(论文速读)TRIP: 基于图像噪声先验的时间残差学习图像到视频生成模型详解
论文概述
这篇论文提出了TRIP(Temporal Residual Learning with Image Noise Prior),一种全新的图像到视频(Image-to-Video, I2V)生成方法。该方法通过创新的时间残差学习和图像噪声先验技术,显著提升了视频生成的时间一致性和视觉质量。
论文题目:TRIP: Temporal Residual Learning with Image Noise Prior for Image-to-Video Diffusion Models(基于图像噪声先验的图像到视频扩散模型的时间残差学习)
会议:CVPR2024
摘要:文本到视频生成的最新进展已经证明了强大的扩散模型的实用性。然而,在塑造扩散模型以动画静态图像(即图像到视频生成)时,问题并非微不足道。难点在于后续动画帧的扩散过程既要保持与给定图像的忠实对齐,又要追求相邻帧之间的时间一致性。为了缓解这一问题,我们提出了TRIP,这是一种新的图像到视频扩散范式,它以源自静态图像的图像噪声先验为中心,共同触发帧间关系推理,并通过时间残差学习简化连贯的时间建模。从技术上讲,首先通过基于静态图像和带噪视频潜码的一步反向扩散处理获得图像噪声先验。接下来,TRIP采用类似残差的双路径方案进行噪声预测:1)一条捷径路径,直接将先验图像噪声作为每帧的参考噪声,放大第一帧与后续帧之间的对齐;2)残差路径,采用3D-UNet对带噪视频和静态图像潜码进行帧间关系推理,从而简化了对每帧残差噪声的学习。此外,通过注意机制将每帧的参考噪声和残差噪声动态合并,最终生成视频。在WebVid-10M, DTDB和MSRVTT数据集上的大量实验证明了我们的TRIP在图像到视频生成方面的有效性。请参阅我们的项目页面https://trip-i2v.github.io/TRIP/。
问题背景
现有方法的局限性
传统的图像到视频生成方法主要面临两个核心挑战:
- 对齐问题:生成的后续帧难以与给定的静态图像保持忠实对齐
- 时间一致性:相邻帧之间缺乏连贯的时间关系,导致视频不自然
现有方法如VideoComposer和T2V-Zero通常采用独立的噪声预测策略
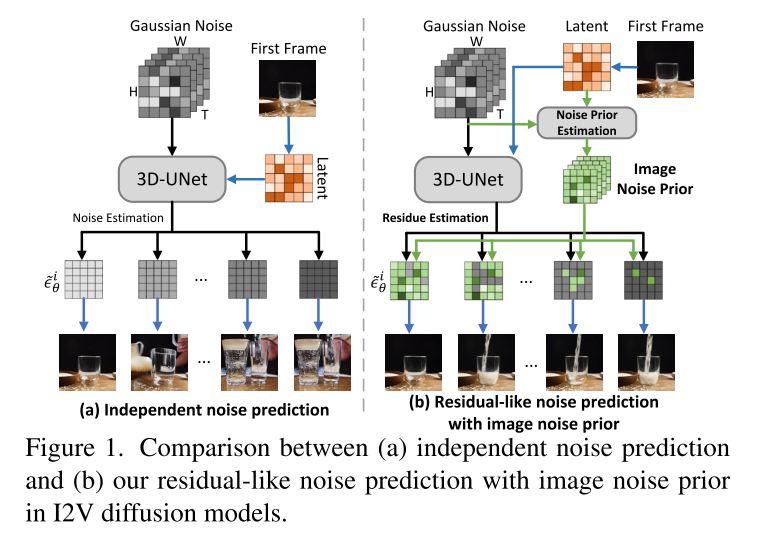
- 将静态图像作为第一帧
- 使用2D VAE编码图像潜在代码
- 将图像潜在代码与噪声视频潜在代码拼接
- 通过3D-UNet预测每帧的反向扩散噪声
这种方法的问题在于:
- 未充分利用给定图像与后续帧之间的内在关系
- 缺乏有效的时间一致性建模机制
TRIP方法详解

核心创新:残差式噪声预测
TRIP的核心思想是将传统的独立噪声预测重新设计为基于图像噪声先验的时间残差学习。
1. 图像噪声先验估计
理论基础: 给定第一帧的图像潜在代码 z_0^1和第i帧的噪声潜在代码 z_t^i,可以通过一步反向扩散重建第i帧:
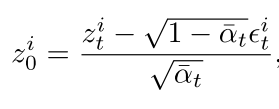
由于I2V中所有帧都与第一帧相关,第i帧可以表示为:
![]()
通过数学推导,可以得到图像噪声先验:
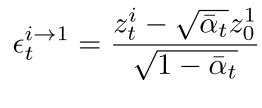
这个图像噪声先验表示了第一帧与第i帧之间的关系。
2. 双路径残差学习架构
TRIP采用两条并行路径进行噪声预测:
快捷路径(Shortcut Path):
- 直接计算图像噪声先验作为参考噪声
- 放大第一帧与后续帧之间的对齐关系
残差路径(Residual Path):
- 使用3D-UNet在噪声视频和静态图像潜在代码上进行帧间关系推理
- 学习每帧的残差噪声
最终噪声预测公式:
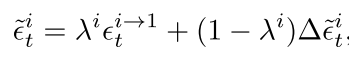
其中λ是权衡参数,随帧索引线性衰减。
3. 时间噪声融合(TNF)模块
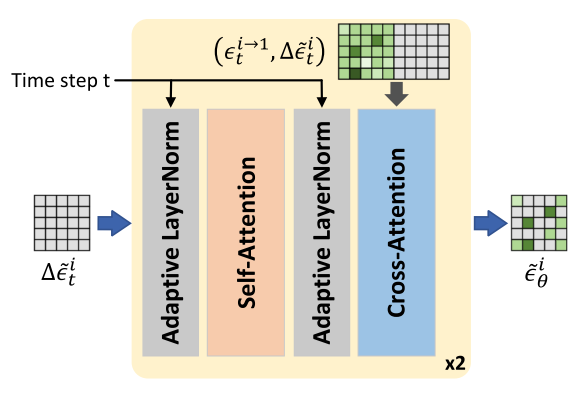
为了避免手工调参的局限性,TRIP设计了基于Transformer的TNF模块:
结构组件:
- 自适应层归一化(由时间步t调制)
- 自注意力层进行特征增强
- 交叉注意力层动态融合参考噪声和残差噪声
优势:
- 无需手工调整超参数λ
- 提供更优雅的动态噪声融合方案
- 显著提升视频质量
实验结果分析
数据集和评估指标
训练数据集:WebVid-10M(1070万视频-文本对,57K视频小时) 评估数据集:WebVid-10M、DTDB、MSR-VTT
评估指标:
- F-Consistency:帧一致性(前4帧和全部16帧)
- FVD:Frechet视频距离
- FID:Frechet图像距离
性能对比

WebVid-10M数据集结果:
| 方法 | F-Consistency4 ↑ | F-Consistencyall ↑ | FVD ↓ |
|---|---|---|---|
| T2V-Zero | 91.59 | 92.15 | 279 |
| VideoComposer | 88.78 | 92.52 | 231 |
| TRIP | 95.36 | 96.41 | 38.9 |
关键发现:
- TRIP在F-Consistency4上比最佳竞争者T2V-Zero提升3.77%
- FVD指标上实现显著改进,表明整体运动动态与真实数据分布更好对齐
- 在不同帧数的一致性评估中持续超越基线方法
消融研究
第一帧条件策略比较:
- TRIPC:沿通道维度拼接(F-Consistency4: 94.77%)
- TRIPTE:在时间维度末尾拼接(F-Consistency4: 95.17%)
- TRIP:在时间维度开始拼接(F-Consistency4: 95.36%)
时间残差学习组件评估:
- TRIP-:移除快捷路径(F-Consistency4: 94.66%)
- TRIPW:简单线性融合(F-Consistency4: 95.22%)
- TRIP:Transformer融合(F-Consistency4: 95.36%)
人类评估
在WebVid-10M上进行的用户研究显示TRIP在三个维度上均显著优于基线:
与T2V-Zero对比:
- 时间一致性:96.9% vs 3.1%
- 运动保真度:93.8% vs 6.2%
- 视觉质量:90.6% vs 9.4%
与VideoComposer对比:
- 时间一致性:84.4% vs 15.6%
- 运动保真度:81.3% vs 18.7%
- 视觉质量:87.5% vs 12.5%
应用扩展
1. 定制化图像动画
TRIP可以与其他生成模型结合:
- 文本到视频流水线:Stable-Diffusion XL + TRIP
- 图像编辑动画:InstructPix2Pix/ControlNet + TRIP
2. 零样本泛化能力
在DTDB和MSR-VTT数据集上的零样本评估证明了TRIP的强泛化能力:
- DTDB:FID 24.8,FVD 433.9
- MSR-VTT:FID 9.68,FVD 91.3
技术优势总结
- 理论创新:首次将残差学习引入I2V扩散模型的噪声预测
- 架构设计:双路径设计充分利用图像先验和时间建模
- 动态融合:Transformer-based TNF模块避免超参数调优
- 性能优异:在多个数据集上显著超越现有方法
- 实用性强:支持多种应用场景的扩展
未来发展方向
- 更长视频生成:扩展到更长时间序列的视频生成
- 高分辨率支持:提升对高分辨率视频的生成质量
- 实时生成:优化模型推理速度实现实时应用
- 多模态控制:集成更多控制信号(深度、光流等)
TRIP为图像到视频生成领域提供了一个强有力的新范式,其创新的时间残差学习思想有望启发更多相关研究。
参考代码Pytorch
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import Dataset, DataLoader
import numpy as np
import math
from transformers import CLIPTextModel, CLIPTokenizer
from diffusers import AutoencoderKL, DDIMScheduler
from typing import Optional, Tuple, Union, List
import cv2
from PIL import Image
import os
