【Java并发】深入理解synchronized
系列文章目录
文章目录
- 系列文章目录
- 一、synchronized简介
- 二、synchronized实现原理
- 1.对象锁(monitor)机制
- 2.synchronized的happens-before关系
- 3. 锁获取和锁释放的内存语义
- 三、CAS操作
- 1. 什么是CAS
- 2.CAS的操作过程
- 3. synchronized 与 CAS 的比较
- 4.CAS的应用场景
- 四、synchronized优化
- 1.偏向锁
- 2.轻量级锁
- 五、具体实例
- 总结

一、synchronized简介
在本篇文章开始之前,首先通过一段代码来看一个现象。
public class synchronizedDemo implements Runnable {private static int count = 0;public static void main(String[] args) {for (int i = 0; i < 10; i++) {Thread thread = new Thread(new synchronizedDemo());thread.start();}try {Thread.sleep(500);} catch (InterruptedException e) {e.printStackTrace();}System.out.println("result: " + count);}@Overridepublic void run() {for (int i = 0; i < 1000000; i++)count++;}
}
上述示例代码中开启了 10 个线程,每个线程都累加了 1000000 次,如果结果正确,累加总数就应该是 10×1000000 = 10000000。可是尽管代码运行多次,结果却都不是这个数,且每次的运行结果都不一样。这是为什么呢?
有什么好的解决方案吗?线程运行时拥有自己的栈空间,执行时会在自身的栈空间中运行。如果多线程间没有共享的数据,也就是说多线程间若没有协作完成一件事情,那么多线程有可能不会发挥其优势,不能带来巨大的价值。那么共享数据的线程安全问题怎样处理?很自然的想法就是每个线程依次去读写这个共享变量,这样就不会有任何数据安全的问题,因为每个线程所操作的都是当前最新版本的数据。
Java 关键字 synchronized 就具备控制数据访问的相对顺序,让每个线程都能够 “依次排队” 操作共享变量的功能。但是这种同步机制效率相对较低,经过底层一系列的策略优化,目前 synchronized 在性能上以及并发效率上已经得到了显著的提升,同时 synchronized 还是其他并发容器实现的基础。
二、synchronized实现原理
在Java代码中,synchronized 可以使用在方法中,也可以使用在代码块中,方法包括实例方法和静态方法,分别锁的是类的实例对象和类对象。而使用在代码块中,根据锁的目标对象也可以分为三种,。这里需要注意的是,如果锁的是类对象,尽管 new 多个实例对象,也依然会被锁住。synchronized 的使用很简单,那么它背后的原理以及实现机制是怎样的呢?
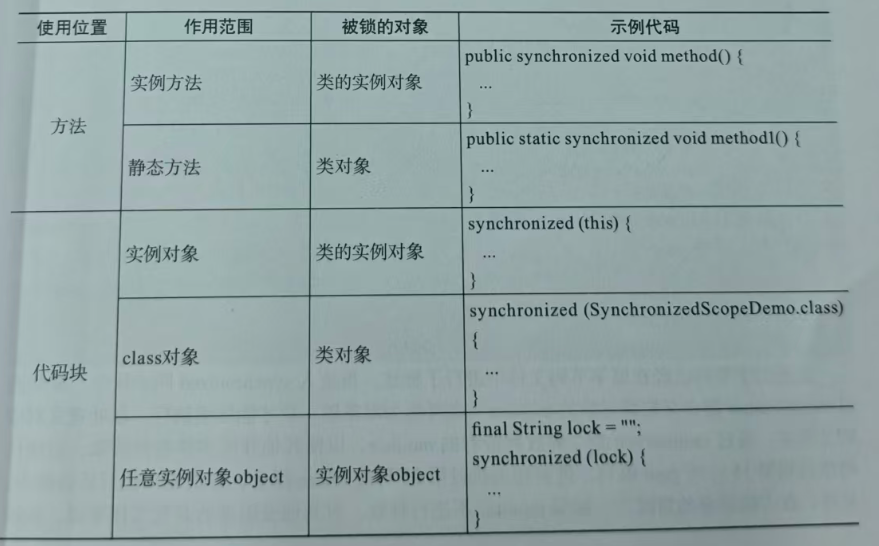
1.对象锁(monitor)机制
现在来进一步分析 synchronized 的具体底层实现,一个简单的示例代码如下:
public class SynchronizedDemo {public static void main(String[] args) {synchronized (SynchronizedDemo.class) {System.out.println("hello synchronized! ");}}
}
上述代码通过 synchronized “锁住” 当前类对象来进行同步,将 Java 代码进行编译之后,可通过 javap -v SynchronizedDemo.class 查看对应的 main () 方法的代码:
public static void main(java.lang.String[]);descriptor: ([Ljava/lang/String;)Vflags: ACC_PUBLIC, ACC_STATICCode:stack=2, locals=3, args_size=10: ldc #22: dup3: astore_14: monitorenter5: getstatic #38: ldc #410: invokevirtual #513: aload_114: monitorexit15: goto 2318: astore_219: aload_120: monitorexit21: aload_222: athrow23: return
再进入 synchronized 同步块中,需要通过 monitorenter 指令获取到对象的 monitor(也可称为对象锁)后才能继续执行,在处理完对应的方法后,通过 monitorexit 指令释放所持有的 monitor,以便其他并发实体进行获取。后续代码执行到第 15 行的 goto 语句,进而转去执行第 23 行的 return 指令,方法成功执行后会退出。另外,在方法异常的情况下,如果 monitor 不进行释放,对其他被阻塞的并发实体来说,就没有机会获取到 monitor 了,系统会形成死锁状态,但显然这样是不合理的。因此,针对异常的情况,会执行到第 20 行通过指令 monitorexit 释放 monitor 锁,接着通过第 22 行的指令 athrow 抛出对应的异常。从字节码指令分析中可以看出,使用 synchronized 是具备隐式加锁和释放锁的操作便利性的,并且针对异常情况也做了释放锁的处理。每个对象都存在一个与之关联的 monitor,线程对 monitor 持有的方式以及时机决定了 synchronized 的锁状态以及状态升级方式。monitor可通过C++中的ObjectMonitor 实现。
ObjectMonitor中主要用WaitSet和Entryist两个队列保存ObjectWaiter 对象,每个阻塞等待获取锁的线程都会被封装成ObjectWaiter 对象进行入队操作,与此同时,获取到锁资源的线程会进行出队操作。另外,owner会指向当前持有ObjectMonitor 对象的线程。
当多个线程想要获取锁时,首先会进入_EntryList队列,其中一个线程获取到对象的monitor后,对monitor而言就会将_owner 变量设置为当前线程,并且monitor维护的计频器会加1。如果当前线程执行完后退出,monitor中的_owner变量就会清空并且让计数器1,这样就能让其他线程竞争到monitor。另外,如果调用了wait()方法,当前线程就会进Waitset中等待被唤醒,如果被唤醒并且执行退出,也会对状态量进行重置,以便其他线程能够获取到 monitor。
从线程状态变化的角度来看,如果要想进入同步块或执行同步方法,都需要先获取到对象的monitor,如果获取不到,就会变更为BLOCKED状态。
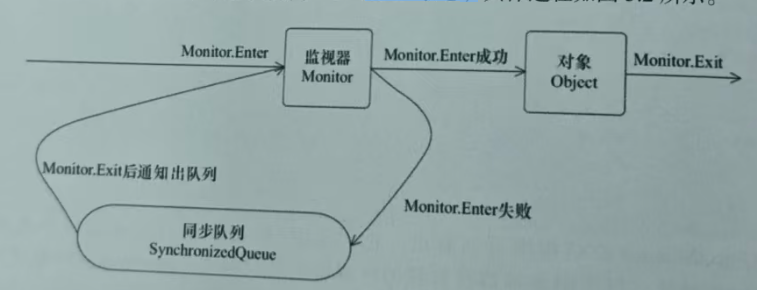
