DB-GPT实现Text2SQL全流程解析
摘要
本文深入解析DB-GPT中Text2SQL功能的完整实现机制,从用户输入自然语言查询到最终执行SQL并返回结果的全过程。通过详细的代码分析、流程图解和实际示例,展现了现代AI驱动的数据库查询系统的设计理念和工程实践。文章涵盖了智能表结构检索、精确提示词工程、安全SQL执行等核心技术,为开发者提供了构建类似系统的完整参考。
1. 引言
Text2SQL(自然语言转SQL)是人工智能在数据库查询领域的重要应用,它让非技术用户能够通过自然语言与数据库进行交互。DB-GPT作为领先的AI原生数据应用开发框架,实现了一套完整、高效、安全的Text2SQL解决方案。
1.1 技术背景
传统的数据库查询需要用户掌握SQL语法,这对非技术人员构成了很大的门槛。随着大语言模型技术的发展,Text2SQL技术逐渐成熟,能够将自然语言查询转换为准确的SQL语句。
1.2 DB-GPT的Text2SQL特色
- 智能表结构检索:基于向量相似度的精准表结构匹配
- 精确提示词工程:结构化约束确保SQL生成质量
- 安全执行机制:完善的SQL注入防护和权限控制
- 多数据库支持:统一抽象层支持多种数据库类型
- 实时性能监控:查询执行时间和资源使用监控
2. Text2SQL整体架构
2.1 分层架构设计
DB-GPT的Text2SQL采用了清晰的分层架构,每层负责特定的功能:
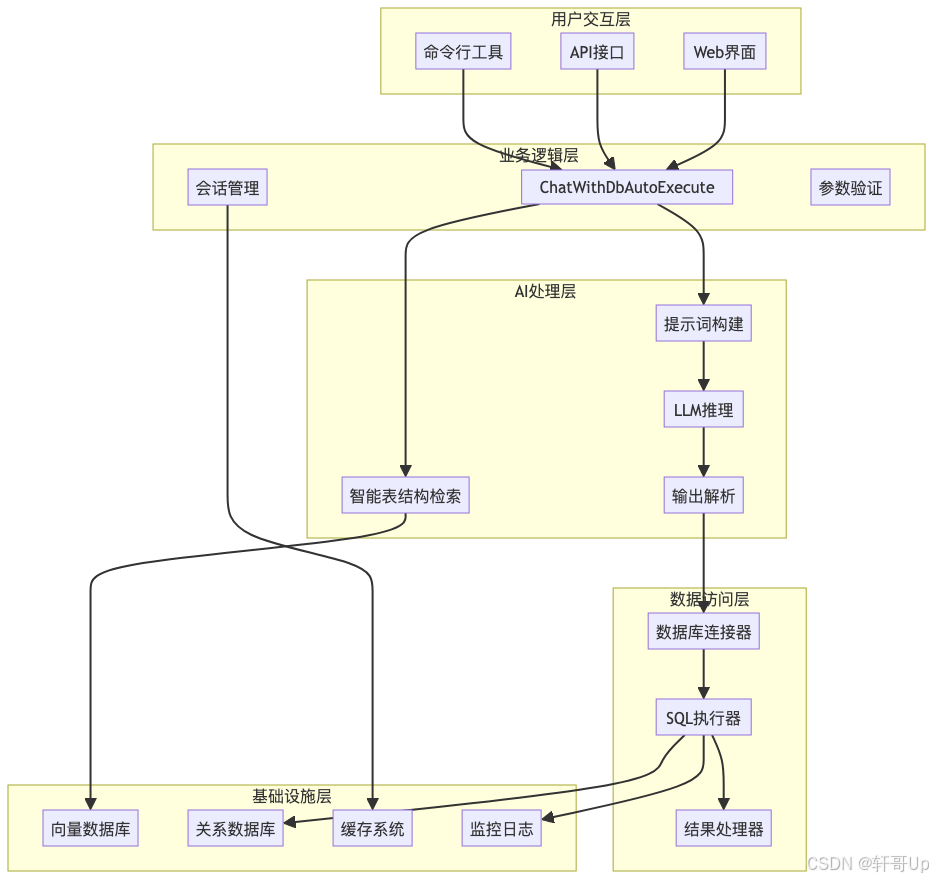
2.2 核心组件关系
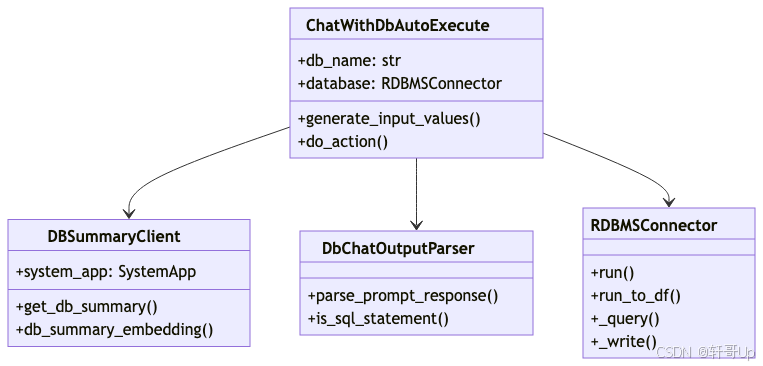
3. 核心组件深度解析
3.1 ChatWithDbAutoExecute - 核心控制器
文件路径: packages/dbgpt-app/src/dbgpt_app/scene/chat_db/auto_execute/chat.py
这是Text2SQL功能的核心控制器,负责整个流程的协调和管理。
class ChatWithDbAutoExecute(BaseChat):"""Text2SQL自动执行聊天场景"""chat_scene: str = ChatScene.ChatWithDbExecute.value()def __init__(self, chat_param: ChatParam, system_app: SystemApp):"""初始化Text2SQL执行器Args:chat_param: 聊天参数,包含数据库名称和用户输入system_app: 系统应用实例"""# 获取用户选择的数据库self.db_name = chat_param.select_paramself.curr_config = chat_param.real_app_config(ChatWithDBExecuteConfig)super().__init__(chat_param=chat_param, system_app=system_app)# 验证数据库选择if not self.db_name:raise ValueError(f"{ChatScene.ChatWithDbExecute.value} mode should chose db!")# 获取数据库连接器with root_tracer.start_span("ChatWithDbAutoExecute.get_connect"):local_db_manager = ConnectorManager.get_instance(self.system_app)self.database = local_db_manager.get_connector(self.db_name)# 初始化API调用工具self.api_call = ApiCall()核心功能分析:
