论文阅读---CARLA:用于时间序列异常检测的自监督对比表示学习方法
来源
【论文标题】
CARLA: Self-supervised contrastive representation learning for time series anomaly detection
CARLA:用于时间序列异常检测的自监督对比表示学习方法
【论文地址】
https://www.sciencedirect.com/science/article/pii/S0031320324006253
【论文源码】
https://github.com/zamanzadeh/CARLA
【期刊名称】
Pattern Recognition
【期刊等级】
中科院一区

简介
时间序列异常检测(TSAD)的核心挑战是真实场景中缺乏带标签数据,现有无监督方法因正常边界定义过严,易导致假阳性率高、泛化能力有限。为解决此问题,研究提出端到端自监督对比表示学习方法CARLA:针对现有对比学习“增强窗口为正样本、远时序窗口为负样本”的假设局限,及照搬图像分析技术的迁移问题,CARLA利用时间序列异常通用知识,注入多种异常作为负样本,既学正常行为,也学异常偏离模式——为时间相近窗口生成相似特征,为异常窗口生成独特特征,还借自监督邻域信息(按最近邻/最远邻分类)提升性能。在7个主流真实TSAD数据集上的实验显示,无论单变量(UTS)还是多变量(MTS)时间序列,CARLA的F1分数和AUPR均优于当前最先进的自监督、半监督及无监督TSAD方法,凸显对比表示学习推动TSAD领域发展的潜力
研究背景
【问题】
(1)标记数据匮乏:真实场景中带标签的数据稀缺,模型难以学习正常行为与异常行为的差异。
(2)正常边界定义过严:现有方法对 “正常边界” 定义往往过于严格,轻微数据偏离易被判定为异常,导致假阳性率高。
(3)对比学习假设局限:现有时间序列异常检测的对比学习方法,假设 “增强的时间序列窗口为正样本、时间上疏远的窗口为负样本”,但该假设不成立(增强可能将正常样本转为负样本,时间疏远的窗口也可能为正常样本),易导致检测性能不佳。
(4)方法迁移性差:现有对比学习方法直接照搬图像、自然语言处理等领域的技术,未适配时间序列的时序特性,正常与异常数据在表示空间易相互交织,且异常检测率提升时常伴随假阳性率增加。
【解决方案】
(1)提出一种用于时间序列异常检测的新型对比表示学习模型,该模型在涵盖单变量(UTS)和多变量(MTS)时间序列的各类真实世界基准数据集上均取得顶尖性能;针对带标签数据稀缺的挑战,能在特征表示空间中有效区分正常与异常模式,且模型实现代码已公开。
(2)提出一种有效的时间序列异常检测(TSAD)对比方法,通过利用时间序列异常的通用知识,为预训练(pretext)任务学习特征表示。
