水田智能监控系统
“水田智能监控系统”
(也叫“智慧稻田监测系统”或“智慧农业水稻管理系统”)的方案和项目,
通常是结合 物联网(IoT)+ 云平台 + 农业大数据 + AI 控制 的综合系统。
🌾 一、水田智能监控系统的总体目标
通过传感器、网络和智能算法,对水田的 水位、水温、土壤湿度、气象数据 等进行实时采集、分析和控制,从而实现:
- 智能灌溉与排水;
- 精准施肥与农药喷洒决策;
- 远程视频监控与自动告警;
- 节水节能、提高产量与质量。
⚙️ 二、系统总体架构(典型三层)
1️⃣ 感知层(硬件设备)
负责数据采集与执行控制,主要包括:
-
传感器:
- 水位传感器
- 土壤湿度传感器
- 水温/气温/光照/PH值/溶氧传感器
-
控制设备:
- 电磁阀、水泵、闸门执行器
- 摄像头(可见光/红外)
-
通信模块:
- LoRa、NB-IoT、4G/5G 模块,用于数据上报
2️⃣ 网络与传输层
- LoRaWAN、NB-IoT、4G、WiFi 等方式传输数据;
- 常配合 边缘网关(如树莓派、ESP32、STM32+NB模块)进行本地预处理;
- 通信协议常用 MQTT、HTTP、Modbus、CoAP 等。
3️⃣ 平台与应用层(软件部分)
在服务器或云端进行:
- 实时数据展示(仪表盘、曲线图)
- 远程控制与策略执行(自动灌溉逻辑)
- 报警与通知(阈值越限短信/微信推送)
- 历史数据存储与分析(数据库 + 可视化)
- 机器学习预测(基于气象数据的智能决策)
💻 三、常用技术与工具(可用于毕业设计或项目实现)
| 模块 | 技术/平台 | 说明 |
|---|---|---|
| 数据采集 | STM32 / ESP32 / Arduino + 各类传感器 | 采集与传输数据 |
| 无线通信 | LoRa / NB-IoT / WiFi / 4G | 根据环境和距离选择 |
| 网关/边缘计算 | 树莓派 / Jetson Nano | 数据预处理、控制逻辑 |
| 服务器端 | Flask / Django / Node.js / SpringBoot | 提供接口与数据存储 |
| 数据库 | MySQL / InfluxDB / MongoDB | 存储实时与历史数据 |
| 前端展示 | Vue / React / ECharts | 实时监控大屏、图表 |
| 云平台 | 阿里云 IoT / ThingsBoard / OneNet | 可快速搭建物联网管理平台 |
| AI 应用 | TensorFlow / PyTorch / Sklearn | 预测灌溉、虫害识别 |
📊 四、系统功能示例
| 功能模块 | 说明 |
|---|---|
| 实时监控 | 显示各田块水位、水温、湿度、气象数据 |
| 视频监控 | 远程查看现场视频画面 |
| 自动控制 | 根据设定阈值自动开关阀门或水泵 |
| 报警系统 | 超过水位/温度上限自动推送消息 |
| 数据分析 | 曲线趋势、历史对比、自动报表 |
| 预测建议 | AI 分析最佳灌溉时机或肥料用量 |
🧠 五、可扩展方向(项目进阶)
- 加入 图像识别模块(识别病虫害、叶片颜色变化);
- 实现 手机App或小程序端控制;
- 与 无人机巡检系统 联动;
- 与气象局 API 或本地气象站联动;
- 接入 农业知识库,实现智能决策。
🧩 六、样例系统结构图(逻辑)
传感器/执行器层 → 网关/边缘节点 → 云服务器(数据库+API) → Web前端/移动端
例如:
- ESP32 采集水位→通过 MQTT 发送至阿里云 IoT;
- 云端通过规则引擎判断水位过低→下发命令→ESP32 控制水泵;
- 同时在 Web 页面显示数据曲线与日志。
🚀 七、适合做项目的方向(按复杂度)
| 难度 | 项目方向 | 说明 |
|---|---|---|
| ⭐ 基础 | 水位+温湿度+阀门控制 | 1~2块田、简单阈值控制 |
| ⭐⭐ 进阶 | 加入 LoRa/NB-IoT + 云平台 | 远程多节点采集 |
| ⭐⭐⭐ 完整 | 云端大屏+AI预测+自动控制 | 综合物联网系统(适合毕业设计) |
import random
import time
from datetime import datetimeclass SmartRiceField:def __init__(self):# 初始化模拟传感器数据self.water_level = random.uniform(5.0, 10.0) # 当前水位(cm)self.temperature = random.uniform(20.0, 30.0) # 水温(℃)self.humidity = random.uniform(70.0, 90.0) # 空气湿度(%)self.valve_open = False # 阀门状态self.pump_on = False # 水泵状态# 阈值配置self.water_min = 6.0self.water_max = 