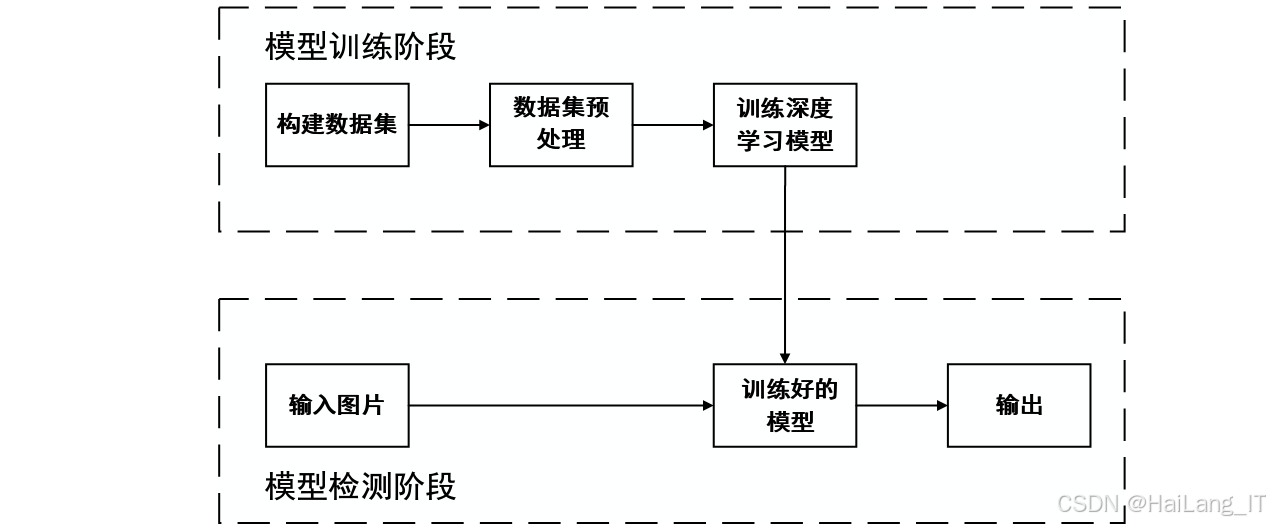
基于YOLO与DeepSort的高效行人跟踪算法研究
目录
- 选题的意义与背景
- 数据集介绍
- 项目功能介绍
- 算法理论介绍
- YOLOv5算法原理
- DeepSort算法原理
- 改进DeepSort算法理论
- 核心代码介绍
- 创新点
选题的意义与背景
随着计算机视觉技术的快速发展,行人检测与跟踪作为计算机视觉领域的重要研究方向,已广泛应用于自动驾驶、智能监控、智慧交通等多个领域。在自动驾驶系统中,准确的行人检测与跟踪能够帮助车辆及时发现道路上的行人,避免交通事故的发生;在智能监控系统中,高效的行人检测与跟踪技术能够实现对公共场所的智能管理和安全监控;在智慧交通领域,行人检测与跟踪技术可以辅助交通信号控制,提高行人过马路的安全性和交通效率。
然而,尽管行人检测与跟踪技术已经取得了长足的进步,但在实际应用中仍然面临着诸多挑战。首先,小目标行人检测是一个难点问题,由于小目标行人在图像中所占像素较少,特征信息不丰富,传统的检测算法往往难以准确识别;其次,遮挡行人检测也是一个痛点问题,在人群密集的场景中,行人之间或行人与其他物体之间的相互遮挡会导致目标信息丢失,影响检测精度;此外,多目标行人跟踪中还存在外观变化、姿态变化等问题,这些因素都会导致行人目标的外观特征难以匹配,影响跟踪性能。

近年来,深度学习技术的兴起为行人检测与跟踪带来了新的机遇。YOLO(You Only Look Once)系列算法作为一种单阶段目标检测算法,具有检测速度快、精度高等优点,已经成为目标检测领域的主流算法之一。其中,YOLOv5算法在保持较高检测精度的同时,还具有较快的推理速度,非常适合实时检测场景。DeepSort算法作为一种基于深度学习的多目标跟踪算法,通过引入重识别网络提取行人目标的外观特征,能够有效提高跟踪性能。
本项目旨在结合YOLOv5和DeepSort算法的优势,针对小目标行人和遮挡行人检测的难点问题,对算法进行改进,提高行人检测与跟踪的精度和性能,为实际应用提供更加可靠的技术支持。通过本项目的研究,可以进一步推动行人检测与跟踪技术的发展,拓展其在自动驾驶、智能监控、智慧交通等领域的应用范围,具有重要的理论意义和实际应用价值。
在研究背景方面,国内外学者已经针对行人检测与跟踪问题进行了大量的研究。早期的行人检测方法主要基于手工特征提取和传统机器学习算法,如HOG+SVM、DPM等。随着深度学习技术的发展,基于卷积神经网络的行人检测方法逐渐成为主流,如Faster R-CNN、SSD、YOLO等。在行人跟踪方面,传统的方法主要包括基于相关滤波的方法和基于深度学习的方法,而DeepSort算法作为SORT算法的改进版本,通过引入深度学习的重识别网络,大大提高了跟踪性能。尽管已有研究取得了一定的成果,但在小目标行人和遮挡行人检测方面仍然存在不足。本项目通过对YOLOv5和DeepSort算法的改进,旨在解决这些问题,提高行人检测与跟踪的性能,为相关领域的研究和应用提供新的思路和方法。
数据集介绍
本项目在研究过程中使用了多个公开数据集,包括PASCAL VOC 2007数据集、Market 1501数据集和MOT16数据集,下面分别对这些数据集进行详细介绍。
PASCAL VOC 2007数据集
PASCAL VOC 2007数据集是一个广泛使用的目标检测基准数据集,由英国牛津大学等机构联合发布。该数据集包含了20个类别,其中包括行人(person)类别。在本项目中,我们主要使用该数据集的行人图像进行模型训练和测试。

PASCAL VOC 2007数据集的行人图像来源于各种真实场景,包括街道、商场、公园等,图像中的行人姿态各异,部分图像还存在遮挡情况,这为我们测试算法在复杂场景下的性能提供了良好的数据基础。在实验中,我们从PASCAL VOC 2007数据集中选取了4015张包含行人的图像作为训练和测试数据,并按照8:2的比例划分为训练集和测试集,其中训练集包含3212张图像,测试集包含803张图像。
Market 1501数据集是一个行人重识别基准数据集,由清华大学于2015年发布。该数据集在清华大学校园中使用5个高清摄像头和1个低分辨率摄像头拍摄,共包含1501个行人,每个行人至少被2个摄像头捕捉到。数据集使用DPM检测器检测到32668个行人矩形框,并进行了手工标注。

Market 1501数据集的训练集包含751个行人,共12936张图片,平均每个行人有17.2张训练图片;测试集包含750个行人,共19732张图片,平均每个行人有26.3张测试图片;Query集包含750个行人,共3368张图片,这些图片都是手动标注的,从6个摄像头中为测试集中的每个行人选取一张图片构成。在本项目中,我们使用Market 1501数据集对DeepSort算法的重识别网络进行训练和测试。
