统短时间扛住高负载没问题,但持续运行几小时 / 几天就会出问题(比如内存泄漏、连接池耗尽)。
- 比如服务器持续 12 小时跑 80% CPU 负载,若期间出现 “进程无响应”“请求失败率上升”,就说明稳定性有问题,需要修复。
2.什么时候该做压力测试?(关键场景)
不是任何时候都需要做压力测试,以下是必须做的 4 个关键节点:
| 场景类型 | 具体时机 | 测试目标 |
|---|---|---|
| 新系统 / 新功能上线前 | 上线前 1-2 周 | 验证 “能否满足预期业务负载”(比如预期支持 5000 并发,测是否达标) |
| 业务峰值来临前 | 大促(618 / 双 11)、节假日(春节抢票)前 2-4 周 | 验证 “峰值负载下系统是否稳定”,提前扩容或优化 |
| 系统变更后 | 服务器硬件升级(如加 CPU / 内存)、软件升级(如换数据库版本)、代码重构后 | 验证 “变更后性能是否提升 / 没下降”,避免改出问题 |
| 定期巡检 | 生产系统每季度 / 半年一次 | 监控 “系统性能是否随时间退化”(比如长期运行后,磁盘碎片增多导致 I/O 变慢) |
3.核心:压力测试结果怎么分析?
学会看指标,才是压力测试的 “核心”。我们以 Linux 系统为例,结合stress工具的压测场景,拆解CPU、内存、磁盘、网络四大核心指标的 “正常范围” 和 “异常信号”。
前提:用什么工具看指标?
光跑stress没用,必须搭配 “监控工具” 看实时指标,常用工具:
- 实时监控:
top(看 CPU / 内存)、free(内存)、iostat(磁盘 I/O)、iftop(网络); - 更直观的图形化工具:
htop(top增强版)、nmon(一站式看所有指标)、glances(跨平台监控)。
1. CPU 指标:看 “负载”“使用率”“核均负载”
压测 CPU 时(如stress -c 8),重点看 3 个指标:
| 指标名称 | 查看方式 | 正常范围 | 异常信号(需要警惕) | 可能原因 |
|---|---|---|---|---|
| CPU 使用率(%us) | top命令中 “% us” 列(用户进程占用 CPU 比例) | 压测时:70%-90%(保留 10%-30% 给系统进程);日常:<50% | 压测时 > 95% 或 日常 > 70% | 1. 压测进程数过多(如 8 核 CPU 开 16 个stress进程);2. 代码没做多核优化(比如单线程跑满一个核,其他核空闲) |
| CPU 负载(load average) | top命令第一行 “load average: 1.2, 0.8, 0.5”(1/5/15 分钟平均负载) | 负载值 ≈ CPU 核心数(如 8 核 CPU,负载 8 左右正常) | 负载值 > 核心数 * 1.5(如 8 核负载 > 12) | 1. 进程数过多,CPU 处理不过来;2. 有进程占用 CPU 但不释放(如死循环) |
| 核均负载 | top中按 “1” 展开所有核,看每个核的 % us | 各核负载均匀(差异 < 20%) | 某一个核 % us>95%,其他核 < 50% | 代码是 “单线程” 或 “线程绑定错误”,没利用多核资源 |
案例分析:8 核 CPU 跑stress -c 8,top显示 % us=98%,load average=10,某一个核 % us=99%,其他核 % us=80%。→ 异常:负载过高(10>8*1.2=9.6),且核负载不均;→ 原因:可能stress进程绑定了特定 CPU 核,或系统有其他高 CPU 进程干扰;→ 解决:检查是否有其他进程占用 CPU,或重新执行stress命令(默认不绑定核)。
表格中cpu负载异常可能原因提到的进程占用问题,可用下列步骤查看:
a.实时查看

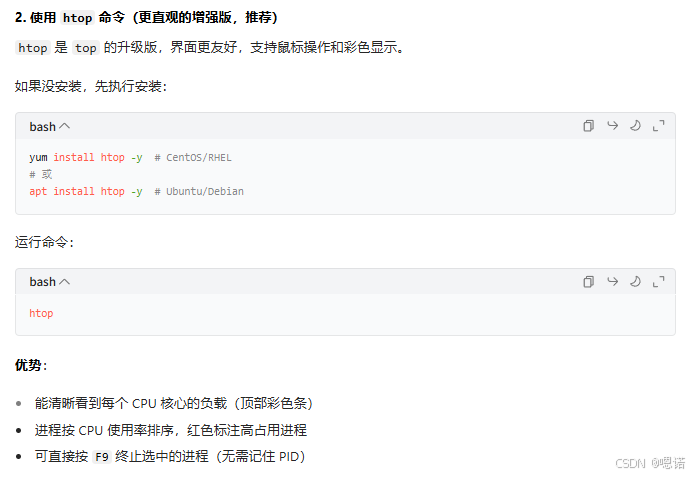
b.一次性查看占用前N的进程
