【完整源码+数据集+部署教程】害虫识别与分类图像分割系统源码和数据集:改进yolo11-MSBlock
背景意义
研究背景与意义
随着全球气候变化和人类活动的加剧,害虫的种类和数量不断增加,给农业、生态环境和公共卫生带来了严重威胁。害虫不仅会直接损害农作物,导致经济损失,还可能传播疾病,影响人类健康。因此,及时准确地识别和分类害虫成为了农业管理和生态保护中的一项重要任务。传统的害虫识别方法依赖于专家的经验和人工观察,效率低下且容易受到主观因素的影响,难以满足现代农业和生态监测的需求。
近年来,计算机视觉技术的快速发展为害虫识别提供了新的解决方案。基于深度学习的目标检测算法,尤其是YOLO(You Only Look Once)系列,因其高效的实时检测能力和较高的准确率,逐渐成为害虫识别领域的研究热点。YOLOv11作为该系列的最新版本,具备更强的特征提取能力和更快的处理速度,能够在复杂环境中实现对多种害虫的快速识别与分类。
本研究旨在基于改进的YOLOv11算法,构建一个高效的害虫识别与分类图像分割系统。该系统将利用一个包含22种害虫的丰富数据集,涵盖了如蚊子、蟑螂、蜜蜂等多种常见害虫。这些害虫不仅在生态系统中扮演着重要角色,也对人类生活产生了深远影响。通过对4857张经过精细标注的图像进行训练,系统将能够实现对不同种类害虫的精准识别与分类,从而为农业管理和生态监测提供有力支持。
此外,本研究还将探讨数据预处理和增强技术对模型性能的影响,力求在提高识别准确率的同时,降低对计算资源的需求。通过建立高效的害虫识别系统,不仅可以为农民提供实时的害虫监测工具,还能为相关科研提供数据支持,推动害虫生态学和防治技术的发展。因此,本研究具有重要的理论价值和实际应用意义。
图片效果
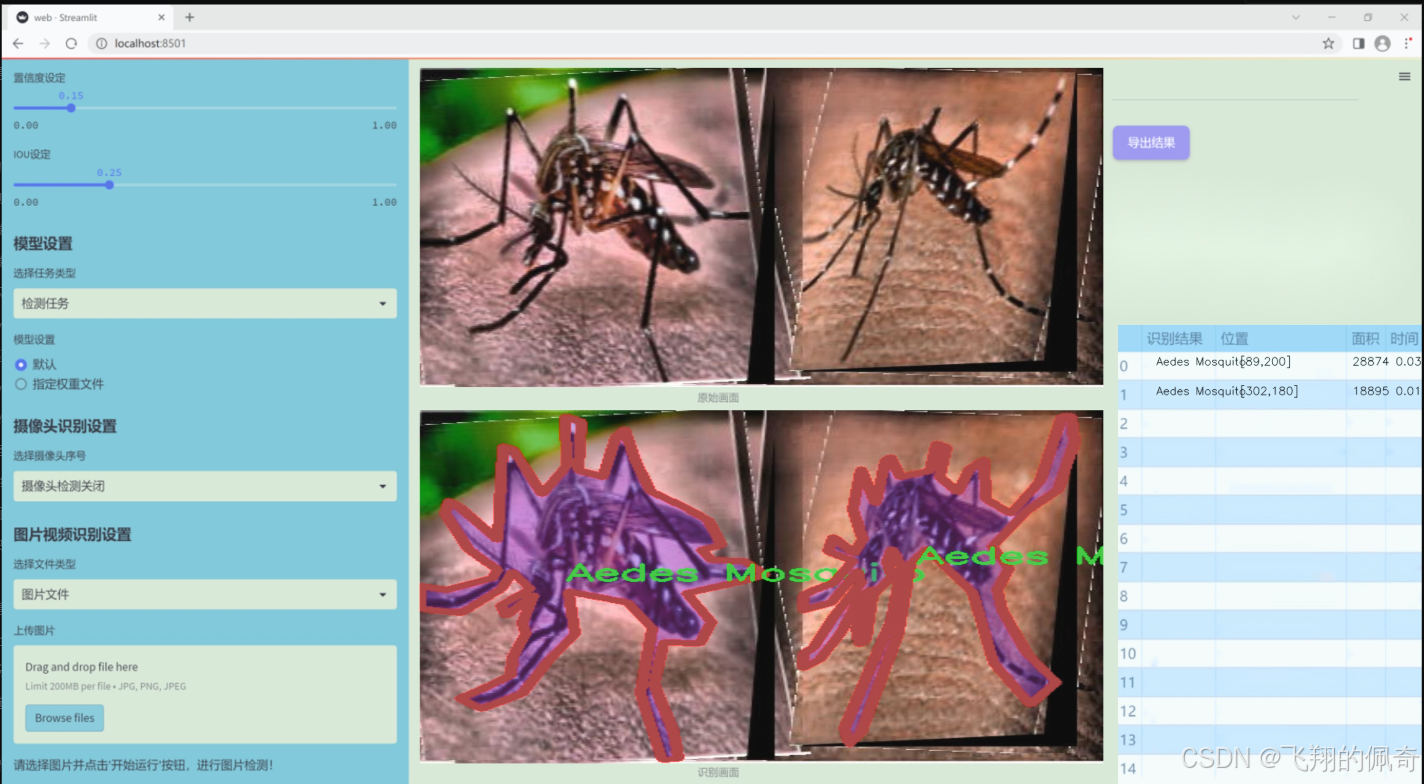
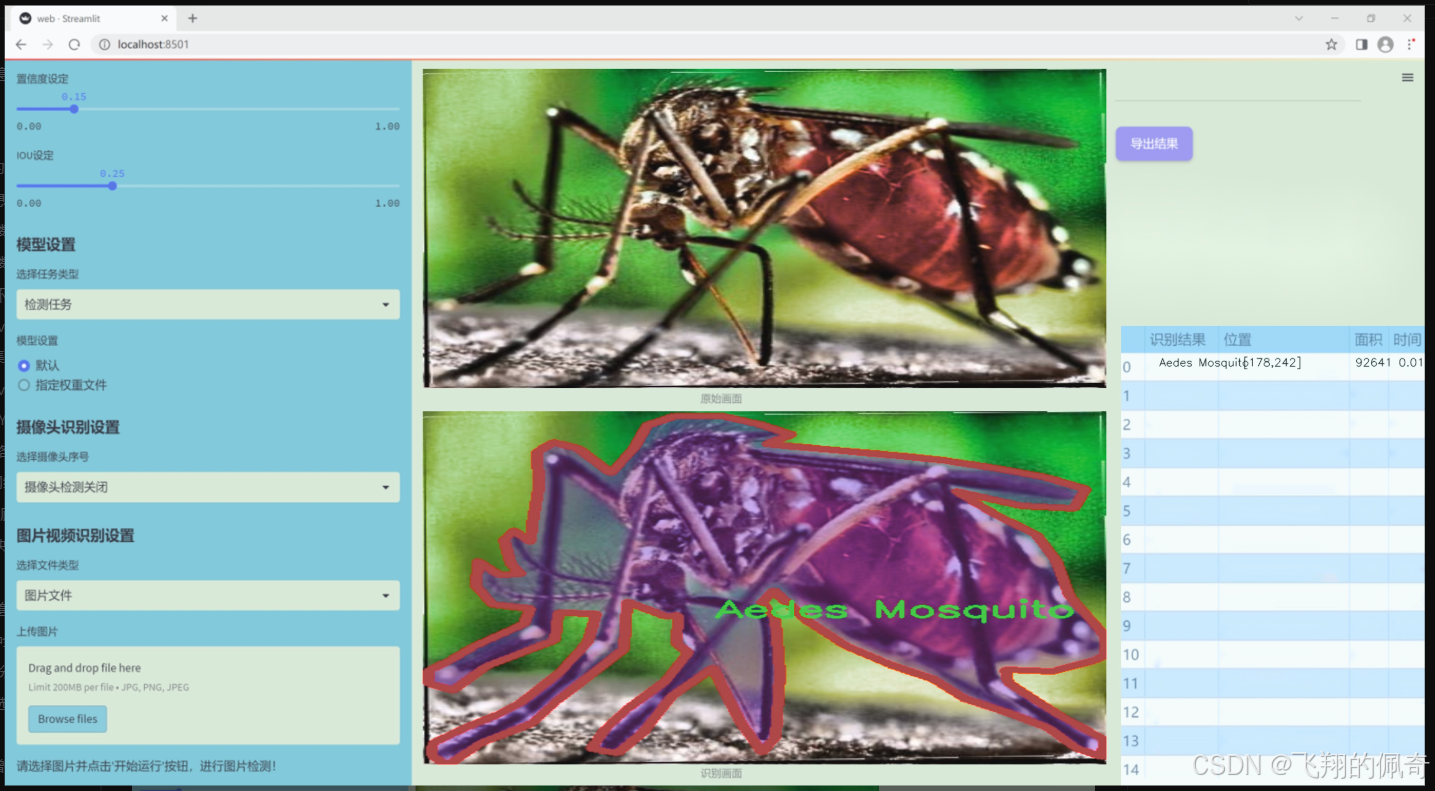
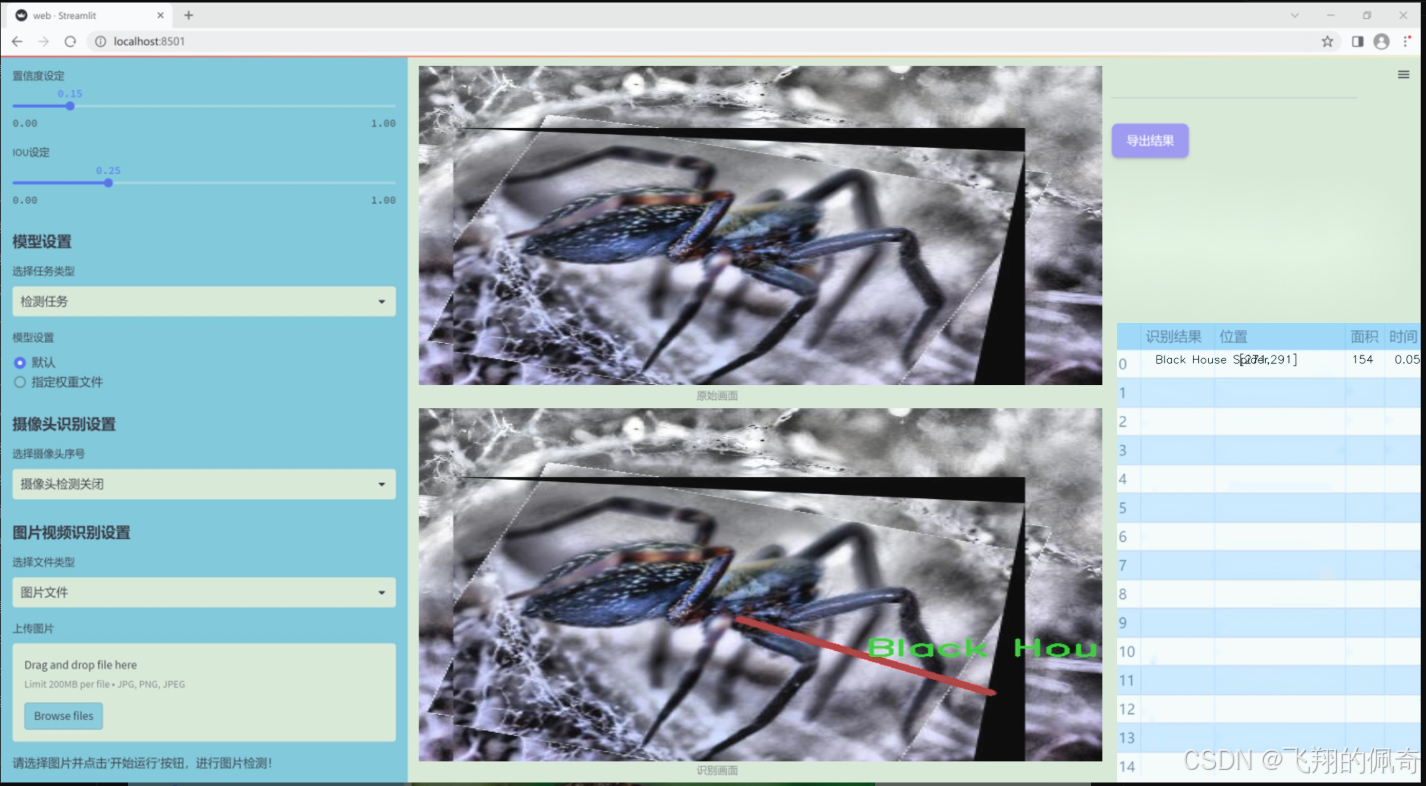
数据集信息
本项目数据集信息介绍
本项目旨在改进YOLOv11的害虫识别与分类图像分割系统,所使用的数据集来源于“Dynamite Duelers Project”,该数据集专注于多种害虫的识别与分类,涵盖了22个不同的类别。这些类别包括了常见的蚊子、蟑螂、蜱虫、蜜蜂及多种蜘蛛等,具体类别有:Aedes蚊子、美国蟑螂、按蚊、亚洲长角蜱、黑屋蜘蛛、黑寡妇蜘蛛、黑木匠蚂蚁、棕色狗蜱、熊蜂、木匠蜂、库勒蚊、鹿蜱、家蝇、孤星蜱、驼鹿蜱、复发热蜱、 stag甲虫、西方蜜蜂、狼蛛、木蜱、杂技蚂蚁和疯狂蚂蚁等。这些害虫在生态系统中扮演着重要的角色,但同时也可能对人类健康和农业生产造成威胁,因此对其进行有效的识别与分类显得尤为重要。
