【AI论文】RLP:将强化学习作为预训练目标
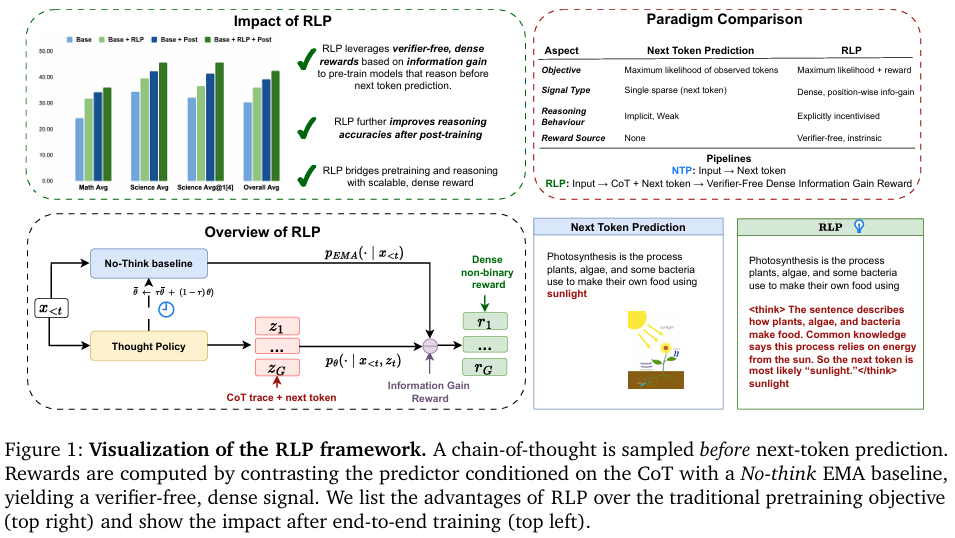
摘要:当前,训练大型推理模型的主流范式是先利用海量数据,基于下一标记预测损失进行预训练,而强化学习虽在扩展推理能力方面表现强大,却仅被作为训练最后阶段的微调后处理引入,且在此之前还需进行监督式微调。尽管这一方式占据主导地位,但它是否是最优的训练方法呢?在本文中,我们提出了RLP(一种基于信息驱动的强化预训练目标),它将强化学习的核心精神——探索——引入预训练的最后阶段。其关键思路是将思维链视为一种探索性动作,并根据其对预测未来标记所提供的信息增益来计算奖励。这种训练目标本质上鼓励模型在预测后续内容之前先进行自主思考,从而在预训练的早期阶段就培养其独立思考能力。更具体地说,奖励信号衡量的是在同时考虑上下文和抽样得到的推理链的条件下,与仅考虑上下文的条件相比,下一标记对数似然值的增加量。这种方法产生了一个无需验证器的密集奖励信号,使得在预训练期间能够对整个文档流进行高效训练。具体而言,RLP将针对推理的强化学习重新定义为普通文本上的预训练目标,从而弥合了下一标记预测与有用的思维链推理能力出现之间的差距。在Qwen3-1.7B-Base模型上使用RLP进行预训练,可使数学与科学八项基准测试套件的整体平均得分提升19%。在采用相同的训练后处理流程时,这种提升效果会进一步累积,在AIME25和MMLU-Pro等侧重推理的任务上实现最大幅度的改进。将RLP应用于混合架构的Nemotron-Nano-12B-v2模型,则使其整体平均得分从42.81%提升至61.32%,科学推理的平均得分提高了23%,这证明了RLP在不同架构和模型规模上的可扩展性。Huggingface链接:Paper page,论文链接:2510.01265
研究背景和目的
研究背景:
随着大型语言模型(LLMs)在自然语言处理任务中的广泛应用,其训练方法成为研究热点。
传统上,LLMs主要依赖下一 token 预测损失进行预训练,这种方法虽然有效,但缺乏显式鼓励模型进行长距离推理或整合世界知识的能力。因此,尽管预训练模型在多项任务中表现出色,但在需要复杂推理的场景下,如数学问题和科学推理,其性能仍有待提升。
强化学习(RL)作为一种能够扩展推理能力的技术,在预训练阶段的应用却相对有限。
现有方法通常将强化学习作为预训练后的最后阶段引入,即后训练阶段,通过监督微调(SFT)和基于人类或验证反馈的强化学习(如RLHF、RLAIF、RLVR)来诱导复杂的推理能力。然而,这种顺序训练方式可能限制了模型在预训练阶段就具备独立推理能力的潜力。
研究目的:
本研究旨在提出一种新的预训练目标——RLP(Reinforcement as a Pretraining Objective),通过将强化学习引入预训练阶段,鼓励模型在预测下一 token 之前进行显式的推理过程(即思维链,CoT)。
RLP的核心思想是将思维链视为一种探索性行动,通过计算基于上下文和采样思维链的下一 token 预测 log 似然增加量来提供奖励信号,从而训练模型在预训练阶段就具备独立推理的能力。本研究期望通过RLP提升模型在数学和科学推理任务上的表现,并探索其在不同模型架构和规模上的可扩展性。
研究方法
1. RLP框架设计:
RLP框架的核心在于将强化学习作为预训练目标,通过引入思维链(CoT)作为显式推理步骤,提升模型在预测下一 token 前的推理能力。
具体而言,RLP在下一 token 预测之前插入一个短的思维链,并计算该思维链对下一 token 预测 log 似然的增加量,以此作为奖励信号。
2. 奖励机制:
RLP使用一种无需验证器的密集奖励信号,该信号基于信息增益计算,即比较在给定上下文和采样思维链条件下,下一 token 的 log 似然与仅给定上下文条件下的 log 似然之间的差异。
这种奖励机制允许模型在预训练过程中持续优化,而无需依赖外部验证器或真实标签。
3. 实验设置:
- 数据集:实验使用了多样化的数据集,包括数学专用数据集(如OmniMath)、混合数学和通用推理数据集(如OpenThoughts、Nemotron-Crossthink)以及通用预训练语料库(如学术论文、数学教材和开放网页QA对)。
