etcd实战课-实战篇(上)
12 一致性:为什么基于Raft实现的etcd还会出现数据不一致?
今天我要和你分享的主题是关于etcd数据一致性的。
我们都知道etcd是基于Raft实现的高可用、强一致分布式存储。但是有一天我和小伙伴王超凡却遭遇了一系列诡异的现象:用户在更新Kubernetes集群中的Deployment资源镜像后,无法创建出新Pod,Deployment控制器莫名其妙不工作了。更令人细思极恐的是,部分Node莫名其妙消失了。
我们当时随便找了一个etcd节点查看存储数据,发现Node节点却在。这究竟是怎么一回事呢? 今天我将和你分享这背后的故事,以及由它带给我们的教训和启发。希望通过这节课,能帮助你搞懂为什么基于Raft实现的etcd有可能出现数据不一致,以及我们应该如何提前规避、预防类似问题。
从消失的Node说起
故事要从去年1月的时候说起,某日晚上我们收到一个求助,有人反馈Kubernetes集群出现了Deployment滚动更新异常、节点莫名其妙消失了等诡异现象。我一听就感觉里面可能大有文章,于是开始定位之旅。
我首先查看了下Kubernetes集群APIServer、Controller Manager、Scheduler等组件状态,发现都是正常。
然后我查看了下etcd集群各节点状态,也都是健康的,看了一个etcd节点数据也是正常,于是我开始怀疑是不是APIServer出现了什么诡异的Bug了。
我尝试重启APIServer,可Node依旧消失。百思不得其解的同时,只能去确认各个etcd节点上数据是否存在,结果却有了颠覆你固定思维的发现,那就是基于Raft实现的强一致存储竟然出现不一致、数据丢失。除了第一个节点含有数据,另外两个节点竟然找不到。那么问题就来了,另外两个节点数据是如何丢失的呢?
一步步解密真相
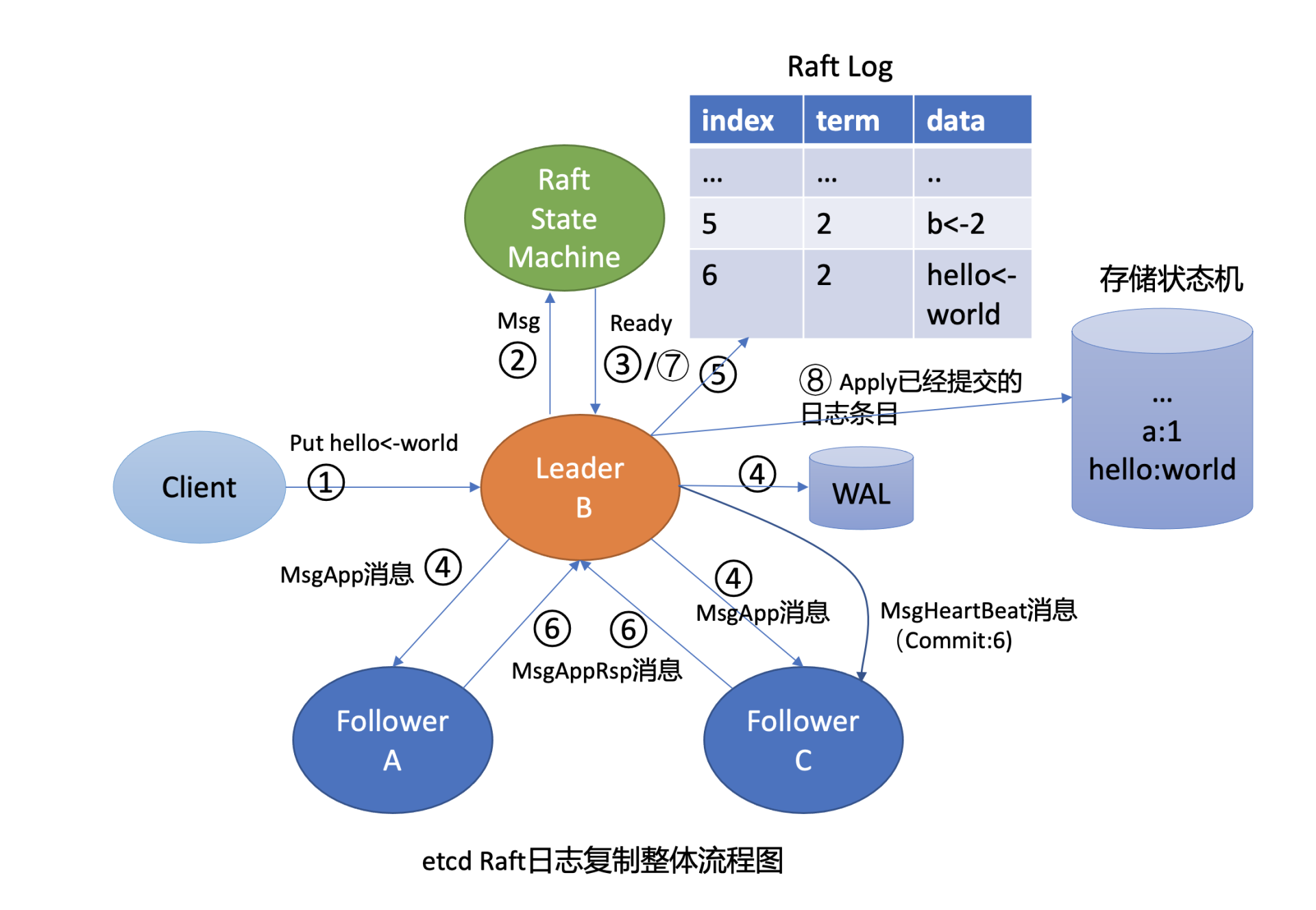
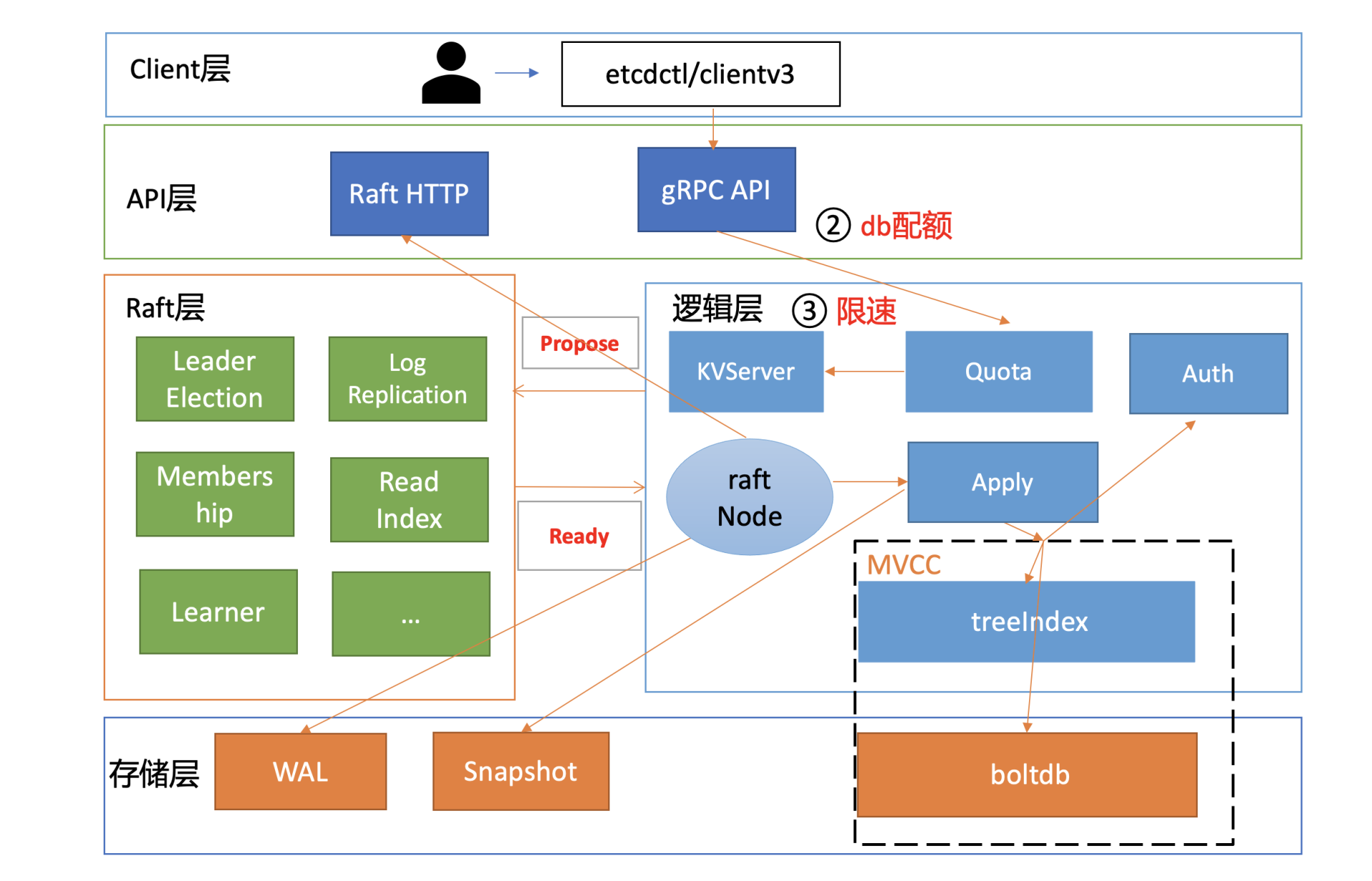
在进一步深入分析前,我们结合基础篇03对etcd写流程原理的介绍(如下图),先大胆猜测下可能的原因。
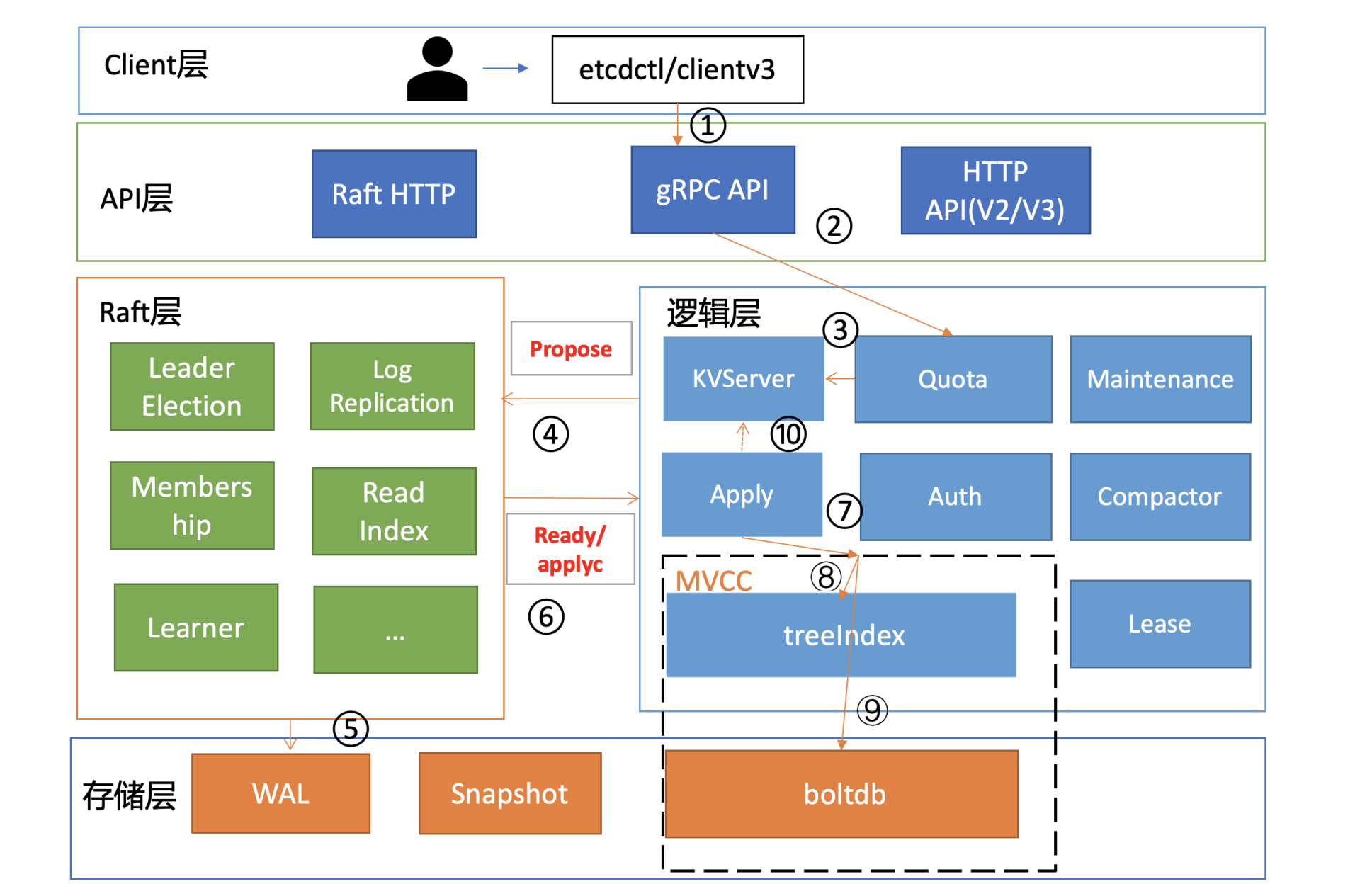
猜测1:etcd集群出现分裂,三个节点分裂成两个集群。APIServer配置的后端etcd server地址是三个节点,APIServer并不会检查各节点集群ID是否一致,因此如果分裂,有可能会出现数据“消失”现象。这种故障之前在Kubernetes社区的确也见到过相关issue,一般是变更异常导致的,显著特点是集群ID会不一致。
猜测2:Raft日志同步异常,其他两个节点会不会因为Raft模块存在特殊Bug导致未收取到相关日志条目呢?这种怀疑我们可以通过etcd自带的WAL工具来判断,它可以显示WAL日志中收到的命令(流程四、五、六)。
猜测3:如果日志同步没问题,那有没有可能是Apply模块出现了问题,导致日志条目未被应用到MVCC模块呢(流程七)?
猜测4:若Apply模块执行了相关日志条目到MVCC模块,MVCC模块的treeIndex子模块会不会出现了特殊Bug, 导致更新失败(流程八)?
猜测5:若MVCC模块的treeIndex模块无异常,写请求到了boltdb存储模块,有没有可能boltdb出现了极端异常导致丢数据呢(流程九)?
带着以上怀疑和推测,让我们不断抽丝剥茧、去一步步探寻真相。
首先还是从故障定位第一工具“日志”开始。我们查看etcd节点日志没发现任何异常日志,但是当查看APIServer日志的时候,发现持续报”required revision has been compacted”,这个错误根据我们基础篇11节介绍,我们知道原因一般是APIServer请求etcd版本号被压缩了。
于是我们通过如下命令查看etcd节点详细的状态信息:
etcdctl endpoint status --cluster -w json | python -m
json.tool
获得以下结果:
[{"Endpoint":"A","Status":{"header":{"cluster_id":17237436991929493444,"member_id":9372538179322589801,"raft_term":10,"revision":1052950},"leader":9372538179322589801,"raftAppliedIndex":1098420,"raftIndex":1098430,"raftTerm":10,"version":"3.3.17"}},{"Endpoint":"B","Status":{"header":{"cluster_id":17237436991929493444,"member_id":10501334649042878790,"raft_term":10,"revision":1025860},"leader":9372538179322589801,"raftAppliedIndex":1098418,"raftIndex":1098428,"raftTerm":10,"version":"3.3.17"}},{"Endpoint":"C","Status":{"header":{"cluster_id":17237436991929493444,"member_id":18249187646912138824,"raft_term":10,"revision":1028860},"leader":9372538179322589801,"raftAppliedIndex":1098408,"raftIndex":1098428,"raftTerm":10,"version":"3.3.17"}}
]
从结果看,我们获得了如下信息:
第一,集群未分裂,3个节点A、B、C cluster_id都一致,集群分裂的猜测被排除。
第二,初步判断集群Raft日志条目同步正常,raftIndex表示Raft日志索引号,raftAppliedIndex表示当前状态机应用的日志索引号。这两个核心字段显示三个节点相差很小,考虑到正在写入,未偏离正常范围,Raft同步Bug导致数据丢失也大概率可以排除(不过最好还是用WAL工具验证下现在日志条目同步和写入WAL是否正常)。
第三,观察三个节点的revision值,相互之间最大差距接近30000,明显偏离标准值。在07中我给你深入介绍了revision的含义,它是etcd逻辑时钟,每次写入,就会全局递增。为什么三个节点之间差异如此之大呢?
接下来我们就一步步验证猜测、解密真相,猜测1集群分裂说被排除后,猜测2Raft日志同步异常也初步被我们排除了,那如何真正确认Raft日志同步正常呢?
你可以使用下面这个方法验证Raft日志条目同步是否正常。
首先我们写入一个值,比如put hello为world,然后马上在各个节点上用WAL工具etcd-dump-logs搜索hello。如下所示,各个节点上都可找到我们刚刚写入的命令。
$ etcdctl put hello world
OK
$ ./bin/tools/etcd-dump-logs ./Node1.etcd/ | grep hello
10 70 norm header:<ID:3632562852862290438 > put:<key:"hello" value:"world" >
$ ./bin/tools/etcd-dump-logs ./Node2.etcd/ | grep hello
10 70 norm header:<ID:3632562852862290438 > put:<key:"hello" value:"world" >
$ ./bin/tools/etcd-dump-logs ./Node3.etcd/ | grep hello
10 70 norm header:<ID:3632562852862290438 > put:<key:"hello" value:"world" >
Raft日志同步异常猜测被排除后,我们再看下会不会是Apply模块出现了问题。但是raftAppliedIndex却显示三个节点几乎无差异,那我们能不能通过这个指标来判断Apply流程是否正常呢?
源码面前了无秘密,etcd更新raftAppliedIndex核心代码如下所示,你会发现这个指标其实并不靠谱。Apply流程出现逻辑错误时,并没重试机制。etcd无论Apply流程是成功还是失败,都会更新raftAppliedIndex值。也就是一个请求在Apply或MVCC模块即便执行失败了,都依然会更新raftAppliedIndex。
// ApplyEntryNormal apples an EntryNormal type Raftpb request to the EtcdServer
func (s *EtcdServer) ApplyEntryNormal(e *Raftpb.Entry) {shouldApplyV3 := falseif e.Index > s.consistIndex.ConsistentIndex() {// set the consistent index of current executing entrys.consistIndex.setConsistentIndex(e.Index)shouldApplyV3 = true}defer s.setAppliedIndex(e.Index)....}
而三个节点revision差异偏离标准值,恰好又说明异常etcd节点可能未成功应用日志条目到MVCC模块。我们也可以通过查看MVCC的相关metrics(比如etcd_mvcc_put_total),来排除请求是否到了MVCC模块,事实是丢数据节点的metrics指标值的确远远落后正常节点。
于是我们将真凶锁定在Apply流程上。我们对Apply流程在未向MVCC模块提交请求前可能提前返回的地方,都加了日志。
同时我们查看Apply流程还发现,Apply失败的时候并不会打印任何日志。这也解释了为什么出现了数据不一致严重错误,但三个etcd节点却并没有任何异常日志。为了方便定位问题,我们因此增加了Apply错误日志。
同时我们测试发现,写入是否成功还跟client连接的节点有关,连接不同节点会出现不同的写入结果。我们用debug版本替换后,马上就输出了一条错误日志auth: revision in header is old。
原来数据不一致是因为鉴权版本号不一致导致的,节点在Apply流程的时候,会判断Raft日志条目中的请求鉴权版本号是否小于当前鉴权版本号,如果小于就拒绝写入。
那为什么各个节点的鉴权版本号会出现不一致呢?那就需要从可能修改鉴权版本号的源头分析。我们发现只有鉴权相关接口才会修改它,同时各个节点鉴权版本号之间差异已经固定不再增加,要成功解决就得再次复现。
然后还了解到,当时etcd进程有过重启,我们怀疑会不会重启触发了什么Bug,手动尝试复现一直失败。然而我们并未放弃,随后我们基于混沌工程,不断模拟真实业务场景、访问鉴权接口、注入故障(停止etcd进程等),最终功夫不负有心人,实现复现成功。
真相终于浮出水面,原来当你无意间重启etcd的时候,如果最后一条命令是鉴权相关的,它并不会持久化consistent index(KV接口会持久化)。consistent index在03里我们详细介绍了,它具有幂等作用,可防止命令重复执行。consistent index的未持久化最终导致鉴权命令重复执行。
恰好鉴权模块的RoleGrantPermission接口未实现幂等,重复执行会修改鉴权版本号。一连串的Bug最终导致鉴权号出现不一致,随后又放大成MVCC模块的key-value数据不一致,导致严重的数据毁坏。
这个Bug影响etcd v3所有版本长达3年之久。查清楚问题后,我们也给社区提交了解决方案,合并到master后,同时cherry-pick到etcd 3.3和3.4稳定版本中。etcd v3.3.21和v3.4.8后的版本已经修复此Bug。
为什么会不一致
详细了解完这个案例的不一致后,我们再从本质上深入分析下为什么会出现不一致,以及还有哪些场景会导致类似问题呢?
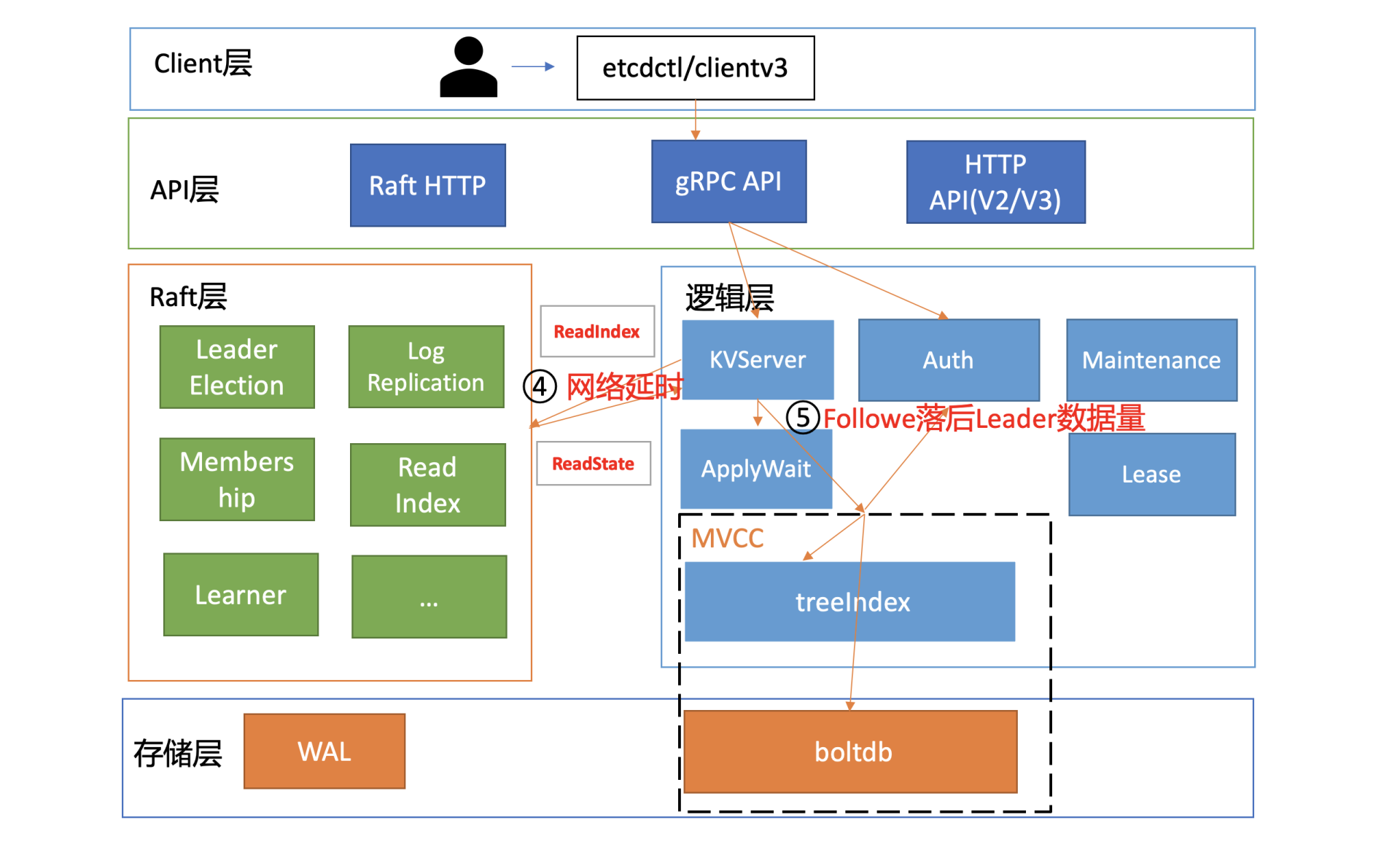
首先我们知道,etcd各个节点数据一致性基于Raft算法的日志复制实现的,etcd是个基于复制状态机实现的分布式系统。下图是分布式复制状态机原理架构,核心由3个组件组成,一致性模块、日志、状态机,其工作流程如下:
- client发起一个写请求(set x = 3);
- server向一致性模块(假设是Raft)提交请求,一致性模块生成一个写提案日志条目。若server是Leader,把日志条目广播给其他节点,并持久化日志条目到WAL中;
- 当一半以上节点持久化日志条目后,Leader的一致性模块将此日志条目标记为已提交(committed),并通知其他节点提交;
- server从一致性模块获取已经提交的日志条目,异步应用到状态机持久化存储中(boltdb等),然后返回给client。
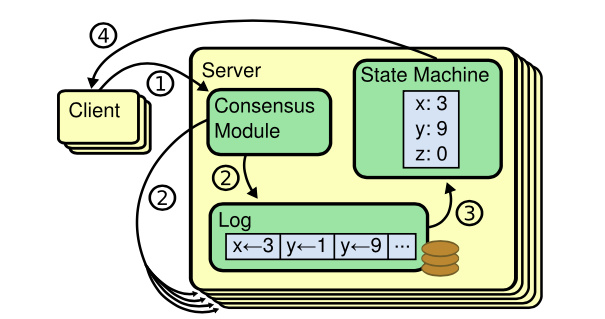
从图中我们可以了解到,在基于复制状态机实现的分布式存储系统中,Raft等一致性算法它只能确保各个节点的日志一致性,也就是图中的流程二。
而对于流程三来说,server从日志里面获取已提交的日志条目,将其应用到状态机的过程,跟Raft算法本身无关,属于server本身的数据存储逻辑。
也就是说有可能存在server应用日志条目到状态机失败,进而导致各个节点出现数据不一致。但是这个不一致并非Raft模块导致的,它已超过Raft模块的功能界限。
比如在上面Node莫名其妙消失的案例中,就是应用日志条目到状态机流程中,出现逻辑错误,导致key-value数据未能持久化存储到boltdb。
这种逻辑错误即便重试也无法解决,目前社区也没有彻底的根治方案,只能根据具体案例进行针对性的修复。同时我给社区增加了Apply日志条目失败的警告日志。
其他典型不一致Bug
还有哪些场景可能还会导致Apply流程失败呢?我再以一个之前升级etcd 3.2集群到3.3集群时,遇到的数据不一致的故障事件为例给你讲讲。
这个故障对外的表现也是令人摸不着头脑,有服务不调度的、有service下的endpoint不更新的。最终我经过一番排查发现,原来数据不一致是由于etcd 3.2和3.3版本Lease模块的Revoke Lease行为不一致造成。
etcd 3.2版本的RevokeLease接口不需要鉴权,而etcd 3.3 RevokeLease接口增加了鉴权,因此当你升级etcd集群的时候,如果etcd 3.3版本收到了来自3.2版本的RevokeLease接口,就会导致因为没权限出现Apply失败,进而导致数据不一致,引发各种诡异现象。
除了重启etcd、升级etcd可能会导致数据不一致,defrag操作也可能会导致不一致。
对一个defrag碎片整理来说,它是如何触发数据不一致的呢? 触发的条件是defrag未正常结束时会生成db.tmp临时文件。这个文件可能包含部分上一次defrag写入的部分key/value数据,。而etcd下次defrag时并不会清理它,复用后就可能会出现各种异常场景,如重启后key增多、删除的用户数据key再次出现、删除user/role再次出现等。
etcd 3.2.29、etcd 3.3.19、etcd 3.4.4后的版本都已经修复这个Bug。我建议你根据自己实际情况进行升级,否则踩坑后,数据不一致的修复工作是非常棘手的,风险度极高。
从以上三个案例里,我们可以看到,算法一致性不代表一个庞大的分布式系统工程实现中一定能保障一致性,工程实现上充满着各种挑战,从不可靠的网络环境到时钟、再到人为错误、各模块间的复杂交互等,几乎没有一个存储系统能保证任意分支逻辑能被测试用例100%覆盖。
复制状态机在给我们带来数据同步的便利基础上,也给我们上层逻辑开发提出了高要求。也就是说任何接口逻辑变更etcd需要保证兼容性,否则就很容易出现Apply流程失败,导致数据不一致。
同时除了Apply流程可能导致数据不一致外,我们从defrag案例中也看到了一些维护变更操作,直接针对底层存储模块boltdb的,也可能会触发Bug,导致数据不一致。
最佳实践
在了解了etcd数据不一致的风险和原因后,我们在实践中有哪些方法可以提前发现和规避不一致问题呢?
下面我为你总结了几个最佳实践,它们分别是:
- 开启etcd的数据毁坏检测功能;
- 应用层的数据一致性检测;
- 定时数据备份;
- 良好的运维规范(比如使用较新稳定版本、确保版本一致性、灰度变更)。
开启etcd的数据毁坏检测功能
首先和你介绍下etcd的数据毁坏检测功能。etcd不仅支持在启动的时候,通过–experimental-initial-corrupt-check参数检查各个节点数据是否一致,也支持在运行过程通过指定–experimental-corrupt-check-time参数每隔一定时间检查数据一致性。
那么它的一致性检测原理是怎样的?如果出现不一致性,etcd会采取什么样动作去降低数据不一致影响面呢?
其实我们无非就是想确定boltdb文件里面的内容跟其他节点内容是否一致。因此我们可以枚举所有key value,然后比较即可。
etcd的实现也就是通过遍历treeIndex模块中的所有key获取到版本号,然后再根据版本号从boltdb里面获取key的value,使用crc32 hash算法,将bucket name、key、value组合起来计算它的hash值。
如果你开启了–experimental-initial-corrupt-check,启动的时候每个节点都会去获取peer节点的boltdb hash值,然后相互对比,如果不相等就会无法启动。
而定时检测是指Leader节点获取它当前最新的版本号,并通过Raft模块的ReadIndex机制确认Leader身份。当确认完成后,获取各个节点的revision和boltdb hash值,若出现Follower节点的revision大于Leader等异常情况时,就可以认为不一致,发送corrupt告警,触发集群corruption保护,拒绝读写。
从etcd上面的一致性检测方案我们可以了解到,目前采用的方案是比较简单、暴力的。因此可能随着数据规模增大,出现检测耗时增大等扩展性问题。而DynamoDB等使用了merkle tree来实现增量hash检测,这也是etcd未来可能优化的一个方向。
最后你需要特别注意的是,etcd数据毁坏检测的功能目前还是一个试验(experimental)特性,在比较新的版本才趋于稳定、成熟(推荐v3.4.9以上),预计在未来的etcd 3.5版本中才会变成稳定特性,因此etcd 3.2⁄3.3系列版本就不能使用此方案。
应用层的数据一致性检测
那要如何给etcd 3.2⁄3.3版本增加一致性检测呢? 其实除了etcd自带数据毁坏检测,我们还可以通过在应用层通过一系列方法来检测数据一致性,它们适用于etcd所有版本。
接下来我给你讲讲应用层检测的原理。
从上面我们对数据不一致性案例的分析中,我们知道数据不一致在MVCC、boltdb会出现很多种情况,比如说key数量不一致、etcd逻辑时钟版本号不一致、MVCC模块收到的put操作metrics指标值不一致等等。因此我们的应用层检测方法就是基于它们的差异进行巡检。
首先针对key数量不一致的情况,我们可以实现巡检功能,定时去统计各个节点的key数,这样可以快速地发现数据不一致,从而及时介入,控制数据不一致影响,降低风险。
在你统计节点key数时,记得查询的时候带上WithCountOnly参数。etcd从treeIndex模块获取到key数后就及时返回了,无需访问boltdb模块。如果你的数据量非常大(涉及到百万级别),那即便是从treeIndex模块返回也会有一定的内存开销,因为它会把key追加到一个数组里面返回。
而在WithCountOnly场景中,我们只需要统计key数即可。因此我给社区提了优化方案,目前已经合并到master分支。对百万级别的key来说,WithCountOnly时内存开销从数G到几乎零开销,性能也提升数十倍。
其次我们可以基于endpoint各个节点的revision信息做一致性监控。一般情况下,各个节点的差异是极小的。
最后我们还可以基于etcd MVCC的metrics指标来监控。比如上面提到的mvcc_put_total,理论上每个节点这些MVCC指标是一致的,不会出现偏离太多。
定时数据备份
etcd数据不一致的修复工作极其棘手。发生数据不一致后,各个节点可能都包含部分最新数据和脏数据。如果最终我们无法修复,那就只能使用备份数据来恢复了。
因此备份特别重要,备份可以保障我们在极端场景下,能有保底的机制去恢复业务。请记住,在做任何重要变更前一定先备份数据,以及在生产环境中建议增加定期的数据备份机制(比如每隔30分钟备份一次数据)。
你可以使用开源的etcd-operator中的backup-operator去实现定时数据备份,它可以将etcd快照保存在各个公有云的对象存储服务里面。
良好的运维规范
最后我给你介绍几个运维规范,这些规范可以帮助我们尽量少踩坑(即便你踩坑后也可以控制故障影响面)。
首先是确保集群中各节点etcd版本一致。若各个节点的版本不一致,因各版本逻辑存在差异性,这就会增大触发不一致Bug的概率。比如我们前面提到的升级版本触发的不一致Bug就属于此类问题。
其次是优先使用较新稳定版本的etcd。像上面我们提到的3个不一致Bug,在最新的etcd版本中都得到了修复。你可以根据自己情况进行升级,以避免下次踩坑。同时你可根据实际业务场景以及安全风险,来评估是否有必要开启鉴权,开启鉴权后涉及的逻辑更复杂,有可能增大触发数据不一致Bug的概率。
最后是你在升级etcd版本的时候,需要多查看change log,评估是否存在可能有不兼容的特性。在你升级集群的时候注意先在测试环境多验证,生产环境务必先灰度、再全量。
小结
最后,我来总结下我们今天的内容。
我从消失的Node案例为例,介绍了etcd中定位一个复杂不一致问题的思路和方法工具。核心就是根据我们对etcd读写原理的了解,对每个模块可能出现的问题进行大胆猜想。
同时我们要善于借助日志、metrics、etcd tool等进行验证排除。定位到最终模块问题后,如果很难复现,我们可以借助混沌工程等技术注入模拟各类故障。遇到复杂Bug时,请永远不要轻言放弃,它一定是一个让你快速成长的机会。
其次我介绍了etcd数据不一致的核心原因:Raft算法只能保证各个节点日志同步的一致性,但Apply流程是异步的,它从一致性模块获取日志命令,应用到状态机的准确性取决于业务逻辑,这块是没有机制保证的。
同时,defrag等运维管理操作,会直接修改底层存储数据,异常场景处理不严谨也会导致数据不一致。
数据不一致的风险是非常大的,轻则业务逻辑异常,重则核心数据丢失。我们需要机制去提前发现和规避它,因此最后我详细给你总结了etcd本身和应用层的一致性监控、定时备份数据、良好的运维规范等若干最佳实践,这些都是宝贵的实践总结,希望你能有所收获。
思考题
掌握好最佳实践、多了解几个已知Bug,能让你少交很多昂贵的学费,针对数据不一致问题,你是否还有更好的建议呢? 同时,你在使用etcd过程中是否还有其他令你记忆深刻的问题和Bug呢?
