计算机视觉——从YOLO系列演进到YOLOv12架构创新、注意力机制优化、推理实践与性能基准
1. 引言与YOLO系列发展脉络
YOLO(You Only Look Once)系列作为实时目标检测领域的标杆,始终致力于平衡检测速度与精度。从YOLOv8到YOLOv11,每一代模型均通过架构优化实现性能突破,而YOLOv12更是首次将注意力机制引入核心设计,在保持实时性的同时突破传统CNN架构的局限。本章将首先梳理YOLO系列的关键演进,为理解YOLOv12的创新奠定基础。
1.1 YOLOv8至YOLOv11的核心改进
- YOLOv8:引入C2f(卷积到融合)模块,通过“特征图拆分-瓶颈层处理-融合”的流程,在不增加计算复杂度的前提下增强多尺度特征学习能力并扩大感受野;8.1版本新增定向边界框(OBB)支持,可高效检测旋转物体,适用于航空影像、文档分析等场景。
- YOLOv9:基于YOLOv8架构提出两项核心技术:
- 可编程梯度信息(PGI):确保网络输入信息完整性与梯度流可靠性,提升训练效率;
- 广义高效层聚合网络(GELAN):优化参数利用率与计算效率,使轻量级模型也能实现高检测精度。
基于Ultralytics实现的YOLOv9u变体同样支持OBB功能。
- YOLOv10:针对非极大值抑制(NMS)的局限性优化:
- 一致性双重分配策略:训练阶段结合一对一与一对多标签分配,无需NMS即可降低推理延迟;
- 效率-精度驱动设计:全面优化模型组件,在提升性能的同时最小化计算开销。
社区讨论显示,部分YOLOv10分支版本已实现OBB支持(官方文档未明确记载)。
- YOLOv11:作为纯CNN架构的收官版本,聚焦速度与效率:
- 采用C3K2模块:以更小卷积核替代原有模块,用更少参数实现更优特征表征;
- 引入深度可分离卷积:在保持精度的同时显著降低计算负荷;
正式集成OBB检测功能,并提供基于DOTAv1等数据集训练的预训练模型(如yolo11n-obb.pt)。
1.2 YOLOv8至YOLOv11的共同局限
尽管上述模型性能持续提升,但均存在两项关键局限:
- 核心架构依赖CNN:未集成注意力机制,难以有效捕捉全局上下文信息;
- 全局特征捕捉能力不足:在复杂场景(如目标遮挡、多尺度混合)中,检测精度受限于CNN的局部感受野特性。
这些局限为YOLOv12的创新提供了方向——通过引入注意力机制突破CNN瓶颈,同时保持实时检测性能。
2. YOLOv12的核心创新:注意力机制与架构优化
