后端八股之Redis
1.缓存
1.1缓存穿透
缓存穿透就是查询一个并不存在的数据,缓存中没有,数据库中也没有,也无法写入到缓存,导致每次请求都查到数据库
解决办法1.缓存空数据:在每次请求的数据查询数据库也没有结果的时候缓存一个空数据,但是可能导致内存浪费,缓存和数据库不一致,缓存雪崩等问题。
2.布隆过滤器:就是通过哈希将一个数据映射到一个二进制数组的不同位置,查询数据的时候可能导致误判,没有的数据也认为有,不支持删除,动态扩容困难,但是空间存储效率高,查询快。
1.2缓存击穿
缓存击穿就是给某个key设置了过期时间,当这个key过期的时候,恰好有大量的关于这个key的请求打过来,这些并发请求可能把数据库压垮
解决办法:1.互斥锁:不是全局锁,是key级别的锁,能够保证强一致性,但是性能会比较差
- 锁必须有过期时间,防止某个请求获取锁后宕机,导致死锁。
- 双重检查缓存:获取锁后再次检查缓存,防止重复加载。
- 读写锁分离:如果是热点数据更新频繁,可以用读写锁优化(读多写少场景)。
- 结合缓存空值:防止缓存穿透 + 互斥锁防止缓存击穿。
请求数据:1. 先查缓存2. 缓存命中 -> 返回3. 缓存未命中 -> 尝试获取互斥锁a. 获取成功 -> 去数据库查数据 -> 写回缓存 -> 释放锁b. 获取失败 -> 等待一段时间 -> 重新查缓存(或者直接返回空/旧值)2.逻辑过期:缓存中的数据 不设置物理 TTL(即 Redis 的 expire 时间),而是在数据 value 中增加一个 expireAt 时间字段。当读取缓存时,先判断这个时间字段是否过期,如果过期,不立即删除缓存并回源数据库,而是:直接返回旧数据(保证高可用,不阻塞用户请求)同时异步去数据库加载最新数据并更新缓存。
优点
高可用:即使数据过期,也不会直接导致缓存失效,用户不会感知卡顿。
防缓存击穿:热点 key 过期时,只有第一个发现过期的线程去更新缓存,其他线程直接返回旧数据。
灵活控制过期逻辑:可以在 value 中加入更多业务字段控制过期策略。
缺点
数据可能短暂不一致(最终一致性):过期后有一段时间返回的是旧数据。
需要额外存储过期时间字段。
实现复杂:需要异步更新机制(线程池 / 消息队列)。
不适合强一致性场景。
1.3缓存雪崩
缓存雪崩是指同一时间段大量缓存的的key同时失效或者redis服务宕机,导致大量请求到数据库,带来巨大压力
解决办法1.给不同的key添加随机过期时间 2.利用redis集群提高服务可用性 3.给缓存业务添加降级限流策略 4.给业务添加多级缓存
1.4双写一致
双写一致指的是:当业务需要同时操作「数据库(DB)」和「缓存」时,通过特定策略确保两者存储的同一份数据始终保持一致(或在可接受的时间窗口内达到一致),避免出现「缓存存旧值、数据库存新值」或「两者数据完全冲突」的情况。
原因:缓存和数据库是两个独立的存储组件,更新操作无法原子性地同时完成。当多个线程 / 服务并发读写时,若操作顺序或时机不当,就会导致数据不一致。
解决办法:1.Cache Aside Pattern(缓存旁路模式)核心逻辑是:读操作走缓存,写操作走数据库,缓存通过 “删除” 而非 “更新” 来触发后续自动加载。2.先删缓存,再更新数据库,再过一会删除缓存 —— 需配合 “延迟双删”3.读写锁(Read-Write Lock)—— 适合读多写少场景 4.缓存与数据库强一致(分布式事务)—— 谨慎使用
1.5持久化
RDB 是通过定时生成内存数据的 “快照”(Snapshot) 并保存到磁盘文件(默认 dump.rdb)实现持久化。
AOF 是通过记录 Redis 所有写命令(如 set、hmset、del) 到文本日志文件(默认 appendonly.aof)实现持久化。
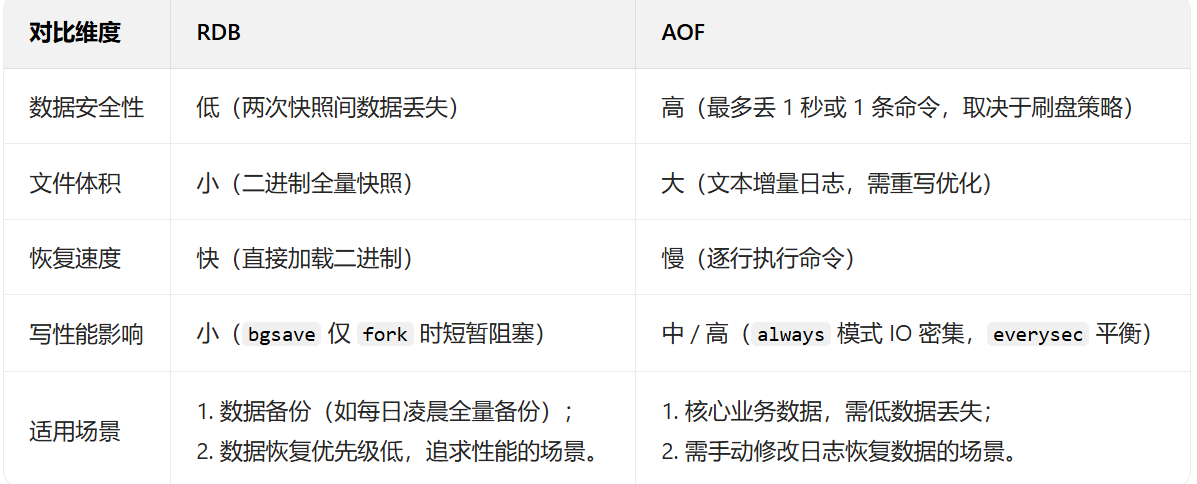
生产环境一般两者同时使用
1.6数据过期策略和数据淘汰策略