数据集中的图像经过精心挑选,确保了每个类别的样本具有足够的多样性和代表性,涵盖了不同的环境、光照条件和角度,以提高模型的泛化能力。此外,数据集还包含了标注信息,便于训练和验证阶段的图像分割任务。通过利用这一数据集,改进后的YOLOv11模型将能够在实际应用中更准确地识别和分类这些害虫,从而为相关领域的研究和实践提供有力支持。
总之,本项目的数据集不仅为害虫识别与分类提供了丰富的样本资源,也为未来的研究和应用奠定了坚实的基础,期待通过技术的进步,能够更好地服务于生态保护和公共卫生的需求。
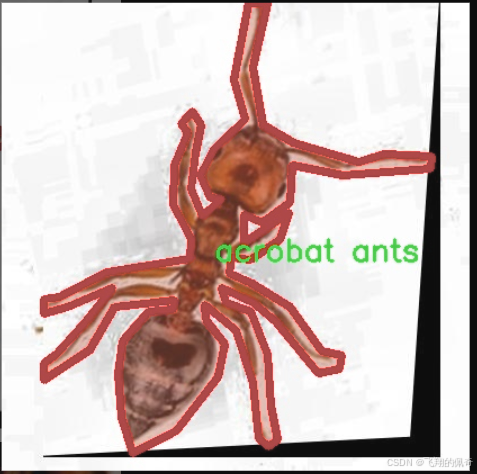




核心代码
以下是经过简化并添加详细中文注释的核心代码部分:
import math
import torch
import torch.nn as nn
def autopad(k, p=None, d=1): # kernel, padding, dilation
“”“自动填充以确保输出形状与输入形状相同。”“”
if d > 1:
# 计算实际的卷积核大小
k = d * (k - 1) + 1 if isinstance(k, int) else [d * (x - 1) + 1 for x in k]
if p is None:
# 默认填充为卷积核大小的一半
p = k // 2 if isinstance(k, int) else [x // 2 for x in k]
return p
class Conv(nn.Module):
“”“标准卷积层,包含卷积、批归一化和激活函数。”“”
default_act = nn.SiLU() # 默认激活函数def __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):"""初始化卷积层,参数包括输入通道数、输出通道数、卷积核大小、步幅、填充、分组、膨胀和激活函数。"""super().__init__()# 定义卷积层self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)# 定义批归一化层self.bn = nn.BatchNorm2d(c2)# 根据输入选择激活函数self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()def forward(self, x):"""前向传播:应用卷积、批归一化和激活函数。"""return self.act(self.bn(self.conv(x)))
class DWConv(Conv):
“”“深度卷积层,适用于每个输入通道独立卷积。”“”
