大型语言模型(LLM)基础:从原理到核心概念详解(GPT-4 / 文心一言 / 通义千问)
当你用 ChatGPT 写邮件、用文心一言生成 PPT 大纲、用通义千问调试代码时,是否好奇这些 AI 背后的 “大脑” 是如何工作的?大型语言模型(LLM)已成为 AI 时代的基础设施,但要真正用好它们,必须先理解其底层逻辑。本文将带你穿透 “黑箱”,系统解析 LLM 的工作原理、Token 化机制、上下文长度等核心概念,为深入掌握大模型技术打下基础。
一、什么是大型语言模型(LLM)?
大型语言模型(Large Language Model,简称 LLM)是一类基于海量文本数据训练的 AI 模型,核心能力是理解人类语言并生成符合逻辑的文本。与传统 AI 不同,LLM 通过 “预训练 + 微调” 的模式,能处理翻译、写作、问答、代码生成等多类任务,无需为每个任务单独设计模型。
LLM 的 “大” 体现在哪里?
- 参数规模:从数十亿到数万亿(如 GPT-4 参数超 1 万亿,文心一言、通义千问也达千亿级)
- 训练数据:涵盖书籍、网页、论文等 TB 级文本(几乎包含人类历史上大部分公开文字)
- 能力边界:能理解复杂语义、逻辑推理、甚至展现类 “常识” 的判断
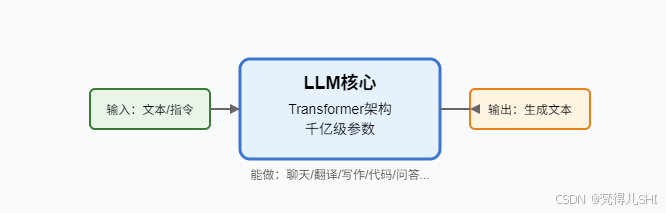
为什么 LLM 能 “理解” 语言?
本质上,LLM 并不像人类一样 “理解” 语义,而是通过统计规律预测 “下一个词”。它在训练中学习到 “词语之间的关联模式”—— 比如 “下雨天要带” 后面接 “伞” 的概率远高于 “手机”,“Python 是一种” 后面接 “编程语言” 的概率最高。
这种基于概率的预测能力,在足够大的模型规模和数据量支撑下,会涌现出类似 “理解” 和 “推理