import json# ================== Utility Functions ==================def timestep_embedding(timesteps, dim, max_period=10000):"""Create sinusoidal timestep embeddings."""half = dim // 2freqs = torch.exp(-math.log(max_period) * torch.arange(start=0, end=half, dtype=torch.float32) / half).to(device=timesteps.device)args = timesteps[:, None].float() * freqs[None]embedding = torch.cat([torch.cos(args), torch.sin(args)], dim=-1)if dim % 2:embedding = torch.cat([embedding, torch.zeros_like(embedding[:, :1])], dim=-1)return embedding# ================== 3D UNet Components ==================class GroupNorm3D(nn.Module):def __init__(self, num_groups, num_channels, eps=1e-6):super().__init__()self.num_groups = num_groupsself.num_channels = num_channelsself.eps = epsself.weight = nn.Parameter(torch.ones(num_channels))self.bias = nn.Parameter(torch.zeros(num_channels))def forward(self, x):# x: (B, C, T, H, W)B, C, T, H, W = x.shapex = x.view(B, self.num_groups, C // self.num_groups, T, H, W)# Compute mean and variance across C, H, W dimensionsmean = x.mean(dim=[2, 3, 4], keepdim=True)var = x.var(dim=[2, 3, 4], keepdim=True, unbiased=False)# Normalizex = (x - mean) / torch.sqrt(var + self.eps)x = x.view(B, C, T, H, W)# Apply scale and shiftx = x * self.weight.view(1, C, 1, 1, 1) + self.bias.view(1, C, 1, 1, 1)return xclass Conv3D(nn.Module):def __init__(self, in_channels, out_channels, kernel_size=3, stride=1, padding=1):super().__init__()self.conv = nn.Conv3d(in_channels, out_channels, kernel_size, stride, padding)def forward(self, x):return self.conv(x)class ResBlock3D(nn.Module):def __init__(self, in_channels, out_channels, time_emb_dim, dropout=0.0):super().__init__()self.in_channels = in_channelsself.out_channels = out_channelsself.norm1 = GroupNorm3D(32, in_channels)self.conv1 = Conv3D(in_channels, out_channels)self.time_emb_proj = nn.Linear(time_emb_dim, out_channels)self.norm2 = GroupNorm3D(32, out_channels)self.dropout = nn.Dropout(dropout)self.conv2 = Conv3D(out_channels, out_channels)if in_channels != out_channels:self.shortcut = Conv3D(in_channels, out_channels, 1, padding=0)else:self.shortcut = nn.Identity()def forward(self, x, time_emb):h = self.norm1(x)h = F.silu(h)h = self.conv1(h)# Add time embeddingtime_emb = self.time_emb_proj(time_emb)h = h + time_emb[:, :, None, None, None]h = self.norm2(h)h = F.silu(h)h = self.dropout(h)h = self.conv2(h)return h + self.shortcut(x)class TemporalAttention(nn.Module):def __init__(self, dim, num_heads=8):super().__init__()self.num_heads = num_headsself.dim = dimself.head_dim = dim // num_headsself.qkv = nn.Linear(dim, dim * 3)self.proj = nn.Linear(dim, dim)def forward(self, x):# x: (B, C, T, H, W)B, C, T, H, W = x.shapex = x.permute(0, 2, 3, 4, 1).reshape(B * H * W, T, C) # (B*H*W, T, C)qkv = self.qkv(x).reshape(B * H * W, T, 3, self.num_heads, self.head_dim)qkv = qkv.permute(2, 0, 3, 1, 4) # (3, B*H*W, num_heads, T, head_dim)q, k, v = qkv[0], qkv[1], qkv[2]# Attentionscale = self.head_dim ** -0.5attn = (q @ k.transpose(-2, -1)) * scaleattn = F.softmax(attn, dim=-1)out = attn @ v # (B*H*W, num_heads, T, head_dim)out = out.transpose(1, 2).reshape(B * H * W, T, C)out = self.proj(out)out = out.reshape(B, H, W, T, C).permute(0, 4, 3, 1, 2) # (B, C, T, H, W)return outclass UNet3D(nn.Module):def __init__(self, in_channels=4,out_channels=4,down_block_types=("DownBlock3D", "DownBlock3D", "DownBlock3D", "DownBlock3D"),up_block_types=("UpBlock3D", "UpBlock3D", "UpBlock3D", "UpBlock3D"),block_out_channels=(320, 640, 1280, 1280),layers_per_block=2,attention_head_dim=8,cross_attention_dim=768):super().__init__()self.conv_in = Conv3D(in_channels, block_out_channels[0])# Time embeddingtime_embed_dim = block_out_channels[0] * 4self.time_proj = nn.Linear(block_out_channels[0], time_embed_dim)self.time_embedding = nn.Sequential(nn.Linear(time_embed_dim, time_embed_dim),nn.SiLU(),nn.Linear(time_embed_dim, time_embed_dim),)# Down blocksself.down_blocks = nn.ModuleList([])output_channel = block_out_channels[0]for i, down_block_type in enumerate(down_block_types):input_channel = output_channeloutput_channel = block_out_channels[i]is_final_block = i == len(block_out_channels) - 1down_block = DownBlock3D(num_layers=layers_per_block,in_channels=input_channel,out_channels=output_channel,time_emb_dim=time_embed_dim,add_downsample=not is_final_block,)self.down_blocks.append(down_block)# Mid blockself.mid_block = UNetMidBlock3D(in_channels=block_out_channels[-1],time_emb_dim=time_embed_dim,num_layers=1,)# Up blocksself.up_blocks = nn.ModuleList([])reversed_block_out_channels = list(reversed(block_out_channels))output_channel = reversed_block_out_channels[0]for i, up_block_type in enumerate(up_block_types):prev_output_channel = output_channeloutput_channel = reversed_block_out_channels[i]input_channel = reversed_block_out_channels[min(i + 1, len(block_out_channels) - 1)]is_final_block = i == len(block_out_channels) - 1up_block = UpBlock3D(num_layers=layers_per_block + 1,in_channels=input_channel,out_channels=output_channel,prev_output_channel=prev_output_channel,time_emb_dim=time_embed_dim,add_upsample=not is_final_block,)self.up_blocks.append(up_block)self.conv_norm_out = GroupNorm3D(32, block_out_channels[0])self.conv_out = Conv3D(block_out_channels[0], out_channels)def forward(self, sample, timestep, encoder_hidden_states=None):# Timestep embeddingtimesteps = timestepif not torch.is_tensor(timesteps):timesteps = torch.tensor([timesteps], dtype=torch.long, device=sample.device)elif torch.is_tensor(timesteps) and len(timesteps.shape) == 0:timesteps = timesteps[None].to(sample.device)t_emb = timestep_embedding(timesteps, self.time_proj.in_features)t_emb = self.time_proj(t_emb)emb = self.time_embedding(t_emb)# Initial convolutionsample = self.conv_in(sample)# Downdown_block_res_samples = (sample,)for down_block in self.down_blocks:sample, res_samples = down_block(sample, emb)down_block_res_samples += res_samples# Midsample = self.mid_block(sample, emb)# Upfor up_block in self.up_blocks:res_samples = down_block_res_samples[-len(up_block.resnets):]down_block_res_samples = down_block_res_samples[:-len(up_block.resnets)]sample = up_block(sample, res_samples, emb)# Outputsample = self.conv_norm_out(sample)sample = F.silu(sample)sample = self.conv_out(sample)return sampleclass DownBlock3D(nn.Module):def __init__(self, in_channels, out_channels, time_emb_dim, num_layers=1, add_downsample=True):super().__init__()resnets = []for i in range(num_layers):in_channels = in_channels if i == 0 else out_channelsresnets.append(ResBlock3D(in_channels, out_channels, time_emb_dim))self.resnets = nn.ModuleList(resnets)if add_downsample:self.downsamplers = nn.ModuleList([Conv3D(out_channels, out_channels, stride=2)])else:self.downsamplers = Nonedef forward(self, hidden_states, temb):output_states = ()for resnet in self.resnets:hidden_states = resnet(hidden_states, temb)output_states += (hidden_states,)if self.downsamplers is not None:for downsampler in self.downsamplers:hidden_states = downsampler(hidden_states)output_states += (hidden_states,)return hidden_states, output_statesclass UpBlock3D(nn.Module):def __init__(self, in_channels, out_channels, prev_output_channel, time_emb_dim, num_layers=1, add_upsample=True):super().__init__()resnets = []for i in range(num_layers):res_skip_channels = in_channels if (i == num_layers - 1) else out_channelsresnet_in_channels = prev_output_channel if i == 0 else out_channelsresnets.append(ResBlock3D(resnet_in_channels + res_skip_channels, out_channels, time_emb_dim))self.resnets = nn.ModuleList(resnets)if add_upsample:self.upsamplers = nn.ModuleList([nn.ConvTranspose3d(out_channels, out_channels, 4, 2, 1)])else:self.upsamplers = Nonedef forward(self, hidden_states, res_hidden_states_tuple, temb):for resnet in self.resnets:res_hidden_states = res_hidden_states_tuple[-1]res_hidden_states_tuple = res_hidden_states_tuple[:-1]hidden_states = torch.cat([hidden_states, res_hidden_states], dim=1)hidden_states = resnet(hidden_states, temb)if self.upsamplers is not None:for upsampler in self.upsamplers:hidden_states = upsampler(hidden_states)return hidden_statesclass UNetMidBlock3D(nn.Module):def __init__(self, in_channels, time_emb_dim, num_layers=1):super().__init__()self.resnets = nn.ModuleList([ResBlock3D(in_channels, in_channels, time_emb_dim)for _ in range(num_layers)])self.attentions = nn.ModuleList([TemporalAttention(in_channels)for _ in range(num_layers)])def forward(self, hidden_states, temb):hidden_states = self.resnets[0](hidden_states, temb)for attn, resnet in zip(self.attentions, self.resnets[1:]):hidden_states = attn(hidden_states)hidden_states = resnet(hidden_states, temb)return hidden_states# ================== TNF Module ==================class AdaptiveLayerNorm(nn.Module):def __init__(self, num_features, time_embed_dim):super().