机器学习17:如何有效使用自监督式学习
摘要
本周课程系统回顾了预训练语言模型(PLMs)的基本原理及其在自然语言处理任务中的应用,重点分析了当前PLMs面临的两大核心挑战:下游任务中标注数据的匮乏以及模型规模过大带来的计算与存储负担。课程详细介绍了一系列针对这些问题的优化方法,包括提示微调(Prompt Tuning)、少样本/零样本学习、半监督学习、参数高效性微调(如适配器、LoRA、前缀微调、软提示)以及提前退出机制等。这些方法从不同角度提升了模型在数据稀缺情况下的适应能力,并显著降低了微调过程中的参数量和计算开销,为在实际资源受限场景中高效部署大规模预训练模型提供了可行的技术路径。
Abstract
This week's lesson systematically reviews the basic principles of Pre-trained Language Models (PLMs) and their applications in natural language processing tasks, with a focus on two core challenges: the scarcity of annotated data in downstream tasks and the computational and storage burdens caused by increasingly large model sizes. The course details a range of optimization techniques to address these issues, including Prompt Tuning, Few-shot/Zero-shot Learning, Semi-supervised Learning, Parameter-Efficient Fine-tuning methods (such as Adapters, LoRA, Prefix Tuning, and Soft Prompting), and Early Exit mechanisms. These approaches enhance the model's