MOT16数据集是一个多目标跟踪基准数据集,包含了多个具有挑战性的视频序列。该数据集由单目摄像头拍摄,涵盖了室内、室外、人群、交通场景等多种不同的场景和环境,考虑了不同的摄像头角度、视角、光照和天气条件。MOT16数据集的评估指标包括多目标跟踪准确率(MOTA)、多目标跟踪精确度(MOTP)、目标ID切换次数(ID_switch)等,这些指标能够全面反映跟踪算法在不同方面的性能表现。通过在MOT16数据集上的实验,我们可以客观地评估改进算法的跟踪性能,并与现有算法进行比较。
为了提高模型的训练效果和泛化能力,我们在实验前对数据集进行了预处理,主要包括以下几个方面:
-
图像尺寸调整:将所有图像调整为统一的尺寸,以适应模型的输入要求。在YOLOv5模型中,我们将输入图像的尺寸调整为640×640;在DeepSort的重识别网络中,我们将输入图像的尺寸调整为128×64×3。
-
数据增强:通过随机翻转、随机裁剪、随机缩放等数据增强技术,增加训练数据的多样性,减少过拟合现象。在YOLOv5模型中,我们还使用了Mosaic数据增强技术,通过将四张图像拼接成一张,丰富了图像的背景信息和小目标的数量。
-
标签格式转换:将数据集中的标签转换为模型所需的格式。在YOLOv5模型中,我们将标签转换为YOLO格式,即每个目标由类别索引和归一化的中心点坐标、宽高组成;在DeepSort的重识别网络中,我们将标签转换为类别索引格式。
-
数据集划分:按照一定的比例将数据集划分为训练集、验证集和测试集,用于模型的训练、验证和测试。在本项目中,我们将PASCAL VOC 2007数据集的行人图像按照8:2的比例划分为训练集和测试集。
通过以上数据预处理步骤,我们为模型的训练和测试提供了高质量的数据基础,有助于提高模型的检测与跟踪性能。
项目功能介绍
本项目主要实现了基于改进YOLOv5和DeepSort的行人检测与跟踪算法,具有以下核心功能:
1. 小目标行人检测功能
针对传统YOLOv5算法在小目标行人检测方面的不足,本项目通过以下两种改进措施,提高了模型对小目标行人的检测能力:
-
引入CA注意力机制:在YOLOv5网络中引入坐标注意力(Coordinate Attention,CA)机制,该机制通过在通道注意力中嵌入位置信息,能够很好地捕获通道之间的关系,以及方向感知和位置感知信息,从而提高模型对小目标行人的定位与识别能力。
-
增加小目标检测层:在YOLOv5网络的三尺度检测层(10×10、20×20、40×40)基础上,增加一个160×160尺度的小目标检测层,加强对小目标行人的特征提取和识别能力。同时,我们还针对新增加的检测层进行了锚框聚类,确保锚框能够更好地匹配小目标行人的尺寸。
实验结果表明,通过这两种改进措施,模型对小目标行人的检测性能得到了显著提升,精确率和平均精度均值分别提高了1.2%和0.7%。
2. 遮挡行人检测功能
为了解决遮挡行人检测的难题,本项目对YOLOv5算法进行了以下两方面的改进:
-
使用EIOU损失函数:将YOLOv5网络中的边界框回归损失函数从CIOU替换为EIOU(Efficient Intersection over Union)损失函数。EIOU损失函数在CIOU的基础上,将纵横比损失拆分为宽高损失,考虑了预测框与真实框的宽高值与最小外接框宽高值的关系,有效减少了检测框与真实框之间的实际宽高值误差,使预测框的位置更加准确,定位效果更好。
-
采用Soft-NMS算法:将传统的非极大值抑制(NMS)算法替换为Soft-NMS算法。Soft-NMS算法通过对大于重叠度阈值的预测框设置一个惩罚函数,降低其置信度得分,而不是直接置零,从而减少了对遮挡行人目标的误判情况,提高了模型对遮挡行人的检测能力。
实验结果显示,结合EIOU损失函数和Soft-NMS算法的改进模型,在精确率和平均精度均值上分别提升了8%和5.2%,能够有效检测出被遮挡的行人目标。
3. 多目标行人跟踪功能
在行人跟踪方面,本项目将改进后的YOLOv5算法与DeepSort算法相结合,并对DeepSort算法进行了改进,具体包括:
-
使用改进YOLOv5作为目标检测器:将结合了CA注意力机制、四尺度检测层、EIOU损失函数和Soft-NMS算法的改进YOLOv5作为DeepSort的目标检测器,提高了目标检测的精度和召回率,为跟踪提供了更可靠的检测结果。
-
改进DeepSort重识别网络:使用MobileNetV3_Small网络替换DeepSort原有的重识别网络。MobileNetV3_Small网络采用了深度可分离卷积和SE注意力模块,能够在减少模型参数量的同时,提高对行人外观特征的提取能力,从而提升跟踪性能。
4. 实时检测与跟踪功能
