AI(学习笔记第十一课) 使用langchain的multimodality
文章目录
- AI(学习笔记第十一课) 使用langchain的multimodality
- 学习内容:
- 1. 什么是`AI multimodality`
- 1.1 介绍`AI multimodality`
- 1.2 确认支持`multimodality`的大模型
- 2. `deepseek`的代替方案智谱`AI`
- 2.1 智谱AI
- 2.2 智谱AI使用注册
- 3. 自定义`Large Language Model (llm)`
- 3.1 继承`langchain`的`BaseChatModel`基类
- 3.2 调用`BaseChatModel`基类的自定义`llm`
AI(学习笔记第十一课) 使用langchain的multimodality
- 什么是
AI multimodality -
deepseek的代替方案智谱AIhttps://bigmodel.cn/ - 自定义
Large Language Model (llm) -
multimodality的代码示例
学习内容:
- 什么是
AI multimodality deepseek的代替方案智谱AI- 自定义
Large Language Model (llm) multimodality的代码示例
1. 什么是AI multimodality
1.1 介绍AI multimodality
AI multimodality介绍
AI multimodality就是AI不仅能够处理文本,还能够处理视频(video),图片(image),以及音频audio的功能。
一个大模型llm应该包括这三个方面的功能:
Chat Models: 能够接受multimodality的input和生成output。Embedding Models: 类似于文本的embedding模型,multimodality的数据同样能够使用embedding model进行向量化。Vector Stores:向量化数据库,同样能够支持multimodality数据,进行向量化数据的存储和查找。
1.2 确认支持multimodality的大模型
支持multimodality的大模型(llm)列表
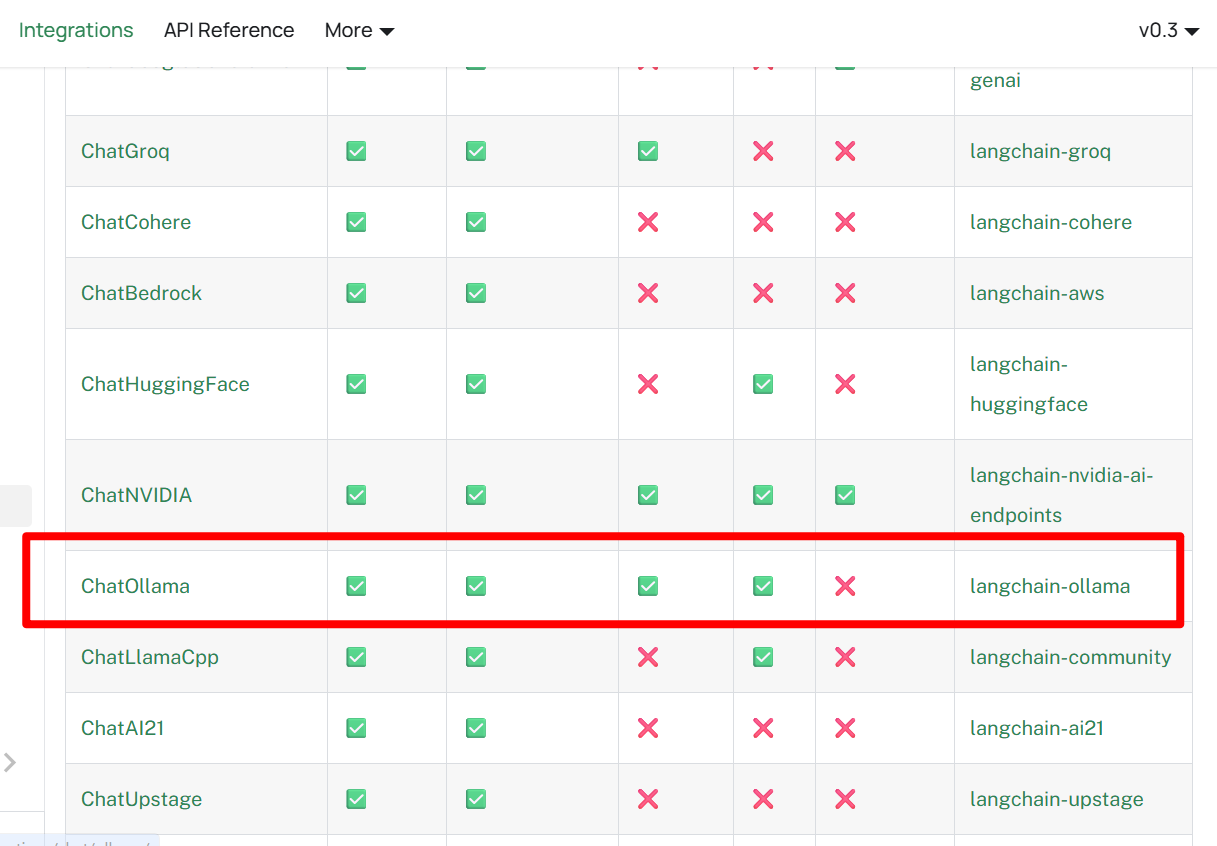
这里可以查找到底哪些llm支持multimodality。可以看到在以前的练习中经常使用的deepseek也不在范围内。ChatOllama中的开源llm支持·multimodality,但是本地创建ollama service性能很差,很不现实。这里考虑其他的llm
2. deepseek的代替方案智谱AI
2.1 智谱AI
经过调查,发现国内的智谱AI比较不错,而且完全支持multimodality。虽然这里需要付费,但是经过注册后,智谱AI给了开始的免费2000万tokens,可以完全满足学习的要求。
2.2 智谱AI使用注册
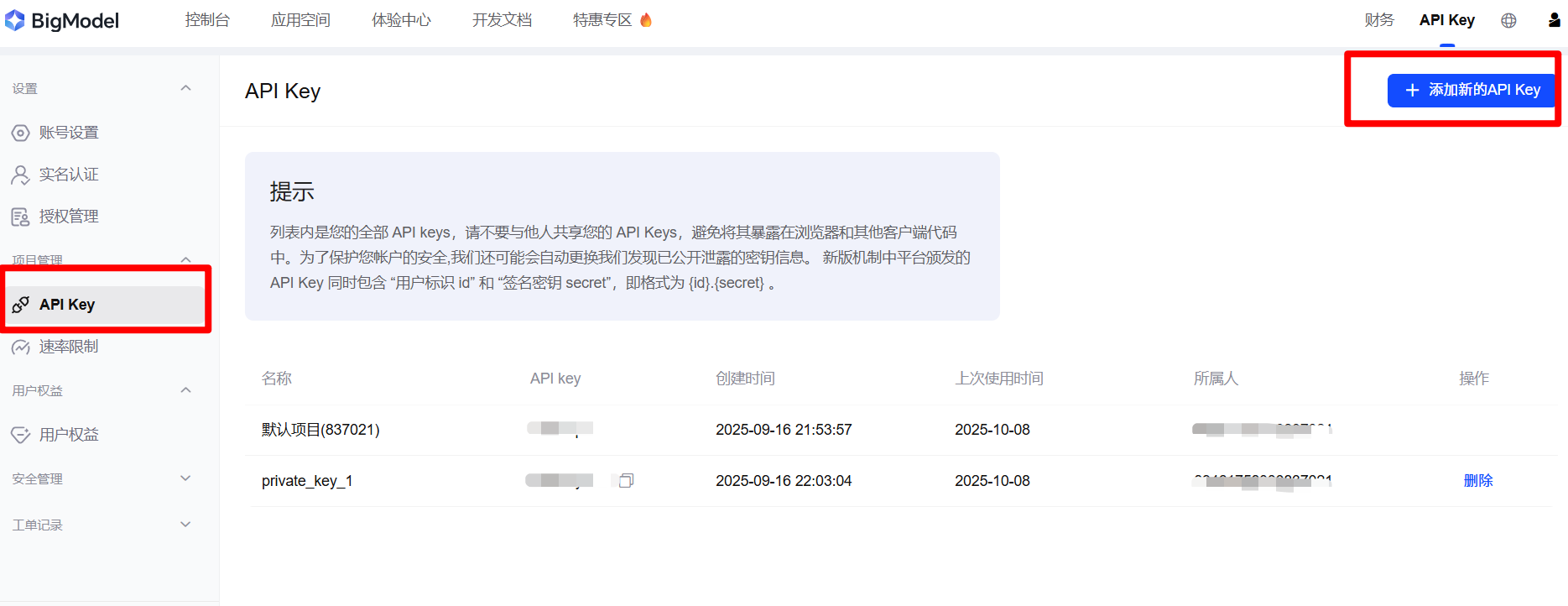
注册起来很简单,利用手机注册了之后,可以在API Key这里,添加新的API Key即可。
有了API key,就可以进行接下来的API调用练习。
3. 自定义Large Language Model (llm)
