LLM 笔记 —— 07 Tokenizers(BPE、WordPeice、SentencePiece、Unigram)
01 Byte Pair Encoding Tokenizer (BPE Tokenizer)
BPE 的基本思想是将单词分成一系列 “子词单元”,这些单元是在参考语料库(即我们用来训练它的语料库)中频繁出现的单元。
BPE training starts with an initial vocabulary and increases it to the desired size.
那么,BPE 标记器是如何被训练的呢?
① 规范化
首先,我们获得一个文本语料库,如下,但我们不会在这个原始文本上训练我们的标记器,而是先对其进行规范化,然后对其进行预标记。


② 预标记
预标记将文本分成一个单词列表,我们可以通过将相同的单词聚集在一起并维护一个单词计数器,如蓝色表示单词出现的次数。


为了理解训练是如何进行的,我们考虑这个由以下单词组成的玩具 语料库 Corpus。
③ Initial Vocab
为了构建初始词汇表,我们首先将 Corpus 中每个单词分成组成它们的 基本单位列表 Splits,这里是单个字符。
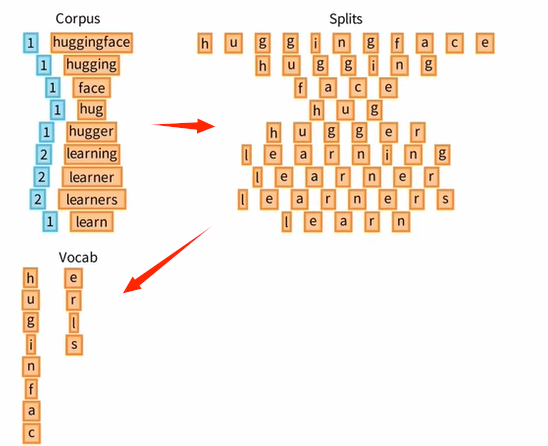
在 词汇表 Vocab 中列出所有出现的字符,这些字符构成我们的初始词汇表!
④ Increase Vocab
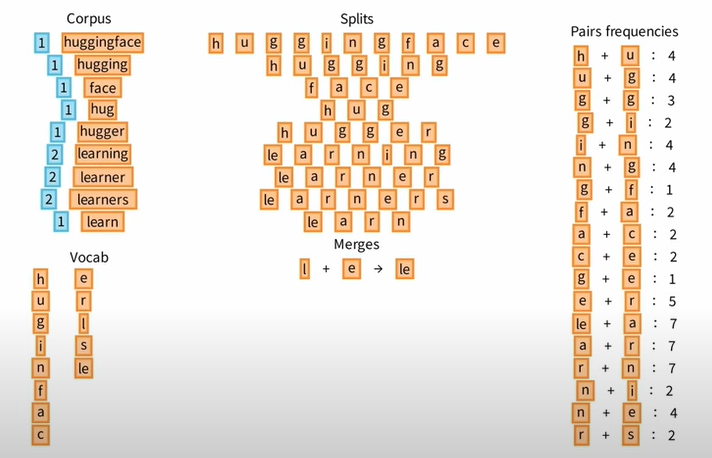
Ⅰ 现在让我们看看如何增加 Vocab,回到 Splits,逐个浏览 标记对 Pairs ,并统计所有标记对的出现次数,比如 hu ug gg 等等。
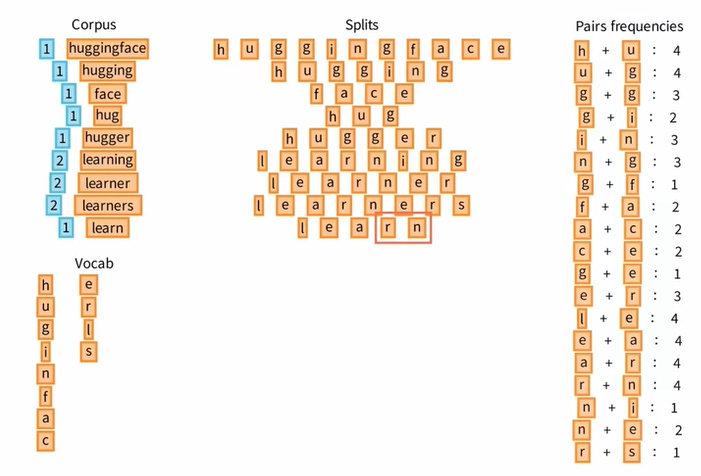
