分布式专题——42 MQ常见问题梳理
1 MQ如何保证消息不丢失
1.1 哪些环节可能会丢失信息
-
MQ的消息传递链路:
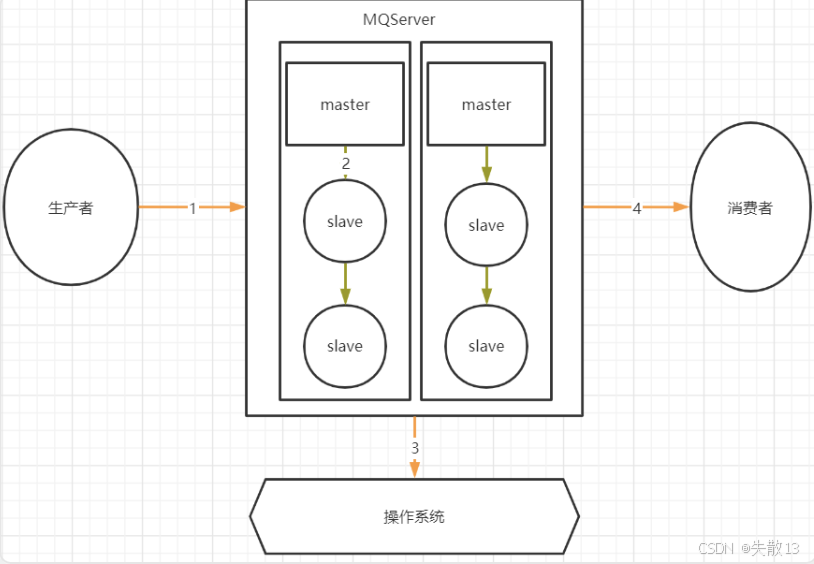
-
环节 1:生产者到 MQ Server。生产者向 MQ Server 发送消息时,此过程是跨网络的。由于网络存在不稳定性,比如网络延迟、中断等情况,消息可能在传输过程中丢失,无法成功到达 MQ Server;
-
环节 2:MQ Server 内部 master 到 slave。在 MQ Server 内部,master 节点向 slave 节点同步消息的过程也是跨网络的。网络问题可能导致消息在 master 到 slave 的同步过程中丢失,使得 slave 节点无法完整获取 master 节点的消息;
-
环节 3:MQ Server 到操作系统。MQ 存盘时,通常会先将消息写入操作系统的缓存(page cache),之后操作系统再异步地将消息写入硬盘。在这个过程中,存在时间差。如果 MQ 服务突然挂掉,缓存中还没来得及写入硬盘的消息就会丢失,因为缓存是基于内存的,服务挂掉后内存中的数据无法保留;
-
环节 4:MQ Server 到消费者。MQ Server 向消费者传递消息时,同样是跨网络的。网络故障等因素可能导致消息在传输到消费者的过程中丢失,消费者无法接收到该消息。
-
1.2 生产者发送消息如何保证不丢失
- 生产者发送消息可能因网络不稳定丢失,通用解决思路是生产者确认,即生产者发消息后,需得到Broker端消息写入完成的通知,不同MQ产品有不同实现方式;
1.2.1 各MQ产品的生产者发送消息确认机制
-
RocketMQ:提供三种发送消息方式
// 异步发送,无需Broker确认,效率高,但有丢消息风险 producer.sendOneway(msg); // 同步发送,生产者等待Broker确认,消息安全但效率低 SendResult sendResult = producer.send(msg, 20 * 1000); // 带回调的异步发送:生产者起线程等Broker确认,收到确认后触发回调方法,在消息安全和效率间较均衡,但加大客户端负担 producer.send(msg, new SendCallback() {@Overridepublic void onSuccess(SendResult sendResult) {// do something}@Overridepublic void onException(Throwable e) {// do something} }); -
Kafka:也有同步和异步发送机制
- 直接
send发送消息(Future<RecordMetadata> future = producer.send(record)):返回Future,属异步调用; - 调用
future.get()(RecordMetadata recordMetadata = producer.send(record).get();):会实际获取发送结果,使过程变为同步;
