中山大学联合项目 论文解读 | iManip:面向机器人操作的技能增量学习
核心问题
在机器人操作领域,“通用智能体” 的研发始终是核心目标 —— 即让机器人能像人类一样,基于已有技能逐步学习新能力,而非每次学习新技能都需从零训练。
中山大学计算机学院联合鹏城实验室、教育部机器智能与先进计算重点实验室,以Franka 机械臂为核心实验载体,提出了iManip 技能增量学习框架。
该框架通过 “时序重放策略” 与 “可扩展 PerceiverIO 结构” 的创新组合,成功解决了机器人操作中会因忽视 “时序性”(动作随时间的动态关联)与 “动作复杂性”(3D 空间中的多维度交互),导致学习新技能后旧技能性能骤降;实现了 “持续学习新技能且保留旧技能” 的核心目标,为家庭服务、工业协作等真实场景下的机器人自适应学习提供了关键技术支撑。
选择Franka机械臂为实验载体核心优势在于其7 自由度设计与毫米级末端精度可保障复杂操作的数据可靠性,且开放的控制接口便于集成 iManip 框架的自定义算法,同时其场景适配性贴合真实应用需求。
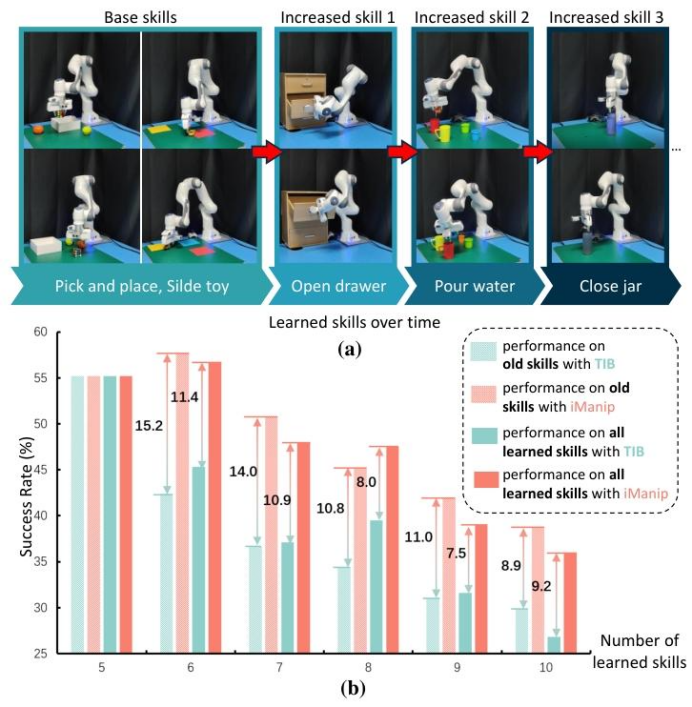
图1. (a) 我们针对机器人操作的技能增量学习概述,该学习要求智能体随时间学习技能序列。(b) 传统增量基线 (TIB) 与我们的iManip之间的模型性能比较。
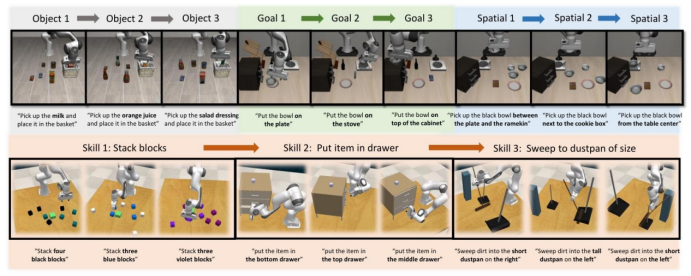
图2.机器人增量学习概述。以往的工作侧重于新对象、目标或空间位置的增量能力,不同任务可能共享同一技能。iManip专注于技能增量学习,这种学习方式能更好地捕捉现实世界中机器人学习所需的真正适应性和灵活性。
iManip:面向机器人操作的技能增量学习
验证方法与框架:两大核心设计破解增量学习难题
iManip 框架的核心思路是 “针对性解决时序性与动作复杂性”,整体由 “体素编码器 + 可扩展PerceiverIO + 策略解码器” 三部分构成,关键创新点集中在时序重放策略与可扩展 PerceiverIO 结构两大模块:
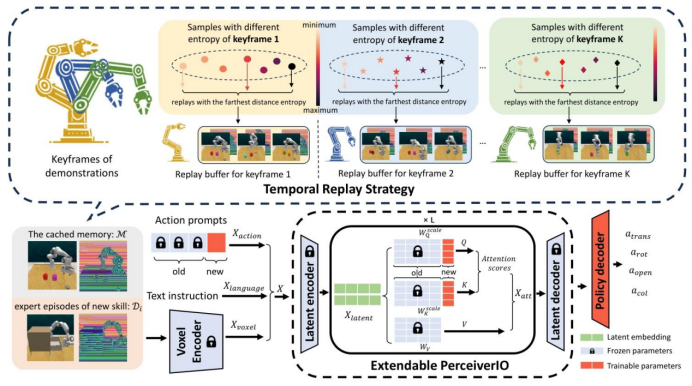
图3. iManip的整体框架,主要包括一个时间回放策略,用于为旧演示的每个关键帧存储具有最远距离熵的样本,以及一个可扩展的PerceiverIO,它由带有可扩展权重的动作提示组成,以适应新的动作基元。
1. 时序重放策略:解决 “时序失衡导致的遗忘”
传统重放方法(如随机采样、聚集采样)仅选取“代表性样本”,易破坏操作轨迹的时序完整性(如遗漏 “抓手闭合” 等关键动作节点)。iManip 提出的时序重放策略通过两步优化解决该问题:
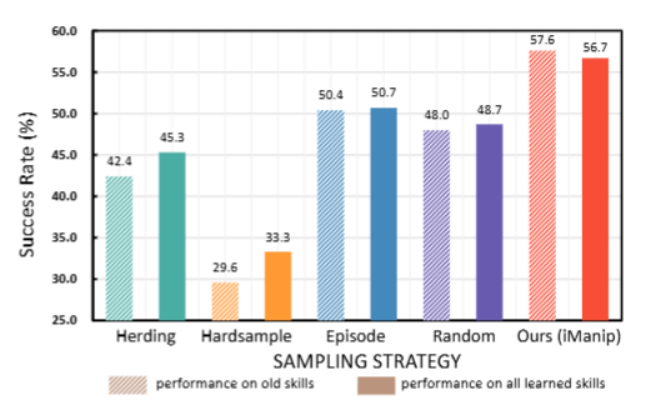
图4.不同重放方法的平均成功率。
关键帧筛选:仅保留操作轨迹中“末端执行器状态变化”(如抓手开合、速度趋近于零)的关键帧,确保样本覆盖时序关键节点;