13 db大小:为什么etcd社区建议db大小不超过8G?
在03写流程中我和你分享了etcd Quota模块,那么etcd为什么需要对db增加Quota限制,以及不建议你的etcd集群db大小超过8G呢? 过大的db文件对集群性能和稳定性有哪些影响?
今天我要和你分享的主题就是关于db大小。我将通过一个大数据量的etcd集群为案例,为你剖析etcd db大小配额限制背后的设计思考和过大的db潜在隐患。
希望通过这节课,帮助你理解大数据量对集群的各个模块的影响,配置合理的db Quota值。同时,帮助你在实际业务场景中,遵循最佳实践,尽量减少value大小和大key-value更新频率,避免db文件大小不断增长。
分析整体思路
为了帮助你直观地理解大数据量对集群稳定性的影响,我首先将为你写入大量数据,构造一个db大小为14G的大集群。然后通过此集群为你分析db大小的各个影响面,db大小影响面如下图所示。
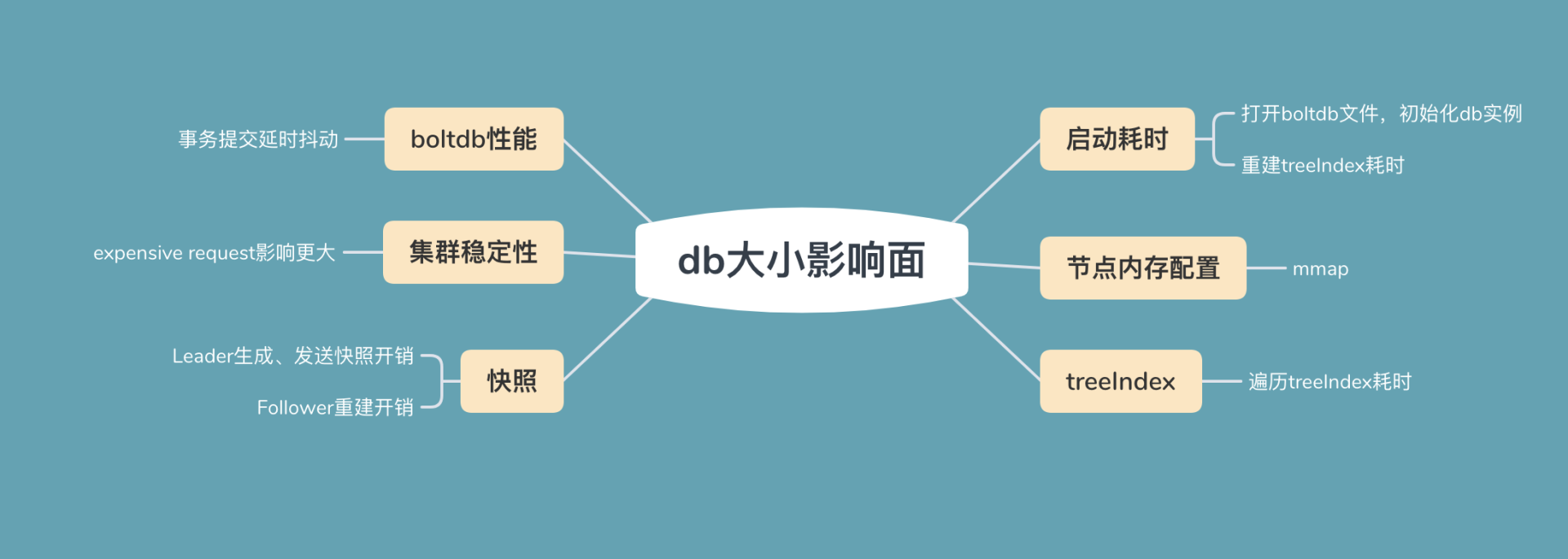
首先是启动耗时。etcd启动的时候,需打开boltdb db文件,读取db文件所有key-value数据,用于重建内存treeIndex模块。因此在大量key导致db文件过大的场景中,这会导致etcd启动较慢。
其次是节点内存配置。etcd在启动的时候会通过mmap将db文件映射内存中,若节点可用内存不足,小于db文件大小时,可能会出现缺页文件中断,导致服务稳定性、性能下降。
接着是treeIndex索引性能。因etcd不支持数据分片,内存中的treeIndex若保存了几十万到上千万的key,这会增加查询、修改操作的整体延时。
然后是boltdb性能。大db文件场景会导致事务提交耗时增长、抖动。
再次是集群稳定性。大db文件场景下,无论你是百万级别小key还是上千个大value场景,一旦出现expensive request后,很容易导致etcd OOM、节点带宽满而丢包。
最后是**快照。**当Follower节点落后Leader较多数据的时候,会触发Leader生成快照重建发送给Follower节点,Follower基于它进行还原重建操作。较大的db文件会导致Leader发送快照需要消耗较多的CPU、网络带宽资源,同时Follower节点重建还原慢。
构造大集群
简单介绍完db大小的六个影响面后,我们下面来构造一个大数据量的集群,用于后续各个影响面的分析。
首先,我通过一系列如下benchmark命令,向一个8核32G的3节点的集群写入120万左右key。key大小为32,value大小为256到10K,用以分析大db集群案例中的各个影响面。
./benchmark put --key-size 32 --val-size 10240 --total
1000000 --key-space-size 2000000 --clients 50 --conns 50
执行完一系列benchmark命令后,db size达到14G,总key数达到120万,其监控如下图所示:
启动耗时
在如上的集群中,我通过benchmark工具将etcd集群db大小压测到14G后,在重新启动etcd进程的时候,如下日志所示,你会发现启动比较慢,为什么大db文件会影响etcd启动耗时呢?
2021-02-15 02:25:55.273712 I | etcdmain: etcd Version: 3.4.9
2021-02-15 02:26:58.806882 I | etcdserver: recovered store from snapshot at index 2100090
2021-02-15 02:26:58.808810 I | mvcc: restore compact to 1000002
2021-02-15 02:27:19.120141 W | etcdserver: backend quota 26442450944 exceeds maximum recommended quota 8589934592
2021-02-15 02:27:19.297363 I | embed: ready to serve client requests
通过对etcd启动流程增加耗时统计,我们可以发现核心瓶颈主要在于打开db文件和重建内存treeIndex模块。
这里我重点先和你介绍下etcd启动后,重建内存treeIndex的原理。
我们知道treeIndex模块维护了用户key与boltdb key的映射关系,boltdb的key、value又包含了构建treeIndex的所需的数据。因此etcd启动的时候,会启动不同角色的goroutine并发完成treeIndex构建。
**首先是主goroutine。**它的职责是遍历boltdb,获取所有key-value数据,并将其反序列化成etcd的mvccpb.KeyValue结构。核心原理是基于etcd存储在boltdb中的key数据有序性,按版本号从1开始批量遍历,每次查询10000条key-value记录,直到查询数据为空。
**其次是构建treeIndex索引的goroutine。**它从主goroutine获取mvccpb.KeyValue数据,基于key、版本号、是否带删除标识等信息,构建keyIndex对象,插入到treeIndex模块的B-tree中。
因可能存在多个goroutine并发操作treeIndex,treeIndex的Insert函数会加全局锁,如下所示。etcd启动时只有一个构建treeIndex索引的goroutine,因此key多时,会比较慢。之前我尝试优化成多goroutine并发构建,但是效果不佳,大量耗时会消耗在此锁上。
func (ti *treeIndex) Insert(ki *keyIndex) {ti.Lock()defer ti.Unlock()ti.tree.ReplaceOrInsert(ki)
}
节点内存配置
etcd进程重启完成后,在没任何读写QPS情况下,如下所示,你会发现etcd所消耗的内存比db大小还大一点。这又是为什么呢?如果etcd db文件大小超过节点内存规格,会导致什么问题吗?
在10介绍boltdb存储原理的时候,我和你分享过boltdb文件的磁盘布局结构和其对外提供的API原理。
etcd在启动的时候,会通过boltdb的Open API获取数据库对象,而Open API它会通过mmap机制将db文件映射到内存中。
由于etcd调用boltdb Open API的时候,设置了mmap的MAP_POPULATE flag,它会告诉Linux内核预读文件,将db文件内容全部从磁盘加载到物理内存中。
因此在你节点内存充足的情况下,启动后你看到的etcd占用内存,一般是db文件大小与内存treeIndex之和。
在节点内存充足的情况下,启动后,client后续发起对etcd的读操作,可直接通过内存获取boltdb的key-value数据,不会产生任何磁盘IO,具备良好的读性能、稳定性。
而当你的db文件大小超过节点内存配置时,若你查询的key所相关的branch page、leaf page不在内存中,那就会触发主缺页中断,导致读延时抖动、QPS下降。
因此为了保证etcd集群性能的稳定性,我建议你的etcd节点内存规格要大于你的etcd db文件大小。
treeIndex
当我们往集群中写入了一百多万key时,此时你再读取一个key范围操作的延时会出现一定程度上升,这是为什么呢?我们该如何分析耗时是在哪一步导致的?
在etcd 3.4中提供了trace特性,它可帮助我们定位、分析请求耗时过长问题。不过你需要特别注意的是,此特性在etcd 3.4中,因为依赖zap logger,默认为关闭。你可以通过设置etcd启动参数中的–logger=zap来开启。
开启之后,我们可以在etcd日志中找到类似如下的耗时记录。
{
"msg":"trace[331581563] range",
"detail":"{range_begin:/vip/a; range_end:/vip/b; response_count:19304; response_revision:1005564; }",
"duration":"146.432768ms",
"steps":[
"trace[331581563] 'range keys from in-memory treeIndex' (duration: 95.925033ms)",
"trace[331581563] 'range keys from bolt db' (duration: 47.932118ms)"
]
此日志记录了查询请求”etcdctl get –prefix /vip/a”。它在treeIndex中查询相关key耗时95ms,从boltdb遍历key时47ms。主要原因还是此查询涉及的key数较多,高达一万九。
也就是说若treeIndex中存储了百万级的key时,它可能也会产生几十毫秒到数百毫秒的延时,对于期望业务延时稳定在较小阈值内的业务,就无法满足其诉求。
boltdb性能
当db文件大小持续增长到16G乃至更大后,从etcd事务提交监控metrics你可能会观察到,boltdb在提交事务时偶尔出现了较高延时,那么延时是怎么产生的呢?
在10介绍boltdb的原理时,我和你分享了db文件的磁盘布局,它是由meta page、branch page、leaf page、free list、free页组成的。同时我给你介绍了boltdb事务提交的四个核心流程,分别是B+ tree的重平衡、分裂,持久化dirty page,持久化freelist以及持久化meta data。
事务提交延时抖动的原因主要是在B+ tree树的重平衡和分裂过程中,它需要从freelist中申请若干连续的page存储数据,或释放空闲的page到freelist。
freelist后端实现在boltdb中是array。当申请一个连续的n个page存储数据时,它会遍历boltdb中所有的空闲页,直到找到连续的n个page。因此它的时间复杂度是O(N)。若db文件较大,又存在大量的碎片空闲页,很可能导致超时。
同时事务提交过程中,也可能会释放若干个page给freelist,因此需要合并到freelist的数组中,此操作时间复杂度是O(NLog N)。
假设我们db大小16G,page size 4KB,则有400万个page。经过各种修改、压缩后,若存在一半零散分布的碎片空闲页,在最坏的场景下,etcd每次事务提交需要遍历200万个page才能找到连续的n个page,同时还需要持久化freelist到磁盘。
为了优化boltdb事务提交的性能,etcd社区在bbolt项目中,实现了基于hashmap来管理freelist。通过引入了如下的三个map数据结构(freemaps的key是连续的页数,value是以空闲页的起始页pgid集合,forwardmap和backmap用于释放的时候快速合并页),将申请和释放时间复杂度降低到了O(1)。
freelist后端实现可以通过bbolt的FreeListType参数来控制,支持array和hashmap。在etcd 3.4版本中目前还是array,未来的3.5版本将默认是hashmap。
freemaps map[uint64]pidSet // key is the size of continuous pages(span),value is a set which contains the starting pgids of same size
forwardMap map[pgid]uint64 // key is start pgid,value is its span size
backwardMap map[pgid]uint64 // key is end pgid,value is its span size
另外在db中若存在大量空闲页,持久化freelist需要消耗较多的db大小,并会导致额外的事务提交延时。
若未持久化freelist,bbolt支持通过重启时扫描全部page来构造freelist,降低了db大小和提升写事务提交的性能(但是它会带来etcd启动延时的上升)。此行为可以通过bbolt的NoFreelistSync参数来控制,默认是true启用此特性。
集群稳定性
db文件增大后,另外一个非常大的隐患是用户client发起的expensive request,容易导致集群出现各种稳定性问题。
本质原因是etcd不支持数据分片,各个节点保存了所有key-value数据,同时它们又存储在boltdb的一个bucket里面。当你的集群含有百万级以上key的时候,任意一种expensive read请求都可能导致etcd出现OOM、丢包等情况发生。
那么有哪些expensive read请求会导致etcd不稳定性呢?
**首先是简单的count only查询。**如下图所示,当你想通过API统计一个集群有多少key时,如果你的key较多,则有可能导致内存突增和较大的延时。
在etcd 3.5版本之前,统计key数会遍历treeIndex,把key追加到数组中。然而当数据规模较大时,追加key到数组中的操作会消耗大量内存,同时数组扩容时涉及到大量数据拷贝,会导致延时上升。
**其次是limit查询。**当你只想查询若干条数据的时候,若你的key较多,也会导致类似count only查询的性能、稳定性问题。
原因是etcd 3.5版本之前遍历index B-tree时,并未将limit参数下推到索引层,导致了无用的资源和时间消耗。优化方案也很简单,etcd 3.5中我提的优化PR将limit参数下推到了索引层,实现查询性能百倍提升。
**最后是大包查询。**当你未分页批量遍历key-value数据或单key-value数据较大的时候,随着请求QPS增大,etcd OOM、节点出现带宽瓶颈导致丢包的风险会越来越大。
问题主要由以下两点原因导致:
第一,etcd需要遍历treeIndex获取key列表。若你未分页,一次查询万级key,显然会消耗大量内存并且高延时。
第二,获取到key列表、版本号后,etcd需要遍历boltdb,将key-value保存到查询结果数据结构中。如下trace日志所示,一个请求可能在遍历boltdb时花费很长时间,同时可能会消耗几百M甚至数G的内存。随着请求QPS增大,极易出现OOM、丢包等。etcd这块未来的优化点是实现流式传输。
{
"level":"info",
"ts":"2021-02-15T03:44:52.209Z",
"caller":"traceutil/trace.go:145",
"msg":"trace[1908866301] range",
"detail":"{range_begin:; range_end:; response_count:1232274; response_revision:3128500; }",
"duration":"9.063748801s",
"start":"2021-02-15T03:44:43.145Z",
"end":"2021-02-15T03:44:52.209Z",
"steps":[
"trace[1908866301] 'range keys from in-memory index tree' (duration: 693.262565ms)",
"trace[1908866301] 'range keys from bolt db' (duration: 8.22558566s)",
"trace[1908866301] 'assemble the response' (duration: 18.810315ms)"
]
}
快照
大db文件最后一个影响面是快照。它会影响db备份文件生成速度、Leader发送快照给Follower节点的资源开销、Follower节点通过快照重建恢复的速度。
我们知道etcd提供了快照功能,帮助我们通过API即可备份etcd数据。当etcd收到snapshot请求的时候,它会通过boltdb接口创建一个只读事务Tx,随后通过事务的WriteTo接口,将meta page和data page拷贝到buffer即可。
但是随着db文件增大,快照事务执行的时间也会越来越长,而长事务则会导致db文件大小发生显著增加。
也就是说当db大时,生成快照不仅慢,生成快照时可能还会触发db文件大小持续增长,最终达到配额限制。
为什么长事务可能会导致db大小增长呢? 这个问题我先将它作为思考题,你可以分享一下你的想法,后续我将为你详细解答。
快照的另一大作用是当Follower节点异常的时候,Leader生成快照发送给Follower节点,Follower使用快照重建并追赶上Leader。此过程涉及到一定的CPU、内存、网络带宽等资源开销。
同时,若快照和集群写QPS较大,Leader发送快照给Follower和Follower应用快照到状态机的流程会耗费较长的时间,这可能会导致基于快照重建后的Follower依然无法通过正常的日志复制模式来追赶Leader,只能继续触发Leader生成快照,进而进入死循环,Follower一直处于异常中。
小结
最后我们来小结下今天的内容。大db文件首先会影响etcd启动耗时,因为etcd需要打开db文件,初始化db对象,并遍历boltdb中的所有key-value以重建内存treeIndex。
其次,较大db文件会导致etcd依赖更高配置的节点内存规格,etcd通过mmap将db文件映射到内存中。etcd启动后,正常情况下读etcd过程不涉及磁盘IO,若节点内存不够,可能会导致缺页中断,引起延时抖动、服务性能下降。
接着treeIndex维护了所有key的版本号信息,当treeIndex中含有百万级key时,在treeIndex中搜索指定范围的key的开销是不能忽略的,此开销可能高达上百毫秒。
然后当db文件过大后,boltdb本身连续空闲页的申请、释放、存储都会存在一定的开销。etcd社区已通过新的freelist管理数据结构hashmap对其进行优化,将时间复杂度降低到了O(1),同时支持事务提交时不持久化freelist,而是通过重启时扫描page重建,以提升etcd写性能、降低db大小。
随后我给你介绍了db文件过大后,count only、limit、大包查询等expensive request对集群稳定性的影响。建议你的业务尽量避免任何expensive request请求。
最后我们介绍了大db文件对快照功能的影响。大db文件意味着更长的备份时间,而更长的只读事务则可能会导致db文件增长。同时Leader发送快照与Follower基于快照重建都需要较长时间,在集群写请求较大的情况下,可能会陷入死循环,导致落后的Follower节点一直无法追赶上Leader。
思考题
在使用etcd过程中,你遇到了哪些案例导致了etcd db大小突增呢? 它们的本质原因是什么呢?
14 延时:为什么你的etcd请求会出现超时?
在使用etcd的过程中,你是否被日志中的”apply request took too long”和“etcdserver: request timed out”等高延时现象困扰过?它们是由什么原因导致的呢?我们应该如何来分析这些问题?
这就是我今天要和你分享的主题:etcd延时。希望通过这节课,帮助你掌握etcd延时抖动、超时背后的常见原因和分析方法,当你遇到类似问题时,能独立定位、解决。同时,帮助你在实际业务场景中,合理配置集群,遵循最佳实践,尽量减少expensive request,避免etcd请求出现超时。
分析思路及工具
首先,当我们面对一个高延时的请求案例后,如何梳理问题定位思路呢?
知彼知己,方能百战不殆,定位问题也是类似。首先我们得弄清楚产生问题的原理、流程,在02、03、04中我已为你介绍过读写请求的核心链路。其次是熟练掌握相关工具,借助它们,可以帮助我们快速攻破疑难杂症。
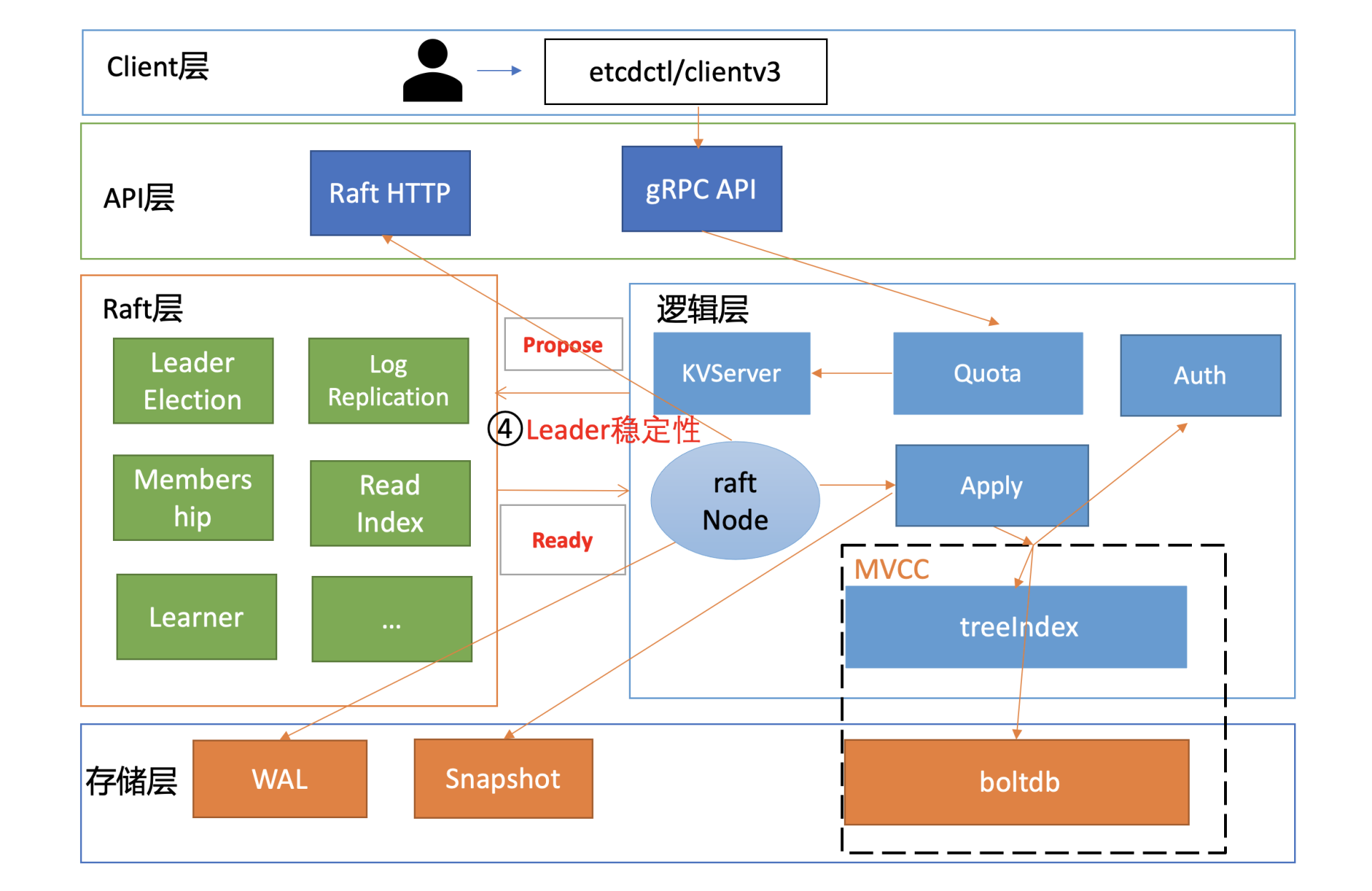
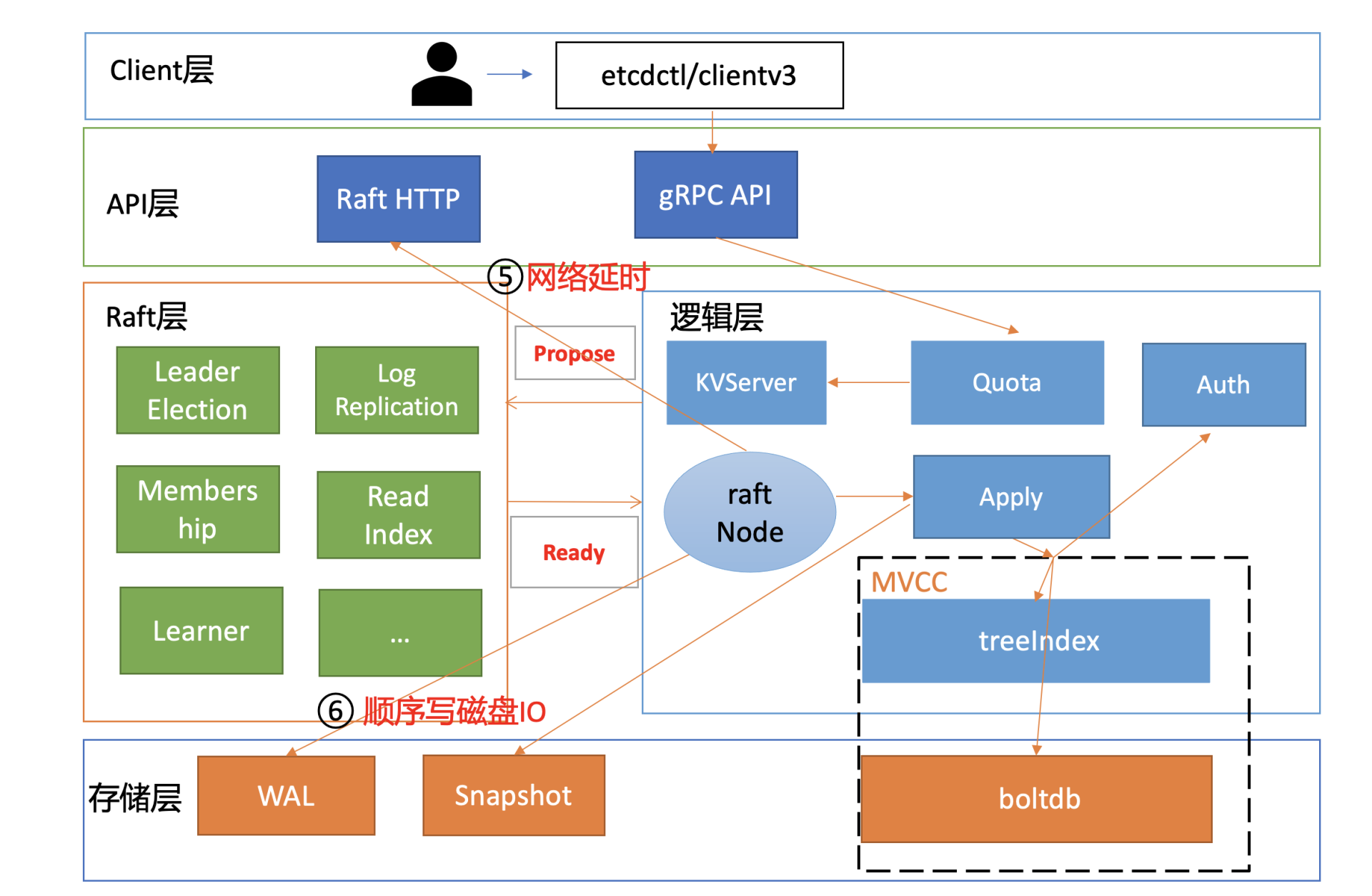
这里我们再回顾下03中介绍的,Leader收到一个写请求,将一个日志条目复制到集群多数节点并应用到存储状态机的流程(如下图所示),通过此图我们看看写流程上哪些地方可能会导致请求超时呢?
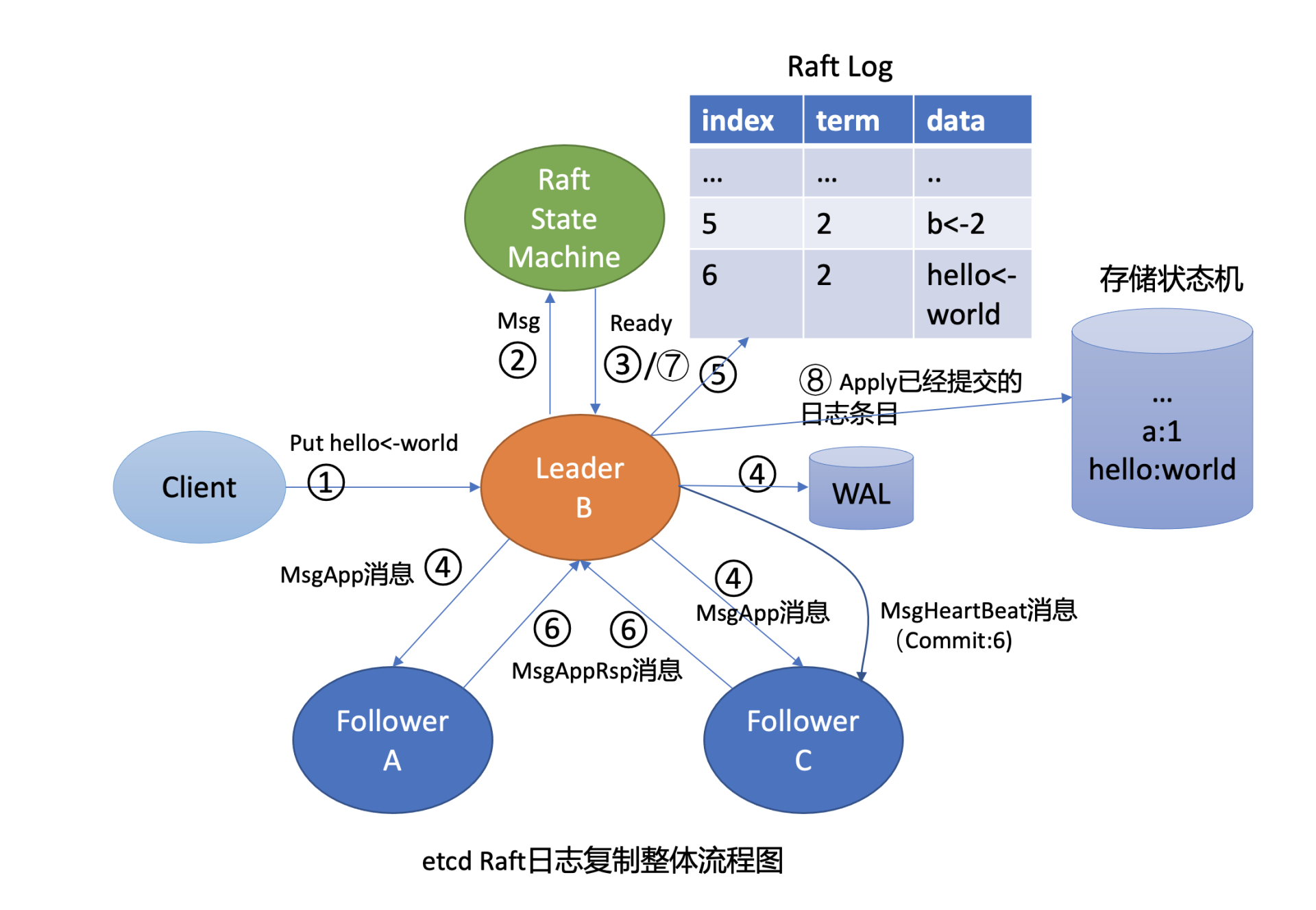
首先是流程四,一方面,Leader需要并行将消息通过网络发送给各Follower节点,依赖网络性能。另一方面,Leader需持久化日志条目到WAL,依赖磁盘I/O顺序写入性能。
其次是流程八,应用日志条目到存储状态机时,etcd后端key-value存储引擎是boltdb。正如我们10所介绍的,它是一个基于B+ tree实现的存储引擎,当你写入数据,提交事务时,它会将dirty page持久化到磁盘中。在这过程中boltdb会产生磁盘随机I/O写入,因此事务提交性能依赖磁盘I/O随机写入性能。
最后,在整个写流程处理过程中,etcd节点的CPU、内存、网络带宽资源应充足,否则肯定也会影响性能。
初步了解完可能导致延时抖动的瓶颈处之后,我给你总结了etcd问题定位过程中常用的工具,你可以参考下面这幅图。
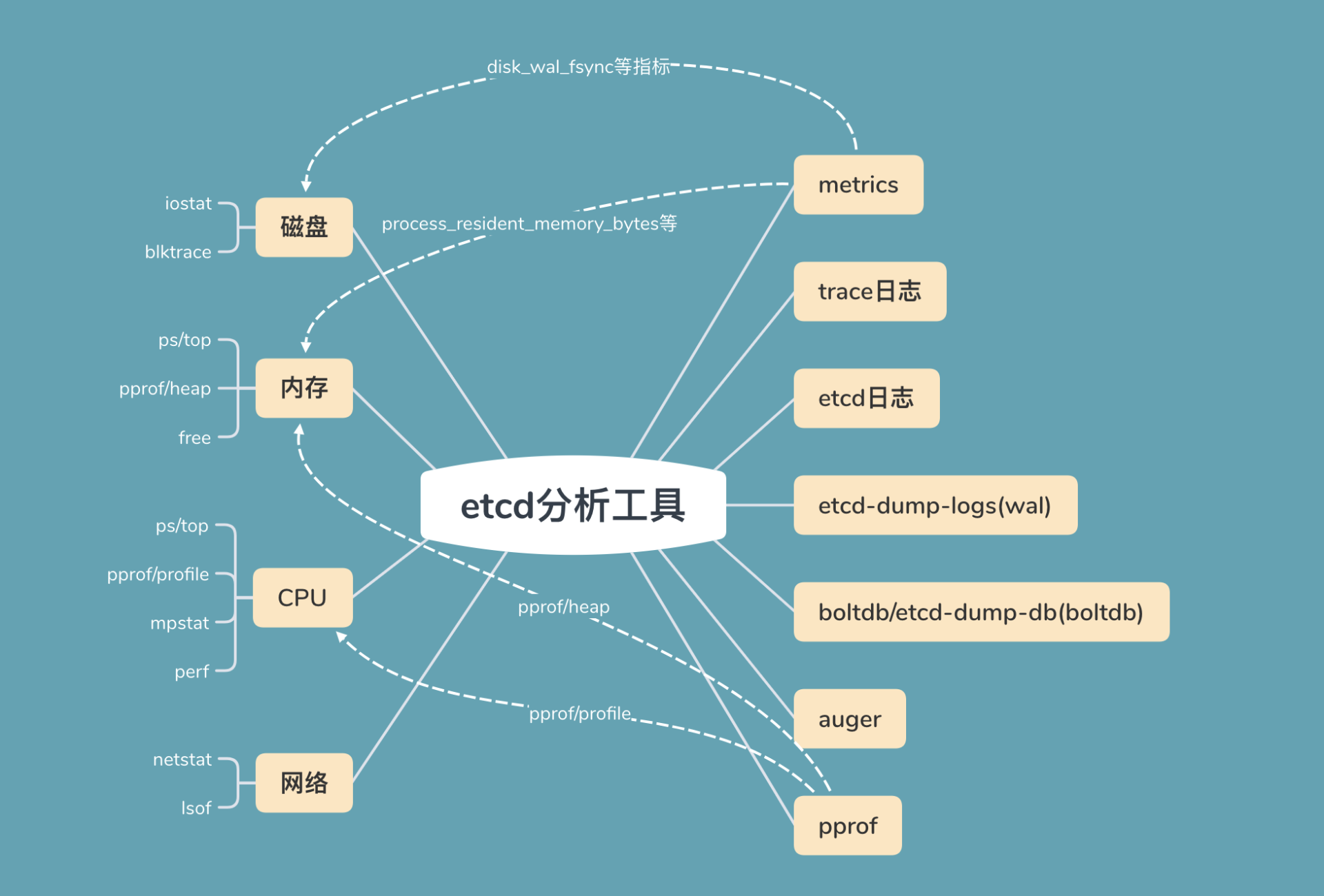
图的左边是读写请求链路中可能出现瓶颈或异常的点,比如上面流程分析中提到的磁盘、内存、CPU、网络资源。
图的右边是常用的工具,分别是metrics、trace日志、etcd其他日志、WAL及boltdb分析工具等。
接下来,我基于读写请求的核心链路和其可能出现的瓶颈点,结合相关的工具,为你深入分析etcd延时抖动的定位方法和原因。
网络
首先我们来看看流程图中第一个提到可能瓶颈点,网络模块。
在etcd中,各个节点之间需要通过2380端口相互通信,以完成Leader选举、日志同步等功能,因此底层网络质量(吞吐量、延时、稳定性)对上层etcd服务的性能有显著影响。
网络资源出现异常的常见表现是连接闪断、延时抖动、丢包等。那么我们要如何定位网络异常导致的延时抖动呢?
