Attention Is All You Need 学习笔记
方法
提出了一种新的简单网络架构,即Transformer,仅基于注意力机制,完全省去重复和卷积
贡献
在两项机器翻译任务的实验表明这些模型在质量上表现出色,同时更具可并行性,且只需要更少的训练时间
Transformer成功应用于英语语法分析上,无论是大量还是有限的训练数据的情况下,并且在其它任务上表现也良好
引言
背景
注意力机制已成为各种任务中序列建模和传导模型的一部分,允许在不考虑输入或输出序列距离的情况下对依赖关系进行建模。然而除了少数情况外,这种注意力机制都与循环神经网络结合使用
本文提出了Transformer,这是一种完全依赖注意力机制绘制输入和输出之间的全局依赖关系,允许增加并行化,并且在八个 P100 GPU 上训练短短 12 小时后,可以在翻译质量方面达到新的水平。
挑战
循环神经网络,特别是LSTM和门控循环神经网络已被确立为序列建模和类似语言建模和机器翻译等最先进的方法,循环模型的固有训练顺序排除了训练示例中的并行化,并在较长的序列长度下至关重要,最近的工作在因式分解技巧和条件计算上实现了计算效率的显著提高,但顺序计算的基本限制仍然存在。
研究现状
自注意力,有时称为内注意力,是一种将单个序列的不同位置联系起来的注意力模型,以计算序列的表示。自注意力以成功应用在了包括阅读理解,摘要总结,文本蕴含和学习与任务无关的句子表示等任务之中。
端到端记忆网络基于重复注意力机制,而不是序列对齐的重复,并且已被证明在简单语言问答和语言建模任务中表现良好
提出新方法
减少顺序计算的目标成为拓展神经GPU等的基础,他们都使用CNN作为基本构件快,并行计算所有输入和输出位置的隐藏表示,但学习远距离位置之间的依赖关系变得很困难。在Transformer中,这杯减少成了固定的操作次数,尽管代价是由于平均注意力加权位置降低了有效分辨率,使用Multi-Head Attention抵消了这一效果
Transformer是第一个完全依赖自注意力来计算和输出的传导模型,,不使用序列对齐的RNN或卷积
方法部分
大多数竞争性神经序列转导模型都具有编码器-解码器结构 。 在这里,编码器将符号表示的输入序列映射 (x1,…,xn) 到连续表示序列 𝐳=(z1,…,zn) 。给定 𝐳 ,然后解码器一次生成一个元素的符号 (y1,…,ym) 输出序列。在每一步中,模型都是自动回归的,在生成下一个符号时将先前生成的符号用作附加输入。
![![[Pasted image 20251011204943.png]]](https://i-blog.csdnimg.cn/direct/9f5c53d3dfde494bb83d351c083158ca.png)
Transformer基于这种架构,为编码器和解码器使用的堆叠的自注意力层和逐点全连接层,分别为图示左半部分和右半部分
编码器和解码器
编码器
编码器由六个相同的层构成,每层第一个是多头自注意力机制,第二个是简单的按位置的全连接前馈网络,并应用了残差连接在每两个子层中的每一层周围,然后进行层归一化
即每一层输出为
LayerNorm(X+sublayer(x))LayerNorm(X+sublayer(x))LayerNorm(X+sublayer(x))
sublayer(x)是每两个子层实现的功能,为了促进残差链接,模型中的所有子层以及嵌入层都会产生维度 dmodel=512 .
解码器
解码器也由6个相同的层组成,除了和编码器一样的两个子层外,解码器还插入了第三个子层,该子层对编码器堆栈的输出进行多头关注。与编码器类似,我们在每个子层周围采用残差连接,然后进行层归一化。同时还添加了mask,确保位置 i 的预测只能依赖于小于 i 位置的已知输出。
注意力
注意力函数可被描述为将一个query(Q)和一组(key(K)、value(V))映射到一个output,其中QKV和output都是向量,output为values的加权和,其中分配给每个value的权重由Q和相应的K的相似性函数计算得出
若为二维向量:
给定输入X∈RT×CX \in \mathbb{R}^{T \times C}X∈RT×C,其中T是序列长度,C是通道数量
若为三维向量:
如输入为X∈RC×H×WX\in \mathbb{R}^{C \times H \times W}X∈RC×H×W,则将图片划分为N的patch,满足H×W=N×S2H \times W = N \times S^2H×W=N×S2,S 是patch的尺寸
则X∈RN×(C×S2)X \in \mathbb{R}^{N \times (C \times {S^2})}X∈RN×(C×S2)
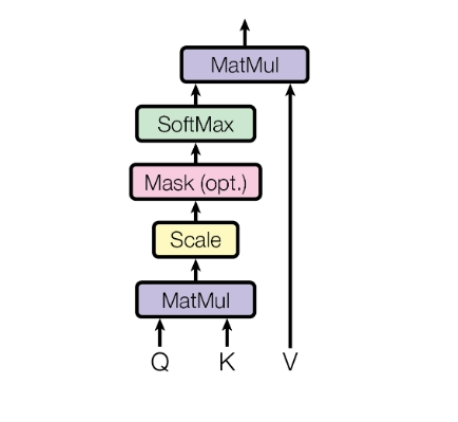
对于输入X∈RT×CX \in \mathbb{R}^{T \times C}X∈RT×C
首先分别通过三个全连接层分别得到Q、K、V∈RT×D\in \mathbb{R}^{T \times D}∈RT×D
这是上方提到的
为了促进这些残差连接,模型中的所有子层以及嵌入层都会产生维度 dmodel=512 .
