FastGPT入门实战
概述
官网,官方文档,开源(GitHub,26K Star,6.7K Fork)。企业级AI Agent构建平台,可视化Workflow编排+超易用AI知识库+创新RAG检索+模板生态=轻松构建强大AI应用。
安装
通过Docker Compose安装,很简单:
git clone https://github.com/labring/FastGPT.git
cd FastGPT/deploy/docker
cp docker-compose-milvus.yml docker-compose.yml
docker compose up -d
FastGPT提供三种存储方式:
- Milvus:本地部署,适合亿级以上的索引量;
- PgVector:适合千万级别知识库索引量;
- zilliz:使用zilliz云服务。
这里使用milvus,复制配置文件:

docker compose up -d执行报错:

查看本地目录以及git status .:
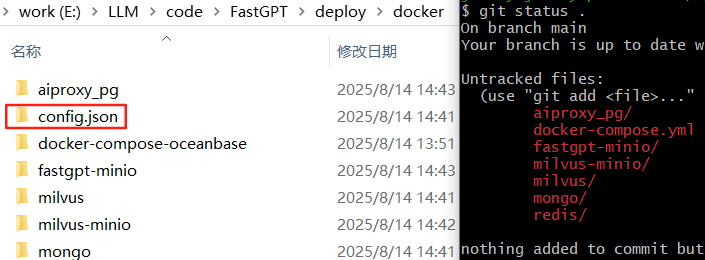
GitHub代码库,并没有该目录:
莫名其妙,config.json文件夹从哪里冒出来的???
解决方法:删除该文件夹,从projects\app\data目录复制该文件:
cp ../../projects/app/data/config.json config.json,然后重试docker compose up -d。
登录
浏览器打开http://localhost:3000,页面并没有刷新出来,也就是说docker compose up -d并没有启动成功,虽然命令行输出启动成功:
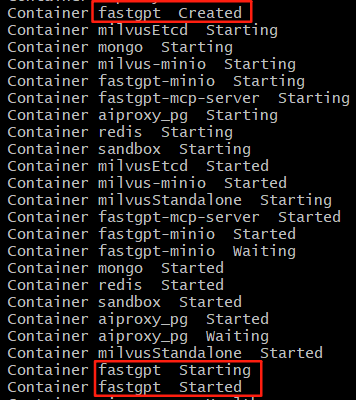
如上图,状态依次经历:Created、Starting、Started。
打开Docker Desktop,会发现fastgpt并没有一起启动:

手动启动fastgpt(注意上面截图中,fastgpt是24秒前启动,而aiproxy是14分钟前启动)。
刷新浏览器,输入用户名root,密码1234,登录成功。
模型配置
系统自动检测,并提示没有可用的语言模型,并跳转到模型配置页面:
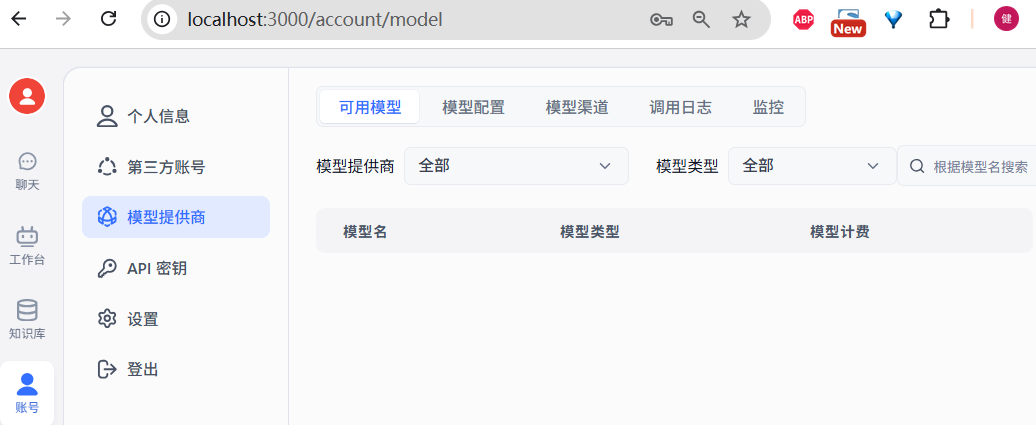
点击【模型渠道】,右上角【新增渠道】
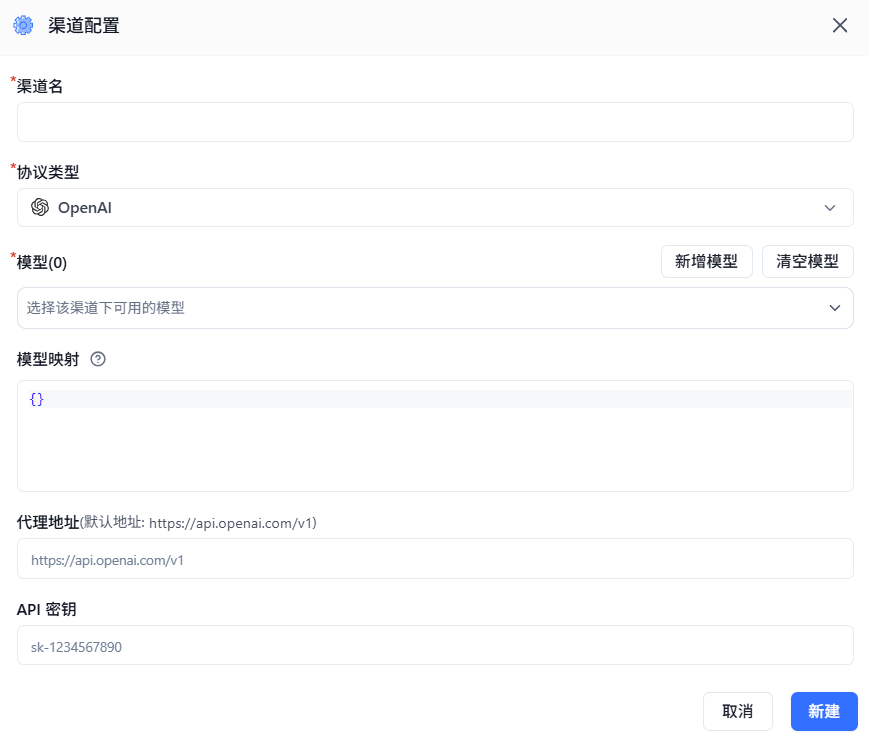
【协议类型】和【模型】两个下拉框,搜索都有点问题。
以阿里云为例:
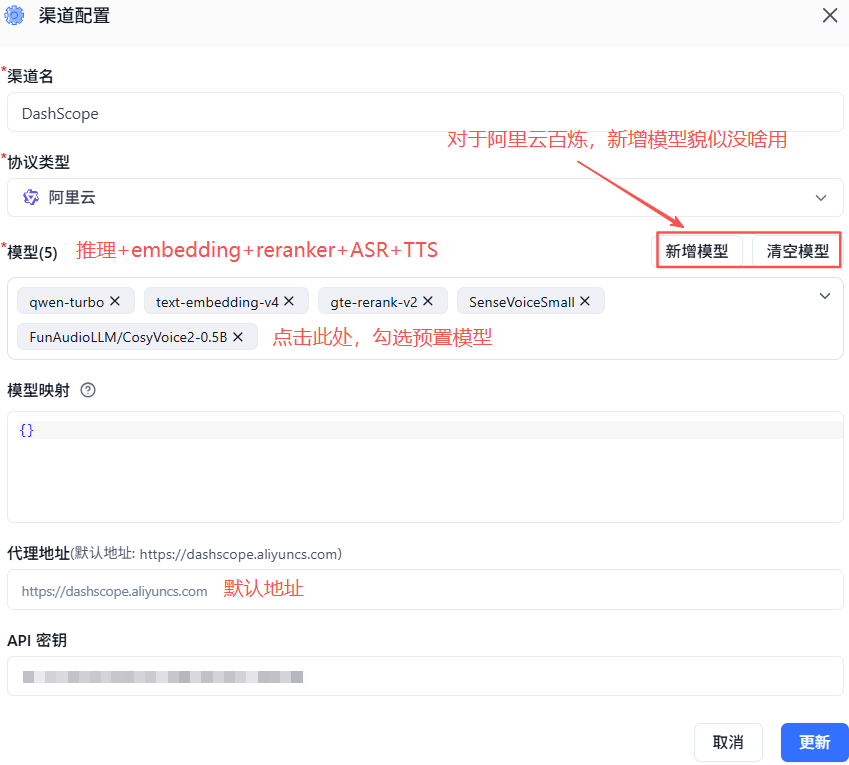
注意:有些平台在对接阿里云百炼时,填写的API URL是https://dashscope.aliyuncs.com/compatible-mode/v1,FastGPT会自动补齐/compatible-mode/v1。
也就是说,先点击【模型渠道】配置好API Key,从下拉列表随便勾选一个模型,测试API Key的可用性,然后点击【模型配置】,点击启用,【可用模型】列表就能看到启用中模型
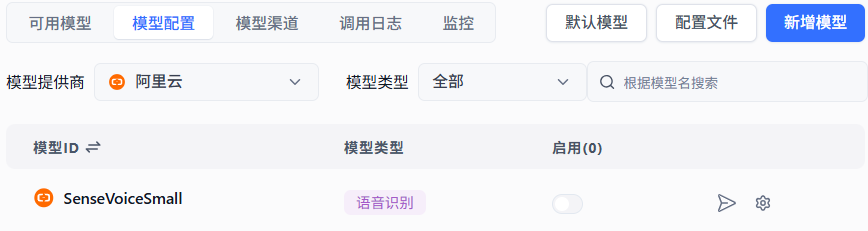
如上图,SenseVoiceSmall这个ASR模型是在【阿里云】不是【通义千问】下面的,这也导致下面提到的ASR模型测试异常。
Ollama
【协议类型】选择Ollama,理论上Ollama支持部署任意模型。点击【新增模型】