adaptability under data-scarce conditions from different perspectives and significantly reduce the number of parameters and computational overhead during fine-tuning, offering practical technical pathways for efficiently deploying large-scale pre-trained models in real-world resource-constrained scenarios.
一.知识回顾
预训练语言模型(Pre-trained Language Models,PLMs)
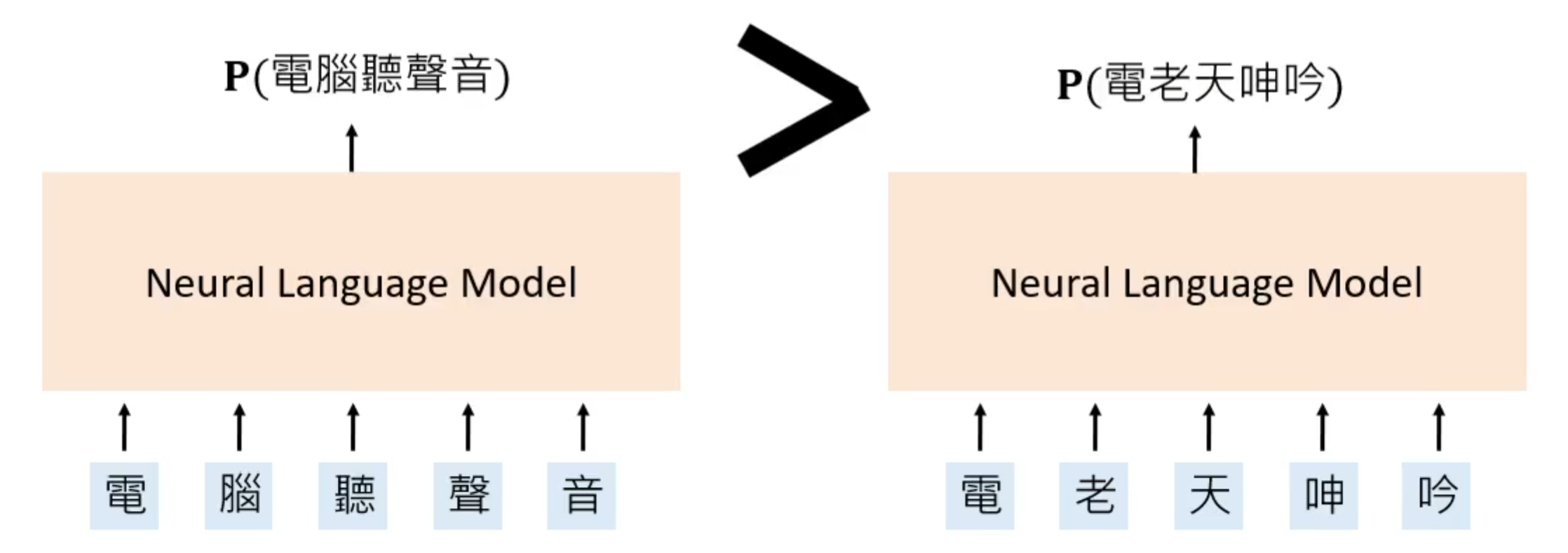
所谓自然语言模型就是一个神经网络,这个网络就是确定一个句子出现的概率大小,如“电脑听声音”和“电老天呻吟”,前者明显出现的概率要大一些。同理将这个两个句子分别输入到自然语言模型中得到的概率前者也自然要比后者大的多。