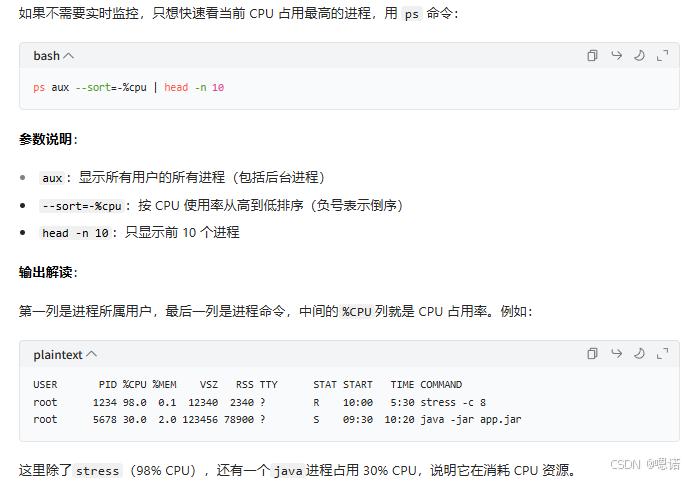
c.检查特定进程的CPU
如果怀疑某个程序(比如nginx、mysql)占用 CPU,可以用 grep 过滤:
# 查看所有包含"java"的进程的CPU占用
ps aux | grep java | grep -v grep
grep -v grep 用于排除命令本身的进程(避免干扰结果)。
d.检查CPU核心的负载均衡
有时候整体 CPU 使用率不高,但某个核心被占满(比如单线程程序),可以用 top 查看每个核心的负载:
- 运行
top命令 - 按数字
1键,展开显示所有 CPU 核心(如Cpu0、Cpu1...) - 观察每个核心的
%us(用户进程占用),如果某一个核心的%us接近 100%,而其他核心很低,说明存在 “核心负载不均” 的问题。
e.发现高占用进程后的处理
- 临时终止进程(仅测试环境,生产环境需谨慎):
bash
kill -9 进程ID # 比如kill -9 5678(终止上面示例中的java进程) - 永久解决:
- 如果是无关进程(如测试残留的程序),直接卸载或禁用
- 如果是必要进程(如业务程序),需要优化其代码(如减少循环计算、优化多线程)
2. 内存指标:看 “使用率”“缓存”“Swap 使用”
压测内存时(如stress --vm 1 --vm-bytes 4G),重点看 3 个指标:
| 指标名称 | 查看方式 | 正常范围 | 异常信号 | 可能原因 |
|---|---|---|---|---|
| 已用内存(used) | free -h命令中 “used” 列(注意:要排除 “buff/cache”) | 压测时:used ≈ 压测分配的内存(如分配 4G,used 应接近 4G,但不超过系统总内存 - 1G);日常:used < 总内存的 70% | 1. 压测时 used + buff/cache > 总内存(会触发 Swap);2. 压测结束后,used 内存不下降(内存泄漏) | 1. 压测分配的内存超过系统实际可用内存;2. stress进程没正常终止;3. 系统有内存泄漏进程 |
| 缓存内存(buff/cache) | free -h中 “buff/cache” 列 | 缓存会动态变化,只要 used 内存正常,缓存高是好事(系统利用空闲内存做缓存) | 缓存突然减少,且 used 内存快速增加 | 系统内存不足,开始回收缓存给应用使用 |
| Swap 使用率(Swap used) | free -h中 “Swap” 列 | 0%(理想)或 <10% | Swap used >20% | 1. 压测分配的内存超过物理内存;2. 系统内存不足,开始用磁盘当内存(会导致性能暴跌,因为磁盘速度比内存慢 1000 倍) |
案例分析:系统总内存 8G,跑stress --vm 1 --vm-bytes 7G,free -h显示 used=7.2G,Swap used=0.5G。→ 异常:Swap 被使用;→ 原因:分配的 7G 内存接近总内存 8G,系统预留的 1G 内存不够,触发 Swap;→ 解决:减少压测内存(如改 6G),或升级物理内存。
3. 磁盘 I/O 指标:看 “读写速度”“IO 等待”
若压测涉及磁盘(如stress --hdd 1模拟磁盘写负载),重点看 2 个指标:
| 指标名称 | 查看方式 | 正常范围 | 异常信号 | 可能原因 |
|---|---|---|---|---|
| IO 等待时间(%iowait) | top中 “% wa” 列(CPU 等待磁盘 I/O 完成的时间比例) | <10% | >20% | 1. 磁盘读写速度跟不上(如机械硬盘跑满写入);2. 磁盘故障(如坏道导致读写延迟) |