从上图可以看出,任意线程对 Object的访问,首先要获得Object 的 monitor,如果获取失败,该线程就会进人同步队列,线程状态会变为BLOCKED。等monitor持有者释放后在同步队列中的线程才会有机会重新获取monitor,继续执行代码。
2.synchronized的happens-before关系
对同一个 monitor 的解锁 happens-before 于对该monitor 的加锁。为了进一步了解synchronized的并发语义,下面通过示例代码分析这条happens-before规则,示例代码如下:
public class MonitorDemo {private int a = 0;public synchronized void writer() { // 1a++; // 2} // 3public synchronized void reader() { // 4int i = a; // 5} // 6
}
在第 5 步操作中读取到的变量 a 的值是多少呢?这就需要通过 happens - before 规则进行分析,上述示例代码中的 happens - before 关系如图 3.3 所示。
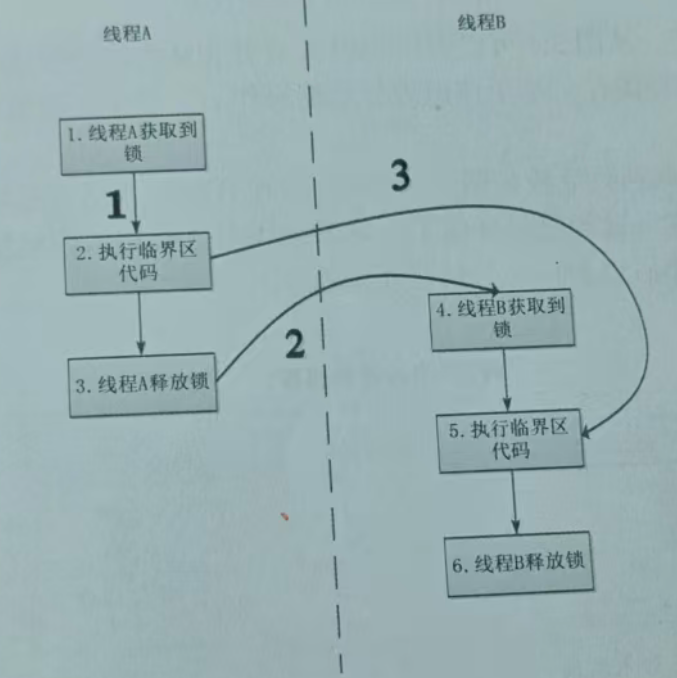
上图中,每个箭头代表两个节点之间的 happens - before 关系,线条 1 是通过程序顺序规则推导出来的,线条 2 是通过监视器锁规则推导出线程 A 释放锁 happens - before 线程 B 加锁的,线条 3 则是通过传递性规则进一步推导的 happens - before 关系。最终得到的结论是操作 2 happens - before 操作 5,通过这个关系可以得出什么呢?
根据 happens - before 规则:如果 A happens - before B,则 A 的执行结果对 B 可见。那么在上述示例代码中,线程 A 先对共享变量 a 进行加 1 操作,由操作 2 happens - before 操作 5 的关系可知线程 A 的执行结果对线程 B 可见,即线程 B 所读取到的变量 a 的值为 1。
3. 锁获取和锁释放的内存语义
JMM的核心分为两部分:happens-before规则以及内存抽象模型。我们前面分析了synchronized 的happens-before 关系,接下来看看基于Java 内存抽象模型的synchronized 的内存语义。
当两个线程同时对线程中的同一个变量操作时。
针对线程A的操作,线程A会首先从主内存中读取共享变量a = 0,然将该变量复制到线程本地内存。基于该值进行数据操作后,变量a变为1,最后会将值写人内存中。
对于线程B而言,线程B获取锁后会强制从主内存中读取共享变量a的值,而此时变量a已经是最新值了。接下来线程B会将该值复制到工作内存中进行工作,同样地,执行完操作后也会将其重新写人主内存中。
从横向来看,线程A和线程B都是基于主内存中的共享变量互相感知到对方的数据操作并基于共享变量完成并发实体中的协同工作,整个过程就好像线程A给线程B发送了一个据变更的“通知”,这种通信机制就是基于共享内存的并发模型结构。
经过上面的解释,我们可以知道synchronized最大的特征就是在同一时刻只有一个线程能够获得对象monitor,从而确保当前线程能够执行到相应的同步逻辑,对线程而言会表现为互斥性(排他性)。当然,这种同步方式会有效率相对低下的弊端,既然同步流程不能发生改变,那么能不能让每次获取锁的速度更快或降低阻塞等待的概率呢?
