开源项目重构我们应该怎么做-以 SQL 血缘系统开源项目为例
在技术人的世界里,“写代码”是起点,但“重构代码”才是成长的开始。 写一个能跑起来的项目并不难,尤其在开源社区里,快速验证想法、实现功能是最常见的节奏。但当项目逐渐成型、功能越来越多、用户越来越多时,你会突然发现:它开始变慢了、变乱了、变得难以维护。那一刻,重构的信号就响了。这次我选择重构的,是一个我自己曾经开源出去的项目——SQL 血缘解析系统。 这个系统的核心目标其实很简单:从 SQL 语句中提取表、字段之间的依赖关系,并以可视化的方式呈现出“数据的流向”。
比如你有一个复杂的分析 SQL,它可能跨了十几张表、嵌套了多层子查询,还包含各种字段别名与派生计算(如 毛利率 = gross_profit_rate_max / 100)。如果没有血缘分析,你根本无法一眼看清这条 SQL 在“用谁的字段、产出什么结果”。最初我写的版本能跑,但非常“野生”。解析逻辑混在一起,模型定义含糊不清,可视化部分更是硬编码写死。那时的它更像是一辆能跑的三轮车:虽然能动,但一碰到复杂 SQL 就摇摇晃晃。
我开始意识到,这不再是一个简单脚本的问题,而是一个需要工程化思维去打磨的系统。
于是,这篇文章诞生了。从思考项目架构,到重新定义核心抽象;从修复语法解析,到让数据血缘“看得见”;再到如何让可视化真正服务于分析。我们将从这个 SQL 血缘系统出发,重新思考一个老问题:
当一个开源项目功能越来越复杂时,我们究竟该如何用重构,让它从“能跑”变成“能用、能扩展、能长期演化”?
从“能跑”到“能维护”:为什么我们必须重构
在一个项目的早期阶段,开发者最常说的一句话是:“先跑起来再说。” 这是合理的——原型阶段的核心目标就是验证思路、确认方向。但当“能跑”变成“上线后也就这样跑了”,问题就悄然埋下了。
SQL 血缘系统最初的版本,其实就是这样一个“快速迭代出来的产物”。 那时候,我的想法很简单:给定一段 SQL,我能不能快速看出它依赖了哪些表、生成了哪些字段? 于是我在一个文件里写完了解析、抽取、可视化,甚至连输出逻辑都混在一起。代码能跑,也能给出结果——看似一切正常。
直到有一天,我用它解析了一条真正复杂的 SQL。那条语句有三层子查询,十几张表,外加多个别名与 CASE WHEN 派生字段。
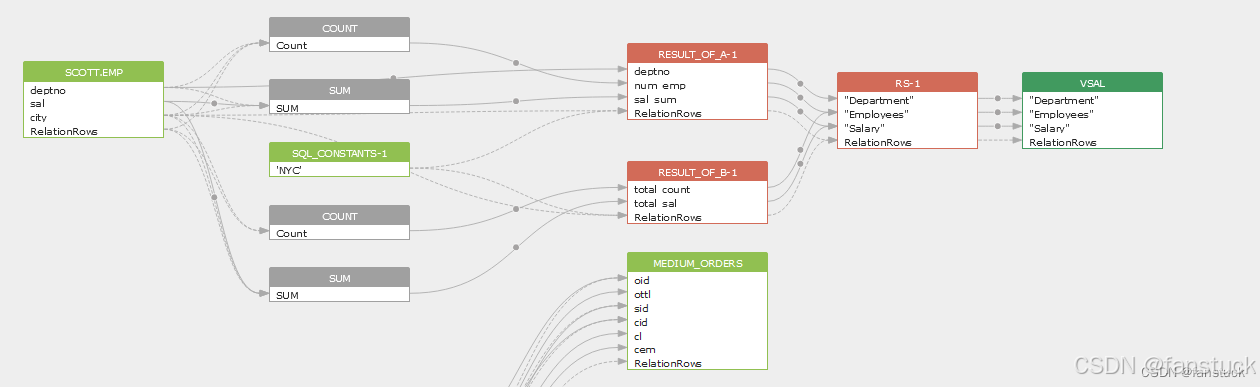
我运行程序,结果画面一片混乱:字段重复、表关系错误、可视化图上甚至有环状链接(自己连自己)。血缘解析其实是一个“结构化重建”的过程。
解析逻辑失控
SQL 看似是字符串,但本质上它是一棵语法树(AST,Abstract Syntax Tree)。 而原版的逻辑,是直接用正则去拆字符串。
举个简单的例子:
SELECT a.product_name, b.price FROM sales a JOIN product b ON a.pid = b.id
