【第十七周】自然语言处理的学习笔记02
文章目录
- 摘要
- Abstract
- 一、机器学习
- 1. KNN算法
- 1.1 KNN算法使用到的API介绍
- 1.1.1 数据集
- 1.1.2 查看数据分布
- 1.1.3 数据集划分
- 1.1.4 特征工程
- 1.1.5 K-近邻算法API
- 1.2 具体案例分析
- 1.3 KNN算法总结
- 2. 网格搜索
- 二、自然语言处理
- 1. 注意力机制
- 1.1 基本介绍
- 1.2 注意力分数计算
- 2. Transformer结构
- 2.1 输入层
- 2.1.1 BPE
- 2.1.2 位置编码PE(positional encoding)
- 2.1.3 输入流程
- 2.2 主要层和输出层
- 输出层:线性变换层和softmax 最后使用交叉熵损失函数计算损失值并更新模型参数 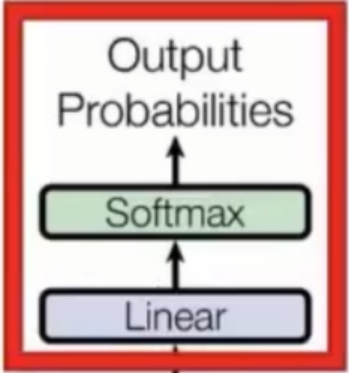
- 总结
摘要
本周主要学习了使用scikit-learn来实现KNN算法,包含数据集的获取、查看数据分布、特征工程等,通过综合案例:鸢尾花种类预测,完成对上述学习内容的综合运用,同时,补充了机器学习中网格搜索的内容。
自然语言处理学习了注意力机制以及transfomer的结构,了解到transfomer整体架构遵循 “编码器 - 解码器” 框架,分为三层结构:输入层,主要层,输出层。输入层学习了使用BPE划分文本序列以及位置编码PE。
Abstract
This week, I mainly learned to implement the K-Nearest Neighbors (KNN) algorithm using scikit-learn, which includes tasks such as obtaining datasets, examining data distribution, and feature engineering. Through a comprehensive case study—the Iris flower species prediction—I completed the integrated application of the above-mentioned learning content. Additionally, I supplemented my knowledge about grid search in machine learning.
In the field of Natural Language Processing (NLP), I learned about the attention mechanism and the Transformer architecture. I understood that the overall architecture of the Transformer follows an “encoder-decoder” framework and is divided into three layers: the input layer, the main layer, and the output layer. For the input layer, I learned to use Byte Pair Encoding (BPE) to segment text sequences and studied Positional Encoding (PE).
