【完整源码+数据集+部署教程】管道与支架检测系统源码和数据集:改进yolo11-RepNCSPELAN
背景意义
研究背景与意义
在现代工业中,管道与支架的检测与维护是确保生产安全和效率的重要环节。随着工业自动化和智能化的不断发展,传统的人工检测方法逐渐暴露出效率低、成本高和误差大的问题。因此,开发基于计算机视觉的自动检测系统成为了行业亟待解决的课题。近年来,深度学习技术的迅猛发展为这一领域带来了新的机遇,尤其是目标检测算法的进步,使得自动化检测的精度和效率得到了显著提升。
YOLO(You Only Look Once)系列算法因其快速且高效的特性,成为了目标检测领域的热门选择。YOLOv11作为该系列的最新版本,结合了多种先进的技术和优化策略,具备了更强的特征提取能力和更高的检测精度。然而,针对特定工业场景的改进仍然是必要的,尤其是在管道与支架的检测任务中。针对这一需求,本研究提出了一种基于改进YOLOv11的管道与支架检测系统,旨在提升检测的准确性和实时性。
本研究所使用的数据集包含2408张经过精心标注的图像,涵盖了两类主要对象:Brida(支架)和Tuberias(管道)。通过对数据集的预处理和增强,包括随机旋转、亮度调整和噪声添加等手段,确保了模型在多样化场景下的鲁棒性。这些措施不仅提升了模型的泛化能力,也为后续的训练和测试提供了丰富的样本。
通过本项目的实施,期望能够为管道与支架的自动检测提供一种高效、准确的解决方案,从而降低人工成本,提高检测效率,最终推动工业智能化的发展。这一研究不仅具有重要的理论意义,也为实际应用提供了可行的技术路径,具有广泛的应用前景。
图片效果
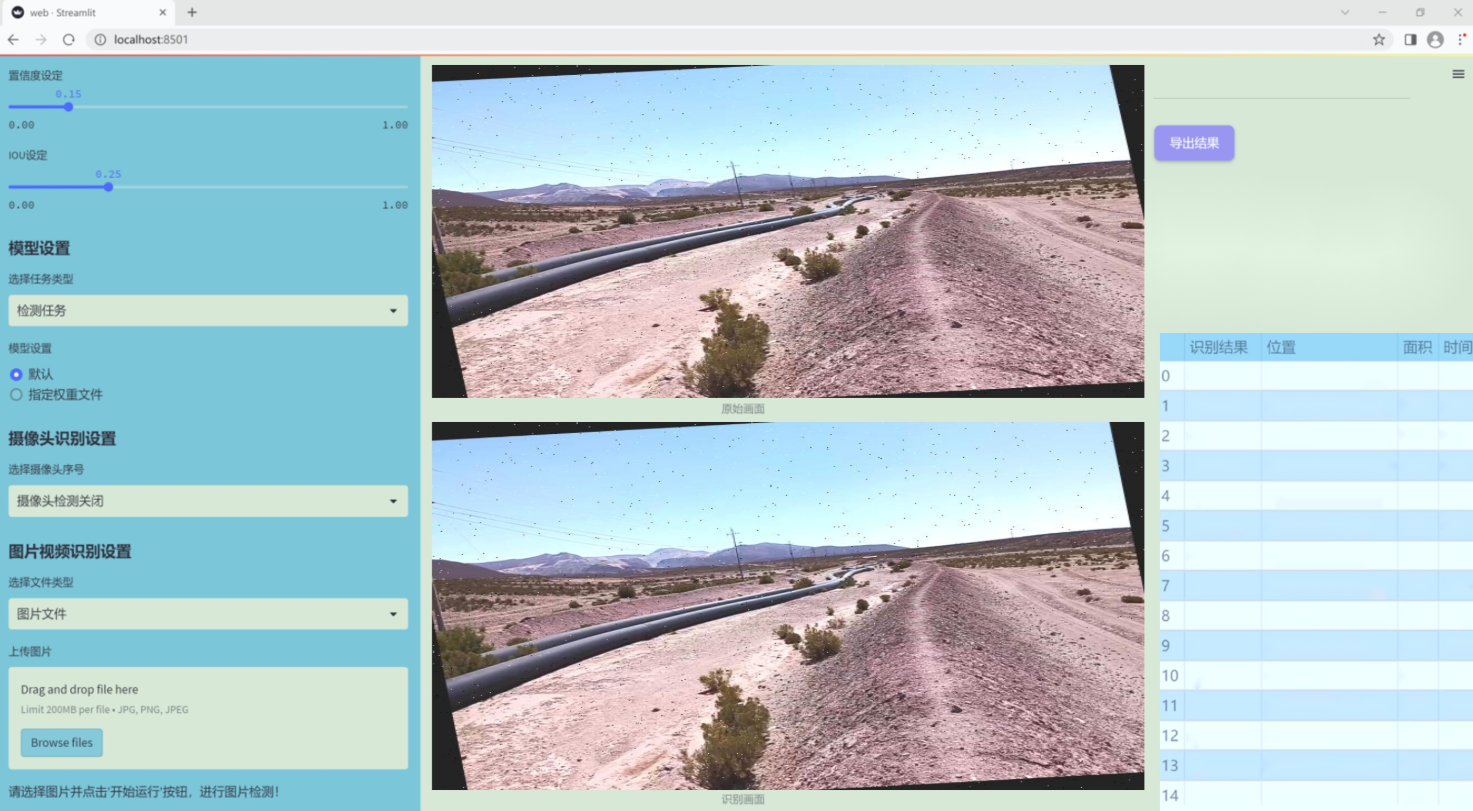
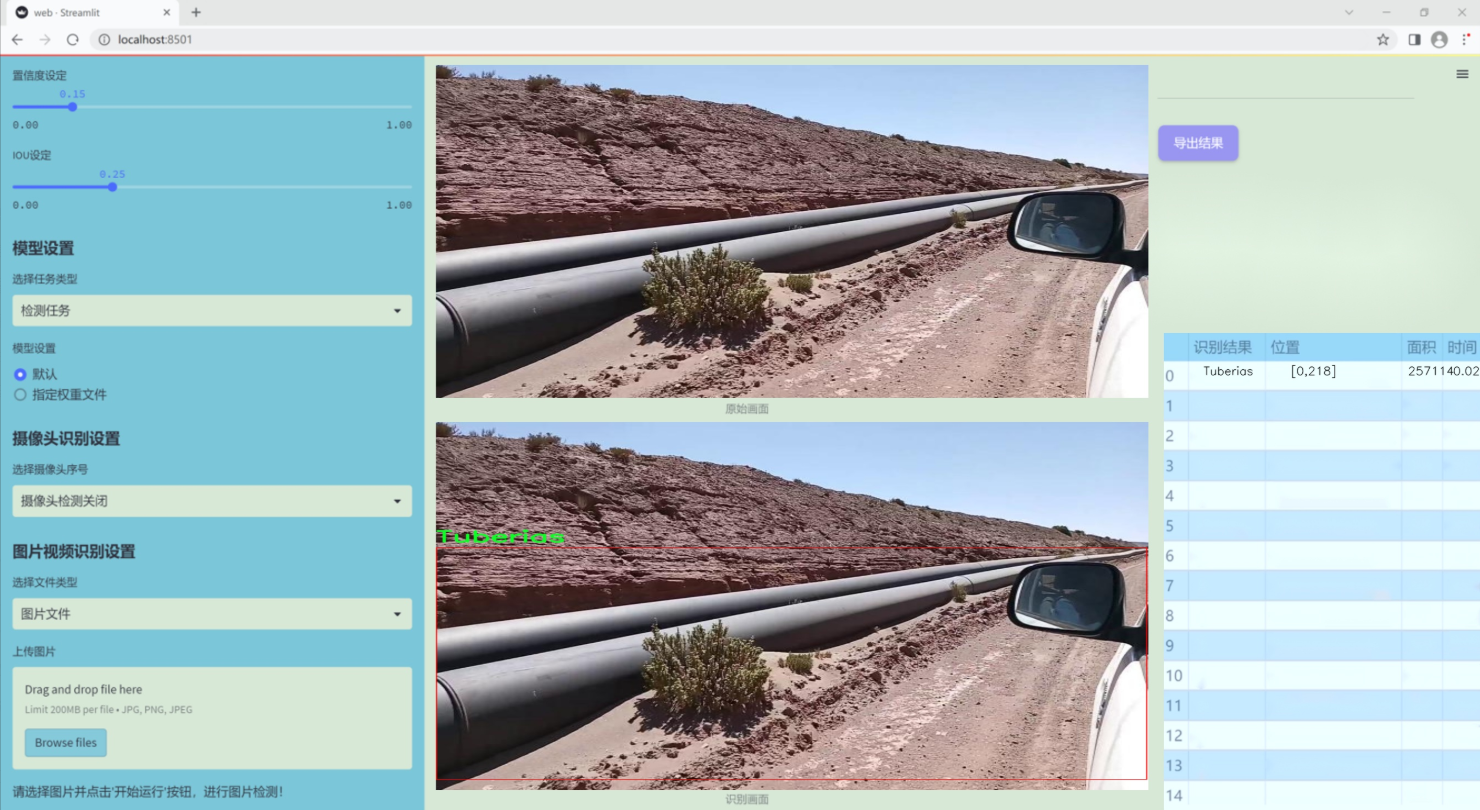
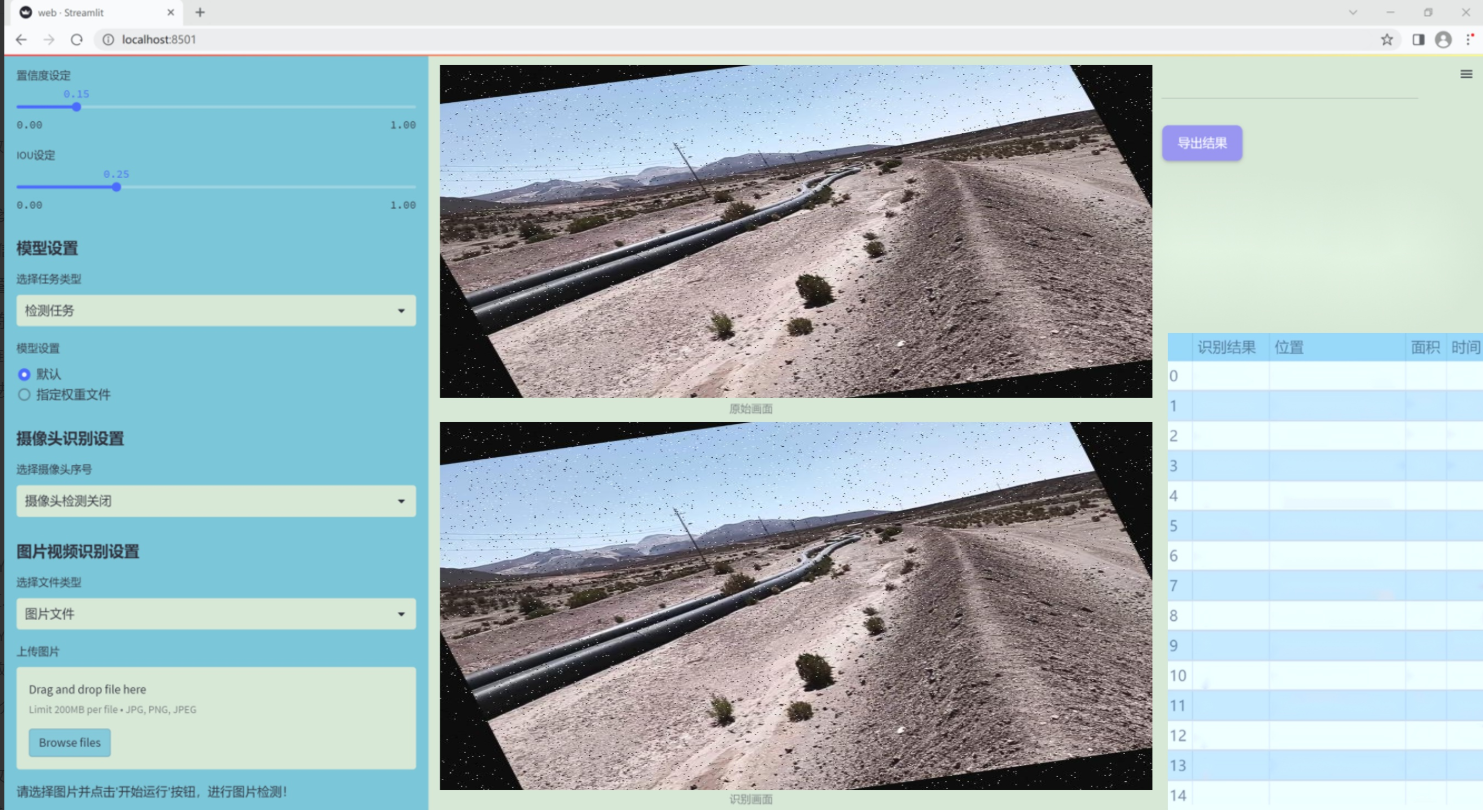
数据集信息
本项目数据集信息介绍
本项目所使用的数据集专注于管道与支架检测,旨在为改进YOLOv11的检测系统提供高质量的训练数据。数据集包含两个主要类别,分别为“Brida”(法兰)和“Tuberias”(管道),这些类别的选择反映了在工业环境中管道系统的重要组成部分。数据集的设计旨在涵盖各种实际应用场景,以确保模型在不同条件下的鲁棒性和准确性。
在数据收集过程中,我们采用了多种方法获取图像,包括现场拍摄和现有图像库的整合。所有图像均经过精心标注,确保每个实例的准确性,以便为YOLOv11模型提供清晰的学习目标。数据集中包含了多种角度、光照条件和背景环境下的图像,以模拟真实世界中可能遇到的各种情况。这种多样性有助于模型在实际应用中表现出更好的泛化能力。
此外,数据集还考虑了不同尺寸和形状的管道及法兰,以便于模型学习到更为丰富的特征。这些特征不仅包括物体的外观,还涵盖了其在特定环境中的相对位置和空间关系。通过这样的设计,我们希望能够提升YOLOv11在管道与支架检测任务中的性能,使其能够更准确地识别和定位目标物体。
总之,本项目的数据集为改进YOLOv11的管道与支架检测系统提供了坚实的基础,涵盖了多样化的场景和实例,以支持模型的训练和优化。通过对“Brida”和“Tuberias”这两个类别的深入研究,我们期望能够在实际应用中实现更高的检测精度和效率,为相关行业的智能化发展贡献力量。





