RWKV架构讲解
简介
RWKV(Receptance Weighted Key-Value)是一种结合了RNN(循环神经网络)和Transformer架构优势的模型。其核心设计通过线性注意力机制替代传统Transformer的二次复杂度注意力,显著降低计算资源消耗,同时保持长序列建模能力。RWKV支持并行训练与高效推理,适用于资源受限场景下的长文本处理任务。
架构讲解
循环神经网络(RNN)
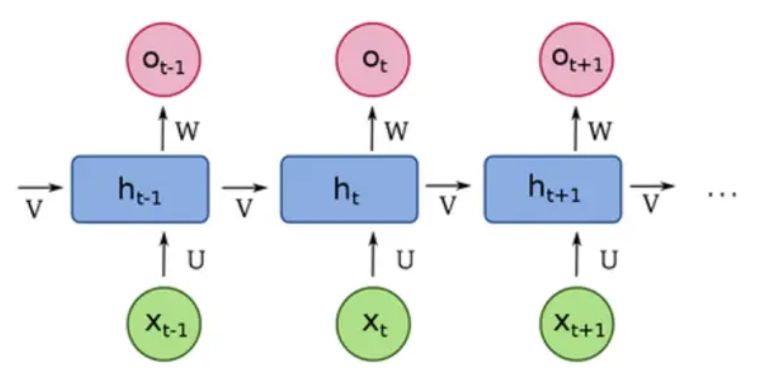
RNN(Recurrent Neural Network)是一种用于处理序列数据的神经网络结构。与传统的前馈神经网络不同,RNN通过隐藏层的循环连接保留历史信息,使网络具备记忆能力。其核心特点是每一时刻的隐藏状态不仅取决于当前输入,还与前一刻的隐藏状态相关。
RNN的优点是能够处理变长序列数据,适用于时间序列、自然语言等任务,通过共享参数减少模型复杂度。
但是由于每个时间步的计算都要依赖上一个时间步的隐藏状态,导致计算复杂度较高。同时存在梯度消失或爆炸问题,导致长序列训练困难,长期依赖捕捉能力较弱。
Transformer
Transformer是一种基于自注意力机制(Self-Attention)的深度学习模型,最初由Vaswani等人于2017年提出。其核心优势在于并行化处理能力和对长距离依赖关系的有效建模,广泛应用于自然语言处理(NLP)、计算机视觉(CV)和多模态任务。但是它的时间复杂度不够友好。
Transformer的整体架构:
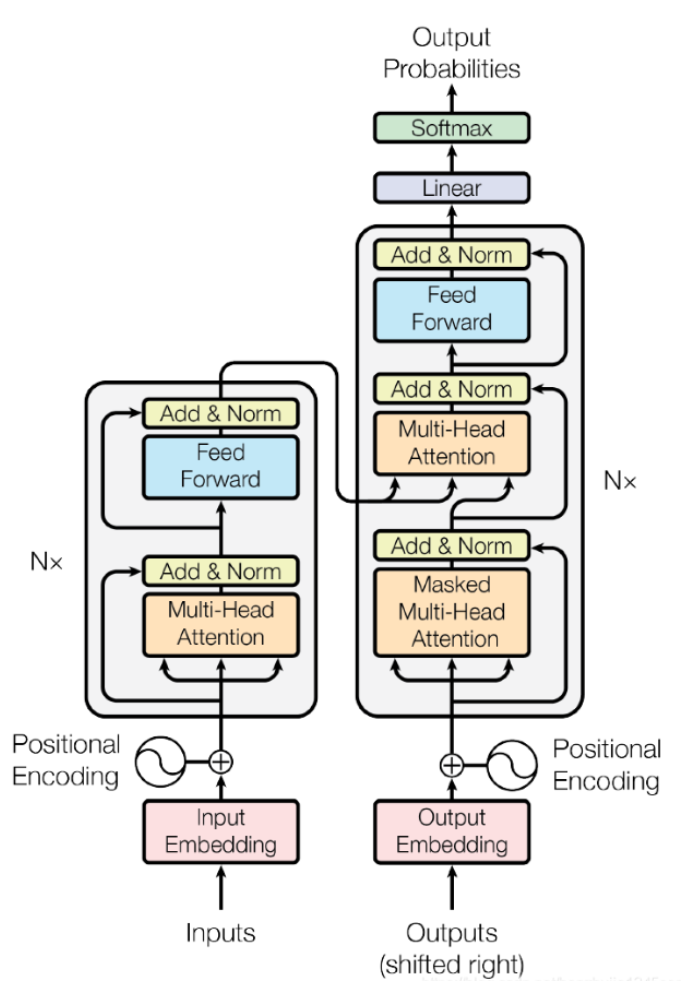
具体Transformer的讲解请看博主的这篇文章:
https://blog.csdn.net/qq_73038863/article/details/152115310?fromshare=blogdetail&sharetype=blogdetail&sharerId=152115310&sharerefer=PC&sharesource=qq_73038863&sharefrom=from_link