- 数据库连接管理:通过ConnectorManager获取数据库连接器
- 配置管理:加载Text2SQL相关配置参数
- 会话管理:继承BaseChat的会话管理能力
- 错误处理:验证必要参数的存在性
3.2 智能表结构检索系统
文件路径: packages/dbgpt-serve/src/dbgpt_serve/datasource/service/db_summary_client.py
这是Text2SQL的核心创新点,通过向量检索技术智能匹配相关表结构。
class DBSummaryClient:"""数据库摘要客户端提供数据库表结构的向量化存储和智能检索功能"""def __init__(self, system_app: SystemApp):self.system_app = system_appself.app_config = self.system_app.config.configs.get("app_config")self.storage_config = self.app_config.rag.storagedef get_db_summary(self, dbname: str, query: str, topk: int) -> List[str]:"""获取与用户查询相关的表结构信息Args:dbname: 数据库名称query: 用户自然语言查询topk: 返回的相关表数量Returns:相关表结构信息列表"""from dbgpt_ext.rag.retriever.db_schema import DBSchemaRetriever# 获取向量存储连接器table_vector_connector, field_vector_connector = (self._get_vector_connector_by_db(dbname))# 创建数据库模式检索器retriever = DBSchemaRetriever(top_k=topk,table_vector_store_connector=table_vector_connector,field_vector_store_connector=field_vector_connector,separator="--table-field-separator--",)# 执行向量检索table_docs = retriever.retrieve(query)# 提取文档内容return [d.content for d in table_docs]智能检索流程:
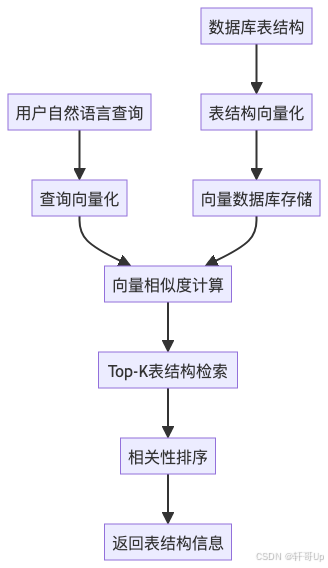
3.3 提示词工程系统
文件路径: packages/dbgpt-app/src/dbgpt_app/scene/chat_db/auto_execute/prompt.py
精心设计的提示词模板是确保SQL生成质量的关键。
# 中文提示词模板
_DEFAULT_TEMPLATE_ZH = """
请根据用户选择的数据库和该库的部分可用表结构定义来回答用户问题.数据库名:{db_name}表结构定义:{table_info}约束条件:1. 请根据用户问题理解用户意图,使用给出表结构定义创建一个语法正确的{dialect} sql2. 除非用户在问题中指定了他希望获得的具体数据行数,否则始终将查询限制为最多{top_k} 个结果3. 只能使用表结构信息中提供的表来生成 sql,如果无法根据提供的表结构中生成 sql,请说:"提供的表结构信息不足以生成 sql 查询。"4. 请注意生成SQL时不要弄错表和列的关系5. 请检查SQL的正确性,并保证正确的情况下优化查询性能6. 请从如下给出的展示方式种选择最优的一种用以进行数据渲染: {display_type}用户问题:{user_input}请一步步思考并按照以下JSON格式回复:{response}确保返回正确的json并且可以被Python json.loads方法解析.