一、机器学习
1. KNN算法
1.1 KNN算法使用到的API介绍
1.1.1 数据集
Sklearn.datasets
加载获取数据集
(1)小数据集:datasets.load_*(),sklearn库中下载了一些数据集,直接load加载本地数据集。
例如加载鸢尾花数据集:sklearn.datasets.load_iris()
(2)大数据集:datasets.fetch_*(data_home = None ),需要从网络中下载大规模数据,函数的第一个参数就是data_home,表示数据集下载的目录,默认是:~/scikit_learn_data/
例如:sklearn.datasets.fetch_20newsgroups(data_home = None,subset=’train’ )
参数说明:
subset可以设置为 ’train’ 或 ’test’ 或 ’all’,按需选择要加载的数据集。
数据集属性:
Load和fetch 返回数据类型 dataset.base.Bunch(字典格式)
Data:特征数据数组,二维numpy.ndarray数组
Target:标签数组,一维numpy.ndarray数组
DESCR:数据描述
Feature_names:特征名(新闻数据,手写数据,回归数据集没有)
Target_names:标签名
1.1.2 查看数据分布
使用seaborn可视化数据,seaborn是matplotlib核心库进行更高级的API封装。
Seaborn安装指令:pip install seabor、
Seaborn常用方法:
Seaborn.Implot():绘制二维散点图,自动完成回归拟合
Sns.Implot():x,y分别代表横纵坐标的列名
Data:关联到数据集
Hue:代表目标值
Fit_reg:是否进行线性拟合
1.1.3 数据集划分
数据集一般划分为两部分:
训练集:训练,构建模型。70%-80%
测试集:检验模型。20%-30%
Sklearn.model_selection.train_test_split(arrays,*options)
参数说明:
X:数据集的特征值
Y:数据集的标签值
Test_size: 测试集的大小,一般float
Random_state: 随机数种子,不同种子会造成不同的随机采样结果。相同的种子采样结果相同。
Return:
x_train , x_test , y_train , y_test
1.1.4 特征工程
特征预处理:通过一些转换函数将特征值转换成更加适合算法模型的特征数据过程。特征放缩,将所有特征经过变换,变成为较小范围内的数据,例如 0-1之间。此时便于机器计算。
归一化和标准化
特征单位或者大小相差较大,或者某特征的方差相比其他的特征要大出几个数量级,容易影响目标结果,使得一些算法无法学到其他特征。
归一化:通过对原始数据变换将数据映射到指定范围间
公式如下:
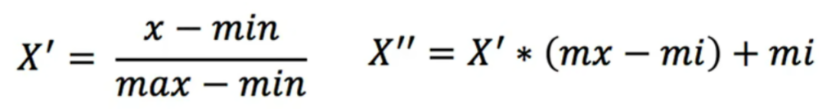
参数说明:
max为一列的最大值,min为一列的最小值,x”为最终结果,mx和mi为指定区间的最大值和最小值。例如指定区间0-1,此时mx为1,mi为0。
具体举例:其中由于最后指定区间为 (0,1),因此x’=x”
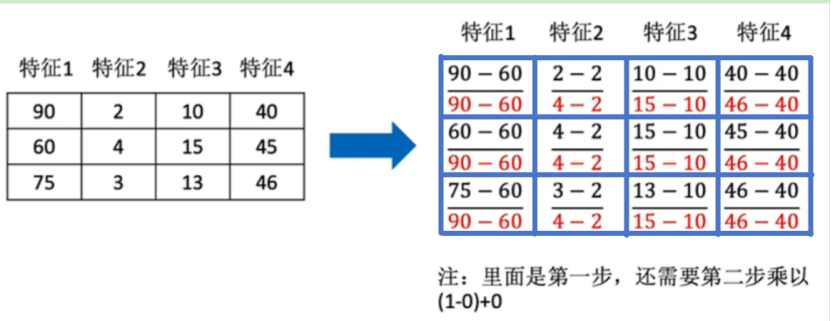
归一化总结:最大最小值是变换的,并且易受异常点影响,方法鲁棒性差,只适合传统精确小数据场景。
归一化Api:sklearn.preprocessing.MinMaxScale(feature_range = (0,1)…)
Feature_range:指定区间
MinMaxScale.fit_transform(X) #开始转换
X:要转换的numpy array 格式的数据[ n_samples,n_features ],
返回值:转换后的形状相同的array
标准化:将原始数据进行变换到均值为0,标准差为1范围内。(标准正态分布),因此,数据范围(-1,1)。
公式:
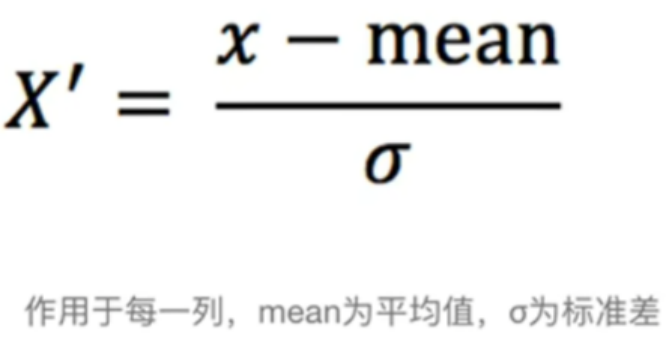
适用于数据较杂的情况。
标准化Api:sklearn.preprocessing.StandardScaler()
StandardScaler().fit_transform(X) #开始转换
X:要转换的numpy array 格式的数据[ n_samples,n_features ],
返回值:转换后的形状相同的array
综上:
对于归一化:如果出现异常点,影响了最大值和最小值,结果发生变化
对于标准化:如果出现异常点,由于具有一定数量,少量异常点对结果影响不大,从而方差改变较小。
因此标准化适合嘈杂的大数据场景。
1.1.5 K-近邻算法API
Sklearn.neighbors.KNeighnorsClassifier(n_neighbors = 5,algorithm = ‘auto’)
参数说明:
- n_neighbors:默认邻居数
- Algorithm:{‘auto’,‘ball_tree’,‘kd_tree’,‘brute’}
k近邻算法,默认参数‘auto’,也可以指定算法‘ball_tree’,‘kd_tree’,‘brute’进行搜索
‘ball_tree’:克服kd树高维失效而发明的
‘kd_tree’:构造kd树存储数据以便对其进行快速检索的树形数据结构
‘brute’:蛮力搜索,线性扫描,训练集大时,计算量大。
1.2 具体案例分析
鸢尾花种类预测
鸢尾花属性:
- Sepal length:萼片长度
- Sepal width:萼片宽度
- Petal length:花瓣长度
- Petal width:花瓣宽度
Class:
- Iris-Setosa 山鸢尾
- Iris-Versicolour 变色鸢尾
- Iris-Virginica 维吉尼亚鸢尾
具体代码如下:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier# 1.获取数据
iris = load_iris()# 2.数据基本处理