(3)提出一种自监督分类方法,利用预训练阶段学习到的表示对时间序列窗口进行分类,目标是借助预训练表示空间中的邻居来对每个样本分类。
(4)在七个真实世界基准数据集上的全面分析表明,与十种最先进的无监督、半监督和自监督对比学习方法相比,所提方法(CARLA)性能更优;且该方法能在各类多变量(MTS)和单变量(UTS)数据集的假阳性率(FPR)与精确率 - 召回率曲线下面积(AU - PR)之间保持一致平衡,为实际应用提供可靠且精准的警报。
论文方法
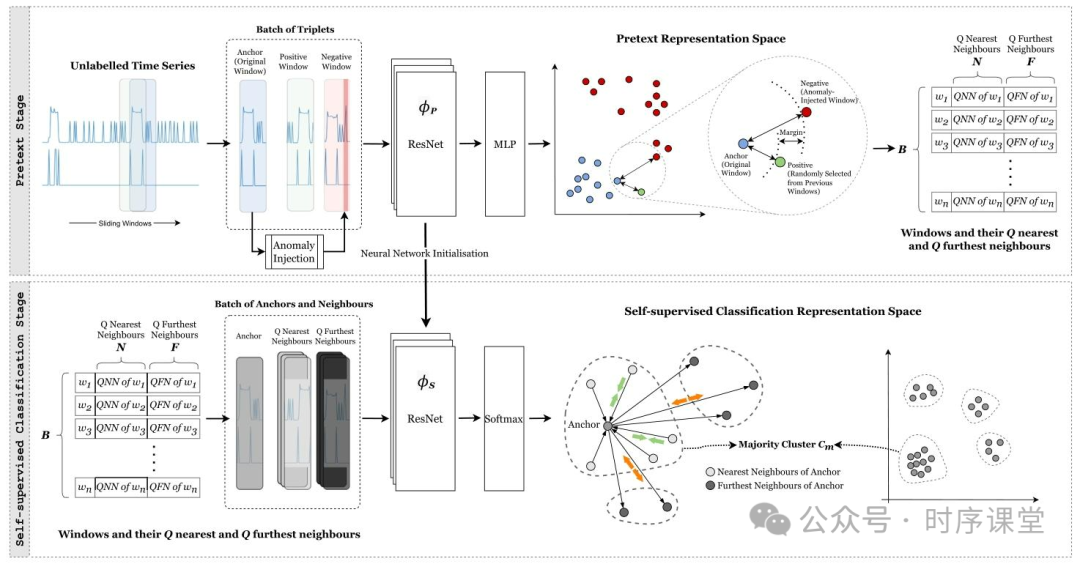
CARLA(一种用于时间序列异常检测的自监督对比表示学习方法)由若干关键组件构成,每个组件在实现高效表示学习方面都发挥着关键作用,如图所示。CARLA 包含两个主要阶段:Pretext 阶段和自监督分类阶段。
【Pretext 阶段】
在 Pretext 阶段,它采用异常注入技术,为时间上邻近的窗口学习相似表示,并为这些窗口及其对应的异常窗口学习相异表示。注入的异常包括点异常(如突发尖峰)和子序列异常(如意外的模式偏移)。这种技术不仅有助于训练模型识别 “与正常模式的偏差”,还能增强模型在各类异常类型之间的泛化能力。在 Pretext 阶段末尾,我们通过为每个窗口表示寻找最近邻和最远邻来建立先验,这为下一阶段奠定基础。
【自监督分类阶段】
在自监督分类阶段,基于 “表示空间中邻居的接近程度”,将窗口分类为正常或异常。这种分类旨在将相似的时间序列窗口归为一组,同时把它们与差异大的窗口明确区分。该阶段对于精准区分时间序列窗口、增强 CARLA 对不同模式的分类能力至关重要。
实验结果
【核心对比实验】
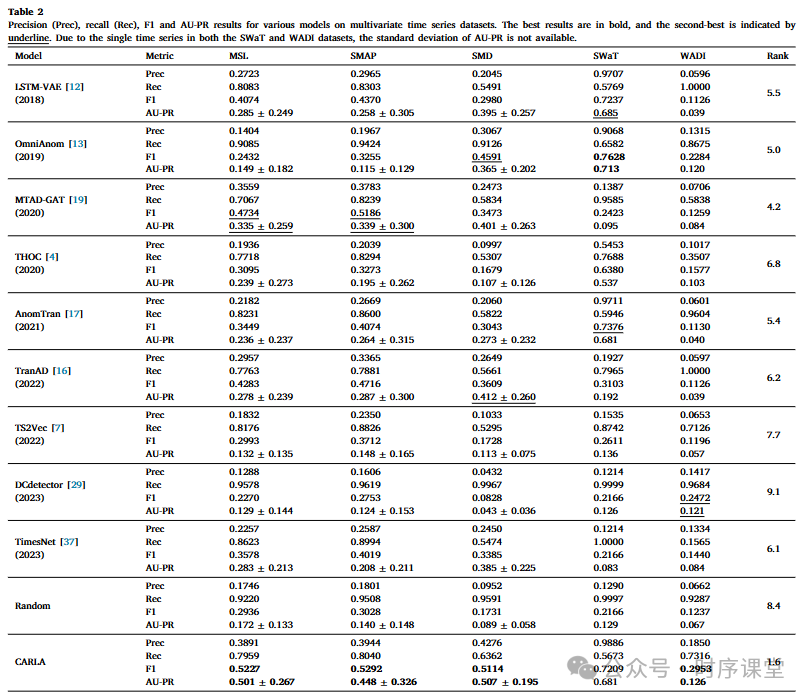
在 7 个真实世界时间序列异常检测(TSAD)数据集上,与 10 种主流 SOTA 方法(涵盖半监督、无监督、自监督等类型)对比,验证 CARLA 的整体性能(以 F1 分数、AU-PR 等为核心指标)。
【消融研究实验】
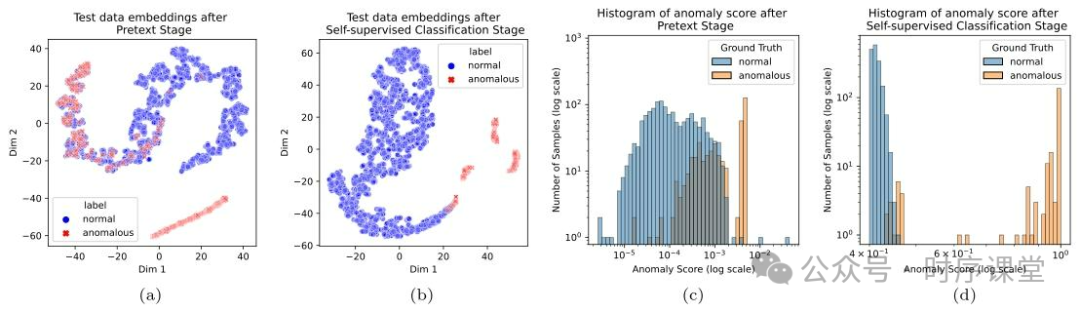
验证 CARLA 两阶段框架的必要性、不同异常注入类型对性能的影响,以及复合损失函数各组件的作用。
【参数敏感性实验】
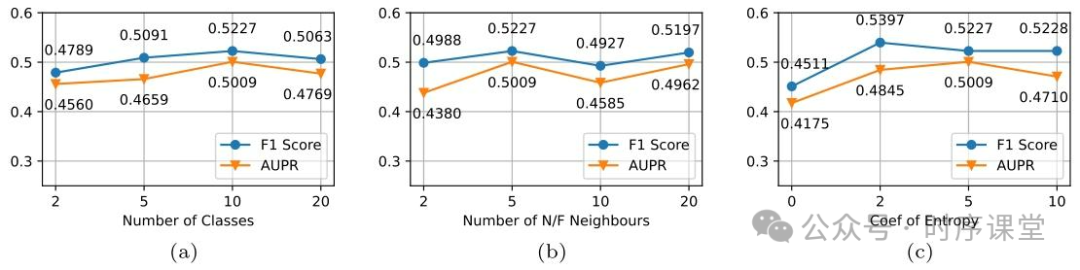
分析窗口大小、类别数、邻居数、熵系数等关键超参数对 CARLA 性能的影响,确定最优参数配置。

总结
本文提出CARLA自监督对比表示学习方法用于时间序列异常检测,解决标签缺乏、假阳性高等问题。通过两阶段框架:先异常注入构建样本对,结合ResNet与三元组损失学表示;再利用邻居信息,通过复合损失优化分类。在7个真实数据集上,其F1分数、AU-PR指标显著优于10种主流方法,且假阳性率低,验证了在该领域的优越性。