自然语言处理中字节级与令牌级 Transformer 模型的对比分析
注:英文引文,机翻未校。
如有内容异常,请看原文。
A Comparative Analysis of Byte-Level and Token-Level Transformer Models in Natural Language Processing
自然语言处理中字节级与令牌级 Transformer 模型的对比分析
Greg Robison
Apr 22, 2025
How you can not know how many letter “r”s are in the word “strawberry”? You just count them up, 1–2–3. But what if you don’t see individual letters, but instead see chunks of letters? Those are tokens and how most current large language models (LLMs) parse and create text. It’s efficient but obviously has downsides — can LLMs process text one letter at a time instead? Yes!
你怎么会不知道“strawberry”这个单词里有多少个字母“r”呢?只需数一数就行,1-2-3。但如果看不到单个字母,只能看到字母块,又该怎么办呢?这些字母块就是令牌(tokens),也是当前大多数大型语言模型(Large Language Models, LLMs)解析和生成文本的方式。这种方式效率很高,但显然存在缺点——那么 LLMs 能否改为逐字母处理文本呢?答案是可以!
To find out more details, I had Gemini 2.5 Deep Research look into the various implementations of byte-level transformers.
为了了解更多细节,我让 Gemini 2.5 Deep Research 研究了字节级 Transformer 的各种实现方式。
1. Introduction
1. 引言
The Transformer architecture has become the cornerstone of modern Natural Language Processing (NLP), demonstrating remarkable capabilities across a wide array of tasks. Central to the operation and performance of these models is the method used to represent raw input text as numerical sequences suitable for processing. This initial step, known as tokenization, transforms continuous text into discrete units or “tokens”.¹ For years, subword tokenization algorithms like Byte Pair Encoding (BPE) and WordPiece have been the de facto standard, offering a balance between the large vocabularies of word-level tokenization and the excessive sequence lengths of character-level approaches.¹
Transformer 架构已成为现代自然语言处理(Natural Language Processing, NLP)的基石,在各类任务中都展现出卓越的性能。这类模型的运行与性能核心在于将原始输入文本转换为适合处理的数值序列的方法。这一初始步骤被称为令牌化(tokenization),它能将连续文本转换为离散单元,即“令牌(tokens)”。¹ 多年来,字节对编码(Byte Pair Encoding, BPE)和 WordPiece 等子词令牌化算法一直是事实上的标准,它们在词级令牌化的庞大词汇量与字符级方法的过长序列长度之间取得了平衡。¹
However, the reliance on these learned subword tokenizers introduces several inherent limitations. They often struggle with out-of-vocabulary (OOV) words, exhibit sensitivity to noise and spelling variations, can introduce biases against certain languages or scripts due to inconsistent compression rates, and add complexity through a separate, pre-trained module detached from the main model’s end-to-end learning process.¹ These drawbacks have motivated significant research into alternative input representations, leading to the rise of byte-level transformer models.
然而,对这些经过训练的子词令牌化器的依赖带来了若干固有局限性。它们常难以处理未登录词(out-of-vocabulary, OOV),对噪声和拼写变体敏感,且由于压缩率不一致可能对某些语言或文字系统产生偏见;此外,这类令牌化器作为独立的预训练模块,与主模型的端到端学习流程分离,增加了系统复杂度。¹ 这些缺点推动了对替代输入表示方式的大量研究,进而催生了字节级 Transformer 模型的兴起。
This report provides an in-depth comparative analysis of these two dominant paradigms: traditional token-based (subword) transformers and the increasingly prominent byte-level transformers. Byte-level models represent a move towards a “token-free” or “tokenizer-free” paradigm, processing raw text directly as sequences of UTF-8 bytes.³ The objective of this report is to dissect the fundamental differences in their text processing mechanisms, evaluate their respective strengths and weaknesses, compare their performance characteristics across various NLP tasks citing empirical evidence, analyze the implications for model architecture and training efficiency, and examine the practical trade-offs involved. By synthesizing findings from recent research, including work on models like ByT5, CANINE, and newer architectures such as Byte Latent Transformer (BLT), SpaceByte, and MrT5 ², this report aims to provide a clear understanding of the scenarios where each approach may be more suitable.