__init__()self.norm = nn.LayerNorm(num_features)self.time_proj = nn.Linear(time_embed_dim, num_features * 2)def forward(self, x, time_emb):x = self.norm(x)time_proj = self.time_proj(time_emb)scale, shift = time_proj.chunk(2, dim=-1)return x * (1 + scale.unsqueeze(1)) + shift.unsqueeze(1)class TemporalNoiseFusion(nn.Module):def __init__(self, noise_dim=4, time_embed_dim=1280, num_heads=8):super().__init__()self.noise_dim = noise_dimself.num_heads = num_headsself.head_dim = noise_dim // num_heads# Adaptive layer normsself.norm1 = AdaptiveLayerNorm(noise_dim, time_embed_dim)self.norm2 = AdaptiveLayerNorm(noise_dim, time_embed_dim)# Self-attentionself.self_attn = nn.MultiheadAttention(noise_dim, num_heads, batch_first=True)# Cross-attentionself.cross_attn = nn.MultiheadAttention(noise_dim, num_heads, batch_first=True)# Output projectionself.output_proj = nn.Linear(noise_dim, noise_dim)def forward(self, residual_noise, reference_noise, time_emb):"""Args:residual_noise: (B, T, C, H, W) - residual noise from 3D-UNetreference_noise: (B, T, C, H, W) - image noise priortime_emb: (B, time_embed_dim) - time embeddingReturns:fused_noise: (B, T, C, H, W) - fused noise"""B, T, C, H, W = residual_noise.shape# Reshape for attention: (B*H*W, T, C)residual_flat = residual_noise.permute(0, 3, 4, 1, 2).reshape(B * H * W, T, C)reference_flat = reference_noise.permute(0, 3, 4, 1, 2).reshape(B * H * W, T, C)# Expand time embeddingtime_emb_expanded = time_emb.unsqueeze(1).expand(B, H * W, -1).reshape(B * H * W, -1)# First adaptive layer norm + self-attentionx = self.norm1(residual_flat, time_emb_expanded)x, _ = self.self_attn(x, x, x)x = x + residual_flat# Second adaptive layer norm + cross-attentionx = self.norm2(x, time_emb_expanded)# Prepare key-value as concatenation of reference and residualkv = torch.cat([reference_flat, residual_flat], dim=-1) # (B*H*W, T, 2*C)kv = nn.Linear(2 * C, C).to(kv.device)(kv) # Project back to C dimensionsfused, _ = self.cross_attn(x, kv, kv)fused = self.output_proj(fused)# Reshape back: (B, T, C, H, W)fused = fused.reshape(B, H, W, T, C).permute(0, 3, 4, 1, 2)return fused# ================== TRIP Model ==================class TRIPModel(nn.Module):def __init__(self, unet_config=None,vae_model_name="stabilityai/sd-vae-ft-mse",clip_model_name="openai/clip-vit-large-patch14"):super().__init__()# Initialize 3D-UNetself.unet = UNet3D()# Initialize VAE (frozen)self.vae = AutoencoderKL.from_pretrained(vae_model_name)for param in self.vae.parameters():param.requires_grad = False# Initialize CLIP text encoder (frozen)self.text_encoder = CLIPTextModel.from_pretrained(clip_model_name)self.tokenizer = CLIPTokenizer.from_pretrained(clip_model_name)for param in self.text_encoder.parameters():param.requires_grad = False# Initialize TNF moduleself.tnf_module = TemporalNoiseFusion()# Noise schedulerself.noise_scheduler = DDIMScheduler(num_train_timesteps=1000,beta_start=1e-4,beta_end=2e-2,beta_schedule="linear",clip_sample=False)def encode_text(self, text_prompts):"""Encode text prompts to embeddings."""text_inputs = self.tokenizer(text_prompts,padding="max_length",max_length=self.tokenizer.model_max_length,truncation=True,return_tensors="pt")with torch.no_grad():text_embeddings = self.text_encoder(text_inputs.input_ids.to(self.text_encoder.device))[0]return text_embeddingsdef encode_video(self, video_frames):"""Encode video frames to latent space."""