def __init__(self, c1, c2, k=1, s=1, d=1, act=True):"""初始化深度卷积层,参数包括输入通道数、输出通道数、卷积核大小、步幅、膨胀和激活函数。"""super().__init__(c1, c2, k, s, g=math.gcd(c1, c2), d=d, act=act)
class DSConv(nn.Module):
“”“深度可分离卷积层,由深度卷积和逐点卷积组成。”“”
def __init__(self, c1, c2, k=1, s=1, d=1, act=True):super().__init__()# 定义深度卷积self.dwconv = DWConv(c1, c1, 3)# 定义逐点卷积self.pwconv = Conv(c1, c2, 1)def forward(self, x):"""前向传播:先通过深度卷积,再通过逐点卷积。"""return self.pwconv(self.dwconv(x))
class ConvTranspose(nn.Module):
“”“转置卷积层,常用于上采样。”“”
default_act = nn.SiLU() # 默认激活函数def __init__(self, c1, c2, k=2, s=2, p=0, bn=True, act=True):"""初始化转置卷积层,参数包括输入通道数、输出通道数、卷积核大小、步幅、填充、是否使用批归一化和激活函数。"""super().__init__()self.conv_transpose = nn.ConvTranspose2d(c1, c2, k, s, p, bias=not bn)self.bn = nn.BatchNorm2d(c2) if bn else nn.Identity()self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()def forward(self, x):"""前向传播:应用转置卷积、批归一化和激活函数。"""return self.act(self.bn(self.conv_transpose(x)))
class ChannelAttention(nn.Module):
“”“通道注意力模块,用于增强特征表示。”“”
def __init__(self, channels: int):"""初始化通道注意力模块,参数为通道数。"""super().__init__()self.pool = nn.AdaptiveAvgPool2d(1) # 自适应平均池化self.fc = nn.Conv2d(channels, channels, 1, 1, 0, bias=True) # 1x1卷积self.act = nn.Sigmoid() # Sigmoid激活函数def forward(self, x: torch.Tensor) -> torch.Tensor:"""前向传播:通过池化和卷积计算通道注意力。"""return x * self.act(self.fc(self.pool(x)))