在缓存系统中,为了控制内存占用、保证数据新鲜度,我们会给缓存的 key 设置 过期时间(TTL, Time-To-Live)。数据过期策略 就是指:当 key 过期后,缓存系统如何发现并删除这些过期 key 的机制。一般来说,过期策略可以分为三大类:1.定时删除(Timer-based)在设置 key 过期时间的同时,创建一个定时器(timer),当时间到达时立即删除该 key,2.惰性删除(Lazy Expiration)不主动删除过期 key,每次访问 key 时才检查是否过期 3. 定期删除(Periodic Expiration)每隔一段时间,扫描部分过期 key 并删除它们。
当 Redis 内存达到 maxmemory 限制时,会触发 内存淘汰策略(即使 key 还没过期)。

2.分布式锁
1. 什么是分布式锁
分布式锁 是控制分布式系统之间互斥访问共享资源的一种方式。在单机环境下,我们可以用 synchronized 或 ReentrantLock 来保证线程互斥,但在多机(分布式)环境下,这些本地锁就无能为力了,这时就需要一个跨进程、跨服务器的锁机制。
分布式锁必须具备的特性:
- 互斥性:同一时刻只能有一个客户端持有锁。
- 无死锁:即使持有锁的客户端崩溃,也能保证锁被释放,避免死锁。
- 容错性:只要大部分 Redis 节点正常运行,分布式锁就能正常工作。
2. Redis 实现分布式锁的原理
Redis 实现分布式锁的核心思路是:
- 利用
SET命令的原子性,在缓存中设置一个 key 作为锁标记; - key 不存在时才能设置成功(获得锁),设置成功后,其他客户端就无法再设置这个 key;
- 锁必须设置 过期时间,防止客户端崩溃导致锁永远不释放;
- 释放锁时,要确保只能释放自己持有的锁(通过唯一 value 区分)。
3. 基本实现(SETNX + EXPIRE)
早期 Redis 版本中,大家会用 SETNX + EXPIRE 来实现:
# 尝试获取锁
SETNX lock:order 1 # key不存在则设置成功,返回1(获得锁)
EXPIRE lock:order 30 # 设置过期时间30秒,防止死锁
缺点:
SETNX和EXPIRE是两条命令,不是原子操作,如果执行完SETNX后 Redis 崩溃,锁就永远不会过期,造成死锁。
4. 改进实现(SET 扩展命令)
Redis 2.6.12 版本后,SET 命令增加了强大的参数,可以原子化地完成 “设置值 + 过期时间 + 不存在才设置”:
SET lock:order 1 NX PX 30000
参数说明:
- NX:只有 key 不存在时才设置成功(相当于 SETNX)。
- PX 30000:设置过期时间 30000 毫秒(30 秒)。
- 这是一个原子操作,要么全部成功,要么全部失败。
释放锁:
DEL lock:order
5. 释放锁的安全性问题
如果锁的过期时间到了,但业务还没执行完,这时 Redis 会自动释放锁,其他客户端会获取到这个锁。当原客户端执行完业务后,会 DEL 掉不属于它的锁,造成误删。
解决办法:
- 在设置锁时,给 value 设置一个唯一标识(如 UUID);
- 释放锁时,先判断 value 是否匹配,匹配才删除。
# 获取锁
SET lock:order <UUID> NX PX 30000# 释放锁(伪代码)
if GET lock:order == <UUID>DEL lock:order
注意:判断和删除必须是原子操作,否则可能在判断后锁过期被别人获取,再执行 DEL 就误删了别人的锁。
6. 原子释放锁(Lua 脚本)
Redis 执行 Lua 脚本是原子的,我们可以用它来安全释放锁:
lua
if redis.call("get", KEYS[1]) == ARGV[1] thenreturn redis.call("del", KEYS[1])
elsereturn 0
end
执行:
EVAL "if redis.call('get',KEYS[1])==ARGV[1] then return redis.call('del',KEYS[1]) else return 0 end" 1 lock:order <UUID>
7. 锁过期问题(锁续命 / Watchdog)
如果业务执行时间超过锁的过期时间,锁会被自动释放,这可能导致多个客户端同时进入临界区。
解决办法:
- 预估业务执行时间,设置足够长的过期时间(不推荐,浪费资源)。
- 实现锁续期机制(Watchdog 看门狗):
- 获得锁后,启动一个后台线程;
- 每隔一段时间(比如锁过期时间的 1/3)检查锁是否还持有;
- 如果持有,就延长锁的过期时间。
开源实现:Redisson 框架已经内置了 Watchdog 机制。
8. Redis 分布式锁的优缺点
优点
- 高性能:Redis 速度快,获取和释放锁开销小。
- 实现简单:用 SET 命令就能实现。
- 支持过期自动释放:避免死锁。
缺点
- 主从架构存在锁丢失风险:
- 客户端在主节点获得锁;
- 主节点宕机,锁还没同步到从节点;
- 从节点升级为主节点,新主节点没有这个锁,其他客户端可以再次获得锁。
- 非强一致性:在分布式系统的某些异常情况下,可能出现多个客户端同时获得锁。
9. 最佳实践建议
- 使用
SET key value NX PX ttl原子命令加锁。 - Value 设置唯一标识(UUID),释放锁用 Lua 脚本原子判断 + 删除。
- 实现锁续期机制(Watchdog),防止业务未完成锁已过期。
- 设置合理的过期时间,既不能太短(容易提前释放),也不能太长(死锁影响大)。
- 考虑使用开源库:如 Redisson(Java)、redis-py-lock(Python),它们已封装好上述最佳实践。
3.高可用和高性能架构
一、主从模式(Master-Slave)—— 基础的数据备份与读写分离
主从模式是 Redis 最基础的集群方案,本质是 “一主多从” 的复制架构,核心目标是实现数据备份和读写分离。
1. 核心原理
- 数据复制:Slave(从节点)会从 Master(主节点)同步全量数据,之后 Master 有新写操作时,会实时同步增量数据给 Slave,保证主从数据一致(最终一致)。
- 复制流程:
- 全量同步(首次连接):
- Slave 启动后,向 Master 发送
SYNC命令; - Master 执行
bgsave生成 RDB 快照,同时记录快照期间的写命令到 “复制缓冲区”; - Master 将 RDB 发送给 Slave,Slave 加载 RDB 恢复数据;
- Master 再将复制缓冲区的写命令发送给 Slave,Slave 执行命令,完成全量同步。
- Slave 启动后,向 Master 发送
- 增量同步(后续同步):
- 全量同步后,Master 每执行一次写命令(如
setdel),都会将命令发送给 Slave; - 主从通过 “复制偏移量” 标记同步进度(Master 记录已发送偏移量,Slave 记录已接收偏移量),避免重复同步。
- 全量同步后,Master 每执行一次写命令(如
- 全量同步(首次连接):
2. 架构结构
- 1 个 Master 节点:
- 唯一可写节点(默认配置下,Slave 只读);
- 负责接收所有写请求,并将数据同步给 Slave。
- N 个 Slave 节点:
- 只读节点(通过
slave-read-only yes配置); - 负责接收读请求,分担 Master 的读压力。
- 只读节点(通过
3. 核心作用
- 读写分离:Master 处理写请求,Slave 处理读请求(如电商商品详情页的查询请求),提升整体 QPS。
- 数据备份:Slave 是 Master 的完整副本,即使 Master 宕机,数据也不会丢失(可从 Slave 恢复)。
- 故障转移基础:为后续哨兵模式的自动故障转移提供 “节点池”(Slave 可升级为新 Master)。
4. 优缺点
