指针和动态分配
地址的概念:
大家都知道我们创建的变量都会占用一定的内存,然而每个变量会在内存中有一个地址,就像我们在地球上的房子,是不是也有对应地址。我们可以使用&去输出我们变量的地址。
地址的输出:
- 取地址符:&变量名
- 地址是16进制数
#include<iostream>
using namespace std;
int main(){int a=100;double b=200.2;cout<<&a<<endl;cout<<&b<<endl;return 0;
}

输出数组地址:
输出数组的地址可以不用&,也可使用&(输出相同数据)
- 数组名就是第一个数据的地址
- &数组名输出的也是第一个数据的地址
#include<iostream>
using namespace std;
int main(){int arr[10]={1,2,3,4,5,6,7,8,9};int arr2[10][10]={1,2,3,4,5,6,7,8,9,10};cout<<arr<<endl;//输出第一个数据地址 cout<<&arr<<endl;//输出第一个数据地址cout<<arr2<<endl;//输出第一个数据地址cout<<&arr2<<endl;//输出第一个数据地址cout<<arr2[1]; //输出第二行第一个元素的地址 return 0;
}char的地址不能用cout直接输出
cout重载了类型转换运算符,默认会把&ch转换char *型,所以会当作字符串进行输出。
#include <iostream>
using namespace std;
int main() {char a='a';cout<<&a<<endl;return 0;
}
char地址输出方式:
- printf("%p",&c);
- cout<<(void*)&c<<endl;//转换为void*输出地址
#include<iostream>
#include<cstdio>
using namespace std;
int main(){char c='A';printf("%p\n",&c);//输出地址cout<<(void*)&c<<endl;//转换为void*输出地址 return 0;
}指针的概念:
指针:是一个变量,其值为另一个变量的地址,即内存位置的直接地址。就像其他变量或常量一样,您必须在使用指针存储其他变量地址之前,对其进行声明。 通过指针可以直接访问或修改内存中的数据,常用于动态内存分配、数组操作、函数参数传递等场景。
指针的声明:
指针的声明和普通数据类型的声明相似,但变量名前面多了 * 号
- * 代表取地址数据的符号
- 格式:数据类型 *变量;
int *p;//int类型的指针需要指向int类型的地址 char *c;//char类型的指针需要指向char类型的地址 double *;//都变了类型的指针需要指向double类型的地址 bool *bl; //bool类型的指针需要指向bool类型的地址指针的初始化:
指针初始化需要给它指向对应数据类型的地址
#include<iostream>
using namespace std;
int main(){int a1=100;char c1='a'; double b1=12.32;bool b2=true;int *p=&a1; //int类型的地址 char *c=&c1; //char类型的地址 double *b=&b1; //double类型的地址 bool *bl=&b2; //指向bool类型的地址 return 0;
}
指针数据及地址:
- 解引用(输出值):*指针名
- 输出地址:直接输出指针名
#include<iostream>
using namespace std;
int main(){int a1=100;int* p=&a1;//int类型的地址//输出地址cout<<p<<endl;//输出值cout<<*p<<endl; return 0;
}野指针:
当你声明了一个指针,并未对它进行初始化,那么在你使用这个指针时,该指针会随机指向其他地址,当你使用这个指针时,会出现意向不到的结果。
#include <iostream>
using namespace std;
int main() {int *p;//声明但未初始化的指针(野指针)int a=10; int *p1=&a;//不是野指针 return 0;
}空指针:
空指针的作用:防止指针指向随机的、不正确的、没有明确限制的地址,防止指针指向了一个地址是不确定的变量,此时去解引用就是去访问了一个不确定的地址,所以结果是不可知的(也就是野指针),空指针用nullptr表示
把指针变量赋为空指针:int *p=nullper
指针和数组:
数组名本质上是一个指向数组首元素的指针,当我们输出数组名时输出的就是第一个元素的地址,指针式可以随意进行修改的,但数组名是不可以随便修改的
一维数组和指针:
数组名是数组的首地址
数组名是一个常指针不可修改(不能进行++ -- 计算)
可以对指针使用++ --操作来访问元素
当指针指向数组是:可以使用 指针名[下标]输出数组元素
数组名表示数组地址:
数组名为第一个元素的地址:可以对数组名进行加减操作进行前移或后移,注意不能越界。
- arr==&arr[0]
- arr+1==&arr[1]
- arr+2==&&arr[2] ......