// 直接send发送消息,返回的是一个Future,属异步调用 Future<RecordMetadata> future = producer.send(record) // 调用future的get方法,会实际获取发送结果,使过程变为同步 RecordMetadata recordMetadata = producer.send(record).get(); - 直接
-
RabbitMQ:提供
Publisher Confirms生产者确认机制,思路是Publisher收到Broker响应后出发对应回调方法,可通过ch.addConfirmListener(ConfirmCallback ackCallback, ConfirmCallback nackCallback)添加处理ack和nack响应的回调;// 获取channel Channel ch = ...; // 添加两个回调,一个处理ack响应,一个处理nack响应 ch.addConfirmListener(ConfirmCallback ackCallback, ConfirmCallback nackCallback) -
这些不同API背后,都是让生产者知道消息是否发送成功,若未成功,由生产者自行补救(如重发或抛业务异常)。
1.2.2 RocketMQ的事务消息机制
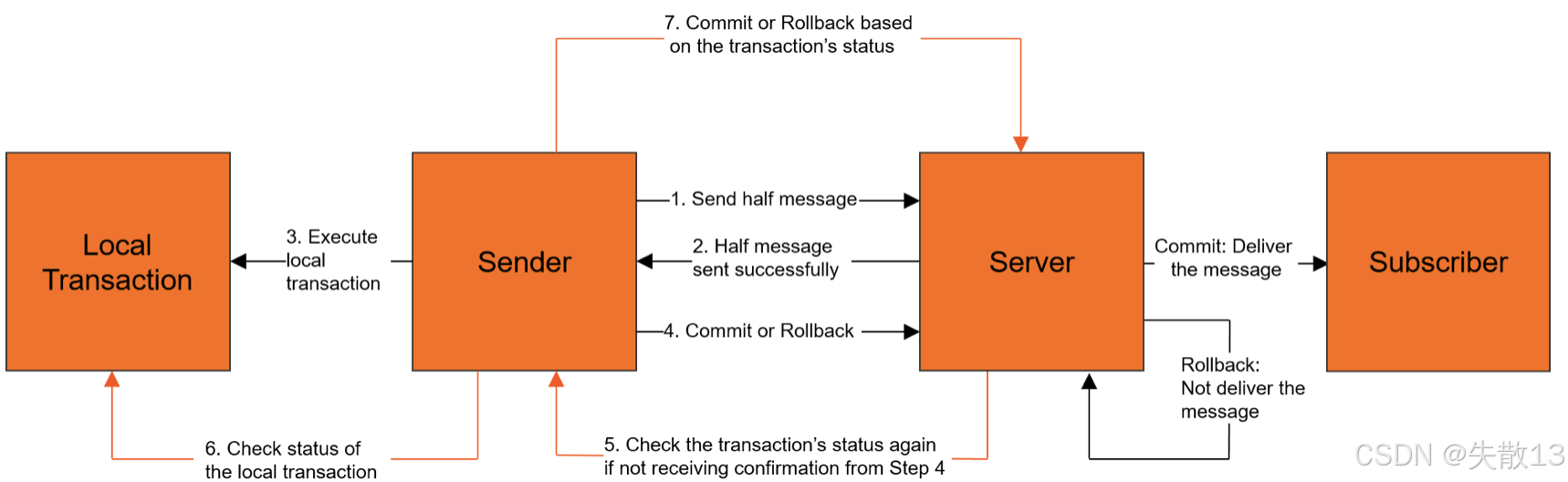
-
基本流程:
- Sender发送half message
- Server回复half message发送成功
- Sender执行本地事务
- Sender向Server提交Commit或Rollback
- 若Server未收到步骤4的确认,会再次检查事务状态
- Sender检查本地事务状态
- Server根据事务状态进行Commit(投递消息给Subscriber)或Rollback(不投递消息)
-
核心思想:
- RocketMQ的事务消息机制,还是基于生产者确认构建的一种实现机制,通过Broker主动触发生产者的回调方法,从而确认消息是否成功发送到了Broker;
- 不过此处将一次确认变为了多次确认,在这个过程中,除了确认消息的安全型,还给了生产者有“反悔”的机会;
- 另外,将生产者确认与生产者本地事务结合,使生产者确认机制更具业务属性;
-
电商订单场景示例:下单后到用户支付过程中使用事务消息机制,保证本地下单和第三方支付平台支付两个业务的事务性,要么同时成功(往下游发订单消息),要么同时失败(不往下游发订单消息);
- 具体流程为:
- 订单系统发送half消息到RocketMQ
- RocketMQ回复half消息
- 订单系统执行本地事务(MySQL下单)
- 订单系统返回本地事务状态给RocketMQ
- 若事务状态未确定,RocketMQ会进行状态回查
- 订单系统检查本地事务状态(如与支付系统对账)
- 订单系统返回本地事务检查状态给RocketMQ
- 最后,RocketMQ根据事务状态,Commit状态则事务提交并将消息发给下游服务,RollBack状态则事务丢弃
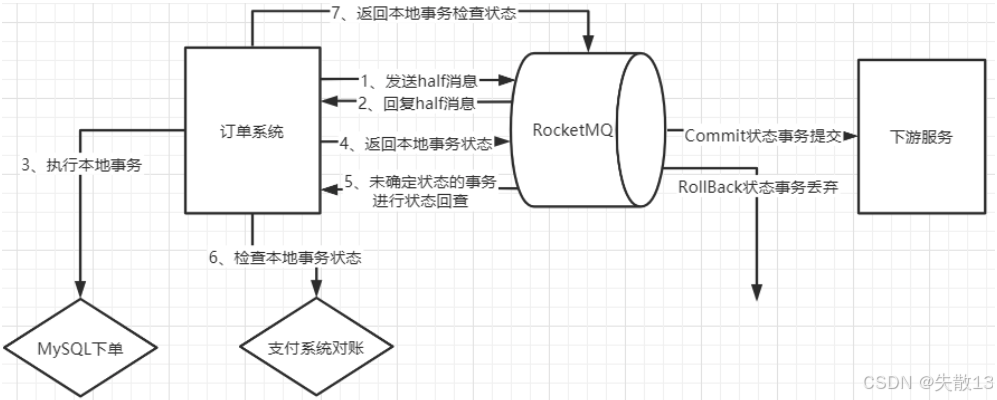
- 具体流程为:
1.3 Broker写入数据如何保证不丢失
-