| 优点 | 缺点 |
|---|---|
实现简单(仅需配置 slaveof <master-ip> <master-port>) | Master 单点故障:Master 宕机后,整个集群无法写数据,需手动切换 Slave 为新 Master |
| 分担读压力,提升读性能 | Slave 只读:无法处理写请求,灵活性低 |
| 数据实时同步(增量同步延迟极低) | 全量同步开销大:Slave 首次连接时,Master 生成 RDB 和传输数据会占用 CPU / 带宽 |
| 数据一致性风险:网络波动时,Slave 可能滞后 Master 少量数据(最终一致) |
5. 适用场景
- 读多写少的业务(如新闻列表查询、商品详情页);
- 对高可用要求不高,可接受手动故障转移的场景(如测试环境、小型业务)。
二、哨兵模式(Sentinel)—— 主从架构的高可用保障
哨兵模式是在主从模式基础上,增加了 “哨兵节点”,核心目标是解决 Master 单点故障问题,实现自动故障转移。
1. 核心原理
- 哨兵节点(Sentinel):独立于主从节点的 “监控进程”,负责:
- 监控(Monitoring):实时检查 Master 和 Slave 是否存活(通过发送
PING命令检测); - 故障检测(Notification):
- 若哨兵发现 Master 未响应
PING,标记为 “主观下线(SDOWN)”; - 多个哨兵(默认需超过半数)确认 Master 下线,标记为 “客观下线(ODOWN)”(避免单哨兵误判);
- 若哨兵发现 Master 未响应
- 自动故障转移(Failover):Master 客观下线后,哨兵集群选举一个 Slave 升级为新 Master,其他 Slave 改为同步新 Master;
- 通知(Notification):故障转移完成后,哨兵将新 Master 地址通知给客户端(如 Java 客户端通过监听哨兵节点获取新地址)。
- 监控(Monitoring):实时检查 Master 和 Slave 是否存活(通过发送
2. 架构结构
- 3 个及以上哨兵节点:
- 哨兵节点需奇数个(如 3、5 个),避免 “脑裂”(多个哨兵同时选不同 Slave 为新 Master);
- 哨兵之间通过 “gossip 协议” 通信,同步主从节点状态和故障判断结果。
- 1 主 N 从节点:与主从模式的主从节点一致,哨兵不存储业务数据,仅负责监控和故障转移。
3. 核心作用
- 自动故障转移:Master 宕机后,无需人工干预,哨兵自动将 Slave 升级为新 Master,保证集群 “写可用”。
- 节点监控:实时检测主从和哨兵节点的健康状态,避免 “假死” 节点影响业务。
- 客户端路由:客户端无需硬编码 Master 地址,只需连接哨兵节点,即可获取当前可用的 Master 地址。
4. 优缺点
| 优点 | 缺点 |
|---|---|
| 解决 Master 单点故障,实现高可用 | 无法解决单机内存瓶颈:所有节点存储全量数据,若数据量超过单机内存(如 100G),仍会崩溃 |
| 故障转移自动化,无需人工干预 | 配置复杂:需配置哨兵节点、故障检测阈值、选举规则等 |
| 兼容主从模式的读写分离能力 | 故障转移期间短暂不可写:从 Master 下线到新 Master 上线,约 1-3 秒写不可用 |
数据一致性风险:故障转移前,部分 Slave 可能未同步 Master 最后少量数据(需通过 min-replicas-to-write 配置降低风险) |
5. 适用场景
- 读多写少、对高可用要求高的业务(如用户登录、订单创建);
- 数据量适中(未超过单机内存上限,如 32G 以内),无需水平扩展的场景。
三、分片模式(Sharding/Cluster)—— 解决单机内存与性能瓶颈
分片模式(Redis Cluster)是 Redis 官方提供的 “水平扩展” 方案,核心目标是将数据拆分到多个节点,解决单机内存不足和单节点性能上限问题。