# video_frames: (B, T, C, H, W)B, T, C, H, W = video_frames.shape# Reshape to (B*T, C, H, W) for VAE encodingframes_flat = video_frames.reshape(B * T, C, H, W)with torch.no_grad():latents_flat = self.vae.encode(frames_flat).latent_dist.sample()latents_flat = latents_flat * self.vae.config.scaling_factor# Reshape back to (B, T, latent_C, latent_H, latent_W)latent_C, latent_H, latent_W = latents_flat.shape[1:]latents = latents_flat.reshape(B, T, latent_C, latent_H, latent_W)return latentsdef decode_video(self, latents):"""Decode latents back to video frames."""B, T, C, H, W = latents.shape# Reshape and scalelatents_flat = latents.reshape(B * T, C, H, W)latents_flat = latents_flat / self.vae.config.scaling_factorwith torch.no_grad():frames_flat = self.vae.decode(latents_flat).sample# Reshape backframes = frames_flat.reshape(B, T, *frames_flat.shape[1:])return framesdef compute_image_noise_prior(self, first_frame_latent, noised_video_latent, timestep):"""Compute image noise prior according to Eq. (8).Args:first_frame_latent: (B, C, H, W) - latent of first framenoised_video_latent: (B, T, C, H, W) - noised video latentstimestep: int or tensor - diffusion timestepReturns:image_noise_prior: (B, T, C, H, W) - image noise prior for each frame"""B, T, C, H, W = noised_video_latent.shape# Get alpha_bar_talpha_bar_t = self.noise_scheduler.alphas_cumprod[timestep]# Expand first frame to match video dimensionsfirst_frame_expanded = first_frame_latent.unsqueeze(1).expand(B, T, C, H, W)# Compute image noise prior: (z_t^i - sqrt(alpha_bar_t) * z_0^1) / sqrt(1 - alpha_bar_t)numerator = noised_video_latent - torch.sqrt(alpha_bar_t) * first_frame_expandeddenominator = torch.sqrt(1 - alpha_bar_t)image_noise_prior = numerator / denominatorreturn image_noise_priordef forward(self, video_latents, text_embeddings, timestep):"""Forward pass for training.Args:video_latents: (B, T, C, H, W) - clean video latentstext_embeddings: (B, seq_len, embed_dim) - text embeddingstimestep: int or tensor - diffusion timestepReturns:predicted_noise: (B, T, C, H, W) - predicted noise"""B, T, C, H, W = video_latents.shape# Sample noisenoise = torch.randn_like(video_latents)# Add noise to video latentsnoised_video_latents = self.noise_scheduler.add_noise(video_latents, noise, timestep)# Get first frame latent (clean)first_frame_latent = video_latents[:, 0] # (B, C, H, W)# Compute image noise prior (shortcut path)image_noise_prior = self.compute_image_noise_prior(first_frame_latent, noised_video_latents, timestep)# Prepare input for 3D-UNet (residual path)# Concatenate first frame with noised video along temporal dimensionfirst_frame_expanded = first_frame_latent.unsqueeze(1) # (B, 1, C, H, W)unet_input = torch.cat([first_frame_expanded, noised_video_latents], dim=1) # (B, T+1, C, H, W)# Reshape for 3D-UNet: (B, C, T+1, H, W)unet_input = unet_input.permute(0, 2, 1, 3, 4)# Get time embeddingif isinstance(timestep, int):timestep = torch.tensor([timestep] * B, device=video_latents.device)# Predict residual noise using 3D-UNetresidual_noise_3d = self.unet(unet_input, timestep, text_embeddings)# Remove first frame and reshape back: (B, T, C, H, W)residual_noise = residual_noise_3d.permute(0, 2, 1, 3, 4)[:, 1:]# Fuse noises using TNF moduletime_emb = timestep_embedding(timestep, 1280)fused_noise = self.tnf_module(residual_noise, image_noise_prior, time_emb)return fused_noise, noise# ================== Dataset ==================class VideoDataset(Dataset):def __init__(self, data_root, annotation_file, max_frames=16, resolution=256):self.data_root = data_rootself.max_frames = max_framesself.resolution = resolution# Load annotationswith open(annotation_file, 'r') as f:self.annotations = json.load(f)def __len__(self):return len(self.annotations)def load_video(self, video_path):"""Load video frames."""cap = cv2.VideoCapture(video_path)frames = []while len(frames) < self.max_frames:ret, frame = cap.read()if not ret:break# Convert BGR to RGBframe = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)# Resizeframe = cv2.resize(frame, (self.resolution, self.resolution))# Normalize to [-1, 1]frame = (frame / 127.5) - 1.0frames.append(frame)cap.release()# Pad if necessarywhile len(frames) < self.max_frames:frames.append(frames[-1]) # Repeat last frame# Convert to tensor: (T, H, W, C) -> (T, C, H, W)frames = np.array(frames)frames = torch.from_numpy(frames).permute(0, 3, 1, 2).float()return framesdef __getitem__(self, idx):annotation = self.annotations[idx]video_path = os.path.join(self.data_root, annotation['video_path'])text_prompt = annotation['text']# Load videovideo_frames = self.load_video(video_path)return {'video': video_frames,'text': text_prompt}# ================== Training Loop ==================class