用正则去拆,看似没问题。但当 SQL 变成:
SELECT CASE WHEN t.sales > 100 THEN '优质' ELSE '普通' END AS tagFROM (SELECT a.*, b.category FROM sales a JOIN product b ON a.pid = b.id) t
整个结构就崩了。嵌套子查询、别名、计算表达式、函数调用——这些复杂语义根本不是正则能“猜”的。
模型结构混乱
第二个问题出在数据结构。 原始代码里,所有的表名、字段名、映射关系都放在几个 list 和 dict 里,临时维护、临时追加。
一开始这样做确实快,但后面当我想增加一个“列到列血缘”功能时,发现完全无从下手。 因为项目里根本没有明确区分:
表级血缘(Table Lineage);
字段级血缘(Column Lineage);
派生字段(Derived Column Lineage)。
于是我开始拆分模型,把它重新抽象为:
StatementLineage(op='SELECT',source_tables=[...],target_tables=[...],columns_by_table={...},column_lineage={...})这样的设计看似多此一举,但意义重大—— 它让系统不再依赖“运行时变量”,而是有了语义层的数据模型。 就像建房子从“砖堆”变成了“结构体”,从此每块砖都有名字、有坐标、有用途。
可视化问题
我最初做的可视化,确实能画图,但也仅此而已。 表和字段全都挤在一起,没有区分层次,也没有颜色分类。对于数据工程师来说,这样的可视化没法真正“用”,只能“看着好看”。
一个真正有用的血缘可视化,应该让人能一眼看出:
数据流从哪里来;
中间经过了哪些转换;
最终输出到了哪里;
哪些字段是原始的,哪些是派生的。
这意味着不仅要画图,还要有语义层的支撑。
而这正是我决定全面重构的原因—— 因为我不想再做一个“能跑”的工具,我想做一个能被信任的系统。
架构重构
如果说前一阶段我们是在发现“哪里出了问题”,那么这一阶段,就是要让系统重新获得“呼吸的空间”。 很多人以为重构就是改代码,但其实更像是“给老屋打地基”—— 你要在不推翻整栋房子的前提下,重新让承重结构变得清晰、坚固、可扩展。
当我着手重构 SQL 血缘系统时,最先要面对的问题是:到底应该以什么为中心来设计整个系统?
在旧版项目里,一切都围绕“功能”展开。 有个功能叫“提取表名”,就写个 extract_tables(); 要提取字段,就写个 extract_columns(); 最后所有函数都堆在一起,靠参数传来传去。
但在血缘系统里,这种“过程式”思维很快会遇到天花板。因为血缘关系不是孤立的函数输出,而是一个层层嵌套、彼此关联的数据网络。 于是我开始从“数据结构驱动架构”的角度出发,重新梳理了整个项目。