| 磁盘读写速度(rMB/s/wMB/s) | iostat -xm 1(每 1 秒刷新一次,看 “rMB/s”“wMB/s”) | 取决于磁盘类型:- 机械硬盘(HDD):写≈50-150MB/s;- 固态硬盘(SSD):写≈300-1000MB/s | 1. 速度远低于磁盘标称值;2. 速度波动大(忽高忽低) | 1. 磁盘性能不足;2. 磁盘分区对齐错误;3. 系统开启了不必要的磁盘缓存 |
案例分析:机械硬盘跑stress --hdd 1,iostat显示 wMB/s=200MB/s(远超 HDD 标称的 150MB/s),top中 % wa=30%。→ 异常:写速度超极限,IO 等待高;→ 原因:stress的磁盘压测参数过强,超出磁盘承载能力;→ 解决:减少stress的磁盘进程数(如--hdd 0.5),或换 SSD 测试。
补充上面的“SSD测试”:机械硬盘HHD的数据读写速度受限于盘片的旋转速度、磁头的寻道时间等机械部件的性能,其顺序读写速度一般在50-150MB/s,随机读写性能更差,当压力测试时,有时会出现机械硬盘无法承受如此高的写入负载,导致大量的CPU时间都花在等待磁盘I/O完成上,出现异常情况。而固态硬盘SSD的数据读写是通过电信号对闪存内存芯片进行操作,数据传输速度更快,相比机械硬盘,SSD的顺序读写可以轻松达到300-1000MB/s甚至更高,随机读写性能也有大幅度提升。
补充上面的“磁盘标称”:磁盘标称值并不是完全固定不变的,它主要由磁盘的类型、品牌、具体型号以及生产工艺等因素决定。不过,对于某一款特定型号的磁盘产品,在其产品说明文档中,会给出一个相对文档的性能参考指标称值,在没有硬件故障、系统异常等问题时,该磁盘正常运行的性能会在这个标称值附近波动。查看方式:产品说明书、厂商官网。
4. 网络指标(补充):看 “带宽利用率”“丢包率”
若压测涉及网络(如模拟多客户端访问服务器),重点看 2 个指标:
| 指标名称 | 查看方式 | 正常范围 | 异常信号 | 可能原因 |
|---|---|---|---|---|
| 带宽利用率 | iftop(实时看网卡带宽使用) | <80%(预留 20% 给突发流量) | >90% | 1. 压测的网络流量超过网卡带宽(如 1G 网卡跑 1.2G 流量);2. 网络拥堵 |
| 丢包率 / 延迟 | ping 服务器IP(看延迟)、tcpdump(抓包看丢包) | 延迟 < 100ms,丢包率 = 0% | 延迟 > 500ms,丢包率 > 1% | 1. 带宽耗尽;2. 服务器网卡性能不足;3. 网络路由问题 |
4.压力值的确认
在压力测试中,“数值怎么定” 和 “异常怎么判” 是两个核心痛点 —— 定错数值会导致测试无效(比如直接拉满压力导致系统瞬间崩溃,啥问题也查不出来),判错异常会浪费排障时间(比如把 “数值设置过高” 当成 “系统故障”)。
a.压力测试数值该怎么确定?(核心原则:从 “基准” 到 “极限”,逐步递进)
压力测试的数值(比如 CPU 进程数、内存分配量)绝对不能直接拉满(比如 8 核 CPU 直接跑stress -c 16,16G 内存直接分配 15G),否则系统会瞬间进入 “极端状态”(如 CPU 100%、内存耗尽触发 Swap),既无法定位瓶颈,还可能导致测试中断。
正确的方法是 **“阶梯式加压”**,分 3 个阶段确定数值,每个阶段都有明确的目标和判断标准:
阶段 1:先测 “基准值”—— 确定系统 “无压力时的正常状态”
在开始加压前,必须先记录系统基准指标,这是后续判断 “是否异常” 的基础。
步骤
- 确保系统无额外负载(关闭无关进程,如测试残留的
stress、非必要的业务程序); - 用
top(CPU / 内存)、iostat(磁盘)、iftop(网络)记录核心指标,持续观察 5-10 分钟; - 记录基准值(示例,8 核 16G 服务器):
指标 基准值范围 说明 CPU 使用率 5%-15% 仅系统进程和必要服务占用 内存使用率 20%-30% 排除缓存后的实际占用 磁盘 IO 等待 <5% 无明显读写操作时的等待 网络带宽使用 <10Mbps 无业务流量时的空闲状态