本项目在提高检测与跟踪精度的同时,也注重模型的实时性能。通过对网络结构的优化和算法的改进,确保模型能够在保证检测与跟踪性能的前提下,满足实时应用的需求。实验结果显示,改进后的YOLOv5_Ours模型在GPU环境下的检测速度达到了23.5FPS,改进后的YOLOv5_Ours+DeepSort_Ours模型也能够满足实时跟踪的要求。
5. 可视化展示功能
为了直观地展示模型的检测与跟踪效果,本项目还实现了可视化展示功能,能够实时显示检测框、跟踪ID和置信度等信息,方便用户对模型性能进行评估和分析。通过可视化界面,用户可以清晰地观察到模型在不同场景下的检测与跟踪结果,包括小目标行人和遮挡行人的检测情况,以及多目标跟踪的稳定性。
算法理论介绍
YOLOv5算法原理
YOLOv5是一种单阶段目标检测算法,其核心思想是将目标检测任务转化为一个回归问题,通过一次前向传播即可预测出目标的类别和位置。YOLOv5的网络结构主要包括四个部分:Input、Backbone、Neck和Head。
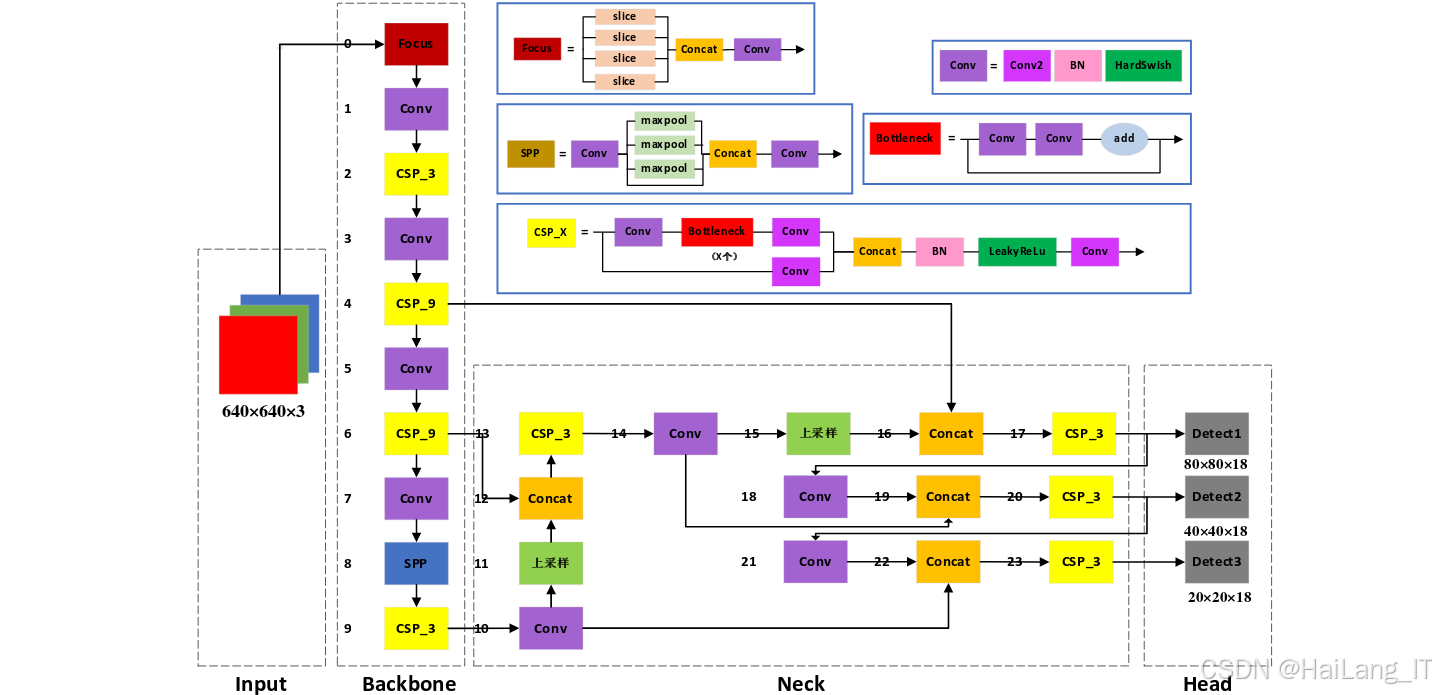
-
Input部分:负责对输入图像进行预处理,包括Mosaic数据增强、自适应图像缩放、自适应锚框计算等。Mosaic数据增强通过将四张图像拼接成一张,丰富了图像的背景信息和小目标的数量;自适应图像缩放通过将图像缩放到固定大小,减少了计算量;自适应锚框计算则根据训练数据自动计算最佳锚框尺寸,提高了模型的检测精度。
-
Backbone部分:采用CSPDarknet53作为主干网络,负责提取图像的特征信息。CSPDarknet53通过跨阶段部分连接(Cross Stage Partial Connection,CSP)结构,减少了计算量,提高了特征提取能力。
-
Neck部分:采用FPN(Feature Pyramid Network)+PAN(Path Aggregation Network)结构,负责特征融合。FPN通过自顶向下的路径,将高层特征与低层特征进行融合,增强了模型对小目标的检测能力;PAN则通过自底向上的路径,进一步增强了特征融合的效果。
-
Head部分:负责输出检测结果,包括目标的类别、位置和置信度。YOLOv5采用了三尺度检测头,分别对应大、中、小三种尺度的目标,提高了模型对不同尺度目标的检测能力。
本项目对YOLOv5算法进行了多方面的改进,主要包括以下几个方面:
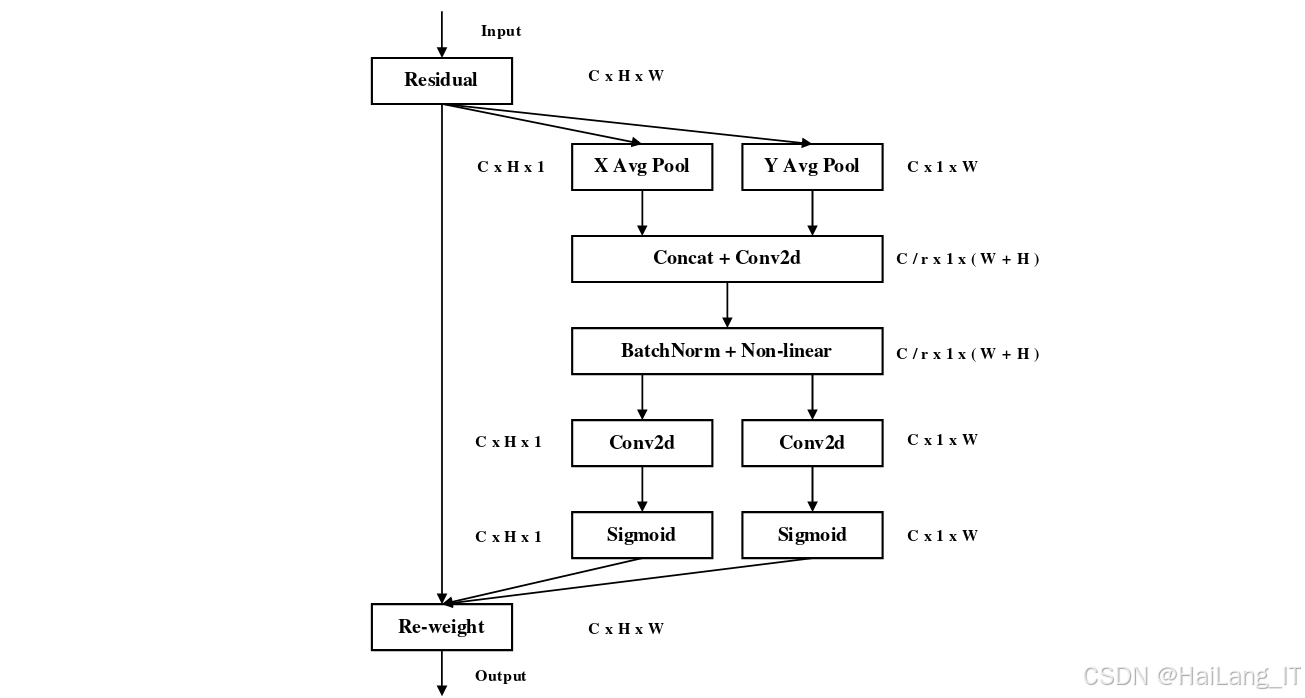
1. CA注意力机制
坐标注意力(CA)机制是一种结合了位置信息的注意力机制,主要包括坐标信息嵌入和坐标注意力生成两个模块。坐标信息嵌入模块通过沿着两个空间方向分别聚合特征,捕获通道间的长距离依赖关系;坐标注意力生成模块则通过门控机制,将捕获到的位置信息嵌入到通道注意力中,增强模型对目标位置的感知能力。
CA注意力机制的具体实现过程如下:首先,对输入特征图进行全局平均池化,得到两个一维特征向量,分别表示水平和垂直方向的特征信息;然后,通过两个全连接层和激活函数,对这两个特征向量进行处理,得到两个权重向量;最后,将这两个权重向量与输入特征图相乘,得到增强后的特征图。
通过引入CA注意力机制,模型能够更好地关注图像中的行人目标区域,获取更多的细节信息,从而提高对小目标行人的检测能力。
2. 四尺度检测层
传统YOLOv5算法采用三尺度检测层(10×10、20×20、40×40),分别对应大、中、小三种尺度的目标。为了提高对小目标行人的检测能力,本项目在三尺度检测层的基础上,增加了一个160×160尺度的小目标检测层。
四尺度检测层的实现过程如下:首先,在Backbone的最后一层特征图之后,添加一个下采样层,得到160×160尺度的特征图;然后,对该特征图进行卷积和激活操作,提取小目标的特征信息;最后,将提取到的特征信息与FPN+PAN结构进行融合,输出小目标的检测结果。
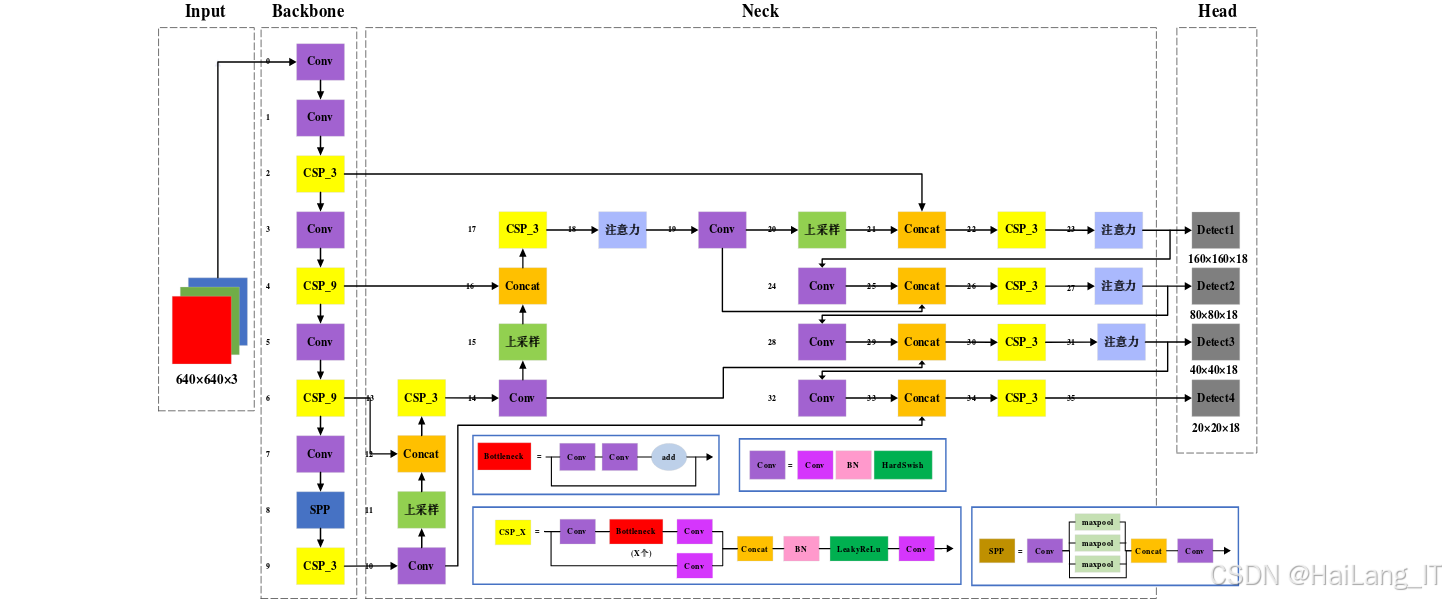
通过增加小目标检测层,模型能够更好地提取小目标行人的特征信息,提高对小目标行人的检测精度。同时,我们还针对新增加的检测层进行了锚框聚类,确保锚框能够更好地匹配小目标行人的尺寸。
3. EIOU损失函数
EIOU损失函数是在CIOU损失函数的基础上改进而来的,主要解决了CIOU损失函数中纵横比损失的模糊定义问题。EIOU损失函数将边界框回归损失分为三个部分:重叠损失、中心点距离损失和宽高损失。
EIOU损失函数的具体计算公式如下:
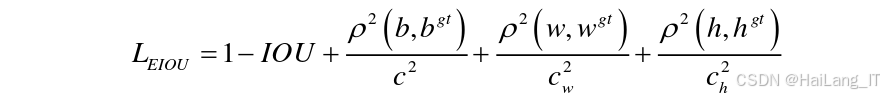
通过使用EIOU损失函数,模型能够更准确地预测行人目标框的位置和大小,减少与真实目标框之间的误差,提高对遮挡行人的定位能力。
4. Soft-NMS算法