一方面,我们可以使用常规的ping/traceroute/mtr、ethtool、ifconfig/ip、netstat、tcpdump网络分析工具等命令,测试网络的连通性、延时,查看网卡的速率是否存在丢包等错误,确认etcd进程的连接状态及数量是否合理,抓取etcd报文分析等。
另一方面,etcd应用层提供了节点之间网络统计的metrics指标,分别如下:
- etcd_network_active_peer,表示peer之间活跃的连接数;
- etcd_network_peer_round_trip_time_seconds,表示peer之间RTT延时;
- etcd_network_peer_sent_failures_total,表示发送给peer的失败消息数;
- etcd_network_client_grpc_sent_bytes_total,表示server发送给client的总字节数,通过这个指标我们可以监控etcd出流量;
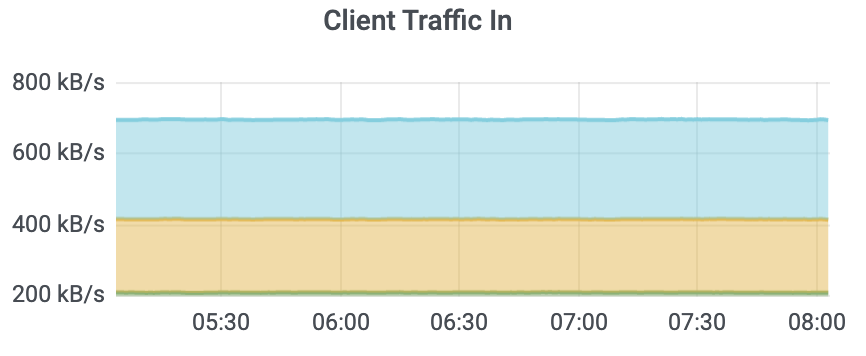
- etcd_network_client_grpc_received_bytes_total,表示server收到client发送的总字节数,通过这个指标可以监控etcd入流量。
client入流量监控如下图所示:
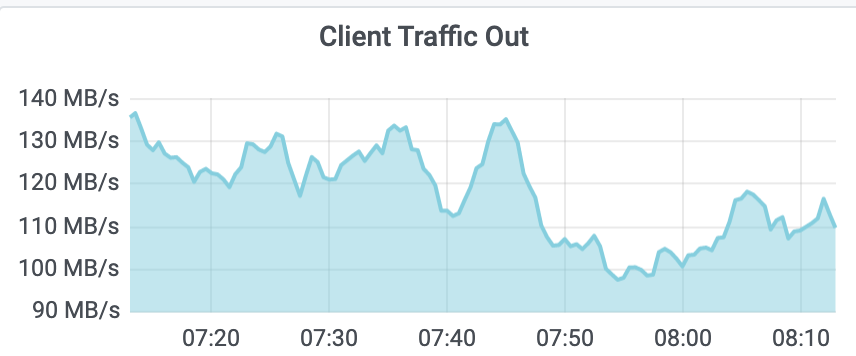
client出流量如下图监控所示。 从图中你可以看到,峰值接近140MB/s(1.12Gbps),这是非常不合理的,说明业务中肯定有大量expensive read request操作。若etcd集群读写请求开始出现超时,你可以用ifconfig等命令查看是否出现丢包等错误。
etcd metrics指标名由namespace和subsystem、name组成。namespace为etcd, subsystem是模块名(比如network、name具体的指标名)。你可以在Prometheus里搜索etcd_network找到所有network相关的metrics指标名。
下面是一个集群中某节点异常后的metrics指标:
etcd_network_active_peers{Local="fd422379fda50e48",Remote="8211f1d0f64f3269"} 1
etcd_network_active_peers{Local="fd422379fda50e48",Remote="91bc3c398fb3c146"} 0
etcd_network_peer_sent_failures_total{To="91bc3c398fb3c146"} 47774
etcd_network_client_grpc_sent_bytes_total 513207
从以上metrics中,你可以看到91bc3c398fb3c146节点出现了异常。在etcd场景中,网络质量导致etcd性能下降主要源自两个方面:
一方面,expensive request中的大包查询会使网卡出现瓶颈,产生丢包等错误,从而导致etcd吞吐量下降、高延时。expensive request导致网卡丢包,出现超时,这在etcd中是非常典型且易发生的问题,它主要是因为业务没有遵循最佳实践,查询了大量key-value。
另一方面,在跨故障域部署的时候,故障域可能是可用区、城市。故障域越大,容灾级别越高,但各个节点之间的RTT越高,请求的延时更高。
磁盘I/O
了解完网络问题的定位方法和导致网络性能下降的因素后,我们再看看最核心的磁盘I/O。
正如我在开头的Raft日志复制整体流程图中和你介绍的,在etcd中无论是Raft日志持久化还是boltdb事务提交,都依赖于磁盘I/O的性能。
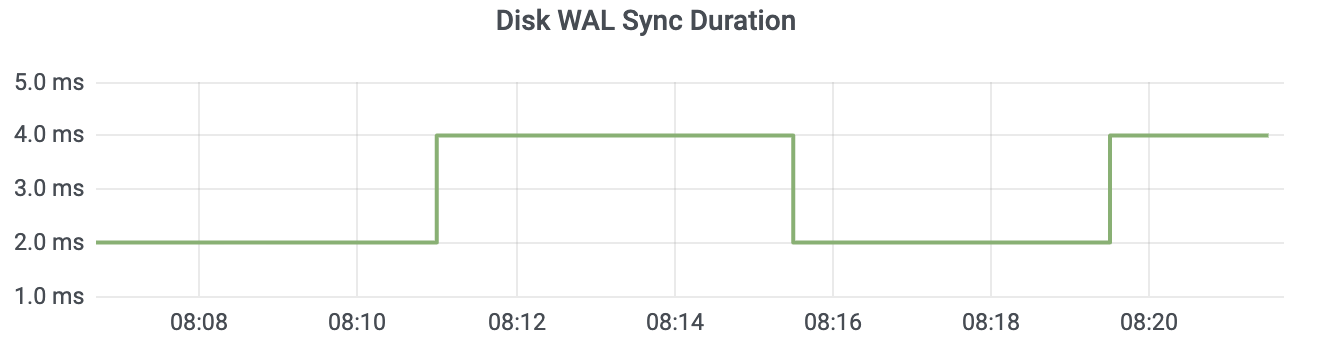
**当etcd请求延时出现波动时,我们往往首先关注disk相关指标是否正常。**我们可以通过etcd磁盘相关的metrics(etcd_disk_wal_fsync_duration_seconds和etcd_disk_backend_commit_duration_seconds)来观测应用层数据写入磁盘的性能。
etcd_disk_wal_fsync_duration_seconds(简称disk_wal_fsync)表示WAL日志持久化的fsync系统调用延时数据。一般本地SSD盘P99延时在10ms内,如下图所示。
etcd_disk_backend_commit_duration_seconds(简称disk_backend_commit)表示后端boltdb事务提交的延时,一般P99在120ms内。
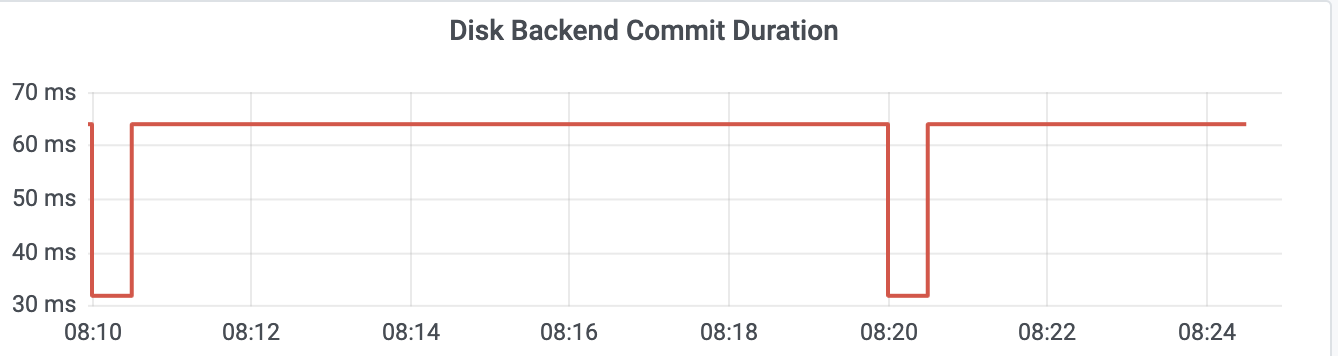
这里你需要注意的是,一般监控显示的磁盘延时都是P99,但实际上etcd对磁盘特别敏感,一次磁盘I/O波动就可能产生Leader切换。如果你遇到集群Leader出现切换、请求超时,但是磁盘指标监控显示正常,你可以查看P100确认下是不是由于磁盘I/O波动导致的。
同时etcd的WAL模块在fdatasync操作超过1秒时,也会在etcd中打印如下的日志,你可以结合日志进一步定位。
if took > warnSyncDuration {if w.lg != nil {w.lg.Warn("slow fdatasync",zap.Duration("took", took),zap.Duration("expected-duration", warnSyncDuration),)} else {plog.Warningf("sync duration of %v, expected less than %v", took, warnSyncDuration)}
}
当disk_wal_fsync指标异常的时候,一般是底层硬件出现瓶颈或异常导致。当然也有可能是CPU高负载、cgroup blkio限制导致的,我们具体应该如何区分呢?
你可以通过iostat、blktrace工具分析瓶颈是在应用层还是内核层、硬件层。其中blktrace是blkio层的磁盘I/O分析利器,它可记录IO进入通用块层、IO请求生成插入请求队列、IO请求分发到设备驱动、设备驱动处理完成这一系列操作的时间,帮助你发现磁盘I/O瓶颈发生的阶段。
当disk_backend_commit指标的异常时候,说明事务提交过程中的B+ tree树重平衡、分裂、持久化dirty page、持久化meta page等操作耗费了大量时间。
disk_backend_commit指标异常,能说明是磁盘I/O发生了异常吗?
若disk_backend_commit较高、disk_wal_fsync却正常,说明瓶颈可能并非来自磁盘I/O性能,也许是B+ tree的重平衡、分裂过程中的较高时间复杂度逻辑操作导致。比如etcd目前所有stable版本(etcd 3.2到3.4),从freelist中申请和回收若干连续空闲页的时间复杂度是O(N),当db文件较大、空闲页碎片化分布的时候,则可能导致事务提交高延时。
那如何区分事务提交过程中各个阶段的耗时呢?
etcd还提供了disk_backend_commit_rebalance_duration和
disk_backend_commit_spill_duration两个metrics,分别表示事务提交过程中B+ tree的重平衡和分裂操作耗时分布区间。
最后,你需要注意disk_wal_fsync记录的是WAL文件顺序写入的持久化时间,disk_backend_commit记录的是整个事务提交的耗时。后者涉及的磁盘I/O是随机的,为了保证你etcd集群的稳定性,建议使用SSD磁盘以确保事务提交的稳定性。
expensive request
若磁盘和网络指标都很正常,那么延时高还有可能是什么原因引起的呢?
从02介绍的读请求链路我们可知,一个读写请求经过Raft模块处理后,最终会走到MVCC模块。那么在MVCC模块会有哪些场景导致延时抖动呢?时间耗在哪个处理流程上了?
etcd 3.4版本之前,在应用put/txn等请求到状态机的apply和处理读请求range流程时,若一个请求执行超过100ms时,默认会在etcd log中打印一条”apply request took too long”的警告日志。通过此日志我们可以知道集群中apply流程产生了较慢的请求,但是不能确定具体是什么因素导致的。
比如在Kubernetes中,当集群Pod较多的时候,若你频繁执行List Pod,可能会导致etcd出现大量的”apply request took too long”警告日志。
因为对etcd而言,List Pod请求涉及到大量的key查询,会消耗较多的CPU、内存、网络资源,此类expensive request的QPS若较大,则很可能导致OOM、丢包。
当然,除了业务发起的expensive request请求导致延时抖动以外,也有可能是etcd本身的设计实现存在瓶颈。
比如在etcd 3.2和3.3版本写请求完成之前,需要更新MVCC的buffer,进行升级锁操作。然而此时若集群中出现了一个long expensive read request,则会导致写请求执行延时抖动。因为expensive read request事务会一直持有MVCC的buffer读锁,导致写请求事务阻塞在升级锁操作中。
在了解完expensive request对请求延时的影响后,接下来要如何解决请求延时较高问题的定位效率呢?
为了提高请求延时分布的可观测性、延时问题的定位效率,etcd社区在3.4版本后中实现了trace特性,详细记录了一个请求在各个阶段的耗时。若某阶段耗时流程超过默认的100ms,则会打印一条trace日志。
下面是我将trace日志打印的阈值改成1纳秒后读请求执行过程中的trace日志。从日志中你可以看到,trace日志记录了以下阶段耗时:
- agreement among raft nodes before linearized reading,此阶段读请求向Leader发起readIndex查询并等待本地applied index >= Leader的committed index, 但是你无法区分是readIndex慢还是等待本地applied index > Leader的committed index慢。在etcd 3.5中新增了trace,区分了以上阶段;
- get authentication metadata,获取鉴权元数据;
- range keys from in-memory index tree,从内存索引B-tree中查找key列表对应的版本号列表;
- range keys from bolt db,根据版本号列表从boltdb遍历,获得用户的key-value信息;
- filter and sort the key-value pairs,过滤、排序key-value列表;
- assemble the response,聚合结果。
{"level":"info","ts":"2020-12-16T08:11:43.720+0800","caller":"traceutil/trace.go:145","msg":"trace[789864563] range","detail":"{range_begin:a; range_end:; response_count:1; response_revision:32011; }","duration":"318.774µs","start":"2020-12-16T08:11:43.719+0800","end":"2020-12-16T08:11:43.720+0800","steps":["trace[789864563] 'agreement among raft nodes before linearized reading' (duration: 255.227µs)","trace[789864563] 'get authentication metadata' (duration: 2.97µs)","trace[789864563] 'range keys from in-memory index tree' (duration: 44.578µs)","trace[789864563] 'range keys from bolt db' (duration: 8.688µs)","trace[789864563] 'filter and sort the key-value pairs' (duration: 578ns)","trace[789864563] 'assemble the response' (duration: 643ns)"]
}
那么写请求流程会记录哪些阶段耗时呢?
下面是put写请求的执行trace日志,记录了以下阶段耗时:
- process raft request,写请求提交到Raft模块处理完成耗时;
- get key’s previous created_revision and leaseID,获取key上一个创建版本号及leaseID的耗时;
- marshal mvccpb.KeyValue,序列化KeyValue结构体耗时;
- store kv pair into bolt db,存储kv数据到boltdb的耗时;
- attach lease to kv pair,将lease id关联到kv上所用时间。
{"level":"info","ts":"2020-12-16T08:25:12.707+0800","caller":"traceutil/trace.go:145","msg":"trace[1402827146] put","detail":"{key:16; req_size:8; response_revision:32030; }","duration":"6.826438ms","start":"2020-12-16T08:25:12.700+0800","end":"2020-12-16T08:25:12.707+0800","steps":["trace[1402827146] 'process raft request' (duration: 6.659094ms)","trace[1402827146] 'get key's previous created_revision and leaseID' (duration: 23.498µs)","trace[1402827146] 'marshal mvccpb.KeyValue' (duration: 1.857µs)","trace[1402827146] 'store kv pair into bolt db' (duration: 30.121µs)","trace[1402827146] 'attach lease to kv pair' (duration: 661ns)"]
}
通过以上介绍的trace特性,你就可以快速定位到高延时读写请求的原因。比如当你向etcd发起了一个涉及到大量key或value较大的expensive request请求的时候,它会产生如下的warn和trace日志。
从以下日志中我们可以看到,此请求查询的vip前缀下所有的kv数据总共是250条,但是涉及的数据包大小有250MB,总耗时约1.85秒,其中从boltdb遍历key消耗了1.63秒。
{"level":"warn","ts":"2020-12-16T23:02:53.324+0800","caller":"etcdserver/util.go:163","msg":"apply request took too long","took":"1.84796759s","expected-duration":"100ms","prefix":"read-only range ","request":"key:"vip" range_end:"viq" ","response":"range_response_count:250 size:262150651"
}
{"level":"info","ts":"2020-12-16T23:02:53.324+0800","caller":"traceutil/trace.go:145","msg":"trace[370341530] range","detail":"{range_begin:vip; range_end:viq; response_count:250; response_revision:32666; }","duration":"1.850335038s","start":"2020-12-16T23:02:51.473+0800","end":"2020-12-16T23:02:53.324+0800","steps":["trace[370341530] 'range keys from bolt db' (duration: 1.632336981s)"]
}
最后,有两个注意事项。
第一,在etcd 3.4中,logger默认为capnslog,trace特性只有在当logger为zap时才开启,因此你需要设置–logger=zap。
第二,trace特性并不能记录所有类型的请求,它目前只覆盖了MVCC模块中的range/put/txn等常用接口。像Authenticate鉴权请求,涉及到大量CPU计算,延时是非常高的,在trace日志中目前没有相关记录。
如果你开启了密码鉴权,在连接数增多、QPS增大后,若突然出现请求超时,如何确定是鉴权还是查询、更新等接口导致的呢?
etcd默认参数并不会采集各个接口的延时数据,我们可以通过设置etcd的启动参数–metrics为extensive来开启,获得每个gRPC接口的延时数据。同时可结合各个gRPC接口的请求数,获得QPS。
如下是某节点的metrics数据,251个Put请求,返回码OK,其中有240个请求在100毫秒内完成。
grpc_server_handled_total{grpc_code="OK",
grpc_method="Put",grpc_service="etcdserverpb.KV",
grpc_type="unary"} 251grpc_server_handling_seconds_bucket{grpc_method="Put",grpc_service="etcdserverpb.KV",grpc_type="unary",le="0.005"} 0
grpc_server_handling_seconds_bucket{grpc_method="Put",grpc_service="etcdserverpb.KV",grpc_type="unary",le="0.01"} 1
grpc_server_handling_seconds_bucket{grpc_method="Put",grpc_service="etcdserverpb.KV",grpc_type="unary",le="0.025"} 51
grpc_server_handling_seconds_bucket{grpc_method="Put",grpc_service="etcdserverpb.KV",grpc_type="unary",le="0.05"} 204
grpc_server_handling_seconds_bucket{grpc_method="Put",grpc_service="etcdserverpb.KV",grpc_type="unary",le="0.1"} 240
集群容量、节点CPU/Memory瓶颈
介绍完网络、磁盘I/O、expensive request导致etcd请求延时较高的原因和分析方法后,我们再看看容量和节点资源瓶颈是如何导致高延时请求产生的。
若网络、磁盘I/O正常,也无expensive request,那此时高延时请求是怎么产生的呢?它的trace日志会输出怎样的耗时结果?
下面是一个社区用户反馈的一个读接口高延时案例的两条trace日志。从第一条日志中我们可以知道瓶颈在于线性读的准备步骤,readIndex和wait applied index。
那么是其中具体哪个步骤导致的高延时呢?通过在etcd 3.5版本中细化此流程,我们获得了第二条日志,发现瓶颈在于等待applied index >= Leader的committed index。
{
"level": "info",
"ts": "2020-08-12T08:24:56.181Z",
"caller": "traceutil/trace.go:145",
"msg": "trace[677217921] range",
"detail": "{range_begin:/...redacted...; range_end:; response_count:1; response_revision:2725080604; }",
"duration": "1.553047811s",
"start": "2020-08-12T08:24:54.628Z",
"end": "2020-08-12T08:24:56.181Z",
"steps": [
"trace[677217921] 'agreement among raft nodes before linearized reading' (duration: 1.534322015s)"
]
}{"level": "info","ts": "2020-09-22T12:54:01.021Z","caller": "traceutil/trace.go:152","msg": "trace[2138445431] linearizableReadLoop","detail": "","duration": "855.447896ms","start": "2020-09-22T12:54:00.166Z","end": "2020-09-22T12:54:01.021Z","steps": ["trace[2138445431] read index received (duration: 824.408µs)","trace[2138445431] applied index is now lower than readState.Index (duration: 854.622058ms)"]
}
为什么会发生这样的现象呢?
首先你可以通过etcd_server_slow_apply_total指标,观查其值快速增长的时间点与高延时请求产生的日志时间点是否吻合。
其次检查是否存在大量写请求。线性读需确保本节点数据与Leader数据一样新, 若本节点的数据与Leader差异较大,本节点追赶Leader数据过程会花费一定时间,最终导致高延时的线性读请求产生。
etcd适合读多写少的业务场景,若写请求较大,很容易出现容量瓶颈,导致高延时的读写请求产生。
最后通过ps/top/mpstat/perf等CPU、Memory性能分析工具,检查etcd节点是否存在CPU、Memory瓶颈。goroutine饥饿、内存不足都会导致高延时请求产生,若确定CPU和Memory存在异常,你可以通过开启debug模式,通过pprof分析CPU和内存瓶颈点。
小结
最后小结下我们今天的内容,我按照前面介绍的读写请求原理、以及丰富的实战经验,给你整理了可能导致延时抖动的常见原因。
如下图所示,我从以下几个方面给你介绍了会导致请求延时上升的原因:
- 网络质量,如节点之间RTT延时、网卡带宽满,出现丢包;
- 磁盘I/O抖动,会导致WAL日志持久化、boltdb事务提交出现抖动,Leader出现切换等;
- expensive request,比如大包请求、涉及到大量key遍历、Authenticate密码鉴权等操作;
- 容量瓶颈,太多写请求导致线性读请求性能下降等;
- 节点配置,CPU繁忙导致请求处理延时、内存不够导致swap等。
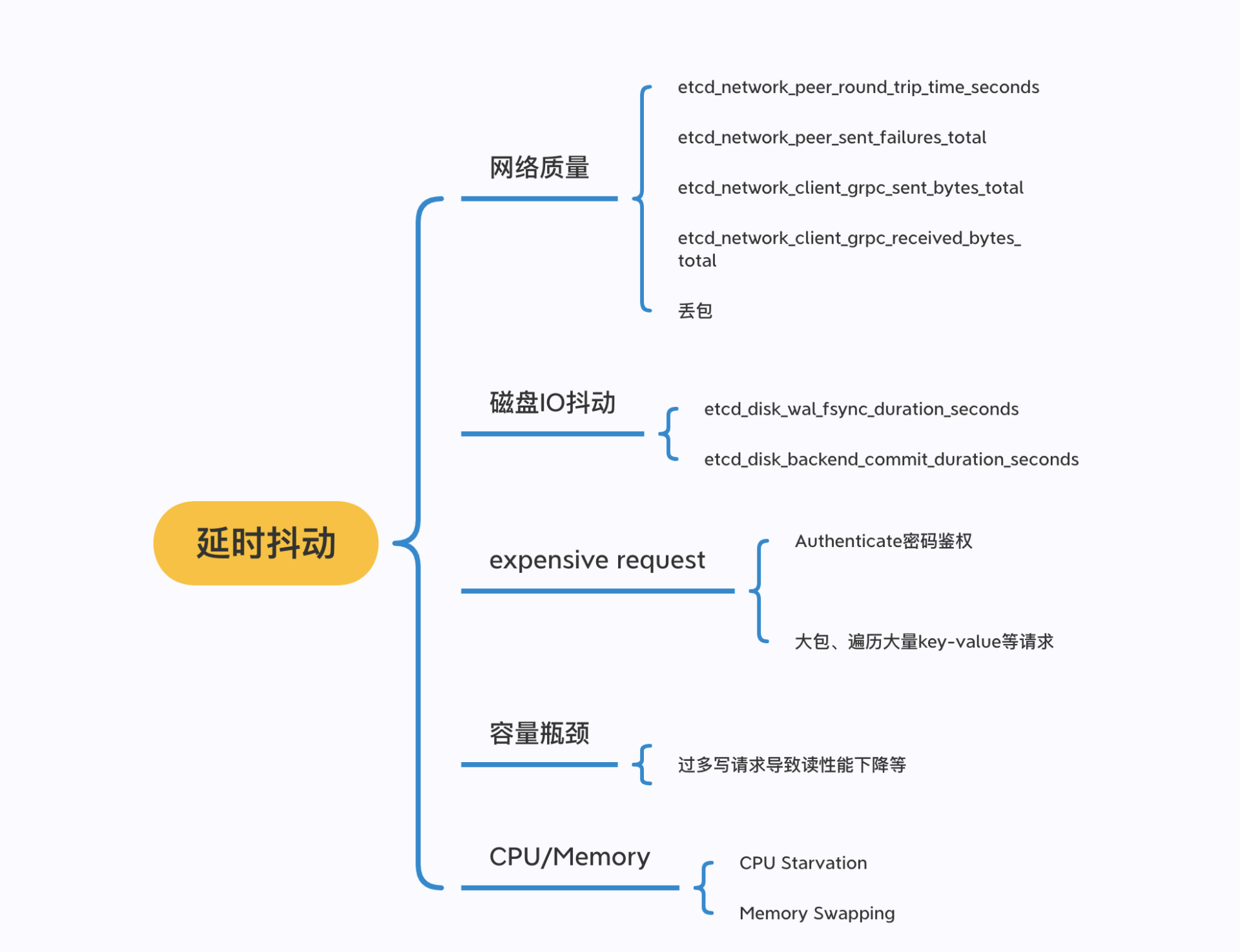
并在分析这些案例的过程中,给你介绍了etcd问题核心工具:metrics、etcd log、trace日志、blktrace、pprof等。
希望通过今天的内容,能帮助你从容应对etcd延时抖动。
思考题
在使用etcd过程中,你遇到过哪些高延时的请求案例呢?你是如何解决的呢?
15 内存:为什么你的etcd内存占用那么高?
在使用etcd的过程中,你是否被异常内存占用等现象困扰过?比如etcd中只保存了1个1MB的key-value,但是经过若干次修改后,最终etcd内存可能达到数G。它是由什么原因导致的?如何分析呢?
这就是我今天要和你分享的主题:etcd的内存。 希望通过这节课,帮助你掌握etcd内存抖动、异常背后的常见原因和分析方法,当你遇到类似问题时,能独立定位、解决。同时,帮助你在实际业务场景中,为集群节点配置充足的内存资源,遵循最佳实践,尽量减少expensive request,避免etcd内存出现突增,导致OOM。
分析整体思路
当你遇到etcd内存占用较高的案例时,你脑海中第一反应是什么呢?
也许你会立刻重启etcd进程,尝试将内存降低到合理水平,避免线上服务出问题。
也许你会开启etcd debug模式,重启etcd进程等复现,然后采集heap profile分析内存占用。
以上措施都有其合理性。但作为团队内etcd高手的你,在集群稳定性还不影响业务的前提下,能否先通过内存异常的现场,结合etcd的读写流程、各核心模块中可能会使用较多内存的关键数据结构,推测出内存异常的可能原因?
