【完整源码+数据集+部署教程】腐蚀类型检测系统源码和数据集:改进yolo11-Faster
背景意义
研究背景与意义
腐蚀是材料在环境因素作用下发生的化学或电化学反应,导致材料性能下降甚至失效。随着工业化进程的加快,腐蚀问题日益严重,给各行各业带来了巨大的经济损失和安全隐患。特别是在建筑、交通运输、能源等关键领域,腐蚀不仅影响设备的使用寿命,还可能导致严重的安全事故。因此,开发高效的腐蚀检测与分类系统显得尤为重要。
近年来,计算机视觉技术的快速发展为腐蚀检测提供了新的解决方案。尤其是基于深度学习的目标检测算法,如YOLO(You Only Look Once),因其高效的实时检测能力和良好的准确性,逐渐成为腐蚀检测领域的研究热点。YOLOv11作为YOLO系列的最新版本,具备更强的特征提取能力和更快的推理速度,能够有效应对复杂环境下的腐蚀类型检测任务。
本研究旨在基于改进的YOLOv11模型,构建一个高效的腐蚀类型检测系统。该系统将针对六种腐蚀类型进行分类,包括裂缝腐蚀、镀锌腐蚀、未腐蚀、点蚀和应力腐蚀开裂等。通过使用包含2301张经过精细标注的图像数据集,我们将利用数据增强技术提升模型的泛化能力,确保其在实际应用中的鲁棒性。
通过本项目的实施,不仅可以提高腐蚀检测的准确性和效率,还能够为相关行业提供可靠的技术支持,降低因腐蚀引发的安全风险和经济损失。最终,我们希望该系统能够在实际应用中发挥重要作用,为腐蚀防治提供科学依据和技术保障。
图片效果
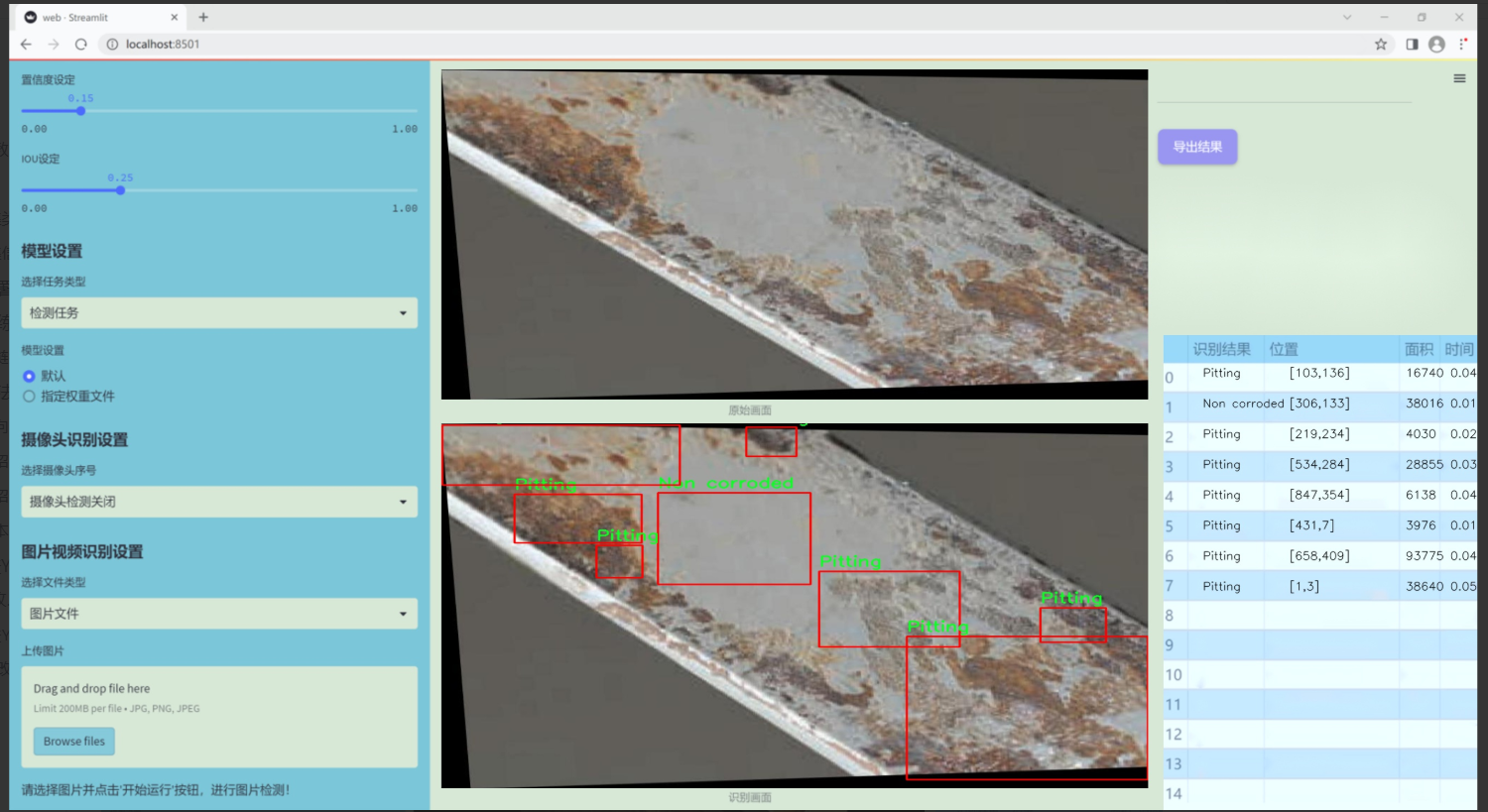
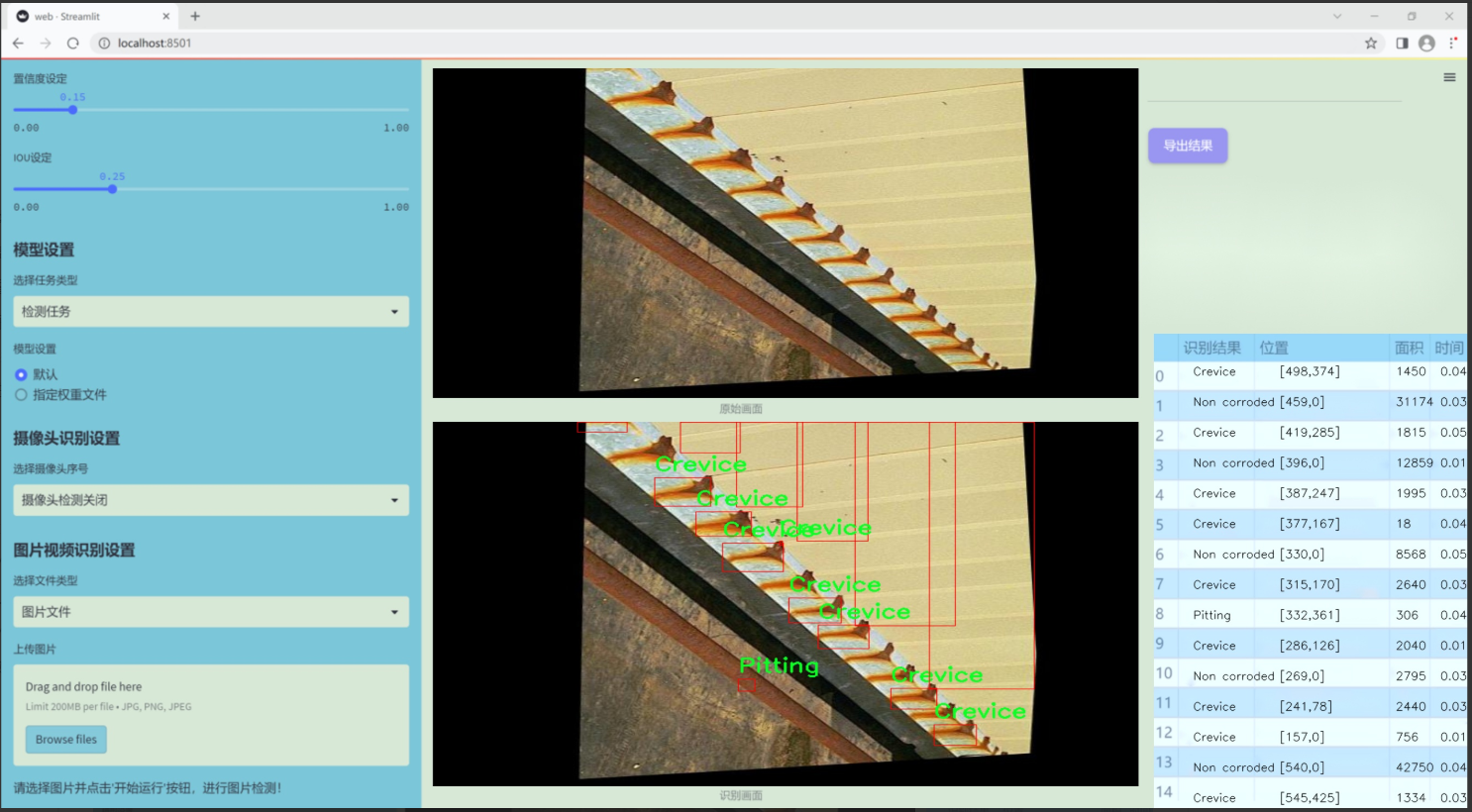
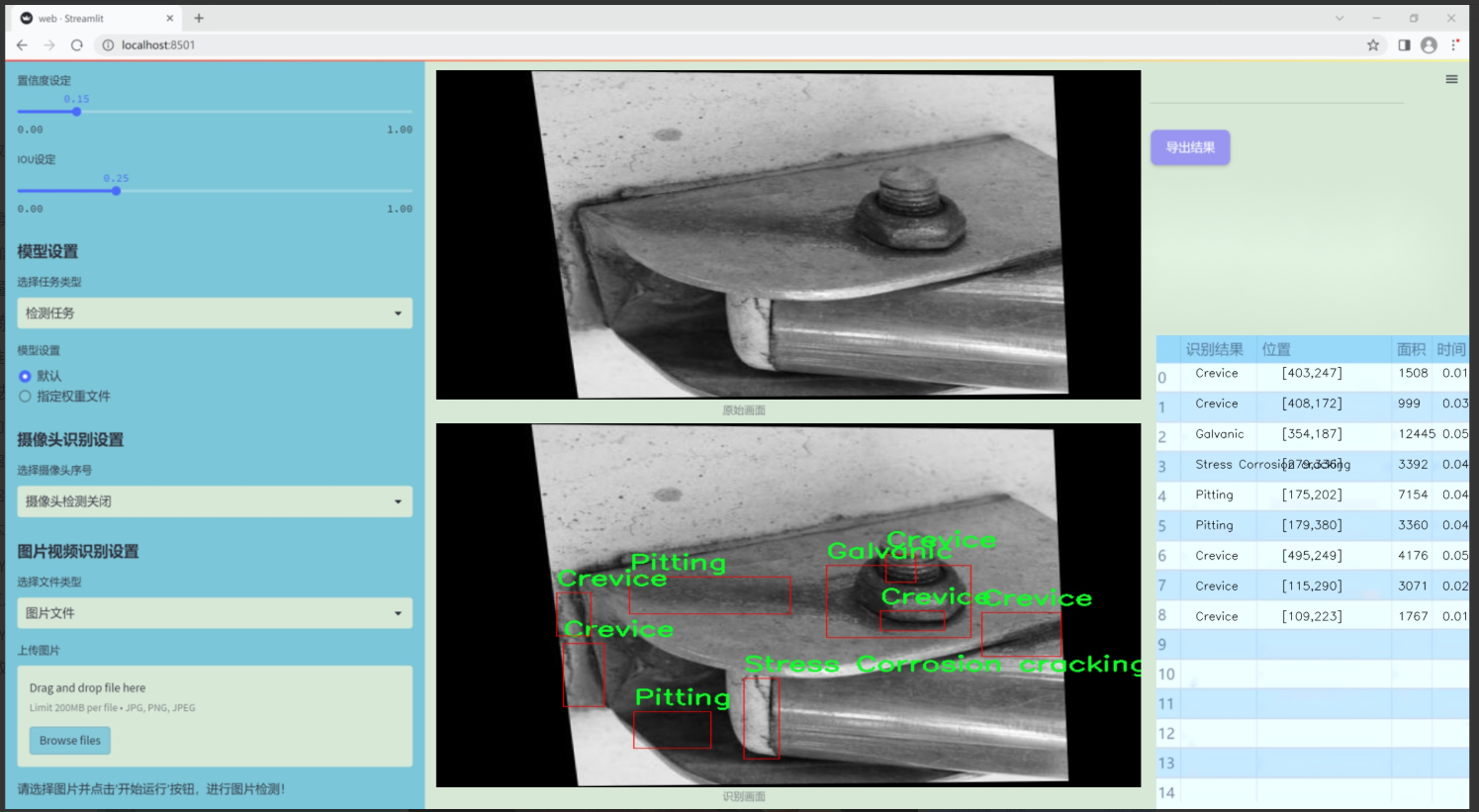
数据集信息
本项目数据集信息介绍
本项目所使用的数据集旨在支持改进YOLOv11的腐蚀类型检测系统,特别聚焦于腐蚀现象的多样性和复杂性。数据集包含六个主要类别,分别为“2”、“Crevice”、“Galvanic”、“Non corroded”、“Pitting”和“Stress Corrosion cracking”。这些类别涵盖了不同类型的腐蚀特征,反映了在实际应用中可能遇到的各种腐蚀形态。
数据集中的“Crevice”类别主要指在接触面或连接处形成的腐蚀,通常由于流体流动不畅而导致的局部环境恶化。相对而言,“Galvanic”类别则涉及到由于电化学反应引起的腐蚀,常见于不同金属接触的情境。另一方面,“Non corroded”类别则代表未受腐蚀影响的表面,为模型提供了对比数据,以便更好地识别和分类其他腐蚀类型。