"""# 响应格式定义
RESPONSE_FORMAT_SIMPLE = {"thoughts": "思考过程摘要","direct_response": "如果上下文足够回答用户,直接回复而不需要sql","sql": "要执行的SQL查询","display_type": "数据展示方法",
}提示词设计原则:
- 结构化约束:明确的SQL生成规则和限制
- 安全性考虑:防止SQL注入和危险操作
- 性能优化:内置查询优化建议
- 用户友好:支持多语言和多种展示方式
- 错误处理:明确的错误情况处理指导
3.4 输出解析与验证
文件路径: packages/dbgpt-app/src/dbgpt_app/scene/chat_db/auto_execute/out_parser.py
智能解析LLM输出,确保结果的正确性和安全性。
class DbChatOutputParser(BaseOutputParser):"""数据库聊天输出解析器"""def __init__(self, is_stream_out: bool = False, **kwargs):super().__init__(is_stream_out=is_stream_out, **kwargs)def is_sql_statement(self, statement: str) -> bool:"""判断是否为有效的SQL语句"""parsed = sqlparse.parse(statement)if not parsed:return Falsefor stmt in parsed:if stmt.get_type() != "UNKNOWN":return Truereturn Falsedef parse_prompt_response(self, model_out_text: str) -> SqlAction:"""解析LLM输出的响应Args:model_out_text: LLM原始输出文本Returns:SqlAction: 解析后的SQL动作对象"""clean_str = super().parse_prompt_response(model_out_text)logger.info(f"Clean prompt response: {clean_str}")# 兼容社区纯SQL输出模型if self.is_sql_statement(clean_str):return SqlAction(clean_str, "", "", "")# 解析JSON格式输出try:response = json.loads(clean_str, strict=False)sql = response.get("sql", "")thoughts = response.get("thoughts", "")display = response.get("display_type", "")direct_response = response.get("direct_response", "")return SqlAction(sql=sql,thoughts=thoughts,display=display,direct_response=direct_response)except Exception as e:logger.error(f"JSON load failed: {clean_str}, error: {e}")return SqlAction("", clean_str, "", "")4. 完整执行流程详解
4.1 端到端执行流程
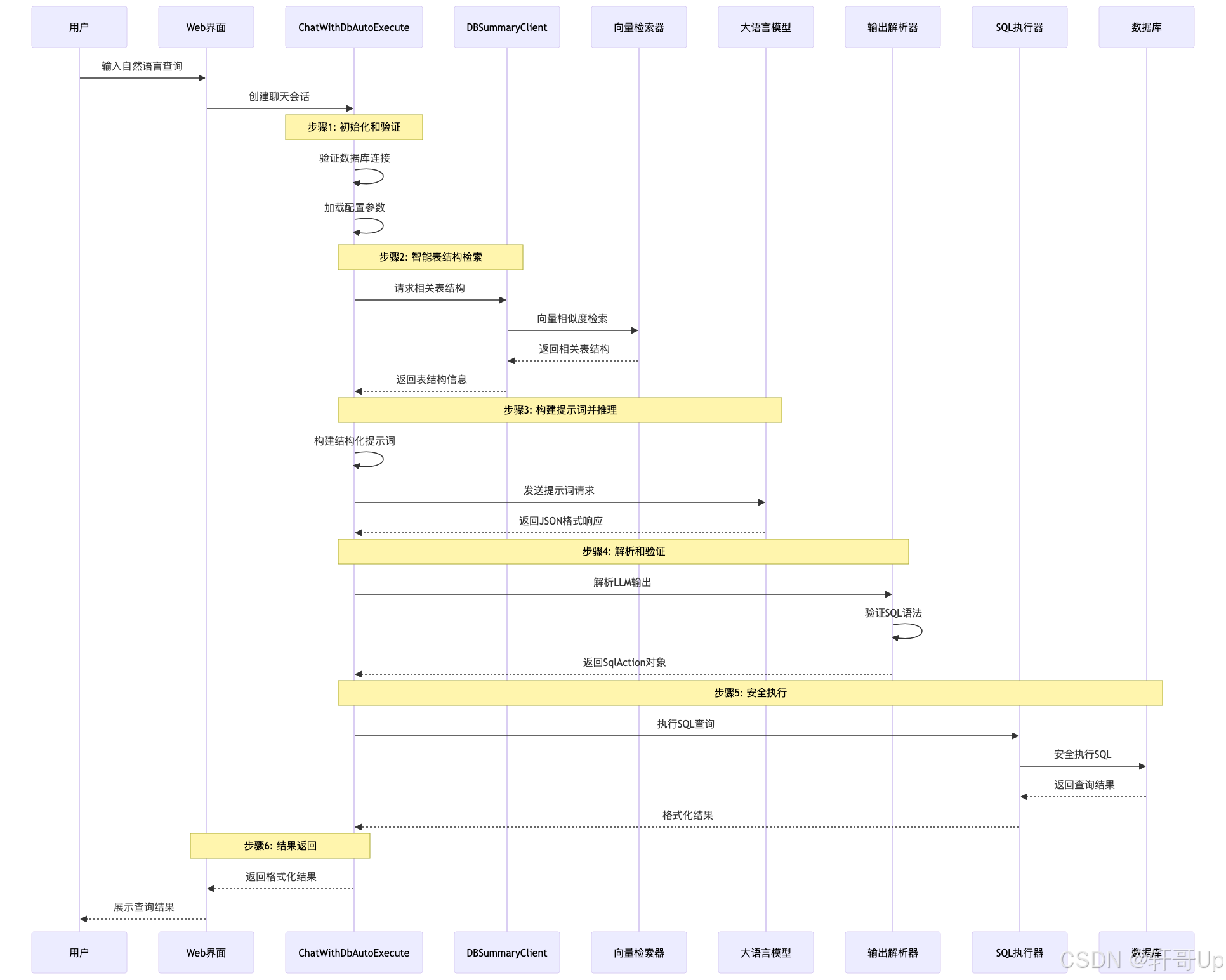
4.2 详细执行步骤
步骤1: 用户输入处理和初始化