Producer将消息发送到Broker后,Broker能否保证消息不丢失的核心问题在于PageCache缓存。数据会先写入缓存,之后再写入磁盘,但缓存数据断电即丢失,若服务器非正常断电且缓存数据未写入磁盘,就会造成消息丢失;
-
操作系统消息写入磁盘的过程:
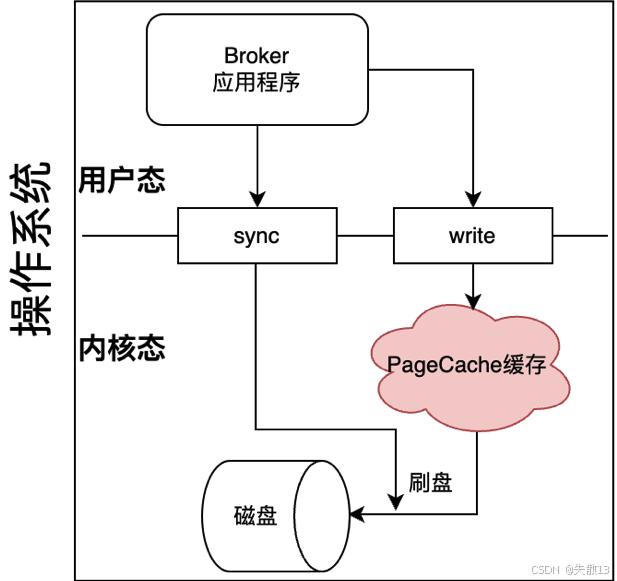
- 以Linux为例,用户态的Broker应用程序要写入磁盘文件,需调用操作系统的
write系统调用申请写磁盘; - 消息经PageCache再写入磁盘的过程在内核态执行,由操作系统自行处理。应用系统唯一能干预的是调用操作系统的
sync(或fsync等)系统调用,主动触发PageCache中的数据刷盘操作。
- 以Linux为例,用户态的Broker应用程序要写入磁盘文件,需调用操作系统的
-
各MQ产品对
fsync的调用方式-
RocketMQ:Broker提供
flushDiskType配置项选择刷盘模式,有SYNC_FLUSH(同步刷盘)和ASYNC_FLUSH(异步刷盘)两个选项- 同步刷盘:
- Broker每往日志文件写入一条消息,就调用一次刷盘操作,消息安全性高,但操作系统I/O压力大;
- 不过并不是真的写一次消息就刷盘一次,在海量消息的场景下,操作系统是撑不住的;
- 实际同步刷盘是按10毫秒间隔调用刷盘操作,仍有极小概率因断电丢消息,但能满足绝大部分业务场景;
- 异步刷盘:Broker每隔固定时间调用一次刷盘操作,性能更稳定,但有丢消息的可能;
- 同步刷盘:
-
Kafka:没有明显的同步刷盘和异步刷盘区别,而是暴露一系列参数管理刷盘频率:
flush.ms:多久进行一次强制刷盘;log.flush.interval.messages:当同一个Partition的消息条数积累到该数量时,申请一次刷盘操作,默认是Long.MAX;log.flush.interval.ms:当一个消息在内存中保留的时间达到该数量时,申请一次刷盘操作,默认值为空,若为空则生效下一个参数;log.flush.scheduler.interval.ms:检查是否有日志文件需要进行刷盘的频率,默认也是Long.MAX。并且若将log.flush.interval.messages参数设置成1,就相当于每写入一条消息就调用一次刷盘操作,即同步刷盘;
-
RabbitMQ:
- 对于Classic经典队列,即便声明为持久化队列,服务端也不会实时调用
fsync,无法保证服务端消息断电不丢失; - 对于Stream流式队列,RabbitMQ明确不会主动调用
fsync进行刷盘,交由操作系统自行刷盘;
- 对于Classic经典队列,即便声明为持久化队列,服务端也不会实时调用
-
-
若对消息安全性有更高要求,可使用
Publisher Confirms机制进一步保证消息安全,这一建议同样适用于Kafka和RocketMQ。
1.4 Broker主从同步如何保证不丢失
-
Broker的Slave(从节点)用于数据备份,当Broker服务或磁盘故障时,可从Slave获取数据。但主从同步失败会导致消息丢失,因此需关注主从同步的可靠性,重点讨论RocketMQ的普通集群和Dledger高可用集群,以及对比Kafka的集群机制;
-