本报告对两种主流范式——传统的基于令牌(子词)的 Transformer 与日益受关注的字节级 Transformer——进行了深入的对比分析。字节级模型代表了向“无令牌(token-free)”或“无令牌化器(tokenizer-free)”范式的转变,它直接将原始文本作为 UTF-8 字节序列进行处理。³ 本报告的目的包括:剖析两种模型在文本处理机制上的根本差异,评估它们各自的优缺点,结合实证证据对比它们在各类 NLP 任务中的性能特征,分析它们对模型架构和训练效率的影响,并探讨相关的实际权衡。通过综合近期研究成果(包括 ByT5、CANINE 等模型的研究,以及字节潜在 Transformer(Byte Latent Transformer, BLT)、SpaceByte、MrT5 ²等新型架构的研究),本报告旨在明确两种方法各自更适用的场景。
The significant research investment directed towards overcoming the inherent computational challenges associated with byte-level processing underscores the perceived value of addressing the fundamental limitations of fixed tokenizers. The development of sophisticated techniques to manage the longer sequence lengths inherent in byte-level models suggests a determined effort to harness their potential benefits, such as universality and robustness, for practical applications.¹ This ongoing evolution makes a detailed comparison particularly timely.
为克服字节级处理固有的计算挑战,研究者投入了大量资源,这凸显了解决固定令牌化器根本局限性的潜在价值。为处理字节级模型固有的较长序列长度,各类复杂技术不断发展,这表明研究者正致力于将字节级模型的潜在优势(如通用性和鲁棒性)应用于实际场景。¹ 这种持续的发展使得对两种模型进行详细对比变得尤为迫切。
2. Understanding Text Processing: Bytes vs. Tokens
2. 理解文本处理:字节与令牌
The way raw text is converted into a format digestible by neural networks is a critical first step in any NLP pipeline, fundamentally influencing model behavior, performance, and efficiency.
在任何 NLP 流程中,将原始文本转换为神经网络可处理格式的方式都是关键的第一步,它从根本上影响模型的行为、性能和效率。
2.1 Tokenization Fundamentals
2.1 令牌化基础
Tokenization serves to segment text into discrete units.¹ Early methods included word-level tokenization, which splits text by spaces and punctuation. While intuitive, this approach suffers from extremely large vocabularies (requiring potentially hundreds of thousands of unique words) and the persistent problem of out-of-vocabulary (OOV) words — words encountered during inference that were not seen during training.¹ At the other extreme, character-level tokenization uses individual characters as the basic units. This drastically reduces vocabulary size but results in very long sequences, posing significant computational challenges for models like Transformers whose cost scales non-linearly with sequence length.¹
令牌化的作用是将文本分割为离散单元。¹ 早期方法包括词级令牌化,即通过空格和标点符号分割文本。这种方法虽然直观,但存在词汇量过大(可能需要包含数十万个唯一单词)和未登录词(out-of-vocabulary, OOV)的固有问题——推理过程中遇到的单词在训练阶段未曾出现。¹ 另一种极端是字符级令牌化,它以单个字符作为基本单元。这种方法大幅减小了词汇量,但会产生极长的序列,给 Transformer 等模型带来巨大的计算挑战,因为这类模型的计算成本随序列长度呈非线性增长。¹
2.2 Subword Tokenization (The Standard)
2.2 子词令牌化(标准方法)
Subword tokenization emerged as a practical compromise, aiming to balance vocabulary size and sequence length while mitigating the OOV problem.¹ These methods break words into smaller, meaningful units (subwords), allowing the model to represent rare or unseen words by composing them from known subwords. Common algorithms include:
子词令牌化是一种实用的折中方案,旨在平衡词汇量与序列长度,同时缓解未登录词问题。¹ 这类方法将单词拆分为更小的、有意义的单元(子词),使得模型能够通过已知子词的组合来表示稀有或未见过的单词。常见的算法包括:
-