9.0def read_sensors(self):"""模拟传感器数据变化"""# 模拟传感器自然波动self.water_level += random.uniform(-0.2, 0.2)self.temperature += random.uniform(-0.1, 0.1)self.humidity += random.uniform(-0.5, 0.5)# 保证数值合理范围self.water_level = max(0, min(self.water_level, 15))self.temperature = max(10, min(self.temperature, 40))self.humidity = max(0, min(self.humidity, 100))def control_logic(self):"""根据水位执行控制逻辑"""if self.water_level < self.water_min:self.pump_on = Trueself.valve_open = Trueaction = "💧 水位过低 → 打开水泵补水"elif self.water_level > self.water_max:self.pump_on = Falseself.valve_open = Falseaction = "⚠️ 水位过高 → 关闭水泵防止积水"else:action = "✅ 水位正常 → 保持当前状态"return actiondef report_status(self):"""打印实时状态"""now = datetime.now().strftime("%Y-%m-%d %H:%M:%S")print(f"\n[{now}]")print(f"水位: {self.water_level:.2f} cm | 温度: {self.temperature:.1f}℃ | 湿度: {self.humidity:.1f}%")print(f"水泵状态: {'开启' if self.pump_on else '关闭'} | 阀门: {'打开' if self.valve_open else '关闭'}")def send_to_cloud(self):"""模拟上传数据到云端"""# 这里只是打印模拟数据上传print("☁️ 上传数据到云平台中……")# ========== 主程序 ==========
if __name__ == "__main__":field = SmartRiceField()print("🌾 智慧水田监控系统启动中...\n")for i in range(10): # 模拟 10 个采集周期field.read_sensors()action = field.control_logic()field.report_status()print(action)field.send_to_cloud()time.sleep(2) # 等待2秒模拟实时监控
# app.py
import streamlit as st
import pandas as pd
import numpy as np
import time
from datetime import datetime, timedelta
import plotly.express as px
import plotly.graph_objects as go
import pydeck as pdkst.set_page_config(layout="wide", page_title="智慧水田大屏", initial_sidebar_state="collapsed")# --------------------------
# 配置 & 辅助函数
# --------------------------
@st.cache_data
def generate_fake_data(num_points=120, field_center=(31.0, 120.0)):"""生成模拟传感器时序数据(每分钟一条,默认120点=2小时)传感器:土壤含水量(%)、水位(cm)、电导率(EC)、空气温度(°C)、空气湿度(%)每个点带经纬度(分布在田块周围)"""now = datetime.utcnow()timestamps = [now - timedelta(minutes=(num_points - 1 - i)) for i in range(num_points)]lat0, lon0 = field_centerdata = []sensor_count = 6 # 假设6个传感器节点for t in timestamps:for n in range(sensor_count):lat = lat0 + np.random.uniform(-0.0008, 0.0008)lon = lon0 + np.random.uniform(-0.0012, 0.0012)soil_moist = np.clip(45 + 10*np.sin((t.minute + n)/12.0) + np.random.normal(0,2), 10, 90) # %water_level = np.clip(12 + 3*np.cos((t.minute + n)/8.0) + np.random.normal(0,0.6), 0, 30) # cmec = np.clip(0.6 + 0.2*np.sin((t.minute + n)/6.0) + np.random.normal(0,0.03), 0.2, 2.0) # mS/cmatmp = np.clip(22 + 6*np.sin((t.hour + n)/3.0) + np.random.normal(0,0.7), -5, 45)ahum = np.clip(60 + 20*np.cos((t.minute + n)/15.0) + np.random.normal(0,3), 10, 100)data.append({"timestamp": t,"node": f"node_{n+1}","lat": lat,"lon": lon,"soil_moist": round(soil_moist,2),"water_level": round(water_level,2),"ec": round(ec,3),"air_temp": round(atmp,2),"air_hum": round(ahum,1),})df = pd.DataFrame(data)return dfdef latest_metrics(df):latest = df.sort_values("timestamp").groupby("node").tail(1)return {"avg_soil_moist": latest["soil_moist"].mean(),"avg_water_level": latest["water_level"].mean(),"avg_ec": latest["ec"].mean(),"avg_air_temp": latest["air_temp"].mean(),"avg_air_hum": latest["air_hum"].mean(),"last_update": latest["timestamp"].max()}def small_kpi_card(label, value, unit=""):st.metric(label, f"{value:.2f} {unit}" if isinstance(value, (int,float)) else f"{value} {unit}")# --------------------------
# 数据准备
# --------------------------
# 模拟或真实数据入口:替换下面这行以接入真实数据源
df = generate_fake_data(num_points=240, field_center=(31.2304, 121.4737)) # 可调整点数 / 中心位置metrics = latest_metrics(df)# --------------------------
# 页面布局(大屏风格)
# --------------------------
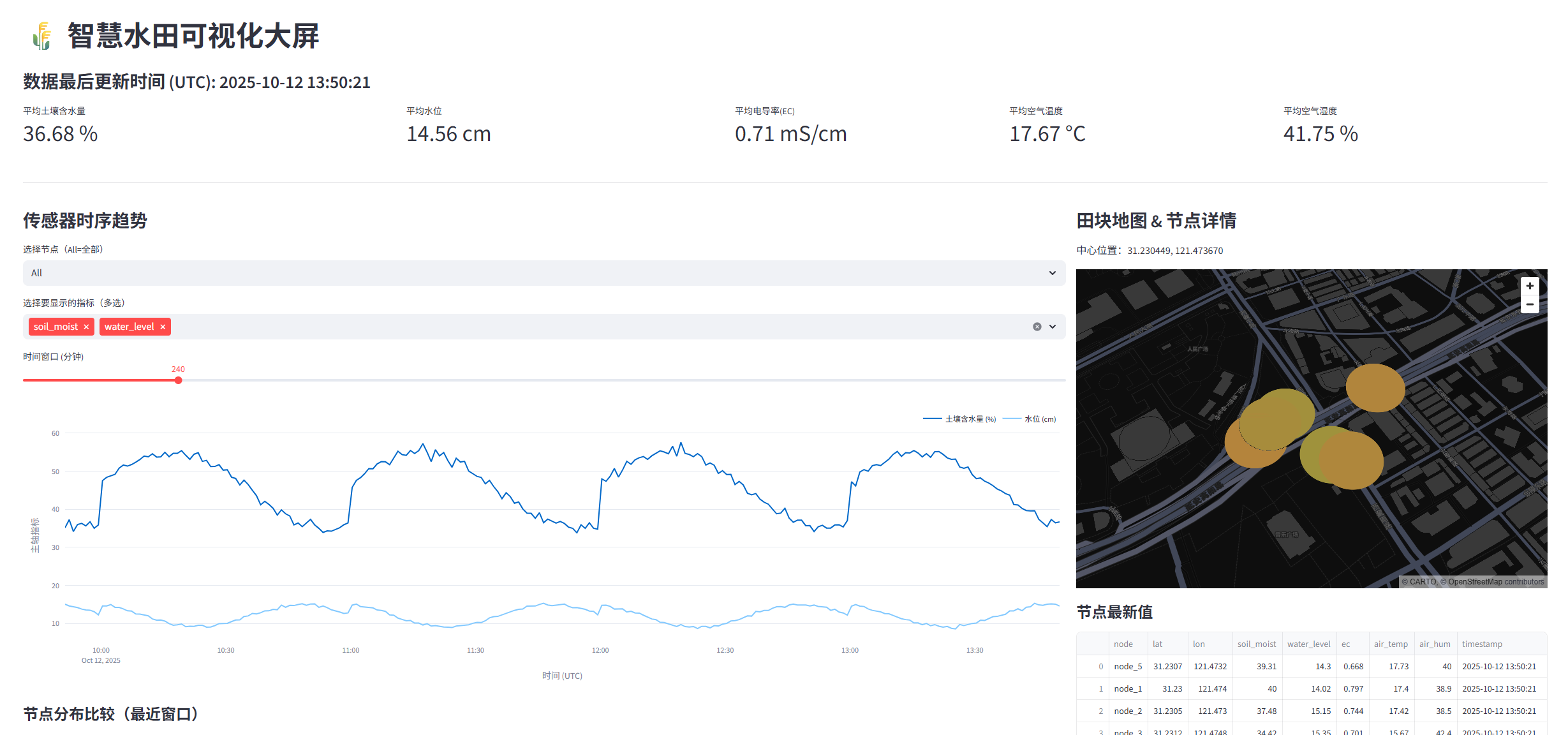
st.title("🌾 智慧水田可视化大屏")
st.subheader(f"数据最后更新时间 (UTC): {metrics['last_update'].strftime('%Y-%m-%d %H:%M:%S')}")# 顶部 KPI 行
kpi_col1, kpi_col2, kpi_col3, kpi_col4, kpi_col5 = st.columns([1.4,1.2,1,1,1])
with kpi_col1:small_kpi_card("平均土壤含水量", metrics["avg_soil_moist"], "%")
with kpi_col2:small_kpi_card("平均水位", metrics["avg_water_level"], "cm")
with kpi_col3:small_kpi_card("平均电导率(EC)", metrics["avg_ec"], "mS/cm")
with kpi_col4:small_kpi_card("平均空气温度", metrics["avg_air_temp"], "°C")
with kpi_col5:small_kpi_card("平均空气湿度", metrics["avg_air_hum"], "%")st.markdown("---")# 左:趋势图、右:地图与节点详情
left, right = st.columns([2.2,1])