RocketMQ普通集群方案:
-
节点角色配置:通过
brokerRole配置节点角色,有ASYNC_MASTER(异步同步主节点)、SYNC_MASTER(同步同步主节点)、SLAVE(从节点)三种; -
Master挂后不将Slave切换成Master:消息从Master同步到Slave存在网络延迟,若Master非正常崩溃,可能有部分数据已写入Master但未同步到Slave。在该集群机制下,这些数据会记录在Master节点,待Master重启后继续同步。且Slave不会主动切换为Master,Master崩溃后无新消息写入,不会有消息冲突问题。只要Master磁盘未损坏,主从同步通常不会造成消息丢失;
-
-
Kafka集群机制对比:
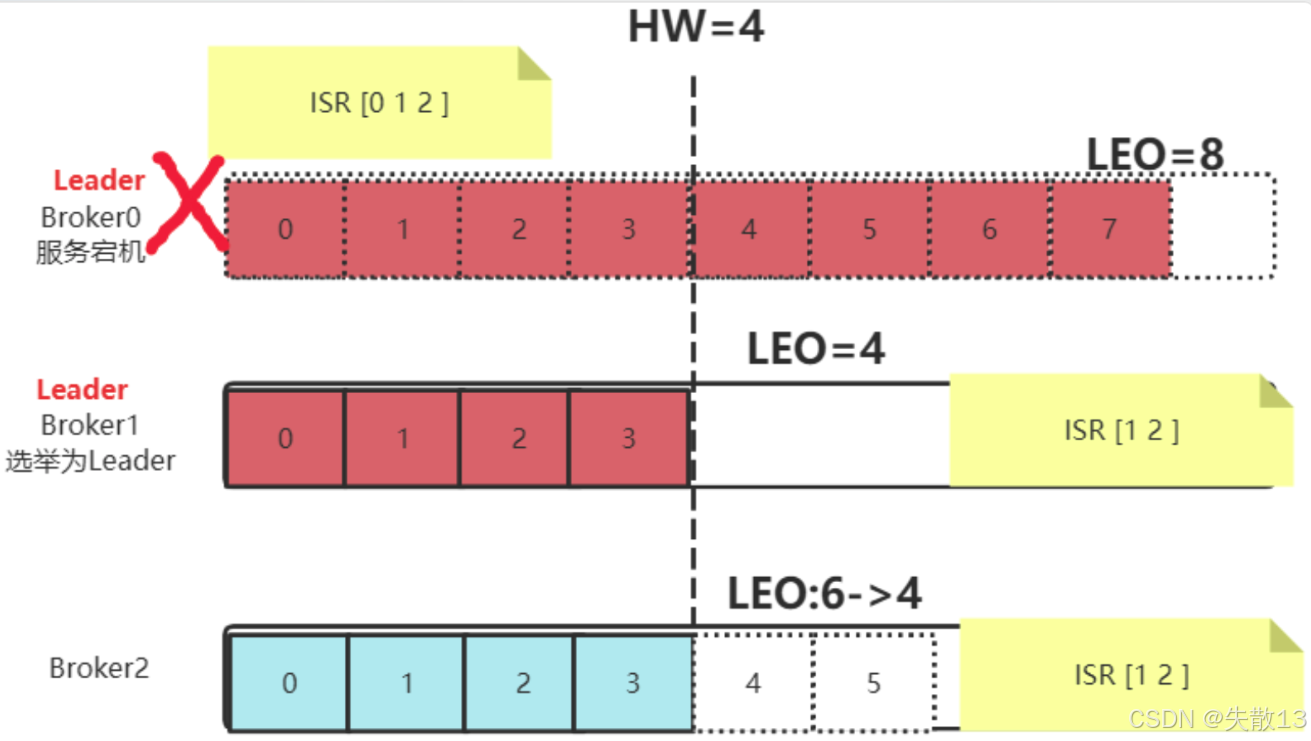
- 在Kafka集群中,若Leader Partition(主分区)的服务崩溃,Follower Partition(从分区)会选举产生新的Leader Partition,集群中所有消息以新Leader Partition的数据为准;
- 旧Leader Partition重启后会作为Follower Partition,主动删除自身HighWater之后的数据,再从新Leader Partition重新同步消息,这会导致已写入旧Leader Partition但未同步的消息彻底丢失;
- 这种差异源于RocketMQ和Kafka处理MQ问题的初衷不同,RocketMQ诞生于阿里金融体系,对消息安全性敏感;Kafka诞生于LinkedIn日志收集体系,对服务可用性要求更高,体现了不同产品对业务的取舍;
-
RocketMQ的Dledger高可用集群方案:
-
核心机制:使用基于Raft协议的Dledger来保存CommitLog消息日志,消息通过Dledger的Raft协议在主从节点之间同步;
-
两阶段提交CommitLog:确保消息能被大多数节点同步。Raft协议是基于两阶段的多数派同意机制,每个节点将客户端指令以Entry形式保存到自己的Log日志中(此时Entry为uncommited状态),当多数节点都保存该Entry后,执行Entry中的客户端指令并提交到StateMachine状态机(此时Entry更新为commited状态);
-
Raft协议优先保证集群内数据一致性,而非绝对不丢失。在网络分区等极端场景下,可能丢失未经过集群内确认的消息,但基于RocketMQ的使用场景,这种情况发生概率极小。结合客户端的生产者确认机制,可较好处理服务端无法保证消息安全的问题,因此在RocketMQ中使用Dledger集群,数据主从同步过程的数据安全性较高,基本可认为不会造成消息丢失。
-
1.5 消费者消费消息如何不丢失
-
几乎所有MQ产品都设置了消费状态确认机制:
- 消费者处理完消息后,需给Broker一个响应,表示消息被正常处理。若Broker端没拿到该响应(不管是Consumer没拿到消息,还是Consumer处理完消息后没给出响应),Broker会认为消息没处理成功,之后会向Consumer重复投递这些没处理成功的消息;
