论文笔记:π0.5 (PI 0.5)KI改进版
Knowledge Insulating Vision-Language-Action Models: Train Fast, Run Fast, Generalize Bette
Pi0.5论文:https://www.physicalintelligence.company/download/pi05.pdf
pi0论文:https://arxiv.org/abs/2410.24164
代码:https://github.com/Physical-Intelligence/openpi
知识隔离(knowledge insulation)
解决问题:依赖来自连续适配器(如扩散头)的梯度作为训练信号,会削弱模型解析语言指令的能力,并导致最终生成的视觉语言动作(VLA)策略的整体性能下降。
知识隔离的核心思想在于:在通过离散化动作对视觉语言模型主干进行微调的同时,适配一个能够生成连续动作的行动专家模块(例如通过流匹配或扩散方法实现),并阻止该模块的梯度回传至视觉语言模型主干。
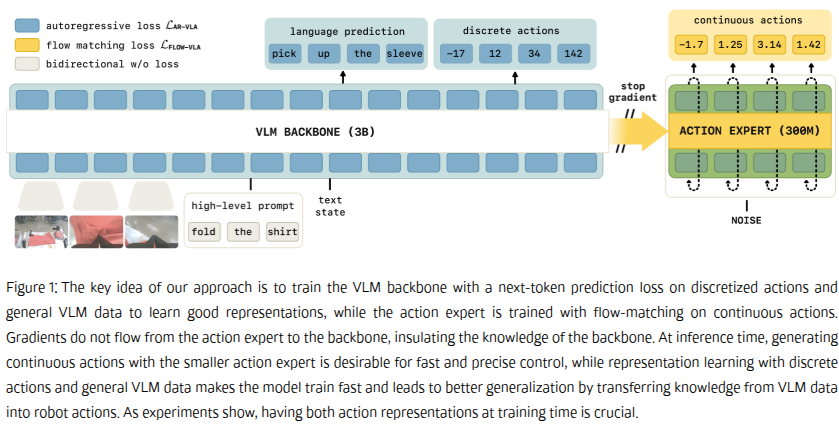
离散动作令牌提供了一种不受行动专家未初始化权重影响的替代学习信号,这使得视觉语言模型能够学习适用于机器人控制的表征,同时又避免了来自行动专家的梯度可能造成的干扰。
知识隔离的优势:
1.采用next-token预测机制使模型能够以更快速度和更高稳定性进行学习;
2.行动专家模块的引入仍能保证高效的推理速度;
3.方案实现了在通用视觉语言数据上的协同训练,从而将视觉语言行动模型的优势重新注入到我们的架构中。
简单的说就是训练的时候动作专家模块的训练梯度与VLM训练梯度隔离,上图中右边动作专家算法模块的梯度不回传给VLM。
相关工作
多模态大语言模型方面:
将图像、文本和语音数据在预测过程中进行交织处理,并将不同模态分配给专门的“专家”网络,使其通过交叉注意力机制相互关联,这种方式既能有效防止模态间的相互干扰,又能显著提升预测结果的质量。借助这样的架构,我们将机器人的动作作为一个单独的模态融合进到预训练VLM模型中。
视觉语言动作模型(VLAS)方面:
视觉-语言-动作模型的核心思想在于通过对预训练的视觉-语言模型进行微调,使其具备动作预测的能力。为实现视觉语言模型在动作数据上的微调,视觉语言动作训练流程通常会将连续动作映射为离散动作令牌序列。当前主流的实现方式主要包含两类技术路径:一是采用基于区间划分的离散化方法(Binning Discretization 区间离散化),二是运用基于压缩编码的令牌化技术(compression-based tokenization approaches)。这样就可以通过标准的自回归next-token预测进行VLA训练,尽管这样的策略在简单低频(<2Hz)控制的任务上表现出有效性,但是有两个明显的缺点,一是从连续到离散token的映射可能会信息损耗;二是自回归解码导致的推理延迟,将动作序列视为令牌序列进行自回归预测(即逐个生成令牌,每个新令牌的生成都依赖于之前生成的所有令牌),会引入显著的串行计算延迟。对于一个多自由度的机器人,其动作序列可能很长,这种逐令牌生成的方式无法利用现代硬件的并行计算能力,导致决策频率降低,难以满足高频实时控制任务的需求。
快速、连续解码机制VLAs方面:
以 OpenVLA-OFT 和 π0.5 为代表的研究采用了一种两阶段训练范式,第一阶段离散化自回归训练,通过牺牲一定的推理速度和动作精度,换来了训练的稳定性和可行性;第二阶段在目标领域使用连续输出进行微调,将已具备基础能力的模型(如在离散动作空间预训练的模型)进一步调整,使其能直接输出精确的连续动作值(如速度、力矩等具体数值),从而在特定任务场景(即目标域)中实现更精准、平滑的控制。
