mysql基础【函数 与 约束】
1. 函数
- 函数是一段可以直接被另一段程序调用的代码片段,在 SQL 中用于对数据进行处理和转换,提升查询效率与灵活性。
- 例如:计算入职天数、判断成绩等级、拼接姓名、格式化日期等,都可以通过内置函数快速实现。
1.1 字符串函数
用于对文本型数据进行操作,如拼接、截取、大小写转换、填充等。
注意:MySQL中字符串位置从1开始计数
1.1.1常用字符串函数一览
| 函数 | 功能说明 |
|---|---|
CONCAT(s1, s2, ..., sn) | 将多个字符串连接成一个新字符串 |
LOWER(str) | 将字符串全部转为小写 |
UPPER(str) | 将字符串全部转为大写 |
LPAD(str, n, pad) | 左填充:用 pad 字符从左边填充 str 至长度 n |
RPAD(str, n, pad) | 右填充:用 pad 字符从右边填充 str 至长度 n |
TRIM(str) | 去除字符串首尾的空格(也可指定字符) |
SUBSTRING(str, start, len) | 返回从 start 位置开始、长度为 len 的子串 |
1.1.2整体示例
1.1.2.1 基础示例:
-- 字符串函数-- CONCAT: 将两个或多个字符串连接成一个字符串
-- 结果为 'HelloMySQL'
SELECT CONCAT('Hello','MySQL');-- LOWER: 将字符串中的所有字符转换为小写
-- 结果为 'hello'
SELECT LOWER('Hello');-- UPPER: 将字符串中的所有字符转换为大写
-- 结果为 'HELLO'
SELECT UPPER('Hello');-- LPAD: 在字符串的左侧填充指定字符,直到达到指定长度
-- 以下语句将字符串 '01' 左侧用 'A' 填充至总长度为
-- 结果为 'AAA01'
SELECT LPAD('01',5,'A');-- RPAD: 在字符串的右侧填充指定字符,直到达到指定长度
-- 以下语句将字符串 '01' 右侧用 'A' 填充至总长度为 5
-- 结果为 '01AAA'
SELECT RPAD('01',5,'A');-- TRIM: 去除字符串首尾的空格(或其他指定字符)
-- 结果为 'Hello MySQL'
SELECT TRIM(' Hello MySQL ');-- SUBSTRING: 从字符串中截取指定位置和长度的子字符串
-- 以下语句从第1个字符开始,截取5个字符
-- 结果为 'Hello'
-- 注意:MySQL中字符串位置从1开始计数
SELECT SUBSTRING('Hello MySQL',1,5);
1.1.2.2 综合示例:
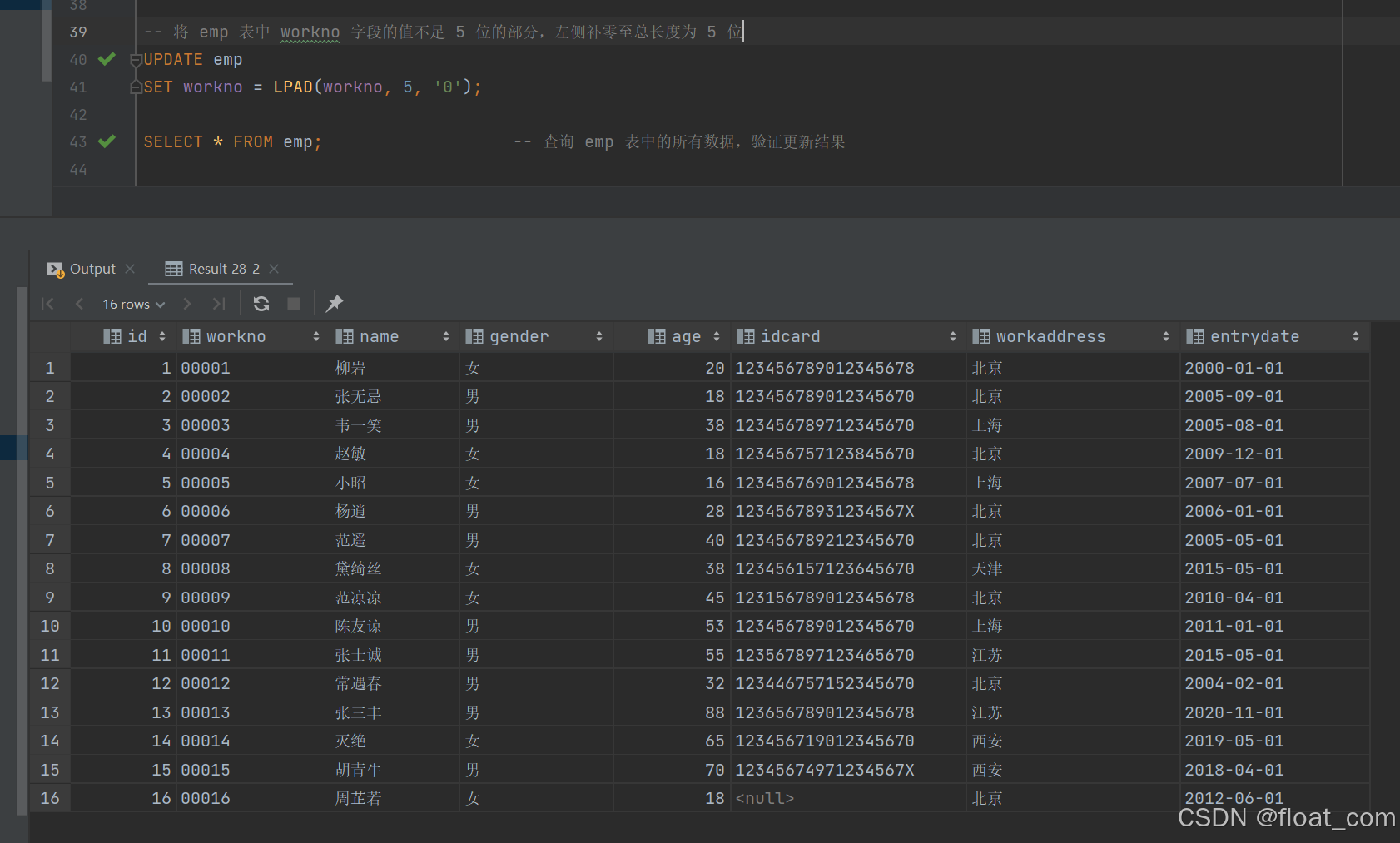
- 将 emp 表中 workno 字段的值不足 5 位的部分,左侧补零至总长度为 5 位
UPDATE emp
SET workno = LPAD(workno, 5, '0');SELECT * FROM emp; -- 查询 emp 表中的所有数据,验证更新结果
1.2 数值函数
用于对数字型数据进行数学运算或格式化处理。
1.2.1常用数值函数一览
| 函数 | 功能说明 |
|---|---|