传统的非极大值抑制(NMS)算法在处理重叠度较高的预测框时,会直接将置信度得分较低的预测框置零,这可能会导致对遮挡行人目标的误判。为了解决这个问题,本项目采用了Soft-NMS算法,通过对大于重叠度阈值的预测框设置一个惩罚函数,降低其置信度得分,而不是直接置零。
Soft-NMS算法的具体实现过程如下:首先,对所有预测框按照置信度得分进行降序排序;然后,从排序后的列表中选取置信度得分最高的预测框,将其作为当前保留的预测框;接着,计算当前保留的预测框与其他预测框的重叠度,并对重叠度大于阈值的预测框,根据其重叠度的大小,降低其置信度得分;最后,重复以上步骤,直到处理完所有预测框。
Soft-NMS算法的惩罚函数采用高斯惩罚函数,具体计算公式如下:
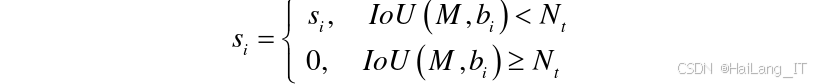
通过使用Soft-NMS算法,模型能够更好地处理遮挡行人目标的检测问题,提高检测精度。
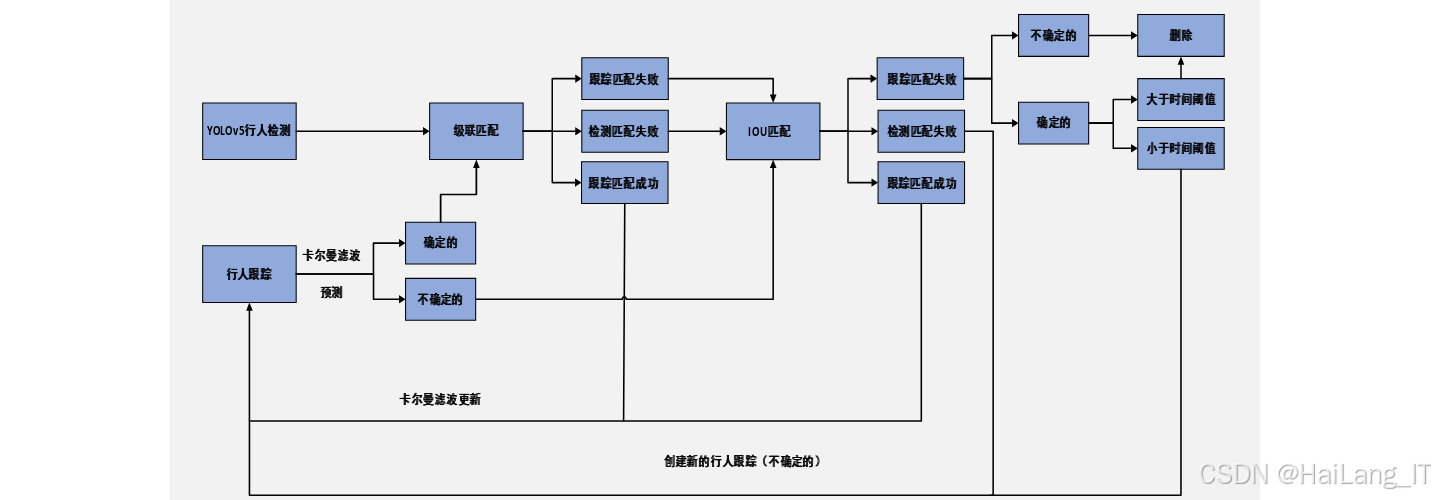
DeepSort算法原理
DeepSort是一种基于深度学习的多目标跟踪算法,是SORT算法的改进版本。DeepSort算法在SORT算法的基础上,引入了深度学习的重识别网络,提取行人目标的外观特征,结合卡尔曼滤波和匈牙利算法,实现了高效准确的多目标跟踪。
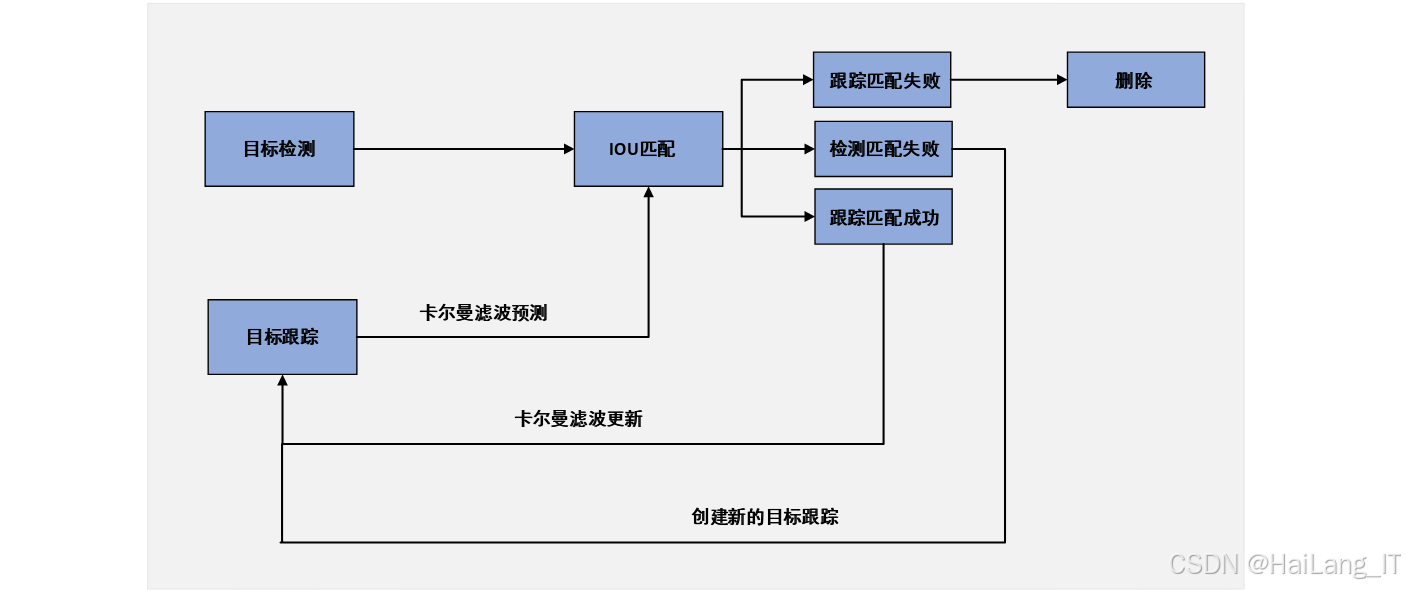
DeepSort算法的主要组成部分包括:
-
卡尔曼滤波:用于预测行人目标的运动状态,包括位置、速度等信息。卡尔曼滤波通过预测和更新两个过程,对行人目标的运动状态进行最优估计。
-
匈牙利算法:用于解决数据关联问题,将当前帧的检测框与上一帧的跟踪框进行匹配。匈牙利算法通过计算检测框与跟踪框之间的距离(包括马氏距离和余弦距离),找到最优的匹配结果。
-
重识别网络:用于提取行人目标的外观特征,帮助区分不同的行人目标。DeepSort算法的重识别网络由两个卷积层和六个残差块组成,能够提取行人目标的深度特征。
改进DeepSort算法理论
为了提高DeepSort算法的跟踪性能,本项目对其重识别网络进行了改进,使用MobileNetV3_Small网络替换了原有的重识别网络。
MobileNetV3_Small是一种轻量级卷积神经网络,其核心是bneck模块,该模块由深度可分离卷积和SE注意力模块组成。深度可分离卷积通过将标准卷积分解为深度卷积和逐点卷积,减少了模型的参数量和计算量;SE注意力模块则通过自适应地学习特征图中不同通道之间的特征信息,提高了模型的特征提取能力。
MobileNetV3_Small网络的具体结构如下:输入图像为128×64×3,经过一系列的bneck模块处理后,输出行人目标的外观特征。bneck模块的数量和参数根据具体需求进行设置,在本项目中,我们使用了11个bneck模块,每个模块的卷积核参数和输出特征图尺寸如表5.3所示。
通过使用MobileNetV3_Small网络作为重识别网络,模型能够更好地提取行人目标的外观特征,提高跟踪性能,同时减少模型的参数量,加快推理速度。
核心代码介绍
1. CA注意力机制实现
CA注意力机制是本项目中用于提升小目标行人检测性能的关键改进点之一。该机制通过在通道注意力中嵌入位置信息,能够有效捕获目标的位置和方向特征,提高模型对小目标的感知能力。
class CoordinateAttention(nn.Module):def __init__(self, in_channels, out_channels, reduction=32):super(CoordinateAttention, self).__init__()# 定义水平和垂直方向的平均池化self.pool_h = nn.AdaptiveAvgPool2d((None, 1))self.pool_w = nn.AdaptiveAvgPool2d((1, None))# 定义共享的全连接层self.conv1 = nn.Conv2d(in_channels, in_channels // reduction, kernel_size=1, stride=1, padding=0)self.bn1 = nn.BatchNorm2d(in_channels // reduction)self.relu = nn.ReLU()# 定义水平和垂直方向的全连接层self.conv_h = nn.Conv2d(in_channels // reduction, out_channels, kernel_size=1, stride=1, padding=0)self.conv_w = nn.Conv2d(in_channels // reduction, out_channels, kernel_size=1, stride=1, padding=0)self.sigmoid = nn.Sigmoid()def forward(self, x):identity = xn, c, h, w = x.size()# 水平方向平均池化x_h = self.pool_h(x)# 垂直方向平均池化x_w = self.pool_w(x).permute(0, 1, 3, 2)# 拼接水平和垂直方向的特征x_cat = torch.cat([x_h, x_w], dim=2)# 特征变换x_cat = self.conv1(x_cat)x_cat = self.bn1(x_cat)x_cat = self.relu(x_cat)# 分离水平和垂直方向的特征x_h, x_w = torch.split(x_cat, [h, w], dim=2)x_w = x_w.permute(0, 1, 3, 2)# 生成注意力权重a_h = self.sigmoid(self.conv_h(x_h))a_w = self.sigmoid(self.conv_w(x_w))# 应用注意力权重out = identity * a_h * a_wreturn out
上述代码实现了CA注意力机制的核心逻辑。首先,通过AdaptiveAvgPool2d分别在水平和垂直方向对输入特征图进行平均池化,获取不同方向的特征信息;然后,将这两个方向的特征进行拼接,并通过一个共享的卷积层进行降维和特征变换;接着,将处理后的特征分离回水平和垂直两个方向,分别通过卷积层生成对应的注意力权重;最后,将注意力权重与原始特征图相乘,得到增强后的特征图。
CA注意力机制的关键创新点在于其能够同时捕获通道间的依赖关系和位置信息,这对于小目标行人检测尤为重要。通过关注目标的具体位置和方向信息,模型能够更准确地定位和识别小目标行人,从而提高检测精度。
2. EIOU损失函数实现
EIOU损失函数是本项目中用于改进边界框回归精度的重要组成部分。相比于传统的CIOU损失函数,EIOU损失函数通过将纵横比损失拆分为宽高损失,更准确地描述了预测框与真实框之间的几何关系,从而提高了模型的定位精度,特别是在遮挡场景下。
def bbox_eiou_loss(pred_boxes, target_boxes, eps=1e-7):# 计算预测框和真实框的中心点坐标和宽高pred_xy = pred_boxes[..., :2]pred_wh = pred_boxes[..., 2:4]target_xy = target_boxes[..., :2]target_wh = target_boxes[..., 2:4]# 计算预测框和真实框的左上角和右下角坐标pred_xy1 = pred_xy - pred_wh / 2pred_xy2 = pred_xy + pred_wh / 2target_xy1 = target_xy - target_wh / 2target_xy2 = target_xy + target_wh / 2# 计算交集面积inter_xy1 = torch.max(pred_xy1, target_xy1)inter_xy2 = torch.min(pred_xy2, target_xy2)inter_wh = torch.clamp(inter_xy2 - inter_xy1, min=0)inter_area = inter_wh[..., 0] * inter_wh[..., 1]# 计算并集面积pred_area = pred_wh[..., 0] * pred_wh[..., 1]target_area = target_wh[..., 0] * target_wh[..., 1]union_area = pred_area + target_area - inter_area + eps# 计算IOUiou = inter_area / union_area# 计算中心点距离center_distance = torch.pow(pred_xy[..., 0] - target_xy[..., 0], 2) + \torch.pow(pred_xy[..., 1] - target_xy[..., 1], 2)# 计算最小外接矩形的宽高enclose_xy1 = torch.min(pred_xy1, target_xy1)enclose_xy2 = torch.max(pred_xy2, target_xy2)enclose_wh = torch.clamp(enclose_xy2 - enclose_xy1, min=0)# 计算最小外接矩形的对角线距离的平方enclose_diagonal = torch.pow(enclose_wh[..., 0], 2) + torch.pow(enclose_wh[..., 1], 2) + eps# 