很熟悉,和Dify一样:
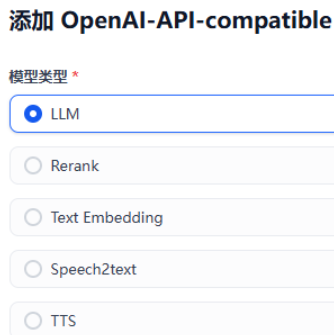
新增模型页面,和XInference比较类似:
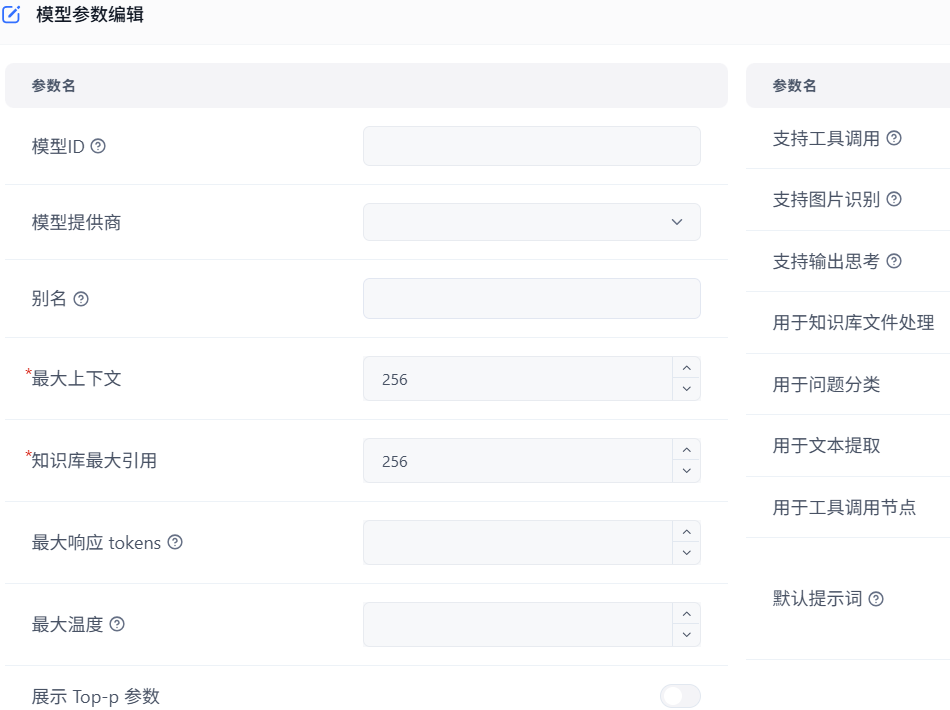
4个必填参数:模型ID、别名、最大上下文、知识库最大引用。模型新增成功后,在模型列表最下面可看到:
点击【模型渠道】列表,很贴心,有个模型测试入口:
测试结果:
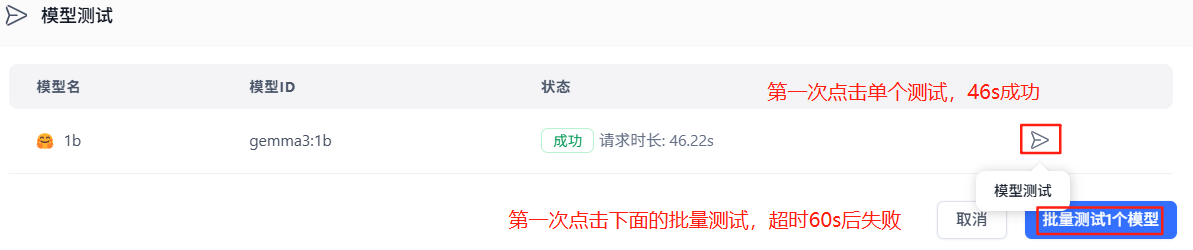
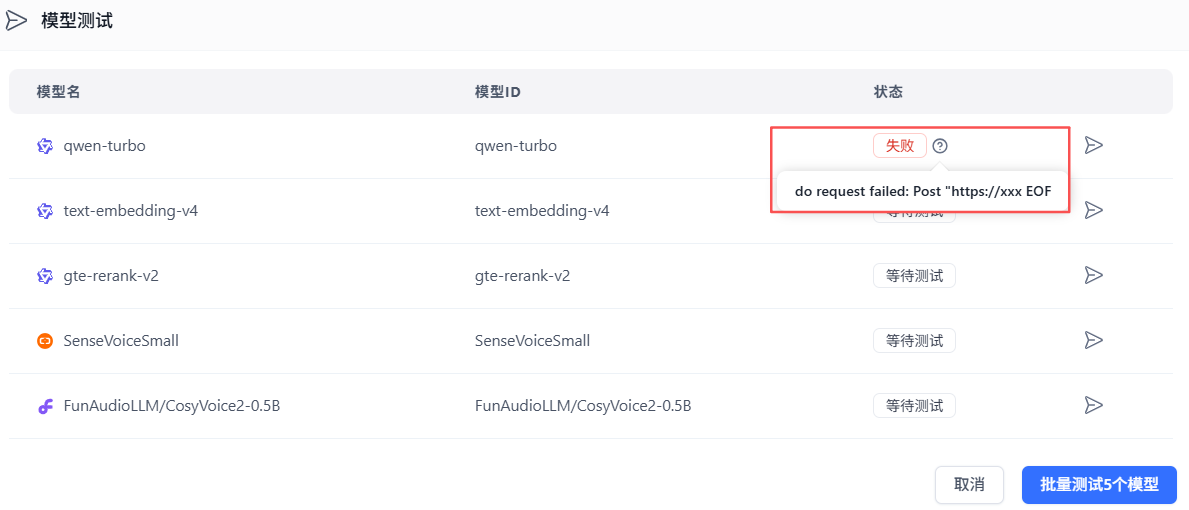
Bug还真不少:

和n8n一样,会自动启动模型:

常见错误
一开始填写完整的地址:https://dashscope.aliyuncs.com/compatible-mode/v1,于是遇到下面这些莫名其妙的报错。
网络连接EOF异常:
模型不存在:

模型404:

请求错误:
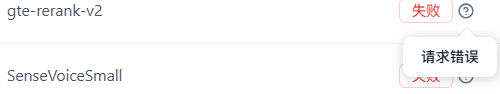
握手异常:

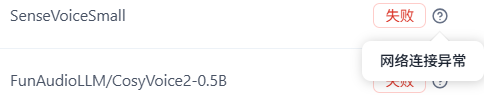
使用阿里云,不填写【代理地址】,ASR和TTS模型还是有问题:

配置DeepSeek驱动+deepseek-chat,模型测试如下,预期之内,未充值:
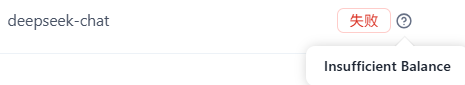
索引模型
理论上有了问答(推理)模型,就可使用【聊天】功能:
Embedding模型为啥是必须的?
Ok, fine.
选择经过q4量化体积约52MB,适合中文嵌入场景的shaw/dmeta-embedding-zh-small-q4,模型测试:

应用
点击【聊天】,发起Query,弹窗报错:

点击【工作台】,
点击新建:
选择创建空白应用:
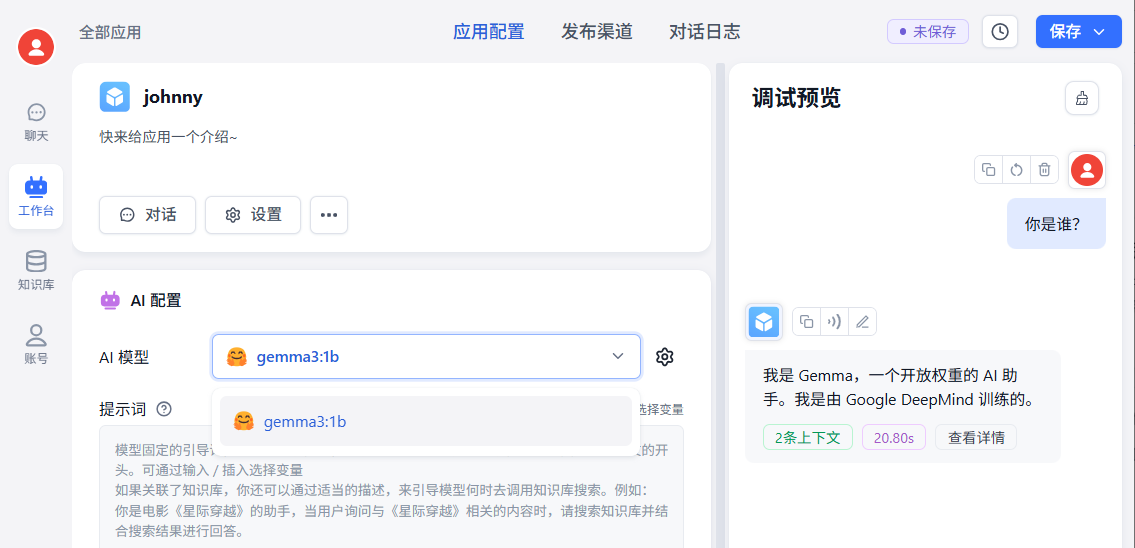
至此,FastGPT本地部署,使用Ollama本地模型,聊天机器人,最小功能已跑通。
知识库
点击右上角【新建】
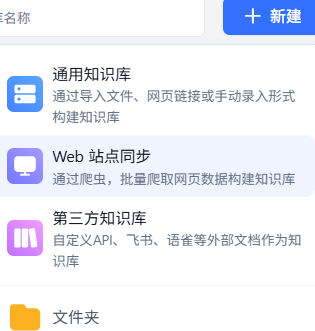
其中【Web站点同步】需升级到商业版方可使用。
新增【第三方知识库】:
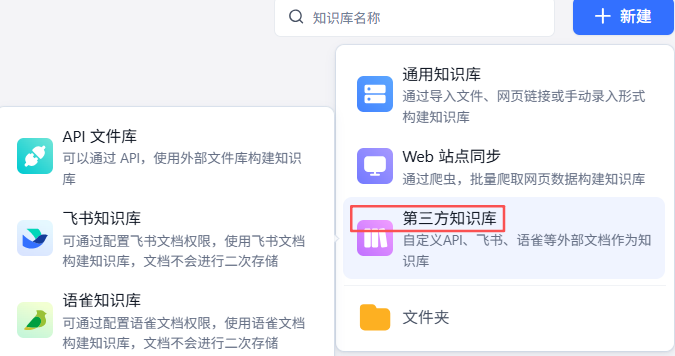
API文件库
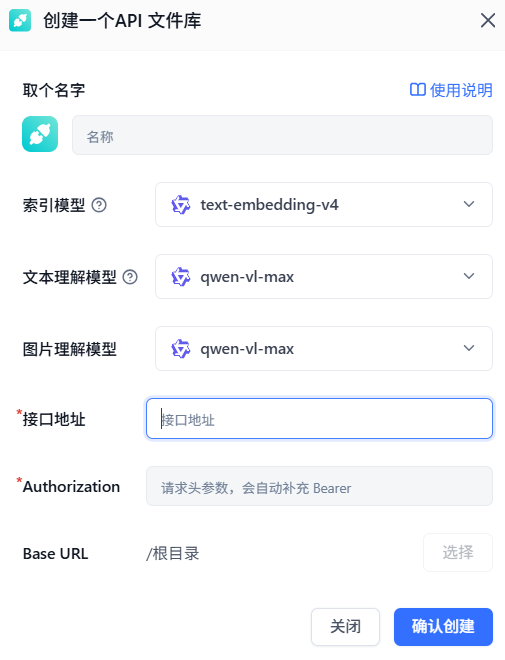
飞书知识库
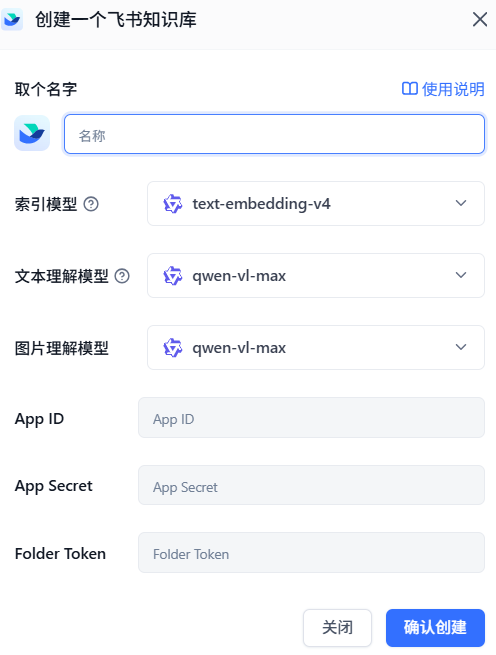
语雀知识库
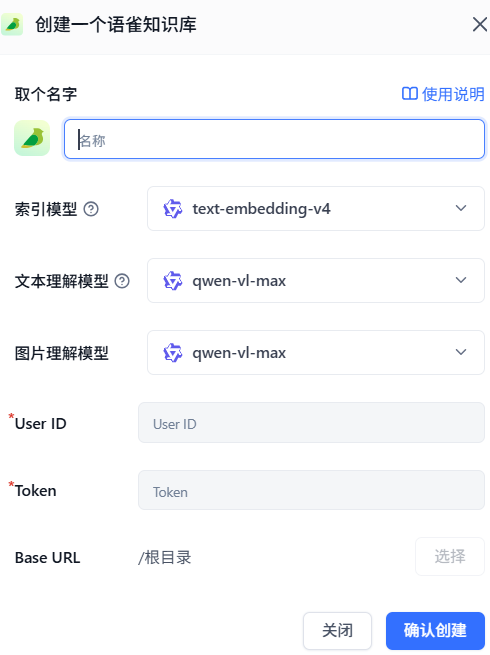
创建一个通用知识库,索引模型是必须要配置的
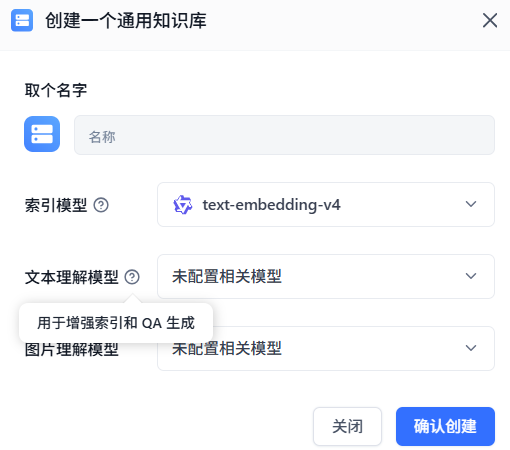
但【文本理解模型】和【图片理解模型】之前从来没看到,这里需要对LLM有一些基本了解,勾选vl类模型的启用后,【可用模型】列表出现该模型
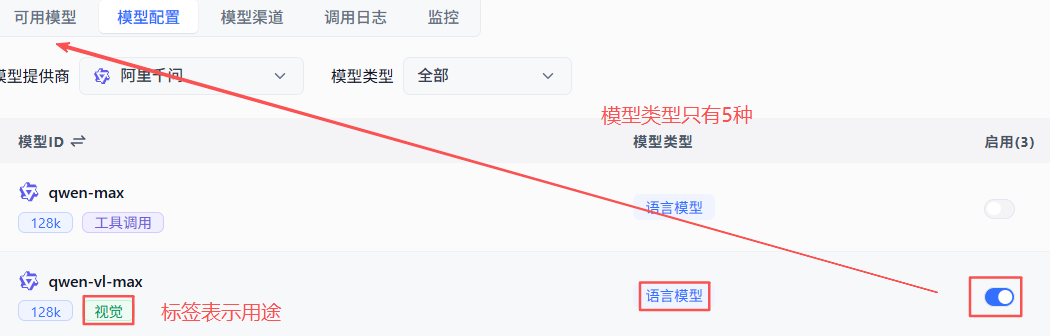
然后新增知识库就能看到