- 其中,RocketMQ和Kafka是根据Offset机制重新投递,RabbitMQ的Classic Queue经典队列则是把消息重新入队。正常情况下,Consumer消费消息的过程不会造成消息丢失,反而可能需要考虑消息重复等问题;
-
消费者消费消息可能丢失的情况:
-
当Consumer异步处理消息时,就有可能造成消息丢失。比如下面代码示例中,
consumer.registerMessageListener注册的监听器里,开启新线程异步处理业务逻辑,然后直接返回ConsumeConcurrentlyStatus.CONSUME_SUCCESS。此时,若异步处理逻辑还没完成,就向Broker返回了消费成功的状态,Broker会认为消息已成功消费,若后续异步处理出现问题(如线程异常等),消息就丢失了;consumer.registerMessageListener(new MessageListenerConcurrently{@Overridepublic ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> msgs, ConsumeConcurrentlyContext context) {new Thread(){public void run(){//处理业务逻辑System.out.printf("Receive New Messages");}};return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;}); -
同时,开发中虽不太会直白地用多线程异步机制处理,但可能在使用第三方框架处理消息时,第三方框架采用了多线程异步机制,这种情况下也可能出现类似消息丢失的风险,所以线程并发知识在任何业务场景下都是必备的基本功。
-
1.6 如果MQ服务全部挂了,如何保证不丢失
-
在MQ服务全部挂掉的极端小概率情况下,为保证业务稳定进行且业务数据不丢失,通常的做法是设计降级缓存;
-
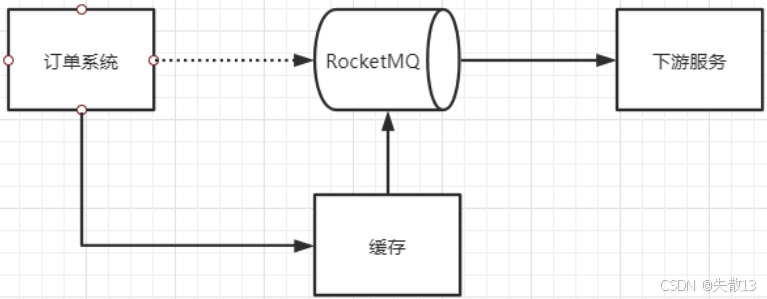
当Producer往MQ发消息失败时,就将消息写入降级缓存,之后仍正常进行后续业务。同时,启动一个线程,不断尝试将降级缓存中的数据往MQ中发送。这样,当MQ服务恢复后,这些消息能尽快进入MQ,继续往下游Consumer推送,从而避免消息丢失
-
下图以订单系统为例:订单系统向RocketMQ发消息,若失败则写入缓存,待MQ恢复后,缓存中的消息再发送到RocketMQ,进而传递给下游服务;
1.7 MQ消息零丢失方案总结
-
以上各种MQ消息防止丢失的方案,都以增加集群负载、降低吞吐为代价,会导致集群效率下降,所以需根据业务场景灵活取舍,而非直接全盘采用;
-
各环节消息零丢失方案及代价
-
生产者发送消息到MQ
- 同步发送 + 多次尝试:能提升消息发送可靠性,但会降低系统吞吐
- 事务消息机制:需多次网络请求,增加网络交互开销
-
Broker收到消息后消息不丢失
- 设置同步刷盘:可保证消息写入磁盘的安全性,但会加重I/O负担
- 搭建Dledger集群:借助Raft协议等保障数据一致性,会增加网络负担
-
消费者消费消息不丢失:采用同步处理消息,再提交offset的方式,能确保消息消费被正确记录,但无法通过异步方式提高吞吐;