class SpatialAttention(nn.Module):
“”“空间注意力模块,用于增强特征的空间信息。”“”
def __init__(self, kernel_size=7):"""初始化空间注意力模块,参数为卷积核大小。"""super().__init__()assert kernel_size in {3, 7}, "卷积核大小必须为3或7"padding = 3 if kernel_size == 7 else 1self.cv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False) # 卷积层self.act = nn.Sigmoid() # Sigmoid激活函数def forward(self, x):"""前向传播:计算空间注意力并返回加权特征图。"""return x * self.act(self.cv1(torch.cat([torch.mean(x, 1, keepdim=True), torch.max(x, 1, keepdim=True)[0]], 1)))
class CBAM(nn.Module):
“”“卷积块注意力模块,结合通道和空间注意力。”“”
def __init__(self, c1, kernel_size=7):"""初始化CBAM模块,参数为输入通道数和卷积核大小。"""super().__init__()self.channel_attention = ChannelAttention(c1) # 通道注意力self.spatial_attention = SpatialAttention(kernel_size) # 空间注意力def forward(self, x):"""前向传播:依次应用通道注意力和空间注意力。"""return self.spatial_attention(self.channel_attention(x))
代码说明
自动填充函数 (autopad): 计算卷积操作所需的填充,以确保输出与输入的空间维度相同。
卷积层 (Conv): 定义了一个标准的卷积层,包含卷积、批归一化和激活函数。
深度卷积 (DWConv): 继承自 Conv,实现深度卷积操作。
深度可分离卷积 (DSConv): 由深度卷积和逐点卷积组成,用于减少参数数量和计算量。