全方位的分析内存异常现场,可以帮助我们节省大量复现和定位时间,也是你专业性的体现。
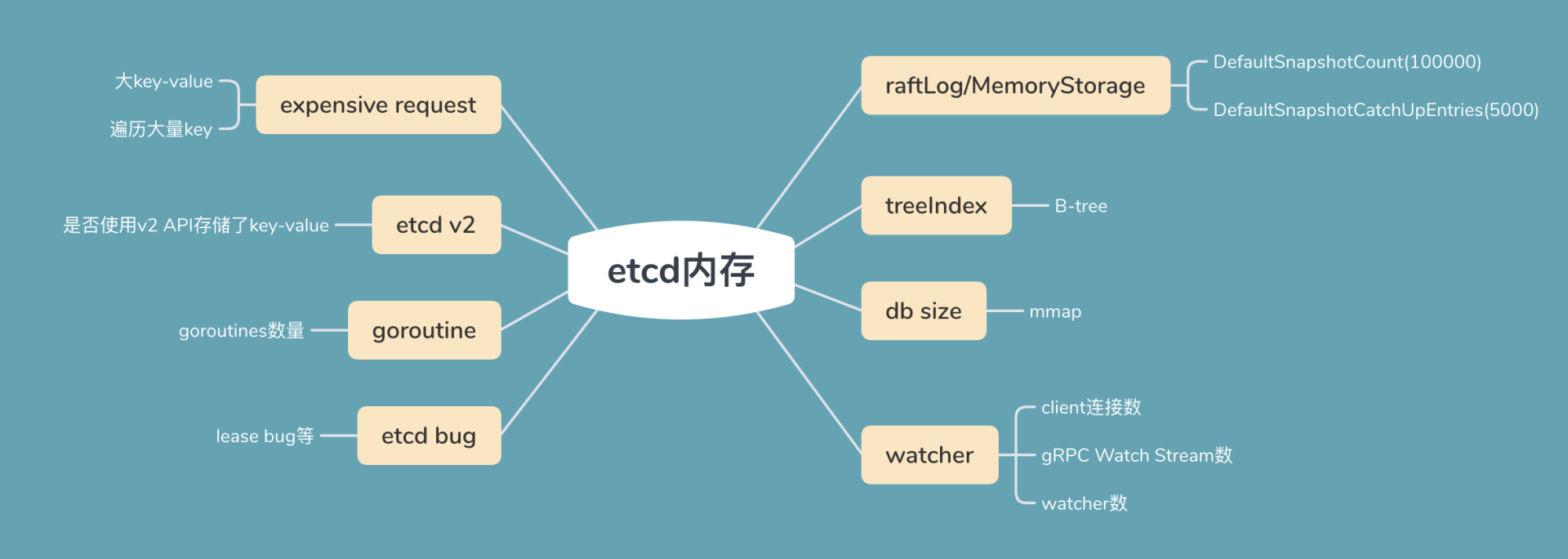
下图是我以etcd写请求流程为例,给你总结的可能导致etcd内存占用较高的核心模块与其数据结构。
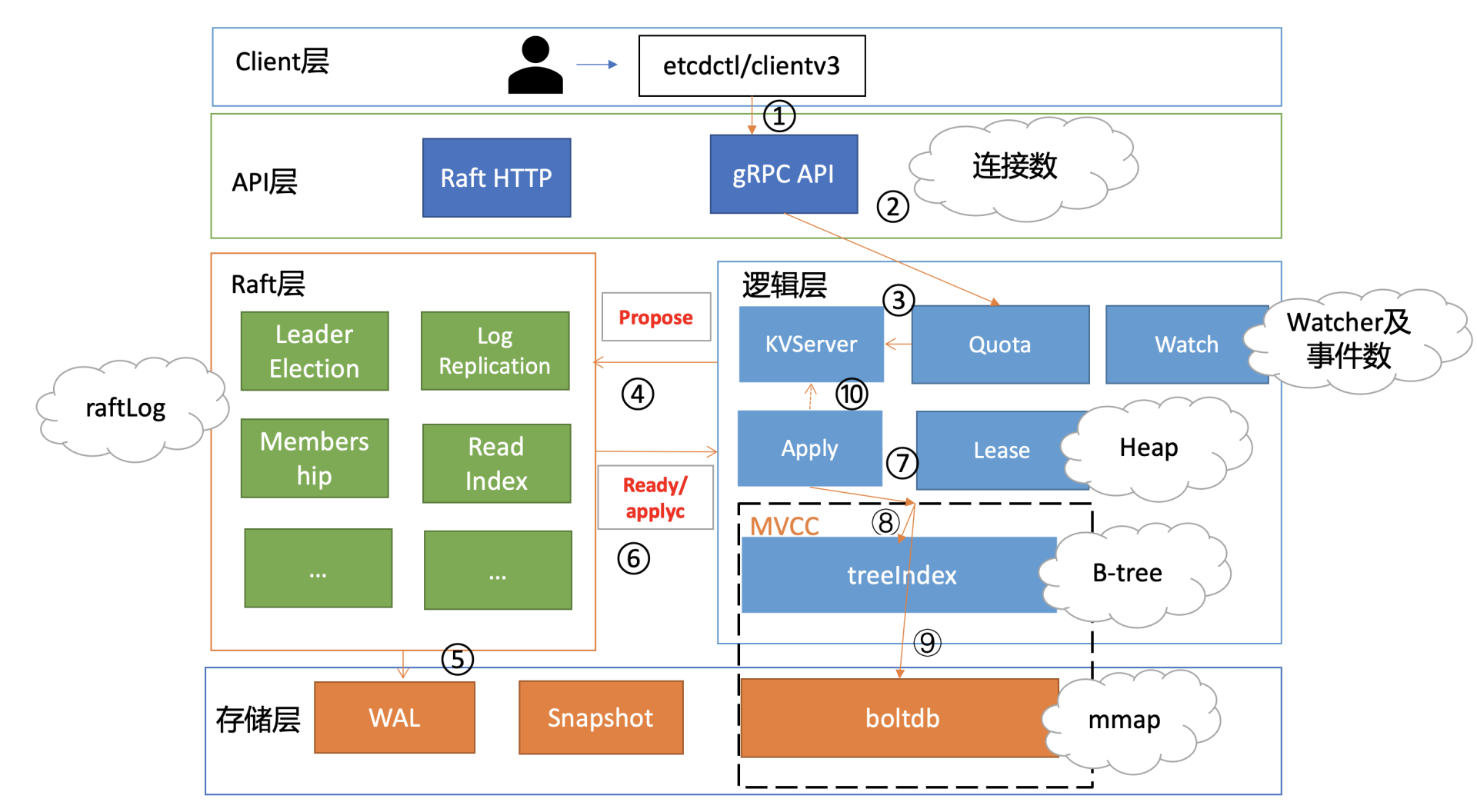
从图中你可以看到,当etcd收到一个写请求后,gRPC Server会和你建立连接。连接数越多,会导致etcd进程的fd、goroutine等资源上涨,因此会使用越来越多的内存。
其次,基于我们04介绍的Raft知识背景,它需要将此请求的日志条目保存在raftLog里面。etcd raftLog后端实现是内存存储,核心就是数组。因此raftLog使用的内存与其保存的日志条目成正比,它也是内存分析过程中最容易被忽视的一个数据结构。
然后当此日志条目被集群多数节点确认后,在应用到状态机的过程中,会在内存treeIndex模块的B-tree中创建、更新key与版本号信息。 在这过程中treeIndex模块的B-tree使用的内存与key、历史版本号数量成正比。
更新完treeIndex模块的索引信息后,etcd将key-value数据持久化存储到boltdb。boltdb使用了mmap技术,将db文件映射到操作系统内存中。因此在未触发操作系统将db对应的内存page换出的情况下,etcd的db文件越大,使用的内存也就越大。
同时,在这个过程中还有两个注意事项。
一方面,其他client可能会创建若干watcher、监听这个写请求涉及的key, etcd也需要使用一定的内存维护watcher、推送key变化监听的事件。
另一方面,如果这个写请求的key还关联了Lease,Lease模块会在内存中使用数据结构Heap来快速淘汰过期的Lease,因此Heap也是一个占用一定内存的数据结构。
最后,不仅仅是写请求流程会占用内存,读请求本身也会导致内存上升。尤其是expensive request,当产生大包查询时,MVCC模块需要使用内存保存查询的结果,很容易导致内存突增。
基于以上读写流程图对核心数据结构使用内存的分析,我们定位问题时就有线索、方法可循了。那如何确定是哪个模块、场景导致的内存异常呢?
接下来我就通过一个实际案例,和你深入介绍下内存异常的分析方法。
一个key使用数G内存的案例
我们通过goreman启动一个3节点etcd集群(linux/etcd v3.4.9),db quota为6G,执行如下的命令并观察etcd内存占用情况:
- 执行1000次的put同一个key操作,value为1MB;
- 更新完后并进行compact、defrag操作;
# put同一个key,执行1000次
for i in {1..1000}; do dd if=/dev/urandom bs=1024
count=1024 | ETCDCTL_API=3 etcdctl put key || break; done# 获取最新revision,并压缩
etcdctl compact `(etcdctl endpoint status --write-out="json" | egrep -o '"revision":[0-9]*' | egrep -o '[0-9].*')`# 对集群所有节点进行碎片整理
etcdctl defrag --cluster
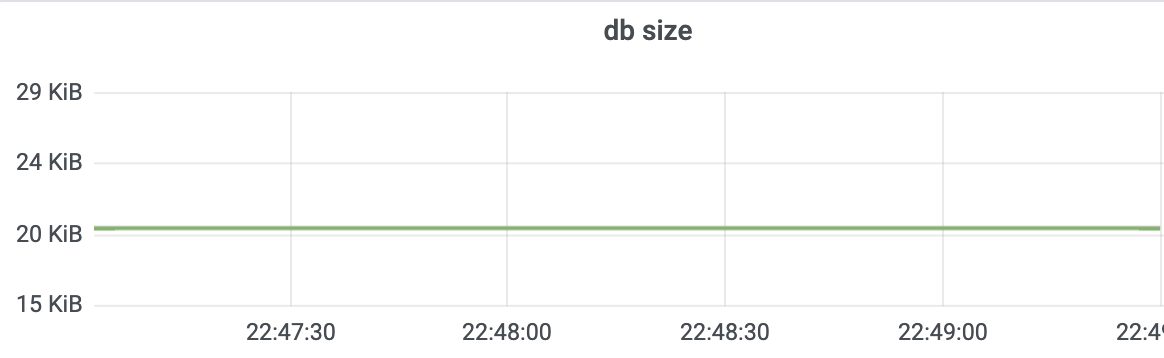
在执行操作前,空集群etcd db size 20KB,etcd进程内存36M左右,分别如下图所示。
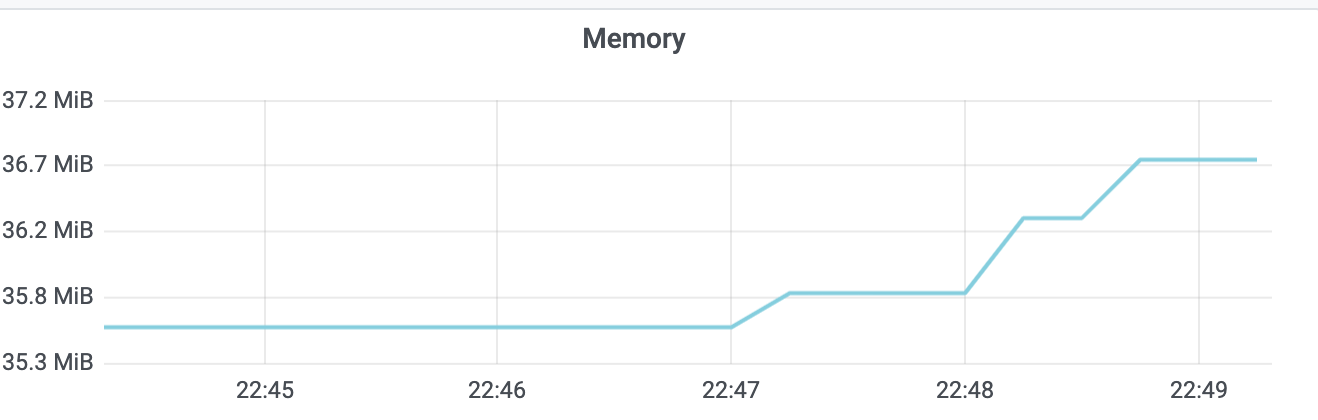
你预测执行1000次同样key更新后,etcd进程占用了多少内存呢? 约37M? 1G? 2G?3G? 还是其他呢?
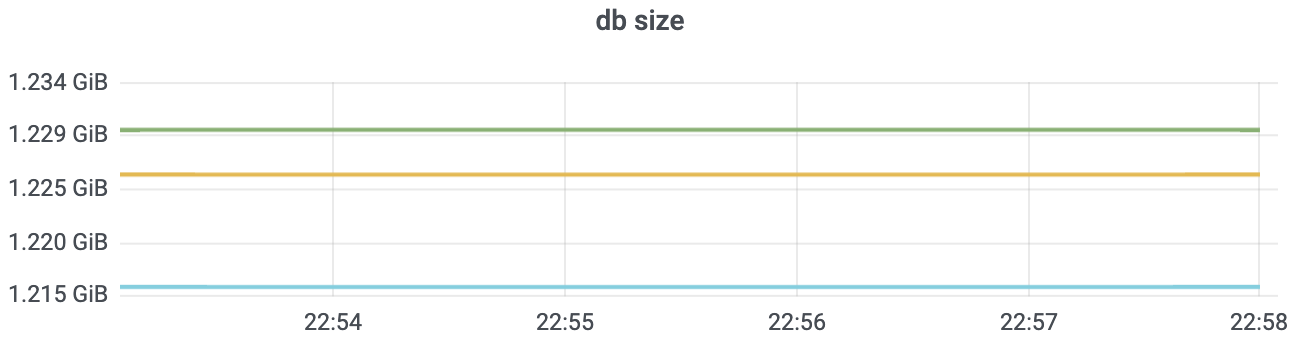
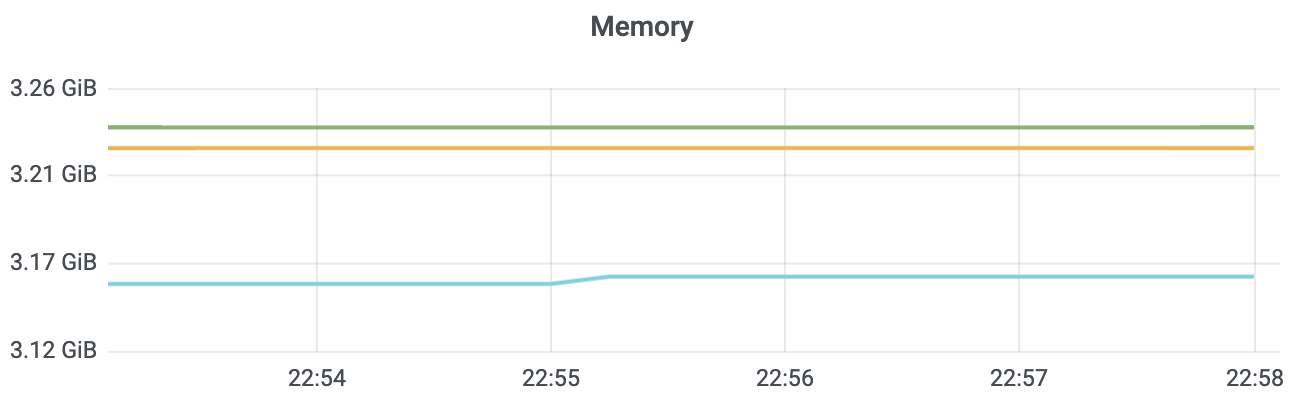
执行1000次的put操作后,db大小和etcd内存占用分别如下图所示。
当我们执行compact、defrag命令后,如下图所示,db大小只有1M左右,但是你会发现etcd进程实际却仍占用了2G左右内存。-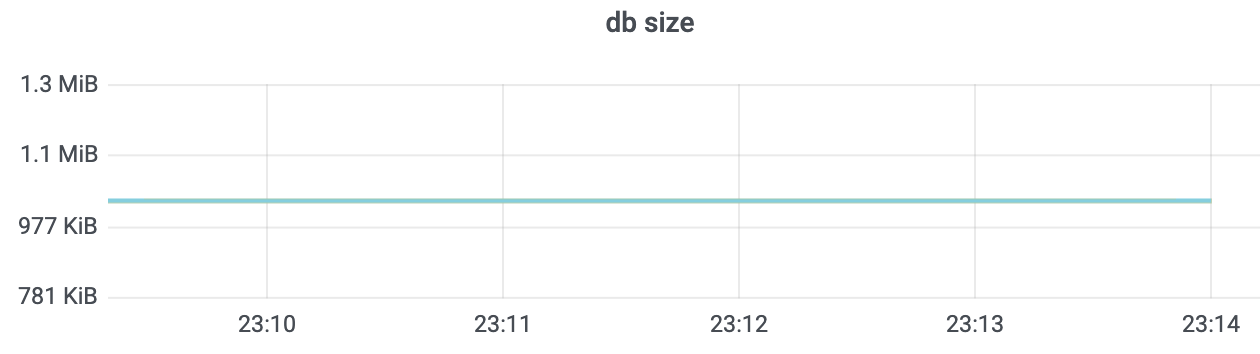
整个集群只有一个key,为什么etcd占用了这么多的内存呢?是etcd发生了内存泄露吗?
raftLog
当你发起一个put请求的时候,etcd需通过Raft模块将此请求同步到其他节点,详细流程你可结合下图再次了解下。
从图中你可以看到,Raft模块的输入是一个消息/Msg,输出统一为Ready结构。etcd会把此请求封装成一个消息,提交到Raft模块。
Raft模块收到此请求后,会把此消息追加到raftLog的unstable存储的entry内存数组中(图中流程2),并且将待持久化的此消息封装到Ready结构内,通过管道通知到etcdserver(图中流程3)。
etcdserver取出消息,持久化到WAL中,并追加到raftLog的内存存储storage的entry数组中(图中流程5)。
下面是raftLog的核心数据结构,它由storage、unstable、committed、applied等组成。storage存储已经持久化到WAL中的日志条目,unstable存储未持久化的条目和快照,一旦持久化会及时删除日志条目,因此不存在过多内存占用的问题。
type raftLog struct {// storage contains all stable entries since the last snapshot.storage Storage// unstable contains all unstable entries and snapshot.// they will be saved into storage.unstable unstable// committed is the highest log position that is known to be in// stable storage on a quorum of nodes.committed uint64// applied is the highest log position that the application has// been instructed to apply to its state machine.// Invariant: applied <= committedapplied uint64
}
从上面raftLog结构体中,你可以看到,存储稳定的日志条目的storage类型是Storage,Storage定义了存储Raft日志条目的核心API接口,业务应用层可根据实际场景进行定制化实现。etcd使用的是Raft算法库本身提供的MemoryStorage,其定义如下,核心是使用了一个数组来存储已经持久化后的日志条目。
// MemoryStorage implements the Storage interface backed
// by an in-memory array.
type MemoryStorage struct {// Protects access to all fields. Most methods of MemoryStorage are// run on the raft goroutine, but Append() is run on an application// goroutine.sync.MutexhardState pb.HardStatesnapshot pb.Snapshot// ents[i] has raftLog position i+snapshot.Metadata.Indexents []pb.Entry
}
那么随着写请求增多,内存中保留的Raft日志条目会越来越多,如何防止etcd出现OOM呢?
etcd提供了快照和压缩功能来解决这个问题。
首先你可以通过调整–snapshot-count参数来控制生成快照的频率,其值默认是100000(etcd v3.4.9,早期etcd版本是10000),也就是每10万个写请求触发一次快照生成操作。
快照生成完之后,etcd会通过压缩来删除旧的日志条目。
那么是全部删除日志条目还是保留一小部分呢?
答案是保留一小部分Raft日志条目。数量由DefaultSnapshotCatchUpEntries参数控制,默认5000,目前不支持自定义配置。
保留一小部分日志条目其实是为了帮助慢的Follower以较低的开销向Leader获取Raft日志条目,以尽快追上Leader进度。若raftLog中不保留任何日志条目,就只能发送快照给慢的Follower,这开销就非常大了。
通过以上分析可知,如果你的请求key-value比较大,比如上面我们的案例中是1M,1000次修改,那么etcd raftLog至少会消耗1G的内存。这就是为什么内存随着写请求修改次数不断增长的原因。
除了raftLog占用内存外,MVCC模块的treeIndex/boltdb模块又是如何使用内存的呢?
treeIndex
一个put写请求的日志条目被集群多数节点确认提交后,这时etcdserver就会从Raft模块获取已提交的日志条目,应用到MVCC模块的treeIndex和boltdb。
我们知道treeIndex是基于google内存btree库实现的一个索引管理模块,在etcd中每个key都会在treeIndex中保存一个索引项(keyIndex),记录你的key和版本号等信息,如下面的数据结构所示。
type keyIndex struct {key []bytemodified revision // the main rev of the last modificationgenerations []generation
}
同时,你每次对key的修改、删除操作都会在key的索引项中追加一条修改记录(revision)。因此,随着修改次数的增加,etcd内存会一直增加。那么如何清理旧版本,防止过多的内存占用呢?
答案也是压缩。正如我在11压缩篇和你介绍的,当你执行compact命令时,etcd会遍历treeIndex中的各个keyIndex,清理历史版本号记录与已删除的key,释放内存。
从上面的keyIndex数据结构我们可知,一个key的索引项内存开销跟你的key大小、保存的历史版本数、compact策略有关。为了避免内存索引项占用过多的内存,key的长度不应过长,同时你需要配置好合理的压缩策略。
boltdb
在treeIndex模块中创建、更新完keyIndex数据结构后,你的key-value数据、各种版本号、lease等相关信息会保存到如下的一个mvccpb.keyValue结构体中。它是boltdb的value,key则是treeIndex中保存的版本号,然后通过boltdb的写接口保存到db文件中。
kv := mvccpb.KeyValue{Key: key,Value: value,CreateRevision: c,ModRevision: rev,Version: ver,Lease: int64(leaseID),
}
前面我们在介绍boltdb时,提到过etcd在启动时会通过mmap机制,将etcd db文件映射到etcd进程地址空间,并设置mmap的MAP_POPULATE flag,它会告诉Linux内核预读文件,让Linux内核将文件内容拷贝到物理内存中。
在节点内存足够的情况下,后续读请求可直接从内存中获取。相比read系统调用,mmap少了一次从page cache拷贝到进程内存地址空间的操作,因此具备更好的性能。
若etcd节点内存不足,可能会导致db文件对应的内存页被换出。当读请求命中的页未在内存中时,就会产生缺页异常,导致读过程中产生磁盘IO。这样虽然避免了etcd进程OOM,但是此过程会产生较大的延时。
从以上boltdb的key-value和mmap机制介绍中我们可知,我们应控制boltdb文件大小,优化key-value大小,配置合理的压缩策略,回收旧版本,避免过多内存占用。
watcher
在你写入key的时候,其他client还可通过etcd的Watch监听机制,获取到key的变化事件。
那创建一个watcher耗费的内存跟哪些因素有关呢?
在08Watch机制设计与实现分析中,我和你介绍过创建watcher的整体流程与架构,如下图所示。当你创建一个watcher时,client与server建立连接后,会创建一个gRPC Watch Stream,随后通过这个gRPC Watch Stream发送创建watcher请求。
每个gRPC Watch Stream中etcd WatchServer会分配两个goroutine处理,一个是sendLoop,它负责Watch事件的推送。一个是recvLoop,负责接收client的创建、取消watcher请求消息。
同时对每个watcher来说,etcd的WatchableKV模块需将其保存到相应的内存管理数据结构中,实现可靠的Watch事件推送。
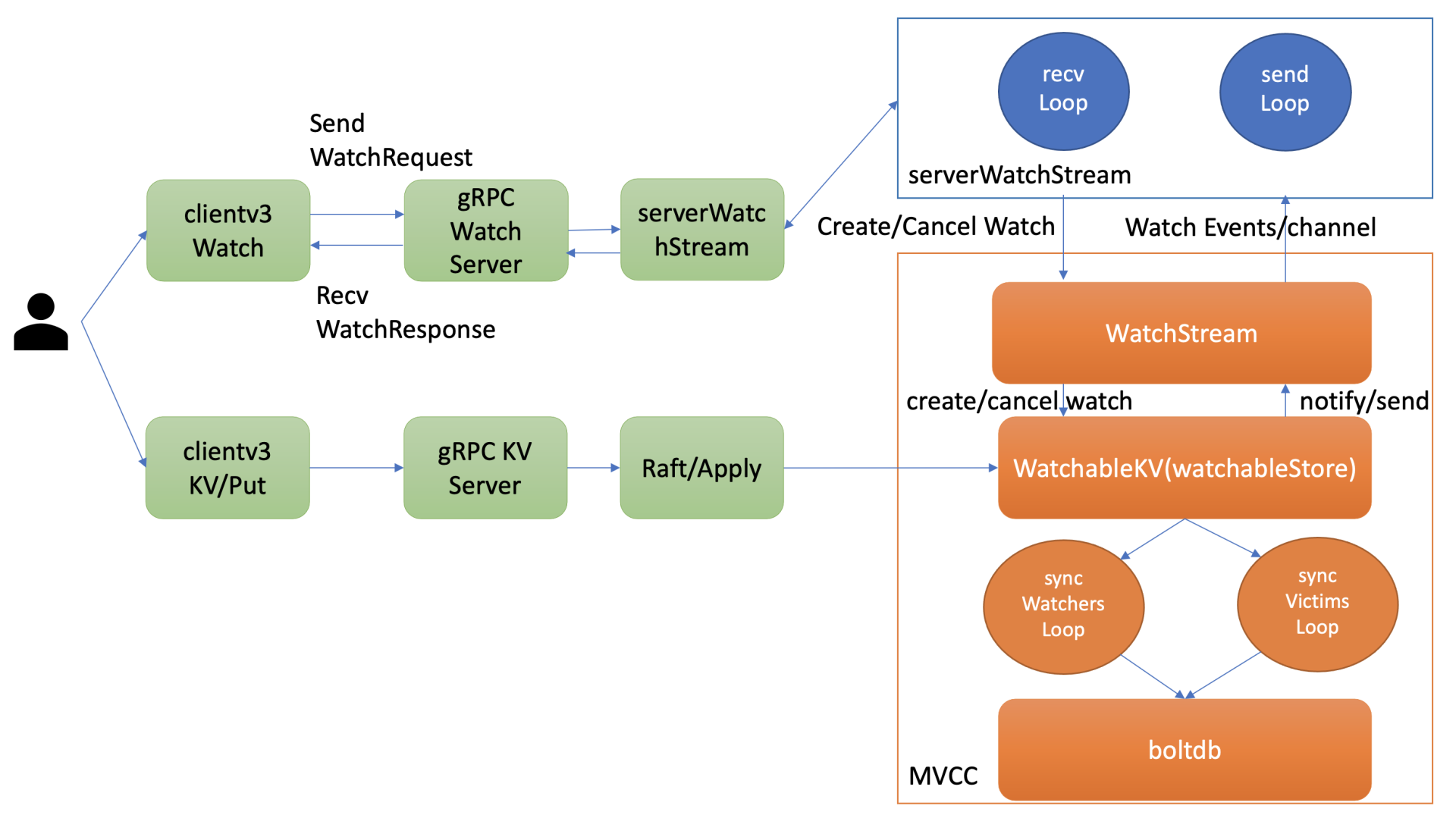
因此watch监听机制耗费的内存跟client连接数、gRPC Stream、watcher数(watching)有关,如下面公式所示:
- c1表示每个连接耗费的内存;
- c2表示每个gRPC Stream耗费的内存;
- c3表示每个watcher耗费的内存。
memory = c1 * number_of_conn + c2 *
avg_number_of_stream_per_conn + c3 *
avg_number_of_watch_stream
根据etcd社区的压测报告,大概估算出Watch机制中c1、c2、c3占用的内存分别如下:
- 每个client连接消耗大约17kb的内存(c1);
- 每个gRPC Stream消耗大约18kb的内存(c2);
- 每个watcher消耗大约350个字节(c3);
当你的业务场景大量使用watcher的时候,应提前估算下内存容量大小,选择合适的内存配置节点。
注意以上估算并不包括watch事件堆积的开销。变更事件较多,服务端、客户端高负载,网络阻塞等情况都可能导致事件堆积。
在etcd 3.4.9版本中,每个watcher默认buffer是1024。buffer内保存watch响应结果,如watchID、watch事件(watch事件包含key、value)等。
若大量事件堆积,将产生较高昂的内存的开销。你可以通过etcd_debugging_mvcc_pending_events_total指标监控堆积的事件数,etcd_debugging_slow_watcher_total指标监控慢的watcher数,来及时发现异常。
expensive request
当你写入比较大的key-value后,如果client频繁查询它,也会产生高昂的内存开销。
假设我们写入了100个这样1M大小的key, 通过Range接口一次查询100个key, 那么boltdb遍历、反序列化过程将花费至少100MB的内存。如下面代码所示,它会遍历整个key-value,将key-value保存到数组kvs中。
kvs := make([]mvccpb.KeyValue, limit)
revBytes := newRevBytes()
for i, revpair := range revpairs[:len(kvs)] {revToBytes(revpair, revBytes)_, vs := tr.tx.UnsafeRange(keyBucketName, revBytes, nil, 0)if len(vs) != 1 {...... }if err := kvs[i].Unmarshal(vs[0]); err != nil {.......}
也就是说,一次查询就耗费了至少100MB的内存、产生了至少100MB的流量,随着你QPS增大后,很容易OOM、网卡出现丢包。
count-only、limit查询在key百万级以上时,也会产生非常大的内存开销。因为它们在遍历treeIndex的过程中,会将相关key保存在数组里面。当key多时,此开销不容忽视。
正如我在13 db大小中讲到的,在master分支,我已提交相关PR解决count-only和limit查询导致内存占用突增的问题。
etcd v2/goroutines/bug
除了以上介绍的核心模块、expensive request场景可能导致较高的内存开销外,还有以下场景也会导致etcd内存使用较高。
首先是etcd中使用了v2的API写入了大量的key-value数据,这会导致内存飙高。我们知道etcd v2的key-value都是存储在内存树中的,同时v2的watcher不支持多路复用,内存开销相比v3多了一个数量级。
在etcd 3.4版本之前,etcd默认同时支持etcd v2/v3 API,etcd 3.4版本默认关闭了v2 API。 你可以通过etcd v2 API和etcd v2内存存储模块的metrics前缀etcd_debugging_store,观察集群中是否有v2数据导致的内存占用高。
其次是goroutines泄露导致内存占用高。此问题可能会在容器化场景中遇到。etcd在打印日志的时候,若出现阻塞则可能会导致goroutine阻塞并持续泄露,最终导致内存泄露。你可以通过观察、监控go_goroutines来发现这个问题。
最后是etcd bug导致的内存泄露。当你基本排除以上场景导致的内存占用高后,则很可能是etcd bug导致的内存泄露。
比如早期etcd clientv3的lease keepalive租约频繁续期bug,它会导致Leader高负载、内存泄露,此bug已在3.2.24⁄3.3.9版本中修复。
还有最近我修复的etcd 3.4版本的Follower节点内存泄露。具体表现是两个Follower节点内存一直升高,Leader节点正常,已在3.4.6版本中修复。
若内存泄露并不是已知的etcd bug导致,那你可以开启pprof, 尝试复现,通过分析pprof heap文件来确定消耗大量内存的模块和数据结构。
小节
今天我通过一个写入1MB key的实际案例,给你介绍了可能导致etcd内存占用高的核心数据结构、场景,同时我将可能导致内存占用较高的因素总结为了下面这幅图,你可以参考一下。
首先是raftLog。为了帮助slow Follower同步数据,它至少要保留5000条最近收到的写请求在内存中。若你的key非常大,你更新5000次会产生较大的内存开销。
其次是treeIndex。 每个key-value会在内存中保留一个索引项。索引项的开销跟key长度、保留的历史版本有关,你可以通过compact命令压缩。
然后是boltdb。etcd启动的时候,会通过mmap系统调用,将文件映射到虚拟内存中。你可以通过compact命令回收旧版本,defrag命令进行碎片整理。
接着是watcher。它的内存占用跟连接数、gRPC Watch Stream数、watcher数有关。watch机制一个不可忽视的内存开销其实是事件堆积的占用缓存,你可以通过相关metrics及时发现堆积的事件以及slow watcher。
最后我介绍了一些典型的场景导致的内存异常,如大包查询等expensive request,etcd中存储了v2 API写入的key, goroutines泄露以及etcd lease bug等。
希望今天的内容,能够帮助你从容应对etcd内存占用高的问题,合理配置你的集群,优化业务expensive request,让etcd跑得更稳。
思考题
在一个key使用数G内存的案例中,最后执行compact和defrag后的结果是2G,为什么不是1G左右呢?在macOS下行为是否一样呢?
欢迎你动手做下这个小实验,分析下原因,分享你的观点。
16 性能及稳定性(上):如何优化及扩展etcd性能?
在使用etcd的过程中,你是否吐槽过etcd性能差呢? 我们知道,etcd社区线性读压测结果可以达到14w/s,那为什么在实际业务场景中有时却只有几千,甚至几百、几十,还会偶发超时、频繁抖动呢?
我相信不少人都遇到过类似的问题。要解决这些问题,不仅需要了解症结所在,还需要掌握优化和扩展etcd性能的方法,对症下药。因为这部分内容比较多,所以我分成了两讲内容,分别从读性能、写性能和稳定性入手,为你详细讲解如何优化及扩展etcd性能及稳定性。
希望通过这两节课的学习,能让你在使用etcd的时候,设计出良好的业务存储结构,遵循最佳实践,让etcd稳定、高效地运行,获得符合预期的性能。同时,当你面对etcd性能瓶颈的时候,也能自己分析瓶颈原因、选择合适的优化方案解决它,而不是盲目甩锅etcd,甚至更换技术方案去etcd化。
今天这节课,我将重点为你介绍如何提升读的性能。
我们说读性能差,其实本质是读请求链路中某些环节出现了瓶颈。所以,接下来我将通过一张读性能分析链路图,为你从上至下分析影响etcd性能、稳定性的若干因素,并给出相应的压测数据,最终为你总结出一系列的etcd性能优化和扩展方法。
性能分析链路
为什么在你的业务场景中读性能不如预期呢? 是读流程中的哪一个环节出现了瓶颈?