核心层(Core):定义结构,而非功能
我首先建立了一个独立的核心层:core/。 它不直接处理可视化、不负责命令行输出,只专注于两件事:
把 SQL 拆解成结构化的信息;
用统一的数据模型(Model)表达这种结构。
在 models.py 中,我定义了一个最重要的类:StatementLineage。 它就像系统的“语言中枢”,描述了一条 SQL 的全部逻辑关系:
StatementLineage(op='SELECT',source_tables=[...],target_tables=[...],columns_by_table={...},column_lineage={...})这段代码看起来平平无奇,但它相当于整个系统的心脏。 它定义了数据的组织方式,也定义了“血缘关系”这一概念在程序中的语义。
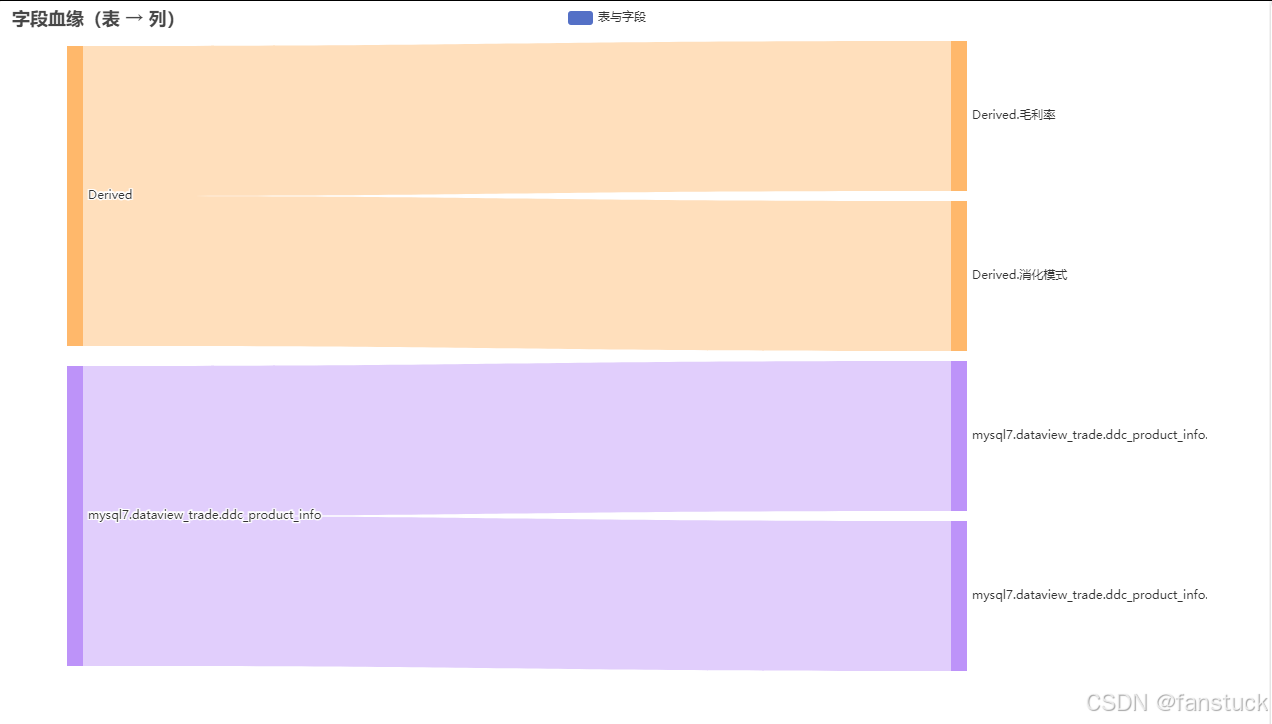
举个例子,source_tables 就是所有参与计算的输入表; target_tables 则代表 SQL 的输出表(如 INSERT INTO 或 CREATE TABLE AS 语句); 而 column_lineage 是最有价值的部分,它记录了列与列之间的映射关系,例如:
{"mysql7.dataview_trade.ddc_product_info.gross_profit_rate_max": ["毛利率"],"mysql7.dataview_trade.ddc_product_info.business_type": ["消化模式"]}换句话说,系统不仅知道“用了哪些表”,还知道“哪个字段计算出了哪个结果”。 这一点在企业级数据治理、字段追溯(Field Lineage)场景中尤其关键。
解析层(Extractor):像语言学家一样理解 SQL
接下来是 extractor.py。这是系统里最“聪明”的部分。旧版的逻辑是靠正则匹配,而现在我让它真正“理解” SQL。
我使用了 sqlparse 这个优秀的开源库,通过 AST(抽象语法树)的方式递归分析 SQL 语句。 每一个 SELECT、JOIN、FROM、ON 都会被识别为一个语法节点(TokenList),程序会逐层遍历、判断、映射。
举个例子,当程序看到:
LEFT JOIN mysql7.dataview_trade.ddc_product_info b ON a.product_id = b.product_id
它会这样思考:
识别出 JOIN 关键字;
提取出关联表名
mysql7.dataview_trade.ddc_product_info;同时捕获别名
b;在后续解析字段时,遇到
b.product_name,能自动映射回这个表。
于是,像下面这样的 SQL:
SELECT b.product_name, b.gross_profit_rate_max / 100 AS 毛利率