转置卷积 (ConvTranspose): 用于上采样的转置卷积层。
通道注意力模块 (ChannelAttention): 通过自适应池化和1x1卷积来增强特征图的通道信息。
空间注意力模块 (SpatialAttention): 通过卷积计算空间注意力,增强特征图的空间信息。
卷积块注意力模块 (CBAM): 结合通道和空间注意力,提升特征图的表示能力。
这个程序文件 conv.py 是一个用于实现各种卷积模块的 Python 脚本,主要用于深度学习中的卷积神经网络(CNN)。文件中使用了 PyTorch 框架,并定义了一系列的卷积层和相关的模块,以便于构建复杂的神经网络架构。
首先,文件中定义了一个名为 autopad 的函数,用于自动计算卷积操作所需的填充(padding)值,以确保输出的形状与输入的形状相同。这个函数考虑了卷积核的大小、填充和扩张(dilation)等参数。
接下来,定义了多个卷积类。其中 Conv 类实现了标准的卷积操作,包含卷积层、批归一化层(Batch Normalization)和激活函数。构造函数中可以设置输入通道数、输出通道数、卷积核大小、步幅、填充、分组卷积和扩张等参数。forward 方法定义了前向传播的过程,依次进行卷积、批归一化和激活操作。
Conv2 类是 Conv 类的简化版本,增加了一个 1x1 的卷积层,以便在前向传播时进行特征融合。它还提供了 fuse_convs 方法,用于将并行的卷积操作融合为一个卷积操作,以提高计算效率。
LightConv 类实现了一种轻量级卷积,包含两个卷积层,其中一个是深度卷积(Depth-wise Convolution),用于减少参数量和计算量。
DWConv 类实现了深度卷积,适用于输入和输出通道数相同的情况。DSConv 类则实现了深度可分离卷积(Depthwise Separable Convolution),由深度卷积和逐点卷积(Pointwise Convolution)组成。
DWConvTranspose2d 类是深度转置卷积的实现,ConvTranspose 类则实现了转置卷积层,支持批归一化和激活函数。
Focus 类用于将空间信息聚焦到通道维度,GhostConv 类实现了 Ghost 卷积,旨在通过主卷积和廉价操作实现高效特征学习。
RepConv 类实现了一种重复卷积结构,支持训练和推理阶段的不同操作,能够在推理时将多个卷积层融合为一个卷积层,以提高推理速度。
文件中还定义了几个注意力机制模块,包括 ChannelAttention 和 SpatialAttention,它们用于增强特征表示能力。CBAM 类则结合了通道注意力和空间注意力,形成了一个完整的卷积块注意力模块。
最后,Concat 类用于在指定维度上连接多个张量,便于在网络中处理不同来源的特征。