YOLOv12的核心突破在于解决了注意力机制在实时检测中的效率难题。传统自注意力机制因二次方复杂度与低效内存访问,难以满足YOLO系列的实时性要求(田等人,2025)。本节将详细解析YOLOv12为适配注意力机制所提出的三大核心创新:区域注意力(A²)、残差高效层聚合网络(R-ELAN)与FlashAttention优化。
2.1 区域注意力(A²):降低注意力机制复杂度
传统自注意力机制的二次方复杂度(随输入尺寸呈n²增长)是其应用于实时检测的主要障碍。YOLOv12提出区域注意力(A²) 机制,通过局部化注意力计算平衡感受野与效率:
2.1.1 区域注意力的核心原理
- 特征图分割:将输入特征图沿水平或垂直方向分割为等尺寸区块(默认4个区块);
- 局部注意力计算:在每个区块内独立执行注意力运算,而非全局计算;
- 优势:在保持大感受野(确保目标检测所需的全局关联捕捉)的同时,将计算复杂度降低50%,满足实时性要求(田等人,2025,Section 3.2)。
2.1.2 区域注意力与传统局部注意力的对比
下图展示了区域注意力与其他代表性局部注意力机制的差异,可见其在感受野覆盖与计算效率上的优势:

图1: 代表性局部注意力机制与区域注意力的比较
2.2 R-ELAN模块:适配注意力架构的特征聚合设计
ELAN(高效层聚合网络)作为YOLOv7以来的经典特征聚合模块,在CNN架构中表现优异,但直接迁移至注意力架构时存在梯度流薄弱、模型不稳定等问题。YOLOv12提出R-ELAN(残差高效层聚合网络) 模块,通过残差连接与简化聚合机制解决上述问题。
2.2.1 ELAN在注意力架构中的局限
- 缺乏残差连接:深层堆叠时梯度流衰减,导致模型收敛困难;
- 模型稳定性差:L/X尺度模型(大参数规模)即使使用Adam/AdamW优化器,仍易出现训练震荡;
- 计算开销大:多次特征分割与过渡层操作增加内存与计算负担(田等人,2025,Section 3.3)。
2.2.2 R-ELAN的核心改进
- 带缩放因子的残差连接:在模块输入与输出间添加捷径连接,引入小尺度缩放因子(默认0.01),增强梯度传播,尤其提升深度注意力网络的收敛性;
- 简化聚合机制:
- 仅使用1个转换层标准化输入通道;
- 经注意力/卷积模块处理后,仅执行1次特征拼接操作;
- 优势:在保留特征整合能力的同时,降低内存占用与计算成本。
2.2.3 R-ELAN与主流模块的架构对比
下图展示了R-ELAN与CSPNet、ELAN、C3K2(GELAN实例)的结构差异,凸显其简化设计与残差连接的优势:
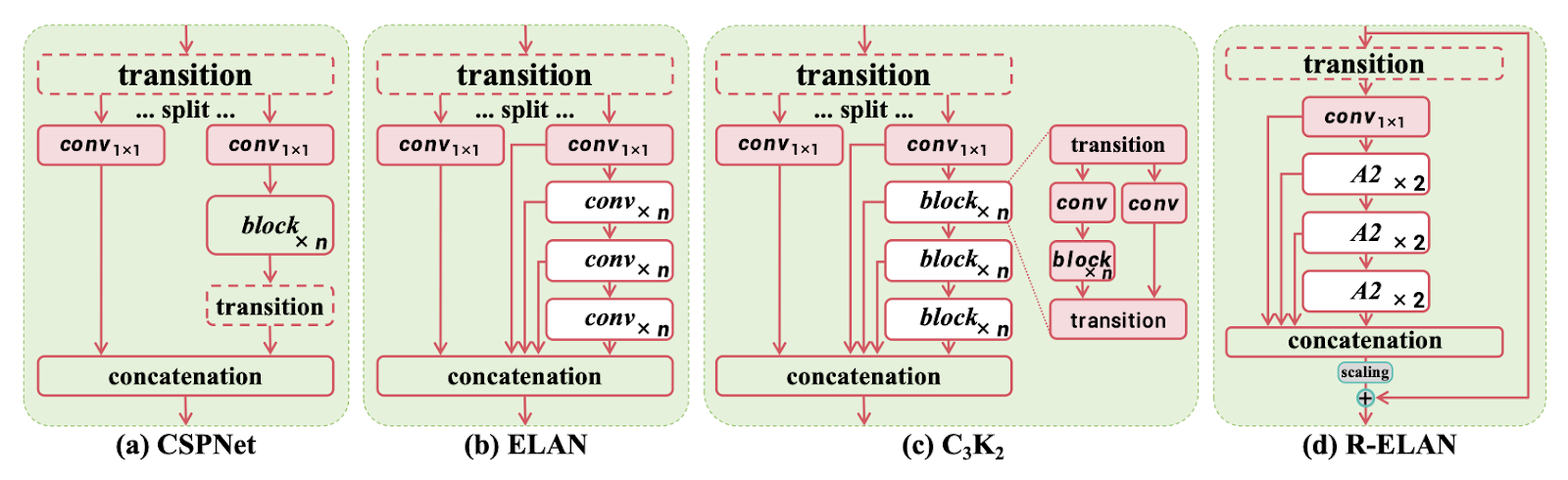
图2: 主流模块架构对比
包括(a)CSPNet、(b)ELAN、©C3K2(GELAN的实例)和(d)提出的R-ELAN(残差高效层聚合网络)