Byte Pair Encoding (BPE): Originally a data compression algorithm, BPE starts with an initial vocabulary of individual characters (or bytes). It iteratively identifies the most frequent pair of adjacent tokens in the training corpus and merges them into a single new token, adding it to the vocabulary. This process repeats until a predefined vocabulary size is reached.¹ BPE can handle OOV words by breaking them down into the learned subwords or, if necessary, falling back to individual characters/bytes present in the initial vocabulary.¹ Models like GPT often utilize BPE.¹⁹
字节对编码(Byte Pair Encoding, BPE):BPE 最初是一种数据压缩算法,其初始词汇表由单个字符(或字节)构成。它会迭代地在训练语料中找出最频繁出现的相邻令牌对,将其合并为一个新令牌并加入词汇表。这一过程会重复进行,直到达到预设的词汇表大小。¹ 对于未登录词,BPE 可将其拆分为已学习的子词;必要时,还可退回到初始词汇表中的单个字符/字节。¹ GPT 等模型通常采用 BPE 算法。¹⁹ -
WordPiece: Employed by models such as BERT ¹⁹, WordPiece is similar to BPE but uses a different merge criterion. Instead of merging the most frequent pair, it merges the pair that maximizes the likelihood of the training data given the vocabulary.¹⁹ This likelihood-based approach can sometimes lead to different, potentially more efficient segmentations compared to frequency-based BPE.¹⁹
WordPiece:BERT ¹⁹等模型采用 WordPiece 算法,它与 BPE 类似,但使用不同的合并准则。WordPiece 不会合并最频繁的令牌对,而是合并能使“给定词汇表下训练数据的概率”最大化的令牌对。¹⁹ 与基于频率的 BPE 相比,这种基于概率的方法有时能产生不同的、可能更高效的分割结果。¹⁹ -
SentencePiece: This approach often tokenizes directly from raw text, treating whitespace as a regular character (e.g., represented by ▁) rather than a pre-tokenization separator.¹⁹ This makes it particularly useful for languages without explicit word boundaries, like Japanese or Chinese.¹⁹ SentencePiece provides implementations of both BPE and Unigram language model tokenization and is used in models like T5, mT5, and XLNet.⁵
SentencePiece:该方法通常直接对原始文本进行令牌化,将空格视为普通字符(例如用▁表示),而非令牌化前的分隔符。¹⁹ 这一特性使其对日语、汉语等无明确词边界的语言尤为适用。¹⁹ SentencePiece 提供了 BPE 和 Unigram 语言模型令牌化的实现,被应用于 T5、mT5、XLNet 等模型中。⁵ -
Byte-Level BPE (BBPE): It is important to distinguish standard BPE (which might start from characters) from Byte-Level BPE. BBPE specifically uses the 256 individual byte values as its initial vocabulary and performs the BPE merge operations on sequences of bytes derived from the UTF-8 encoding of the text.²⁰ This guarantees that any Unicode character can be represented, as its UTF-8 byte sequence can always be broken down into individual bytes present in the base vocabulary.²⁰ This avoids issues with unseen characters and limits the base vocabulary size to 256, unlike character-level BPE which might need a much larger initial set to cover all Unicode characters.²⁰ RoBERTa, for instance, uses BBPE.²⁰
字节级 BPE(Byte-Level BPE, BBPE):需注意区分标准 BPE(可能从字符开始构建词汇表)与字节级 BPE。BBPE 明确以 256 个独立的字节值作为初始词汇表,并对文本经 UTF-8 编码后得到的字节序列执行 BPE 合并操作。²⁰ 由于任何 Unicode 字符的 UTF-8 字节序列都可拆分为基础词汇表中的单个字节,因此 BBPE 能保证所有 Unicode 字符都可被表示。²⁰ 这避免了未见过字符的问题,并将基础词汇表大小限制为 256;而字符级 BPE 为覆盖所有 Unicode 字符,可能需要大得多的初始字符集。²⁰ 例如,RoBERTa 模型就采用了 BBPE。²⁰
2.3 Byte-Level Processing (The Alternative)
2.3 字节级处理(替代方案)
Byte-level models circumvent the tokenization step entirely. They operate directly on the raw UTF-8 byte representation of the input text.⁵ In the UTF-8 standard, each character is encoded as a sequence of one to four bytes.²⁶