1. 核心原理
- 数据分片(哈希槽):
- Redis Cluster 将所有数据划分为 16384 个哈希槽(Hash Slot);
- 每个节点负责一部分槽(如 3 个主节点时,节点 A 负责 0-5460,节点 B 负责 5461-10922,节点 C 负责 10923-16383);
- 存储数据时,Redis 通过
CRC16(key) % 16384计算 key 所属的槽,将数据存入负责该槽的节点。
- 槽迁移与重定向:
- 新增 / 删除节点时,Redis 会自动将槽和对应数据在节点间迁移(无需停机);
- 客户端访问数据时,若目标槽不在当前节点,节点会返回
MOVED指令,指引客户端到正确节点(客户端会缓存槽与节点的映射,后续直接访问)。
- 高可用保障:
- 每个主节点可配置多个 Slave 节点(如主节点 A 有 Slave A1、A2);
- 若主节点 A 宕机,其 Slave 会通过 “槽投票” 升级为新主节点,接管 A 的槽,保证数据可用。
2. 架构结构
- 至少 3 个主节点(官方推荐,保证槽分布均匀和高可用):
- 每个主节点负责不同的哈希槽,可独立处理写请求;
- 主节点之间通过 “gossip 协议” 同步槽分布和节点状态。
- 每个主节点对应 N 个 Slave 节点:
- Slave 同步主节点的槽数据,负责主节点宕机后的故障转移;
- Slave 只读(默认),可分担主节点的读压力。
3. 核心作用
- 水平扩展:
- 内存扩展:数据拆分到多个节点,单机内存限制被打破(如 3 个节点可存储 3 倍于单机的 data);
- 性能扩展:多个主节点并行处理写请求,整体 QPS 随节点数增加而提升。
- 高可用:每个主节点有 Slave 备份,自动故障转移,避免单点故障。
- 槽自动迁移:新增 / 删除节点时,槽和数据自动分配,无需手动干预。
4. 优缺点
| 优点 | 缺点 |
|---|---|
| 解决单机内存和性能瓶颈,支持大规模数据存储 | 不支持跨槽事务:若一个事务包含多个 key(如 MSET key1 value1 key2 value2),且 key1 和 key2 在不同槽,事务会报错 |
| 自动槽迁移和故障转移,运维成本低 | 数据分片后,备份 / 恢复复杂:需分别备份每个节点的数据,恢复时需按槽还原 |
| 多主节点并行写,提升写性能 | 客户端复杂度高:需支持槽映射缓存和 MOVED 重定向(需用官方客户端或成熟库,如 Java 的 Redisson) |
| 一致性风险:主从同步延迟可能导致 Slave 读取旧数据(最终一致) |
5. 适用场景
- 数据量大的业务(如用户行为日志、订单历史数据,单机内存无法存储);
- 高并发写业务(如秒杀、直播弹幕,单主节点 QPS 不足);
- 对水平扩展能力要求高的大型分布式系统。
四、三种模式的核心对比
| 对比维度 | 主从模式 | 哨兵模式 | 分片模式(Cluster) |
|---|---|---|---|
| 核心目标 | 读写分离、数据备份 | 解决主从的 Master 单点故障,实现高可用 | 水平扩展(内存 / 性能),支持大规模数据 |
| 架构复杂度 | 低(仅需配置主从关系) | 中(需配置哨兵节点和故障规则) | 高(需配置主从、槽分布、节点通信) |
| 写节点数量 | 1 个(Master) | 1 个(Master,自动切换) | N 个(主节点,并行写) |
| 数据存储方式 | 全量存储(所有节点存完整数据) | 全量存储(所有节点存完整数据) | 分片存储(每个节点存部分槽数据) |
| 故障转移 | 手动 | 自动(哨兵集群) | 自动(主从槽投票) |
| 适用数据量 | 小(单机内存上限) | 中(单机内存上限) | 大(支持 TB 级数据) |
| 典型业务场景 | 测试环境、小型读多写少业务 | 中型读多写少、需高可用业务 | 大型分布式系统、高并发写、大数据量业务 |