RWKV(Receptance Weighted Key-Value)
RWKV架构图如下所示:
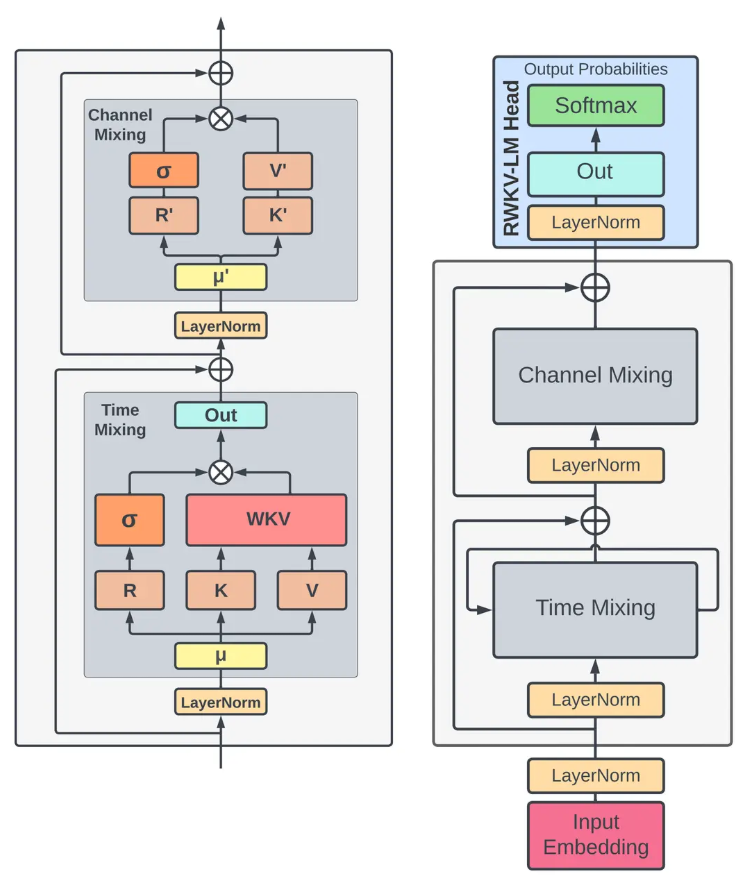
RWKV结合了循环神经网络(RNN)和Transformer的优点,旨在提高模型的效率和性能。RWKV架构主要包括以下几个关键部分:输入嵌入(Input Embedding)、时间混合(Time Mixing)、通道混合(Channel Mixing)和RWKV-LM头部(RWKV-LM Head)。
输入嵌入(Input Embedding)
功能:将输入的离散数据(如文本、图像等)转换为模型可以处理的连续向量。
输入数据首先通过嵌入层,将每个输入单元(如单词、像素块等)映射到一个高维向量空间中。
假设我们有一个单词序列 "Hello",我们想要将其输入到RWKV模型中。首先,我们需要一个嵌入矩阵,它将每个单词映射到一个固定维度的向量(例如,维度为128)。如果我们的词汇表中有10000个单词,嵌入矩阵的大小将是10000x128。每个单词在词汇表中都有一个唯一的索引,我们使用这个索引来从嵌入矩阵中检索对应的向量。
"H" -> [0.1, 0.2, ..., 0.128]
"e" -> [0.3, 0.4, ..., 0.128]
"l" -> [0.5, 0.6, ..., 0.128]
"o" -> [0.7, 0.8, ..., 0.128]
时间混合(Time Mixing)核心模块
功能:处理输入数据的时间维度(序列维度),捕捉序列中元素之间的依赖关系。
LayerNorm:对输入进行层归一化,稳定训练。
μ:输入数据(如嵌入后的位置编码序列)。
K, V:由 μ 投影得到的键和值。
R:递归状态向量(recurring state),不是 Query!而是时间混合模块中的状态变量,相当于“可变的查询”或“上下文感知器”。用于模拟“查询”的作用,但会随时间步更新。
σ:通过 sigmoid 激活函数生成注意力权重。
WKV:核心函数,计算加权的键值组合,利用 R、K、V 和 σ 构造输出。
Out:经过 WKV 处理后的输出。
残差连接:将输出与输入相加,保留原始信息。