目标
- 确认系统 “初始状态是否正常”(比如基准状态下 CPU 就有 30%,说明有隐藏进程占用,需先清理);
- 后续加压时,用 “当前指标 - 基准值” 计算 “实际压力负载”(比如加压后 CPU 80%,实际负载是 80%-10%=70%)。
阶段 2:再测 “目标负载值”—— 验证系统 “能否满足业务需求”
“目标负载值” 不是拍脑袋定的,而是基于实际业务场景(比如 “日常并发 500,峰值并发 1000”),换算成对应的 CPU / 内存负载。
操作步骤:
- 先明确业务目标(关键!):比如 “电商服务器日常需支持 500 用户同时下单,CPU 负载不超过 60%,内存占用不超过 8G”;
- 换算成
stress的测试数值:- CPU:8 核服务器,目标负载 60% → 进程数 = 核心数 × 负载比例 = 8×0.6≈5 → 用
stress -c 5; - 内存:目标占用 8G → 分配量 = 目标占用 - 基准内存(16G×30%=4.8G)≈3G → 用
stress --vm 1 --vm-bytes 3G;(这边的基准内存是因为前文假设了我们的机器是16g,30%是“记录基准值”那个表假设的最高值,实际要替换成自己的机器和实际记录的基准值)
- CPU:8 核服务器,目标负载 60% → 进程数 = 核心数 × 负载比例 = 8×0.6≈5 → 用
- 维持目标负载运行 30-60 分钟,观察指标:
- 若指标稳定(CPU 稳定在 60%±5%,内存稳定在 8G 左右,无明显波动)→ 说明系统能满足业务需求;
- 若指标波动大(比如 CPU 忽高到 80% 忽低到 40%)→ 可能是测试数值设置不合理,或系统有不稳定因素。
关键提醒:
- 目标负载值必须 “贴合业务”,比如 “日常负载” 不能按 “极限负载” 定(否则系统长期高负载运行,容易崩溃);
- 若目标负载下就出现异常(如 CPU 超 80%、内存泄漏)→ 不用测极限,先解决目标负载的问题。
阶段 3:最后测 “极限负载值”—— 找到系统 “最大能扛多少”
极限负载是 “系统刚好不崩溃的最大压力”,用于判断 “业务峰值是否有冗余”(比如峰值 1000 并发,极限是 1500,说明有 50% 冗余,安全)。峰值可以从业务场景和历史数据倒退,至于系统极限要通过压力测试阶梯加压测出,两者结合再判断

操作步骤:
- 从 “目标负载值” 开始,阶梯式增加压力,每次增加 10%-20%,维持 15-30 分钟:
- 例:CPU 目标负载 60%(5 进程)→ 第一次加至 70%(6 进程)→ 第二次加至 80%(7 进程)→ 第三次加至 90%(8 进程);
- 观察 “极限信号”,出现以下情况说明达到极限:
- CPU:持续 100%,且
%iowait(IO 等待)超 20%(CPU 等着磁盘 / 网络,无法干活); - 内存:开始使用 Swap(
free -h显示 Swap used>10%),且系统响应变慢; - 进程:
stress进程被系统杀死(OOM killer 触发),或出现 “defunct”(僵尸进程); - 响应:若有业务程序,请求失败率超 5%(比如接口超时、报错)。
- CPU:持续 100%,且
- 记录极限负载值:比如 8 核 CPU 极限是 9 进程(CPU 95%,无 Swap 使用),内存极限是 8G(分配 8G 时无 Swap,分配 9G 时触发 Swap)。
注意:
- 极限测试时要 “慢加压力”,每次增加后给系统适应时间,避免瞬间崩溃;
- 极限测试后需重启系统(释放缓存、清理僵尸进程),避免影响后续测试。
5.出现异常信号时,怎么判断是 “数值错”“系统错” 还是 “机器错”?(3 步归因法)
异常信号(如 CPU 超 100%、Swap 使用、进程崩溃)出现后,不要立刻下结论,按 “先查数值→再查系统→最后查机器” 的顺序排查,避免误判。