也就是通过局部的优化提升系统整体的并发同步效率。例如去收银台付款的场景,之前的方式是顾客都去排队结账,然后用纸币付款,收银员找零。甚至有些人付款时还需要先从包里拿出钱包再拿出钱,这个过程是比较耗时的。针对付款的流程,可以通过线上化的手段进行优化。现在顾客只需要通过支付宝扫描二维码就可以完成付款了,也省去了收银员找零的时间。尽管整个付款场景还是需要排队,但是因为付款(类似于获取锁、释放锁)环节的优化导致耗时大大缩短,对收银台(系统整体并发效率)而言操作效率得到了极大的提升。如此类比,如果能对锁操作过程进行优化,可能也会对并发效率带来一定的提升。
三、CAS操作
1. 什么是CAS
synchronized 是一种悲观锁策略,它假设每次执行临界区代码都会产生冲突,所以当前线程在获取到锁的同时也会阻塞其他线程获取该锁。而 CAS 操作(又称为无锁操作)是一种乐观锁策略,它假设所有线程访问共享资源时不会出现冲突,既然不会出现冲突,自然就不会阻塞其他线程的操作,因此线程不会出现阻塞停顿的状态。如果出现冲突了怎么办?无锁操作是使用比较交换方式(compare and swap,CAS)鉴别线程是否出现冲突,出现冲突就重试当前操作直到没有冲突为止。
2.CAS的操作过程
CAS 的操作过程可以通俗地理解为 CAS(V, O, N):
(1)V 为内存地址存放的实际值;
(2)O 为预期的值(旧值);
(3)N 为更新的新值。
当 V 和 O 相同时,也就是旧值和内存中实际的值相同时,表明该值没有被其他线程更改,即该旧值 O 就是目前最新的值了,自然可以将新值 N 赋值给 V。反之,若 V 和 O 不相同,表明该值已经被其他线程改过,则该旧值 O 不是最新版本的值,所以不能将新值 N 赋给 V。当多个线程并发使用 CAS 操作一个变量时,只有一个线程会成功,并成功更新,余者会失败。失败的线程会重新尝试,当然也可以选择挂起线程。
3. synchronized 与 CAS 的比较
元老级的 synchronized(未优化前)最主要的问题是采用了悲观锁策略,即在存在线程竞争的情况下会出现线程阻塞和唤醒锁带来的性能问题,因为这是一种互斥同步(阻塞同步)。
CAS 则是采用乐观锁策略,而并不是武断地将线程挂起,当 CAS 操作失败后,失败的线程会进行一定的尝试,而非等待唤醒操作,因此它也叫作非阻塞同步。这是两者主要的区别。
4.CAS的应用场景
在 java.util.concurrent(j.u.c)包中利用 CAS 实现的类有很多,可以说是支撑起整个 concurrency 包实现的基石工具。例如,在 Lock 实现中会有 CAS 改变 state 变量,以及在 atomic 包中的实现类,这几乎都是用 CAS 实现的。但是 CAS 在使用过程中会存在一些常见的问题。
(1)ABA 问题
因为 CAS 会检查旧值有没有变化,这里存在这样一个有意思的问题。例如,一个旧值 A 变成了 B,然后再变成 A,刚好在做 CAS 时检查发现旧值并没有变化,依然为 A,但实际上旧值的确发生了变化。解决方案:可以沿袭数据库中常用的乐观锁方式,添加一个版本号,原来的变化路径 A→B→A 就变成了 1A→2B→3A。
(2)自旋时间过长
使用 CAS 这种非阻塞同步的方式,当出现数据竞争时就会通过自旋操作进行下一次尝试,如果这里自旋时间过长,那么对性能是会有很大消耗的。
(3)只能保证一个共享变量的原子操作
当对一个共享变量执行操作时,CAS 能保证其原子性;当对多个共享变量进行操作时,CAS 不能保证其整体的原子性。有一个解决方案是利用对象整合多个共享变量,即一个类中的成员变量就是这几个共享变量,然后对这个对象做 CAS 操作就可以保证其原子性。另外,j.u.c 包中 atomic 提供的 AtomicReference 可以保证引用对象之间的原子性。
四、synchronized优化
为了减少获得锁和释放锁带来的性能消耗,之后在实现上引入了“偏向锁”和“轻量级锁”策略,并且锁的状态也分成了无锁状态、偏向锁状态、轻量级锁状态以及重量级锁状态,代表不同的并发竞争情况,通过更加细颗粒度的区分以及不同的升级策略能够对加锁和释放锁的性能带来更大的提升。
1.偏向锁
HotSpot的作者经过研究,发现锁在大多数情况下不存在竞争,而且总是由同一线程多次获得,为了让锁能够被同一个线程以更低的成本获得,就引入了偏向锁机制。
(1)偏向锁的获取。
当一个线程访问同步块并获取锁时,会在对象头的 Mark Word 和栈帧的锁记录中存储偏向的线程 ID,后续线程如果需要获取锁,会与保存的线程 ID 进行比较,获取锁的主要步骤如下。
①判断锁状态,先检测 Mark Word 是否为可偏向状态,即是否为偏向锁 1,同时锁标识位为 01。
②若为可偏向状态,则测试线程 ID 是否为当前线程 ID。如果是,就执行步骤⑤,否则执行步骤③。