系统就能自动生成血缘映射:
mysql7.dataview_trade.ddc_product_info.gross_profit_rate_max → 毛利率
这就是让机器“读懂 SQL”的力量。它不再只是字符串拼接,而是能推导出数据依赖的真正路径。
可视化层(Viz):让数据关系“看得见”
当数据结构清晰了,可视化层就成了水到渠成的事。 我在 viz/ 目录下设计了三种图形:
Tree:展示表级血缘(谁依赖谁);Sankey:展示表与字段之间的映射;Col2Col Sankey:展示列与列之间的派生关系。
这三个可视化就像是不同“分辨率”的视图—— Tree 看整体结构,Sankey 看细节流向,Col2Col 则看计算链条。
更重要的是,我在可视化层引入了语义色彩:
Hive 表(绿色):代表数据仓库源;
MySQL 表(蓝色):代表业务系统源;
Derived 字段(橙色):代表计算生成列。
这样一来,一张复杂的 SQL 关系图瞬间就“活”了。你能一眼看到哪些字段是直接来源、哪些是中间计算结果,哪些又是最终产出。在实际的数据治理场景中,这种“直观性”比任何报告都更有说服力。因为它不需要解释,数据自己在说话。
接口层(CLI):从工具到平台
最后,我加入了命令行入口(cli/main.py),让整个系统变得可调用、可配置。
python -m cli.main examples/demo.sql --viz all --outdir out --topn 30
这一条命令就能:
自动解析 SQL;
生成所有三种可视化;
输出为 HTML 文件;
并支持自定义输出目录和节点数量。
这意味着——这个系统不再是一个“脚本”,而是一个“平台”。 任何人都可以用它来审查自己的 SQL,或者嵌入到数据治理管道里。
到这里,我们完成了从“结构混乱”到“架构清晰”的核心重构。系统终于有了清晰的职责边界、统一的数据模型、可扩展的表现层。它不再是一个“能跑的项目”,而是一个“能进化的系统”。
可视化重构
当系统的底层逻辑重构完毕后,我面临的下一个问题是—— 数据血缘虽已清晰,但人看不懂。
是的,机器能告诉我:
"mysql7.dataview_trade.ddc_product_info.gross_profit_rate_max" → "毛利率"
但对于一个数据分析师来说,这种结构化文本并不友好。他们希望看到的是:数据从哪张表、哪一列流向了最终报表字段,整个过程能一眼看清。答案就是——可视化重构。
最初版本的可视化其实能画图,但不“讲故事”。 所有节点都在同一层级,线条杂乱,颜色也单调。 对于复杂 SQL 来说,这种图形只会让人更迷惑。
于是我重新设计了可视化逻辑,让每个节点都有“语义”:
表节点(蓝/绿):数据来源;
字段节点(橙/灰):具体指标;
派生字段节点(红):由计算生成的结果。