核心代码
以下是代码中最核心的部分,并附上详细的中文注释:
import torch
import torch.nn as nn
from typing import List
from torch import Tensor
class Partial_conv3(nn.Module):
“”"
定义部分卷积层,用于在特定通道上进行卷积操作。
“”"
def init(self, dim, n_div, forward):
super().init()
self.dim_conv3 = dim // n_div # 计算需要进行卷积的通道数
self.dim_untouched = dim - self.dim_conv3 # 计算未改变的通道数
self.partial_conv3 = nn.Conv2d(self.dim_conv3, self.dim_conv3, 3, 1, 1, bias=False) # 定义卷积层
# 根据forward类型选择前向传播方式if forward == 'slicing':self.forward = self.forward_slicingelif forward == 'split_cat':self.forward = self.forward_split_catelse:raise NotImplementedErrordef forward_slicing(self, x: Tensor) -> Tensor:# 仅用于推理阶段x = x.clone() # 保持原始输入不变,以便后续的残差连接x[:, :self.dim_conv3, :, :] = self.partial_conv3(x[:, :self.dim_conv3, :, :]) # 对部分通道进行卷积return xdef forward_split_cat(self, x: Tensor) -> Tensor:# 用于训练和推理阶段x1, x2 = torch.split(x, [self.dim_conv3, self.dim_untouched], dim=1) # 按通道分割输入x1 = self.partial_conv3(x1) # 对分割出的部分进行卷积x = torch.cat((x1, x2), 1) # 将卷积后的部分和未改变的部分拼接return x
class MLPBlock(nn.Module):
“”"
定义多层感知机(MLP)块,包含卷积、归一化和激活函数。
“”"
def init(self, dim, n_div, mlp_ratio, drop_path, layer_scale_init_value, act_layer, norm_layer, pconv_fw_type):
super().init()
self.dim = dim
self.mlp_ratio = mlp_ratio
self.drop_path = nn.Identity() if drop_path <= 0 else DropPath(drop_path) # 根据drop_path值选择是否使用DropPath