在下图中,我为你总结了一个开启密码鉴权场景的读性能瓶颈分析链路图,并在每个核心步骤数字旁边,标出了影响性能的关键因素。我之所以选用密码鉴权的读请求为案例,是因为它使用较广泛并且请求链路覆盖最全,同时它也是最容易遇到性能瓶颈的场景。
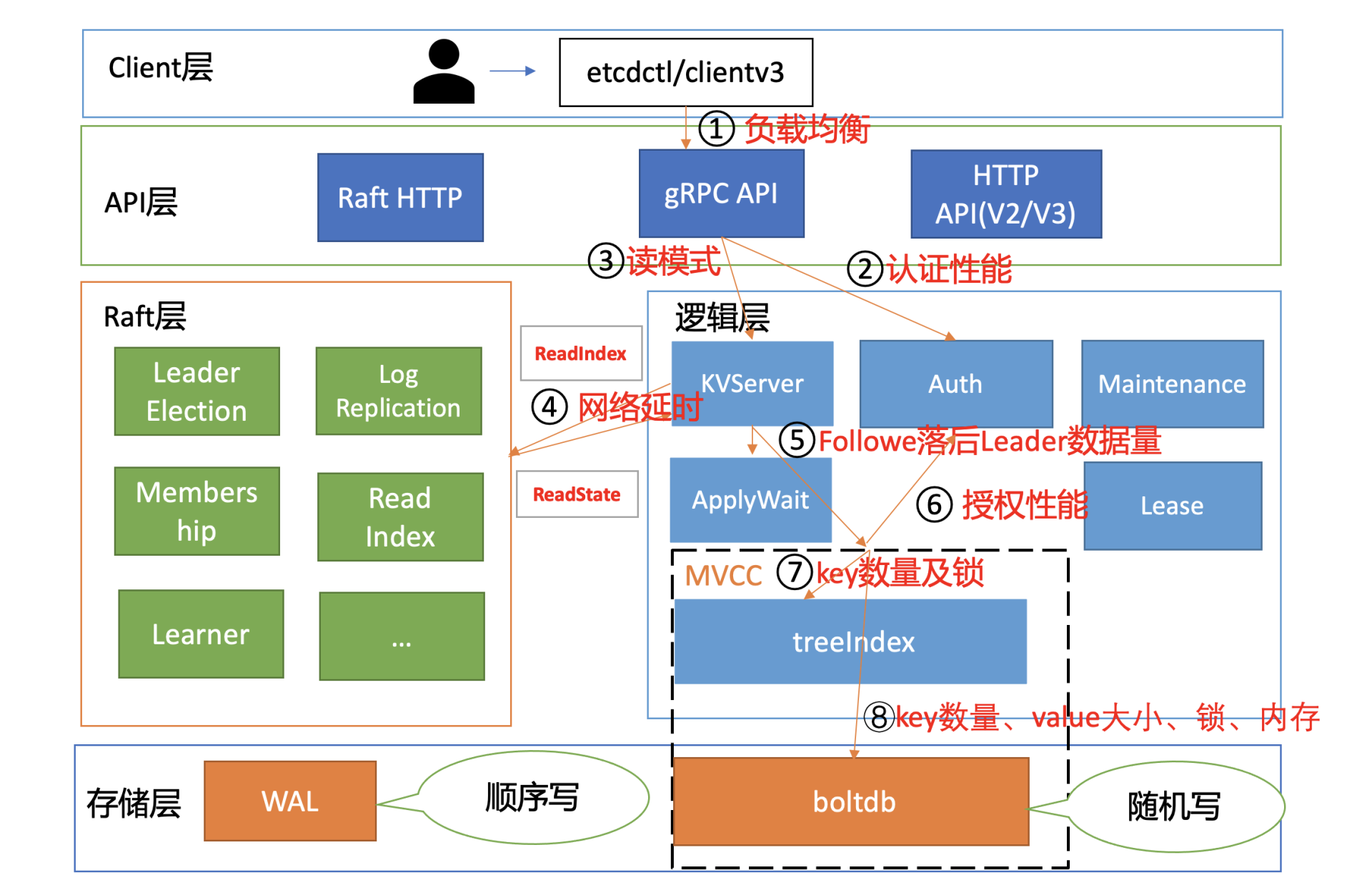
接下来我将按照这张链路分析图,带你深入分析一个使用密码鉴权的线性读请求,和你一起看看影响它性能表现的核心因素以及最佳优化实践。
负载均衡
首先是流程一负载均衡。在02节时我和你提到过,在etcd 3.4以前,client为了节省与server节点的连接数,clientv3负载均衡器最终只会选择一个sever节点IP,与其建立一个长连接。
但是这可能会导致对应的server节点过载(如单节点流量过大,出现丢包), 其他节点却是低负载,最终导致业务无法获得集群的最佳性能。在etcd 3.4后,引入了Round-robin负载均衡算法,它通过轮询的方式依次从endpoint列表中选择一个endpoint访问(长连接),使server节点负载尽量均衡。
所以,如果你使用的是etcd低版本,那么我建议你通过Load Balancer访问后端etcd集群。因为一方面Load Balancer一般支持配置各种负载均衡算法,如连接数、Round-robin等,可以使你的集群负载更加均衡,规避etcd client早期的固定连接缺陷,获得集群最佳性能。
另一方面,当你集群节点需要替换、扩缩容集群节点的时候,你不需要去调整各个client访问server的节点配置。
选择合适的鉴权
client通过负载均衡算法为请求选择好etcd server节点后,client就可调用server的Range RPC方法,把请求发送给etcd server。在此过程中,如果server启用了鉴权,那么就会返回无权限相关错误给client。
如果server使用的是密码鉴权,你在创建client时,需指定用户名和密码。etcd clientv3库发现用户名、密码非空,就会先校验用户名和密码是否正确。
client是如何向sever请求校验用户名、密码正确性的呢?
client是通过向server发送Authenticate RPC鉴权请求实现密码认证的,也就是图中的流程二。
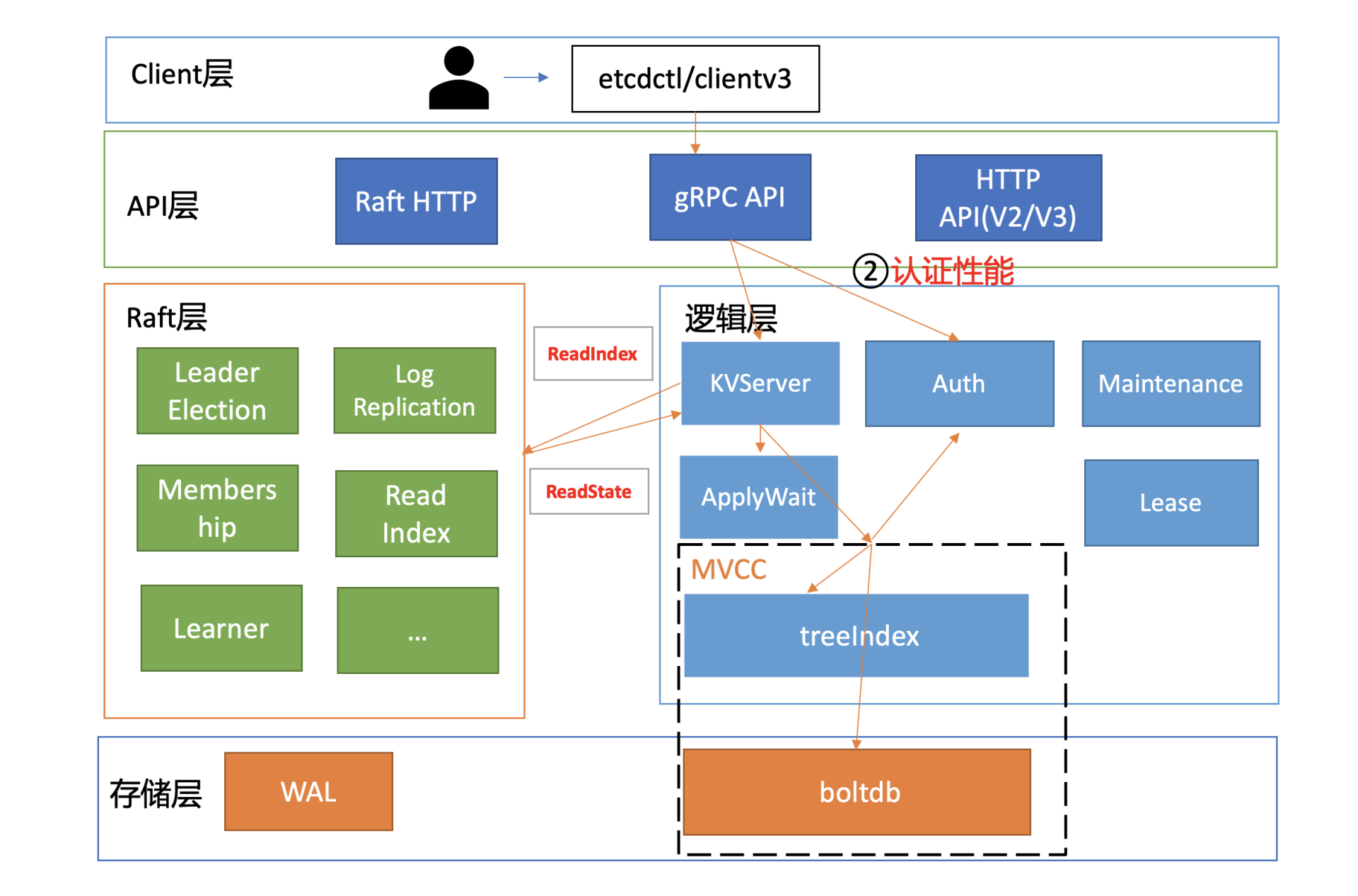
根据我们05介绍的密码认证原理,server节点收到鉴权请求后,它会从boltdb获取此用户密码对应的算法版本、salt、cost值,并基于用户的请求明文密码计算出一个hash值。
在得到hash值后,就可以对比db里保存的hash密码是否与其一致了。如果一致,就会返回一个token给client。 这个token是client访问server节点的通行证,后续server只需要校验“通行证”是否有效即可,无需每次发起昂贵的Authenticate RPC请求。
讲到这里,不知道你有没有意识到,若你的业务在访问etcd过程中未复用token,每次访问etcd都发起一次Authenticate调用,这将是一个非常大的性能瓶颈和隐患。因为正如我们05所介绍的,为了保证密码的安全性,密码认证(Authenticate)的开销非常昂贵,涉及到大量CPU资源。
那这个Authenticate接口究竟有多慢呢?
为了得到Authenticate接口的性能,我们做过这样一个测试:
- 压测集群etcd节点配置是16核32G;
- 压测方式是我们通过修改etcd clientv3库、benchmark工具,使benchmark工具支持Authenticate接口压测;
- 然后设置不同的client和connection参数,运行多次,观察结果是否稳定,获取测试结果。
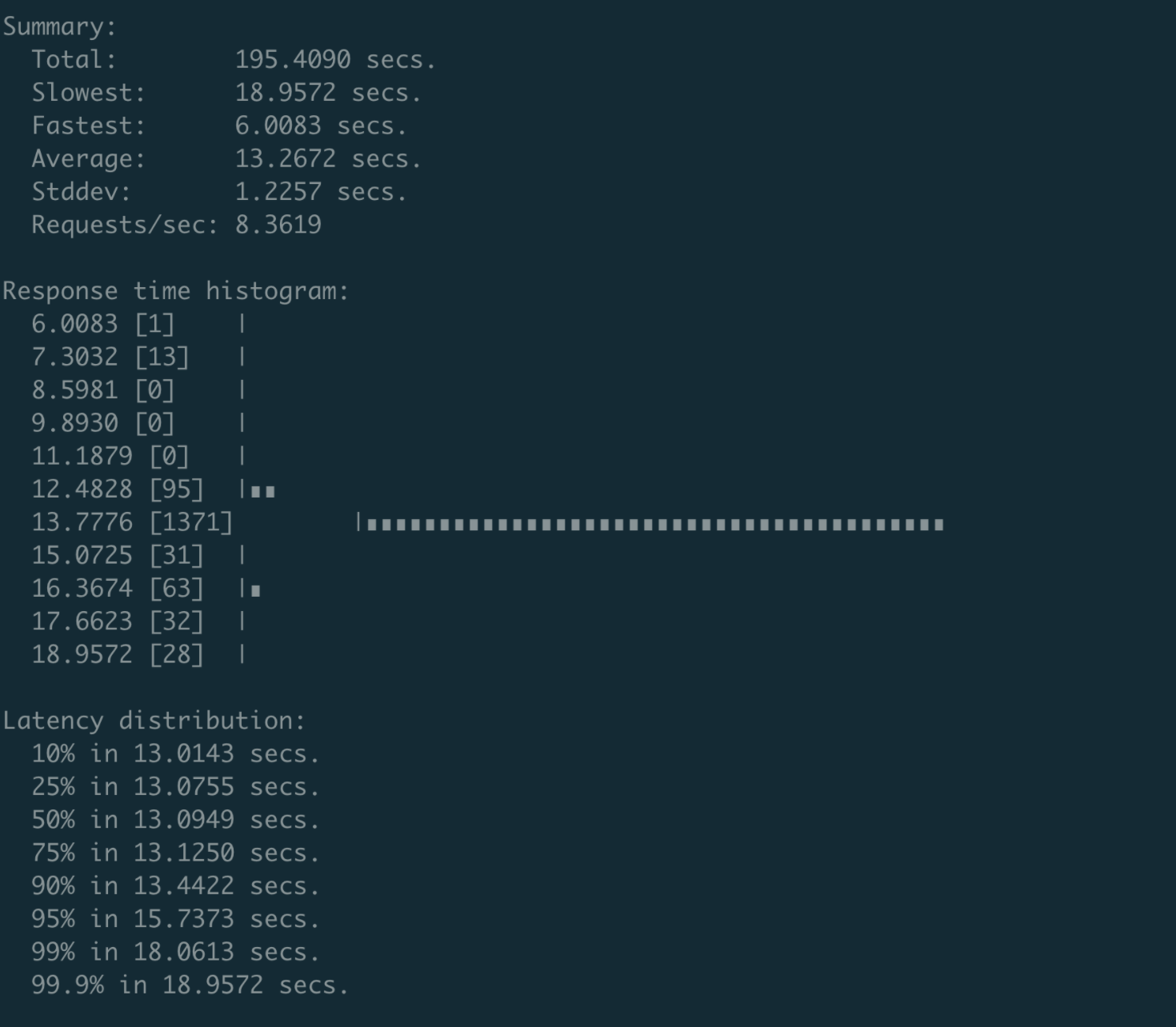
最终的测试结果非常惊人。etcd v3.4.9之前的版本,Authenticate接口性能不到16 QPS,并且随着client和connection增多,该性能会继续恶化。
当client和connection的数量达到200个的时候,性能会下降到8 QPS,P99延时为18秒,如下图所示。
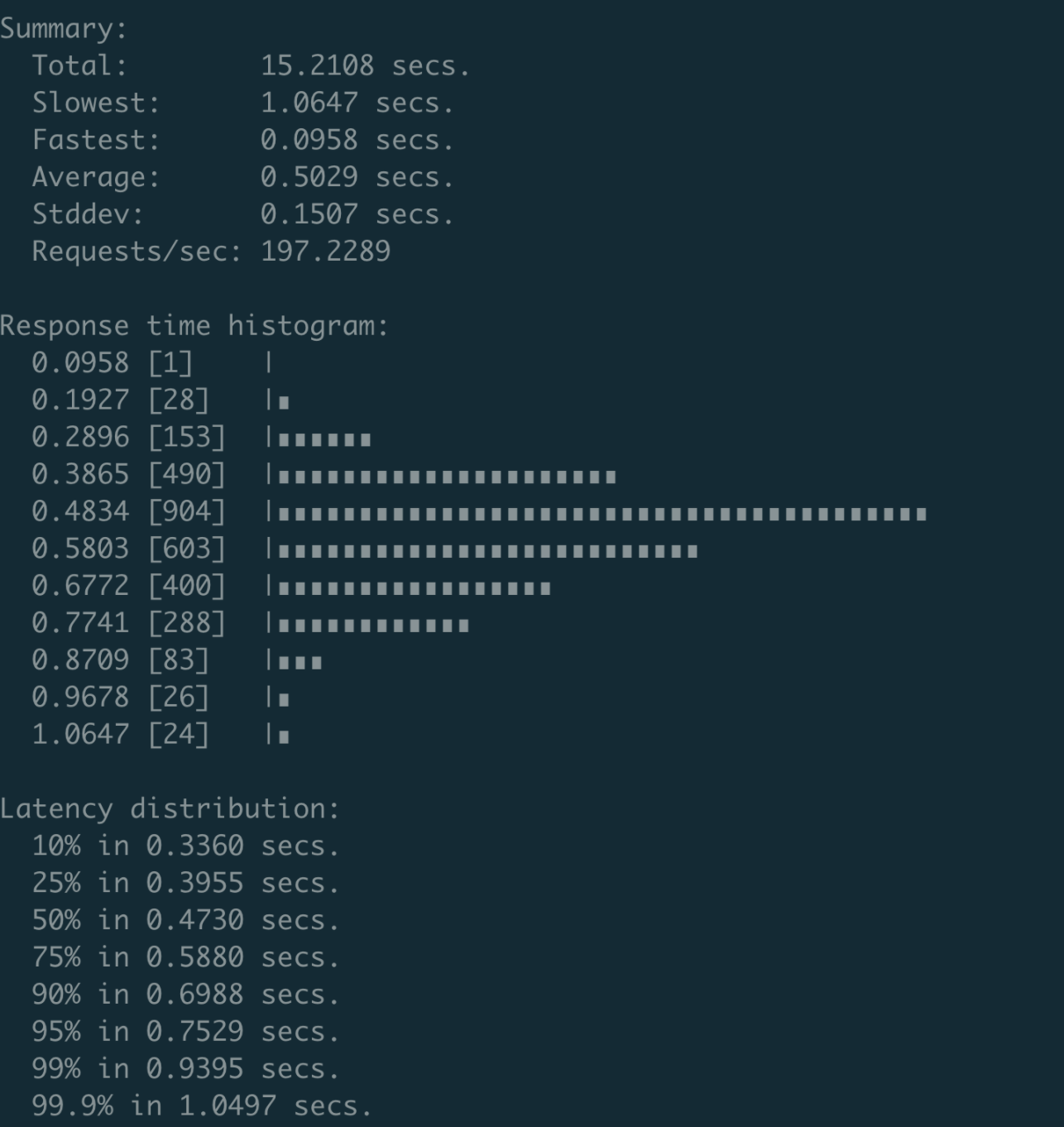
对此,我和小伙伴王超凡通过一个减少锁的范围PR(该PR已经cherry-pick到了etcd 3.4.9版本),将性能优化到了约200 QPS,并且P99延时在1秒内,如下图所示。
由于导致Authenticate接口性能差的核心瓶颈,是在于密码鉴权使用了bcrpt计算hash值,因此Authenticate性能已接近极限。
最令人头疼的是,Auenticate的调用由clientv3库默默发起的,etcd中也没有任何日志记录其耗时等。当大家开启密码鉴权后,遇到读写接口超时的时候,未详细了解etcd的同学就会非常困惑,很难定位超时本质原因。
我曾多次收到小伙伴的求助,协助他们排查etcd异常超时问题。通过metrics定位,我发现这些问题大都是由比较频繁的Authenticate调用导致,只要临时关闭鉴权或升级到etcd v3.4.9版本就可以恢复。
为了帮助大家快速发现Authenticate等特殊类型的expensive request,我在etcd 3.5版本中提交了一个PR,通过gRPC拦截器的机制,当一个请求超过300ms时,就会打印整个请求信息。
讲到这里,你应该会有疑问,密码鉴权的性能如此差,可是业务又需要使用它,我们该怎么解决密码鉴权的性能问题呢?对此,我有三点建议。
第一,如果你的生产环境需要开启鉴权,并且读写QPS较大,那我建议你不要图省事使用密码鉴权。最好使用证书鉴权,这样能完美避坑认证性能差、token过期等问题,性能几乎无损失。
第二,确保你的业务每次发起请求时有复用token机制,尽可能减少Authenticate RPC调用。
第三,如果你使用密码鉴权时遇到性能瓶颈问题,可将etcd升级到3.4.9及以上版本,能适当提升密码鉴权的性能。
选择合适的读模式
client通过server的鉴权后,就可以发起读请求调用了,也就是我们图中的流程三。
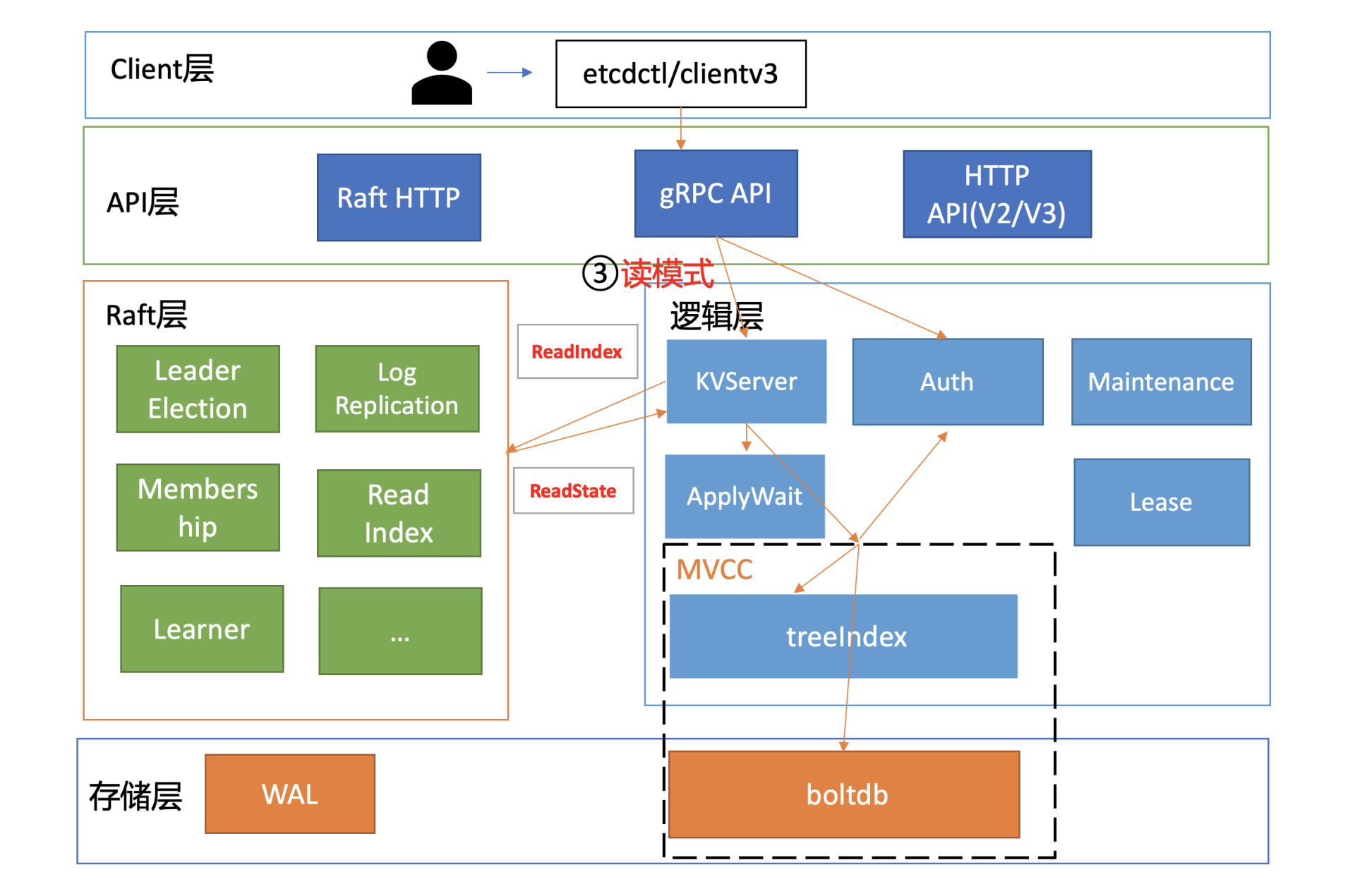
在这个步骤中,读模式对性能有着至关重要的影响。我们前面讲过etcd提供了串行读和线性读两种读模式。前者因为不经过ReadIndex模块,具有低延时、高吞吐量的特点;而后者在牺牲一点延时和吞吐量的基础上,实现了数据的强一致性读。这两种读模式分别为不同场景的读提供了解决方案。
关于串行读和线性读的性能对比,下图我给出了一个测试结果,测试环境如下:
- 机器配置client 16核32G,三个server节点8核16G、SSD盘,client与server节点都在同可用区;
- 各节点之间RTT在0.1ms到0.2ms之间;
- etcd v3.4.9版本;
- 1000个client。
执行如下串行读压测命令:
benchmark --endpoints=addr --conns=100 --clients=1000 \
range hello --consistency=s --total=500000
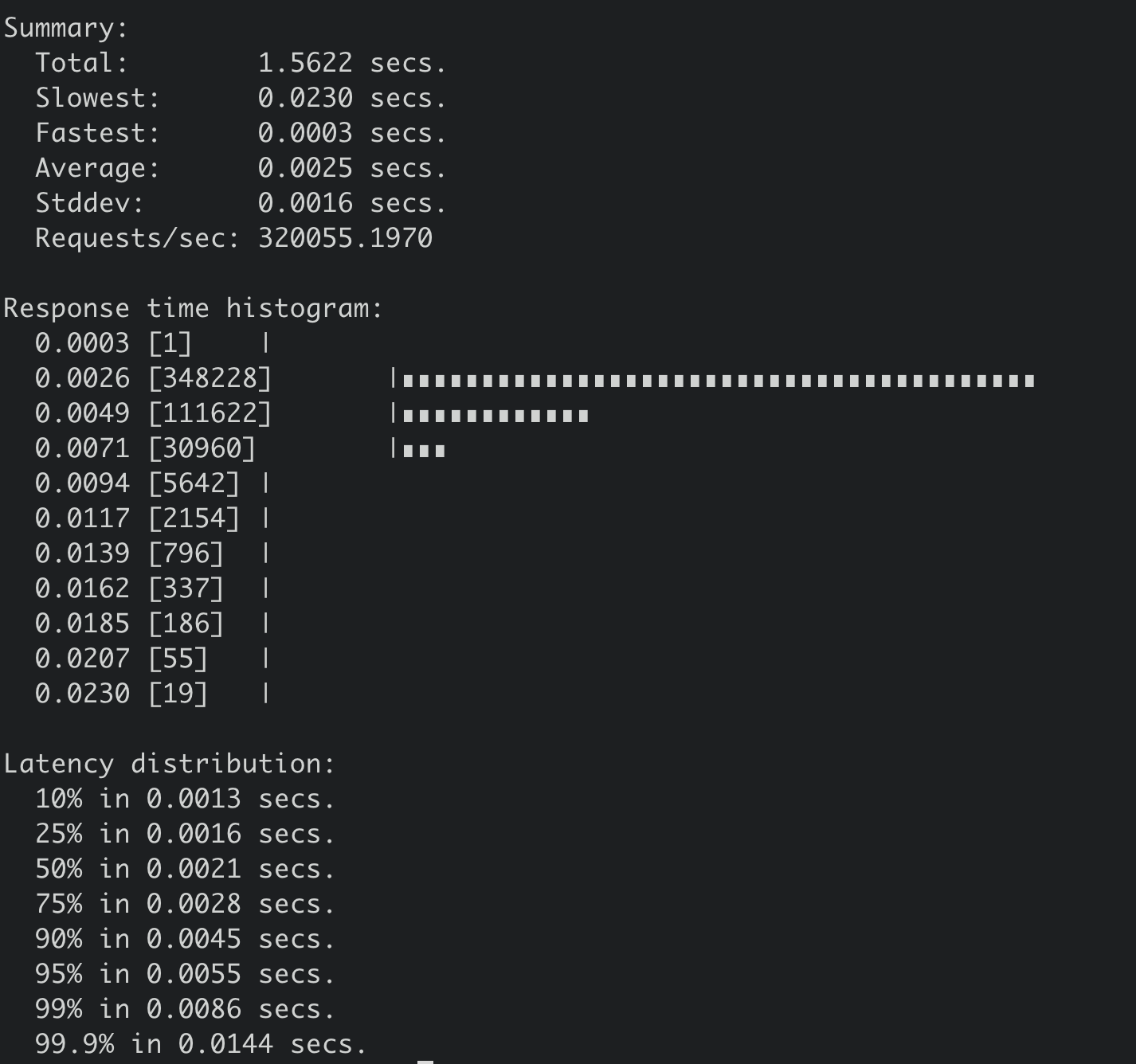
得到串行读压测结果如下,32万 QPS,平均延时2.5ms。
执行如下线性读压测命令:
benchmark --endpoints=addr --conns=100 --clients=1000 \
range hello --consistency=l --total=500000
得到线性读压测结果如下,19万 QPS,平均延时4.9ms。
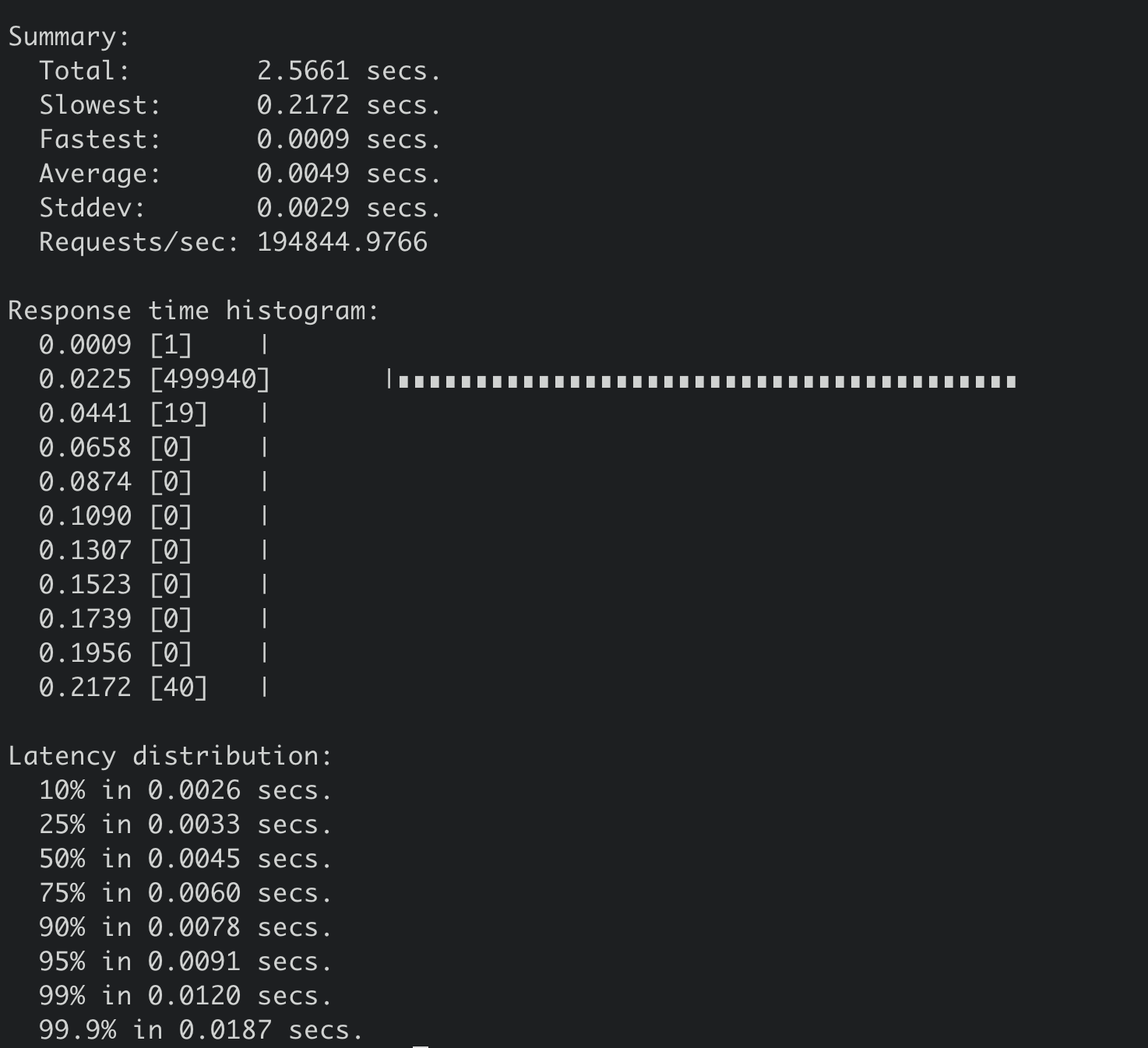
从两个压测结果图中你可以看到,在100个连接时,串行读性能比线性读性能高近11万/s,串行读请求延时(2.5ms)比线性读延时约低一半(4.9ms)。
**需要注意的是,以上读性能数据是在1个key、没有任何写请求、同可用区的场景下压测出来的,实际的读性能会随着你的写请求增多而出现显著下降,这也是实际业务场景性能与社区压测结果存在非常大差距的原因之一。**所以,我建议你使用etcd benchmark工具在你的etcd集群环境中自测一下,你也可以参考下面的etcd社区压测结果。
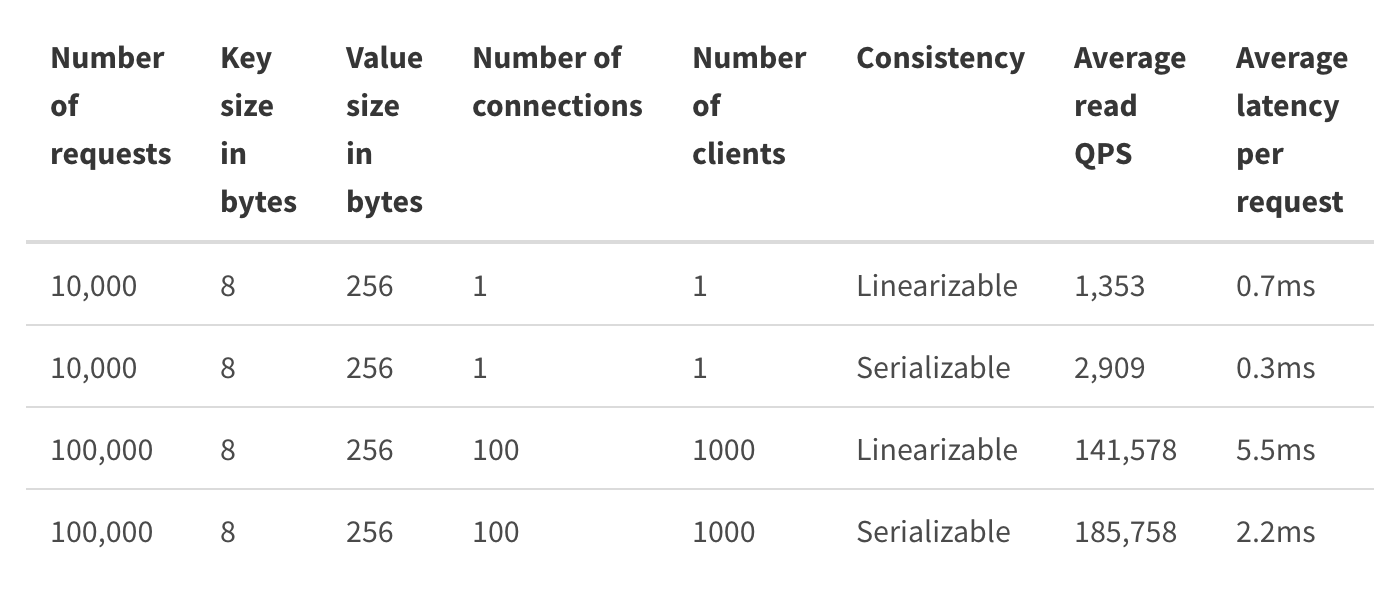
如果你的业务场景读QPS较大,但是你又不想通过etcd proxy等机制来扩展性能,那你可以进一步评估业务场景对数据一致性的要求高不高。如果你可以容忍短暂的不一致,那你可以通过串行读来提升etcd的读性能,也可以部署Learner节点给可能会产生expensive read request的业务使用,实现cheap/expensive read request隔离。
线性读实现机制、网络延时
了解完读模式对性能的影响后,我们继续往下分析。在我们这个密码鉴权读请求的性能分析案例中,读请求使用的是etcd默认线性读模式。线性读对应图中的流程四、流程五,其中流程四对应的是ReadIndex,流程五对应的是等待本节点数据追上Leader的进度(ApplyWait)。
在早期的etcd 3.0版本中,etcd线性读是基于Raft log read实现的。每次读请求要像写请求一样,生成一个Raft日志条目,然后提交给Raft一致性模块处理,基于Raft日志执行的有序性来实现线性读。因为该过程需要经过磁盘I/O,所以性能较差。
为了解决Raft log read的线性读性能瓶颈,etcd 3.1中引入了ReadIndex。ReadIndex仅涉及到各个节点之间网络通信,因此节点之间的RTT延时对其性能有较大影响。虽然同可用区可获取到最佳性能,但是存在单可用区故障风险。如果你想实现高可用区容灾的话,那就必须牺牲一点性能了。
跨可用区部署时,各个可用区之间延时一般在2毫秒内。如果跨城部署,服务性能就会下降较大。所以一般场景下我不建议你跨城部署,你可以通过Learner节点实现异地容灾。如果异地的服务对数据一致性要求不高,那么你甚至可以通过串行读访问Learner节点,来实现就近访问,低延时。
各个节点之间的RTT延时,是决定流程四ReadIndex性能的核心因素之一。
磁盘IO性能、写QPS
到了流程五,影响性能的核心因素就是磁盘IO延时和写QPS。
如下面代码所示,流程五是指节点从Leader获取到最新已提交的日志条目索引(rs.Index)后,它需要等待本节点当前已应用的Raft日志索引,大于等于Leader的已提交索引,确保能在本节点状态机中读取到最新数据。
if ai := s.getAppliedIndex(); ai < rs.Index {select {case <-s.applyWait.Wait(rs.Index):case <-s.stopping:return}
}
// unblock all l-reads requested at indices before rs.Index
nr.notify(nil)
而应用已提交日志条目到状态机的过程中又涉及到随机写磁盘,详情可参考我们03中介绍过etcd的写请求原理。
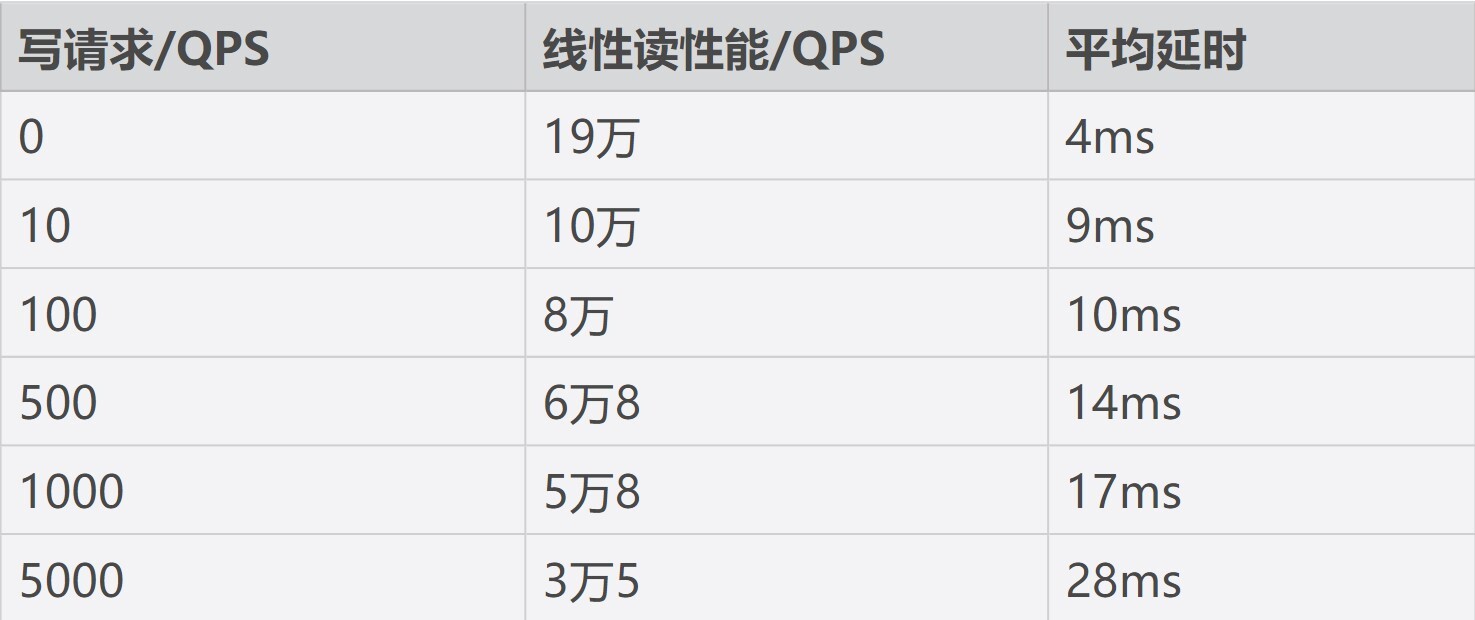
因此我们可以知道,etcd是一个对磁盘IO性能非常敏感的存储系统,磁盘IO性能不仅会影响Leader稳定性、写性能表现,还会影响读性能。线性读性能会随着写性能的增加而快速下降。如果业务对性能、稳定性有较大要求,我建议你尽量使用SSD盘。
下表我给出了一个8核16G的三节点集群,在总key数只有一个的情况下,随着写请求增大,线性读性能下降的趋势总结(基于benchmark工具压测结果),你可以直观感受下读性能是如何随着写性能下降。
当本节点已应用日志条目索引大于等于Leader已提交的日志条目索引后,读请求就会接到通知,就可通过MVCC模块获取数据。
RBAC规则数、Auth锁
读请求到了MVCC模块后,首先要通过鉴权模块判断此用户是否有权限访问请求的数据路径,也就是流程六。影响流程六的性能因素是你的RBAC规则数和锁。
首先是RBAC规则数,为了解决快速判断用户对指定key范围是否有权限,etcd为每个用户维护了读写权限区间树。基于区间树判断用户访问的范围是否在用户的读写权限区间内,时间复杂度仅需要O(logN)。
另外一个因素则是AuthStore的锁。在etcd 3.4.9之前的,校验密码接口可能会占用较长时间的锁,导致授权接口阻塞。etcd 3.4.9之后合入了缩小锁范围的PR,可一定程度降低授权接口被阻塞的问题。
expensive request、treeIndex锁
通过流程六的授权后,则进入流程七,从treeIndex中获取整个查询涉及的key列表版本号信息。在这个流程中,影响其性能的关键因素是treeIndex的总key数、查询的key数、获取treeIndex锁的耗时。
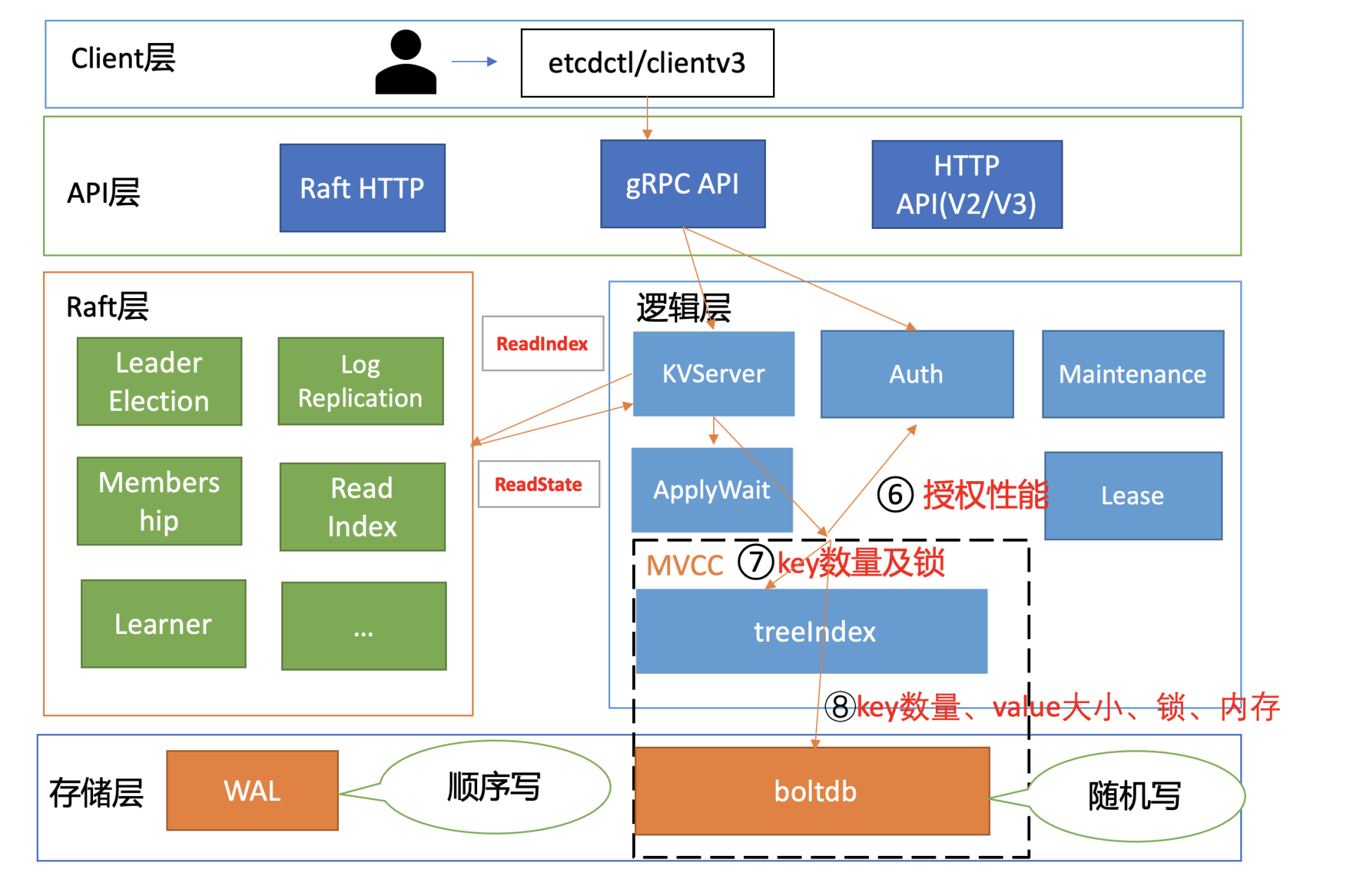
首先,treeIndex中总key数过多会适当增大我们遍历的耗时。
其次,若要访问treeIndex我们必须获取到锁,但是可能其他请求如compact操作也会获取锁。早期的时候,它需要遍历所有索引,然后进行数据压缩工作。这就会导致其他请求阻塞,进而增大延时。
为了解决这个性能问题,优化方案是compact的时候会将treeIndex克隆一份,以空间来换时间,尽量降低锁阻塞带来的超时问题。