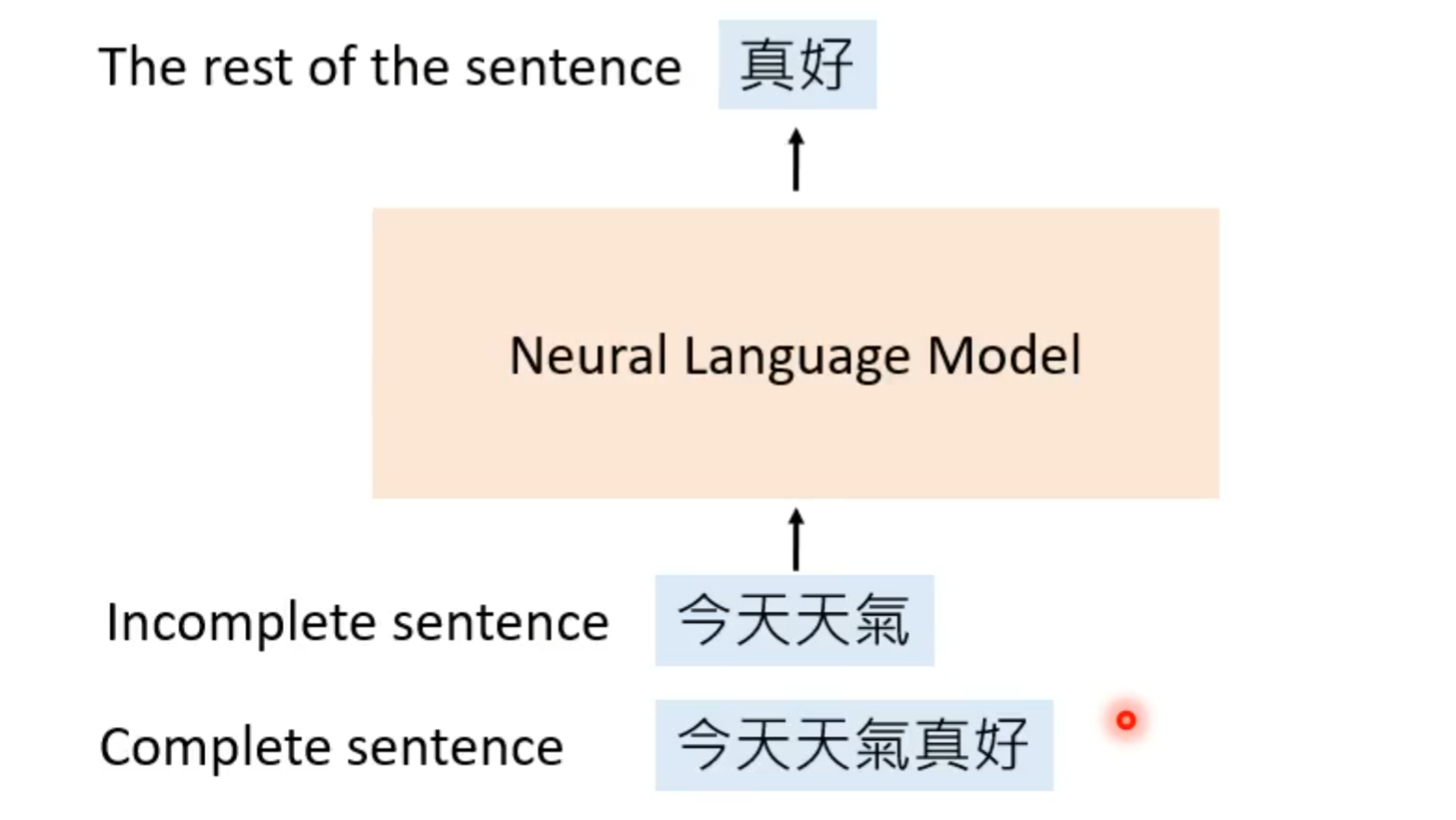
这样的模型的训练就是通过不完整的句子,让其去预测剩下的句子,就如下将“今天天气真好”中后两个字去掉,然后将这个不完整的句子输入到自然语言模型中,让其预测句子后面需要加上的字。
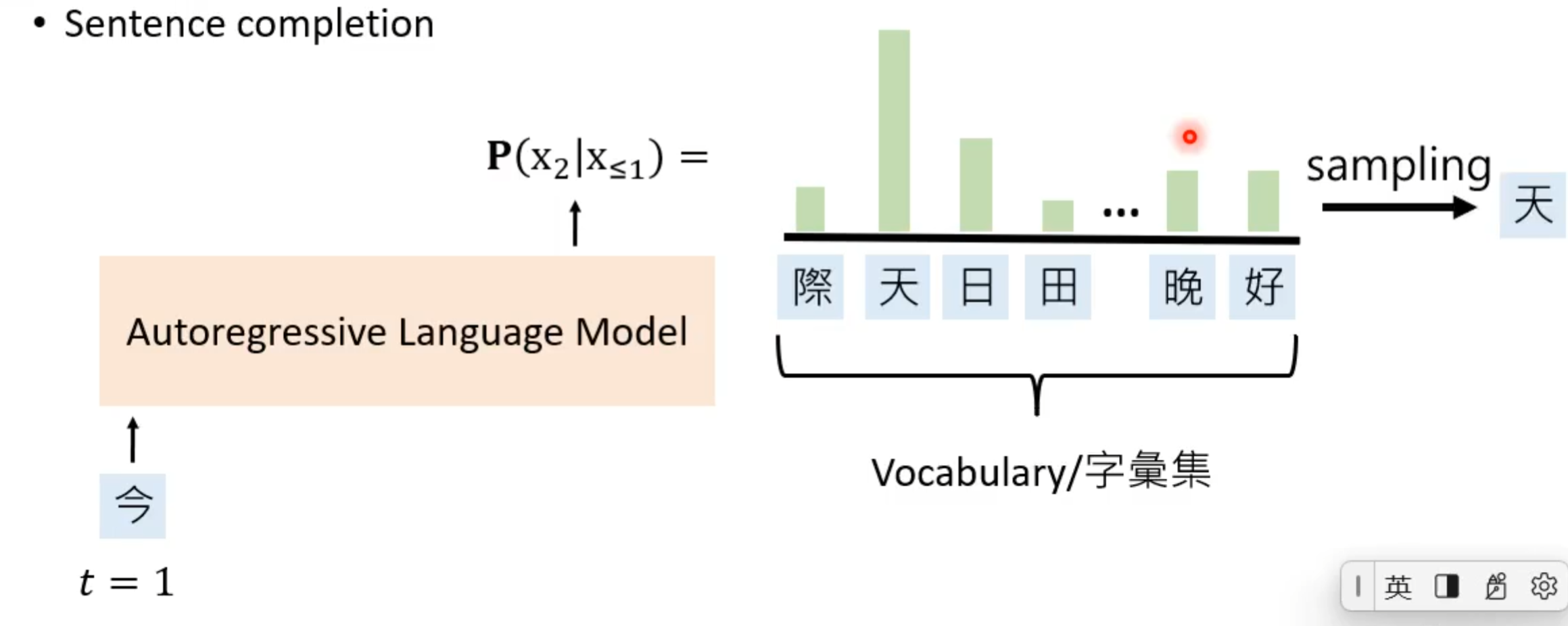
对于构造不完整的句子是有很多方式。根据构造方式可以将语言模型大概分为两种:
① 自回归语言模型(Autoregressive Language Model),其实通过给出的前半段的句子去补上后半段的句子。就如去预测“今天天气真好”,当输入第一个“今”,其就要通过这个字去预测下一个字,这个预测就是通过第一个字后模型得到第二个字的概率分布,这个概率分布是在字符集上的一个离散分布,然后再在这个分布中抽取一个字。
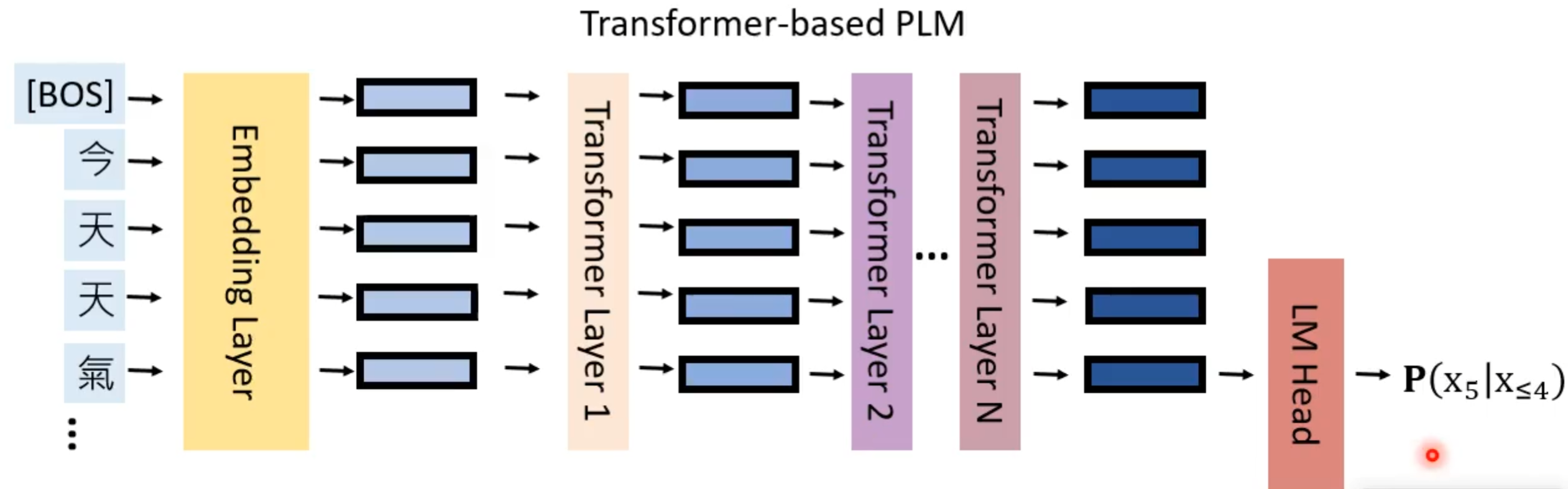
接着就得到第二个字,然后将第二个字输入到模型中开始同理预测下一个。因为后面在字符集中抽取一个字是随机的,所以也是可能抽到概率小的。