CEIL(x) | 向上取整(向上舍入) |
FLOOR(x) | 向下取整(向下舍入) |
MOD(x, y) | 返回 x ÷ y 的余数(模运算) |
RAND() | 返回 0~1 之间的随机浮点数 |
ROUND(x, y) | 对 x 四舍五入,保留 y 位小数 |
1.2.2整体示例
1.2.2.1基础示例:
-- CEIL: 返回大于或等于指定数值的最小整数(向上取整)
-- 结果为 2
SELECT CEIL(1.2);-- FLOOR: 返回小于或等于指定数值的最大整数(向下取整)
-- 结果为 1
SELECT FLOOR(1.2);-- MOD: 返回两数相除的余数,即取模运算
-- 结果为 3
SELECT MOD(3,4);-- RAND: 返回一个介于 0 和 1 之间的随机浮点数(包含 0,不包含 1)
SELECT RAND();-- ROUND: 对数值进行四舍五入,保留指定的小数位数
-- 结果为 1.26
SELECT ROUND(1.2564, 2);
1.2.2.2综合示例:
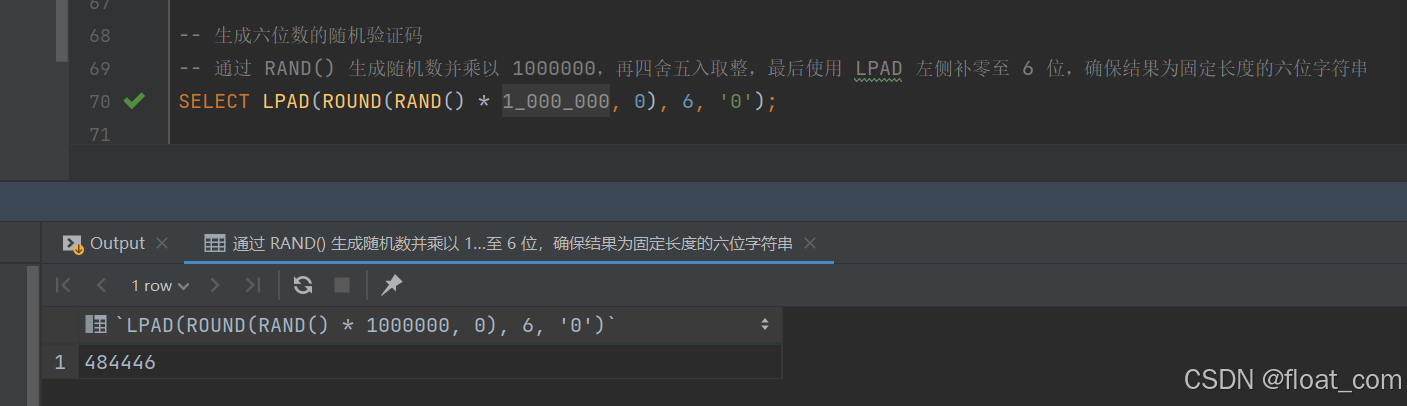
- 生成六位数的随机验证码
-- 通过 RAND() 生成随机数并乘以 1000000,再四舍五入取整,最后使用 LPAD 左侧补零至 6 位,确保结果为固定长度的六位字符串
SELECT LPAD(ROUND(RAND() * 1000000, 0), 6, '0');
1.3 日期函数
用于处理日期和时间数据,是数据分析中非常关键的一类函数。
1.3.1常用日期函数一览
| 函数 | 功能说明 |
|---|---|
CURDATE() | 返回当前日期(YYYY-MM-DD) |
CURTIME() | 返回当前时间(HH:MM:SS) |
NOW() | 返回当前日期和时间(YYYY-MM-DD HH:MM:SS) |
YEAR(date) | 获取指定日期的年份 |
MONTH(date) | 获取指定日期的月份 |
DAY(date) | 获取指定日期的日 |
DATE_ADD(date, INTERVAL expr type) | 在日期上增加指定的时间间隔 |
DATEDIFF(date1, date2) | 计算两个日期之间的天数差(date1 - date2) |
1.3.2整体示例
1.3.2.1基础示例:
-- CURDATE: 返回当前日期(不包含时间部分)
SELECT CURDATE();
-- 结果:2025-10-12-- CURTIME: 返回当前时间(不包含日期部分)
SELECT CURTIME();
-- 结果:20:13:45-- NOW: 返回当前的日期和时间(即系统当前的日期时间戳)
SELECT NOW();
-- 结果:2025-10-12 20:13:45-- YEAR: 提取指定日期中的年份
SELECT YEAR(NOW());
-- 结果:2025-- MONTH: 提取指定日期中的月份(1-12)
SELECT MONTH(NOW());
-- 结果:10-- DAY: 提取指定日期中的日(1-31)
SELECT DAY(NOW());
-- 结果:12-- DATE_ADD: 在指定日期上增加一个时间间隔
-- 以下语句分别在当前时间基础上增加:
-- 70年
SELECT DATE_ADD(NOW(), INTERVAL 70 YEAR);
-- 结果:2095-10-12 20:13:45-- 70个月
SELECT DATE_ADD(NOW(), INTERVAL 70 MONTH);
-- 结果:2031-08-12 20:13:45-- 70天
SELECT DATE_ADD(NOW(), INTERVAL 70 DAY);
-- 结果:2026-12-21 20:13:45-- DATEDIFF: 计算两个日期之间的天数差(第一个日期减去第二个日期)
SELECT DATEDIFF('2025-10-12', '2021-12-01');
-- 结果:1410
1.3.2.2综合示例:
- 查询员工姓名及其入职以来的天数,并按天数降序排列
-- 使用 DATEDIFF 函数计算从 entrydate 到今天(CURDATE())之间的天数
-- days 别名表示每位员工已工作的天数
-- 结果按工作天数从高到低排序,即工龄最长的排在前面
SELECTname,DATEDIFF(CURDATE(), entrydate) AS days
FROMemp
ORDER BYdays DESC;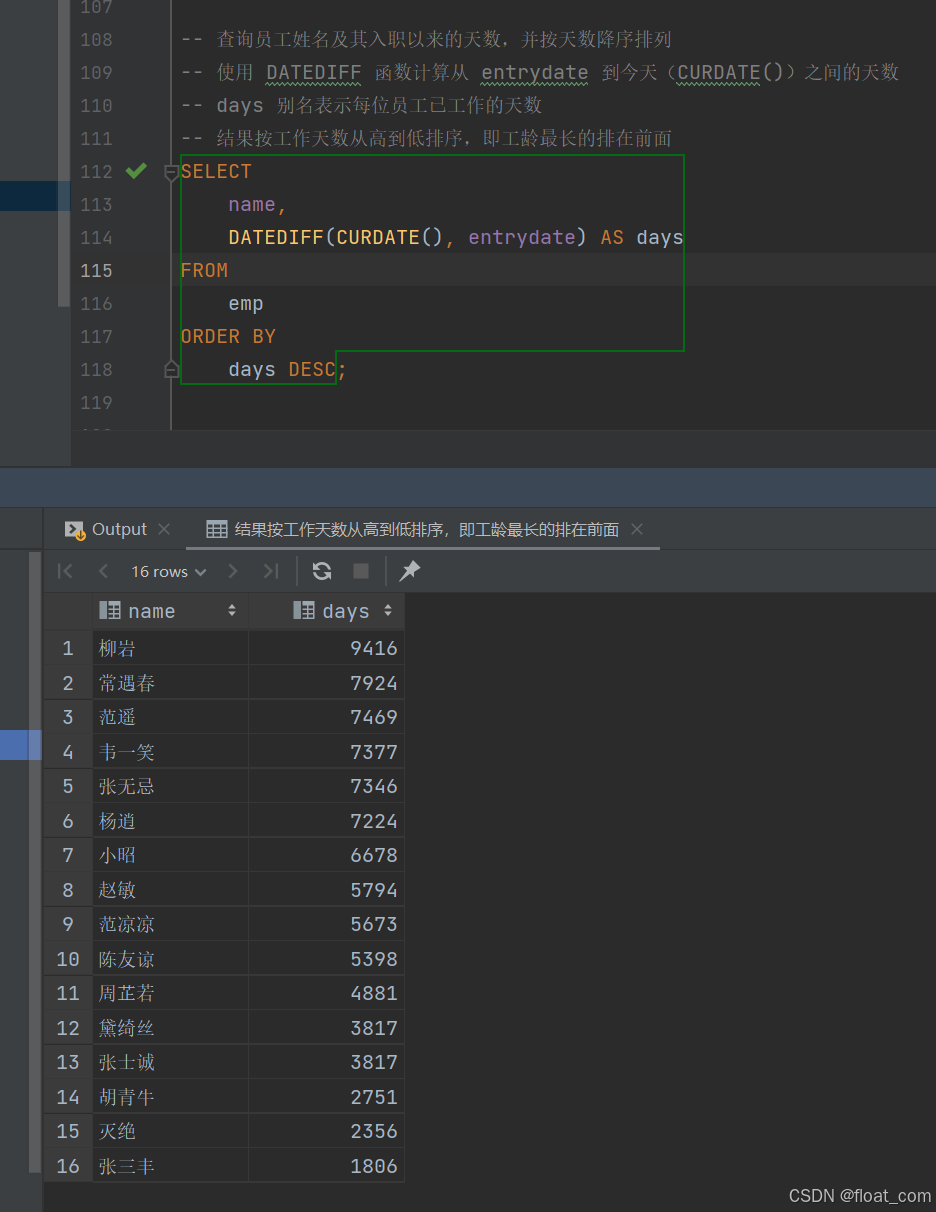
1.4 流程函数
用于在 SQL 查询中实现条件判断逻辑,替代复杂的 WHERE 条件或 CASE 语句,提高可读性和执行效率。
1.4.1 常用流程函数一览
| 函数 | 功能说明 |
|---|---|
IF(value, t, f) | 如果 value 为真,返回 t;否则返回 f |
IFNULL(value1, value2) | 如果 value1 不为空,返回 value1;否则返回 value2 |
CASE WHEN [val1] THEN [res1] ... ELSE [default] END | 根据布尔表达式判断返回结果 |
CASE [expr] WHEN [val1] THEN [res1] ... ELSE [default] END | 根据表达式值匹配返回结果 |
1.4.2整体示例
1.4.2.1基础示例:
-- IF(expr, v1, v2): 判断表达式 expr 是否为真
-- 如果为真,返回 v1;否则返回 v2
SELECT IF(1+1=3, 'OK', 'Error'); -- 1+1=3为假,返回'Error'-- IFNULL(value, default): 判断 value 是否为 NULL
-- 如果 value 不为 NULL,则返回 value 本身
-- 如果 value 为 NULL,则返回 default 值SELECT IFNULL('OK', 'Error'); -- 'OK' 非空,返回 'OK'
SELECT IFNULL('', 'Error'); -- 空字符串 '' 不是 NULL,返回 ''
SELECT IFNULL(NULL, 'Error'); -- 值为 NULL,返回 'Error'
1.4.2.2综合示例:
- 根据 workaddress 字段的值,返回对应的城市等级
- 布尔表达式判断
-- 如果工作地址是 '北京' 或 '上海',则归类为 '一线城市'