接下来我重点给你介绍下查询key数较多等expensive read request时对性能的影响。
假设我们链路分析图中的请求是查询一个Kubernetes集群所有Pod,当你Pod数一百以内的时候可能对etcd影响不大,但是当你Pod数千甚至上万的时候, 流程七、八就会遍历大量的key,导致请求耗时突增、内存上涨、性能急剧下降。你可结合13db大小、14延时、15内存三节一起看看,这里我就不再重复描述。
如果业务就是有这种expensive read request逻辑,我们该如何应对呢?
首先我们可以尽量减少expensive read request次数,在程序启动的时候,只List一次全量数据,然后通过etcd Watch机制去获取增量变更数据。比如Kubernetes的Informer机制,就是典型的优化实践。
其次,在设计上评估是否能进行一些数据分片、拆分等,不同场景使用不同的etcd prefix前缀。比如在Kubernetes中,不要把Pod全部都部署在default命名空间下,尽量根据业务场景按命名空间拆分部署。即便每个场景全量拉取,也只需要遍历自己命名空间下的资源,数据量上将下降一个数量级。
再次,如果你觉得Watch改造大、数据也无法分片,开发麻烦,你可以通过分页机制按批拉取,尽量减少一次性拉取数万条数据。
最后,如果以上方式都不起作用的话,你还可以通过引入cache实现缓存expensive read request的结果,不过应用需维护缓存数据与etcd的一致性。
大key-value、boltdb锁
从流程七获取到key列表及版本号信息后,我们就可以访问boltdb模块,获取key-value信息了。在这个流程中,影响其性能表现的,除了我们上面介绍的expensive read request,还有大key-value和锁。
首先是大key-value。我们知道etcd设计上定位是个小型的元数据存储,它没有数据分片机制,默认db quota只有2G,实践中往往不会超过8G,并且针对每个key-value大小,它也进行了大小限制,默认是1.5MB。
大key-value非常容易导致etcd OOM、server 节点出现丢包、性能急剧下降等。
那么当我们往etcd集群写入一个1MB的key-value时,它的线性读性能会从17万QPS具体下降到多少呢?
我们可以执行如下benchmark命令:
benchmark --endpoints=addr --conns=100 --clients=1000 \
range key --consistency=l --total=10000
得到其结果如下,从下图你可以看到,读取一个1MB的key-value,线性读性能QPS下降到1163,平均延时上升到818ms,可见大key-value对性能的巨大影响。
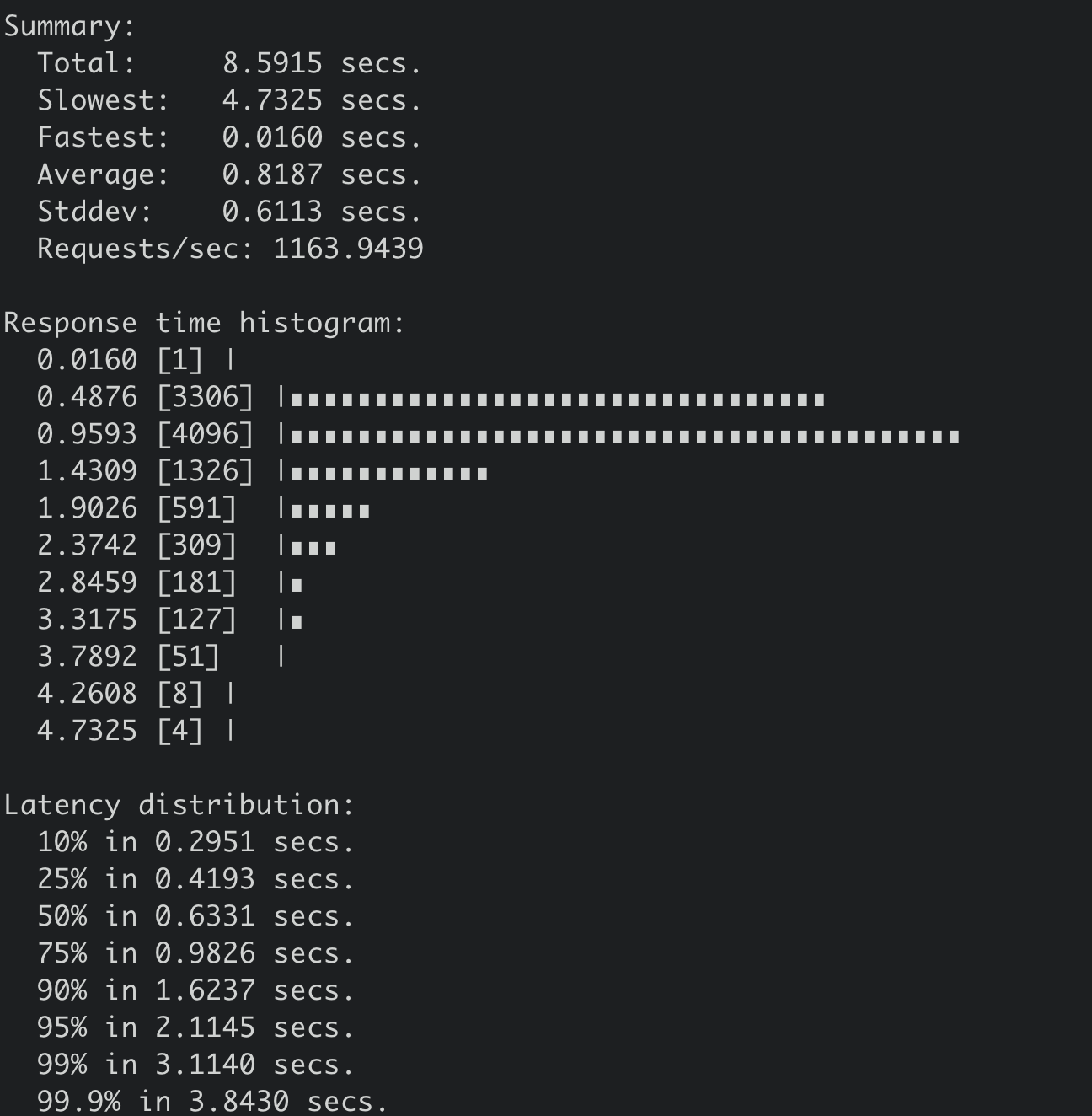
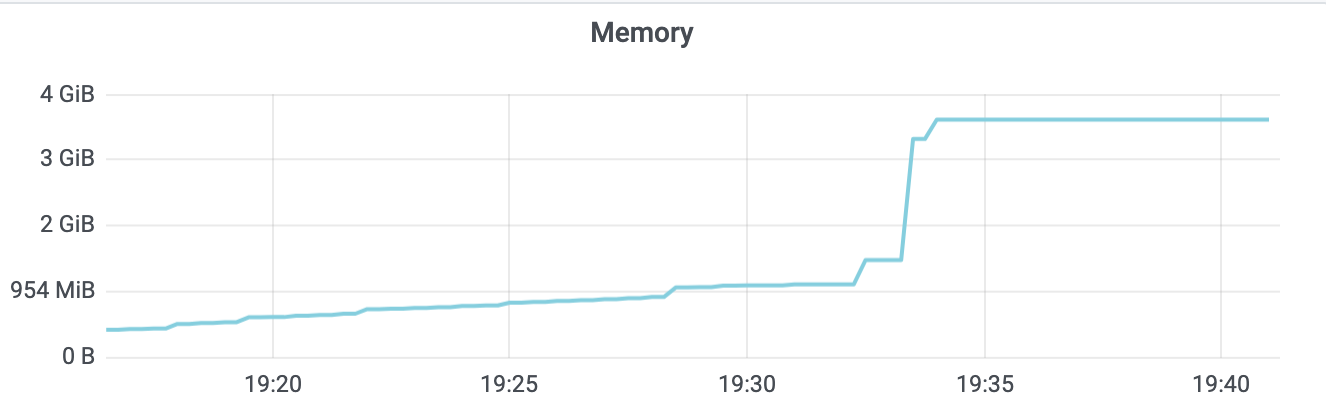
同时,从下面的etcd监控图上你也可以看到内存出现了突增,若存在大量大key-value时,可想而知,etcd内存肯定暴涨,大概率会OOM。
其次是锁,etcd为了提升boltdb读的性能,从etcd 3.1到etcd 3.4版本,分别进行过几次重大优化,在下一节中我将和你介绍。
以上就是一个开启密码鉴权场景,线性读请求的性能瓶颈分析过程。
小结
今天我通过从上至下的请求流程分析,介绍了各个流程中可能存在的瓶颈和优化方法、最佳实践等。
优化读性能的核心思路是首先我们可通过etcd clientv3自带的Round-robin负载均衡算法或者Load Balancer,尽量确保整个集群负载均衡。
然后,在开启鉴权场景时,建议你尽量使用证书而不是密码认证,避免校验密码的昂贵开销。
其次,根据业务场景选择合适的读模式,串行读比线性度性能提高30%以上,延时降低一倍。线性读性能受节点之间RTT延时、磁盘IO延时、当前写QPS等多重因素影响。
最容易被大家忽视的就是写QPS对读QPS的影响,我通过一系列压测数据,整理成一个表格,让你更直观感受写QPS对读性能的影响。多可用区部署会导致节点RTT延时增高,读性能下降。因此你需要在高可用和高性能上做取舍和平衡。
最后在访问数据前,你的读性能还可能会受授权性能、expensive read request、treeIndex及boltdb的锁等影响。你需要遵循最佳实践,避免一个请求查询大量key、大key-value等,否则会导致读性能剧烈下降。
希望你通过本文当遇到读etcd性能问题时,能从请求执行链路去分析瓶颈,解决问题,让业务和etcd跑得更稳、更快。
思考题
你在使用etcd过程中遇到了哪些读性能问题?又是如何解决的呢?
17 性能及稳定性(下):如何优化及扩展etcd性能?
我们继续来看如何优化及扩展etcd性能。上一节课里我为你重点讲述了如何提升读的性能,今天我将重点为你介绍如何提升写性能和稳定性,以及如何基于etcd gRPC Proxy扩展etcd性能。
当你使用etcd写入大量key-value数据的时候,是否遇到过etcd server返回”etcdserver: too many requests”错误?这个错误是怎么产生的呢?我们又该如何来优化写性能呢?
这节课我将通过写性能分析链路图,为你从上至下分析影响写性能、稳定性的若干因素,并为你总结出若干etcd写性能优化和扩展方法。
性能分析链路
为什么你写入大量key-value数据的时候,会遇到Too Many Request限速错误呢? 是写流程中的哪些环节出现了瓶颈?
和读请求类似,我为你总结了一个开启鉴权场景的写性能瓶颈及稳定性分析链路图,并在每个核心步骤数字旁边标识了影响性能、稳定性的关键因素。
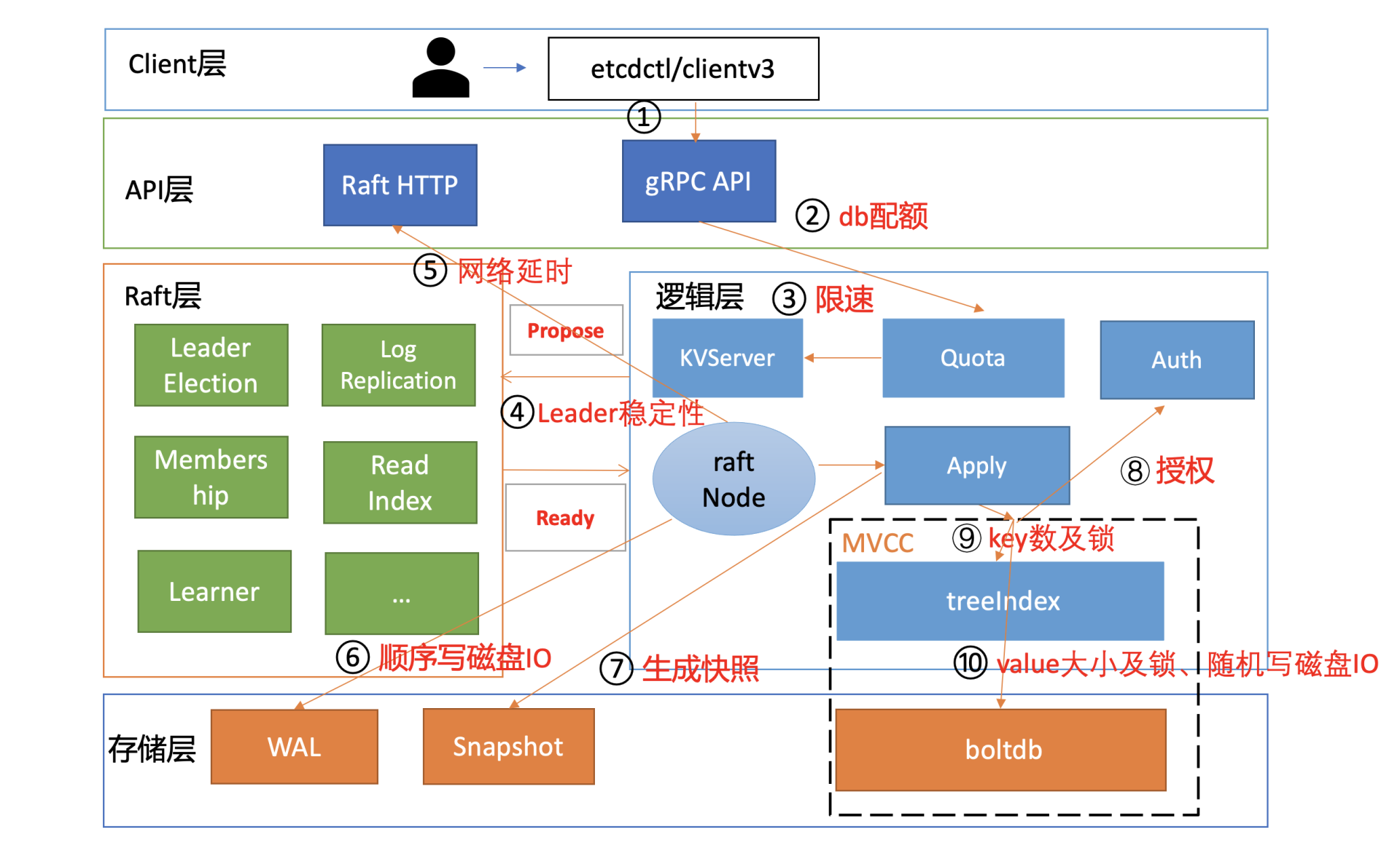
下面我将按照这个写请求链路分析图,和你深入分析影响etcd写性能的核心因素和最佳优化实践。
db quota
首先是流程一。在etcd v3.4.9版本中,client会通过clientv3库的Round-robin负载均衡算法,从endpoint列表中轮询选择一个endpoint访问,发起gRPC调用。
然后进入流程二。etcd收到gRPC写请求后,首先经过的是Quota模块,它会影响写请求的稳定性,若db大小超过配额就无法写入。
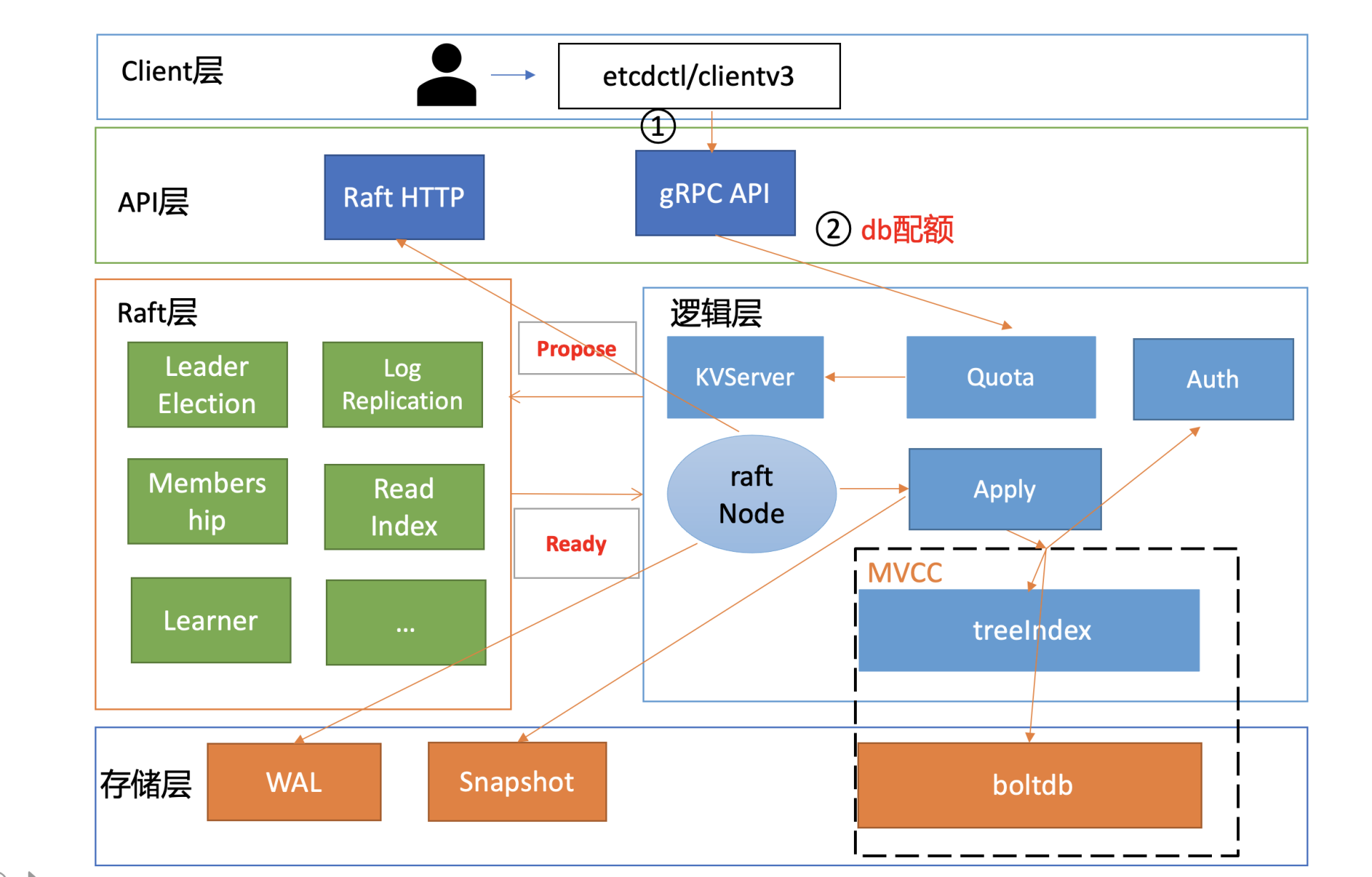
etcd是个小型的元数据存储,默认db quota大小是2G,超过2G就只读无法写入。因此你需要根据你的业务场景,适当调整db quota大小,并配置的合适的压缩策略。
正如我在11里和你介绍的,etcd支持按时间周期性压缩、按版本号压缩两种策略,建议压缩策略不要配置得过于频繁。比如如果按时间周期压缩,一般情况下5分钟以上压缩一次比较合适,因为压缩过程中会加一系列锁和删除boltdb数据,过于频繁的压缩会对性能有一定的影响。
一般情况下db大小尽量不要超过8G,过大的db文件和数据量对集群稳定性各方面都会有一定的影响,详细你可以参考13。
限速
通过流程二的Quota模块后,请求就进入流程三KVServer模块。在KVServer模块里,影响写性能的核心因素是限速。
KVServer模块的写请求在提交到Raft模块前,会进行限速判断。如果Raft模块已提交的日志索引(committed index)比已应用到状态机的日志索引(applied index)超过了5000,那么它就返回一个”etcdserver: too many requests”错误给client。
那么哪些情况可能会导致committed Index远大于applied index呢?
首先是long expensive read request导致写阻塞。比如etcd 3.4版本之前长读事务会持有较长时间的buffer读锁,而写事务又需要升级锁更新buffer,因此出现写阻塞乃至超时。最终导致etcd server应用已提交的Raft日志命令到状态机缓慢。堆积过多时,则会触发限速。
其次etcd定时批量将boltdb写事务提交的时候,需要对B+ tree进行重平衡、分裂,并将freelist、dirty page、meta page持久化到磁盘。此过程需要持有boltdb事务锁,若磁盘随机写性能较差、瞬间大量写入,则也容易写阻塞,应用已提交的日志条目缓慢。
最后执行defrag等运维操作时,也会导致写阻塞,它们会持有相关锁,导致写性能下降。
心跳及选举参数优化
写请求经过KVServer模块后,则会提交到流程四的Raft模块。我们知道etcd写请求需要转发给Leader处理,因此影响此模块性能和稳定性的核心因素之一是集群Leader的稳定性。
那如何判断Leader的稳定性呢?
答案是日志和metrics。
一方面,在你使用etcd过程中,你很可能见过如下Leader发送心跳超时的警告日志,你可以通过此日志判断集群是否有频繁切换Leader的风险。
另一方面,你可以通过etcd_server_leader_changes_seen_total metrics来观察已发生Leader切换的次数。
21:30:27 etcd3 | {"level":"warn","ts":"2021-02-23T21:30:27.255+0800","caller":"wal/wal.go:782","msg":"slow fdatasync","took":"3.259857956s","expected-duration":"1s"}
21:30:30 etcd3 | {"level":"warn","ts":"2021-02-23T21:30:30.396+0800","caller":"etcdserver/raft.go:390","msg":"leader failed to send out heartbeat on time; took too long, leader is overloaded likely from slow disk","to":"91bc3c398fb3c146","heartbeat-interval":"100ms","expected-duration":"200ms","exceeded-duration":"827.162111ms"}
那么哪些因素会导致此日志产生以及发生Leader切换呢?
首先,我们知道etcd是基于Raft协议实现数据复制和高可用的,各节点会选出一个Leader,然后Leader将写请求同步给各个Follower节点。而Follower节点如何感知Leader异常,发起选举,正是依赖Leader的心跳机制。
在etcd中,Leader节点会根据heartbeart-interval参数(默认100ms)定时向Follower节点发送心跳。如果两次发送心跳间隔超过2*heartbeart-interval,就会打印此警告日志。超过election timeout(默认1000ms),Follower节点就会发起新一轮的Leader选举。
哪些原因会导致心跳超时呢?
一方面可能是你的磁盘IO比较慢。因为etcd从Raft的Ready结构获取到相关待提交日志条目后,它需要将此消息写入到WAL日志中持久化。你可以通过观察etcd_wal_fsync_durations_seconds_bucket指标来确定写WAL日志的延时。若延时较大,你可以使用SSD硬盘解决。
另一方面也可能是CPU使用率过高和网络延时过大导致。CPU使用率较高可能导致发送心跳的goroutine出现饥饿。若etcd集群跨地域部署,节点之间RTT延时大,也可能会导致此问题。
最后我们应该如何调整心跳相关参数,以避免频繁Leader选举呢?
etcd默认心跳间隔是100ms,较小的心跳间隔会导致发送频繁的消息,消耗CPU和网络资源。而较大的心跳间隔,又会导致检测到Leader故障不可用耗时过长,影响业务可用性。一般情况下,为了避免频繁Leader切换,建议你可以根据实际部署环境、业务场景,将心跳间隔时间调整到100ms到400ms左右,选举超时时间要求至少是心跳间隔的10倍。
网络和磁盘IO延时
当集群Leader稳定后,就可以进入Raft日志同步流程。
我们假设收到写请求的节点就是Leader,写请求通过Propose接口提交到Raft模块后,Raft模块会输出一系列消息。
etcd server的raftNode goroutine通过Raft模块的输出接口Ready,获取到待发送给Follower的日志条目追加消息和待持久化的日志条目。
raftNode goroutine首先通过HTTP协议将日志条目追加消息广播给各个Follower节点,也就是流程五。
流程五涉及到各个节点之间网络通信,因此节点之间RTT延时对其性能有较大影响。跨可用区、跨地域部署时性能会出现一定程度下降,建议你结合实际网络环境使用benchmark工具测试一下。etcd Raft网络模块在实现上,也会通过流式发送和pipeline等技术优化来降低延时、提高网络性能。
同时,raftNode goroutine也会将待持久化的日志条目追加到WAL中,它可以防止进程crash后数据丢失,也就是流程六。注意此过程需要同步等待数据落地,因此磁盘顺序写性能决定着性能优异。
为了提升写吞吐量,etcd会将一批日志条目批量持久化到磁盘。etcd是个对磁盘IO延时非常敏感的服务,如果服务对性能、稳定性有较大要求,建议你使用SSD盘。
那使用SSD盘的etcd集群和非SSD盘的etcd集群写性能差异有多大呢?