async def generate_input_values(self) -> Dict:"""生成输入值,准备LLM推理所需的所有参数"""# 获取用户输入user_input = self.current_user_input.last_textlogger.info(f"User input: {user_input}")# 初始化数据库摘要客户端try:from dbgpt_serve.datasource.service.db_summary_client import DBSummaryClientexcept ImportError:raise ValueError("Could not import DBSummaryClient.")client = DBSummaryClient(system_app=self.system_app)# 智能检索相关表结构try:with root_tracer.start_span("ChatWithDbAutoExecute.get_db_summary"):table_infos = await blocking_func_to_async(self._executor,client.get_db_summary,self.db_name,user_input,self.curr_config.schema_retrieve_top_k,)except Exception as e:logger.error(f"Retrieved table info error: {str(e)}")# 降级处理:获取所有表的简单信息table_infos = await blocking_func_to_async(self._executor, self.database.table_simple_info)# 限制表结构信息长度if len(table_infos) > self.curr_config.schema_max_tokens:table_infos = table_infos[: self.curr_config.schema_max_tokens]# 构建输入参数input_values = {"db_name": self.db_name,"user_input": user_input,"top_k": self.curr_config.max_num_results,"dialect": self.database.dialect,"table_info": table_infos,"display_type": self._generate_numbered_list(),}return input_values步骤2: 智能表结构检索详解
def _get_vector_connector_by_db(self, dbname: str) -> Tuple[VectorStoreBase, VectorStoreBase]:"""获取数据库对应的向量存储连接器"""# 表级别向量存储table_vector_store_name = dbname + "_profile"storage_manager = StorageManager.get_instance(self.system_app)table_vector_store = storage_manager.create_vector_store(index_name=table_vector_store_name)# 字段级别向量存储field_vector_store_name = dbname + "_profile_field"field_vector_store = storage_manager.create_vector_store(index_name=field_vector_store_name)return