每个全连接层对应一个可训练的可训练的权重矩阵
- W1:负责将输入特征 X 映射到 “查询(Query)” 空间,学习 “当前位置需要关注什么信息” 的特征表示。
- W2:负责将输入特征 X 映射到 “键(Key)” 空间,学习 “其他位置提供了什么信息” 的特征表示。
- W3:负责将输入特征 X 映射到 “值(Value)” 空间,学习 “其他位置的信息具体是什么内容” 的特征表示。
Q∈RT×D=FC1(X)=X⋅W1∈RC×DQ \in \mathbb{R}^{T \times D}=FC_1(X)=X \cdot W_1 \in \mathbb{R}^{C \times D}Q∈RT×D=FC1(X)=X⋅W1∈RC×DK∈RT×D=FC2(X)=X⋅W2∈RC×DK \in \mathbb{R}^{T \times D}=FC_2(X)=X \cdot W_2 \in \mathbb{R}^{C \times D}K∈RT×D=FC2(X)=X⋅W2∈RC×DV∈RT×D=FC3(X)=X⋅W3∈RC×DV \in \mathbb{R}^{T \times D}=FC_3(X)=X \cdot W_3 \in \mathbb{R}^{C \times D}V∈RT×D=FC3(X)=X⋅W3∈RC×D
对于向量点积QKTQK^TQKT获得两两向量之间的相似度,但点积对于向量长度敏感,如果向量长度过长或者过短都会导致点积的值太大或太小,从而影响softmax梯度计算(如果有值太极端,那么softmax会把这个值挤到将近1,其他的几乎为0,则注意力变得极端,只能关注某一个位置的值,在这种情况下梯度接近0,模型无法学到东西)
使用dk\sqrt{d_k}dk能使数值被压回合理的范围,不会随着维度疯狂增长,使相似度计算更加合理一致
Attention(Q,K,V)=softmax(QKTdk)VAttention(Q,K,V)=softmax \left ( \frac {QK^T} {\sqrt{d_k}} \right) V Attention(Q,K,V)=softmax(dkQKT)V
经过缩放点积获得稳定的注意力分数后,通过softmax函数转换为注意力权重,softmax确保每个query向量和对应的key的注意力权重和为1,这样会使模型全局性关注输入不同地方
得到权重后,对V∈RT×DV \in \mathbb{R}^{T \times D}V∈RT×D加权求和,得到最终的注意力模块输出。
多头注意力
![![[Pasted image 20251012122505.png]]](https://i-blog.csdnimg.cn/direct/49ffb890c6bc4a349bf3c6659dd00403.png)
多头注意力通过缩放点积注意力机制应用于多组query,key和value相量,在每组注意力机制之后将结果合并,从而允许模型在不同的表示空间中同时关注多个方面的信息
对于