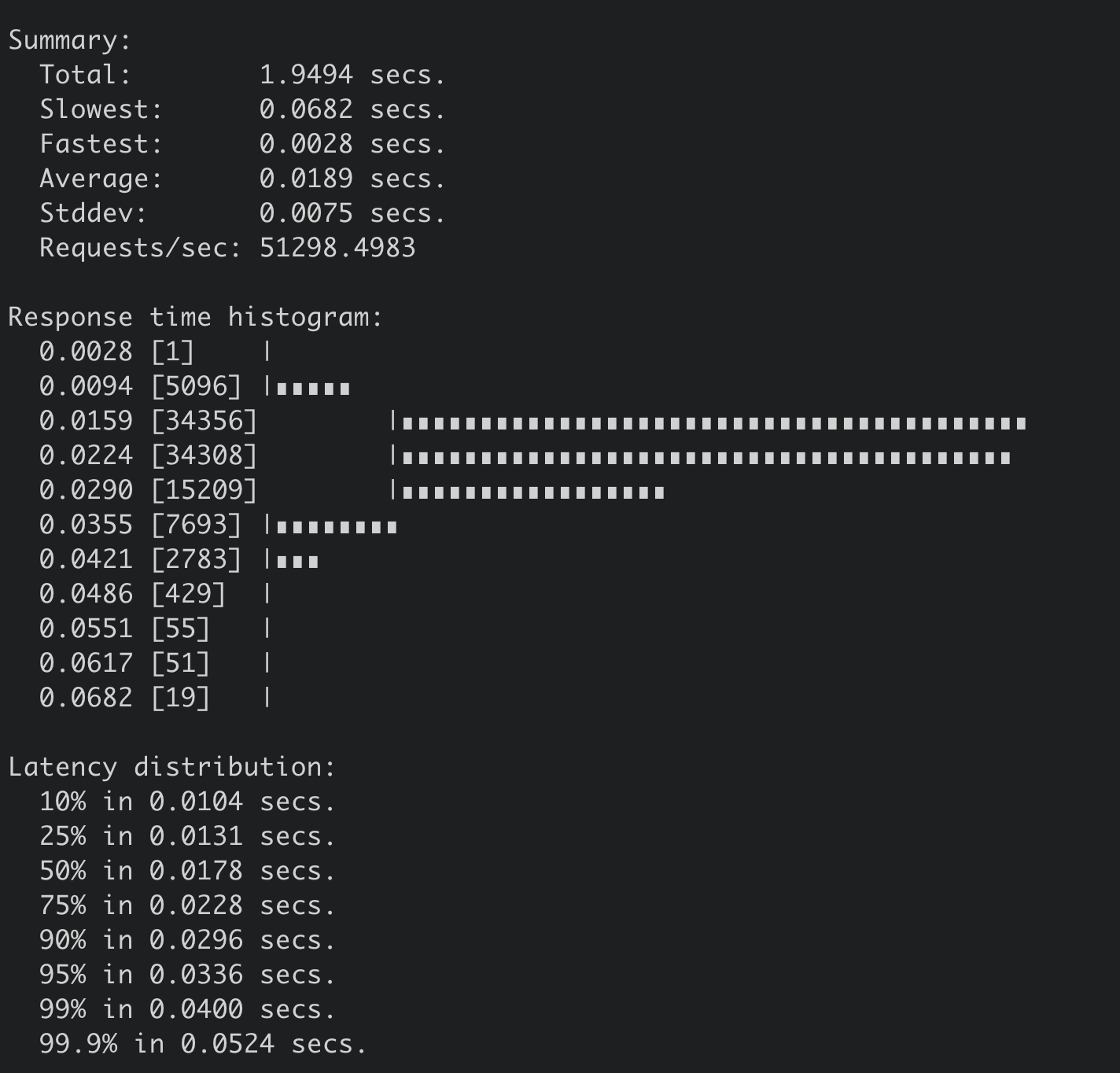
下面是SSD盘集群,执行如下benchmark命令的压测结果,写QPS 51298,平均延时189ms。
benchmark --endpoints=addr --conns=100 --clients=1000 \put --key-size=8 --sequential-keys --total=10000000 --
val-size=256
下面是非SSD盘集群,执行同样benchmark命令的压测结果,写QPS 35255,平均延时279ms。
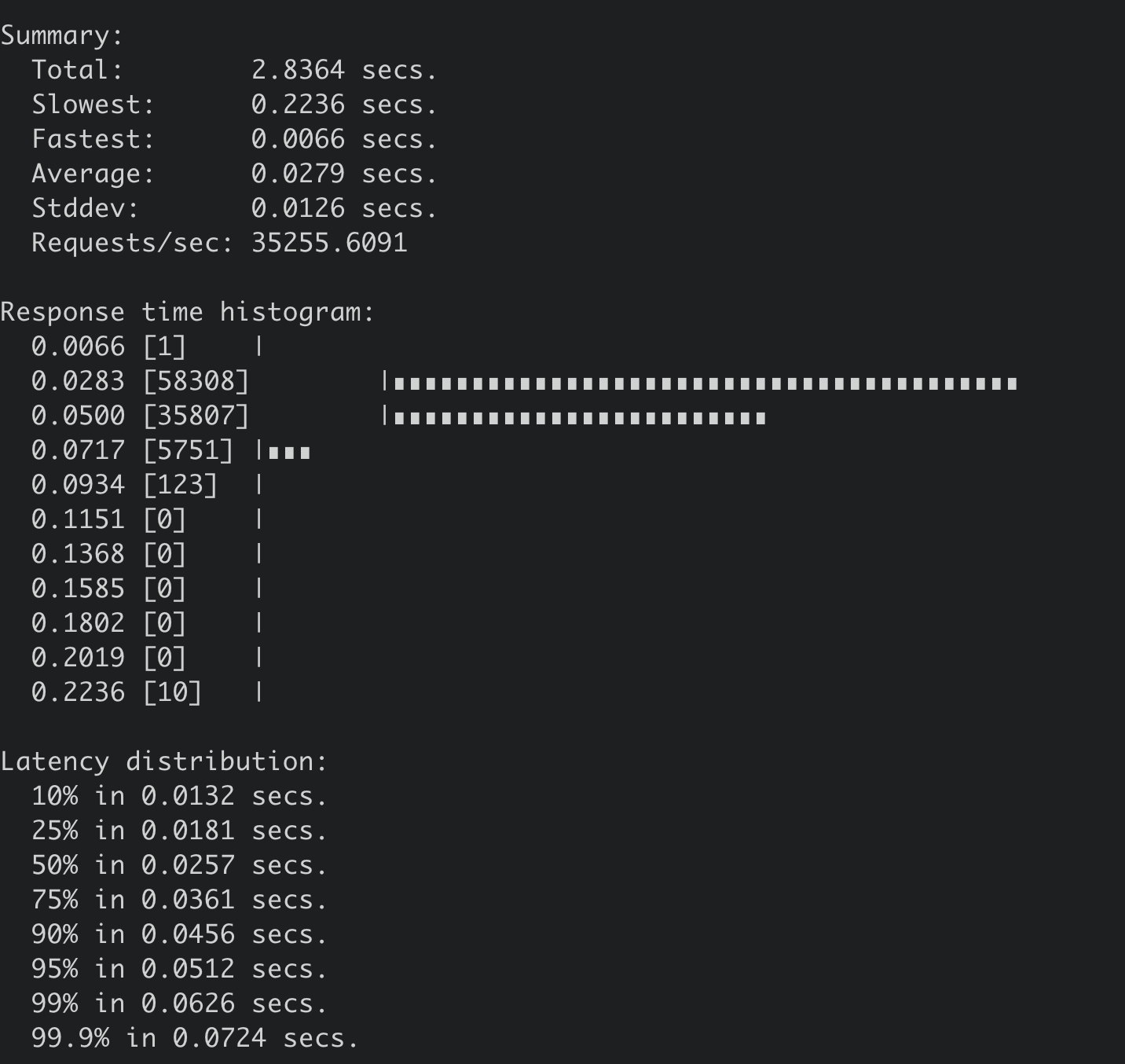
快照参数优化
在Raft模块中,正常情况下,Leader可快速地将我们的key-value写请求同步给其他Follower节点。但是某Follower节点若数据落后太多,Leader内存中的Raft日志已经被compact了,那么Leader只能发送一个快照给Follower节点重建恢复。
在快照较大的时候,发送快照可能会消耗大量的CPU、Memory、网络资源,那么它就会影响我们的读写性能,也就是我们图中的流程七。
一方面, etcd Raft模块引入了流控机制,来解决日志同步过程中可能出现的大量资源开销、导致集群不稳定的问题。
另一方面,我们可以通过快照参数优化,去降低Follower节点通过Leader快照重建的概率,使其尽量能通过增量的日志同步保持集群的一致性。
etcd提供了一个名为–snapshot-count的参数来控制快照行为。它是指收到多少个写请求后就触发生成一次快照,并对Raft日志条目进行压缩。为了帮助slower Follower赶上Leader进度,etcd在生成快照,压缩日志条目的时候也会至少保留5000条日志条目在内存中。
那snapshot-count参数设置多少合适呢?
snapshot-count值过大它会消耗较多内存,你可以参考15内存篇中Raft日志内存占用分析。过小则的话在某节点数据落后时,如果它请求同步的日志条目Leader已经压缩了,此时我们就不得不将整个db文件发送给落后节点,然后进行快照重建。
快照重建是极其昂贵的操作,对服务质量有较大影响,因此我们需要尽量避免快照重建。etcd 3.2版本之前snapshot-count参数值是1万,比较低,短时间内大量写入就较容易触发慢的Follower节点快照重建流程。etcd 3.2版本后将其默认值调大到10万,老版本升级的时候,你需要注意配置文件是否写死固定的参数值。
大value
当写请求对应的日志条目被集群多数节点确认后,就可以提交到状态机执行了。etcd的raftNode goroutine就可通过Raft模块的输出接口Ready,获取到已提交的日志条目,然后提交到Apply模块的FIFO待执行队列。因为它是串行应用执行命令,任意请求在应用到状态机时阻塞都会导致写性能下降。
当Raft日志条目命令从FIFO队列取出执行后,它会首先通过授权模块校验是否有权限执行对应的写操作,对应图中的流程八。影响其性能因素是RBAC规则数和锁。
然后通过权限检查后,写事务则会从treeIndex模块中查找key、更新的key版本号等信息,对应图中的流程九,影响其性能因素是key数和锁。
更新完索引后,我们就可以把新版本号作为boltdb key, 把用户key/value、版本号等信息组合成一个value,写入到boltdb,对应图中的流程十,影响其性能因素是大value、锁。
如果你在应用中保存1Mb的value,这会给etcd稳定性带来哪些风险呢?
首先会导致读性能大幅下降、内存突增、网络带宽资源出现瓶颈等,上节课我已和你分享过一个1MB的key-value读性能压测结果,QPS从17万骤降到1100多。
那么写性能具体会下降到多少呢?
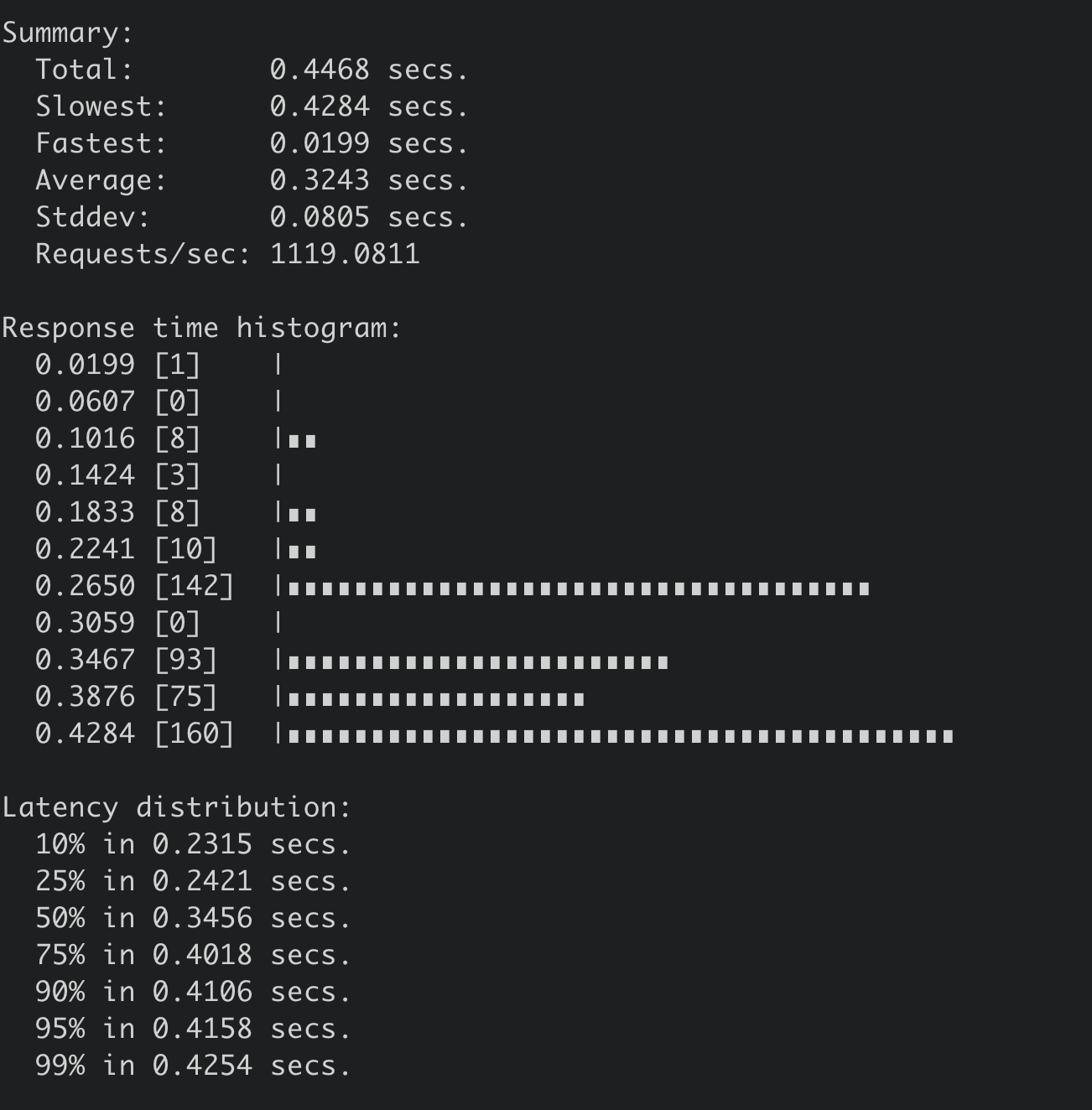
通过benchmark执行如下命令写入1MB的数据时候,集群几乎不可用(三节点8核16G,非SSD盘),事务提交P99延时高达4秒,如下图所示。
benchmark --endpoints=addr --conns=100 --clients=1000 \
put --key-size=8 --sequential-keys --total=500 --val-
size=1024000

因此只能将写入的key-value大小调整为100KB。执行后得到如下结果,写入QPS 仅为1119/S,平均延时高达324ms。
其次etcd底层使用的boltdb存储,它是个基于COW(Copy-on-write)机制实现的嵌入式key-value数据库。较大的value频繁更新,因为boltdb的COW机制,会导致boltdb大小不断膨胀,很容易超过默认db quota值,导致无法写入。
那如何优化呢?
首先,如果业务已经使用了大key,拆分、改造存在一定客观的困难,那我们就从问题的根源之一的写入对症下药,尽量不要频繁更新大key,这样etcd db大小就不会快速膨胀。
你可以从业务场景考虑,判断频繁的更新是否合理,能否做到增量更新。之前遇到一个case, 一个业务定时更新大量key,导致被限速,最后业务通过增量更新解决了问题。
如果写请求降低不了, 就必须进行精简、拆分你的数据结构了。将你需要频繁更新的数据拆分成小key进行更新等,实现将value值控制在合理范围以内,才能让你的集群跑的更稳、更高效。
Kubernetes的Node心跳机制优化就是这块一个非常优秀的实践。早期kubelet会每隔10s上报心跳更新Node资源。但是此资源对象较大,导致db大小不断膨胀,无法支撑更大规模的集群。为了解决这个问题,社区做了数据拆分,将经常变更的数据拆分成非常细粒度的对象,实现了集群稳定性提升,支撑住更大规模的Kubernetes集群。
boltdb锁
了解完大value对集群性能的影响后,我们再看影响流程十的另外一个核心因素boltdb锁。
首先我们回顾下etcd读写性能优化历史,它经历了以下流程:
- 3.0基于Raft log read实现线性读,线性读需要经过磁盘IO,性能较差;
- 3.1基于ReadIndex实现线性读,每个节点只需要向Leader发送ReadIndex请求,不涉及磁盘IO,提升了线性读性能;
- 3.2将访问boltdb的锁从互斥锁优化到读写锁,提升了并发读的性能;
- 3.4实现全并发读,去掉了buffer锁,长尾读几乎不再影响写。
并发读特性的核心原理是创建读事务对象时,它会全量拷贝当前写事务未提交的buffer数据,并发的读写事务不再阻塞在一个buffer资源锁上,实现了全并发读。
最重要的是,写事务也不再因为expensive read request长时间阻塞,有效的降低了写请求的延时,详细测试结果你可以参考并发读特性实现PR,因篇幅关系就不再详细描述。
扩展性能
当然有不少业务场景你即便用最高配的硬件配置,etcd可能还是无法解决你所面临的性能问题。etcd社区也考虑到此问题,提供了一个名为gRPC proxy的组件,帮助你扩展读、扩展watch、扩展Lease性能的机制,如下图所示。
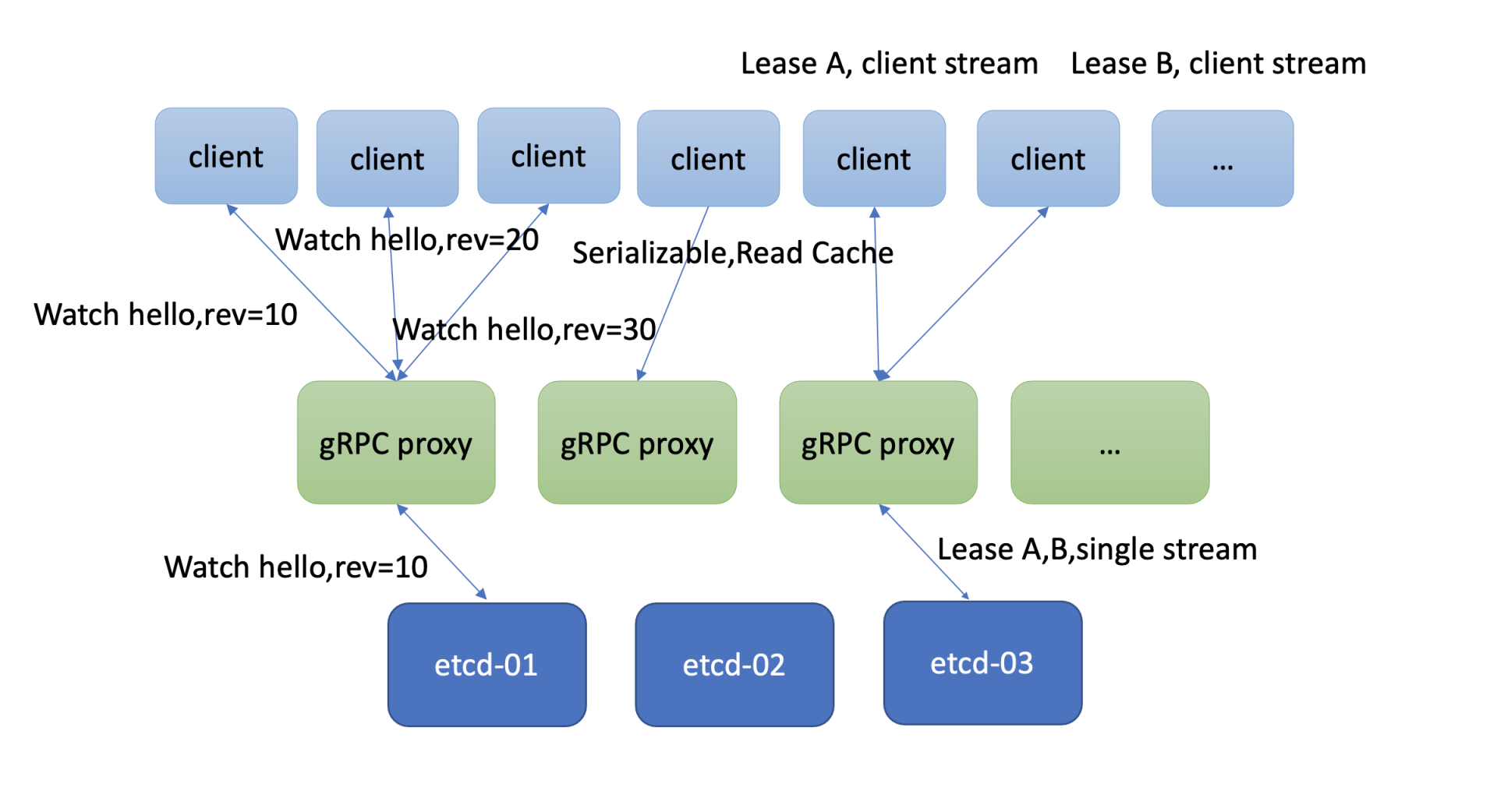
扩展读
如果你的client比较多,etcd集群节点连接数大于2万,或者你想平行扩展串行读的性能,那么gRPC proxy就是良好一个解决方案。它是个无状态节点,为你提供高性能的读缓存的能力。你可以根据业务场景需要水平扩容若干节点,同时通过连接复用,降低服务端连接数、负载。
它也提供了故障探测和自动切换能力,当后端etcd某节点失效后,会自动切换到其他正常节点,业务client可对此无感知。
扩展Watch
大量的watcher会显著增大etcd server的负载,导致读写性能下降。etcd为了解决这个问题,gRPC proxy组件里面提供了watcher合并的能力。如果多个client Watch同key或者范围(如上图三个client Watch同key)时,它会尝试将你的watcher进行合并,降低服务端的watcher数。
然后当它收到etcd变更消息时,会根据每个client实际Watch的版本号,将增量的数据变更版本,分发给你的多个client,实现watch性能扩展及提升。
扩展Lease
我们知道etcd Lease特性,提供了一种客户端活性检测机制。为了确保你的key不被淘汰,client需要定时发送keepalive心跳给server。当Lease非常多时,这就会导致etcd服务端的负载增加。在这种场景下,gRPC proxy提供了keepalive心跳连接合并的机制,来降低服务端负载。
小结
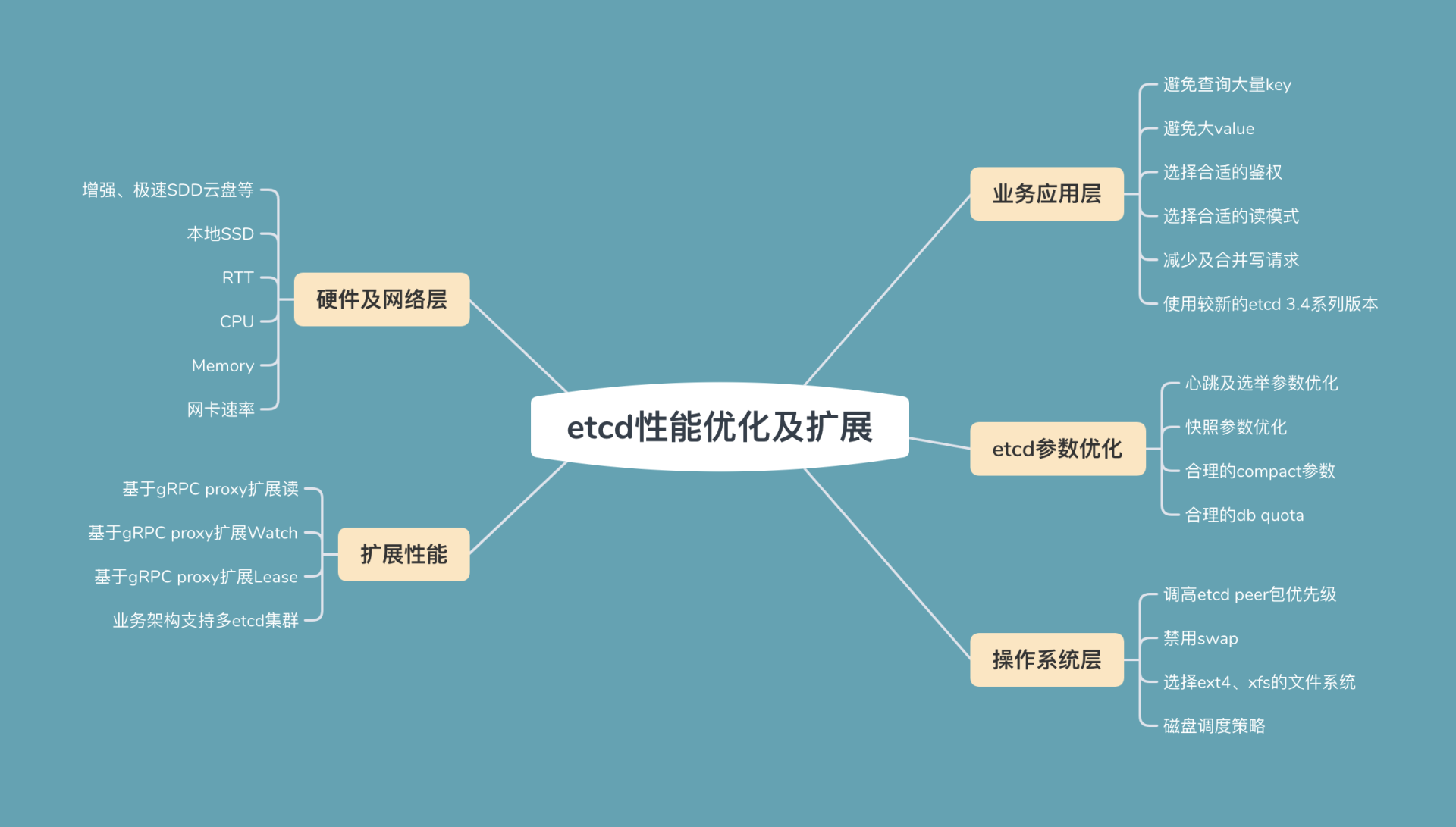
今天我通过从上至下的写请求流程分析,介绍了各个流程中可能存在的瓶颈和优化方法、最佳实践。最后我从分层的角度,为你总结了一幅优化思路全景图,你可以参考一下下面这张图,它将我们这两节课讨论的etcd性能优化、扩展问题分为了以下几类:
- 业务应用层,etcd应用层的最佳实践;
- etcd内核层,etcd参数最佳实践;
- 操作系统层,操作系统优化事项;
- 硬件及网络层,不同的硬件设备对etcd性能有着非常大的影响;
- 扩展性能,基于gRPC proxy扩展读、Watch、Lease的性能。
希望你通过这节课的学习,以后在遇到etcd性能问题时,能分别从请求执行链路和分层的视角去分析、优化瓶颈,让业务和etcd跑得更稳、更快。
思考题
最后,我还给你留了一个思考题。
watcher较多的情况下,会不会对读写请求性能有影响呢?如果会,是在什么场景呢?gRPC proxy能安全的解决watcher较多场景下的扩展性问题吗?
18 实战:如何基于Raft从0到1构建一个支持多存储引擎分布式KV服务?
通过前面课程的学习,我相信你已经对etcd基本架构、核心特性有了一定理解。如果让你基于Raft协议,实现一个简易的类etcd、支持多存储引擎的分布式KV服务,并能满足读多写少、读少写多的不同业务场景诉求,你知道该怎么动手吗?
纸上得来终觉浅,绝知此事要躬行。
今天我就和你聊聊如何实现一个类etcd、支持多存储引擎的KV服务,我们将基于etcd自带的raftexample项目快速构建它。
为了方便后面描述,我把它命名为metcd(表示微型的etcd),它是raftexample的加强版。希望通过metcd这个小小的实战项目,能够帮助你进一步理解etcd乃至分布式存储服务的核心架构、原理、典型问题解决方案。
同时在这个过程中,我将详细为你介绍etcd的Raft算法工程实现库、不同类型存储引擎的优缺点,拓宽你的知识视野,为你独立分析etcd源码,夯实基础。
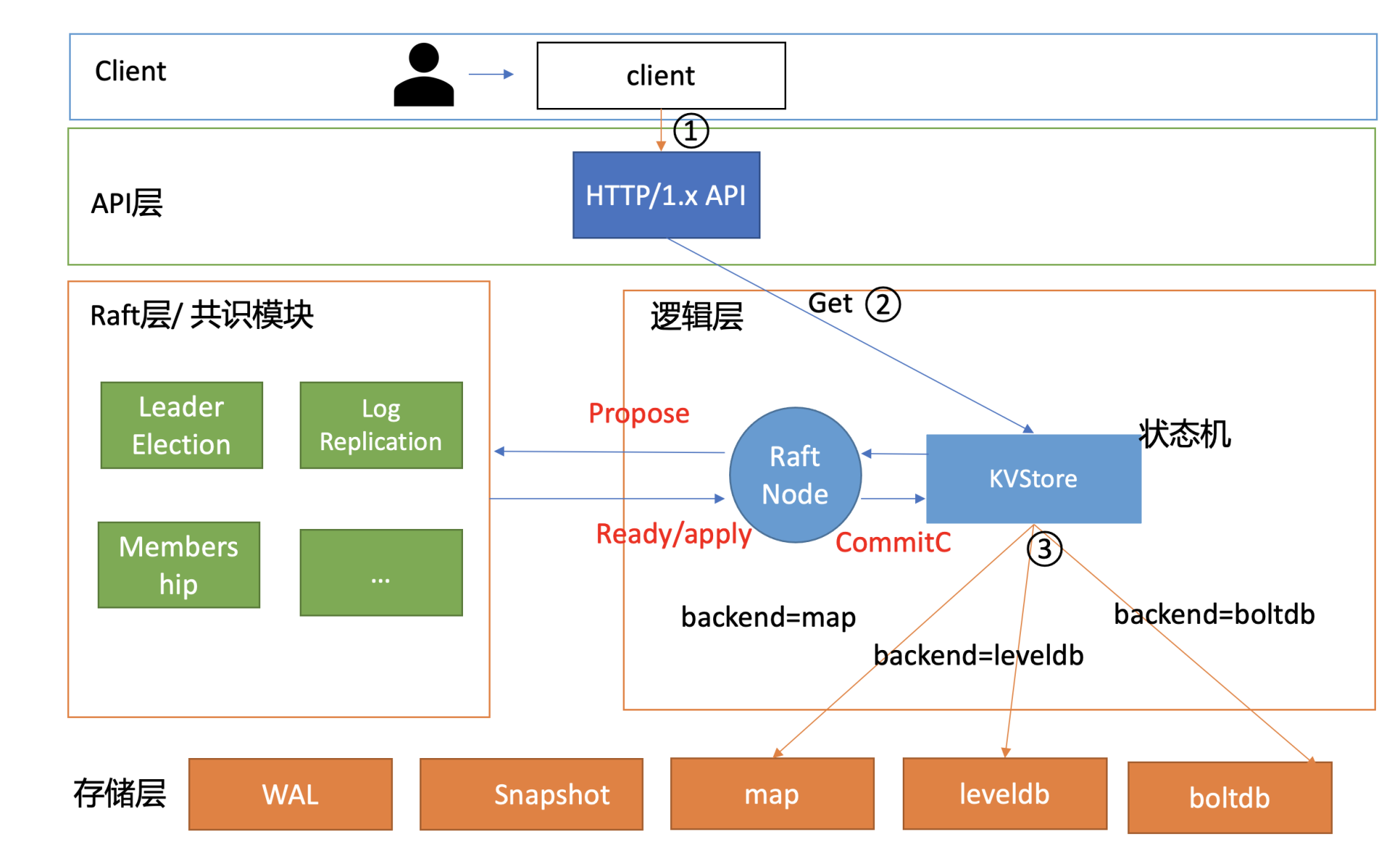
整体架构设计
在和你深入聊代码细节之前,首先我和你从整体上介绍下系统架构。
下面是我给你画的metcd整体架构设计,它由API层、Raft层的共识模块、逻辑层及存储层组成的状态机组成。
接下来,我分别和你简要分析下API设计及复制状态机。
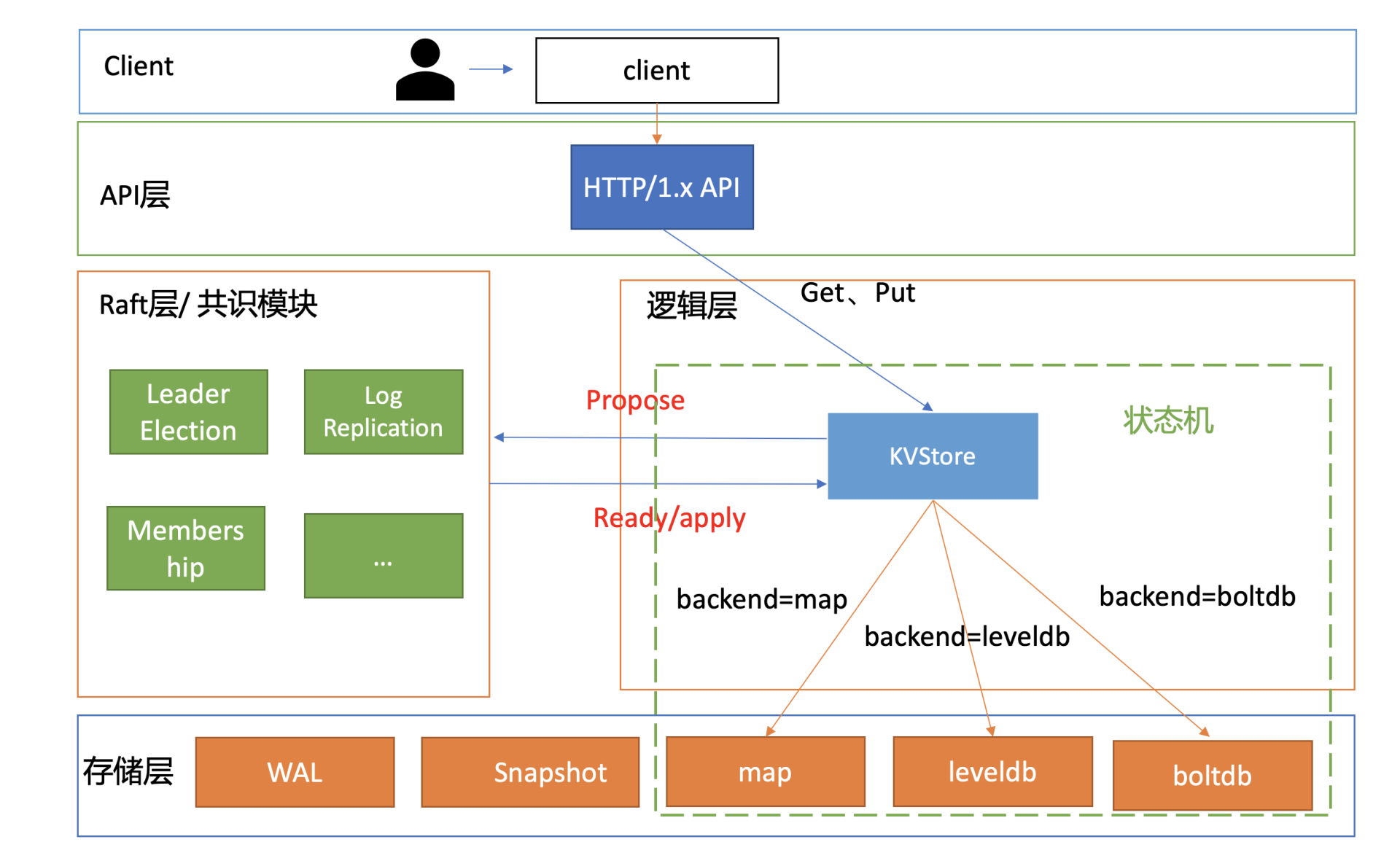
API设计
API是软件系统对外的语言,它是应用编程接口的缩写,由一组接口定义和协议组成。
在设计API的时候,我们往往会考虑以下几个因素:
- 性能。如etcd v2使用的是简单的HTTP/1.x,性能上无法满足大规模Kubernetes集群等场景的诉求,因此etcd v3使用的是基于HTTP/2的gRPC协议。
- 易用性、可调试性。如有的内部高并发服务为了满足性能等诉求,使用的是UDP协议。相比HTTP协议,UDP协议显然在易用性、可调试性上存在一定的差距。
- 开发效率、跨平台、可移植性。相比基于裸UDP、TCP协议设计的接口,如果你使用Protobuf等IDL语言,它支持跨平台、代码自动自动生成,开发效率更高。
- 安全性。如相比HTTP协议,使用HTTPS协议可对通信数据加密更安全,可适用于不安全的网络环境(比如公网传输)。
- 接口幂等性。幂等性简单来说,就是同样一个接口请求一次与多次的效果一样。若你的接口对外保证幂等性,则可降低使用者的复杂度。
因为我们场景的是POC(Proof of concept)、Demo开发,因此在metcd项目中,我们优先考虑点是易用性、可调试性,选择HTTP/1.x协议,接口上为了满足key-value操作,支持Get和Put接口即可。
假设metcd项目使用3379端口,Put和Get接口,如下所示。
- Put接口,设置key-value
curl -L http://127.0.0.1:3379/hello -XPUT -d world
- Get接口,查询key-value
curl -L http://127.0.0.1:3379/hello
world
复制状态机
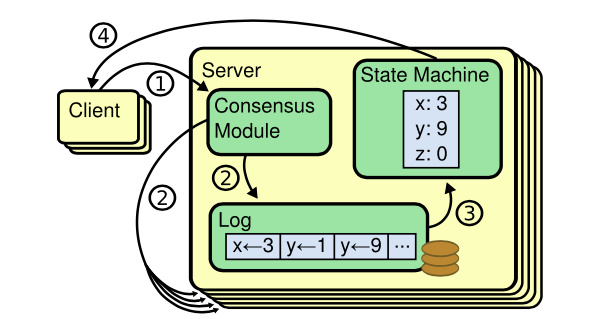
了解完API设计,那最核心的复制状态机是如何工作的呢?