table_vector_store, field_vector_storedef init_db_profile(self, db_summary_client, dbname: str):"""初始化数据库表结构的向量化存储"""table_vector_connector, field_vector_connector = (self._get_vector_connector_by_db(dbname))# 检查向量存储是否已存在if not table_vector_connector.vector_name_exists():from dbgpt_ext.rag.assembler.db_schema import DBSchemaAssemblerfrom dbgpt_ext.rag.summary.rdbms_db_summary import _DEFAULT_COLUMN_SEPARATOR# 配置文本分割参数chunk_parameters = ChunkParameters(text_splitter=RDBTextSplitter(column_separator=_DEFAULT_COLUMN_SEPARATOR,separator="--table-field-separator--",))# 创建数据库模式组装器db_assembler = DBSchemaAssembler.load_from_connection(connector=db_summary_client.db,table_vector_store_connector=table_vector_connector,field_vector_store_connector=field_vector_connector,chunk_parameters=chunk_parameters,max_seq_length=self.app_config.service.web.embedding_model_max_seq_len,)# 持久化向量数据if len(db_assembler.get_chunks()) > 0:db_assembler.persist()logger.info("Database schema vectorization completed")else:logger.info(f"Vector store for {dbname} already exists")步骤3: SQL执行和结果处理
def run(self, command: str, fetch: str = "all") -> List:"""执行SQL命令并返回结果"""logger.info(f"Executing SQL: {command}")# 验证输入if not command or len(command) < 0:return []# 解析SQL语句parsed, ttype, sql_type, table_name = self.__sql_parse(command)command = self._format_sql(command)# 根据SQL类型执行不同逻辑if ttype == sqlparse.tokens.DML:if sql_type == "SELECT":# 执行查询操作return self._query(command, fetch)else:# 执行写操作self._write(command)# 转换为SELECT语句查看结果select_sql = self.convert_sql_write_to_select(command)logger.info(f"Write result query: {select_sql}")return self._query(select_s