langchain并没有包装wrap所有的llm,对于deepseek这种比较知名的llm,进行了封装,可以方便的使用langchain的class进行调用,但是对于智谱AI这种模型,没有可以使用的class,这里可以使用自定义的Large Language Model (llm)进行保证,以期待和其他llm(例如deepseek)一样来书写代码。
自定义Large Language Model (llm)参照文档
3.1 继承langchain的BaseChatModel基类
继承BaseChatModel基类进行自定义llm的示例代码
import base64
import requests
from langchain_core.language_models.chat_models import BaseChatModel
from langchain_core.messages import AIMessage
from langchain_core.outputs import ChatResult, ChatGeneration
from pydantic import Fielddef image_to_base64(image_path):"""将本地图片文件转换为 base64 编码"""with open(image_path, "rb") as image_file:base64_data = base64.b64encode(image_file.read()).decode('utf-8')return f"data:image/jpeg;base64,{base64_data}"def _format_messages(messages):"""将 LangChain 消息格式转换为智谱 API 格式"""formatted = []for msg in messages:if hasattr(msg, 'type'):# 处理多模态消息if hasattr(msg, 'content') and isinstance(msg.content, list):content_list = []for content_item in msg.content:if content_item.get('type') == 'text':content_list.append({"type": "text","text": content_item['text']})elif content_item.get('type') == 'image_url':image_url = content_item['image_url']['url']if image_url.startswith('file://') or image_url.startswith('/'):# 处理本地文件路径image_path = image_url.replace('file://', '')base64_data = image_to_base64(image_path)content_list.append({"type": "image_url","image_url": {"url": base64_data}})elif image_url.startswith('data:image'):# 已经是 base64 格式content_list.append({"type": "image_url","image_url": {"url": image_url}})else:# 处理网络 URLtry:response = requests.get(image_url)response.raise_for_status()base64_data = base64.b64encode(response.content).decode('utf-8')content_list.append({"type": "image_url","image_url": {"url": f"data:image/jpeg;base64,{base64_data}"}})except Exception as e:print(f"图片处理失败: {e}")continueformatted.append({"role": "user", # 多模态消息通常是用户消息"content": content_list})else:# 处理普通文本消息formatted.append({"role": "user" if msg.type == "human" else "assistant","content": msg.content})return formattedclass GLM45V(BaseChatModel):"""智谱 AI GLM-4V 多模态模型"""api_key: str = Field(..., description="智谱 AI API 密钥")base_url: str = Field(default="https://open.bigmodel.cn/api/paas/v4/chat/completions")def __init__(self, api_key=None, **kwargs):super().__init__(api_key=api_key, **kwargs)def _generate(self, messages, stop=None, run_manager=None, **kwargs):try:response_content = self._call_glm4v_api(messages)message = AIMessage(content=response_content)generation = ChatGeneration(message=message)result = ChatResult(generations=[generation])return resultexcept Exception as e:error_message = AIMessage(content=f"API调用错误: {str(e)}")error_generation = ChatGeneration(message=error_message)return ChatResult(generations=[error_generation])def _call_glm4v_api(self, messages):headers = {"Content-Type": "application/json","Authorization": f"Bearer {self.api_key}"}# 转换 LangChain 消息格式为智谱 API 格式formatted_messages = _format_messages(messages)payload = {"model": "glm-4v","messages": formatted_messages,"max_tokens": 1000}response = requests.post(self.base_url, headers=headers, json=payload)response.raise_for_status() # 这会抛出 HTTPError 如果状态码不是 200result = response.json()return result["choices"][0]["message"]["content"]@propertydef _llm_type(self) -> str:return "glm-4v"