Ⅱ 从所有 Pairs 中挑选一个出现次数最高的,比如 l + e,并将 le 添加到 Vocab 中。
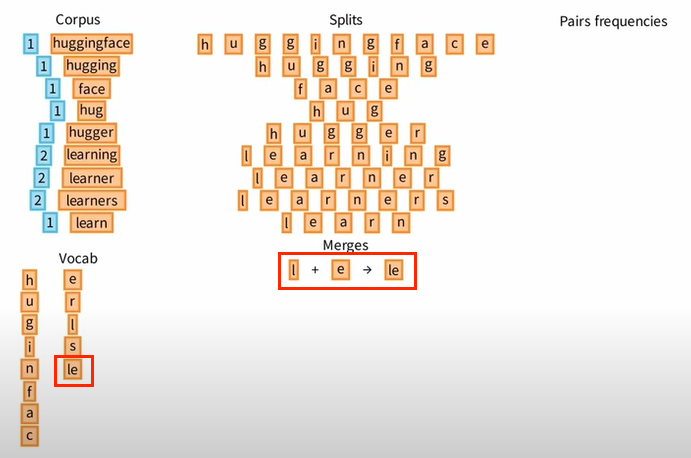
Ⅲ 然后,我们优化原来的 Splits,将 l 和 e 合并为 le。
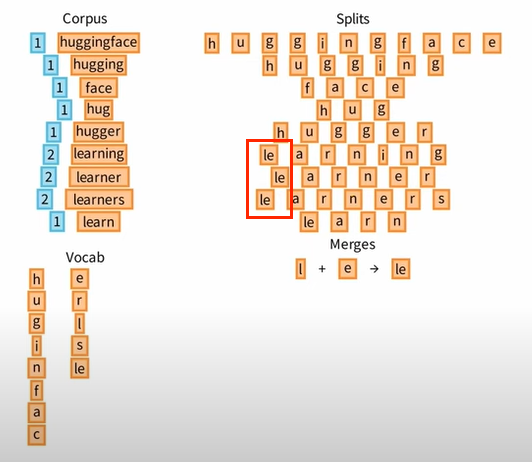
让我们重复 ④ 这一核心步骤,不断地统计 Pairs 的频率,不断地选择频率最高的 Pairs 添加进 Vocab 中,同时优化原来的 Splits。
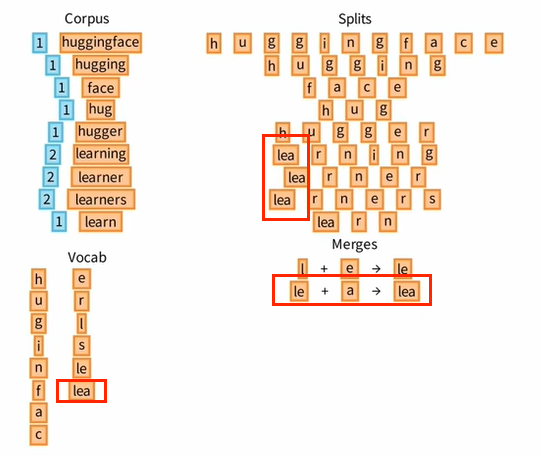
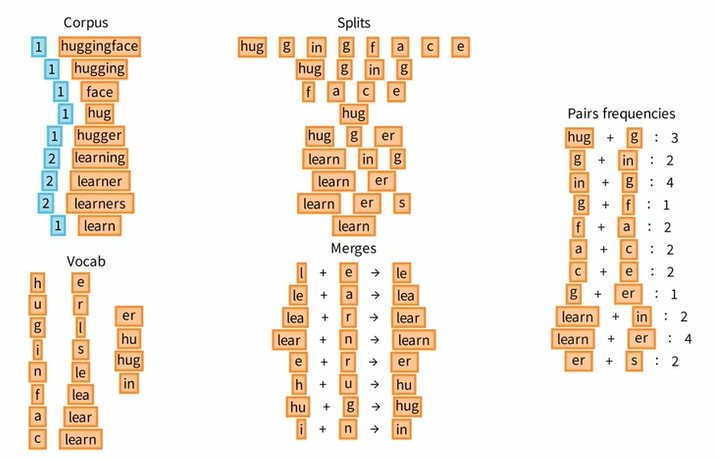
⑤ Tokenization
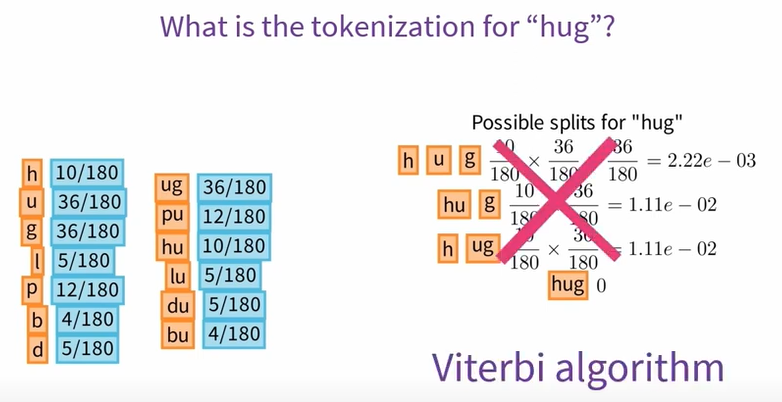
现在,我们已经了解了词汇和合并规则,可以对新文本进行标记,假设我们要对单词 hugs 进行标记。
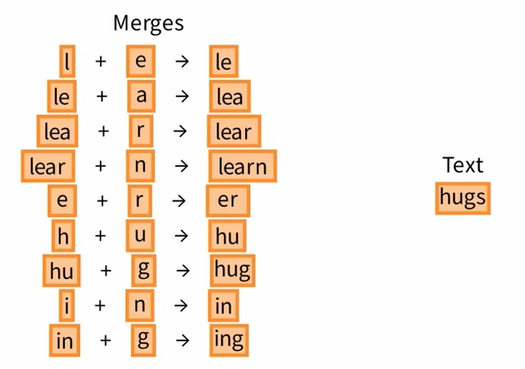
首先,我们将其分为基本单位 h u g s,构成一个字符列表,然后,我们检查合并规则 Merges,直到找到可以应用的规则,这里我们可以合并 h u g 为 hug,当我们到达合并规则的末尾时,标记化就完成了。
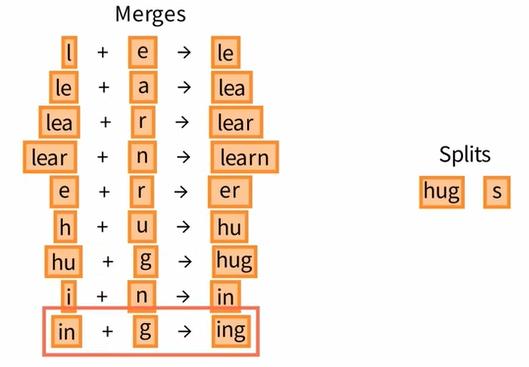
02 WordPiece tokenizer
The learning strategy for a WordPiece tokenizer is similar to that of BPE but differs in the way the score for each candidate token is calculated.