-- 其他所有情况(ELSE)归类为 '二线城市'
-- 查询员工姓名及其对应的工作地址分类
SELECTname,(CASE workaddressWHEN '北京' THEN '一线城市'WHEN '上海' THEN '一线城市'ELSE '二线城市'END) AS '工作地址'
FROMemp;
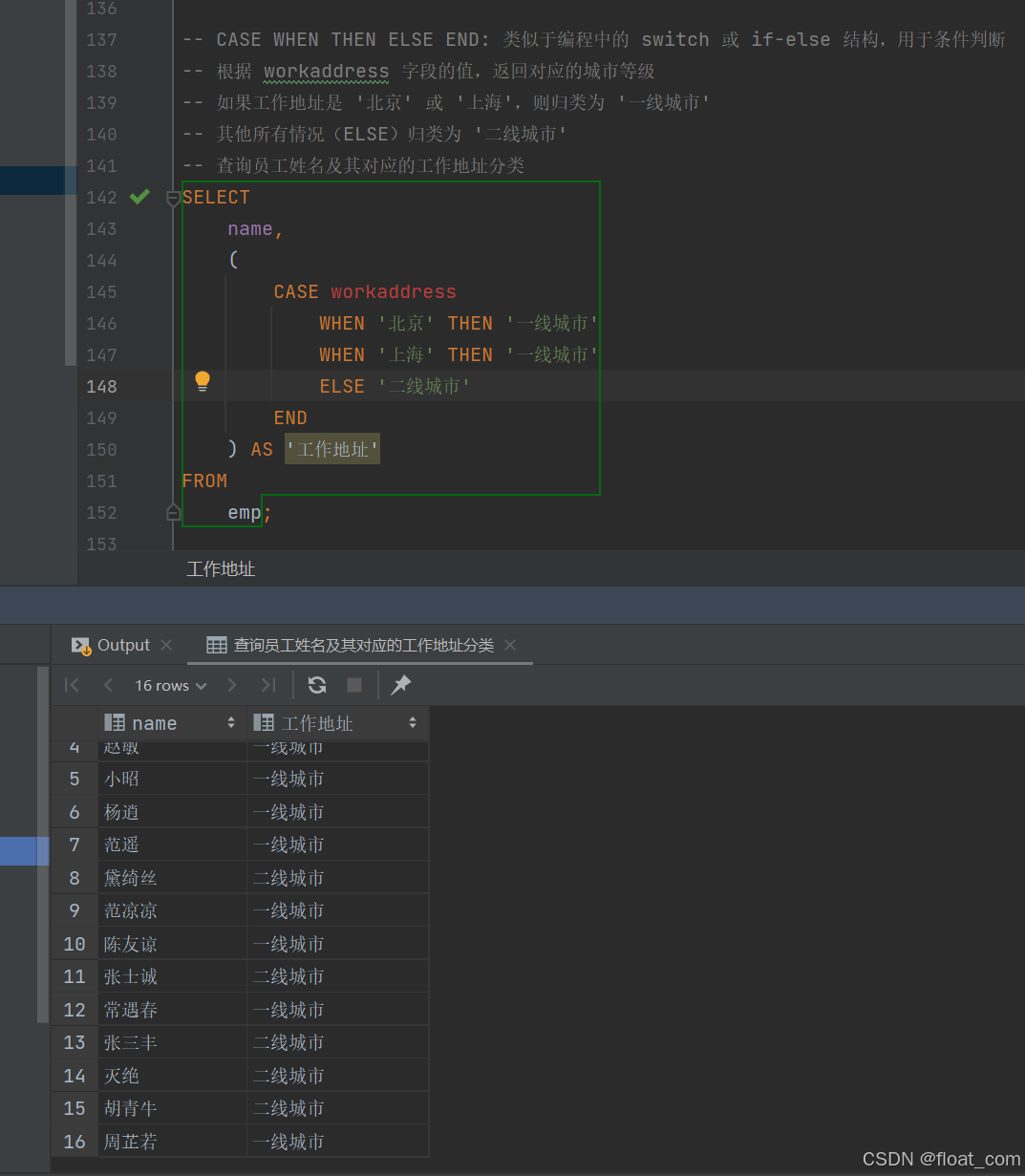
- 使用 CASE 语句对学生各科成绩进行等级划分
- 表达式值匹配
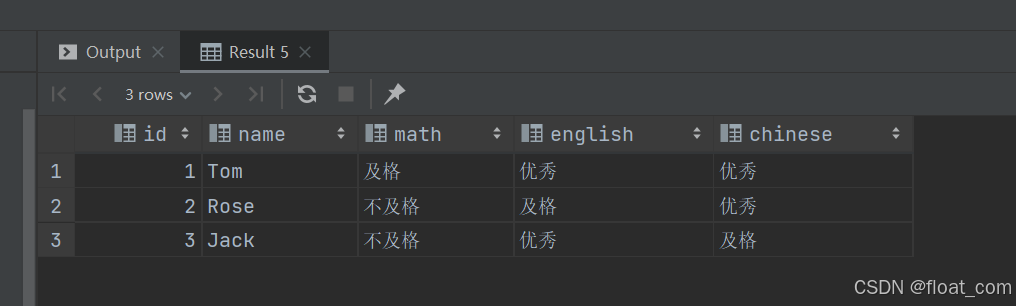
-- 查询学生ID、姓名以及数学、英语、语文三科的成绩等级SELECTid, -- 学生IDname, -- 学生姓名-- 对数学成绩(math)进行等级评定(CASEWHEN math >= 85 THEN '优秀' -- 数学成绩 >= 85 分,评为“优秀”WHEN math >= 60 THEN '及格' -- 数学成绩 >= 60 分(但 < 85),评为“及格”ELSE '不及格' -- 数学成绩 < 60 分,评为“不及格”END) AS math, -- 将评定结果命名为 math 列(覆盖原数值)-- 对英语成绩(english)进行等级评定(CASEWHEN english >= 85 THEN '优秀' -- 英语成绩 >= 85 分,评为“优秀”WHEN english >= 60 THEN '及格' -- 英语成绩 >= 60 分(但 < 85),评为“及格”ELSE '不及格' -- 英语成绩 < 60 分,评为“不及格”END) AS english, -- 将评定结果命名为 english 列-- 对语文成绩(chinese)进行等级评定(CASEWHEN chinese >= 85 THEN '优秀' -- 语文成绩 >= 85 分,评为“优秀”WHEN chinese >= 60 THEN '及格' -- 语文成绩 >= 60 分(但 < 85),评为“及格”ELSE '不及格' -- 语文成绩 < 60 分,评为“不及格”END) AS chinese -- 将评定结果命名为 chinese 列FROMscore; -- 数据来源于 score 表(成绩表)原表:
查询后:
1.5 小结
1.5.1四大函数类别对比总结
| 函数类型 | 核心作用 | 常见函数 | 典型应用场景 |
|---|---|---|---|
| 字符串函数 | 处理文本数据 | CONCAT, UPPER, LOWER, TRIM, SUBSTRING, LPAD/RPAD | 拼接姓名、格式化手机号、去除空格、补零 |
| 数值函数 | 执行数学运算 | CEIL, FLOOR, ROUND, MOD, RAND | 取整、四舍五入、生成随机数、判断奇偶 |
| 日期函数 | 操作时间数据 | CURDATE, CURTIME, NOW, YEAR, MONTH, DAY, DATE_ADD, DATEDIFF | 计算年龄、工龄、倒计时、时间偏移 |
| 流程函数 | 实现条件判断 | IF, IFNULL, CASE WHEN | 数据脱敏、等级划分、空值处理、多分支判断 |
1.5.2要点回顾
- 字符串函数:用于文本处理(拼接、截取、格式化)
- 数值函数:用于数学运算(取整、取模、四舍五入)