3.2 调用BaseChatModel基类的自定义llm
这里给出示例图片

示例代码
from langchain_core.messages import HumanMessage
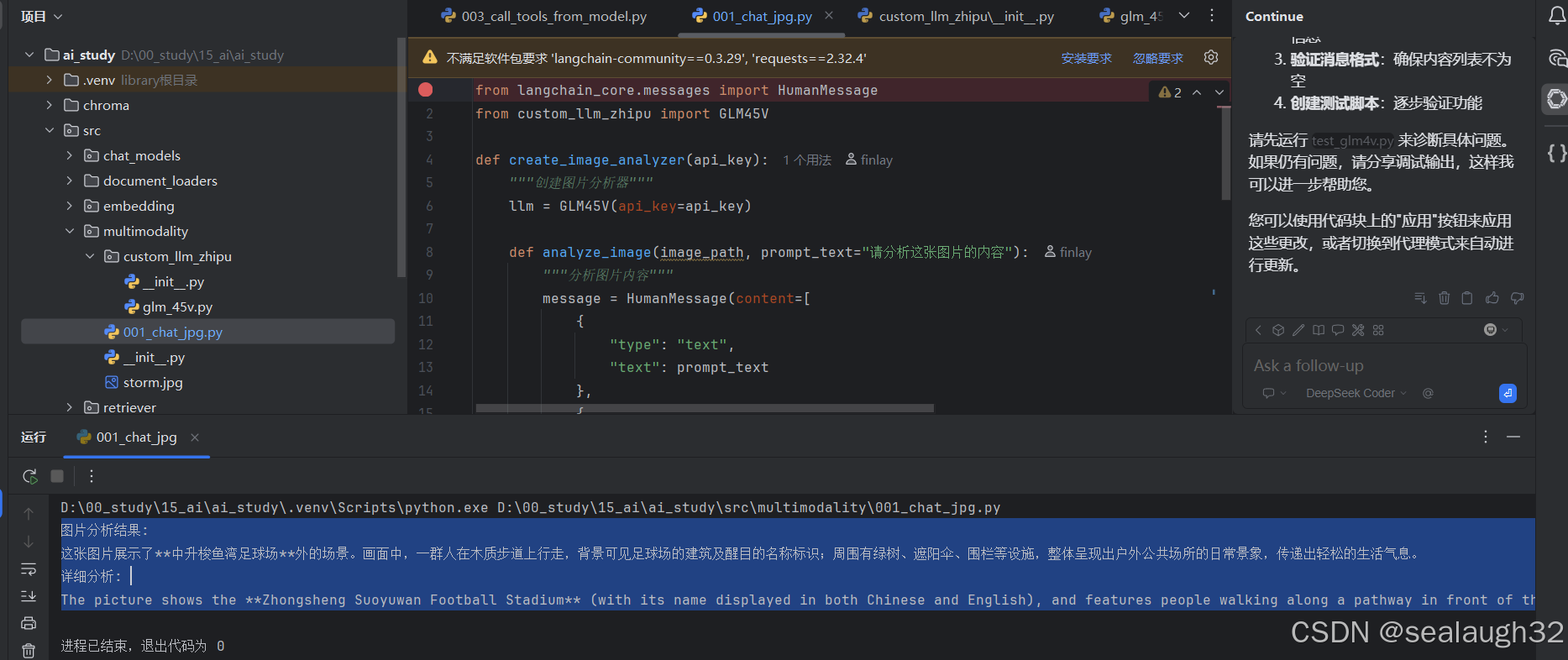
from custom_llm_zhipu import GLM45Vdef create_image_analyzer(api_key):"""创建图片分析器"""llm = GLM45V(api_key=api_key)def analyze_image(image_path, prompt_text="请分析这张图片的内容"):"""分析图片内容"""message = HumanMessage(content=[{"type": "text","text": prompt_text},{"type": "image_url","image_url": {"url": image_path}}])result = llm.generate([[message]])return result.generations[0][0].textreturn analyze_imageif __name__ == "__main__":analyzer = create_image_analyzer("67e07baf204f4c2d9fae94902f15954f.kOeTY0zLp4C3y57w")image_path = "https://pics0.baidu.com/feed/342ac65c103853430cafd074ea8f206ecb8088b4.jpeg@f_auto?token=ab564cab31e6f058f0648a17f06865af"result = analyzer(image_path)print("图片分析结果:", result)detailed_result = analyzer(image_path,"What are the pics talk about?")print("详细分析:", detailed_result)给大模型一个图片,并提出问题,请分析这张图片的内容。
执行代码,看看llm给出的分析结果
- 图片分析结果:
这张图片展示了中升梭鱼湾足球场外的场景。画面中,一群人在木质步道上行走,背景可见足球场的建筑及醒目的名称标识;周围有绿树、遮阳伞、围栏等设施,整体呈现出户外公共场所的日常景象,传递出轻松的生活气息。
详细分析:
The picture shows the Zhongsheng Suoyuwan Football Stadium (with its name displayed in both Chinese and English), and features people walking along a pathway in front of the stadium, depicting a public space around the sports venue. - 执行结果