self.n_div = n_div
mlp_hidden_dim = int(dim * mlp_ratio) # 计算MLP隐藏层的维度# 定义MLP层mlp_layer: List[nn.Module] = [nn.Conv2d(dim, mlp_hidden_dim, 1, bias=False),norm_layer(mlp_hidden_dim),act_layer(),nn.Conv2d(mlp_hidden_dim, dim, 1, bias=False)]self.mlp = nn.Sequential(*mlp_layer) # 将MLP层组合成序列# 定义空间混合层self.spatial_mixing = Partial_conv3(dim, n_div, pconv_fw_type)def forward(self, x: Tensor) -> Tensor:shortcut = x # 保存输入以进行残差连接x = self.spatial_mixing(x) # 进行空间混合x = shortcut + self.drop_path(self.mlp(x)) # 添加残差连接并应用DropPathreturn x
class FasterNet(nn.Module):
“”"
定义FasterNet模型,包含多个阶段和嵌入层。
“”"
def init(self, in_chans=3, num_classes=1000, embed_dim=96, depths=(1, 2, 8, 2), mlp_ratio=2., n_div=4,
patch_size=4, patch_stride=4, patch_size2=2, patch_stride2=2, patch_norm=True, drop_path_rate=0.1,
layer_scale_init_value=0, norm_layer=‘BN’, act_layer=‘RELU’, pconv_fw_type=‘split_cat’):
super().init()
# 选择归一化层和激活函数norm_layer = nn.BatchNorm2d if norm_layer == 'BN' else NotImplementedErroract_layer = partial(nn.ReLU, inplace=True) if act_layer == 'RELU' else NotImplementedErrorself.num_stages = len(depths) # 模型阶段数self.embed_dim = embed_dim # 嵌入维度self.mlp_ratio = mlp_ratio # MLP比率# 图像分块嵌入self.patch_embed = PatchEmbed(patch_size=patch_size, patch_stride=patch_stride, in_chans=in_chans,embed_dim=embed_dim, norm_layer=norm_layer if patch_norm else None)# 构建各个阶段stages_list = []for i_stage in