我们知道etcd是基于下图复制状态机实现的分布式KV服务,复制状态机由共识模块、日志模块、状态机组成。
我们的实战项目metcd,也正是使用与之一样的模型,并且使用etcd项目中实现的Raft算法库作为共识模块,此算法库已被广泛应用在etcd、cockroachdb、dgraph等开源项目中。
以下是复制状态机的写请求流程:
- client发起一个写请求(put hello = world);
- server向Raft共识模块提交请求,共识模块生成一个写提案日志条目。若server是Leader,则把日志条目广播给其他节点,并持久化日志条目到WAL中;
- 当一半以上节点持久化日志条目后,Leader的共识模块将此日志条目标记为已提交(committed),并通知其他节点提交;
- server从共识模块获取已经提交的日志条目,异步应用到状态机存储中(boltdb/leveldb/memory),然后返回给client。
多存储引擎
了解完复制状态机模型后,我和你再深入介绍下状态机。状态机中最核心模块当然是存储引擎,那要如何同时支持多种存储引擎呢?
metcd项目将基于etcd本身自带的raftexample项目进行快速开发,而raftexample本身只支持内存存储。
因此我们通过将KV存储接口进行抽象化设计,实现支持多存储引擎。KVStore interface的定义如下所示。
type KVStore interface {// LookUp get key valueLookup(key string) (string, bool)// Propose propose kv request into raft state machinePropose(k, v string)// ReadCommits consume entry from raft state machine into KvStore map until errorReadCommits(commitC <-chan *string, errorC <-chan error)// Snapshot return KvStore snapshotSnapshot() ([]byte, error)// RecoverFromSnapshot recover data from snapshotRecoverFromSnapshot(snapshot []byte) error// Close close backend databasesClose() err
}
基于KV接口抽象化的设计,我们只需要针对具体的存储引擎,实现对应的操作即可。
我们期望支持三种存储引擎,分别是内存map、boltdb、leveldb,并做一系列简化设计。一组metcd实例,通过metcd启动时的配置来决定使用哪种存储引擎。不同业务场景不同实例,比如读多写少的存储引擎可使用boltdb,写多读少的可使用leveldb。
接下来我和你重点介绍下存储引擎的选型及原理。
boltdb
boltdb是一个基于B+ tree实现的存储引擎库,在10中我已和你详细介绍过原理。
boltdb为什么适合读多写少?
对于读请求而言,一般情况下它可直接从内存中基于B+ tree遍历,快速获取数据返回给client,不涉及经过磁盘I/O。
对于写请求,它基于B+ tree查找写入位置,更新key-value。事务提交时,写请求包括B+ tree重平衡、分裂、持久化ditry page、持久化freelist、持久化meta page流程。同时,ditry page可能分布在文件的各个位置,它发起的是随机写磁盘I/O。
因此在boltdb中,完成一个写请求的开销相比读请求是大很多的。正如我在16和17中给你介绍的一样,一个3节点的8核16G空集群,线性读性能可以达到19万QPS,而写QPS仅为5万。
leveldb
那要如何设计适合写多读少的存储引擎呢?
最简单的思路当然是写内存最快。可是内存有限的,无法支撑大容量的数据存储,不持久化数据会丢失。
那能否直接将数据顺序追加到文件末尾(AOF)呢?因为磁盘的特点是顺序写性能比较快。
当然可以。Bitcask存储模型就是采用AOF模式,把写请求顺序追加到文件。Facebook的图片存储Haystack根据其论文介绍,也是使用类似的方案来解决大规模写入痛点。
那在AOF写入模型中如何实现查询数据呢?
很显然通过遍历文件一个个匹配key是可以的,但是它的性能是极差的。为了实现高性能的查询,最理想的解决方案从直接从内存中查询,但是内存是有限的,那么我们能否通过内存索引来记录一个key-value数据在文件中的偏移量,实现从磁盘快速读取呢?
是的,这正是Bitcask存储模型的查询的实现,它通过内存哈希表维护各个key-value数据的索引,实现了快速查找key-value数据。不过,内存中虽然只保存key索引信息,但是当key较多的时候,其对内存要求依然比较高。
快速了解完存储引擎提升写性能的核心思路(随机写转化为顺序写)之后,那leveldb它的原理是怎样的呢?与Bitcask存储模型有什么不一样?
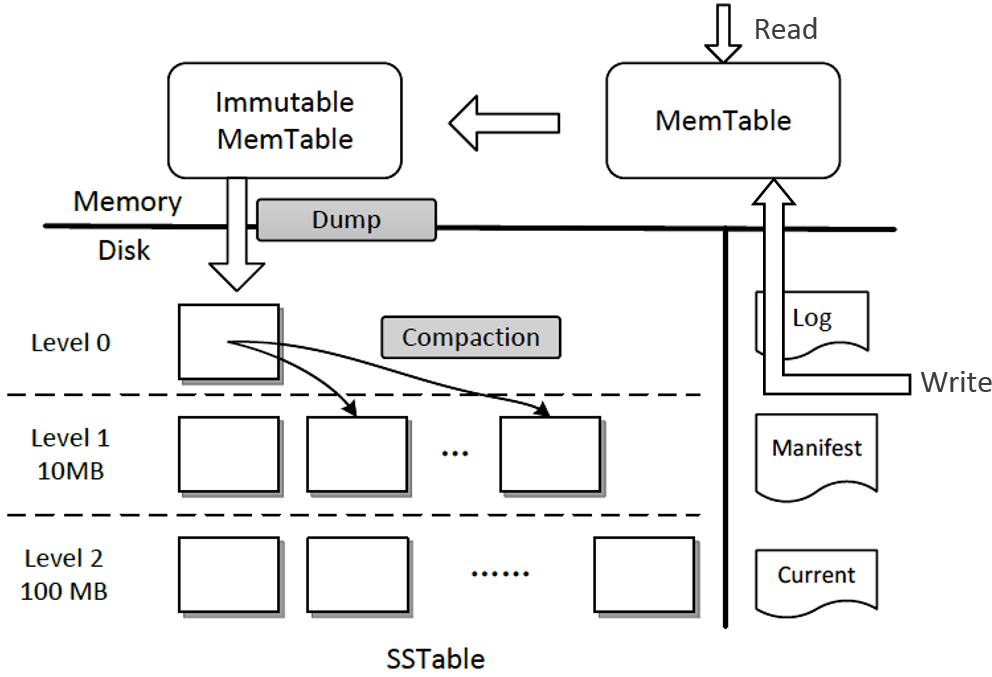
leveldb是基于LSM tree(log-structured merge-tree)实现的key-value存储,它的架构如下图所示(引用自微软博客)。
它提升写性能的核心思路同样是将随机写转化为顺序写磁盘WAL文件和内存,结合了我们上面讨论的写内存和磁盘两种方法。数据持久化到WAL文件是为了确保机器crash后数据不丢失。
那么它要如何解决内存不足和查询的痛点问题呢?
核心解决方案是分层的设计和基于一系列对象的转换和压缩。接下来我给你分析一下上面架构图写流程和后台compaction任务:
- 首先写请求顺序写入Log文件(WAL);
- 更新内存的Memtable。leveldb Memtable后端数据结构实现是skiplist,skiplist相比平衡二叉树,实现简单却同样拥有高性能的读写;
- 当Memtable达到一定的阈值时,转换成不可变的Memtable,也就是只读不可写;
- leveldb后台Compact任务会将不可变的Memtable生成SSTable文件,它有序地存储一系列key-value数据。注意SST文件按写入时间进行了分层,Level层次越小数据越新。Manifest文件记录了各个SSTable文件处于哪个层级、它的最小与最大key范围;
- 当某个level下的SSTable文件数目超过一定阈值后,Compact任务会从这个level的SSTable中选择一个文件(level>0),将其和高一层级的level+1的SSTable文件合并;
- 注意level 0是由Immutable直接生成的,因此level 0 SSTable文件中的key-value存在相互重叠。而level > 0时,在和更高一层SSTable合并过程中,参与的SSTable文件是多个,leveldb会确保各个SSTable中的key-value不重叠。
了解完写流程,读流程也就简单了,核心步骤如下:
- 从Memtable跳跃表中查询key;
- 未找到则从Immutable中查找;
- Immutable仍未命中,则按照leveldb的分层属性,因level 0 SSTable文件是直接从Immutable生成的,level 0存在特殊性,因此你需要从level 0遍历SSTable查找key;
- level 0中若未命中,则从level 1乃至更高的层次查找。level大于0时,各个SSTable中的key是不存在相互重叠的。根据manifest记录的key-value范围信息,可快递定位到具体的SSTable。同时leveldb基于bloom filter实现了快速筛选SSTable,因此查询效率较高。
更详细原理你可以参考一下leveldb源码。
实现分析
从API设计、复制状态机、多存储引擎支持等几个方面你介绍了metcd架构设计后,接下来我就和你重点介绍下共识模块、状态机支持多存储引擎模块的核心实现要点。
Raft算法库
共识模块使用的是etcd Raft算法库,它是一个经过大量业务生产环境检验、具备良好可扩展性的共识算法库。
它提供了哪些接口给你使用? 如何提交一个提案,并且获取Raft共识模块输出结果呢?
Raft API
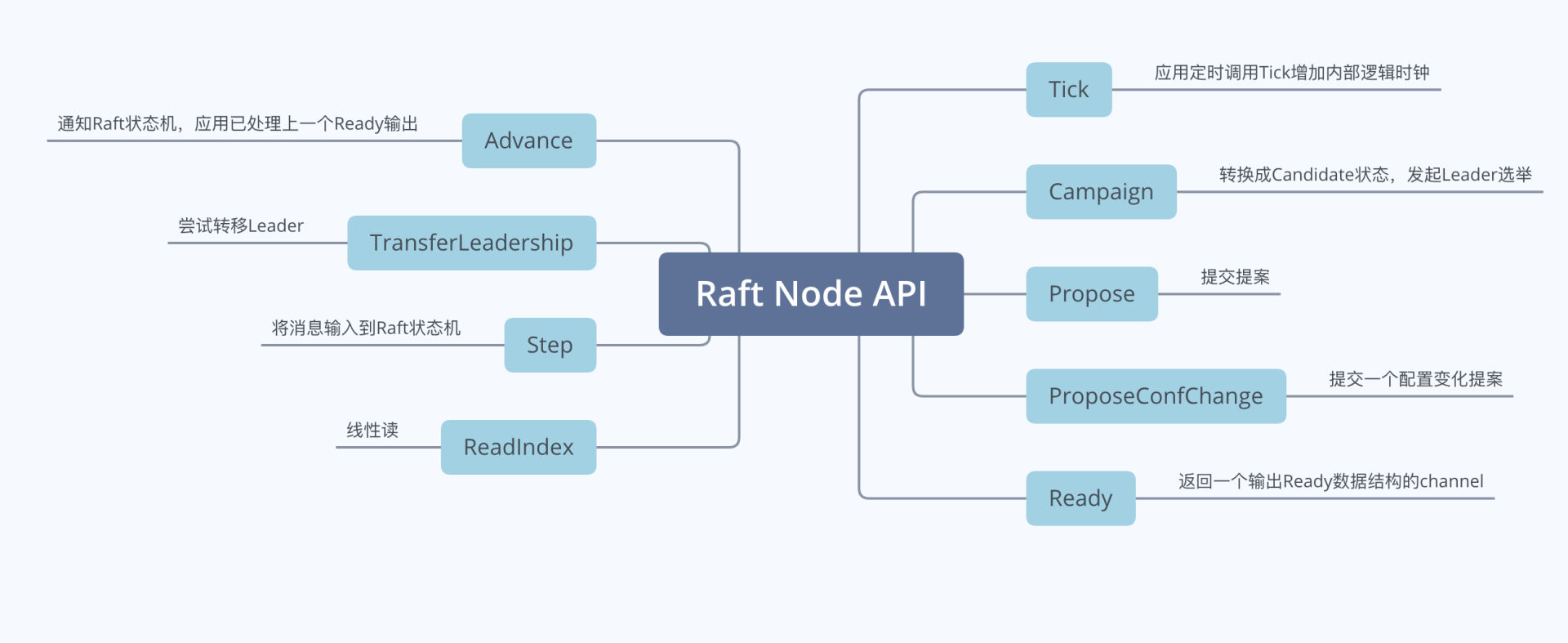
Raft作为一个库,它对外最核心的对象是一个名为Node的数据结构。Node表示Raft集群中的一个节点,它的输入与输出接口如下图所示,下面我重点和你介绍它的几个接口功能:
- Campaign,状态转换成Candidate,发起新一轮Leader选举;
- Propose,提交提案接口;
- Ready,Raft状态机输出接口,它的返回是一个输出Ready数据结构类型的管道,应用需要监听此管道,获取Ready数据,处理其中的各个消息(如持久化未提交的日志条目到WAL中,发送消息给其他节点等);
- Advance,通知Raft状态机,应用已处理上一个输出的Ready数据,等待发送下一个Ready数据;
- TransferLeaderShip,尝试将Leader转移到某个节点;
- Step,向Raft状态机提交收到的消息,比如当Leader广播完MsgApp消息给Follower节点后,Leader收到Follower节点回复的MsgAppResp消息时,就通过Step接口将此消息提交给Raft状态机驱动其工作;
- ReadIndex,用于实现线性读。
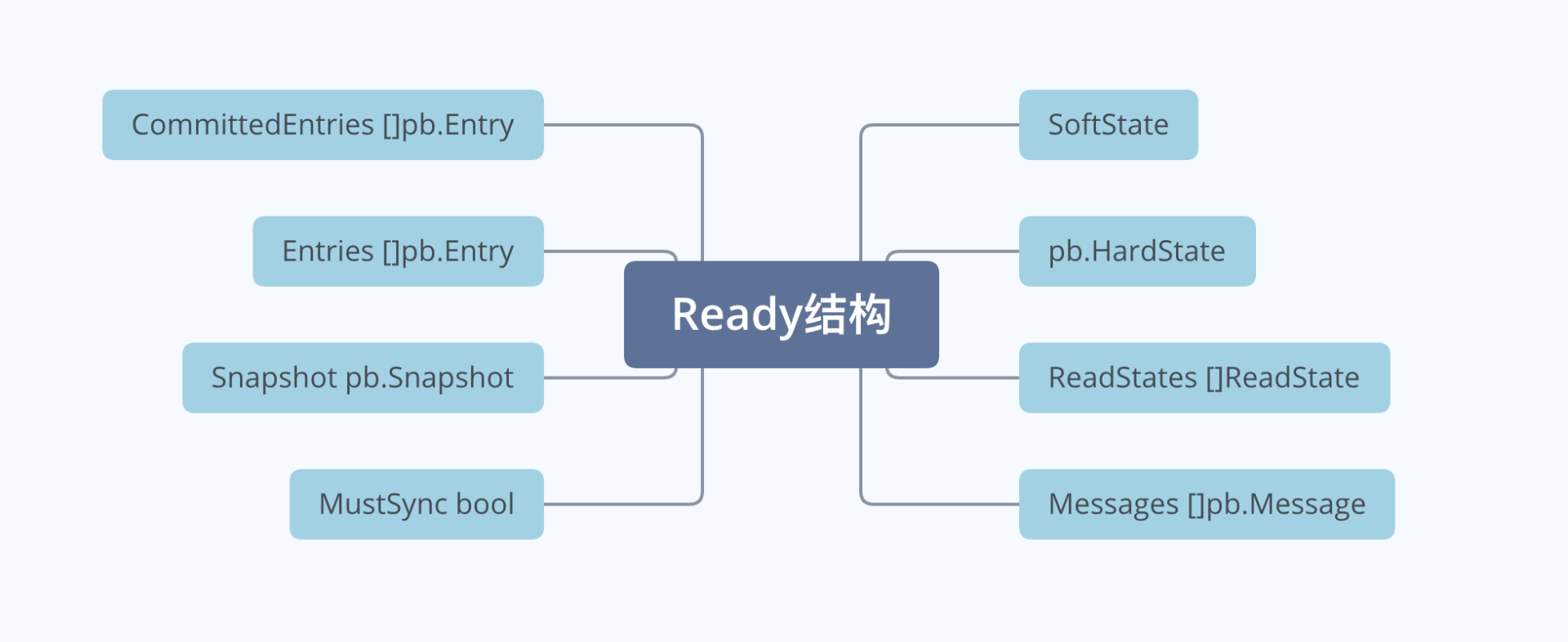
上面提到的Raft状态机的输出Ready结构含有哪些信息呢? 下图是其详细字段,含义如下:
- SoftState,软状态。包括集群Leader和节点状态,不需要持久化到WAL;
- pb.HardState,硬状态。与软状态相反,包括了节点当前Term、Vote等信息,需要持久化到WAL中;
- ReadStates,用于线性一致性读;
- Entries,在向其他节点发送消息之前需持久化到WAL中;
- Messages,持久化Entries后,发送给其他节点的消息;
- Committed Entries,已提交的日志条目,需要应用到存储状态机中;
- Snapshot,快照需保存到持久化存储中;
- MustSync,HardState和Entries是否要持久化到WAL中;
了解完API后,我们接下来继续看看代码如何使用Raft的Node API。
正如我在04中和你介绍的,etcd Raft库的设计抽象了网络、Raft日志存储等模块,它本身并不会进行网络、存储相关的操作,上层应用需结合自己业务场景选择内置的模块或自定义实现网络、存储、日志等模块。
因此我们在使用Raft库时,需要先自定义好相关网络、存储等模块,再结合上面介绍的Raft Node API,就可以完成一个Node的核心操作了。其数据结构定义如下:
// A key-value stream backed by raft
type raftNode struct {proposeC <-chan string // proposed messages (k,v)confChangeC <-chan raftpb.ConfChange // proposed cluster config changescommitC chan<- *string // entries committed to log (k,v)errorC chan<- error // errors from raft sessionid int // client ID for raft session......node raft.NoderaftStorage *raft.MemoryStoragewal *wal.WALtransport *rafthttp.Transport
}
这个数据结构名字叫raftNode,它表示Raft集群中的一个节点。它是由我们业务应用层设计的一个组合结构。从结构体定义中你可以看到它包含了Raft核心数据结构Node(raft.Node)、Raft日志条目内存存储模块(raft.MemoryStorage)、WAL持久化模块(wal.WAL)以及网络模块(rafthttp.Transport)。
同时,它提供了三个核心的管道与业务逻辑模块、存储状态机交互:
- proposeC,它用来接收client发送的写请求提案消息;
- confChangeC,它用来接收集群配置变化消息;
- commitC,它用来输出Raft共识模块已提交的日志条目消息。
在metcd项目中因为我们是直接基于raftexample定制开发,因此日志持久化存储、网络都使用的是etcd自带的WAL和rafthttp模块。
WAL模块中提供了核心的保存未持久化的日志条目和快照功能接口,你可以参考03节写请求中我和你介绍的原理。
rafthttp模块基于HTTP协议提供了各个节点间的消息发送能力,metcd使用如下:
rc.transport = &rafthttp.Transport{Logger: zap.NewExample(),ID: types.ID(rc.id),ClusterID: 0x1000,Raft: rc,ServerStats: stats.NewServerStats("", ""),LeaderStats: stats.NewLeaderStats(strconv.Itoa(rc.id)),ErrorC: make(chan error),
}
搞清楚Raft模块的输入、输出API,设计好raftNode结构,复用etcd的WAL、网络等模块后,接下来我们就只需要实现如下两个循环逻辑,处理业务层发送给proposeC和confChangeC消息、将Raft的Node输出Ready结构进行相对应的处理即可。精简后的代码如下所示:
func (rc *raftNode) serveChannels() {// send proposals over raftgo func() {confChangeCount := uint64(0)for rc.proposeC != nil && rc.confChangeC != nil {select {case prop, ok := <-rc.proposeC:if !ok {rc.proposeC = nil} else {// blocks until accepted by raft state machinerc.node.Propose(context.TODO(), []byte(prop))}case cc, ok := <-rc.confChangeC:if !ok {rc.confChangeC = nil} else {confChangeCount++cc.ID = confChangeCountrc.node.ProposeConfChange(context.TODO(), cc)}}}}()// event loop on raft state machine updatesfor {select {case <-ticker.C:rc.node.Tick()// store raft entries to wal, then publish over commit channelcase rd := <-rc.node.Ready():rc.wal.Save(rd.HardState, rd.Entries)if !raft.IsEmptySnap(rd.Snapshot) {rc.saveSnap(rd.Snapshot)rc.raftStorage.ApplySnapshot(rd.Snapshot)rc.publishSnapshot(rd.Snapshot)}rc.raftStorage.Append(rd.Entries)rc.transport.Send(rd.Messages)if ok := rc.publishEntries(rc.entriesToApply(rd.CommittedEntries)); !ok {rc.stop()return}rc.maybeTriggerSnapshot()rc.node.Advance()}}
}
代码简要分析如下:
- 从proposeC中取出提案消息,通过raft.Node.Propose API提交提案;
- 从confChangeC取出配置变更消息,通过raft.Node.ProposeConfChange API提交配置变化消息;
- 从raft.Node中获取Raft算法状态机输出到Ready结构中,将rd.Entries和rd.HardState通过WAL模块持久化,将rd.Messages通过rafthttp模块,发送给其他节点。将rd.CommittedEntries应用到业务存储状态机。
以上就是Raft实现的核心流程,接下来我来和你聊聊业务存储状态机。
支持多存储引擎
在整体架构设计时,我和你介绍了为了使metcd项目能支撑多存储引擎,我们将KVStore进行了抽象化设计,因此我们只需要实现各个存储引擎相对应的API即可。
这里我以Put接口为案例,分别给你介绍下各个存储引擎的实现。
boltdb
首先是boltdb存储引擎,它的实现如下,你也可以去10里回顾一下它的API和原理。
func (s *boltdbKVStore) Put(key, value string) error {s.mu.Lock()defer s.mu.Unlock()// Start a writable transaction.tx, err := s.db.Begin(true)if err != nil {return err}defer tx.Rollback()// Use the transaction...bucket, err := tx.CreateBucketIfNotExists([]byte("keys"))if err != nil {log.Printf("failed to put key %s, value %s, err is %v", key, value, err)return err}err = bucket.Put([]byte(key), []byte(value))if err != nil {log.Printf("failed to put key %s, value %s, err is %v", key, value, err)return err}// Commit the transaction and check for error.if err := tx.Commit(); err != nil {log.Printf("failed to commit transaction, key %s, err is %v", key, err)return err}log.Printf("backend:%s,put key:%s,value:%s succ", s.config.backend, key, value)return nil
leveldb
其次是leveldb,我们使用的是goleveldb,它基于Google开源的c++ leveldb版本实现。它提供的常用API如下所示。
- 通过OpenFile API创建或打开一个leveldb数据库。
db, err := leveldb.OpenFile("path/to/db", nil)
...
defer db.Close()
- 通过DB.Get/Put/Delete API操作数据。
data, err := db.Get([]byte("key"), nil)
...
err = db.Put([]byte("key"), []byte("value"), nil)
...
err = db.Delete([]byte("key"), nil)
...
了解其接口后,通过goleveldb的库,client调用就非常简单了,下面是metcd项目中,leveldb存储引擎Put接口的实现。
func (s *leveldbKVStore) Put(key, value string) error {err := s.db.Put([]byte(key), []byte(value), nil)if err != nil {log.Printf("failed to put key %s, value %s, err is %v", key, value, err)return err}log.Printf("backend:%s,put key:%s,value:%s succ", s.config.backend, key, value)return nil
}
读写流程
介绍完在metcd项目中如何使用Raft共识模块、支持多存储引擎后,我们再从整体上介绍下在metcd中写入和读取一个key-value的流程。
写流程
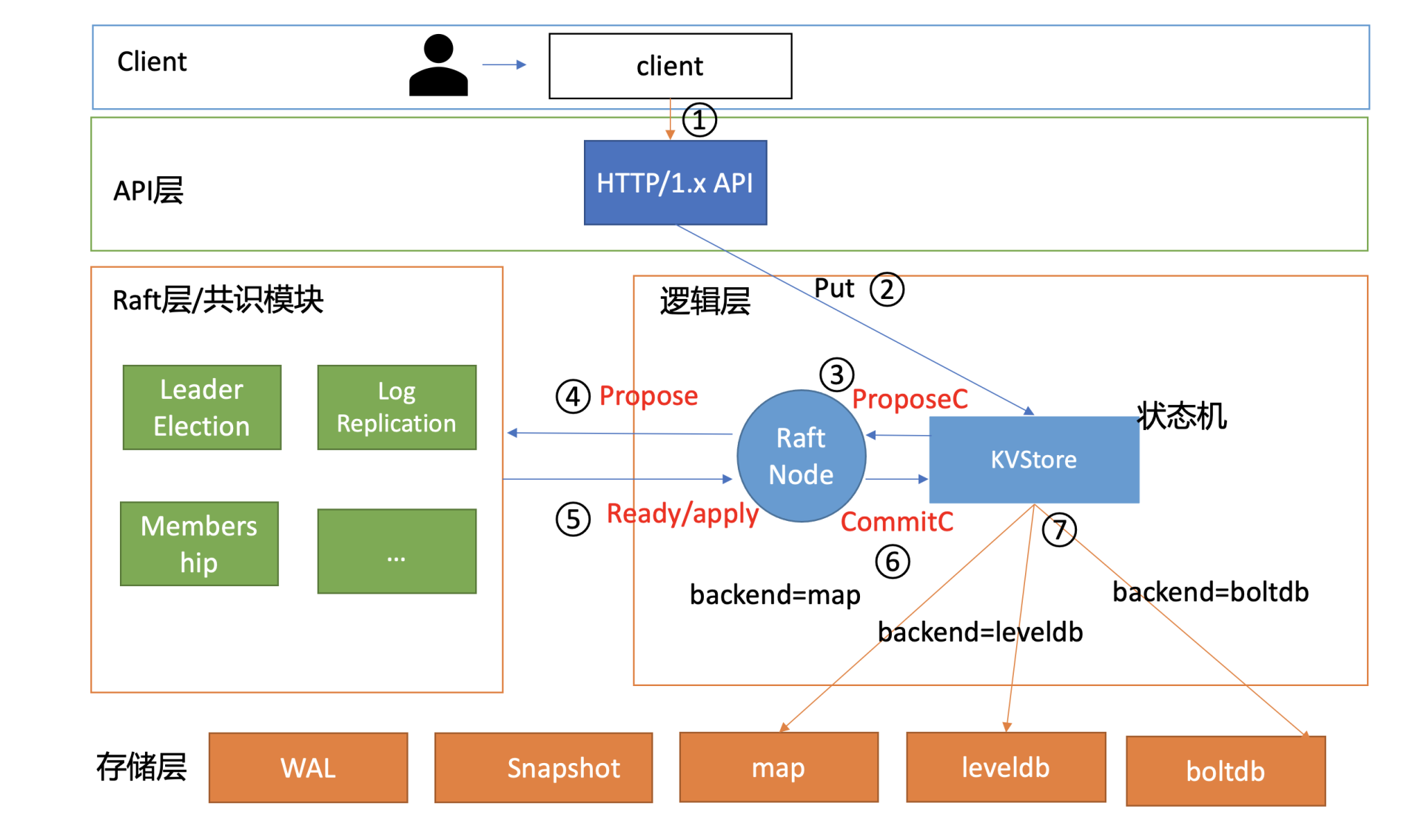
当你通过如下curl命令发起一个写操作时,写流程如下面架构图序号所示:
curl -L http://127.0.0.1:3379/hello -XPUT -d world
- client通过curl发送HTTP PUT请求到server;
- server收到后,将消息写入到KVStore的ProposeC管道;
- raftNode循环逻辑将消息通过Raft模块的Propose接口提交;
- Raft模块输出Ready结构,server将日志条目持久化后,并发送给其他节点;
- 集群多数节点持久化此日志条目后,这个日志条目被提交给存储状态机KVStore执行;
- KVStore根据启动的backend存储引擎名称,调用对应的Put接口即可。
读流程
当你通过如下curl命令发起一个读操作时,读流程如下面架构图序号所示:
curl -L http://127.0.0.1:3379/hello
world
- client通过curl发送HTTP Get请求到server;
- server收到后,根据KVStore的存储引擎,从后端查询出对应的key-value数据。
小结
最后,我来总结下我们今天的内容。我这节课分别从整体架构设计和实现分析,给你介绍了如何基于Raft从0到1构建一个支持多存储引擎的分布式key-value数据库。
在整体架构设计上,我给你介绍了API设计核心因素,它们分别是性能、易用性、开发效率、安全性、幂等性。其次我和你介绍了复制状态机的原理,它由共识模块、日志模块、存储状态机模块组成。最后我和你深入分析了多存储引擎设计,重点介绍了leveldb原理,它将随机写转换为顺序写日志和内存,通过一系列分层、创新的设计实现了优异的写性能,适合读少写多。
在实现分析上,我和你重点介绍了Raft算法库的核心对象Node API。对于一个库而言,我们重点关注的是其输入、输出接口,业务逻辑层可通过Propose接口提交提案,通过Ready结构获取Raft算法状态机的输出内容。其次我和你介绍了Raft算法库如何与WAL模块、Raft日志存储模块、网络模块协作完成一个写请求。
最后为了支持多存储引擎,我们分别基于boltdb、leveldb实现了KVStore相关接口操作,并通过读写流程图,从整体上为你介绍了一个读写请求在metcd中是如何工作的。
麻雀虽小,五脏俱全。希望能通过这个迷你项目解答你对如何构建一个简易分布式KV服务的疑问,以及让你对etcd的工作原理有更深的理解。
思考题
你知道raftexample启动的时候是如何工作的吗?它的存储引擎内存map是如何保证数据不丢失的呢?