- 日期函数:用于时间计算(获取当前时间、加减日期、计算天数)
- 流程函数:用于条件判断(IF、CASE、IFNULL)
这些函数可以单独使用,也可以嵌套组合,实现更复杂的逻辑处理。
2. 约束
- 数据库中的“约束”(Constraint)是作用于表字段上的规则,用于限制存储在表中的数据,确保数据的正确性、有效性和完整性。
- 它是数据库设计中不可或缺的一环,能有效防止非法数据进入系统,提升数据质量与系统稳定性。
2.1 概述
2.1.1 概念
约束 是一种强制性的规则,定义了表中字段的数据必须满足的条件。它在插入、更新或删除数据时自动生效,由数据库管理系统(DBMS)负责检查和执行。
2.1.2 目的
- 保障数据一致性:避免出现逻辑矛盾(如员工属于不存在的部门)
- 提高数据可靠性:防止无效值(如年龄为负数、姓名为空)
- 简化业务逻辑:将校验逻辑交给数据库处理,减少应用层负担
- 支持复杂关系建模:通过外键实现多表关联,构建完整的关系型数据模型
2.1.3 分类
| 约束类型 | 关键字 | 功能说明 |
|---|---|---|
| 非空约束 | NOT NULL | 字段值不能为 NULL |
| 唯一约束 | UNIQUE | 字段值不允许重复(可为空) |
| 主键约束 | PRIMARY KEY | 表的唯一标识符,非空且唯一,常配合 AUTO_INCREMENT 自增 |
| 默认约束 | DEFAULT | 未指定值时使用默认值 |
| 检查约束 | CHECK | 限制字段值满足特定条件(MySQL 8.0.16+ 支持) |
| 外键约束 | FOREIGN KEY | 实现表间关联,维护参照完整性 |
📌 注意:约束可以在创建表(
CREATE TABLE)时添加,也可以在后续修改表结构(ALTER TABLE)时添加。
2.2 案例:用户表设计与约束应用
根据以下需求,创建一个名为
user的用户表,包含字段及其约束要求:
| 字段名 | 含义 | 类型 | 约束条件 | 关键字 |
|---|---|---|---|---|
| id | 用户唯一标识 | INT | 主键,自增 | PRIMARY KEY, AUTO_INCREMENT |
| name | 姓名 | VARCHAR(20) | 不为空,唯一 | NOT NULL, UNIQUE |
| age | 年龄 | INT | >0 且 ≤120 | CHECK |
| status | 状态 | CHAR(1) | 默认为 ‘1’(启用) | DEFAULT |
| gender | 性别 | CHAR(1) | 可为空 | —— |
CREATE TABLE user(-- 主键字段:唯一标识每个用户-- INT 类型,自动递增(AUTO_INCREMENT),确保每条记录都有唯一的 IDid INT PRIMARY KEY AUTO_INCREMENT COMMENT '主键',-- 姓名字段:存储用户的姓名-- NOT NULL 表示该字段不能为空-- UNIQUE 表示姓名必须唯一,不允许重复name VARCHAR(20) NOT NULL UNIQUE COMMENT '姓名',-- 年龄字段:存储用户的年龄-- CHECK 约束确保年龄值在合理范围内:大于 0 且小于等于 120age