与 BPE 算法相似,WordPiece 算法同样首先建立由基本单元组成的初始词汇表,然后将该词汇表增加到所需的大小。
二者的不同之处:
Ⅰ Splits 当中不作为单词开头的字母前面添加了##标签
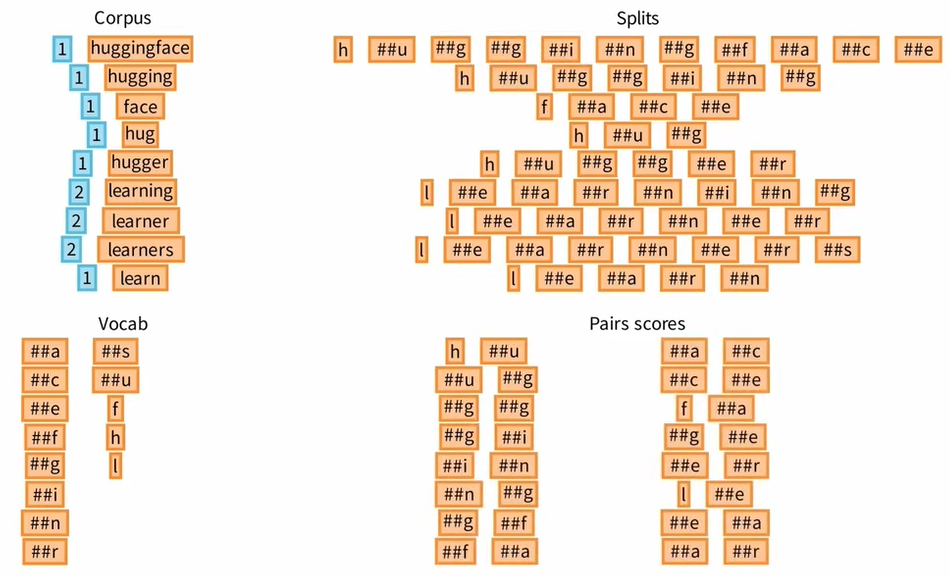
Ⅱ 统计 Pairs scores 而非 Pairs frequencies
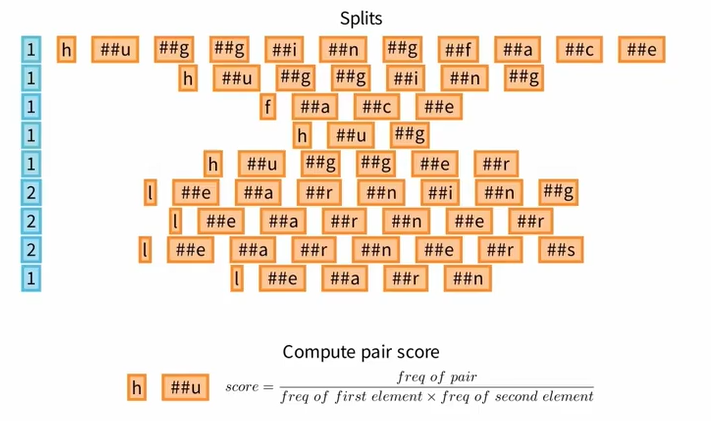
标记对的分数等于该对出现的频率除以第一个标记出现的频率与第二个标记出现的频率的乘积。也就是说,当该对出现的频率固定时,如果该对的子标记在预料库中出现的频率非常高,那么这个分数就会非常低。
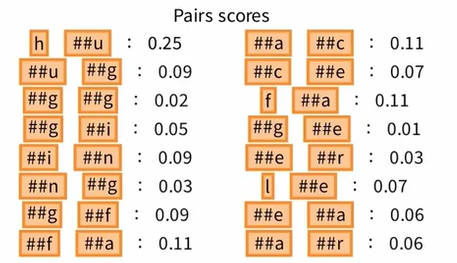
WordPiece tokenizer 的训练结果:
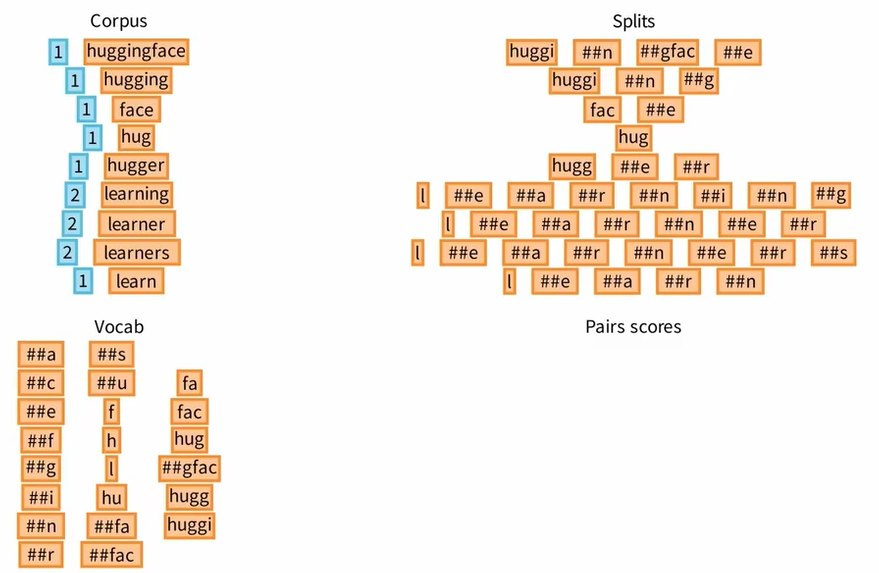
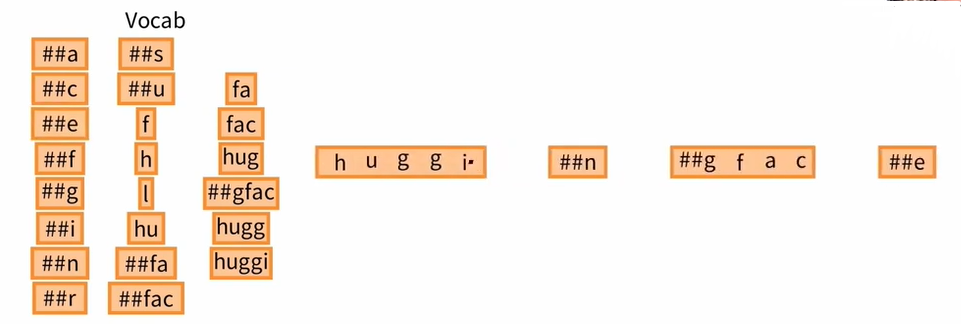
我们可以试着标记文本 huggingface,WordPiece tokenizer 要求在单词的开头寻找尽可能长的标记, 然后,开启单词的剩余部分,继续寻找尽可能长的标记,就这样,huggingface 最终被分为 4 个标记。