#include<iostream>
using namespace std;
int main(){int arr[10]={1,2,3,4,5,6,7,8};for(int i=0;i<10;i++) cout<<*(arr+i)<<" ";//使用数组名+i 进行数组的输出return 0;
}数组地址的表示:
使用&数组名[下标]表示:
- 第一个元素地址==&arr[0]
- 第二个元素地址==&arr[1]
- 第三个元素地址==&arr[2] ......
#include<iostream>
using namespace std;
int main(){int arr[10]={1,2,3,4,5,6,7,8};for(int i=0;i<10;i++) cout<<*&arr[i]<<" ";//地址遍历数组return 0;
}指针遍历数组:
指针是可以进行 ++ -- 操作的,是可以进行修改的
- 让指针指向数组名
- 然后遍历++即可
#include<iostream>
using namespace std;
int main(){int arr[10]={1,2,3,4,5,6,7,8};int *p=arr;//指向第一个元素for(int i=0;i<10;i++){cout<<*p++<<endl;//直接使用++即可} return 0;
}
指针数组和数组指针:
指针数组:
指针数组是一种数组,其元素均为指针类型。每个元素存储的是内存地址,可以指向其他变量、数组或函数。
- 指针数组的声明语法:
数据类型 *数组名[数组长度]- 由于[ ]的优先级大于*的优先级,所以会先组成数组然后再结合,所以形成指针数组
#include<iostream>
using namespace std;
int main(){int* arr[10];//拥有10个int类型指针 int a=100;arr[0]=&a;//第一个指针指向aint a1[10]={};arr[1]=a1;//第二个指针指向a1数组第一个数数据cout<<*arr[0]<<endl;//输出数组第一个数据值cout<<*arr[1]<<endl;//输出数组第二个数据值 return 0;
}
数组指针:
数组指针是指向数组的指针,它存储的是数组的首地址。数组指针的类型取决于数组元素的类型和数组的维度。
- 数组指针声明语法:
数据类型 (*数组名)[数组长度]- int (*arr)[10] 指向一个包含5个int元素的数组
- (*arr)相当于一个一维数组
- 数组指针就是二维数组
#include<iostream>
using namespace std;
int main(){int (*p)[10];//指向拥有10个int数据的数组int arr[10][10]={};p=arr;//p直接指向二维数组for(int i=0;i<10;i++){for(int j=0;j<10;j++){cout<<(*(p+0))[j]<<" ";//输出二维数组 }cout<<endl;} return 0;
}
二维数组和指针:
二维数组与指针的转换:
int (* p)[10];int a[10][10]={};p=a;//指针指向二维数组可以拆解为:
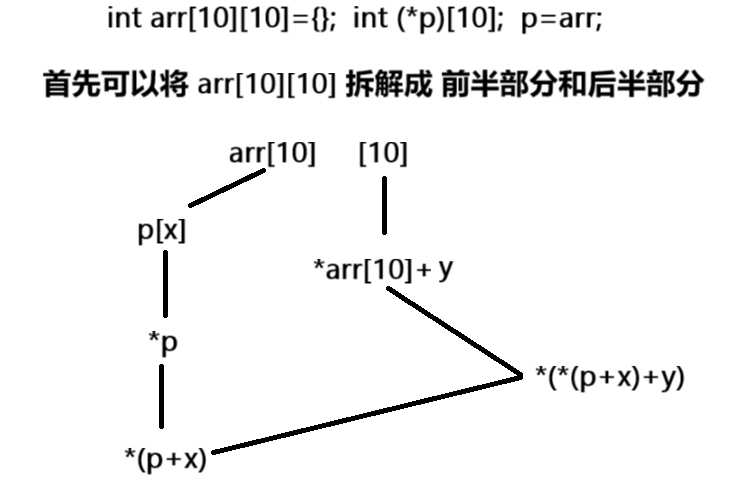
三种方法遍历二维数组:
- p[x][y]
- (*(p+x))[y]
- *(*(p+x)+y)
#include<iostream>
using namespace std;