计算宽高损失w_diff = torch.pow(target_wh[..., 0] - pred_wh[..., 0], 2) / (enclose_wh[..., 0] ** 2 + eps)h_diff = torch.pow(target_wh[..., 1] - pred_wh[..., 1], 2) / (enclose_wh[..., 1] ** 2 + eps)wh_loss = w_diff + h_diff# 计算EIOU损失eiou_loss = 1 - iou + center_distance / enclose_diagonal + wh_lossreturn eiou_loss
上述代码实现了EIOU损失函数的计算过程。首先,根据预测框和真实框的中心点坐标和宽高,计算它们的左上角和右下角坐标;然后,计算交集面积和并集面积,进而得到交并比(IOU);接着,计算预测框与真实框中心点之间的距离,以及最小外接矩形的宽高和对角线距离;最后,计算宽高损失,并将所有部分组合成最终的EIOU损失。
EIOU损失函数的核心优势在于其同时考虑了预测框与真实框的重叠度、中心点距离以及宽高差异,特别是将宽高损失与最小外接矩形的宽高相关联,使得模型能够更准确地学习到目标的几何形状,从而提高边界框回归的精度。这对于遮挡行人检测尤为重要,因为准确的边界框回归能够帮助模型更好地定位被遮挡的行人目标。
3. 重识别网络实现
为了提高DeepSort算法的行人重识别能力,本项目使用MobileNetV3_Small网络替换了原有的重识别网络。MobileNetV3_Small网络采用了深度可分离卷积和SE注意力模块,能够在减少模型参数量的同时,提高特征提取能力,从而提升多目标跟踪的性能。
class MobileNetV3_Small(nn.Module):def __init__(self, num_classes=751):super(MobileNetV3_Small, self).__init__()# 定义初始卷积层self.conv1 = nn.Conv2d(3, 16, kernel_size=3, stride=2, padding=1, bias=False)self.bn1 = nn.BatchNorm2d(16)self.hsigmoid = nn.Hardsigmoid()# 定义bneck模块self.bneck1 = self._make_bneck(16, 16, 3, 2, se=True, nl='RE')self.bneck2 = self._make_bneck(16, 24, 3, 2, se=False, nl='RE')self.bneck3 = self._make_bneck(24, 24, 3, 1, se=False, nl='RE')self.bneck4 = self._make_bneck(24, 40, 5, 2, se=True, nl='HS')self.bneck5 = self._make_bneck(40, 40, 5, 1, se=True, nl='HS')self.bneck6 = self._make_bneck(40, 40, 5, 1, se=True, nl='HS')self.bneck7 = self._make_bneck(40, 48, 5, 1, se=True, nl='HS')self.bneck8 = self._make_bneck(48, 48, 5, 1, se=True, nl='HS')self.bneck9 = self._make_bneck(48, 96, 5, 2, se=True, nl='HS')self.bneck10 = self._make_bneck(96, 96, 5, 1, se=True, nl='HS')self.bneck11 = self._make_bneck(96, 96, 5, 1, se=True, nl='HS')# 定义后续卷积层和池化层self.conv2 = nn.Conv2d(96, 576, kernel_size=1, stride=1, padding=0, bias=False)self.bn2 = nn.BatchNorm2d(576)self.avgpool = nn.AdaptiveAvgPool2d((1, 1))self.conv3 = nn.Conv2d(576, 1024, kernel_size=1, stride=1, padding=0, bias=False)self.bn3 = nn.BatchNorm2d(1024)self.conv4 = nn.Conv2d(1024, num_classes, kernel_size=1, stride=1, padding=0, bias=True)def _make_bneck(self, in_channels, out_channels, kernel_size, stride, se, nl):# 定义bneck模块layers = []# 1×1卷积层,用于升维layers.append(nn.Conv2d(in_channels, in_channels, kernel_size=1, stride=1, padding=0, bias=False))layers.append(nn.BatchNorm2d(in_channels))layers.append(self._get_activation(nl))# 深度可分离卷积层layers.append(nn.Conv2d(in_channels, in_channels, kernel_size=kernel_size, stride=stride, padding=kernel_size//2, groups=in_channels, bias=False))layers.append(nn.BatchNorm2d(in_channels))layers.append(self._get_activation(nl))# SE注意力模块if se:layers.append(self._make_se(in_channels, in_channels//4))# 1×1卷积层,用于降维layers.append(nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=1, padding=0, bias=False))layers.append(nn.BatchNorm2d(out_channels))# 跳跃连接if in_channels == out_channels and stride == 1:shortcut = nn.Identity()else:shortcut = nn.Sequential(nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride, padding=0, bias=False),nn.BatchNorm2d(out_channels))return nn.Sequential(*layers), shortcutdef _make_se(self, in_channels, reduction):# 定义SE注意力模块return nn.Sequential(nn.AdaptiveAvgPool2d(1),nn.Conv2d(in_channels, reduction, kernel_size=1, stride=1, padding=0, bias=False),nn.BatchNorm2d(reduction),nn.ReLU(),nn.Conv2d(reduction, in_channels, kernel_size=1, stride=1, padding=0, bias=False),nn.Hardsigmoid())def _get_activation(self, nl):# 获取激活函数if nl == 'RE':return nn.ReLU()elif nl == 'HS':return nn.Hardswish()else:raise NotImplementedErrordef forward(self, x):# 前向传播x = self.conv1(x)x = self.bn1(x)x = self.hsigmoid(x)# 通过bneck模块for i in range(1, 12):bneck, shortcut = getattr(self, f'bneck{i}')residual = shortcut(x)x = bneck(x)x += residual# 后续处理x = self.conv2(x)x = self.bn2(x)x = self.hsigmoid(x)x = self.avgpool(x)x = self.conv3(x)x = self.bn3(x)x = self.hsigmoid(x)x = self.conv4(x)return x
上述代码实现了MobileNetV3_Small网络的核心结构。首先,定义了初始卷积层,用于对输入图像进行初步特征提取;然后,定义了11个bneck模块,每个模块由1×1卷积层、深度可分离卷积层、SE注意力模块(可选)和跳跃连接组成,用于进一步提取和增强特征;最后,定义了后续的卷积层和池化层,用于生成最终的特征表示。
