深度学习入门(四)——从激活到注意力:神经网络的现代模块与工程实践
在前三篇中,我们已经走完了神经网络的核心理论路径——
从神经元到前向传播,从损失函数到反向传播,从优化算法到数值稳定。
你现在已经可以手写一个两层网络并跑通梯度下降。
但如果要让一个网络真正「跑得快、收敛稳、效果好」,
光有数学推导远远不够。
深度学习的成熟来自工程化——各种模块、正则化手段、数值技巧和结构设计。
这一篇,我们就来系统地梳理神经网络在实际中最重要的几个「现代模块」与「工程问题」,
从直觉到原理,让你能真正理解它们为什么存在、该在什么地方用。
一、激活函数:非线性的本质与选择
1. 为什么需要激活函数?
如果没有激活函数,神经网络每一层都是线性变换。
多个线性层叠加仍然是线性函数。
这意味着无论堆多少层,你都无法逼近非线性关系。
所以,激活函数的核心作用是:引入非线性,使网络能表达复杂映射。
2. Sigmoid 与 Tanh:早期的经典
最早使用的激活函数是 sigmoid:
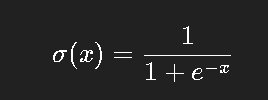
它的输出在 (0, 1) 之间,形状平滑,适合二分类概率建模。
但问题也明显:
在 |x| 很大时,梯度几乎为 0 → 梯度消失
输出非零均值,导致每层输入偏移
Tanh(双曲正切)是 sigmoid 的改进:
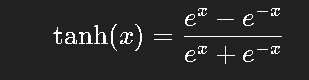
输出范围 (-1, 1),均值居中,效果稍好,但依旧有梯度消失问题。
3. ReLU 的崛起
Rectified Linear Unit(ReLU)是目前最主流的激活函数:
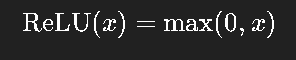
优点:
计算极快(只需取最大值)
正区间梯度恒为 1,避免梯度消失
稀疏激活,部分神经元可自然「休眠」
缺点:
负区间梯度为 0 → 神经元死亡问题
在部分任务上表现不稳(尤其是输入数据分布变化较大时)
4. Leaky ReLU、ELU、GELU:改良版本
为解决 ReLU 的“死亡问题”,出现了 Leaky ReLU:
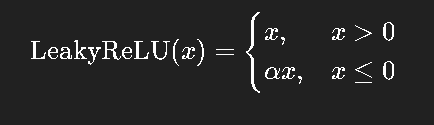
通常取 α = 0.01。
进一步的改良如 ELU、GELU(Transformer中使用):
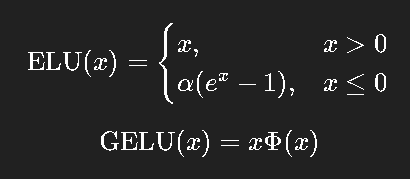
其中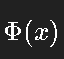 是标准正态分布的累积分布函数。
是标准正态分布的累积分布函数。
GELU 在数学上近似「输入越大越可能被保留」,更平滑自然。
这也是为什么几乎所有 Transformer 模型都采用 GELU。
5. 实战建议
| 场景 | 建议激活函数 |
|---|---|
| 普通全连接层 | ReLU 或 Leaky ReLU |
| RNN/LSTM | Tanh / Sigmoid |
| Transformer / BERT 类模型 | GELU |
| 稀疏特征或非负输入 | ReLU |
| 对梯度平滑性敏感任务 | ELU 或 Swish |
一句话总结:默认用 ReLU,不够平滑用 GELU。
二、Batch Normalization:让训练更稳
1. 为什么需要 BN?