“Pitting”类别则是指表面形成的小孔或凹坑,这种腐蚀形式在金属材料中非常常见,且其检测难度较大,故而对模型的训练提出了更高的要求。最后,“Stress Corrosion cracking”类别则关注由于应力和腐蚀共同作用而导致的裂纹,通常在高应力环境下更为明显,这一类别的准确识别对于结构安全至关重要。
通过对这些类别的深入分析和标注,数据集为训练改进后的YOLOv11模型提供了丰富的样本,确保模型能够在多种腐蚀情境下进行有效的检测与分类。这不仅有助于提升腐蚀检测的准确性,还能为相关领域的研究和应用提供重要的数据支持。整体而言,本项目的数据集不仅具备多样性和代表性,还在一定程度上反映了实际工业环境中腐蚀现象的复杂性,为后续的研究和开发奠定了坚实的基础。





核心代码
以下是经过简化和注释的核心代码部分,保留了模型的主要结构和功能。
import torch
import torch.nn as nn
import torch.nn.functional as F
class DWConv2d(nn.Module):
“”" 深度可分离卷积层 “”"
def init(self, dim, kernel_size, stride, padding):
super().init()
# 使用分组卷积实现深度可分离卷积
self.conv = nn.Conv2d(dim, dim, kernel_size, stride, padding, groups=dim)
def forward(self, x: torch.Tensor):""" 前向传播x: 输入张量,形状为 (b, h, w, c)"""x = x.permute(0, 3, 1, 2) # 转换为 (b, c, h, w)x = self.conv(x) # 卷积操作x = x.permute(0, 2, 3, 1) # 转换回 (b, h, w, c)return x
class FeedForwardNetwork(nn.Module):
“”" 前馈神经网络 “”"
def init(self, embed_dim, ffn_dim, activation_fn=F.gelu, dropout=0.0):
super().init()
self.fc1 = nn.Linear(embed_dim, ffn_dim) # 第一层线性变换
self.fc2 = nn.Linear(ffn_dim, embed_dim) # 第二层线性变换
self.dropout = nn.Dropout(dropout) # Dropout层
self.activation_fn = activation_fn # 激活函数