那这个模型的架构是基于Transformer,并由Transformer堆叠形成的。所以这个模型是先输入一个句子,这个句子中有许多token,包括特殊的BOS表示开始。这些token就经过嵌入层转换成对应一个一个向量,然后将这些向量输入到一层又一层的transformer中,知道最后一层就会抽出最后的embeddings,若想预测下一个字就需要将最后一个embedding,输入到语言模型输出层(language model head),得到下一个字的概率分布,这个其实也是一种自注意机制。
②掩码语言模型(Masked Language Models)
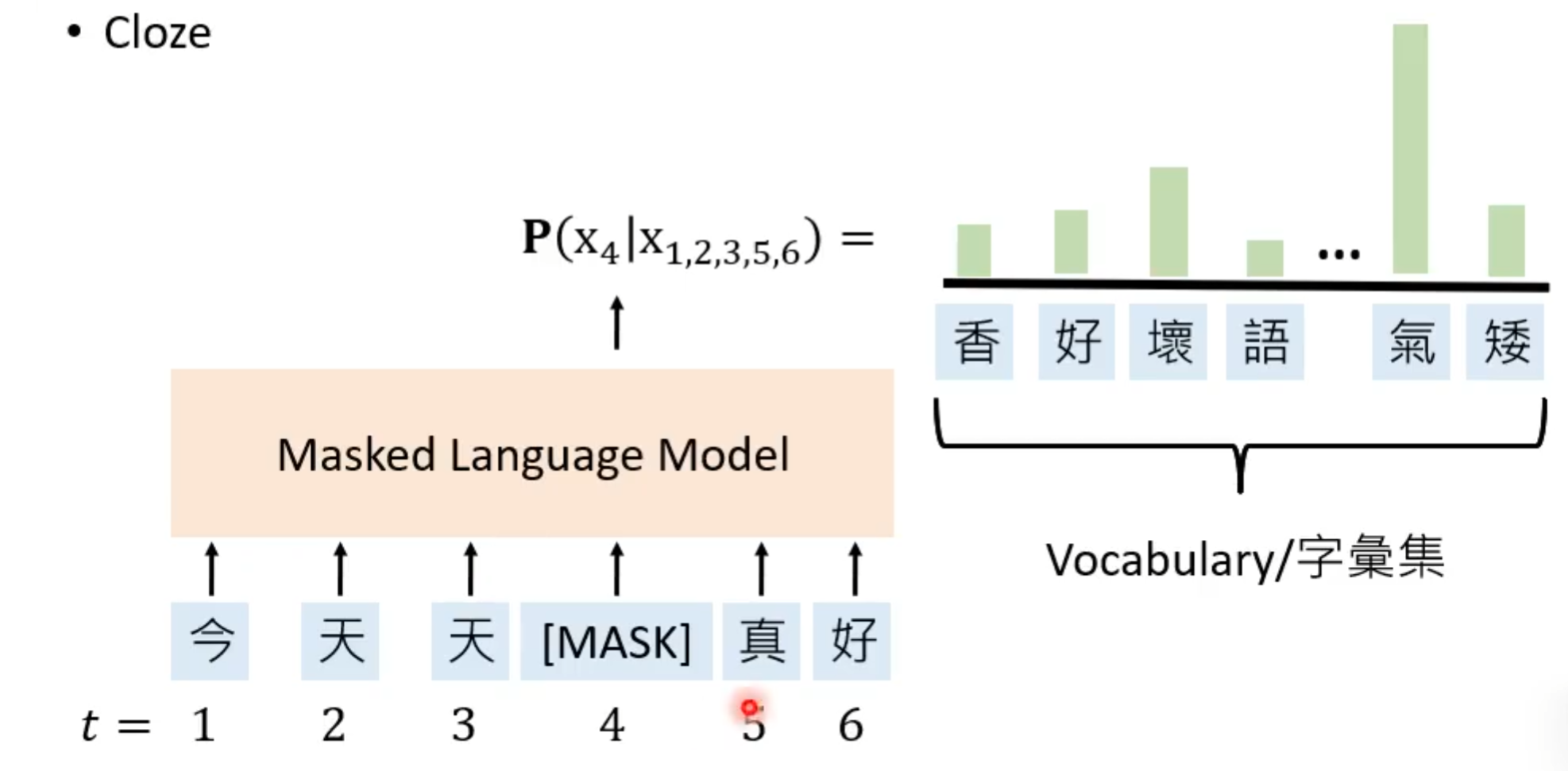
也就是前所学的,遮蔽句中的一个token,让这个模型完成“填空”。
那这些预训练语言模型的好处在于当我们将一个句子输入到预训练语言模型中,这个模型中就会有许多隐藏表示(Hidden Representation),所以当利用这个模型以及返回出来的隐藏表示在训练任务上时,可以得到很好的训练结果。