第一步:先判断 “是不是测试数值设置错了”(最常见原因)
数值设置错误是新手最容易犯的问题,比如 “分配的内存超过物理内存”“CPU 进程数远超核心数”,导致的异常不是系统问题,而是 “压力给太猛了”。
排查方法:
- 核对 “测试数值” 与 “硬件配置”:
- CPU:进程数是否超过核心数的 2 倍(8 核 CPU 最多 16 进程,超过就是过度加压);
- 内存:分配量是否超过 “物理内存 - 2G”(16G 内存最多分配 14G,留 2G 给系统,否则触发 Swap);
- 磁盘:
stress --hdd的进程数是否超过磁盘 IO 能力(机械硬盘最多 1-2 个进程,SSD 最多 3-4 个,多了 IO 等待必超);
- 对比 “当前压力” 与 “基准 + 目标”:
- 例:目标负载 CPU 60%,但你设置了 10 进程(8 核),导致 CPU 100%→ 明显是数值设高了;
- 例:内存基准 4.8G,你分配了 12G→ 16G-4.8G=11.2G,分配 12G 超了,触发 Swap→ 数值设高了。
结论:
- 若数值超过 “硬件配置上限” 或 “目标负载合理范围”→ 是数值错,调整后重新测试;
- 若数值在合理范围→ 进入下一步,查系统。
第二步:再判断 “是不是系统配置 / 软件有问题”(核心排查点)
数值合理但仍有异常,大概率是 “系统软件” 的问题(如配置不当、代码 bug、依赖冲突),而非硬件。
排查方法:
- 查 “系统日志”,找异常原因:
- CPU / 内存异常:看
/var/log/messages(系统日志),搜索 “OOM”(内存溢出)、“killed process”(进程被杀死):bash
grep -i "oom" /var/log/messages grep -i "killed" /var/log/messages- 若日志显示 “Out of memory: Kill process stress (PID 1234)”→ 可能是内存泄漏(stress 本应稳定占用,却持续申请内存);
- 使用 dmesg 命令:
dmesg命令用于显示内核环形缓冲区的内容,其中也会包含 OOM 相关的信息。执行dmesg | grep -i "oom",若有 OOM 事件,会输出相关的内核报错信息,帮助你了解 OOM 发生时的具体情况,如当时系统内存的使用状态等 。 - 借助监控工具:像
top、htop等实时监控工具,在 OOM 发生前后,如果密切关注内存使用情况,会发现内存占用持续上升直至达到系统极限,同时可能会看到某些进程因内存不足被突然终止 。此外,一些专业的系统监控软件(如 Zabbix、Prometheus 等),可以设置内存相关的监控指标和告警规则,当 OOM 即将发生或已经发生时,能及时发出告警通知 。
- 磁盘异常:看
/var/log/messages搜索 “io error”→ 若有 “hard error”(硬件错误)→ 可能是磁盘坏道(但先排除软件问题);
- CPU / 内存异常:看
- 查 “软件配置”:
- 比如内存测试时,是否开启了 “内存限制”(如
cgroup限制了 stress 的内存使用); - CPU 测试时,是否开启了 “CPU 亲和性”(绑定了特定核心,导致其他核心空闲但单个核心满负载);
- 比如内存测试时,是否开启了 “内存限制”(如
- 对比 “不同系统的测试结果”(交叉验证):
- 若在 “相同硬件、不同系统”(如同一台机器,装 CentOS 7 和 CentOS 8)测试,只有一个系统异常→ 是系统配置 / 软件问题;
- 若两个系统都异常→ 进入下一步,查机器。
常见系统问题案例:
- 案例 1:目标负载 CPU 60%(5 进程),但 CPU 持续 100%→ 查日志发现 “java 进程占用 30% CPU”→ 是系统有隐藏进程,清理后恢复正常;