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=22)# 3.特征工程 - 特征预处理
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)# 4.机器学习-KNN
# 4.1 实例化一个估计器
estimator = KNeighborsClassifier(n_neighbors=5)
# 4.2 模型训练
estimator.fit(x_train, y_train)# 5.模型评估
# 5.1 预测值结果输出
y_pre = estimator.predict(x_test)
print("预测值是:\n", y_pre)
print("预测值和真实值的对比是:\n", y_pre==y_test)# 5.2 准确率计算
score = estimator.score(x_test, y_test)
print("准确率为:\n", score)
步骤分析:
(1)获取数据
(2)数据基本处理
划分数据集:训练集,测试集。以及特征值,标签值
(3)特征工程
标准化处理
(4)机器学习
模型训练预测:
KNeighnorsClassifier(n_neighbors = k) #实例化估计器,指定k值
Fit() #具体模型训练
(5)模型评估
方法一:对比真实值与预测值
数据预测:predict(测试集特征) 进行预测
结果对比
方法二:计算准确率
score(测试集特征,测试集标签)
1.3 KNN算法总结
优点:
(1)简单有效
(2)重新训练的代价低。
(3)适合类域交叉样本
KNN 方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,KNN 方法较其他方法更为适合。
(4)适合大样本自动分类
该算法比较适用于样本容量比较大的类域的自动分类,而那些样本容量较小的类域采用这种算法比较容易产生误分。
缺点:
(1)惰性学习
KNN 算法是懒散学习方法(lazy learning,基本上不学习),一些积极学习的算法要快很多
(2)类别评分不是规格化
不像一些通过概率评分的分类
(3)输出可解释性不强
例如决策树的输出可解释性就较强
(4)对不均衡的样本不擅长
当样本不平衡时,如一个类的样本容量很大,而其他类样本容量很小时,有可能导致当输入一个新样本时,该样本的 K 个邻居中大容量类的样本占多数。该算法只计算 “最近的” 邻居样本,某一类的样本数量很大,那么或者这类样本并不接近目标样本,或者这类样本很靠近目标样本。无论怎样,数量并不能影响运行结果。可以采用权值的方法(和该样本距离小的邻居权值大)来改进。
(5)计算量较大
目前常用的解决方法是事先对已知样本点进行剪辑,事先去除对分类作用不大的样本。
2. 网格搜索
网格搜索:机器学习中用于优化模型超参数的一种常见方法,它通过系统地遍历指定范围内的所有超参数组合,评估每个组合下模型的性能,从而找到最优的超参数设置。
超参数:超参数是在开始学习过程之前设置值的参数,而不是学习得到的。例如,在支持向量机(SVM)中,核函数的类型(线性核、多项式核、径向基核等)、惩罚参数 C ;在 K 近邻算法(KNN)中,邻居数量 K ;在决策树中,最大深度等,都是超参数。
网格搜索流程:
(1)定义超参数范围。明确需要优化的超参数以及它们的取值范围。
(2)生成超参数组合。根据定义的超参数范围,生成所有可能的超参数组合。
(3)交叉验证评估。对于每一种超参数组合,使用交叉验证的方法来评估模型在训练数据上的性能。对训练集a进行划分,a=b+c,其中b部分数据进行训练,通过b的数据对模型训练,c部分数据进行验证模型是否在性能上有提升。
(4)选择最优组合。比较所有超参数组合的性能得分,选择得分最高(或最低,取决于评估指标)的超参数组合作为最优设置,使用该组合重新训练模型,并应用到测试数据或实际任务中。
二、自然语言处理
1. 注意力机制
1.1 基本介绍
信息瓶颈:需要在 “保留输入数据中的关键信息” 与 “压缩冗余噪声信息” 之间找到平衡 。
decoder端最后表示的向量来输出完整、正确的句子。因此要求encoder端最后一个向量表示需要包含输入句子的所有信息,但是仅此一个向量无法包含句子中的所有信息。encoder最后一个向量就是与decoder模型的信息瓶颈。
注意力机制:解决信息瓶颈而提出。在处理序列数据(如文本、语音、图像)时,动态聚焦于对当前任务更重要的信息,忽略无关或次要信息。
注意力机制核心思想:decoder的每一步都将encoder端所有向量提供给decoder模型,使decoder自动选择需要使用的信息和向量。
以机器翻译为例:
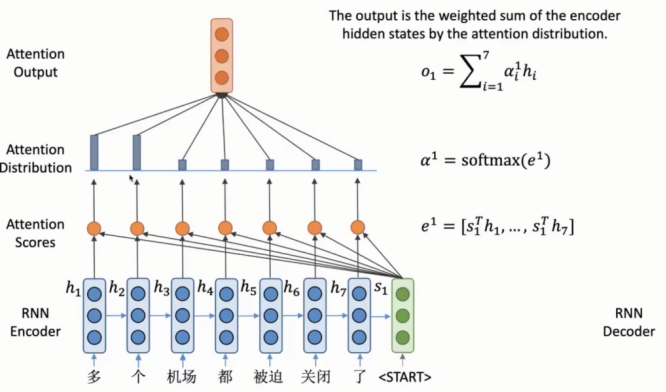
Encoder端多个隐向量h(蓝色部分)
Decoder端的每一步得到一个向量S :通过RNN得到的表示当前状态的隐向量(绿色部分),不直接计算生成单词的概率,而是使用s来选择关注输入句子的哪些信息,并计算得到新的隐向量,从而得到生成单词的概率。
注意力分数(attention score):将encoder端所有h与decoder端s进行点积得到e注意力分数
注意力分布(attention distribution):对注意力分数进行softmax得到α注意力分布,概率越高即为当前需要翻译部分。
简单理解:快速将句子重点信息检索出来。
最后模型如下:
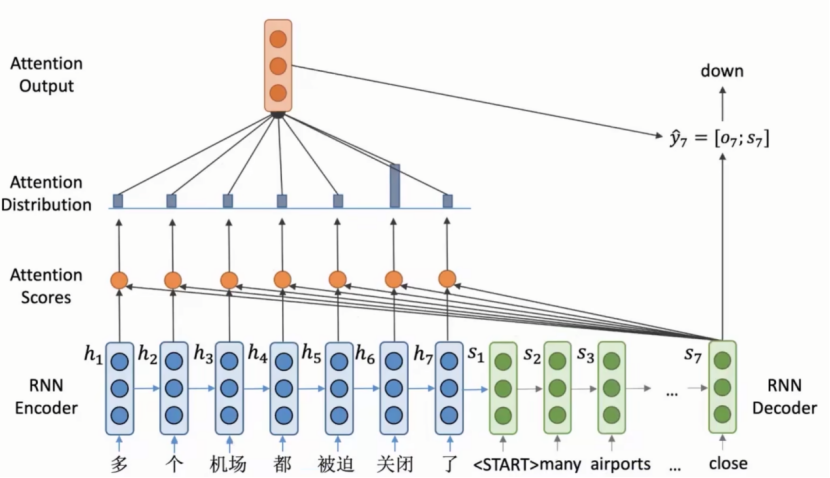
自主关注到decoder不同位置的隐向量,并翻译新单词。
抽象化注意力机制:decoder端为query向量,encoder端为values向量。query为对一组values向量加权求平均
1.2 注意力分数计算
求注意力分数的方法:
(1)点积
(2)当向量维度不同,在中间加上一个权重矩阵,实现两者间相乘,得到一个标量。
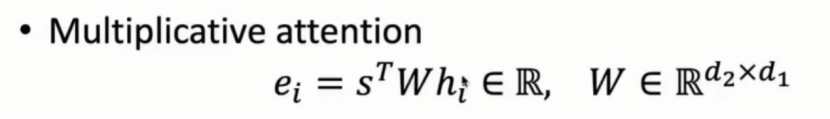
(3)使用一层前馈神经网络将两个向量变成一个标量。
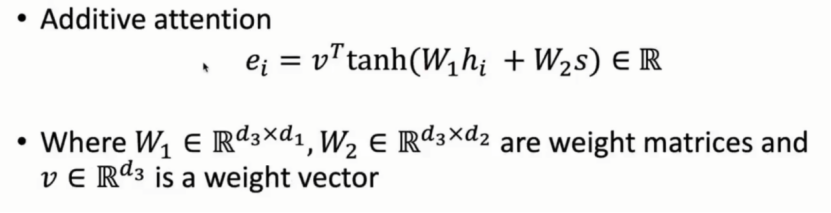
v为权重向量,w为权重矩阵
注意力机制工作本质:计算重要性、分配权重、聚焦关键信息
注意力机制的作用:
(1)解决信息瓶颈
(2)有效缓解RNN中梯度爆炸和梯度消失问题。在encoder与decoder间直接连接防止梯度在RNN中传播过长。
(3)提供可解释性。decoder端每次的注意力分布可视化便于找到软对应关系(翻译例子中:多—many),计算相似度。