在训练深层网络时,随着层数加深,输入分布不断变化,
导致后续层的学习变得困难。
这种现象叫做 Internal Covariate Shift。
Batch Normalization 的想法非常简单:
在每一层中,把中间激活值标准化成均值 0、方差 1,再引入可学习的缩放与偏移。
2. 公式
对每个 mini-batch:
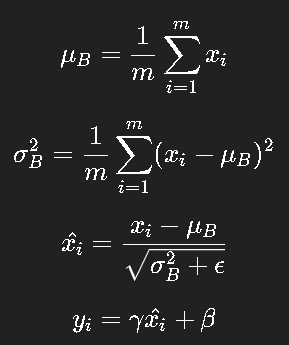
其中 γ、β 是可学习参数。
3. BN 的好处
缓解梯度消失与爆炸问题
提高学习率容忍度
加快收敛速度
起到一定正则化作用
4. 实践注意点
推理阶段使用移动平均的均值与方差
对小 batch(如小于 8)时 BN 不稳定 → 可用 LayerNorm 替代
在 Transformer 中,LayerNorm 更常见,因为它对 batch size 不敏感
三、Dropout:一种简单而强大的正则化
1. 过拟合的本质
神经网络参数众多,训练集很容易被「记住」。
当模型过于依赖少数神经元时,泛化能力就会下降。
2. Dropout 的思想
在训练时,随机将一部分神经元“丢弃”(置为0):
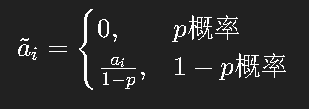
这样网络在每次训练时都像在「抽样多个子网络」,
从而避免单一神经元过度依赖。
3. 实现与注意
伪代码:
for each layer l:mask = random_matrix(shape=a[l], keep_prob=p)a[l] = a[l] * mask / p
推理阶段:
a[l] = a[l] # 不做丢弃
实战经验:
对小模型:p=0.1~0.3
对大模型:p=0.3~0.5
在 BN 之后使用效果更稳定
四、卷积与注意力:特征提取的两种路径
1. 卷积:空间局部性的表达
卷积神经网络(CNN)是图像任务的基石。
其核心思想是局部感受野与权值共享。
以二维卷积为例:
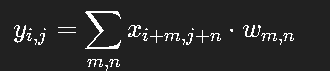
这样,卷积核(filter)可以自动学习空间局部模式,如边缘、角点、纹理等。
随着层数加深,卷积层学到的特征也从「低级」变成「高级」。
2. 卷积的演化:从 LeNet 到 ResNet
LeNet(1998):首个 CNN,用于手写数字识别
AlexNet(2012):GPU+ReLU+Dropout,引爆深度学习浪潮
VGG(2014):统一 3×3 卷积结构,层数更深
ResNet(2015):引入残差连接(skip connection)
残差结构核心思想:
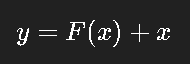
允许梯度直接跨层传播,从根本上解决了深层网络训练难的问题。
3. 注意力机制:打破空间固定性的限制
卷积的局部性是一把双刃剑。
它高效,但只能捕捉邻近区域关系。
对于全局依赖任务(如语言理解),这种结构不够灵活。
注意力机制(Attention) 由此诞生。
核心思想:
让每个位置都能“关注”输入序列中其他位置的重要性。
公式:

其中:
Q: Query(当前元素的查询向量)
K: Key(全体元素的键向量)
V: Value(全体元素的值向量)
每个输出是所有输入的加权平均,权重由相似度决定。
这让模型具备「全局依赖建模能力」。
4. 从注意力到 Transformer
Transformer(2017)用纯注意力结构取代了循环与卷积,
实现了并行、高效、强表达的特性。
核心结构:
Multi-Head Attention(多头注意力)
Position-wise Feed Forward(逐位置全连接)
Layer Normalization
残差连接
伪代码概要:
for each layer:x = x + MultiHeadAttention(LayerNorm(x))x = x + FeedForward(LayerNorm(x))
五、训练调试与部署注意事项
1. 学习率选择
初学者常见错误:学习率过大或过小。
建议:从 1e-3 起,观察损失曲线振荡程度调整。
现代方法:使用 Cosine Annealing 或 Warmup 策略。
2. 初始化策略
Xavier(均匀分布):适合 tanh
He 初始化:适合 ReLU 系列
过大 → 梯度爆炸;过小 → 梯度消失
3. 正则化
L2 权重衰减(weight decay)
Dropout
数据增强(augmentation)
4. Debug 技巧
先跑一个小 batch,确保前向输出与损失正常
梯度检查(gradient check):验证反向传播是否正确
梯度可视化:查看是否消失或爆炸
学习曲线:训练集与验证集误差是否同步下降
5. 部署阶段注意
BN 改为固定统计量
Dropout 关闭
使用混合精度(float16)加速
对模型进行量化 / 蒸馏以减小体积
六、总结:深度学习的工程之美
回到最初的问题——为什么深度学习能起飞?
不仅因为有数学推导,更因为工程化体系成熟:
ReLU 让梯度流动顺畅
BatchNorm 让训练稳定
Dropout 让模型泛化
Residual 与 Attention 让信息传递高效
优化算法让训练变得可控
从「感知机」到「Transformer」,
深度学习走过了从经验到体系的漫长过程。
每个改进都不是偶然,而是对真实工程问题的回应。
尾声 · 写给正在学习的你
如果你一路读到了这里,请给自己一点肯定。
你已经掌握了神经网络的全流程原理——
从数学出发,理解算法,再到工程实现。
接下来你可以:
自己实现一个 mini 框架(从前向到反向)
尝试在 MNIST / CIFAR10 跑出结果
阅读经典论文(LeNet、ResNet、Transformer)
学习自动求导与模型部署
记住一句话:
理论让你理解模型,工程让你驯服模型。