def forward(self, x: torch.Tensor):""" 前向传播x: 输入张量,形状为 (b, h, w, c)"""x = self.fc1(x) # 线性变换x = self.activation_fn(x) # 激活函数x = self.dropout(x) # Dropoutx = self.fc2(x) # 线性变换return x
class RetBlock(nn.Module):
“”" 保留块,用于模型的基本构建 “”"
def init(self, embed_dim, num_heads, ffn_dim):
super().init()
self.ffn = FeedForwardNetwork(embed_dim, ffn_dim) # 前馈网络
self.pos = DWConv2d(embed_dim, 3, 1, 1) # 位置卷积
def forward(self, x: torch.Tensor):""" 前向传播x: 输入张量,形状为 (b, h, w, c)"""x = x + self.pos(x) # 添加位置编码x = self.ffn(x) # 前馈网络return x
class VisRetNet(nn.Module):
“”" 可视化保留网络 “”"
def init(self, in_chans=3, num_classes=1000, embed_dims=[96, 192, 384, 768], depths=[2, 2, 6, 2], num_heads=[3, 6, 12, 24]):
super().init()
self.patch_embed = nn.Conv2d(in_chans, embed_dims[0], kernel_size=4, stride=4) # 图像到补丁的嵌入
self.layers = nn.ModuleList() # 存储网络层
# 构建每一层for i in range(len(depths)):layer = nn.ModuleList([RetBlock(embed_dims[i], num_heads[i], embed_dims[i] * 4) for _ in range(depths[i])])self.layers.append(layer)def forward(self, x):""" 前向传播x: 输入张量,形状为 (b, c, h, w)"""x = self.patch_embed(x) # 嵌入for layer in self.layers:for blk in layer:x = blk(x) # 通过每个块return x
def RMT_T():
“”" 创建 RMT_T 模型 “”"
model = VisRetNet(
embed_dims=[64, 128, 256, 512],