2. Transformer结构
整体架构遵循 “编码器 - 解码器” 框架,但内部层的设计完全基于注意力机制。
编码器(encoder):接收输入序列(如源语言文本),输出包含上下文信息的特征序列。
解码器(decoder):接收编码器的输出和目标序列(如目标语言文本),生成最终的输出序列(如翻译结果)。
两者均由N 个相同的层堆叠而成(原论文中 N=6),每层包含特定的子层结构。
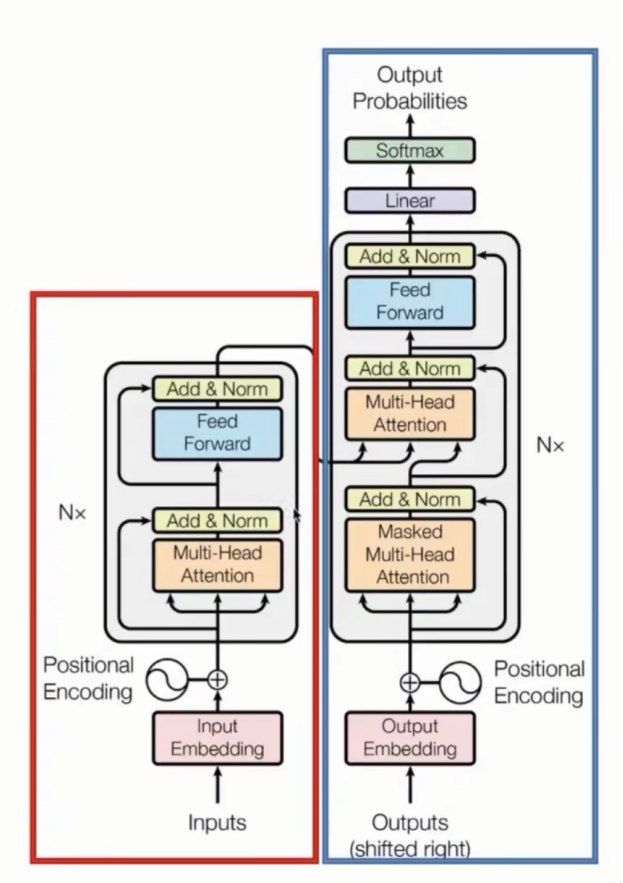
encoder与decoder模型:红色部分encoder,蓝色部分decoder
从下往上看分为三个部分:
2.1 输入层
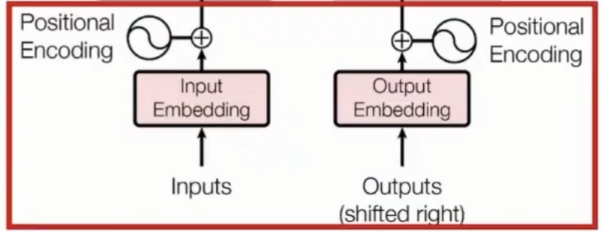
输入层:正常文本序列划分为一个个小单元(token),通过embedding化为一个向量。
Byte pair encoding(BPE)方式进行文本切分,并在每个位置加上token的位置向量。表示它在文本序列中的位置
- Token 是文本经过分词后得到的最小处理单位,解决 “文本是字符串,模型只能处理数字” 的问题。
- Embedding 将离散的 Token 转换为连续的数值向量,即 映射为低维稠密向量的过程,得到的向量称为 “嵌入向量”。
两者是 “预处理→数值化” 的连续过程
Token,embedding具体说明如下:假设一句话由12个字组成,将它划分为12个字,一个字为512维。下图中一行就是一个字符向量,共有12行。

使用BPE分词方式的原因:
对文本进行空格切分时可能导致词表过大,单词不同形态对应完全不同的embedding等问题。BPE子词分词算法,为新的分词方式,解决简单空格划分出现的问题。
2.1.1 BPE
切分单元流程:
(1)初始化词汇表。将语料库中出现的所有单词切分为最小单元:一个个字母,
(2)迭代合并高频对。统计语料库中每一个byte gram出现的数量,将频率高的加入词表。(byte gram:相邻字母出现的组合)如此重复直到达到预设词汇表大小。
(3)最终分词效果。复合词会被拆分为有意义的子词,例如 “unhappiness”→[“un”, “happy”, “ness”],“乒乓球”→[“乒乓”, “球”]。
具体举例:
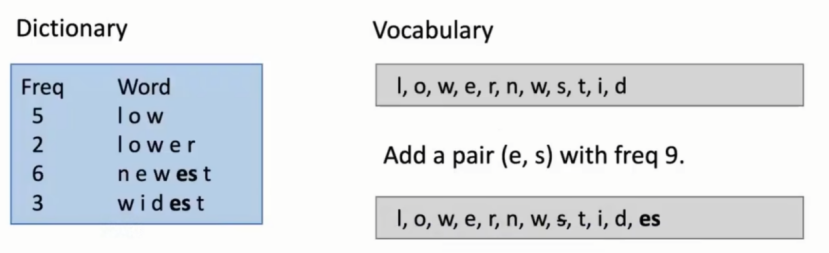
上面语料库中由于es出现频率最高,因此加入词表,又因为s没有单独出现,因此在词表中划除。
下面对词表再次进行更新,此时est为新的byte gram,同理更新后的词表:
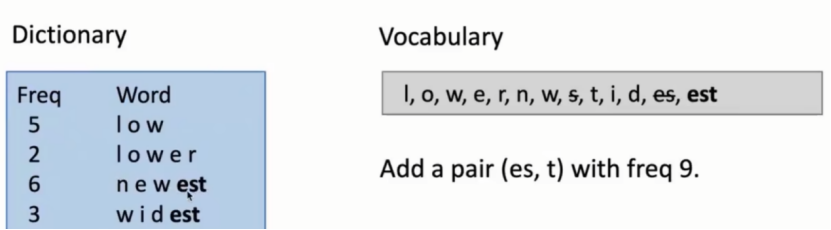
不断重复此过程,直到词表数量达到预定值。
总结:BPE通过将词汇拆分为更小的单元(如字母或音素组合),动态合并高频字符 / 子词对来缓解OOV(out of vocabulary)超出词表的词汇问题。
上述例子中若出现;lowest则会被划分为 “low est”,并且low与lowest的关系能被泛化到new与newest
2.1.2 位置编码PE(positional encoding)
位置编码:注入序列位置信息。区分不同位置的相同单词。
为什么需要位置编码?