- 模型架构:实验在qwen3-1.7b-base和Nemotron-Nano-12B-v2两种模型架构上进行,以验证RLP在不同规模和架构上的有效性。
- 评估指标:使用八个数学和科学基准测试套件来评估模型性能,包括GSM8K、MATH-500、Minerva Math、AMC23等数学基准,以及MMLU、MMLU-Pro和GPQA-Diamond等科学基准。
4. 实施细节:
- 训练过程:RLP训练通过交替进行强化学习更新和标准似然训练来实现,使用组相对优势、思维 token 的剪辑替代和缓慢更新的指数移动平均(EMA)基线来确保训练的稳定性。
- 基线对比:实验设置了多个基线,包括持续预训练(CPT)、链式思维预训练(CPT)以及传统下一 token 预测基线,以全面评估RLP的性能。
研究结果
1. 数学和科学推理性能提升:
在qwen3-1.7b-base模型上,RLP预训练使八个数学和科学基准测试套件的总体平均性能提升了19%。
特别是在AIME25和MMLU-Pro等推理密集型任务上,性能提升显著。对于Nemotron-Nano-12B-v2模型,RLP将其在科学基准上的平均性能从42.81%提升至61.32%,展示了RLP在不同模型架构和规模上的可扩展性。
2. 后训练性能增强:
RLP预训练的优势在后训练阶段进一步放大。
与持续预训练(CPT)和链式思维预训练(CPT)相比,RLP预训练后的模型在后训练后表现出更高的性能,表明RLP为模型提供了更稳健的推理基础,这些基础在后训练过程中得以巩固和增强。
3. 跨领域泛化能力:
RLP不仅在数学推理任务上表现出色,还在科学推理任务上展示了强大的泛化能力。实验结果表明,RLP预训练的模型在科学基准测试上的平均性能显著提升,尤其是在需要多步解释驱动的推理任务上。
4. 数据效率:
RLP在数据效率方面也表现出色。
在仅使用0.125%的数据量的情况下,RLP在Nemotron-Nano-12B-v2模型上实现了35%的相对性能提升,展示了其在数据利用上的高效性。
研究局限
1. 干预策略复杂性:
尽管RLP框架在理论上具有优势,但在实际应用中,如何设计有效的干预策略仍是一个挑战。
不同专家或AI代理在训练同一模型时可能采取不同的干预策略,导致结果差异。
2. 模型规模与数据需求:
虽然RLP在较小规模的模型上展示了显著的性能提升,但随着模型规模的扩大,对数据量和计算资源的需求也会增加。
如何在资源有限的情况下保持RLP的有效性是一个需要进一步探索的问题。
3. 评估指标局限性:
当前研究主要关注数学和科学基准测试上的性能提升,但这些指标可能无法全面反映模型在实际应用中的表现。未来研究需要开发更全面的评估指标,以更准确地评估模型在各种场景下的性能。
未来研究方向
1. 开发更复杂的干预策略:
未来的研究可以探索如何设计更复杂的干预策略,以进一步提升RLP框架的性能。这包括开发能够自动检测训练异常并指导训练的AI代理,以及设计更精细的奖励机制来引导模型行为。
2. 扩展至更多领域:
尽管RLP在数学和科学推理任务上表现出色,但其在其他领域(如自然语言理解、生成任务等)的应用仍有待探索。
未来研究可以将RLP框架应用于更多领域,以验证其普适性和有效性。
3. 结合其他优化技术:
RLP可以与其他优化技术(如AutoML、自适应优化方法等)相结合,以进一步提升模型性能。
例如,可以利用AutoML技术自动调整RLP训练过程中的超参数,或使用自适应优化方法根据实时反馈调整训练策略。
4. 实际应用测试:
将RLP框架应用于实际场景中,如在线教育、智能客服等,以验证其在真实环境中的表现。
通过实际应用测试,可以更全面地了解RLP框架的优势和局限性,并为未来的改进提供方向。
5. 跨语言和文化适应性:
探索RLP在不同语言和文化背景下的适应性。由于RLP主要在英文数据集上进行验证,未来研究可以探索其在其他语言和文化背景下的表现,以推动全球范围内的模型优化和本地化应用。
6. 长期训练稳定性与可扩展性:
进一步研究RLP在长期训练过程中的稳定性和可扩展性。
随着训练时间的延长和数据量的增加,如何保持RLP框架的稳定性和性能是一个重要的研究方向。
7. 解释性与透明度:
提升RLP训练模型的解释性和透明度。通过开发可解释性工具和方法,帮助用户更好地理解模型的工作原理和决策过程,从而增强用户对模型的信任度。