range(self.num_stages):stage = BasicStage(dim=int(embed_dim * 2 ** i_stage), n_div=n_div, depth=depths[i_stage],mlp_ratio=self.mlp_ratio, drop_path=[drop_path_rate] * depths[i_stage],layer_scale_init_value=layer_scale_init_value, norm_layer=norm_layer,act_layer=act_layer, pconv_fw_type=pconv_fw_type)stages_list.append(stage)# 添加分块合并层if i_stage < self.num_stages - 1:stages_list.append(PatchMerging(patch_size2=patch_size2, patch_stride2=patch_stride2,dim=int(embed_dim * 2 ** i_stage), norm_layer=norm_layer))self.stages = nn.Sequential(*stages_list) # 将所有阶段组合成序列def forward(self, x: Tensor) -> Tensor:# 输出四个阶段的特征x = self.patch_embed(x) # 嵌入层处理输入outs = []for stage in self.stages:x = stage(x) # 通过每个阶段outs.append(x) # 收集输出return outs
代码核心部分说明:
Partial_conv3:实现了部分卷积的功能,可以选择不同的前向传播方式(切片或拼接)。
MLPBlock:构建了一个多层感知机块,包含卷积、归一化和激活函数,并实现了残差连接。
FasterNet:定义了整个网络结构,包含多个阶段的处理,每个阶段由多个MLPBlock组成,并且在不同阶段之间进行特征的合并和处理。
这些核心部分共同构成了FasterNet模型的基础,能够进行图像特征提取和处理。
这个程序文件 fasternet.py 实现了一个名为 FasterNet 的深度学习模型,主要用于图像处理任务。文件中使用了 PyTorch 框架,并且包含了一些自定义的神经网络模块。以下是对代码的详细讲解。
首先,文件导入了一些必要的库,包括 PyTorch、YAML 和一些用于构建神经网络的模块。接着,定义了一些辅助类和函数,这些类和函数构成了 FasterNet 模型的基础。
Partial_conv3 类是一个自定义的卷积层,支持两种前向传播方式:slicing 和 split_cat。在 slicing 模式下,输入的部分通道会经过卷积处理,而在 split_cat 模式下,输入会被分割成两部分,经过卷积处理的部分与未处理的部分再合并。这种设计使得模型在训练和推理时可以灵活处理输入数据。
MLPBlock 类实现了一个多层感知机(MLP)模块,包含了一个卷积层、归一化层、激活函数和另一个卷积层。该模块支持可选的层级缩放,以便在训练过程中调整输出的特征。