打开知识库,点击右上角【新建/导入】
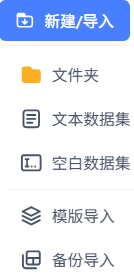
支持的导入方式还是挺多的,
点击空白数据集,支持三种方式:
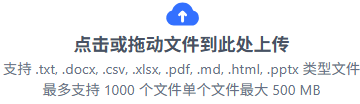
选择本地文件,支持的文件后缀名以及文件(大小和数量)限制如下:
继续
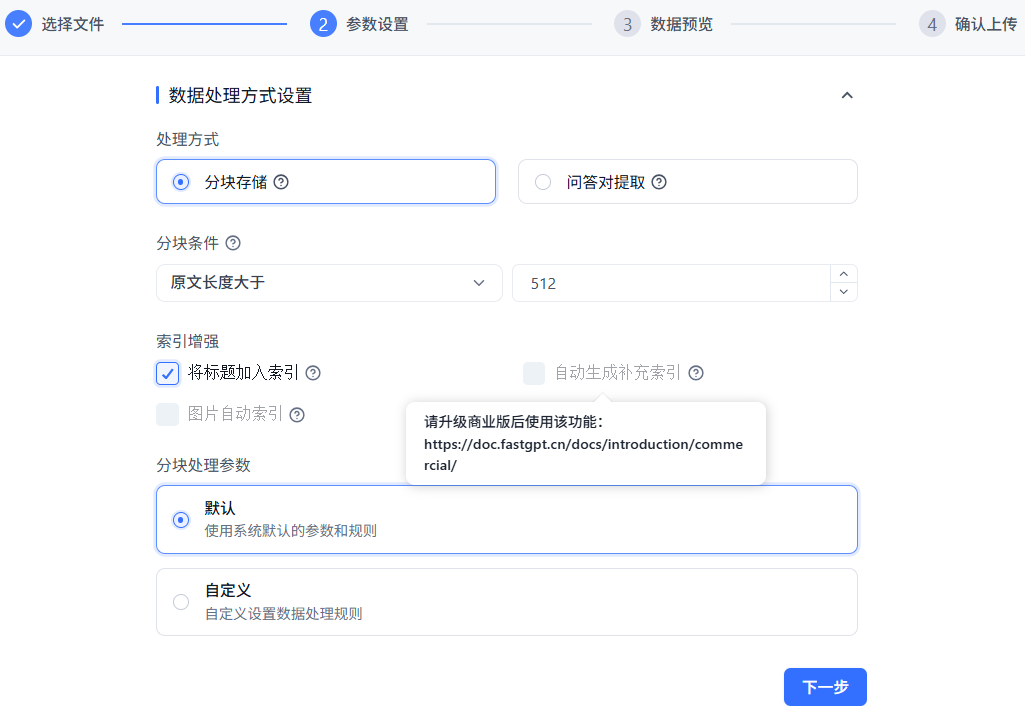
其中处理方式有两种:
- 分块存储:将文本按一定的规则进行分段处理后,转成可进行语义搜索的格式,适合绝大多数场景。不需要调用模型额外处理,成本低。
- 问答对提取:根据一定规则,将文本拆成一段较大的段落,调用AI为该段落生成问答对。有非常高的检索精度,但是会丢失很多内容细节。
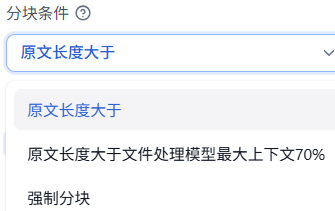
分块条件有三种:
索引增强有三个选项:
- 将标题加入索引:自动给索引所有索引加标题名;
- 自动生成补充索引:通过大模型进行额外索引生成,提高语义丰富度,提高检索的精度。需升级商业版方可使用;
- 图片自动索引:调用VLM自动标注文档里的图片,并生成额外的检索索引。同上需付费。
分块处理参数,有两种选项,来看看自定义:
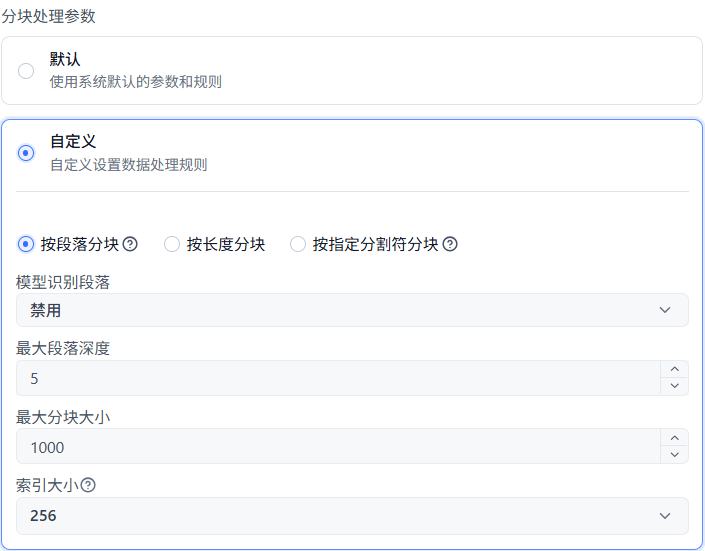
有三种分块方式:
- 段落:优先按Makdown标题段落进行分块,如果分块过长,再按长度进行二次分块;
- 长度:最简单暴力方式;