2.3 FlashAttention:优化注意力机制的内存访问
即使采用区域注意力与R-ELAN,内存访问效率仍是注意力机制的关键瓶颈。YOLOv12引入FlashAttention——一种内核级内存优化技术,通过重构GPU缓存与主内存的数据交互方式,减少数据传输延迟。
2.3.1 FlashAttention的优化原理
- 避免重复数据传输:传统注意力计算中,注意力图需频繁在GPU缓存与主内存间往返;FlashAttention通过定制内核设计,将数据暂存于GPU高速缓存,减少传输次数;
- 性能提升效果:田等人(2025,Section 4.5)实验表明,启用FlashAttention后:
- YOLOv12-N每张图像推理速度提升0.3毫秒;
- YOLOv12-S每张图像推理速度提升0.4毫秒;
为YOLOv12的实时推理提供关键支撑。
2.4 其他架构细节优化
YOLOv12在注意力机制之外,还对架构细节进行系统性调整,以平衡性能与效率:
- MLP比率调整:传统Transformer的前馈网络隐藏维度比例为4:1,YOLOv12将其降至1.2或2.0,将计算资源向注意力层倾斜;
- 卷积+批归一化替代线性层+层归一化:相较于视觉Transformer常用的“全连接层+层归一化”,该组合提升GPU利用率与检测精度;
- 取消位置编码:通过7×7可分离卷积(“位置感知器”)注入空间信息,替代传统Transformer的位置编码,降低模型复杂度;
- 保留层级化设计:延续YOLO系列的多阶段特征处理结构,确保模型能同时检测大小目标。
下表汇总了YOLOv12的核心设计创新及其解决的瓶颈问题:
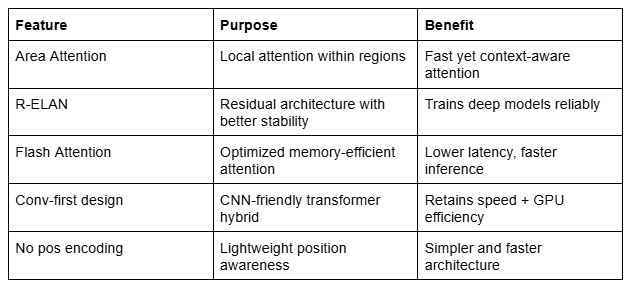
表1: YOLOv12设计创新
详细列示区域注意力、闪存注意力及R-ELAN等关键特性,这些特性解决了Transformer-CNN混合架构中的瓶颈,提升了速度、稳定性和效率。
3. YOLOv12支持的任务与硬件兼容性
YOLOv12延续了YOLO系列的多任务支持能力,可处理目标检测、实例分割等多种计算机视觉任务,同时对硬件存在特定要求(尤其针对FlashAttention优化)。本节将明确其任务范围与硬件兼容性限制。
3.1 支持的核心任务
YOLOv12支持与前代YOLO模型(如YOLOv8、YOLOv11)一致的任务类型,包括:
- 目标检测:定位并识别图像中的物体类别;
- 实例分割:对单个物体进行像素级分割;
- 图像分类:为整张图像分配类别标签;
- 姿态/关键点估计:检测人体或物体的关键兴趣点,估算姿态;
- 定向目标检测:检测带方向角的目标(如旋转边界框);
- 多目标跟踪:结合检测、分割或姿态模型,实现跨帧目标跟踪。