Q∈RT×D=FC1(X)=X⋅W1∈RC×DQ \in \mathbb{R}^{T \times D}=FC_1(X)=X \cdot W_1 \in \mathbb{R}^{C \times D}Q∈RT×D=FC1(X)=X⋅W1∈RC×DK∈RT×D=FC2(X)=X⋅W2∈RC×DK \in \mathbb{R}^{T \times D}=FC_2(X)=X \cdot W_2 \in \mathbb{R}^{C \times D}K∈RT×D=FC2(X)=X⋅W2∈RC×DV∈RT×D=FC3(X)=X⋅W3∈RC×DV \in \mathbb{R}^{T \times D}=FC_3(X)=X \cdot W_3 \in \mathbb{R}^{C \times D}V∈RT×D=FC3(X)=X⋅W3∈RC×D
通过split+reshape操作变换为H组QKV向量 ∈RH×T×d\in \mathbb{R}^{H \times T \times d}∈RH×T×d,其中d是每个头的通道数,D=H×dD = H \times dD=H×d
Q′∈RH×T×d=reshape(Q)Q' \in \mathbb{R}^{H \times T \times d}=reshape(Q)Q′∈RH×T×d=reshape(Q)
K′∈RH×T×d=reshape(K)K' \in \mathbb{R}^{H \times T \times d}=reshape(K)K′∈RH×T×d=reshape(K)
V′∈RH×T×d=reshape(V)V' \in \mathbb{R}^{H \times T \times d}=reshape(V)V′∈RH×T×d=reshape(V)
每个注意力头进行注意力运算后,再通过concat拼接,并通过reshape恢复shape,最后通过一个线性层对H个子空间的特征进行融合,得到多头注意力机制的输出矩阵Y∈RT×DY\in \mathbb{R}^{T \times D}Y∈RT×D
Yi∈RT×d=Attention(Q′,K′,V′)Y_i \in \mathbb{R}^{T \times d}=Attention(Q',K',V')Yi∈RT×d=Attention(Q′,K′,V′)
Y∈RH×T×d=Concat(Y1,⋯,YH)Y \in \mathbb{R}^{H \times T \times d}=Concat(Y_1,\cdots,Y_H)Y∈RH×T×d=Concat(Y1,⋯,YH)
Y∈RT×D=reshape(Y)Y\in \mathbb{R}^{T \times D}=reshape(Y)Y∈RT×D=reshape(Y)
Y∈RT×D=Y⋅WY \in \mathbb{R}^{T \times D } = Y \cdot WY∈RT×D=Y⋅W
本文使用了八个平行的注意力层每一个都使用了dk=dv=dmodel/h=64d_k=d_v=d_{model}/h=64dk=dv=dmodel/h=64
由于每个头维度减少,计算成本和全维度的单头注意力相似
注意力在模型中的应用
Transformer以三种不同方式使用多头注意力:
在编码器-解码器层,查询前一个解码器和来自前一个解码器的层、内存KV,允许每个解码器都关注输入序列的所有位置
编码器包含自注意力层,在自注意力层中,QKV都来自都一个位置,在本例中,编码器中的每个位置都可以关注编码器上一层中所有位置。
类似的,解码器的自注意力层允许每个位置关注所有位置,为防止解码器的信息向左流动(屏蔽当前位置右侧信息的干扰,保证自回归生成的合理性),使用mask进行屏蔽
位置前馈网络
在编码器和解码器中每一层都包含有一个全连接的FFN
先升维度从512升至2048,为ReLU提供更充足的“特征空间”
然后通过ReLU函数激活
再次降维,方便后续衔接
FFN(x)=(ReLU(x⋅W1+b1))W2+b2FFN(x)=(ReLU(x \cdot W_1+b_1))W_2 +b_2FFN(x)=(ReLU(x⋅W1+b1))W2+b2
为什么是自注意力机制
![![[Pasted image 20251012144942.png]]](https://i-blog.csdnimg.cn/direct/acd9ed7f68ba47e3b9bee8708eb45f49.png)
自注意力机制通过恒定的顺序执行🔗所有位置,自注意力机制比循环层快当序列长度n比特征维度d更小时,且并行计算量和远程依赖关系之间的路径长度更短
实验部分
实验设置
我们在标准 WMT 2014 英德数据集上进行了训练,该数据集由大约 450 万个句子对组成。使用字节对编码对句子进行编码,该编码具有约 37000 个标记的共享源目标词汇表。对于英法语,我们使用了更大的 WMT 2014 英法语数据集,该数据集由 36M 个句子组成,并将标记拆分为 32000 个单词的词汇表。 句子对按近似序列长度批处理在一起。每个训练批次包含一组句子对,其中包含大约 25000 个源标记和 25000 个目标标记。
我们在一台配备 8 个 NVIDIA P100 GPU 的机器上训练了我们的模型。对于使用整篇论文中描述的超参数的基础模型,每个训练步骤大约需要 0.4 秒。我们对基础模型进行了总共 100,000 步或 12 小时的训练。对于我们的大模型,步进时间为 1.0 秒。大模型训练了 300,000 步(3.5 天)。
机器翻译
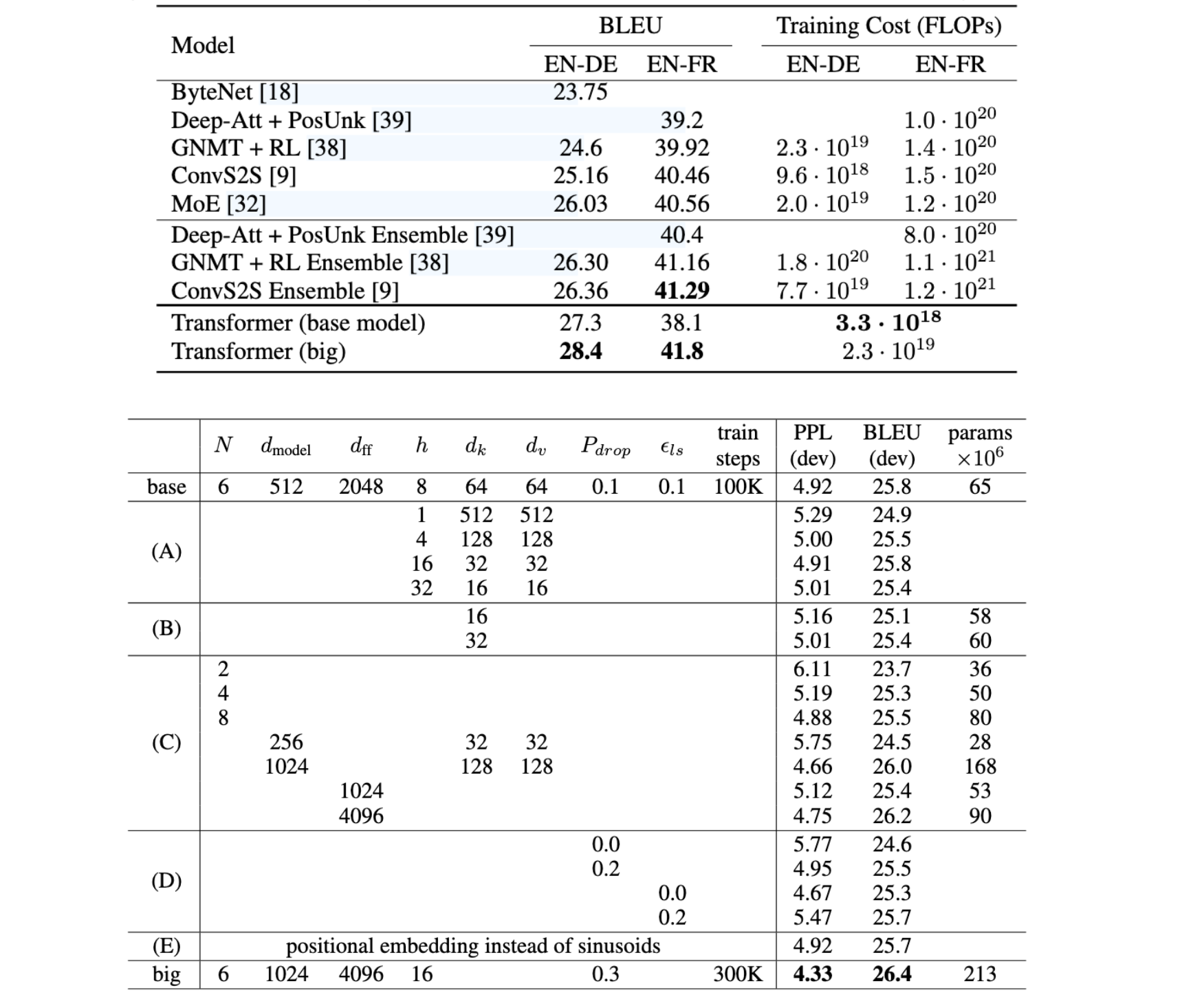
在 WMT 2014 英德翻译任务中,大 Transformer 模型(表 2 中的 Transformer (big))的性能优于之前报告的最佳模型(包括集成)超过 2.0 BLEU,建立了新的最先进的 BLEU 分数 28.4 。该型号的配置列在表 3 的底行中。在 P100 GPU 上 8 进行训练需要数天时间 3.5 。甚至我们的基础模型也超过了所有以前发布的模型和集成,而训练成本只是任何竞争模型的一小部分。
在 WMT 2014 英法翻译任务中,我们的大模型获得了 41.0 的 BLEU 分数,优于之前发布的所有单个模型,而 1/4 训练成本低于之前最先进模型的训练成本。针对英语到法语训练的 Transformer(大)模型使用辍学率 Pdrop=0.1 ,而不是 0.3 。
型号变化(消融实验?)