BasicStage 类由多个 MLPBlock 组成,构成了模型的基本阶段。每个阶段会处理输入特征并输出结果。
PatchEmbed 类用于将输入图像分割成不重叠的补丁,并通过卷积层进行嵌入。PatchMerging 类则用于将特征图的补丁合并,以减少特征图的尺寸并增加通道数。
FasterNet 类是整个模型的核心,初始化时会设置输入通道数、类别数、嵌入维度、深度等参数。模型的结构由多个阶段(BasicStage)和补丁合并层(PatchMerging)组成。模型的前向传播方法会依次通过补丁嵌入和各个阶段,最终输出多个阶段的特征图。
此外,文件中还定义了一些函数用于加载模型权重,例如 update_weight 函数用于更新模型的权重字典,确保模型的权重与预训练权重相匹配。fasternet_t0、fasternet_t1、fasternet_t2 等函数则用于根据配置文件和可选的权重加载不同版本的 FasterNet 模型。
在文件的最后部分,包含了一个主程序块,用于测试模型的加载和输入输出的尺寸。通过创建一个 FasterNet 实例并传入随机生成的输入数据,程序会打印出每个阶段输出的特征图的尺寸。
总的来说,这个文件实现了一个灵活且高效的深度学习模型,适用于图像处理任务,具备多种配置和加载预训练权重的能力。
10.4 test_selective_scan.py
以下是经过简化和注释的核心代码部分,主要保留了 build_selective_scan_fn 函数及其内部的 SelectiveScanFn 类。代码中的注释详细解释了每个部分的功能和目的。
import torch
import torch.nn.functional as F
def build_selective_scan_fn(selective_scan_cuda: object = None, mode=“mamba_ssm”, tag=None):
“”"
构建选择性扫描函数,返回一个可用于前向和反向传播的自定义函数。
参数:
selective_scan_cuda: 选择性扫描的CUDA实现
mode: 模式选择,决定使用的算法
tag: 额外的标记信息
"""class SelectiveScanFn(torch.autograd.Function):@staticmethoddef forward(ctx, u, delta, A, B, C, D=None, z=None, delta_bias=None, delta_softplus=False, return_last_state=False, nrows=1, backnrows=-1):"""前向传播函数,计算选择性扫描的输出。参数:ctx: 上下文对象,用于保存状态u: 输入张量delta: 变化率张量A, B, C: 权重张量D: 可选的偏置张量z: 可选的张量delta_bias: 可选的变化率偏置delta_softplus: 是否使用softplus激活return_last_state: 是否返回最后状态nrows: 行数参数backnrows: 反向传播行数参数返回:out: 输出张量last_state: 最后状态(可选)"""# 确保输入张量是连续的if u.stride(-1) != 1:u = u.contiguous()if delta.stride(-1) != 1:delta = delta.contiguous()if D is not None:D = D.contiguous()if B.stride(-1) != 1:B = B.contiguous()if C.stride(-1) != 1:C = C.contiguous()if z is not None and z.stride(-1) != 1:z = z.contiguous()# 处理B和C的维度if B.dim() == 3:B = rearrange(B, "b dstate l -> b 1 dstate l")ctx.squeeze_B = Trueif C.dim() == 3:C = rearrange(C, "b dstate l -> b 1 dstate l")ctx.squeeze_C = True# 确保数据类型为floatif D is not None and (D.dtype != torch.float):ctx._d_dtype = D.dtypeD = D.float()if delta_bias is not None and (delta_bias.dtype != torch.float):ctx._delta_bias_dtype = delta_bias.dtypedelta_bias = delta_bias.float()# 断言检查assert u.shape[1] % (B.shape[1] * nrows) == 0 assert nrows in [1, 2, 3, 4]# 选择相应的CUDA实现进行前向计算if mode == "mamba_ssm":out, x, *rest = selective_scan_cuda.fwd(u, delta, A, B, C, D, z, delta_bias, delta_softplus)else:raise NotImplementedError("未实现的模式")# 保存状态以便反向传播ctx.delta_softplus = delta_softplusctx.has_z = z is not Nonelast_state = x[:, :, -1, 1::2] # 获取最后状态ctx.save_for_backward(u, delta, A, B, C, D, delta_bias, x)return out if not return_last_state else (out, last_state)@staticmethoddef backward(ctx, dout):"""反向传播函数,计算梯度。参数:ctx: 上下文对象,包含前向传播时保存的状态dout: 输出的梯度返回:梯度的元组"""u, delta, A, B, C, D, delta_bias, x = ctx.saved_tensors# 确保dout是连续的if dout.stride(-1) != 1:dout = dout.contiguous()# 使用CUDA实现进行反向计算du, ddelta, dA, dB, dC, dD, ddelta_bias, *rest = selective_scan_cuda.bwd(u, delta, A, B, C, D, delta_bias, dout, x, ctx.delta_softplus)# 返回梯度return (du, ddelta, dA, dB, dC, dD if D is not None else None, ddelta_bias if delta_bias is not None else None)# 返回选择性扫描函数
return SelectiveScanFn.apply
代码说明
build_selective_scan_fn 函数: 该函数用于构建选择性扫描的自定义函数,接受CUDA实现和模式作为参数。
SelectiveScanFn 类: 继承自 torch.autograd.Function,实现了前向和反向传播的方法。
forward 方法: 计算选择性扫描的输出,并保存必要的状态以供反向传播使用。
backward 方法: 计算输入张量的梯度,使用保存的状态和输出的梯度进行反向传播。
该代码的核心功能是实现选择性扫描操作,并支持在前向和反向传播中使用自定义的CUDA实现。
这个程序文件 test_selective_scan.py 主要用于实现和测试一个名为“选择性扫描”(Selective Scan)的功能。该功能涉及深度学习中的张量操作,特别是在处理序列数据时的动态计算。程序中使用了 PyTorch 库,并结合了 CUDA 以提高计算效率。
首先,程序导入了必要的库,包括 PyTorch 和一些数学功能。接着定义了一个 build_selective_scan_fn 函数,该函数用于构建一个选择性扫描的自定义操作。这个操作通过继承 torch.autograd.Function 来实现前向和反向传播的计算。
在 SelectiveScanFn 类中,forward 方法负责前向传播的计算。它接收多个输入参数,包括张量 u、delta、A、B、C、D、z 等。该方法首先确保输入张量是连续的,然后根据输入的维度和形状进行必要的调整。接着,它调用不同模式下的 CUDA 函数来执行选择性扫描的计算,最终返回输出结果。
backward 方法实现了反向传播的计算,计算梯度并返回给定输入的梯度。这个方法根据不同的模式调用相应的 CUDA 函数来处理梯度计算。
程序还定义了几个参考实现的函数,如 selective_scan_ref 和 selective_scan_ref_v2,这些函数用于在没有 CUDA 加速的情况下进行选择性扫描的计算,以便于与 CUDA 实现进行比较。
在文件的最后部分,程序通过 pytest 框架定义了一系列的测试用例。使用了多个参数化的测试条件,以确保选择性扫描功能在不同输入条件下的正确性和稳定性。测试包括对输出的相对误差和绝对误差的检查,以及对反向传播计算的梯度进行验证。
整个程序的设计旨在提供一个高效的选择性扫描实现,并通过测试确保其在各种条件下的正确性和性能。通过使用 CUDA 加速,程序能够处理大规模的张量运算,适用于深度学习中的复杂模型训练和推理任务。
源码文件
源码获取
欢迎大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式