depths=[2, 2, 8, 2],
num_heads=[4, 4, 8, 16]
)
return model
if name == ‘main’:
model = RMT_T() # 实例化模型
inputs = torch.randn((1, 3, 640, 640)) # 随机输入
res = model(inputs) # 前向传播
print(res.size()) # 输出结果的形状
代码说明:
DWConv2d: 实现了深度可分离卷积,用于减少模型参数和计算量。
FeedForwardNetwork: 实现了前馈神经网络,包括两个线性层和一个激活函数。
RetBlock: 由前馈网络和位置卷积组成的基本块,用于模型的构建。
VisRetNet: 主模型类,负责构建整个网络结构,包括补丁嵌入和多个保留块。
RMT_T: 创建一个特定配置的模型实例。
这个简化版本保留了模型的核心结构,并提供了必要的注释以帮助理解每个部分的功能。
这个程序文件 rmt.py 实现了一个视觉变换器(Vision Transformer)模型,名为 VisRetNet,并提供了多种不同规模的模型构建函数(如 RMT_T, RMT_S, RMT_B, RMT_L)。以下是对文件中各个部分的详细说明。
首先,文件导入了必要的库,包括 PyTorch 和一些用于构建模型的模块。模型的核心组件包括各种自定义的神经网络层,如深度卷积层、相对位置编码、注意力机制等。
文件中定义了多个类,每个类代表模型的一个组成部分:
DWConv2d:实现了深度可分离卷积,主要用于处理输入特征图的通道。
RelPos2d:用于生成二维相对位置编码,帮助模型捕捉输入特征之间的空间关系。
MaSAd 和 MaSA:实现了多头自注意力机制,分别用于处理不同的注意力计算方式。MaSAd 适用于分块处理,而 MaSA 则用于整体处理。
FeedForwardNetwork:实现了前馈神经网络,包含两个线性层和激活函数,用于对特征进行非线性变换。
RetBlock:一个残差块,结合了注意力机制和前馈网络,并支持层归一化和可选的层缩放。
PatchMerging:用于将输入特征图进行下采样,合并特征块。
BasicLayer:构建了一个基本的层,包含多个残差块,并支持相对位置编码。
LayerNorm2d:实现了二维层归一化,适用于图像数据。
PatchEmbed:将输入图像分割成小块并进行嵌入,生成适合后续处理的特征表示。
VisRetNet:主模型类,整合了所有的层和模块,负责将输入图像经过多个层处理后输出特征。
在 VisRetNet 的构造函数中,定义了多个参数,包括输入通道数、输出类别数、嵌入维度、层数、注意力头数等。模型通过 PatchEmbed 将输入图像转换为特征块,然后依次通过定义的层进行处理。