③如果线程 ID 不为当前线程 ID,则通过 CAS 操作竞争锁替换 Thread ID。如果竞争成功,就会将 Mark Word 的线程 ID 替换为当前线程 ID,否则执行步骤④。
④通过 CAS 竞争锁失败,说明当前存在多线程资源竞争的情况,则会执行锁撤销流程。
⑤执行同步逻辑。
(2)偏向锁的撤销。
偏向锁使用了一种等到竞争出现才释放锁的机制,所以当其他线程尝试竞争偏向锁时,持有偏向锁的线程才会释放锁。持有偏向锁的线程需要等待全局安全点(在这个时间点上没有正在执行的字节码),才会暂停拥有偏向锁的线程,转去检查其他线程的线程状态。如果线程不处于活动状态,就会将对象头设置为无锁状态,表示锁资源已经释放。如果线程仍然活跃,要么栈中的锁记录对象头的 Mark Word,要么重新偏向于其他线程,要么升级到轻量级锁。
(3)如何关闭偏向锁。
偏向锁在 Java 6 和 Java 7 中是默认启用的,但是它在应用程序启动几秒钟之后才会被激活,如有必要,可以使用 JVM 参数关闭延迟,如果确定应用程序中的锁在大部分情况下处于竞争状态,可以通过 JVM 参数关闭偏向锁。当出现锁竞争时默认会进入轻量级锁状态。
2.轻量级锁
引入轻量级锁的主要原因是:对于绝大部分的锁,它在整个同步周期内都不存在竞争,可能是线程能够交替获取到锁执行。轻量级锁与偏向锁的区别在于:偏向锁的设置是建立在大多数锁是由同一个线程获取的假设前提下,而轻量级锁则是建立在多个线程能够交替获取,且彼此出现竞争的概率很低的假设前提下。引入轻量级锁的主要目的是在没有多线程竞争的前提下,降低使用重量级锁带来的性能消耗。
触发轻量级锁的条件是:当关闭偏向锁功能或多个线程竞争偏向锁导致偏向锁升级为轻量级锁,Mark Word 的结构也变为轻量级锁的结构。如果存在锁并发竞争的情况,就会导致轻量级锁升级为重量级锁。
(1)加锁
①线程在执行同步块之前,JVM 会先在当前线程的栈帧中创建用于存储锁记录的空间 Lock Record,并将对象目前的 Mark Word 复制至 Lock Record(官方为这份副本加了一个 Displaced 前缀,即 Displaced Mark Word)。
②利用 CAS 操作尝试将对象的 Mark Word 更新为指向 Lock Record 的指针。如果 CAS 操作成功,表示竞争到锁,就将锁标志位变为 00,表示轻量级锁状态,并可以执行同步操作;如果失败则执行步骤③。③如果 CAS 操作失败,就通过自旋尝试获取,自旋到一定的次数仍然未成功,说明该锁对象已经被其他线程抢占了,这时轻量级锁需要膨胀为重量级锁,锁标志位变为 10,后面等待的线程将会进入阻塞状态。
(2)解锁
轻量级解锁时,会使用原子的 CAS 操作将 Displaced Mark Word 替换回到对象头,如果成功,就表示没有竞争发生并释放锁。如果替换失败,说明有其他线程尝试获取该锁,锁已经膨胀为重量级锁,则需要唤醒阻塞等待的线程。
五、具体实例
开篇的代码现象就可以得到解决,更正后的代码如下:
public class synchronizedDemo implements Runnable {private static int count = 0;public static void main(String[] args) {for (int i = 0; i < 10; i++) {Thread thread = new Thread(new synchronizedDemo());thread.start();}try {Thread.sleep(500);} catch (InterruptedException e) {e.printStackTrace();}System.out.println("result: " + count);}@Overridepublic void run() {synchronized (synchronizedDemo.class) {for (int i = 0; i < 1000000; i++)count++;}}
}
上述示例代码中开启10个线程,每个线程都在原值的基础上累加了1000000次,最终正确的结果为10x1000000=10000000。这里能够计算出正确的结果是因为在做累加操作时使用了同步代码块,这样就能保证每个线程所获得共享变量的值都是当前最新的值。如果不使用步,就可能出现虽然线程A累加了,但线程B做累加操作时仍使用原来的“脏值”数据、而导致累加的计算结果错误。这里使用synchronized 根据内存语义就能够保障每个线程在工作内存中都是最新值,因此最终的计算结果就是正确的。
总结
总结
本文主要通过源码的方式带大家学习synchronized关键字,通过源码了解其实现的根本方法的源码来理解其原理。
参考书籍 深入理解Java并发
以上就是本文全部内容,感谢各位能够看到最后,如有问题,欢迎各位大佬在评论区指正,希望大家可以有所收获!创作不易,希望大家多多支持!