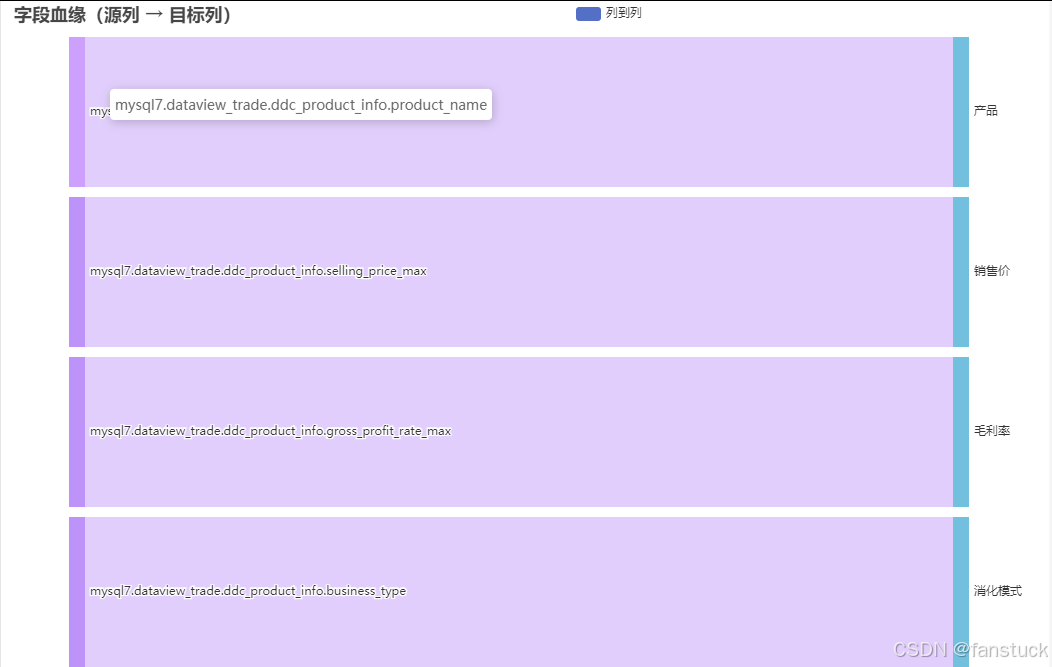
重构后的 sankey.py,不再只是把“表和列连起来”,而是让数据的流动路径具象化。
比如:
SELECTb.product_name AS 产品,b.selling_price_max AS 销售价,b.gross_profit_rate_max / 100 AS 毛利率FROMmysql7.dataview_trade.ddc_product_info b
生成的桑基图是这样的逻辑结构:
mysql7.dataview_trade.ddc_product_info│├── product_name → 产品├── selling_price_max → 销售价└── gross_profit_rate_max → 毛利率
每一条线代表一次“血缘传递”,每一个颜色代表数据来源。 蓝线来自 MySQL 业务表,绿线来自 Hive 数据仓库,橙线代表派生计算字段。
而且我还引入了“流量权重”概念—— 如果一个字段被多个派生指标使用,连线就会更粗,代表该字段在 SQL 中的重要程度。 这种视觉强化,让血缘图不只是“好看”,而是“有用”。
有了桑基图,我们可以看到字段之间的流向; 但对于整个 SQL 的结构,桑基图却不够“分层”。
于是我又重构了 tree.py,让它能像思维导图一样展示表级血缘。
现在的树状结构会根据 SQL 的嵌套逻辑自动分层,比如:
SELECT ...FROM (SELECT ...FROM hive.bdc_dwd.dw_mk_order aJOIN mysql7.dataview_trade.mk_order_merchant b) tJOIN mysql7.dataview_trade.ddc_product_info c
树状图会显示为:
SELECT├── hive.bdc_dwd.dw_mk_order│ ├── 子查询 1│ └── mysql7.dataview_trade.mk_order_merchant└── mysql7.dataview_trade.ddc_product_info
不同的节点颜色代表不同的数据层:
Hive 表:绿色(数据仓库源);
MySQL 表:蓝色(业务系统源);
Derived 子查询:橙色(逻辑中间层)。
这样一来,SQL 的层次结构就像一棵数据树,一目了然。 当你鼠标悬停时,还能显示表的别名、来源系统、甚至所在业务域。
到这里,表级和字段级的关系都已经可视化。 但在实际业务分析中,我们最想知道的,往往是“指标是怎么计算出来的”。
比如你在报表中看到“毛利率”这一列,你可能想追问:
它到底从哪来的? 是原始字段,还是由多个字段计算而来?
于是我引入了“列到列血缘(Column-to-Column Lineage)”。
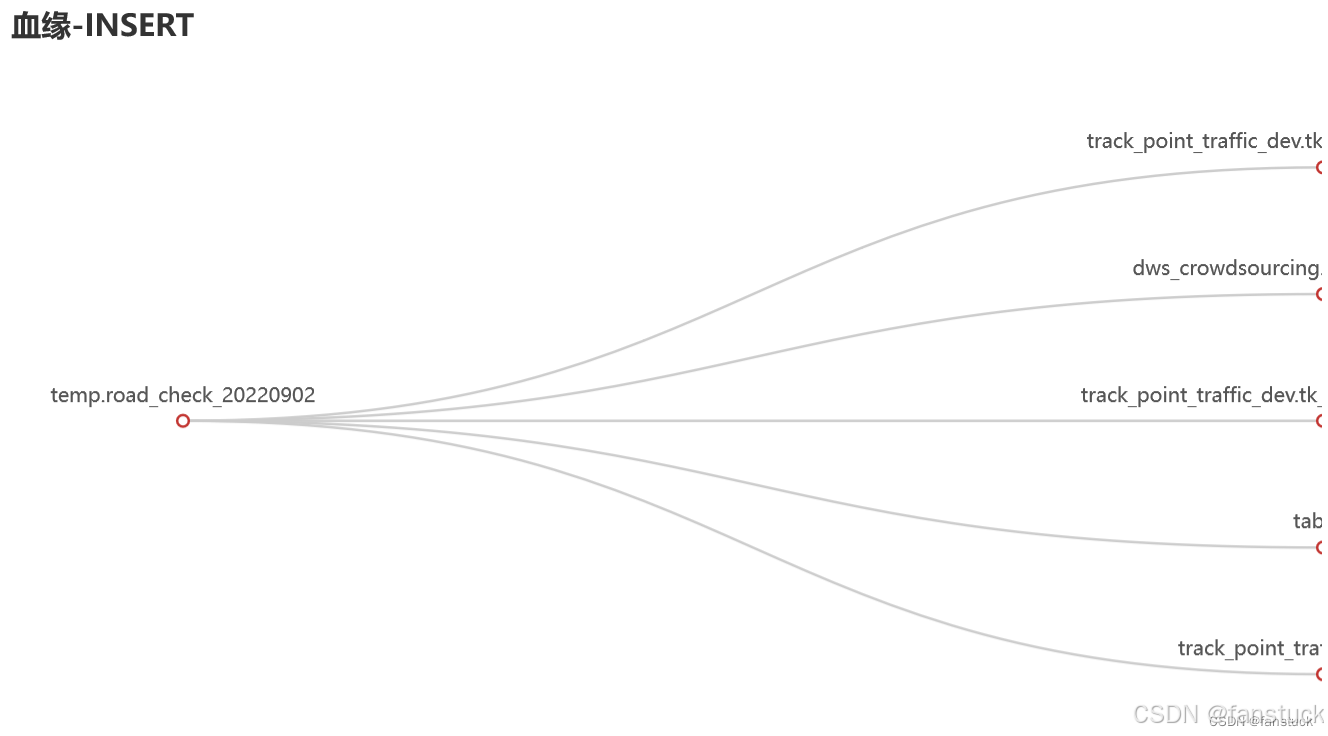