03 SentencePiece tokenizer
我们做一种假设,现在需要对中文或日语进行 BPE 算法,其中单词之间没有明确的空格,所以我们必须为这些语言实现不同的预标记器,那么,SentencePiece tokenizer 试图解决这个问题。
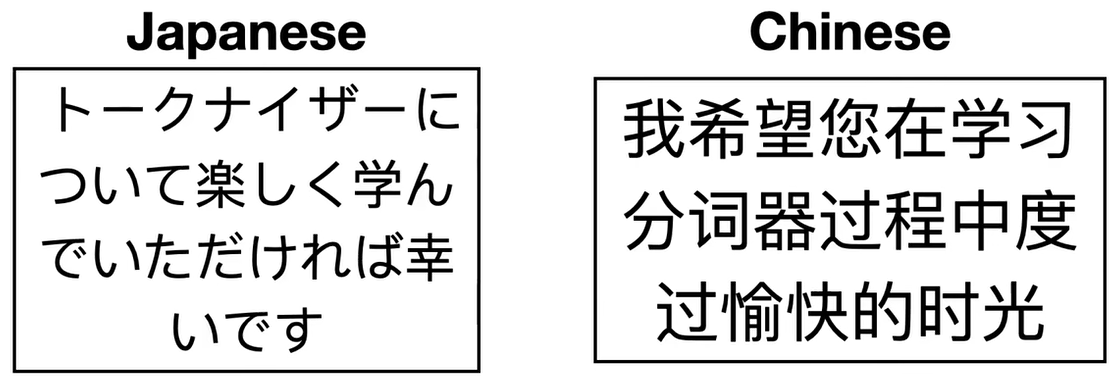
首先,将中文或日语输入转化为英文,其是一个包含空格的字符流,她采用和 unigram 相同的合并算法,其基本词汇初始化为大量 token,然后逐步修剪每个 token 以获得较小的词汇量,直到到达所需大小。
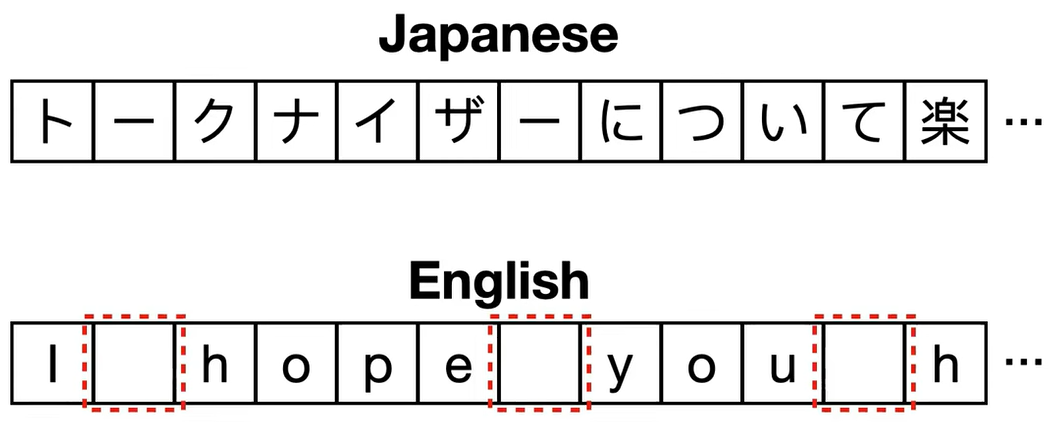
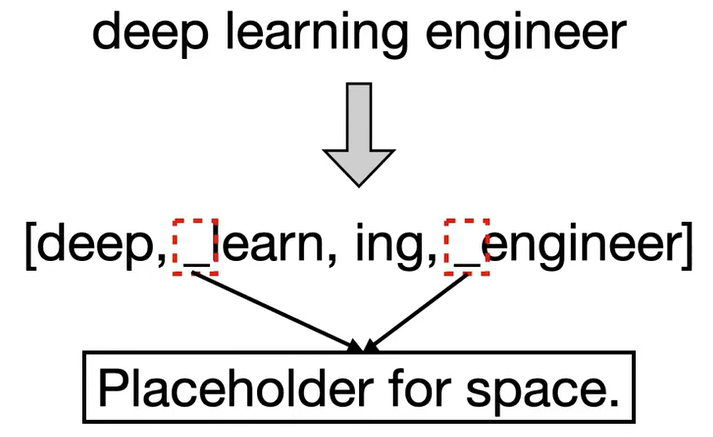
例如,在 deep learing engineer 这一句子上应用 SentencePiece tokenizer 后得到的 token 如下,某些 token 前面有一个下划线,代表空格的占位符,和 BPE 或者 WordPiece 相比,它允许我们通过简单的连接 token 并使用 SP 替换下划线来构建原始句子。
04 Unigram tokenizer
Unigram tokenizer 的整体策略是,从一个非常大的词汇表开始,然后再每次迭代中删除标记,直到达到所需大小为止。