最后,文件提供了几个函数(RMT_T, RMT_S, RMT_B, RMT_L),用于创建不同规模的模型实例。每个函数设置了不同的嵌入维度、层数和注意力头数,以适应不同的任务需求。
在 main 部分,创建了一个 RMT_T 模型实例,并对随机生成的输入进行前向传播,输出特征的尺寸。这部分代码可以用于测试模型的构建和运行是否正常。
整体而言,这个文件实现了一个灵活且可扩展的视觉变换器模型,适用于各种计算机视觉任务。
10.4 test_selective_scan_speed.py
以下是经过简化并添加详细中文注释的核心代码部分:
import torch
import torch.nn.functional as F
def build_selective_scan_fn(selective_scan_cuda: object = None, mode=“mamba_ssm”):
“”"
构建选择性扫描函数的工厂函数。
参数:
selective_scan_cuda: CUDA实现的选择性扫描函数
mode: 模式选择,决定选择性扫描的具体实现
"""class SelectiveScanFn(torch.autograd.Function):@staticmethoddef forward(ctx, u, delta, A, B, C, D=None, z=None, delta_bias=None, delta_softplus=False, return_last_state=False):"""前向传播函数,执行选择性扫描的计算。参数:ctx: 上下文对象,用于保存状态u: 输入张量delta: 增量张量A, B, C: 相关参数D: 可选的额外参数z: 可选的状态张量delta_bias: 可选的增量偏置delta_softplus: 是否使用softplus激活return_last_state: 是否返回最后状态返回:计算结果或计算结果和最后状态的元组"""# 确保输入张量是连续的if u.stride(-1) != 1:u = u.contiguous()if delta.stride(-1) != 1:delta = delta.contiguous()if D is not None:D = D.contiguous()if B.stride(-1) != 1:B = B.contiguous()if C.stride(-1) != 1:C = C.contiguous()if z is not None and z.stride(-1) != 1:z = z.contiguous()# 选择性扫描的具体实现if mode == "mamba_ssm":out, x, *rest = selective_scan_cuda.fwd(u, delta, A, B, C, D, z, delta_bias, delta_softplus)else:raise NotImplementedError("未实现的模式")# 保存状态以便反向传播ctx.save_for_backward(u, delta, A, B, C, D, delta_bias, x)last_state = x[:, :, -1, 1::2] # 获取最后状态return out if not return_last_state else (out, last_state)@staticmethoddef backward(ctx, dout):"""反向传播函数,计算梯度。参数:ctx: 上下文对象,包含前向传播时保存的状态dout: 上游梯度返回:输入张量的梯度"""u, delta, A, B, C, D, delta_bias, x = ctx.saved_tensors# 调用CUDA实现的反向传播du, ddelta, dA, dB, dC, dD, ddelta_bias, *rest = selective_scan_cuda.bwd(u, delta, A, B, C, D, delta_bias, dout, x, None, False)return (du, ddelta, dA, dB, dC, dD, ddelta_bias, None)def selective_scan_fn(u, delta, A, B, C, D=None, z=None, delta_bias=None, delta_softplus=False, return_last_state=False):"""封装选择性扫描函数的调用。"""return SelectiveScanFn.apply(u, delta, A, B, C, D, z, delta_bias, delta_softplus, return_last_state)return selective_scan_fn
示例使用
selective_scan_fn = build_selective_scan_fn(selective_scan_cuda, mode=“mamba_ssm”)
代码说明:
build_selective_scan_fn: 这是一个工厂函数,用于创建选择性扫描的函数。它接受一个CUDA实现和模式参数,并返回一个可调用的选择性扫描函数。
SelectiveScanFn: 这是一个自定义的PyTorch自动求导函数,包含前向和反向传播的实现。