下图展示了YOLO系列(以YOLOv11为例)的任务支持范围,YOLOv12在此基础上保持完全兼容:
图3: YOLO11支持的任务
3.2 硬件兼容性限制
YOLOv12的速度优势高度依赖FlashAttention优化,而该技术仅支持特定GPU架构:
- 兼容GPU:NVIDIA T4、RTX 20/30/40系列、A系列(A5000、A6000、A100)、H100(Hopper架构);
- 不兼容硬件:旧款GPU(如GTX 1080)、低端移动GPU;
- 降级机制:在不兼容硬件上,YOLOv12将回退到标准注意力内核,推理速度大幅下降(但仍可正常运行)。
4. YOLOv12推理环境搭建与实践
本节提供两种YOLOv12推理环境的搭建方案:官方GitHub仓库(支持FlashAttention)与Ultralytics库(安装简便,兼容旧硬件),并详细说明推理流程与常见问题解决方法。
4.1 环境搭建方案1:官方GitHub仓库(支持FlashAttention)
该方案适用于拥有现代GPU(支持FlashAttention)的用户,可充分发挥YOLOv12的性能潜力。
4.1.1 步骤1:克隆仓库并切换分支
# 克隆官方YOLOv12仓库
git clone https://github.com/sunsmarterjie/yolov12.git
cd yolov12# 切换至支持FlashAttention的v1.0分支
git checkout v1.0
4.1.2 步骤2:创建并激活conda环境
# 创建Python 3.11环境
conda create -n yolov12 python=3.11
conda activate yolov12
4.1.3 步骤3:安装依赖与FlashAttention
# 手动下载FlashAttention的whl文件(适配Python 3.11、CUDA 11)
wget https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.3/flash_attn-2.7.3+cu11torch2.2cxx11abiFALSE-cp311-cp311-linux_x86_64.whl# 安装requirements.txt中的依赖
pip install -r requirements.txt# 以可编辑模式安装YOLOv12(便于代码修改与测试)
pip install -e .
4.1.4 步骤4:运行推理
4.1.4.1 方式1:Gradio可视化界面
# 启动Gradio应用
python app.py