π0、π0.5:
π0引入了一种连续动作专家模型,该模型能够学习动作序列段上的复杂连续分布,从而实现高效推理,并胜任诸如折叠衣物等需要精细连续控制的灵巧操作任务。π0方案本身会导致指令跟随能力下降和训练速度减慢,这是因为来自动作专家的梯度会损害预训练的视觉语言模型主干网络
π0-FAST通过采用分词化动作解决了这一问题,其使用的基于离散余弦变换的编码器能够实现对复杂动作序列的高效离散化。然而,正如我们实验所验证的,这种方案需要付出两大代价:既需要耗费大量计算资源的自回归推理,又会导致执行精细动态任务的能力下降。
π0.5模型首先使用FAST分词化动作进行初步训练,随后在后训练阶段引入随机初始化的动作专家模块,通过联合训练方式在移动操作数据上进行微调。
KI改进版研究对π0.5方案进行了系统化完善,并进一步开发出单阶段训练范式:在利用离散令牌使视觉语言模型主干适应机器人控制的同时,并行训练动作专家模块生成连续动作,实现了优势互补。通过系统性的消融实验验证了不同知识保留与协同训练机制的有效性,最终提出了首个同时具备快速训练、保持视觉语言知识体系、支持高频连续动作输出三大特性的视觉语言动作模型解决方案。
通过协同训练、联合训练与知识隔离提升视觉语言动作模型性能
提出的创新方法:
1.联合训练:通过联合训练方式,使模型同时学习自回归与流匹配两种动作预测目标。该模型利用(规模更小的)动作专家模块生成连续动作,以实现测试时的高速推理。自回归目标仅在训练阶段作为表征学习目标使用,该机制能显著提升模型的训练速度。
2.协同训练:通过在通用视觉语言数据与机器人规划数据等非动作数据集上的协同训练,确保模型在适配视觉语言动作模型时能最大程度保留其原有知识体系。
3.知识隔离:通过阻断动作专家模块与主干网络权重之间的梯度传播路径,我们在将预训练视觉语言模型适配为视觉语言动作模型时,可确保新初始化的动作专家权重不会干扰预训练权重的知识结构。
协同训练 & 联合离散/连续动作预测的表征学习:
协同训练的loss计算公式
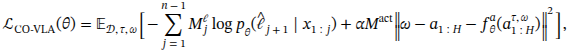
自回归部分的loss(应该是VLM部分)公式:
![]()
用作action预测的流匹配部分的loss计算公式:
![]()
协同训练的loss计算公式就是把自回归的和流匹配的加在一起。
α为损失乘数,用于权衡通过流匹配实现的动作预测损失与标准语言建模损失之间的关系
Mℓ为语言损失掩码(用于标识应在令牌流的哪些位置施加语言损失)
Mact是一个动作掩码指示符,用于规定在给定样本条件下是否应预测动作。
知识隔离&梯度控制
由于知识隔离机制,动作专家模块的梯度不能传送给VLM部分的backbone,所以专家模块的梯度仅在注意力层与VLM的梯度进行交互
因此修改了注意力层的算法为:
![]()
x 为注意力层的输入,Q、 K是注意力层的query 和key的投影向量,A 是掩码
Pbb来自视觉语言模型(VLM)主干的特征对主干特征的注意力概率
Pab动作专家特征对主干特征的注意力概率
Paa动作专家特征对其他动作专家特征的注意力概率
基于此,可以通过以下方式实现softmax计算,从而按需限制信息流:
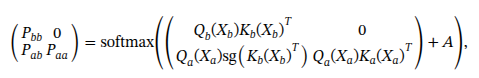
其中sg表示梯度截断操作符,用于阻断计算图中该部分的梯度回流。Xb对应所有通过主干网络权重处理的特征xi,Xa则表示通过动作专家权重处理的令牌。
随后通过以下公式计算值嵌入:
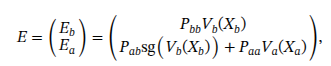
最终注意力是
attn(X)=PE
这一设计还有个额外优势:由于扩散损失项现在作用于独立的权重集,我们可以直接将公式中的α参数设为1。