通道混合(Channel Mixing)核心模块
功能:处理输入数据的通道维度,捕捉不同特征之间的相互作用。
LayerNorm:归一化输入。
μ':上一步的输出。
R', K', V':从 μ' 投影得到的三个分支,用于构建门控式通道交互。
σ:激活函数(如 sigmoid),用于生成通道级别的权重。
Out:通过 R' ⊙ σ(K') ⊙ V' 等操作获得。
残差连接:将加权后的输出与输入进行残差连接。
RWKV-LM头部(RWKV-LM Head)
功能:生成最终的输出概率分布,用于预测下一个时间步的输出。也就是把模型内部已经学到的“下一个词知识”变成可读的概率分布。
LayerNorm:对经过时间混合和通道混合后的输出进行层归一化。
Out:通过一个线性层(或全连接层)生成输出。
Softmax:将输出通过Softmax函数转换为概率分布,用于预测下一个时间步的输出。例如,模型可能会预测下一个单词是 "World" 的概率最高。
RWKV的高效线性复杂度
Transformer里的自注意力机制如下:
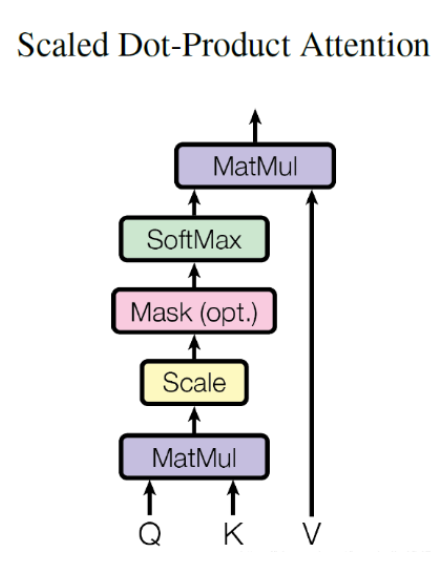
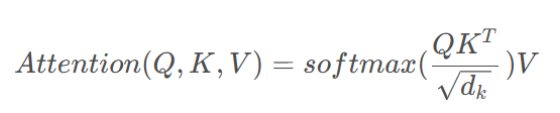
Transformer中QK^T 计算得到一个 N×N 的注意力权重矩阵。
RWKV不再显式计算所有 token 之间的 attention 权重矩阵,以可学习的状态向量 R 在序列推进过程中动态累积加权的键值信息,使得每一步的计算和存储仅与模型维度相关。因此整体序列长度 N 的计算量从 O(N²) 降到 O(N)。
具体一点是:
在 RWKV 的 Time Mixing 模块(具体到WKV模块)中,不显式计算注意力分数,而是通过状态传递“记住”过去的重要信息。
输出不是通过计算所有 token 之间的注意力权重得到的,而是通过两个可递归更新的状态变量来在线性时间内累积历史信息。
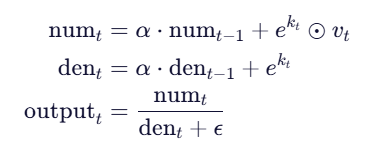
每步只更新两个维度为 d 的向量 (num,den),每步复杂度为 O(d),总复杂度O(N⋅d)≈O(N)。