-
整个MQ集群挂了,如何不丢失消息:增加临时的降级存储,在MQ集群故障时暂存消息,待集群恢复后再发送消息;
-
-
这些消息零丢失方案没有最优解,因为若有最优解,MQ产品就无需保留多样设计了。实际业务中,需根据具体业务场景调整,并非如面试八股文那样有固定标准答案。
2 MQ如何保证消息的顺序性
-
通常讨论MQ的消息顺序性,强调的是局部有序,而非全局有序。比如QQ和微信的聊天消息,只需保证同一个聊天窗口内的消息严格有序,不同窗口间消息顺序有偏差无关紧要,全局有序在业务上使用场景不多,像RocketMQ和Kafka把Topic的分区数设为1来强行保证全局有序的方案,不太符合实际业务需求;
-
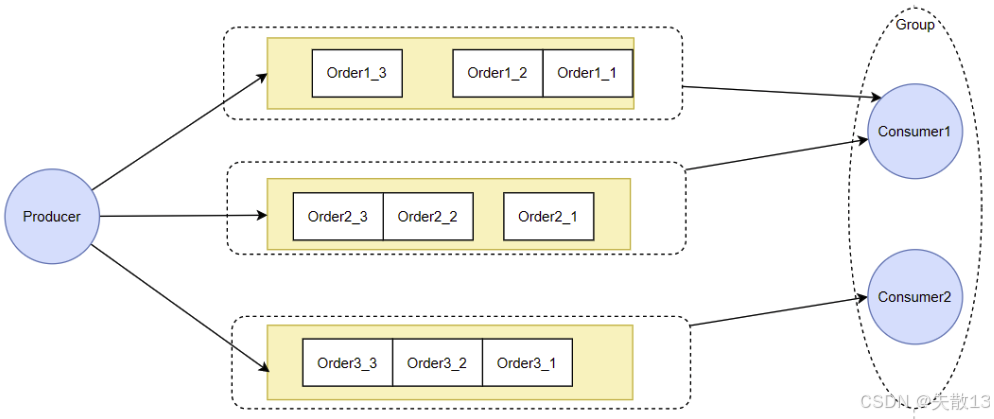
要保证消息局部有序,典型的是RocketMQ的顺序消费机制,该机制需要两方面保障:
-
Producer端:将一组有序的消息写入到同一个MessageQueue中
- RocketMQ和Kafka都提供分区计算机制,让应用程序自行决定消息写入的分区,业务可通过定制数据分片算法,把一组局部有序的消息发到同一个队列,利用队列的FIFO特性保证处理顺序;
- RabbitMQ可通过维护Exchange与Queue之间的绑定关系,将一组局部有序的消息转发到同一个队列,保证内部存储有序;
-
Consumer端:每次集中从一个MessageQueue中拿取消息
- RocketMQ通过让Consumer注入不同的消息监听器,对消费线程进行并发控制来保证消费顺序;
- Kafka的Consumer对某一个Partition拉取消息时天生是单线程的,所以天生能保证局部顺序消费;
- RabbitMQ的Classic Queue经典队列,若一个队列只对应一个Consumer,消息被一个Consumer从队列拉取后直接删除,不存在资源竞争,能保证顺序消费;
- 若一个队列对应多个Consumer,同批消息可能进入不同Consumer处理,无法保证消费顺序。
-
3 MQ如何保证消息幂等性
3.1 生产者发送消息如何保持幂等性
-
Producer发送消息时,若采用发送者确认机制,会等待Broker响应。若未收到响应,Producer会重试,但可能存在Broker已正常处理消息,只是响应丢失的情况,此时重试会造成消息重复;
-
RocketMQ保证幂等的方式:
-
RocketMQ在发送消息时,会给每条消息分配一个唯一的ID;
//org.apache.rocketmq.client.impl.producer.DefaultMQProducerImpl#sendKernelImpl //for MessageBatch,ID has been set in the generating process if (!(msg instanceof MessageBatch)) {MessageClientIDSetter.setUniqID(msg); }public static void setUniqID(final Message msg) {if (msg.getProperty(MessageConst.PROPERTY_UNIQ_CLIENT_MESSAGE_ID_KEYIDX) == null) {msg.putProperty(MessageConst.PROPERTY_UNIQ_CLIENT_MESSAGE_ID_KEYIDX, createUniqID());} } -