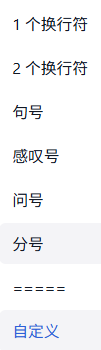
- 分隔符:允许根据自定义的分隔符进行分块。通常用于已处理好的数据,使用特定的分隔符来精确分块。可使用
|符号表示多个分割符,如。|.表示中英文句号。尽量避免使用正则相关特殊符号,如*()[]{}等。
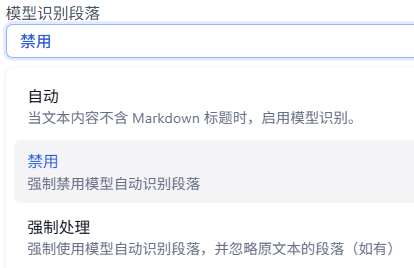
模型识别段落选项:
分隔符支持自定义:
选择【问答对提取】时,系统预设拆分引导词(提示词),支持修改: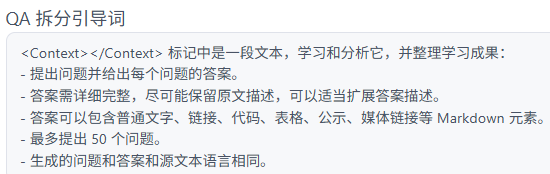
右上角可以看到文档索引排队情况
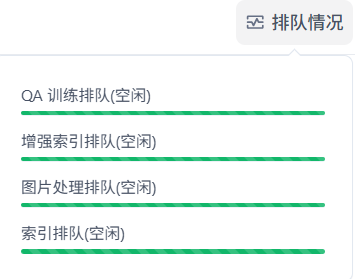
遇到的问题,训练异常(已经结束)不能修改切换索引模型,下面的提示文案有点误导性:
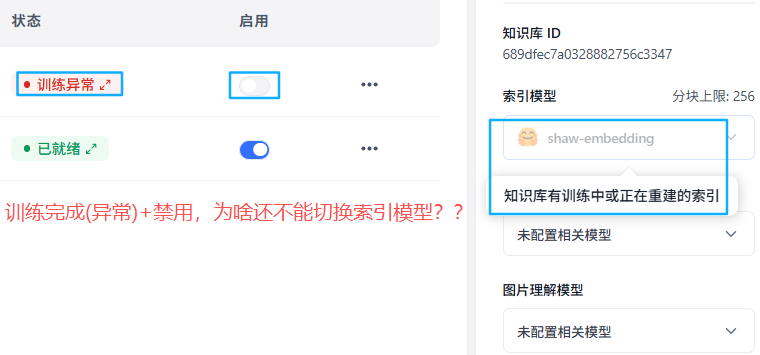
解决方法:
- 删除训练异常的文件,重新导入文件
- 新增知识库,导入文件
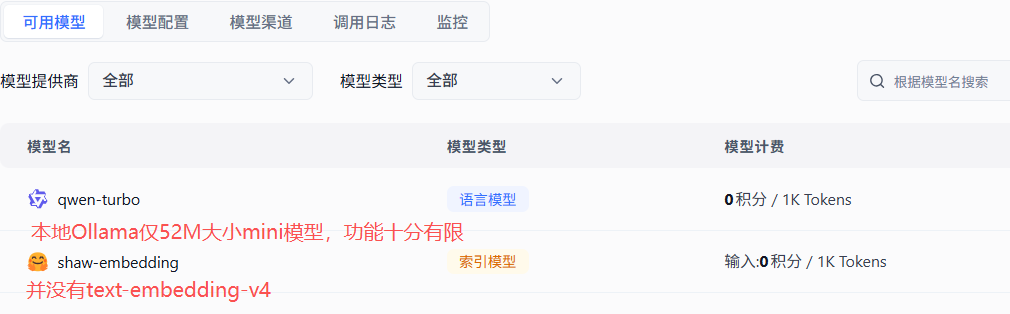
第一种方法更快捷,前提是新增更强大的embedding模型,要不然使用shaw-embedding大概率还是嵌入(训练)异常。
在下拉列表里选择的模型,在【模型配置】里点击启用,才能出现在【可用模型】标签页下面:
切换提示:
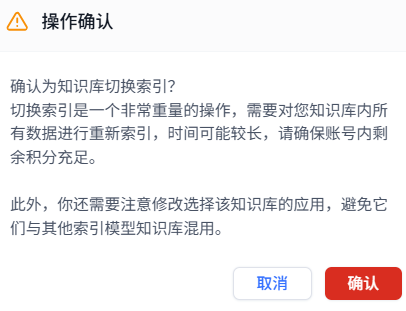
新的问题:

重试,貌似解决。
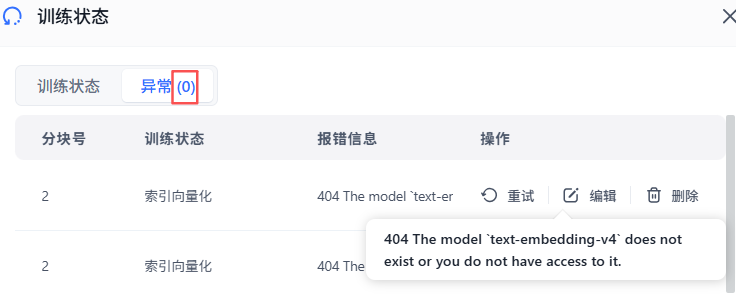
可是点击编辑,没有问题啊,QA对提取正常!!!

搜索测试报错如下(忽略下面的v3,用v4也是这个报错):

解决方法:在【模型渠道】里需勾选模型
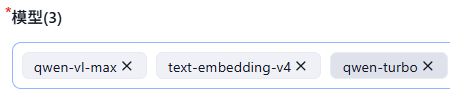
测试成功的效果:
导出功能
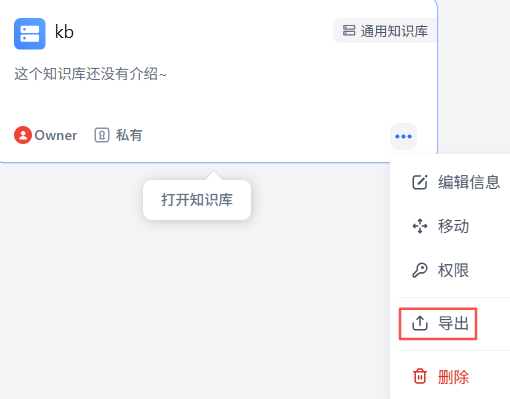
导出为CSV文件。
权限
点击权限配置,添加协作者:
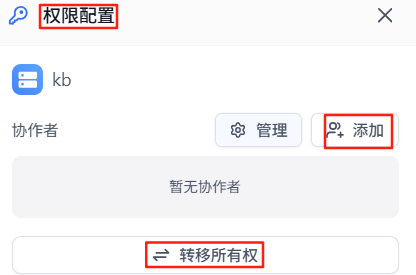
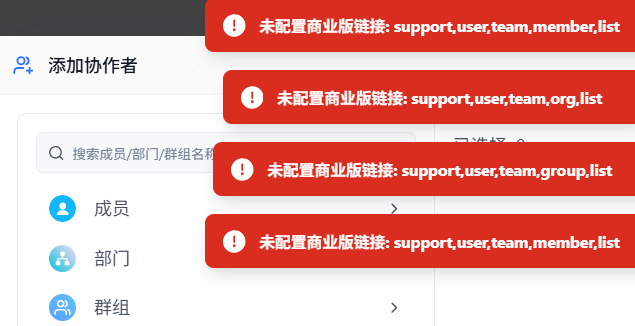
报错如下,同样地,转移所有权也是下面这个报错提示:
系统插件

分类看起来挺详细,但很多分类下没有插件。我安装的版本是V4.12.0,共29个插件,集中在工具(4个)、搜索(9个)、多模态(4个)、通讯(4个)、科研(1个)。
模板市场
有4大类型:
- 图片生成
- 联网搜索
- 角色扮演
- 办公服务

试个【谷歌搜索】,不太行
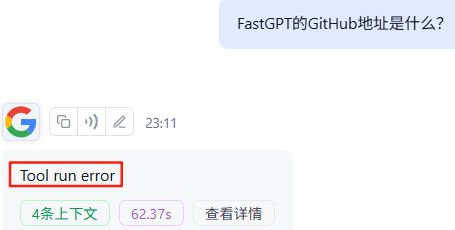
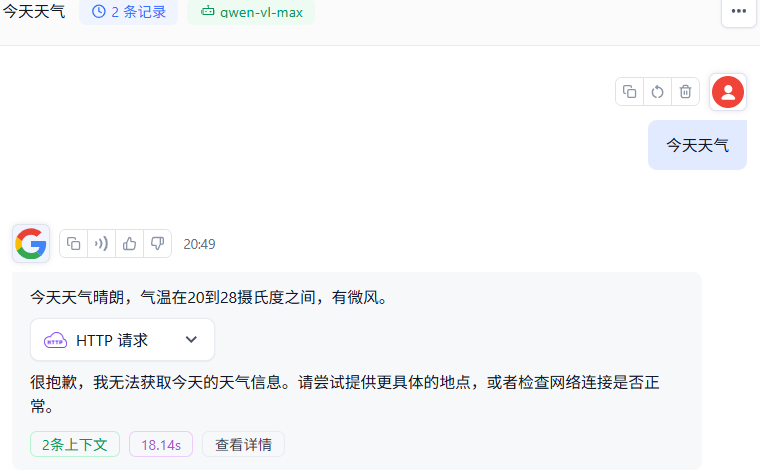
MCP
laf账号
https://laf.dev