运行后将输出本地/公共URL(如http://127.0.0.1:7860),通过浏览器访问即可上传图像并查看检测结果。
4.1.4.2 方式2:Python代码直接推理
from ultralytics import YOLO
import cv2
import matplotlib.pyplot as plt# 加载YOLOv12模型(确保模型路径正确)
model = YOLO("yolov12s.pt")# 执行推理(输入可为图像URL或本地路径)
results = model.predict(source="https://ultralytics.com/images/bus.jpg", # 输入源device="cuda:0", # 使用第1块GPUimgsz=320, # 输入图像尺寸conf=0.5 # 置信度阈值
)# 可视化结果
result_image = results[0].plot() # 生成带检测框的图像
result_image_bgr = cv2.cvtColor(result_image, cv2.COLOR_RGB2BGR) # 转换为OpenCV兼容格式# 保存结果
cv2.imwrite("output.jpg", result_image_bgr)# 可选:显示结果
plt.imshow(result_image)
plt.axis('off')
plt.show()
4.1.4.3 方式3:CLI命令行推理
# 通过YOLO CLI运行推理
yolo detect predict model=yolov12s.pt source=path_to_image.jpg
4.1.5 常见问题解决
- 服务器运行时的TypeError:若在服务器环境中遇到
TypeError: argument of type 'bool' is not iterable,需在app.py中设置share=True:if __name__ == '__main__':gradio_app.launch(share=True) # 启用公共链接 - Gradio版本兼容问题:若上述方法无效,升级Gradio与Gradio Client至最新版本:
pip install --upgrade gradio gradio-client
4.2 环境搭建方案2:Ultralytics库(兼容旧硬件)
该方案安装简便,默认不支持FlashAttention,但适用于无现代GPU的用户,仍能提供稳定性能。
4.2.1 步骤1:安装Ultralytics库
pip install ultralytics
4.2.2 步骤2:Python代码推理