with left:st.markdown("### 传感器时序趋势")# 用户可以选时间范围与指标nodes = sorted(df["node"].unique().tolist())selected_node = st.selectbox("选择节点(All=全部)", ["All"] + nodes, index=0)metric_options = ["soil_moist", "water_level", "ec", "air_temp", "air_hum"]metric_map = {"soil_moist": "土壤含水量 (%)","water_level": "水位 (cm)","ec": "电导率 (mS/cm)","air_temp": "空气温度 (°C)","air_hum": "空气湿度 (%)"}selected_metrics = st.multiselect("选择要显示的指标(多选)", metric_options, default=["soil_moist","water_level"])time_window = st.slider("时间窗口 (分钟)", min_value=30, max_value=1440, value=240, step=30)cutoff = df["timestamp"].max() - timedelta(minutes=time_window)df_window = df[df["timestamp"] >= cutoff]if selected_node != "All":df_window = df_window[df_window["node"] == selected_node]# Plotly 折线图 — 多指标在同图(使用次坐标)fig = go.Figure()colors = px.colors.qualitative.T10for i, m in enumerate(selected_metrics):# 聚合成按时间的平均(跨节点)agg = df_window.groupby("timestamp")[m].mean().reset_index()fig.add_trace(go.Scatter(x=agg["timestamp"],y=agg[m],name=metric_map[m],yaxis="y1" if i < 2 else "y2" # 把前两个放主轴,剩下放副轴(简化)))fig.update_layout(legend=dict(orientation="h", yanchor="bottom", y=1.02, xanchor="right", x=1),margin={"l":30,"r":10,"t":30,"b":30},xaxis_title="时间 (UTC)",yaxis=dict(title="主轴指标"),yaxis2=dict(title="副轴指标", overlaying="y", side="right"))st.plotly_chart(fig, use_container_width=True)# 节点比较(箱线/小提琴)st.markdown("#### 节点分布比较(最近窗口)")compare_metric = st.selectbox("选择比较指标", metric_options, index=0)box_fig = px.box(df_window, x="node", y=compare_metric, points="all", title=f"{metric_map[compare_metric]} 各节点分布")st.plotly_chart(box_fig, use_container_width=True)with right:st.markdown("### 田块地图 & 节点详情")latest = df.sort_values("timestamp").groupby("node").tail(1)# 使用 streamlit.pydeck 显示热力/节点midpoint = (latest["lat"].mean(), latest["lon"].mean())st.markdown(f"中心位置:{midpoint[0]:.6f}, {midpoint[1]:.6f}")# pydeck 层layer = pdk.Layer("ScatterplotLayer",data=latest,get_position='[lon, lat]',get_fill_color='[255 * (1 - (soil_moist-10)/80), 80 + ((soil_moist-10)/80)*175, 60]',get_radius=50,pickable=True)view_state = pdk.ViewState(latitude=midpoint[0], longitude=midpoint[1], zoom=16, pitch=30)deck = pdk.Deck(layers=[layer], initial_view_state=view_state, tooltip={"text":"节点: {node}\n土壤含水: {soil_moist}%\n水位: {water_level} cm\nEC: {ec}"})st.pydeck_chart(deck)st.markdown("#### 节点最新值")st.dataframe(latest[["node","lat","lon","soil_moist","water_level","ec","air_temp","air_hum","timestamp"]].reset_index(drop=True))# --------------------------
# 告警与自动化规则(示例)
# --------------------------
st.markdown("---")
st.markdown("## 告警规则与自动联动(示例)")
col_a, col_b, col_c = st.columns(3)
with col_a:soil_thresh = st.number_input("土壤含水下限(%)", value=20.0)
with col_b:water_thresh = st.number_input("水位下限(cm)", value=3.0)
with col_c:ec_thresh = st.number_input("电导率上限 (mS/cm)", value=1.5)# 计算告警
latest_all = df.sort_values("timestamp").groupby("node").tail(1)
alerts = []
for _, row in latest_all.iterrows():if row["soil_moist"] < soil_thresh:alerts.append((row["node"], "低土壤含水", row["soil_moist"]))if row["water_level"] < water_thresh:alerts.append((row["node"], "低水位", row["water_level"]))if row["ec"] > ec_thresh:alerts.append((row["node"], "EC偏高", row["ec"]))if alerts:st.error(f"发现 {len(alerts)} 条异常告警:")for a in alerts:st.write(f"- 节点 {a[0]}:{a[1]} = {a[2]}")
else:st.success("当前无告警")# --------------------------
# 历史数据导出与自定义查询
# --------------------------
st.markdown("---")
st.markdown("### 历史数据导出")
export_period = st.selectbox("导出时间范围", ["最近1小时","最近6小时","最近24小时","全部"], index=2)
if export_period == "最近1小时":dr = df["timestamp"].max() - timedelta(hours=1)
elif export_period == "最近6小时":dr = df["timestamp"].max() - timedelta(hours=6)
elif export_period == "最近24小时":dr = df["timestamp"].max() - timedelta(hours=24)
else:dr = df["timestamp"].min() - timedelta(seconds=1)
export_df = df[df["timestamp"] >= dr]
st.write(f"匹配记录:{len(export_df)} 条")
@st.cache_data
def to_excel_bytes(df):import iowith io.BytesIO() as output:writer = pd.ExcelWriter(output, engine="openpyxl")df.to_excel(writer, index=False, sheet_name="history")writer.save()return output.getvalue()if st.button("下载 Excel"):b = to_excel_bytes(export_df)st.download_button("点击下载历史数据.xlsx", data=b, file_name="waterfield_history.xlsx", mime="application/vnd.openxmlformats-officedocument.spreadsheetml.sheet")