int main(){int (*p)[10];//指向拥有10个int数据的数组int arr[10][10]={};p=arr;//p直接指向二维数组for(int i=0;i<10;i++){for(int j=0;j<10;j++){cout<<p[i][j]<<" ";//输出二维数组 }cout<<endl;} cout<<"-------------------------"<<endl;for(int i=0;i<10;i++){for(int j=0;j<10;j++){cout<<(*(p+i))[j]<<" ";//由于[]优先级大于*,所以要加括号}cout<<endl;}cout<<"-------------------------"<<endl;for(int i=0;i<10;i++){for(int j=0;j<10;j++){cout<<*(*(p+i)+j)<<" ";//输出二维数组 }cout<<endl;}return 0;
}const修饰指针:
const在c++中代表的是不可修改,const也可以修改指针,通常有以下四种
- const int * p
- int const *p
- int * const p
- const int * const p
指向常量指针:
指向常量的指针(指针指向的内容不可变),当const 修饰 *p时代表值不能修改,*p是值,所以const修饰过后,代表不能修改值,但可以改变指向(地址)
有以下两种:
- const int * p
- int const * p
- 指针p可以指向不同的变量。
- 不能通过p修改所指向的值。
- 所指
- 向的值本身不一定是常量,但通过p访问时视为常量。
#include <iostream>
using namespace std;
int main()
{int a=20;int b=30;const int * p=&a;//或 int const *p=&a;*p=30;//错误,不能改变值 p=&b;//可以改变指针指向 return 0;
} 常量指针:
当const修饰 p的时候,由于p代表的是地址,所以指针的地址是不能改变的,不能进行++ --炒作,不然会改变p的地址。
- 指针p一旦初始化后,不能再指向其他地址。
- 可以通过p修改所指向的值。
- 指针本身是常量,但指向的内容可以修改。
#include <iostream>
using namespace std;
int main()
{int a=20;int b=30;int * const p=&a;*p=30;//能改变值 p=&b;//不可以改变指针指向 return 0;
} 指向常量的常量指针
const既修饰*p 也修饰p,值不能改变指向也不能改变
- 指针p不能指向其他地址。
- 不能通过p修改所指向的值。
- 指针和指向的内容都是常量。
#include <iostream>
using namespace std;
int main()
{int a=20;int b=30;const int * const p=&a;*p=30;//不能改变值 p=&b;//不可以改变指针指向 return 0;
} 顶层const和底层const

#include <iostream>
using namespace std;
int main()
{int a=10;const int * const data=&a;//指向a 指向和值都不能改变 const int * const Data=data;// 使用const int * const 一定可以指向dataint * const Data1=data;//报错,这个指针的值可以改变,而data的值不能被改变const int * Data2=data;//可以,能保证值不能被改变,Data2的指向与data毫不相干 return 0;
} 动态分配内存:
内存分布图:
一般我们使用的变量基本是直接创建的,这些都是电脑分配的内存,以下是内存分配图:
一般来讲,在32位系统下,内核空间为1GB,堆空间为3GB