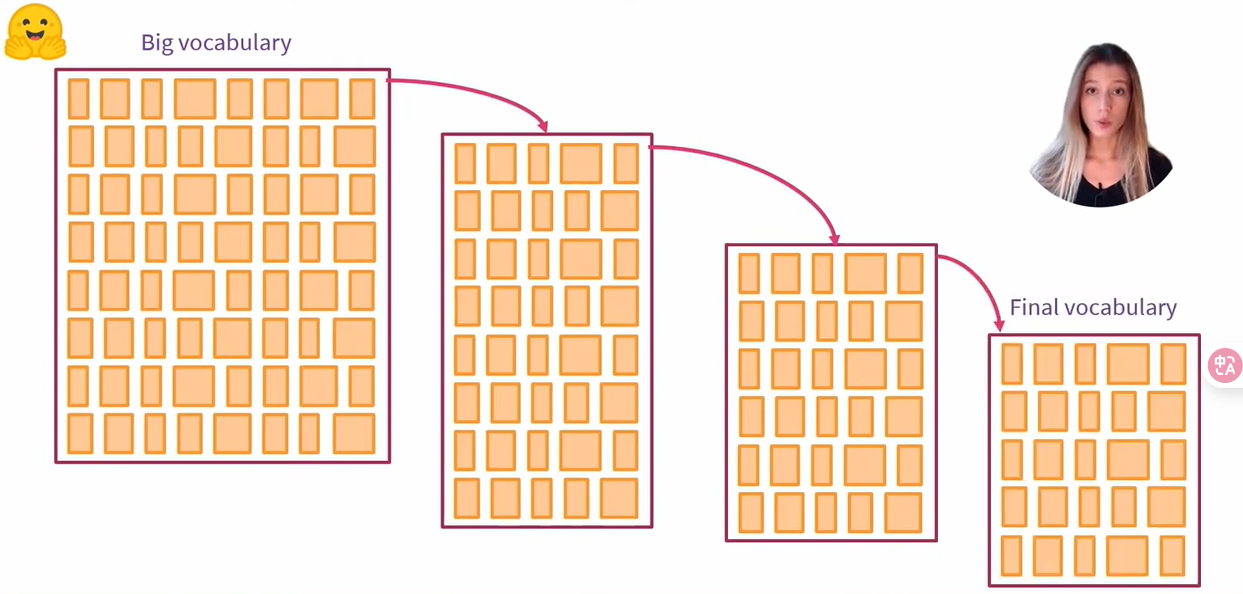
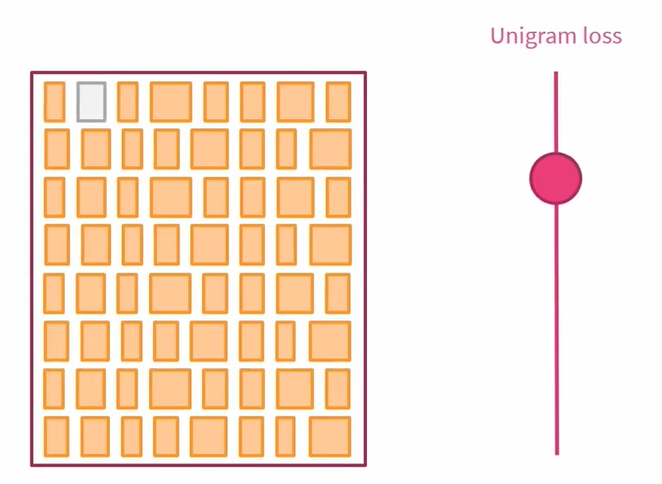
在每次迭代中,利用 Unigram 模型计算训练语料库的损失,我们通过依次从词汇表中删除每个标记来观察损失的演变,最终,我们将选择删除损失增加较少的 p% 个标记。
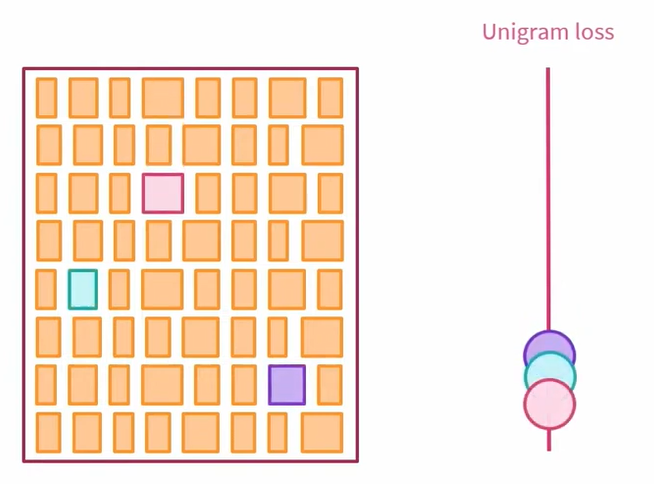
这里需要解释一下,什么是 Unigram 模型。
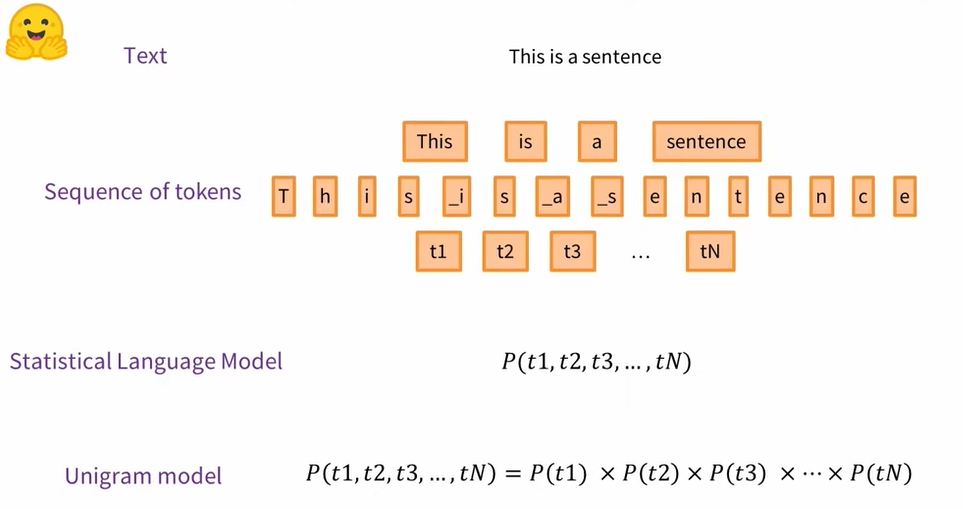
Unigram 模型是一种统计语言模型,该统计语言模型会为文本分配一个概率,因为文本实际上是一个标记序列。可以想象,最简单的标记序列是组成句子或字符的单词。Unigram 模型的特殊之处在于,它假设每个单词的出现与前一个单词无关,一段文本的概率等于组成该文本的标记的概率的乘积。
这里需要注意的是,这是一个非常简单的模型,它不适用于文本生成,因为该模型总是会生成相同的标记,即具有最大概率的标记。尽管如此,对于进行标记化,该模型对我们来说非常有用,因为它可用于估计不同短语的相对可能性。