最大距离熵采样:对每个关键帧,通过计算动作预测熵的距离矩阵,选取“信息熵差异最大” 的样本存入内存,既保证时序平衡,又覆盖更多物体变体(如不同颜色、尺寸的操作对象)。
2. 可扩展 PerceiverIO:适配 “新动作原语学习”
为解决“新技能动作原语与旧知识冲突” 问题,框架设计了带有 “可扩展权重 + 技能专属动作提示” 的 PerceiverIO结构:
多模态输入融合:将体素编码(3D 场景特征)、语言编码(指令信息)、动作提示(旧 + 新技能)拼接为统一令牌,实现跨模态协同;
权重扩展与参数冻结:学习新技能时,冻结旧PerceiverIO 的权重参数,仅新增少量 “技能专属动作提示” 与 “可扩展权重矩阵”(如追加WQnew、WKnew),既降低训练成本,又避免旧知识被覆盖;
知识蒸馏辅助:通过计算新旧模型在“平移、旋转、抓手开合、碰撞规避” 四类动作上的损失(MSE损失 + L1损失),实现旧技能知识向新模型的迁移。

表3.五组B5-1N1实验的性能,这些实验具有相同的基础技能和不同的新技能,同时冻结不同的网络层。对于每个新技能,我们总共训练100k次迭代,并报告平均成功率和平均模型收敛步数。
实验配置
核心硬件设备
机械臂:采用Franka机械臂(7自由度,末端执行器精度达毫米级),支持复杂操作动作(如拧瓶盖、堆叠方块);
视觉采集:使用Realsense D455深度相机,采集128×128 分辨率的正面RGB-D 图像,用于3D场景特征提取;
计算硬件:训练阶段采用2台NVIDIA RTX 4090 GPU,保障多模态数据处理与模型训练效率。
环境与数据配置
仿真环境:基于RLBench基准构建技能增量环境,选取10项语言约束操作技能(如关罐子、扫入簸箕、堆叠方块),每项技能包含2-60种变体(颜色、尺寸、位置等),总计166种操作场景;
真实环境:设计5项日常操作技能(滑玩具、开抽屉、拾取放置、倒水、关罐子),每个技能采集20组人类演示轨迹,测试时每项技能执行10个episode;
数据模态:输入包含“RGB-D图像 + 深度图像 + proprioception 矩阵”(记录抓手开合度、末端位置、时间步),输出为 “平移 + 旋转 + 开合度 + 碰撞规避” 四类动作参数。
实验设计与验证(问题与挑战)
研究团队通过 “性能对比实验”“消融实验”“多场景泛化实验”,系统性验证 iManip 框架对核心挑战的解决效果:
挑战1 :灾难性遗忘的缓解效果验证
-
实验设计:在“B5-5N1” 场景下(先学 5 项基础技能,再分5步学5项新技能),对比iManip与传统方法(如 PerAct、ManiGaussian)、传统增量基准(TIB)的性能;
-
验证逻辑:若iManip能在 “学习新技能后保持旧技能高成功率”,则证明其缓解了灾难性遗忘;
-