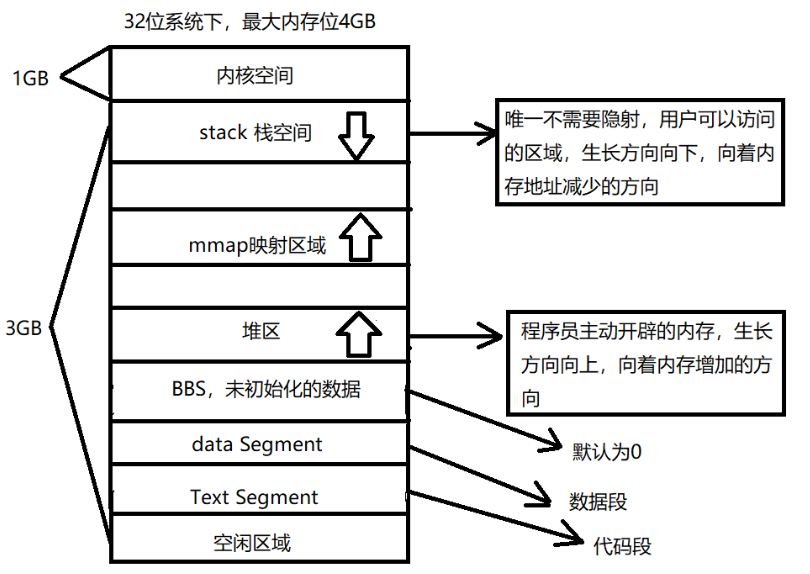
内存分区的作用:把不同的数据 存放在不同的区中,使得由不同的生存周期,使编程更加灵活
内存分区:

BSS段:通常是指用来存放程序中未初始化的全局变量的一块内存区域;
数据段:通常是指用来存放程序中 已初始化 的 全局变量 的一块内存区域,static意味着在数据段中存放变量;
代码段:通常是指用来存放 程序执行代码 的一块内存区域;
堆:存放进程运行中被动态分配的内存段,它的大小并不固定,可动态扩张或缩减,这一块在程序运行前就已经确定了;
栈:栈又称堆栈, 存放程序的 局部变量 (不包括static声明的变量)。除此以外,在函数被调用时,栈用来传递参数和返回值。
未执行该程序前分配:
代码区:
存放cpu执行的机器指令
代码区是共享的,多次使用的程序,只由一份代码
代码区是只读的,防止修改指令
全局区:
存放全局变量和静态变量和各种常量(字符串常量,全局常量)
程序结束后,由系统释放
栈区:
由编译器自动分配释放,存放函数的参数值,局部变量
不要返回局部变量的地址
栈区开辟的数据由编译器自动释放
堆区:
由程序员开辟和释放 ,程序员未释放,由系统回收
c++一般用new开辟
栈和堆的区别:
| 栈 | 堆 | |
|---|---|---|
| 分配方式 | 系统自动分配 | 由程序员申请 |
| 释放方式 | 编译器自动管理 | 由程序员释放 |
| 内存方向 | 生长方向是向下的,向着内存地址减少的方向 | 生长方向是向上的,向着内存地址增加的方向 |
| 内存分散 | 则不会存在这个问题 | 频繁的 new/delete 势必会造成内存空间的不连续, 从而造成大量的碎片,使程序效率降低 |
new和delete的使用:
new申请内存:
分配单个变量的内存:
int* ptr = new int;分配并初始化单个变量的内存:
int* ptr = new int(5);分配一维数组的内存:
int* arr = new int[10];分配(数组指针)二维数组的内存:
int (*array)[10] = new int[5][10];分配(指针数组)二维数组的内存:
int ** arr=new int*[5];
for(int i=0;i<5;i++)
{arr[i]=new int[10];
}delete释放内存:
释放单个变量的内存:
delete ptr;释放数组的内存:(一维数组和多维数组都是)
delete[] arr;内存泄漏和重复释放
使用 new 和 delete 时需要注意内存泄漏和重复释放的问题。每次使用 new 分配的内存都必须使用 delete 释放,否则会导致内存泄漏。同一块内存不能重复释放,否则会导致程序错误。
int* p = new int;delete p;delete p; // 错误,重复释放new 和 delete 是 C++ 中进行动态内存管理的重要工具,正确使用可以提高程序的效率和稳定性。
#include <iostream>
using namespace std;int main() {int *a=new int;//仅申请内存int *a1=new int (10);//申请内存并赋值//一维数组int *b=new int[10];//数组指针:二维数组int (*p)[10]=new int[10][10];//指针数组:二维数组int **arr=new int *[5];//先创建一个数组指针for(int i=0; i<; i++) {arr[i]=new int [10];//再依次分配内存}//释放内存delete a;delete a1;delete[] b;delete[] p;for(int i=0;i<5;i++){delete[] arr[i];}delete[]arr;return 0;
}