现在我们准备回到对训练算法的解释,假设我们的训练语料库中有10次单词hug、12次单词pug、5次单词lug、4次bug和5次dug。正如视频开头所说,训练从大量词汇开始。显然,由于我们使用的是玩具语料库,所以词汇量不会那么大,但它应该可以向我们展示其中的原理。
第一种方法是列出所有可能的严格子字符串,这就是我们在这里要做的。我们还可以使用词汇量非常大的 BPE 算法,这样我们就有了最初的词汇表。
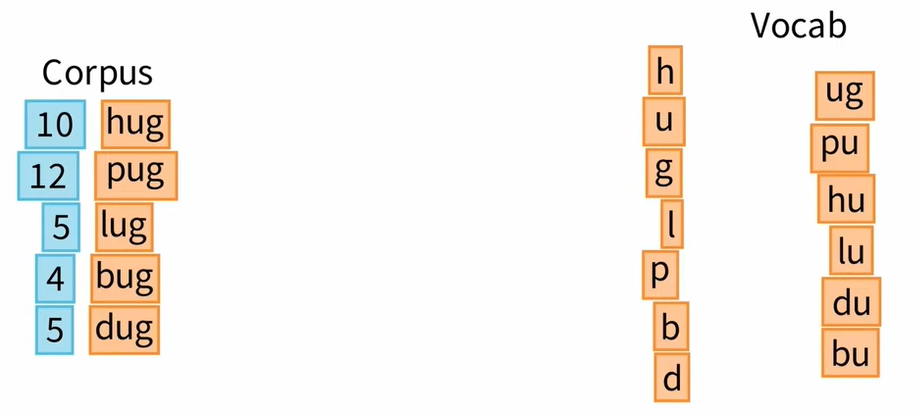
Unigram标记器的训练基于期望最大化方法:在每次迭代过程中,我们估计词汇表中标记的概率。然后,我们删除 p% 的标记,以最小化语料库的损失,这些标记不属于基本字符,因为我们希望在最终的词汇表中保留基本字符,以便能够标记任何单词。
① 1st iteration
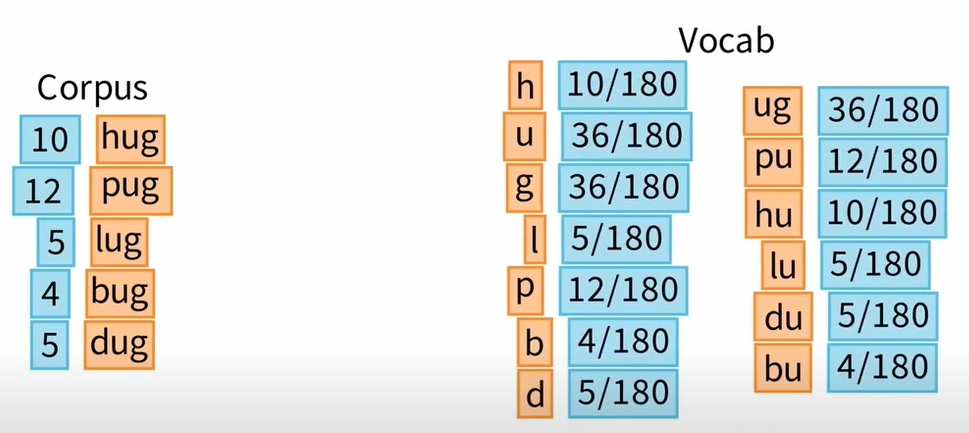
Ⅰ E-step: Estimate the probabilities
一个标记的概率可以简单地通过该标记在我们的训练语料库中出现的次数除以所有标记出现的总次数来估计。
Ⅱ M-step: Remove the token that least impacts the loss on the corpus