通过该ID可判断消息是否重复投递,上面代码中,在
DefaultMQProducerImpl#sendKernelImpl方法里,对非MessageBatch类型的消息,会调用MessageClientIDSetter.setUniqID方法设置唯一ID,若消息属性中无唯一客户端消息ID键值,就生成并设置;
-
-
Kafka保证幂等的方式
-
Kafka通过幂等性配置防止生产者重复投递消息。为保证消息发送的Exactly - once语义,涉及以下概念:
-
PID:每个新Producer初始化时会分配一个唯一的PID,对用户不可见;
-
Sequence Number:每个PID针对Partition会维护一个从0开始单调递增的
Sequence Number,Producer往同一Partition发消息时,该序号加1并随消息发往Broker; -
Broker端序列号(SN):Broker针对每个
<PID, Partition>维护序列号SN,只有当对应的Sequence Number = SN + 1时,Broker才接收消息并将SN更新为SN + 1;若Sequence Number过小,认为消息已写入,无需重复写入;若Sequence Number过大,认为中间可能有数据丢失,会抛出OutOfOrderSequenceException;
-
-
Kafka幂等性的流程示例(结合图示)
-
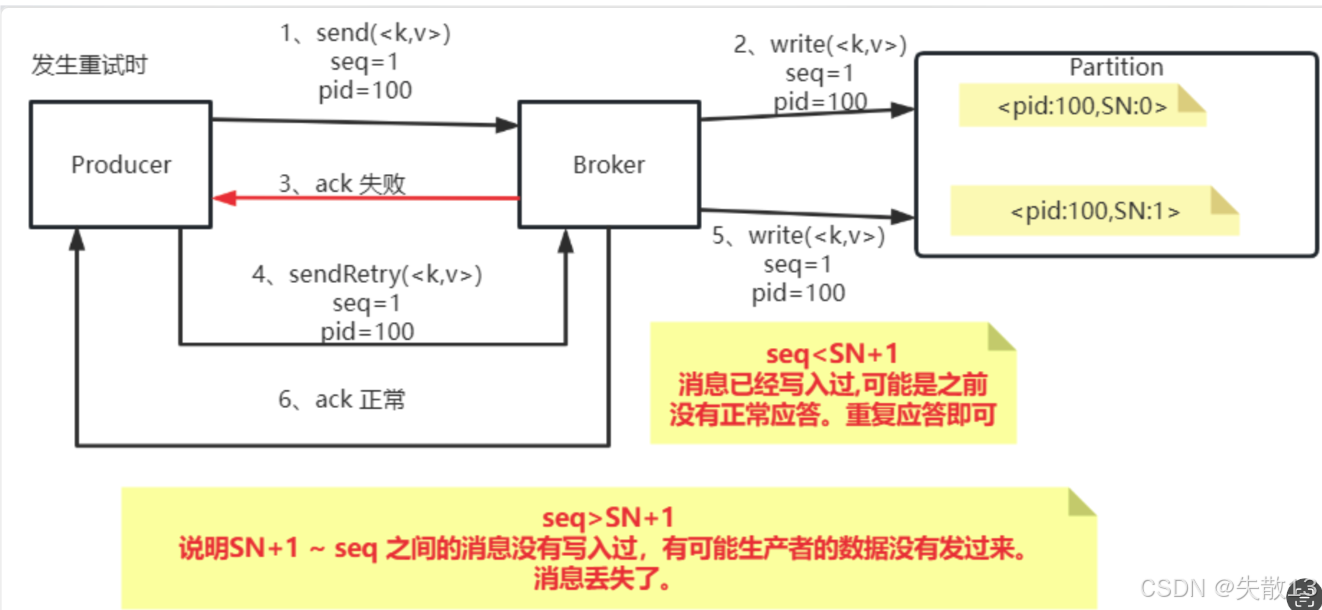
正常流程:Producer发送
<k, v>,seq = 1,pid = 100;Broker写入后,维护<pid:100, SN:1>; -
重试场景:
- 若
seq < SN + 1(如重试时seq = 1,SN = 1,则seq = SN),说明消息已写入过,可能是之前响应正常但Producer没收到,重复应答即可; - 若
seq > SN + 1,说明SN + 1到seq之间的消息没写入过,可能生产者数据没发过来,存在消息丢失情况;
- 若
-
-
3.2 消费者消费消息如何保持幂等性
-
以RocketMQ为例,如何防止消费者多次重复消费同一条消息?RocketMQ官网明确,消息至少传递一次,大多数情况下不会重复,但存在小概率重复情况,比如网络波动时,Consumer从Broker获取消息正常处理后,向Broker返回响应因网络波动丢失,Broker会认为消息未处理成功,向该Consumer所在Group重复投递消息,从而导致重复消费;
-
防止重复消费的关键是找到唯一性指标:
-
通常情况:RocketMQ内部会给每条消息分配唯一的
messageId,Consumer可获取该messageId,记录已处理过的messageId,以此判断消息之前是否处理过; -
特殊情况(批量发送、事务消息机制发送):