INT CHECK(age > 0 AND age <= 120) COMMENT '年龄',-- 状态字段:表示用户当前的状态(例如:启用、禁用)-- DEFAULT '1' 表示若插入数据时未指定状态,默认值为 '1'(即启用状态)status CHAR(1) DEFAULT '1' COMMENT '状态',-- 性别字段:存储用户的性别-- 允许为空(没有 NOT NULL 约束),表示性别可选填gender CHAR(1) COMMENT '性别') COMMENT '用户表';-- 插入数据
INSERT INTO user(name, age, status, gender) VALUES ('Tom1',19,1,'男'),('Tom2',25,0,'男');
SELECT * FROM user;
输出结果:
id name age status gender 1 Tom1 19 1 男 2 Tom2 25 0 男
成功实现了多种约束的组合使用,确保了数据的有效性与完整性。
2.3 外键约束
外键(Foreign Key)是用于建立两个表之间关系的关键机制,确保子表的数据引用父表中存在的记录,从而维护参照完整性(Referential Integrity)。
2.3.1 概念
- 父表(主表):被引用的表(如
dept部门表) - 子表(从表):引用其他表的表(如
emp员工表) - 外键列:子表中指向父表主键的字段(如
emp.dept_id引用dept.id)
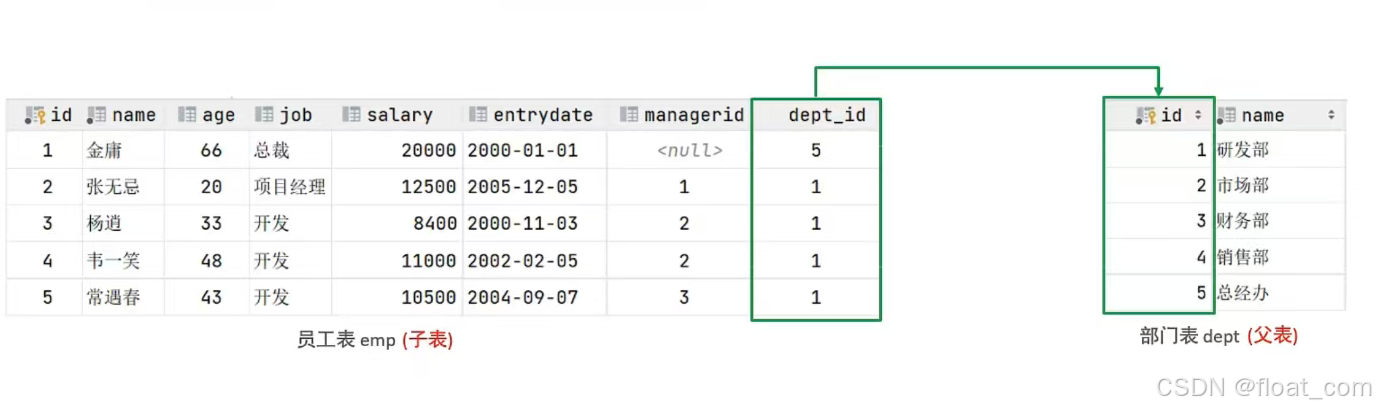
🚫 若没有外键约束,可能产生“孤儿记录”——例如员工属于一个已删除的部门。
2.3.2 语法
外键约束可以在创建表时定义,也可以在已有表上通过 ALTER TABLE 添加。推荐在表结构稳定后,使用 ALTER TABLE 方式添加外键,便于维护与命名规范。
2.3.2.1 添加外键
2.3.2.1.1表创建后添加外键
ALTER TABLE 子表名
ADD CONSTRAINT 外键约束名
FOREIGN KEY (外键字段)
REFERENCES 父表名 (父表主键字段)[ON UPDATE 行为][ON DELETE 行为];
参数说明:
子表名:需要添加外键的表(如emp员工表)外键约束名:自定义的约束名称,建议命名规范如:fk_子表_父表(如fk_emp_dept)外键字段:子表中引用父表主键的字段(如dept_id)父表名:被引用的主表(如dept部门表)父表主键字段:通常是父表的主键(如id)[ON UPDATE ...]和[ON DELETE ...]:可选,用于设置更新/删除时的行为(如CASCADE、SET NULL等)
2.3.2.1.2创建表时直接定义外键
CREATE TABLE 子表名(字段1 数据类型,...[CONSTRAINT] 外键字段 数据类型,FOREIGN KEY (外键字段) REFERENCES 父表名(父表主键字段)[ON UPDATE 行为][ON DELETE 行为]
);
2.3.2.2 示例
完整代码:
-- 为 emp 表添加外键约束,建立与 dept 表的关联
ALTER TABLE emp
-- 添加一个名为 fk_emp_dept_id 的外键约束
ADD CONSTRAINT fk_emp_dept_id