文本“Hug”的Unigram LM标记化将是出现概率最高的标记化。为了找到它,最简单的方法是列出文本“Hug”的所有可能的分割,计算每个分割的概率,然后选择概率最高的分割。
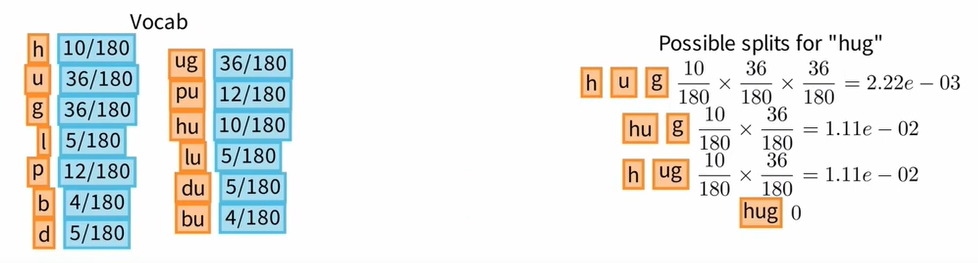
使用当前词汇表,2个标记化获得完全相同的概率。因此我们选择其中一个并记住相关的概率。为了计算训练语料库的损失,我们需要对语料库中剩余的所有单词进行标记,损失就是语料库所有单词出现频率的总和乘以与该单词标记化相关的概率的对数的倒数,我们在这里损失了 170 。

我们最初的目标是减少词汇量。为此,我们将从词汇表中删除一个标记并计算相关损失。例如,让我们删除标记 “ug”。我们注意到,用字母 h 和元组 ug 对 "hug” 进行标记化现在是不可能的。
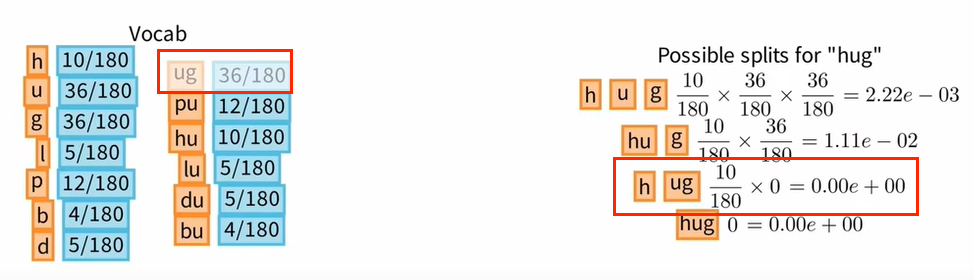
尽管如此,正如我们之前看到的,两个标记化具有相同的概率,我们仍然可以以 1.10 减 2 的概率选择剩余的标记化。词汇表中其他单词的标记也保持不变,最后即使我们从词汇表中删除标记 “ug”,损失仍然等于 170。
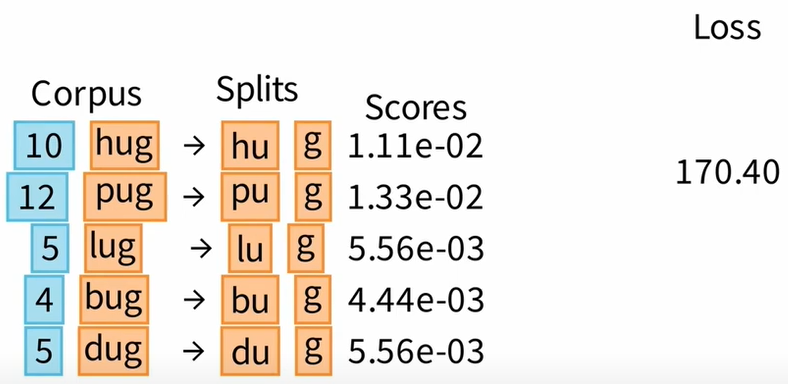
对于第一次迭代,我们发现,不管删除任何标记都不会影响损失。

因此,我们将在开始第二次迭代之前随机选择删除标记"ug”。