Transformer 模型的自注意力机制是并行处理序列的,无法像 RNN 那样自然捕捉序列顺序,即transfomer较于RNN可以一次输入所有字符,因此需要进行位置编码。PE 的作用是向输入嵌入中注入位置信息,让模型知道每个 Token 在序列中的位置(如 “我爱你” 与 “你爱我” 的区别)。
对transfomer block不同位置的相同单词添加位置向量
①位置编码PE(positional encoding)需要与BPE同维度。
②基于三角函数得到对应位置向量:偶数下标位置为正弦,奇数下标位置为余弦
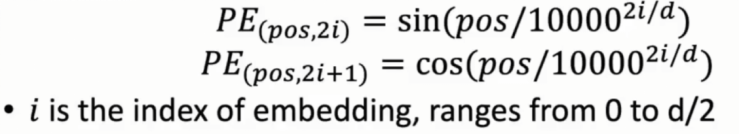
参数说明:
pos:当前token在句子中的位置,
i:0 - d/2 (d为BPE维度),为embedding中索引值,词内的维度。上述中举例一个字划分为512维,i即为0-511内某一个值。
2.1.3 输入流程
原始文本 → BPE 分词(得到子词 Token) → Token 嵌入(映射为向量) → 加 PE(注入位置信息) → 输入 Transformer 编码器 / 解码器。
输入transfomer block的向量为:BPE与PE按照位置相加,Input = BPE + PE。
2.2 主要层和输出层
主要层:由多个encoder或decoder的transformer block堆叠而成,其中encoder/decoder中block结构一致,只是参数不同
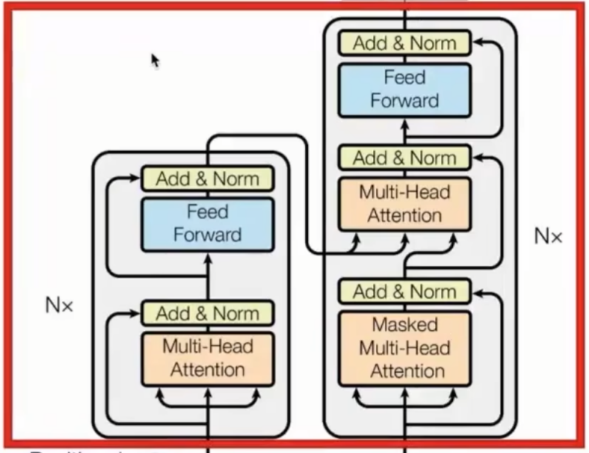
输出层:线性变换层和softmax
最后使用交叉熵损失函数计算损失值并更新模型参数

总结
对于transfomer结构还未学习完,下周需要对transfomer中的主要层和输出层进行内容补充,并通过查看transfomer的实现代码来更深入理解transfomer。