forward: 计算选择性扫描的前向传播。它会检查输入张量的连续性,调用CUDA实现进行计算,并保存必要的张量以供反向传播使用。
backward: 计算反向传播的梯度,调用CUDA实现的反向传播函数,并返回输入张量的梯度。
selective_scan_fn: 封装了对SelectiveScanFn的调用,使得用户可以直接使用这个函数进行选择性扫描的计算。
以上代码保留了核心功能,并添加了详细的中文注释以帮助理解。
这个程序文件 test_selective_scan_speed.py 主要用于实现和测试选择性扫描(Selective Scan)算法的速度和性能。程序中使用了 PyTorch 库来处理张量运算,并利用 CUDA 加速来提高计算效率。以下是对文件中各个部分的详细说明。
首先,程序导入了必要的库,包括 torch、torch.nn.functional、pytest、time 等,此外还使用了 einops 库来进行张量的重排和重复操作。接着,定义了一个函数 build_selective_scan_fn,该函数用于构建选择性扫描的前向和反向传播函数。函数内部定义了一个名为 SelectiveScanFn 的类,继承自 torch.autograd.Function,用于实现自定义的前向和反向传播逻辑。
在 SelectiveScanFn 类中,forward 方法负责处理前向传播。它首先确保输入张量的连续性,然后根据输入的维度和形状进行必要的调整。接着,调用 CUDA 实现的选择性扫描函数 selective_scan_cuda.fwd,并根据不同的模式(如 mamba_ssm、sscore 等)处理输入数据。最终,返回计算结果和最后的状态(如果需要的话)。
backward 方法则负责反向传播的计算,使用保存的张量进行梯度计算,并根据不同的模式调用相应的 CUDA 后向函数。它还处理了数据类型的转换,以确保梯度的正确性。
接下来,定义了几个选择性扫描的参考实现函数,如 selective_scan_ref 和 selective_scan_easy,这些函数提供了选择性扫描的基本逻辑,主要用于与 CUDA 实现进行性能比较。
在文件的最后部分,定义了 test_speed 函数,用于测试不同选择性扫描实现的速度。该函数设置了一些参数,包括数据类型、序列长度、批量大小等,并生成随机输入数据。然后,它通过多次调用不同的选择性扫描实现来测量其执行时间,并打印出每个实现的前向和反向传播的耗时。
总体来说,这个程序文件实现了选择性扫描算法的多种版本,并通过性能测试来评估不同实现的效率,适合用于深度学习模型中的序列数据处理。
源码文件
源码获取
欢迎大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式