关键结论:传统方法(如ManiGaussian)在学习5项新技能后,旧技能成功率从 55.2%降至5.3%,而 iManip 仍保持38.7%,且所有技能平均成功率达36.0%,较 TIB 方法提升 9.4%。
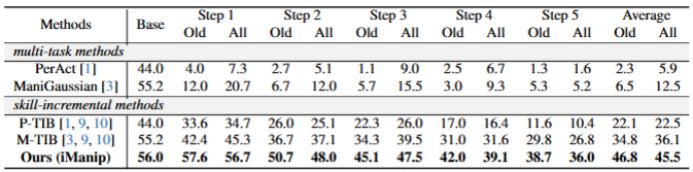
表1. Rlbench中B5-5N1不同方法的性能比较。我们展示了旧技能和所有已学习技能的平均成功率,以及所有新步骤的平均性能。基线[1, 3]上的传统增量方法[9, 10]被称为TIB。
挑战2:时序性与动作复杂性的适配验证
-
消融实验设计:设置4组对照实验(无任何增量策略R1、仅时序重放R2、时序重放+可扩展PerceiverIO R3、完整框架Ours);
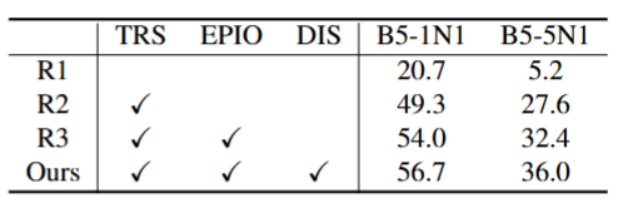
表2. 两个实验设置的消融研究。我们报告所有已学习技能的平均成功率。
-
验证逻辑:通过对比各组在“B5-1N1”“B5-5N1” 场景下的成功率,量化各模块对 “时序性”“动作复杂性” 的解决效果;
-
关键结论:仅加入时序重放(R2)可使成功率提升 22.4%-28.6%(解决时序失衡),再加入可扩展 PerceiverIO(R3)可进一步提升 4.7%-4.8%(适配动作复杂性),完整框架(Ours)性能最优,证明两大模块的协同有效性。
挑战3:多场景与多框架的泛化能力验证
-
实验设计:在“B5-1N5”“B2-4N2”“B3-2N3” 等不同增量场景下测试,并将 iManip 集成到 PerAct、GNFactor、3DDA 等现有机器人操作框架中;
-
验证逻辑:若iManip在不同场景与框架中均保持高成功率,则证明其泛化性;
-
关键结论:在所有增量场景下,iManip 的成功率均高于传统方法(如在 B3-2N3 场景下,较 M-TIB 提升 8 个百分点);集成到其他框架后,可使任务成功率提升 5%-10%,证明其 “即插即用” 的可扩展性。
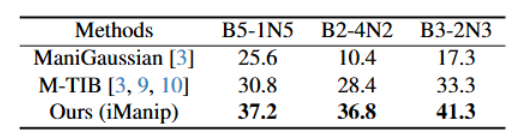
表4.不同技能增量设置下所有已学习技能的平均成功率。
关键成果与突破:为机器人增量学习提供范式创新
技术层面:突破传统增量学习的“机器人适配瓶颈”
基准层面:构建更贴近真实需求的技能增量环境
应用层面:推动机器人从 “单技能工具” 向 “多技能助手” 升级
未来应用方向:从技术到场景的价值延伸
家庭服务机器人:打造“自适应学习型” 助手
工业柔性制造:实现“多工序协同” 的智能产线
医疗辅助机器人:适配“个性化操作” 需求
结语
iManip 框架解决了机器人操作技能增量学习的核心难题,提供 “时序感知 + 轻量化扩展 + 知识蒸馏” 的技术范式。从仿真到真实场景验证,证明机器人可逐步积累技能。未来融合 LLM 与多模态技术,有望推动机器人升级为智能助手,为多领域智能化变革注入动力。
项目详情:https://arxiv.org/pdf/2503.07087