总体来说,这个文件提供了一系列灵活且高效的卷积层和模块,适用于构建现代深度学习模型,尤其是在目标检测和图像处理等任务中。
10.4 predict.py
以下是经过简化和注释的核心代码部分:
导入必要的模块
from ultralytics.engine.predictor import BasePredictor
from ultralytics.engine.results import Results
from ultralytics.utils import ops
class DetectionPredictor(BasePredictor):
“”"
DetectionPredictor类,继承自BasePredictor类,用于基于检测模型进行预测。
“”"
def postprocess(self, preds, img, orig_imgs):"""对预测结果进行后处理,并返回Results对象的列表。参数:preds: 模型的预测结果img: 输入图像orig_imgs: 原始图像列表或张量返回:results: 包含后处理结果的Results对象列表"""# 应用非极大值抑制(NMS)来过滤预测框preds = ops.non_max_suppression(preds,self.args.conf, # 置信度阈值self.args.iou, # IOU阈值agnostic=self.args.agnostic_nms, # 是否进行类别无关的NMSmax_det=self.args.max_det, # 最大检测框数量classes=self.args.classes, # 需要检测的类别)# 如果输入的原始图像不是列表,则将其转换为numpy数组if not isinstance(orig_imgs, list):orig_imgs = ops.convert_torch2numpy_batch(orig_imgs)results = [] # 初始化结果列表for i, pred in enumerate(preds):orig_img = orig_imgs[i] # 获取对应的原始图像# 将预测框的坐标缩放到原始图像的尺寸pred[:, :4] = ops.scale_boxes(img.shape[2:], pred[:, :4], orig_img.shape)img_path = self.batch[0][i] # 获取图像路径# 创建Results对象并添加到结果列表results.append(Results(orig_img, path=img_path, names=self.model.names, boxes=pred))return results # 返回后处理的结果列表