MobileNetV3_Small网络的关键特点在于其高效的特征提取能力和较低的计算复杂度。通过深度可分离卷积和SE注意力模块的结合,网络能够在减少参数量的同时,捕获更丰富的行人外观特征,这对于多目标行人跟踪尤为重要。实验结果表明,使用MobileNetV3_Small作为重识别网络的DeepSort算法,在行人跟踪性能上有显著提升,特别是在行人外观变化和姿态变化较大的场景下。
创新点
重难点分析
本项目的重点难点主要集中在以下几个方面:
小目标行人检测一直是行人检测领域的难点问题,主要原因包括:
-
特征信息不足:小目标行人在图像中所占像素较少,特征信息不丰富,传统的特征提取方法难以有效捕获其关键特征。
-
上下文信息干扰:小目标行人往往容易受到背景和其他物体的干扰,导致检测精度下降。
-
尺度变化大:在实际场景中,行人目标的尺度变化范围很大,从小型的远处行人到大型的近处行人,这对检测器的尺度适应性提出了很高的要求。
为了解决这些问题,本项目通过引入CA注意力机制和增加小尺度检测层的方式,增强了模型对小目标行人的感知和识别能力。CA注意力机制通过在通道注意力中嵌入位置信息,能够有效捕获小目标行人的位置和方向特征;增加小尺度检测层则专门针对小目标行人进行特征提取和识别,提高了模型对小尺度目标的检测精度。
遮挡行人检测是另一个具有挑战性的问题,主要困难包括:
-
目标信息缺失:当行人被其他物体或行人遮挡时,其部分或大部分特征信息会丢失,导致检测器难以准确识别。
-
边界框定位困难:遮挡会导致行人目标的边界框形状发生变化,增加了边界框回归的难度。
-
重叠框处理复杂:在遮挡场景下,多个行人目标的检测框往往会重叠,如何正确处理这些重叠框是一个难题。
针对这些问题,本项目采用了EIOU损失函数和Soft-NMS算法进行改进。EIOU损失函数通过更精确地描述预测框与真实框之间的几何关系,提高了边界框回归的精度;Soft-NMS算法则通过对重叠框设置惩罚函数,而不是直接删除,有效减少了对遮挡行人目标的误判。
多目标行人跟踪面临的主要挑战包括:
-
目标外观变化:行人在运动过程中,其外观可能会因为姿态、光照、视角等因素的变化而发生很大变化,增加了特征匹配的难度。
-
目标遮挡:行人之间或行人与其他物体之间的相互遮挡,可能导致目标暂时消失或外观发生变化,影响跟踪的连续性。
-
计算效率要求高:多目标跟踪需要实时处理视频帧,对算法的计算效率提出了很高的要求。
将改进后的YOLOv5与DeepSort算法相结合,并对DeepSort的重识别网络进行了优化。改进后的YOLOv5提供了更准确的行人检测结果,为跟踪提供了可靠的基础;使用MobileNetV3_Small作为重识别网络,在保证特征提取能力的同时,提高了模型的推理速度。
创新点
本项目的主要创新点包括:
-
传统的注意力机制如SE和CBAM主要关注通道间的依赖关系,而忽略了位置信息的重要性。本项目创新性地将CA注意力机制引入YOLOv5网络,通过在通道注意力中嵌入位置信息,使模型能够同时捕获通道间的依赖关系和目标的位置信息,从而提高对小目标行人的检测能力。实验结果表明,引入CA注意力机制的YOLOv5模型在精确率和平均精度均值上分别提高了0.9%和0.2%,检测性能优于引入SE和CBAM注意力机制的模型。
-
在YOLOv5网络的三尺度检测层基础上,增加了一个160×160尺度的小目标检测层,形成四尺度检测结构。通过专门针对小目标行人设计的检测层,模型能够更有效地提取小目标的特征信息,提高检测精度。同时,我们还针对新增加的检测层进行了锚框聚类,确保锚框能够更好地匹配小目标行人的尺寸。
-
EIOU损失函数通过将纵横比损失拆分为宽高损失,更准确地描述了预测框与真实框之间的几何关系,提高了边界框回归的精度;Soft-NMS算法则通过对重叠框设置惩罚函数,有效减少了对遮挡行人目标的误判。实验结果表明,结合这两种改进的模型在精确率和平均精度均值上分别提升了8%和5.2%,能够有效检测出被遮挡的行人目标。
-
使用MobileNetV3_Small网络替换了原有的重识别网络。MobileNetV3_Small网络采用了深度可分离卷积和SE注意力模块,能够在减少模型参数量的同时,提高特征提取能力。
-
将改进后的YOLOv5与DeepSort算法进行了高效融合,充分发挥了两者的优势。改进后的YOLOv5提供了更准确的行人检测结果,为DeepSort提供了可靠的输入;而改进后的DeepSort则能够更好地利用检测结果进行多目标跟踪,提高跟踪的精度和稳定性。
本项目针对传统行人检测与跟踪算法在小目标识别和遮挡场景下的局限性,提出了一种基于改进YOLOv5和DeepSort的行人检测与跟踪方案。通过在YOLOv5网络中引入CA注意力机制、增加小尺度检测层、使用EIOU损失函数和Soft-NMS算法,以及在DeepSort算法中使用MobileNetV3_Small作为重识别网络,有效提高了模型的检测与跟踪性能。