- 案例 2:内存测试时,分配 3G 却持续增长到 5G→ 查日志发现 “stress 内存泄漏”→ 是 stress 版本 bug,升级版本后解决。
第三步:最后判断 “是不是机器硬件有问题”(最少见,但需确认)
硬件问题(如 CPU 故障、内存坏条、磁盘坏道)导致的异常,通常有 “持续性、普遍性” 特征(不是只在压力测试时出现)。90% 的异常是 “数值设置错” 或 “系统软件问题”,只有 10% 是硬件问题
排查方法:
- 用 “硬件检测工具” 检查:
- CPU:用
mprime(Linux 版 Prime95)跑 30 分钟,若出现 “Hardware failure detected”→ CPU 有问题; - 内存:用
memtest86+(需重启进入)检测,若有 “Errors found”→ 内存坏条; - 磁盘:用
smartctl查磁盘健康状态(需安装smartmontools):bash
smartctl -a /dev/sda # /dev/sda是磁盘设备名,用lsblk查看- 若 “SMART Health Status” 显示 “FAILING”→ 磁盘故障;
- CPU:用
- 观察 “非测试时的硬件状态”:
- 若日常使用中也出现 “突然死机”“蓝屏”“磁盘读写报错”→ 大概率是硬件问题;
- 若只有压力测试时出现,且硬件检测无异常→ 不是硬件问题,回到系统排查。
硬件问题案例:
- 案例:压力测试时 CPU 总是忽高到 100% 忽低到 50%,且
top显示 CPU 核心温度超 90℃→ 是 CPU 散热不良(风扇故障),导致 CPU 降频,更换风扇后恢复正常。
6、压力测试 vs 其他常见测试:有啥区别?
很多人会混淆 “压力测试”“性能测试”“负载测试”,这里用表格明确区分,避免用错场景:
| 测试类型 | 核心目标 | 测试方式 | 适用场景 |
|---|---|---|---|
| 压力测试(Stress Test) | 找 “系统极限” 和 “崩溃点” | 逐步增加负载(如 CPU 从 50%→80%→100%),直到系统响应变慢 / 崩溃 | 验证系统最大承载能力(如 “服务器最多能扛多少并发”) |
| 负载测试(Load Test) | 验证 “系统在预期负载下是否稳定” | 维持 “预期业务负载” 运行一段时间(如 8 核 CPU 跑 70% 负载,持续 2 小时) | 确认系统能满足日常 / 峰值业务需求(如 “双 11 预期 8000 并发,测是否稳定运行”) |
| 性能测试(Performance Test) | 测 “系统性能指标是否达标” | 固定负载下,测响应时间、吞吐量等(如 “1000 并发下,接口响应时间是否 < 500ms”) | 验证系统性能是否符合设计要求(如接口响应时间、吞吐量) |
| 稳定性测试(Soak Test) | 测 “系统长时间运行是否稳定” | 低 - 中负载下(如 CPU 50%),持续运行 12-72 小时 | 检查是否有内存泄漏、连接池耗尽等长期问题 |
一句话总结:
- 想知道 “系统最多能扛多少”→ 压力测试;
- 想知道 “系统在日常负载下稳不稳”→ 负载测试;
- 想知道 “接口响应快不快”→ 性能测试;
- 想知道 “系统跑几天会不会崩”→ 稳定性测试。
7、新手分析指标的 实用建议
1.“对比法” 分析
压测前记录 “baseline (基准指标)”(如 CPU 10%、内存 30%),压测中对比指标变化 —— 若压测时 CPU 从 10%→90%,但响应时间没明显变长,就是正常;若 CPU 只到 50%,响应时间就从 100ms→1s,就是异常。
2.“单一变量” 原则
一次只测一个组件(比如先测 CPU,再测内存,不要同时测),避免多个指标同时异常,无法定位原因。
3.“不要只看数值,要看趋势”
比如内存使用率从 40%→50%→60%(缓慢上升),可能是正常缓存;但从 40%→80%→95%(快速上升),就是内存泄漏的信号。