TRIPTrainer:def __init__(self, model, train_dataset, val_dataset=None, lr=2e-6, device='cuda'):self.model = model.to(device)self.device = device# Optimizersself.optimizer = torch.optim.AdamW([{'params': self.model.unet.parameters(), 'lr': lr},{'params': self.model.tnf_module.parameters(), 'lr': lr * 10} # Higher LR for TNF])# Data loadersself.train_loader = DataLoader(train_dataset, batch_size=1, shuffle=True, num_workers=4)self.val_loader = DataLoader(val_dataset, batch_size=1, shuffle=False, num_workers=4) if val_dataset else Noneself.global_step = 0def train_step(self, batch):self.model.train()self.optimizer.zero_grad()video_frames = batch['video'].to(self.device) # (B, T, C, H, W)text_prompts = batch['text']# Encode video to latentsvideo_latents = self.model.encode_video(video_frames)# Encode texttext_embeddings = self.model.encode_text(text_prompts)# Sample random timesteptimestep = torch.randint(0, self.model.noise_scheduler.config.num_train_timesteps, (video_frames.shape[0],), device=self.device)# Forward passpredicted_noise, target_noise = self.model(video_latents, text_embeddings, timestep)# Compute lossloss = F.mse_loss(predicted_noise, target_noise)# Backward passloss.backward()self.optimizer.step()return loss.item()def validate(self):if self.val_loader is None:return Noneself.model.eval()total_loss = 0num_batches = 0with torch.no_grad():for batch in self.val_loader:video_frames = batch['video'].to(self.device)text_prompts = batch['text']video_latents = self.model.encode_video(video_frames)text_embeddings = self.model.encode_text(text_prompts)timestep = torch.randint(0, self.model.noise_scheduler.config.num_train_timesteps, (video_frames.shape[0],), device=self.device)predicted_noise, target_noise = self.model(video_latents, text_embeddings, timestep)loss = F.mse_loss(predicted_noise, target_noise)total_loss += loss.item()num_batches += 1return total_loss / num_batchesdef train(self, num_epochs, save_every=1000, log_every=100):for epoch in range(num_epochs):for batch_idx, batch in enumerate(self.train_loader):loss = self.train_step(batch)if self.global_step % log_every == 0:print(f"Epoch {epoch}, Step {self.global_step}, Loss: {loss:.6f}")if self.global_step % save_every == 0:self.save_checkpoint(f"checkpoint_step_{self.global_step}.pt")self.global_step += 1# Validationif self.val_loader:val_loss = self.validate()print(f"Epoch {epoch}, Validation Loss: {val_loss:.6f}")def save_checkpoint(self, path):torch.save({'model_state_dict': self.model.state_dict(),'optimizer_state_dict': self.optimizer.state_dict(),'global_step': self.global_step,}, path)print(f"Checkpoint saved: {path}")def load_checkpoint(self, path):checkpoint = torch.load(path)self.model.load_state_dict(checkpoint['model_state_dict'])self.optimizer.load_state_dict(checkpoint['optimizer_state_dict'])self.global_step = checkpoint['global_step']print(f"Checkpoint loaded: {path}")# ================== Inference ==================class TRIPInference:def __init__(self, model, device='cuda', num_inference_steps=50):self.model = model.to(device)self.device = deviceself.num_inference_steps = num_inference_steps# Setup scheduler for inferenceself.model.noise_scheduler.set_timesteps(num_inference_steps)@torch.no_grad()def generate_video(self, first_frame, text_prompt, num_frames=16, guidance_scale=7.5):"""Generate video from first frame and text prompt.Args:first_frame: PIL Image or tensor (C, H, W)text_prompt: strnum_frames: intguidance_scale: float for classifier-free guidanceReturns:generated_video: tensor (T, C, H, W)"""self.model.eval()# Process first frameif isinstance(first_frame, Image.Image):first_frame = torch.from_numpy(np.array(first_frame)).float()first_frame = first_frame.permute(2, 0, 1) / 127.5 - 1.0first_frame = first_frame.unsqueeze(0).to(self.device) # (1, C, H, W)# Encode first framefirst_frame_latent = self.model.vae.encode(first_frame).latent_dist.sample()first_frame_latent = first_frame_latent * self.model.vae.config.scaling_factor# Encode texttext_embedding = self.model.encode_text([text_prompt])# Initialize noiseB, C, H, W = first_frame_latent.shapelatents_shape = (B, num_frames, C, H, W)latents = torch.randn(latents_shape, device=self.device)# Set first framelatents[:, 0] = first_frame_latent.squeeze(0)# Denoising loopfor i, t in enumerate(self.model.noise_scheduler.timesteps):# Predict noisepredicted_noise, _ = self.model(latents, text_embedding, t)# Scheduler steplatents = self.model.noise_scheduler.step(predicted_noise, t, latents).prev_sample# Ensure first frame remains unchangedlatents[:, 0] = first_frame_latent.squeeze(0)# Decode to framesgenerated_frames = self.model.decode_video(latents)return generated_frames.squeeze(0) # Remove batch dimension# ================== Example Usage ==================def main():# Initialize modelmodel = TRIPModel()# Prepare dataset (you need to customize this based on your data format)train_dataset = VideoDataset(data_root="/path/to/your/videos",annotation_file="/path/to/annotations.json")# Initialize trainertrainer = TRIPTrainer(model, train_dataset, lr=2e-6)# Traintrainer.train(num_epochs=100)# For inferenceinference = TRIPInference(model)# Generate videofirst_frame = Image.open("/path/to/first/frame.jpg")text_prompt = "A cat is walking in the garden"generated_video = inference.generate_video(first_frame=first_frame,text_prompt=text_prompt,num_frames=16)print(f"Generated video shape: {generated_video.shape}")if __name__ == "__main__":main()准备指南
TRIP模型使用指南和数据准备
📋 环境要求
首先安装必要的依赖包:
pip install torch torchvision torchaudio
pip install transformers diffusers
pip install opencv-python pillow
pip install numpy accelerate
📁 数据集准备
1. 数据格式
您的数据集应该包含:
- 视频文件:MP4格式,建议分辨率256x256或512x512
- 标注文件:JSON格式,包含视频路径和对应的文本描述
2. 目录结构示例
your_dataset/
├── videos/
│ ├── video_001.mp4
│ ├── video_002.mp4
│ └── ...
├── annotations.json
└── val_annotations.json (可选)
3. 标注文件格式
创建annotations.json文件:
[{"video_path": "videos/video_001.mp4","text": "A cat is walking slowly in the garden"},{"video_path": "videos/video_002.mp4", "text": "A dog is running on the beach"}
]
🔧 配置和训练
1. 基础训练脚本
import torch
from PIL import Image
import json# 导入我们的TRIP模型
from trip_model import TRIPModel, TRIPTrainer, VideoDatasetdef prepare_training():# 检查GPU可用性device = 'cuda' if torch.cuda.is_available() else 'cpu'print(f"Using device: {device}")# 初始化模型model = TRIPModel()# 准备数据集train_dataset = VideoDataset(data_root="/path/to/your/dataset", # 修改为您的数据路径annotation_file="/path/to/your/annotations.json", # 修改为您的标注文件max_frames=16, # 每个视频的帧数resolution=256 # 分辨率)# 验证数据集(可选)val_dataset = VideoDataset(data_root="/path/to/your/dataset",annotation_file="/path/to/your/val_annotations.json",max_frames=16,resolution=256) if os.path.exists("/path/to/your/val_annotations.json") else None# 初始化训练器trainer = TRIPTrainer(model=model,train_dataset=train_dataset,val_dataset=val_dataset,lr=2e-6, # 学习率device=device)return trainerdef main():trainer = prepare_training()# 开始训练trainer.train(num_epochs=100, # 训练轮数save_every=1000, # 每1000步保存一次log_every=100 # 每100步打印一次日志)if __name__ == "__main__":main()
2. 高级配置
# 自定义模型配置
model = TRIPModel(vae_model_name="stabilityai/sd-vae-ft-mse", # VAE模型clip_model_name="openai/clip-vit-large-patch14" # CLIP模型
)# 自定义训练器配置
trainer = TRIPTrainer(model=model,train_dataset=train_dataset,val_dataset=val_dataset,lr=2e-6,device='cuda'
)# 使用不同的优化器设置
trainer.optimizer = torch.optim.AdamW([{'params': model.unet.parameters(), 'lr': 2e-6},{'params': model.tnf_module.parameters(), 'lr': 2e-5} # TNF模块使用更高学习率
], weight_decay=1e-2)
🎯 推理和生成
1. 基础推理
from trip_model import TRIPInference
from PIL import Image# 加载训练好的模型
model = TRIPModel()
model.load_state_dict(torch.load("checkpoint_step_10000.pt")['model_state_dict'])# 初始化推理器
inference = TRIPInference(model, device='cuda', num_inference_steps=50)# 加载第一帧图像
first_frame = Image.open("path/to/your/first_frame.jpg")# 生成视频
generated_video = inference.generate_video(first_frame=first_frame,text_prompt="A beautiful sunset over the ocean",num_frames=16,guidance_scale=7.5
)# 保存生成的视频
import torchvision
torchvision.io.write_video("generated_video.mp4",(generated_video * 255).byte().permute(0, 2, 3, 1),fps=8
)
2. 批量生成