在新的可视化层中,我加入了第三种图表:col2col_sankey.py。 它不再展示表与字段,而是展示字段之间的计算依赖链。
举个例子:
SELECTb.gross_profit_rate_max / 100 AS 毛利率
在可视化图上,它会画出:
gross_profit_rate_max│▼毛利率
如果字段是多源计算,比如:
SELECT (a.income - b.cost) / a.income AS 利润率
那么血缘链会变成分叉结构:
a.income ─┬──► 利润率b.cost ───┘
这让“指标口径追溯”成为可能。 在 BI 场景或数仓治理中,这一功能能直接帮助分析师快速定位指标计算逻辑,避免口径不一致的风险。
当图形可读、可分层后,我做的最后一步优化是“交互化”。 在新版系统中,每个节点都支持点击—— 点击表节点会高亮关联字段,点击字段节点会反向追溯源表。
这意味着你可以在一张图上,完成从“表 → 字段 → 指标”的全链路溯源。 它不再只是一个静态图,而是一种交互式“可视化 IDE”。
有趣的是,我把这一功能移植到了浏览器端后,发现它其实非常适合企业内部系统集成。 例如,在一个招标数据分析平台中,你可以:
点击“投标金额”字段,就能看到它来源于哪张项目表;
点击“评分指标”,就能看到它由哪些中间字段计算而来;
甚至能导出这一整条血缘路径,作为合规审计报告的一部分。
过去,我们追求的是“让图画出来”; 而现在,我们追求的是“让图说明问题”。
一个好的血缘可视化,不仅是展示,更是洞察。 它能让我们发现:
哪些字段是“高频依赖点”,是系统中的关键指标;
哪些表是“单点来源”,可能带来数据风险;
哪些计算逻辑冗余,可以被优化或复用。
当血缘不再只是“技术结果”,而成为“数据资产的镜像”, 那一刻,我们才真正完成了从工具到系统的蜕变。
落地与启示:开源项目重构的通用方法论
当我完成整个 SQL 血缘系统的重构,再次打开那张干净、层次分明、能交互的可视化图时,我其实有点感慨。 这不仅仅是一次“代码重写”,更像是一次从“工具意识”到“系统意识”的跃迁。
过去我追求的是功能能实现, 现在我追求的是系统能成长。
这次重构让我对“开源项目该如何进化”有了更深的理解——不仅仅是技术的事情,更是一种思维方式的转变。
很多人不敢重构的第一个原因,是害怕承认问题。 但事实上,一个项目如果经过半年都没有出现问题,那只说明一个事实:
它要么没人用,要么没人改。
SQL 血缘系统的问题并不在于“写得不好”,而在于“它被新的场景逼得不够好”。
当系统需要解析多层子查询、跨库表、计算字段、甚至嵌套函数时, 过去那些“能跑”的逻辑就不够用了。
重构的起点,不是完美的设计,而是勇敢地面对复杂性。
正如 Martin Fowler 在《重构》一书中提到的那句经典:
“重构的前提,是承认代码永远不会一开始就完美。”