-- 指定该约束为外键,作用于 emp 表的 dept_id 字段
FOREIGN KEY (dept_id)
-- 关联到 dept 表的主键 id 字段
REFERENCES dept(id);
说明:
fk_emp_dept_id是外键约束的名称,用于唯一标识该约束,便于后续维护(如删除或修改)dept_id是emp表中的字段,称为“外键列”,用于存储对dept表的引用
3.REFERENCES dept(id)表示dept_id的值必须在dept表的id字段中存在(即必须是有效的部门ID)- 此约束确保了数据的参照完整性:
- 不能在
emp表中插入一个不存在于dept表中的dept_id- 不能删除
dept表中被emp表引用的部门记录(除非先解除关联)- 这样就建立了“员工属于某个部门”的逻辑关系,保证了数据的一致性和有效性。
2.3.2.2 删除外键
ALTER TABLE 表名
DROP FOREIGN KEY 外键约束名;
参数说明:
表名:包含外键约束的表(通常是子表)外键约束名:要删除的外键约束名称(可通过SHOW CREATE TABLE 表名;查看)
⚠️ 重要提醒:
- 删除外键前请确认是否会影响数据完整性。
- 若需重建外键,建议重新命名并明确设置
ON UPDATE/ON DELETE行为。
2.3.2.3示例
-- 删除 emp 表中名为 fk_emp_dept_id 的外键约束
ALTER TABLE emp
-- 删除指定名称的外键约束
DROP FOREIGN KEY fk_emp_dept_id;
说明:
ALTER TABLE emp:表示要对emp表进行结构修改。DROP FOREIGN KEY fk_emp_dept_id:删除emp表上名为fk_emp_dept_id的外键约束。- 执行此语句后,
emp表的dept_id字段将不再受外键约束限制。
- 可以插入
dept_id不存在于dept表中的值(即失去参照完整性检查)- 可以删除
dept表中的记录,即使emp表中仍有员工属于该部门- 注意:此操作仅删除约束,不会删除
dept_id字段本身的数据或该字段。- 通常在需要修改外键定义、迁移数据或重构表结构时使用此语句。
- 删除外键后,数据库不再强制维护
emp表与dept表之间的关联关系,需谨慎操作以避免数据不一致。
2.3.3 删除 / 更新行为
当父表(dept)中的记录被删除或更新时,子表(emp)如何响应?可通过以下五种行为控制:
| 行为 | 说明 | 是否支持 InnoDB |
|---|---|---|
NO ACTION / RESTRICT | 默认行为,禁止删除/更新有外键引用的记录 | ✅ |
CASCADE | 级联操作:删除/更新父表记录时,自动删除/更新子表中相关记录 | ✅ (重点) |
SET NULL | 置空操作:设置子表外键字段为 NULL(需允许 NULL) | ✅ (重点) |
SET DEFAULT | 将外键设为默认值(InnoDB 不支持) | ❌ |
推荐使用场景:
CASCADE:适用于强依赖关系(如部门解散则员工也清除)SET NULL:适用于弱依赖(如部门合并,员工保留但无归属)RESTRICT:最安全,防止误删关键数据
2.3.4整体示例
2.3.4.1级联操作:
完整代码:
-- 级联操作(CASCADE)
ALTER TABLE emp
ADD CONSTRAINT fk_emp_dept_id
FOREIGN KEY (dept_id) REFERENCES dept(id)ON UPDATE CASCADE -- 当 dept 表中的 id(主键)被更新时,emp 表中对应的 dept_id 自动同步更新ON DELETE CASCADE; -- 当 dept 表中的某条部门记录被删除时,emp 表中所有属于该部门的员工记录也会被自动删除
说明:
- 优点:自动维护数据一致性,避免“孤儿”记录。
- 风险:删除部门时会连带删除该部门所有员工,操作不可逆,需谨慎使用。
- 适用场景:当子表记录完全依赖于父表记录存在时(如部门不存在,员工也应一并清除)。
2.3.4.2置空操作:
完整代码:
--置空操作(SET NULL)
ALTER TABLE emp
ADD CONSTRAINT fk_emp_dept_id
FOREIGN KEY (dept_id) REFERENCES dept(id)ON UPDATE SET NULL -- 当 dept 表中的 id 被更新时,emp 表中对应的 dept_id 被设置为 NULLON DELETE SET NULL; -- 当 dept 表中的某条部门记录被删除时,emp 表中对应的 dept_id 被设置为 NULL
说明:
- 前提:外键字段 dept_id 必须允许为 NULL(即定义时没有 NOT NULL 约束)。
- 效果:删除部门后,员工记录不会被删除,但部门信息变为“未分配”(dept_id = NULL)。
- 优点:避免数据丢失,保留员工历史信息。
- 适用场景:需要保留员工记录,即使其所属部门被撤销或合并。
2.4 总结
约束是数据库设计的“守门员”,它让数据不再随意流动,而是遵循预设规则运行。掌握各类约束的使用方法,是构建高质量、高可靠数据库系统的基石。
2.4.1六大约束一览表
| 约束类型 | 关键字 | 作用 | 示例 |
|---|---|---|---|
| 非空约束 | NOT NULL | 禁止字段为空 | name VARCHAR(20) NOT NULL |
| 唯一约束 | UNIQUE | 确保值唯一 | name VARCHAR(20) UNIQUE |
| 主键约束 | PRIMARY KEY | 唯一标识行 | id INT PRIMARY KEY AUTO_INCREMENT |
| 默认约束 | DEFAULT | 提供默认值 | status CHAR(1) DEFAULT '1' |
| 检查约束 | CHECK | 限制取值范围 | age INT CHECK(age > 0) |
| 外键约束 | FOREIGN KEY | 维护表间关系 | FOREIGN KEY(dept_id) REFERENCES dept(id) |
2.4.2 使用建议
- 合理设计主键:优先选择自增整数作为主键,避免使用业务字段
- 慎用外键:虽然强大,但在高并发写入场景下可能影响性能,需权衡
- 明确约束含义:命名规范(如
fk_emp_dept_id),便于后期维护 - 结合索引使用:外键字段通常会自动创建索引,提升查询效率
- 提前规划约束:在建表初期就考虑好约束逻辑,避免后期频繁修改