为了评估 Transformer 不同组件的重要性,我们以不同的方式改变了基础模型,测量了开发集 newstest2013 上英德翻译性能的变化。我们使用了上一节中描述的波束搜索,但没有检查点平均。我们在表 [3] 中列出了这些结果。
在A中改变了注意力头的数量以及注意力KV的维度,保持计算量不变,虽然单头注意力比最佳设置差了0.9BLEU,但质量会随着头部过多而下降
在B中观察到减少注意力键大小dkd_kdk会损害模型质量
在CD中发现模型越大越好
E中将位置嵌入替换成了正弦位置编码,并观察到与基本模型几乎相同的结果
英语选区解析
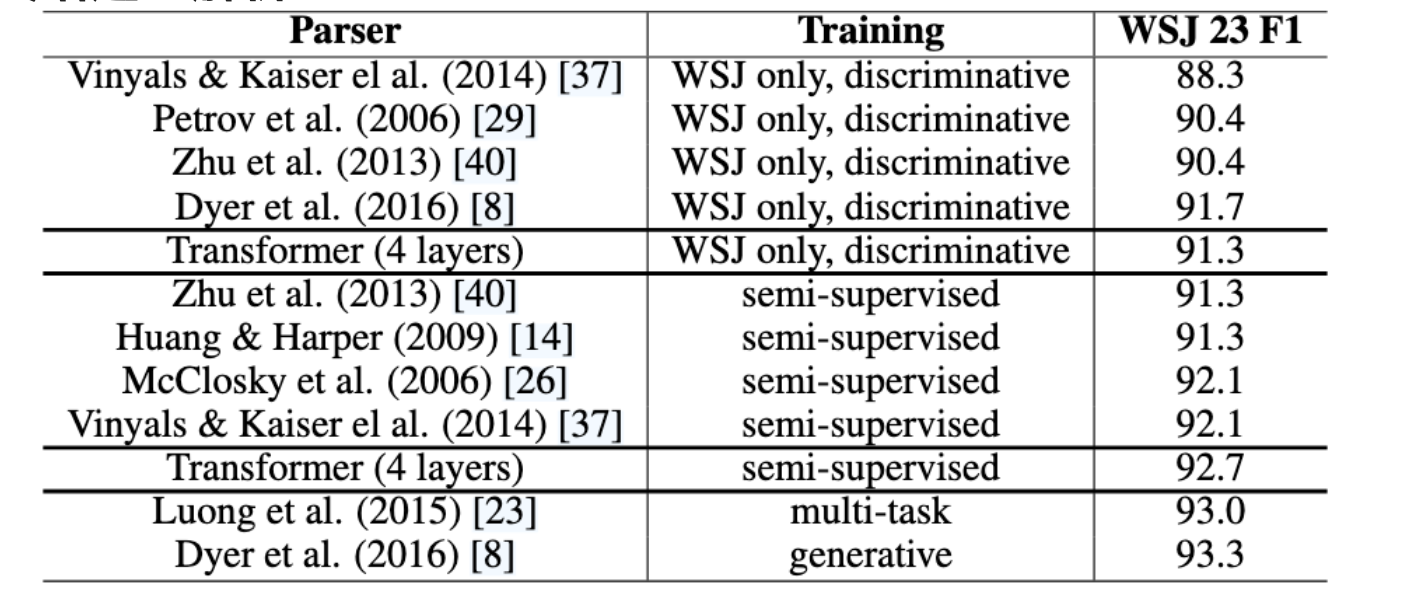
为了评估 Transformer 是否可以推广到其他任务,我们进行了英语选区解析实验。这项任务提出了具体的挑战:产出受到强烈的结构限制,并且明显长于投入。此外,RNN 序列到序列模型在小数据条件下无法获得最先进的结果
表 中的结果表明,尽管缺乏特定于任务的调整,但我们的模型表现得非常好,比之前报道的所有模型都产生了更好的结果,但循环神经网络语法除外
与 RNN 相比,Transformer 的性能优于 BerkeleyParser,即使仅在 WSJ 的 40K 句子训练集上进行训练也是如此。
结论
方法
提出了Transformer,第一个完全基于注意力的序列转导模型,用多头自注意力取代了编码器-解码器架构中最常见的循环层
效果
对于翻译任务Transformer的训练速度比基于递归或卷积层的架构快得多,在 WMT 2014 英德语和 WMT 2014 英法翻译任务中,都达到了新的技术水平。在前一个任务中,最佳模型甚至优于所有先前报告的集合。
展望未来
计划将Transformer拓展到设计文本以外的输入或输出模式的问题,并研究局部的、受限的注意力机制,以有效地处理图像、音频和视频等大型输入和输出。减少生成的顺序是另一个研究目标。