② 2nd iteration
Ⅰ E-step: Estimate the probabilities
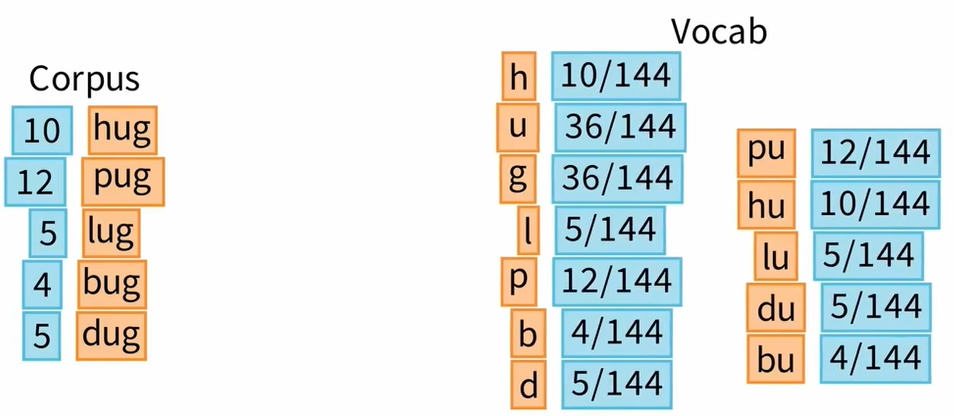
Ⅱ M-step: Remove the token that least impacts the loss on the corpus
例如,如果我们现在删除由字母h”和“u"组成的标记,那么 hug 就只剩下一种可能的标记化。词汇表中其他单词的标记化没有改变。
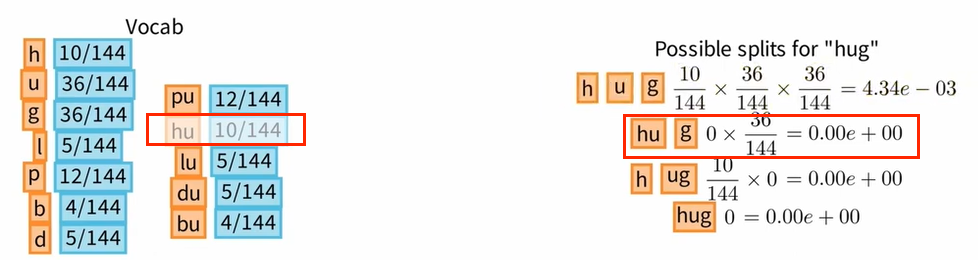
最后,通过从词汇表中删除由字母“h"和“u"组成的标记,我们获得了 168 的损失。

最后,为了选择删除哪个标记,我们将针对词汇表中每个剩余的非基本标记计算相关损失,然后比较它们之间的损失。我们将要删除的标记是对损失影响最小的标记:这里是标记 bu。本次迭代中可以删除的第二个标记是 du。
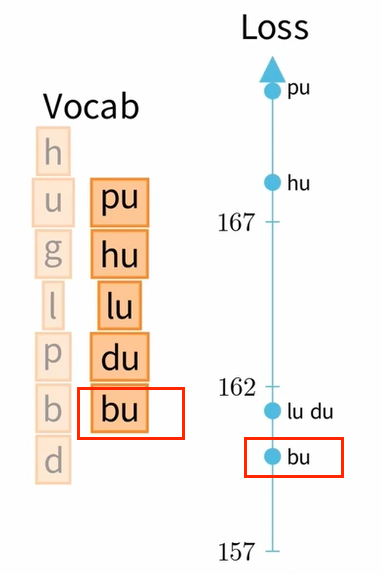
就是这样,我们只需重复这些步骤,直到获得所需大小的词汇量。
最后一点,在实践中,当我们使用 Unigram 模型对单词进行标记时,我们不会在比较单词可能的拆分概率集以保留最佳拆分概率之前计算这些概率集,而是使用效率更高的Viterbi算法。就是这样!