from ultralytics import YOLO
import matplotlib.pyplot as plt# 加载YOLOv12模型
model = YOLO("yolov12s.pt")# 执行推理
results = model.predict(source="https://ultralytics.com/images/bus.jpg",device="cuda:0", # 无GPU时可改为device="cpu"imgsz=320,conf=0.5
)# 保存并显示结果
result_image = results[0].plot()
plt.imsave("output.png", result_image)# 可选:显示图像
plt.imshow(result_image)
plt.axis('off')
plt.show()
4.2.3 关键注意事项
- 避免目录冲突:使用Ultralytics库时,需确保不在官方YOLOv12仓库目录内运行代码(否则会导入作者自定义的Ultralytics版本,可能引发兼容性问题);
- 性能差异:未启用FlashAttention时,YOLOv12-S在A100 GPU上的推理时间约为12-13毫秒,略高于启用FlashAttention的10毫秒,但仍接近YOLOv11-S(7.8毫秒)的速度水平。
4.3 推理结果示例
下图展示了YOLOv12在真实街道场景中的检测结果,模型成功识别多个人体与公交车,并标注置信度分数,体现其对复杂场景的适应能力:

图4: YOLOv12在真实街道场景中的预测结果
模型检测到多个人和一辆公交车并显示置信度分数,展示了其有效处理拥挤高分辨率输入的能力。
下图为Gradio演示界面的示例,左侧为输入图像,右侧为带检测框与置信度的输出结果,支持置信度阈值调整与模型选择:
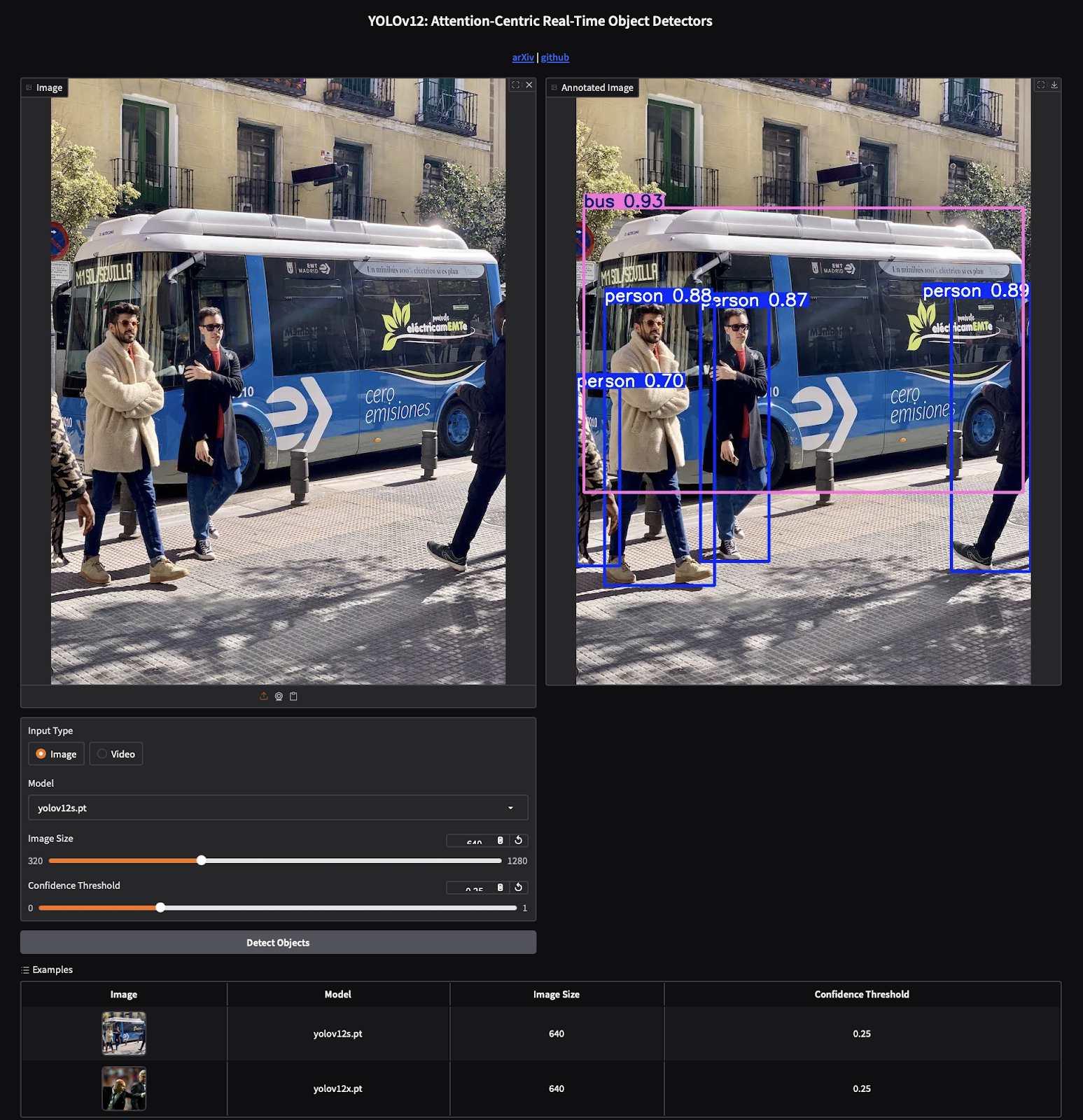
图5: YOLOv12 Gradio演示界面
使用yolov12x.pt模型对输入图像执行实时目标检测。标注后的输出(右侧)显示了针对行人和巴士的高置信度精准预测,突显了YOLOv12以注意力为核心的架构及其与Gradio平台的无缝集成,实现交互式可视化。
5. YOLOv12性能基准与对比分析
本节通过关键指标(平均精度均值mAP、延迟、参数量)评估YOLOv12的性能,并与前代YOLO模型(YOLOv10、YOLOv11)及RT-DETR进行对比,明确其在速度-精度权衡中的定位。
5.1 YOLOv12各规模模型的性能指标
YOLOv12提供从纳米(N)到超大型(X)的5种规模模型,适配不同硬件与精度需求,具体指标如下表所示:
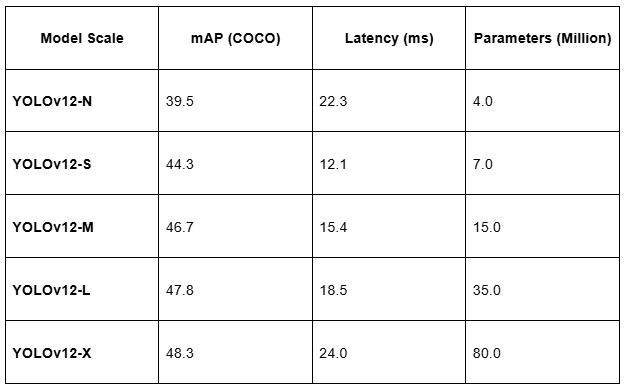
表2: 各规模模型的mAP、延迟时间与参数数量(N/S/M/L/X)
- mAP(平均精度均值):衡量模型在所有类别上的平均检测精度,值越高表示精度越好;
- 延迟:每张图像的推理时间(单位:毫秒),值越低表示速度越快;
- 参数量:模型参数总数(单位:百万),反映模型复杂度与计算需求。
5.2 速度-精度权衡分析
下图展示了YOLOv12各规模模型的延迟-精度与FLOPs-精度权衡关系,直观体现模型规模与性能的取舍:
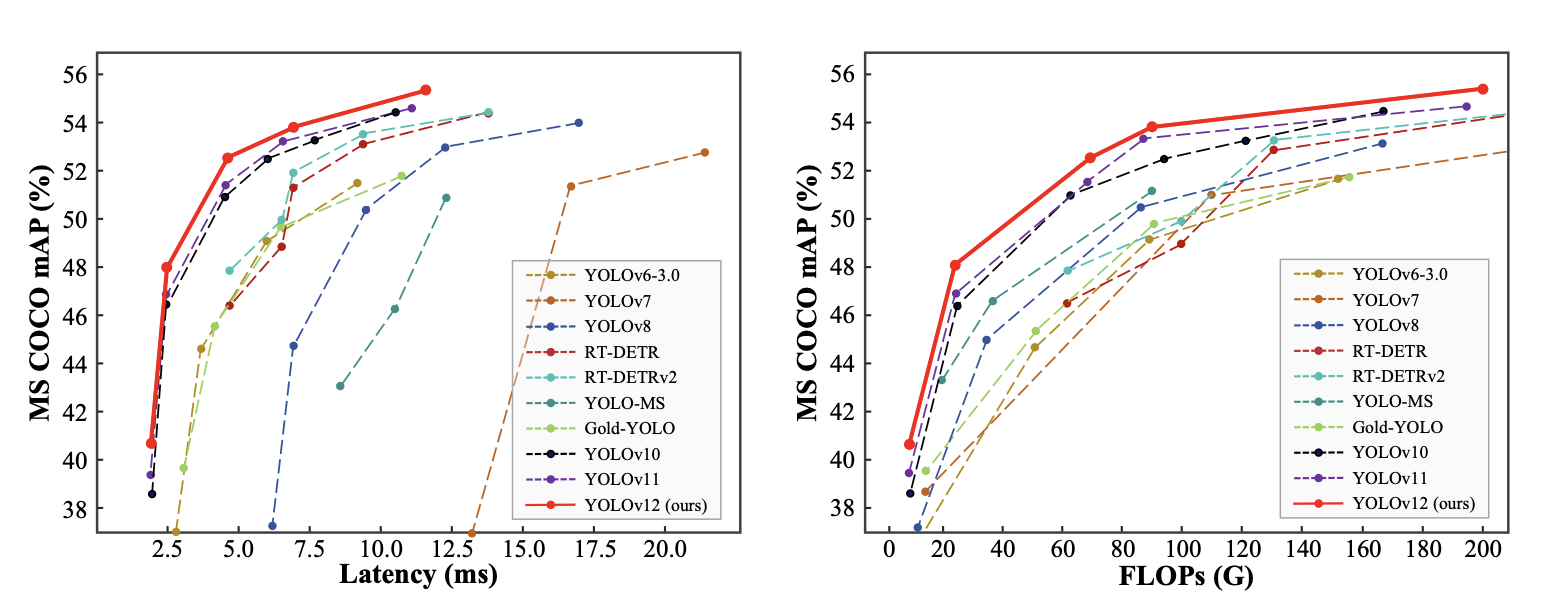
图6: 延迟-准确率(左)与FLOPs(每秒浮点运算次数)-准确率(右)权衡对比
关键结论:
- 小模型(YOLOv12-N/S):延迟低(适合实时场景),但mAP略低;
- 大模型(YOLOv12-L/X):mAP显著提升,但延迟与参数量大幅增加(适合对精度要求高的场景);
- FlashAttention的影响:启用后,各规模模型的延迟均降低约0.3-0.4毫秒,缩小了与纯CNN模型(如YOLOv11)的速度差距。
5.3 与前代模型的性能对比
以YOLOv11-S(纯CNN架构)为基准,YOLOv12-S的性能对比如下:
- 精度:YOLOv12-S的mAP高于YOLOv11-S(得益于注意力机制的全局特征捕捉能力);
- 速度:未启用FlashAttention时,YOLOv12-S延迟(12-13毫秒)略高于YOLOv11-S(7.8毫秒);启用FlashAttention后,延迟降至10毫秒,与YOLOv11-S差距显著缩小;
- 综合优势:YOLOv12在保持接近YOLOv11速度的同时,实现更高检测精度,尤其在复杂场景中表现更优。
6. 总结与展望
YOLOv12作为YOLO系列首个以注意力为核心的架构,通过区域注意力、R-ELAN与FlashAttention三大创新,突破了传统CNN的局限,实现了“注意力机制+实时检测”的融合。其核心贡献包括:
- 效率突破:区域注意力与FlashAttention将注意力机制的复杂度与内存开销降至实时检测可接受范围;
- 架构适配:R-ELAN模块解决了注意力架构的梯度流与稳定性问题;
- 性能平衡:在保持YOLO系列实时性优势的同时,通过注意力机制提升复杂场景的检测精度。
未来,YOLOv12的优化方向可能包括:
- 更广泛的硬件适配:扩展FlashAttention对中低端GPU的支持;
- 多任务注意力优化:针对分割、姿态估计等任务定制注意力机制;
- 动态注意力调整:根据输入场景自适应调整注意力区域大小,进一步平衡速度与精度。