def batch_generate(image_paths, text_prompts, output_dir):inference = TRIPInference(model, device='cuda')for i, (img_path, prompt) in enumerate(zip(image_paths, text_prompts)):first_frame = Image.open(img_path)generated_video = inference.generate_video(first_frame=first_frame,text_prompt=prompt,num_frames=16)# 保存视频output_path = f"{output_dir}/generated_{i:04d}.mp4"torchvision.io.write_video(output_path,(generated_video * 255).byte().permute(0, 2, 3, 1),fps=8)print(f"Generated: {output_path}")# 使用示例
image_paths = ["img1.jpg", "img2.jpg", "img3.jpg"]
text_prompts = ["A cat walking", "A dog running", "Birds flying"]
batch_generate(image_paths, text_prompts, "output_videos")
🔄 模型微调和适配
1. 从预训练模型微调
# 加载预训练检查点
def load_pretrained_model(checkpoint_path):model = TRIPModel()checkpoint = torch.load(checkpoint_path)model.load_state_dict(checkpoint['model_state_dict'])return model# 微调特定领域数据
def finetune_model(pretrained_path, new_dataset):# 加载预训练模型model = load_pretrained_model(pretrained_path)# 冻结部分参数(可选)for param in model.unet.parameters():param.requires_grad = False# 只训练TNF模块trainer = TRIPTrainer(model=model,train_dataset=new_dataset,lr=1e-5 # 使用较小的学习率)trainer.train(num_epochs=50)
2. 渐进式训练
def progressive_training():model = TRIPModel()# 第一阶段:只训练TNF模块for param in model.unet.parameters():param.requires_grad = Falsetrainer = TRIPTrainer(model, train_dataset, lr=1e-4)trainer.train(num_epochs=20)# 第二阶段:训练整个模型for param in model.parameters():param.requires_grad = Truetrainer = TRIPTrainer(model, train_dataset, lr=2e-6)trainer.train(num_epochs=80)
📊 监控和调试
1. 训练监控
import wandb # 可选:使用Weights & Biasesdef train_with_monitoring():# 初始化wandb(可选)wandb.init(project="trip-training")trainer = TRIPTrainer(model, train_dataset, lr=2e-6)# 修改训练循环以包含监控for epoch in range(num_epochs):for batch_idx, batch in enumerate(trainer.train_loader):loss = trainer.train_step(batch)# 记录到wandbwandb.log({"train_loss": loss, "step": trainer.global_step})if trainer.global_step % 100 == 0:print(f"Step {trainer.global_step}, Loss: {loss:.6f}")
2. 调试技巧
# 检查数据加载
def debug_dataset():dataset = VideoDataset("/path/to/data", "/path/to/annotations.json")for i in range(3):sample = dataset[i]print(f"Video shape: {sample['video'].shape}")print(f"Text: {sample['text']}")# 检查模型输出
def debug_model():model = TRIPModel()# 创建假数据video_latents = torch.randn(1, 16, 4, 32, 32)text_embeddings = torch.randn(1, 77, 768)timestep = torch.tensor([500])# 前向传播predicted_noise, target_noise = model(video_latents, text_embeddings, timestep)print(f"Predicted noise shape: {predicted_noise.shape}")print(f"Target noise shape: {target_noise.shape}")# 检查内存使用
def monitor_memory():import psutilimport GPUtil# CPU内存print(f"CPU Memory: {psutil.virtual_memory().percent}%")# GPU内存if torch.cuda.is_available():gpus = GPUtil.getGPUs()for gpu in gpus:print(f"GPU {gpu.id}: {gpu.memoryUtil*100:.1f}%")
⚡ 性能优化
1. 内存优化
# 使用梯度检查点
def enable_gradient_checkpointing(model):if hasattr(model.unet, 'enable_gradient_checkpointing'):model.unet.enable_gradient_checkpointing()# 使用混合精度训练
from torch.cuda.amp import autocast, GradScalerclass OptimizedTrainer(TRIPTrainer):def __init__(self, *args, **kwargs):super().__init__(*args, **kwargs)self.scaler = GradScaler()def train_step(self, batch):self.model.train()self.optimizer.zero_grad()video_frames = batch['video'].to(self.device)text_prompts = batch['text']with autocast():video_latents = self.model.encode_video(video_frames)text_embeddings = self.model.encode_text(text_prompts)timestep = torch.randint(0, 1000, (video_frames.shape[0],), device=self.device)predicted_noise, target_noise = self.model(video_latents, text_embeddings, timestep)loss = F.mse_loss(predicted_noise, target_noise)self.scaler.scale(loss).backward()self.scaler.step(self.optimizer)self.scaler.update()return loss.item()
2. 数据加载优化
# 优化的数据加载器
def create_optimized_dataloader(dataset, batch_size=1):return DataLoader(dataset,batch_size=batch_size,shuffle=True,num_workers=8, # 增加工作进程pin_memory=True, # 固定内存persistent_workers=True, # 持久化工作进程prefetch_factor=2 # 预取因子)
🎛️ 常见问题和解决方案
1. 内存不足
- 减少batch_size
- 使用梯度累积
- 启用梯度检查点
- 使用混合精度训练
2. 训练不稳定
- 调整学习率
- 使用梯度裁剪
- 检查数据质量
- 增加warmup步骤
3. 生成质量不佳
- 增加训练步数
- 检查文本-视频对齐
- 调整guidance_scale
- 增加推理步数