messageId不好控制,更建议根据业务场景确定唯一指标。例如电商下单场景,订单ID是带有业务属性的好的唯一指标,可使用message的key属性传递订单ID,Consumer据此防止重复消费;
-
-
除防止重复消费外,还需防止消费丢失(Consumer一直未正常消费消息)
- 在RocketMQ中,重复投递的消息会放到以消费者组为维度的重试队列,若多次重试仍无法正常消费,最终会进入消费者组对应的死信队列;
- 出现死信队列意味着一批消费者逻辑有问题,需单独维护一个消费者,对死信队列中的错误业务消息进行补充处理。且RocketMQ的死信队列默认权限无法消费,需手动调整权限才能正常消费。
4 MQ如何快速处理积压的消息
4.1 消息积压的问题
- RocketMQ与Kafka:二者消息积压能力较强,短时间积压无大问题。但若积压问题长期不解决,当日志文件过期后,RocketMQ和Kafka会直接删除过期日志文件,未消费的消息也会随之丢失;
- RabbitMQ:
- Classic Queue(经典队列)和Quorum Queue(仲裁队列)若有大量消息积压且未被消费,会严重影响服务端性能,需重点关注;
- Stream Queue(流式队列)处理机制与RocketMQ、Kafka较相似,对消息积压承受能力较强,但仍需注意和RocketMQ、Kafka相同的日志文件过期导致消息丢失的问题。
4.2 大量积压消息的处理方法
-
产生消息积压的根本原因是Consumer处理消息效率低,核心目标是提升Consumer消费消息的效率。若无法从业务上提升Consumer消费性能,最直接的办法是针对处理消息慢的消费者组,增加更多Consumer实例,但要注意增加Consumer实例是否有上限;
-
对于RabbitMQ的Classic Queue:针对同一个Queue的多个消费者,按Work Queue模式在多个Consumer间依次分配消息。若Consumer消费能力不足,可直接增加Consumer实例;若各Consumer实例运行环境或处理消息速度有差别,可优化每个Consumer的比重(QoS属性),以充分发挥Consumer实例性能;
-
对于RocketMQ:
- 同一个消费者组下的多个Consumer需和对应Topic下的MessageQueue建立对应关系,且一个MessageQueue最多只能被一个Consumer消费。因此,增加的Consumer实例最多只能和Topic下的MessageQueue个数相同,若继续增加,多余的Consumer实例因无MessageQueue可消费而无用;
- 若Topic下的MessageQueue配置较少,无法一直增加Consumer节点个数,可创建新Topic并配置足够多的MessageQueue,将Consumer实例的Topic转向新Topic,紧急上线一组新消费者,只负责消费旧Topic中的消息并转存到新Topic中(该过程处理速度比普通Consumer处理业务逻辑快很多),之后在新Topic上通过添加消费者个数提高消费速度,再根据情况考虑是否恢复正常。这种思路与RocketMQ内部固定级别的延迟消息机制类似(把消息临时转到系统内部Topic,处理后再转回来);
-
对于Kafka:可采用与RocketMQ相似的处理方式。