代码说明:
导入模块:引入必要的类和函数,以便进行预测和处理结果。
DetectionPredictor类:该类用于基于YOLO模型进行目标检测的预测,继承自BasePredictor。
postprocess方法:该方法负责对模型的预测结果进行后处理,包括应用非极大值抑制(NMS)和缩放预测框。
非极大值抑制:用于过滤掉重叠度高的预测框,保留最有可能的框。
坐标缩放:将预测框的坐标从网络输出的尺寸转换为原始图像的尺寸。
结果存储:将处理后的结果存储在Results对象中,并返回一个包含所有结果的列表。
这个程序文件 predict.py 是一个用于目标检测的预测模块,基于 Ultralytics YOLO(You Only Look Once)模型。文件中定义了一个名为 DetectionPredictor 的类,它继承自 BasePredictor 类,专门用于处理基于检测模型的预测任务。
在类的文档字符串中,提供了一个使用示例,展示了如何创建 DetectionPredictor 的实例并调用其 predict_cli 方法进行预测。示例中使用了一个名为 yolov8n.pt 的模型文件和一个名为 ASSETS 的数据源。
DetectionPredictor 类中包含一个名为 postprocess 的方法,该方法负责对模型的预测结果进行后处理。具体来说,后处理步骤包括:
非极大值抑制(Non-Maximum Suppression, NMS):通过调用 ops.non_max_suppression 函数,使用指定的置信度阈值、IoU(Intersection over Union)阈值以及其他参数,对预测结果进行筛选,以消除冗余的检测框。
图像格式转换:如果输入的原始图像不是列表格式(即它是一个 torch.Tensor),则调用 ops.convert_torch2numpy_batch 函数将其转换为 NumPy 数组格式,以便后续处理。
结果构建:对于每个预测结果,首先获取对应的原始图像,然后通过 ops.scale_boxes 函数将预测框的坐标缩放到原始图像的尺寸。接着,构建一个 Results 对象,包含原始图像、图像路径、模型的类别名称以及预测框信息,并将其添加到结果列表中。
最后,postprocess 方法返回一个包含所有处理后结果的列表。这些结果可以用于后续的可视化或分析工作。
总体而言,这个文件实现了一个目标检测的预测流程,能够对输入图像进行处理并返回检测结果,便于用户在实际应用中使用 YOLO 模型进行目标检测任务。
源码文件
源码获取
欢迎大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