字节级模型完全跳过了令牌化步骤,直接对输入文本的原始 UTF-8 字节表示进行处理。⁵ 在 UTF-8 标准中,每个字符被编码为 1 到 4 个字节的序列。²⁶
The core idea is to treat each individual byte as the fundamental processing unit. Consequently, the model’s vocabulary is extremely small and fixed, typically consisting of the 256 possible byte values (0–255), potentially augmented with a few special symbols for tasks like padding or indicating end-of-sequence.⁵ This contrasts dramatically with the large, learned vocabularies of subword tokenizers, which commonly range from 32,000 to over 128,000 entries.¹ A key implication is the elimination of the separate tokenizer module, which is normally trained independently on a corpus and then frozen.¹
其核心思想是将每个独立字节作为基本处理单元。因此,模型的词汇表极小且固定,通常包含 256 种可能的字节值(0-255);根据任务需求(如填充或表示序列结束),可能会额外添加少量特殊符号。⁵ 这与子词令牌化器的大型习得词汇表形成鲜明对比——子词词汇表通常包含 3.2 万到超过 12.8 万个条目。¹ 一个关键影响是,字节级模型无需独立的令牌化器模块(该模块通常需在语料上独立训练后固定)。¹
2.4 Comparative Sequence Characteristics
2.4 序列特征对比
The choice between token-level and byte-level processing leads to fundamental differences in the input sequences fed to the Transformer:
选择令牌级还是字节级处理,会导致输入到 Transformer 的序列产生根本差异:
-
Vocabulary Size: Byte-level models have a minimal, fixed vocabulary (e.g., 259 for ByT5: 256 bytes + 3 special tokens).⁵ Token-level models have much larger vocabularies learned from data (e.g., 32k for Llama 3 8B, 128k for Llama 3 70B, ~250k for mT5).¹
词汇量:字节级模型的词汇表极小且固定(例如,ByT5 的词汇表大小为 259,包含 256 个字节 + 3 个特殊符号)。⁵ 令牌级模型的词汇表则是从数据中习得的大型词汇表(例如,Llama 3 8B 为 3.2 万,Llama 3 70B 为 12.8 万,mT5 约为 25 万)。¹ -
Sequence Length: For the same input text, byte sequences are considerably longer than token sequences.¹ Subword tokenization acts as a form of compression.² For example, the mC4 corpus used for training mT5 and ByT5 showed an average compression rate of 4.1 bytes per SentencePiece token.⁵
序列长度:对于相同的输入文本,字节序列远长于令牌序列。¹ 子词令牌化本质上是一种压缩方式。² 例如,用于训练 mT5 和 ByT5 的 mC4 语料库显示,每个 SentencePiece 令牌的平均压缩率为 4.1 个字节。⁵ -
Information Density: Subword tokens, being composed of multiple characters or bytes and often corresponding to morphemes or frequent word parts, are designed to carry more semantic weight per unit than individual bytes.¹⁴ Bytes represent the most “atomic” level of text representation.¹
信息密度:子词令牌由多个字符或字节构成,通常对应语素或频繁出现的词片段,因此设计上每单位携带的语义信息比单个字节更多。¹⁴ 而字节是文本表示的最“原子化”层级。¹
Essentially, the distinction boils down to a trade-off between the granularity of the input representation and the degree of sequence compression achieved before the main model processes the data. Token-based approaches perform upfront compression and attempt to create semantically meaningful units via algorithms like BPE or WordPiece, but this introduces dependencies on the tokenizer’s training data and vocabulary, leading to brittleness and potential biases. Byte-level approaches prioritize universality and robustness by operating on the raw byte stream, but this necessitates significantly longer input sequences, thereby shifting the burden of efficiently processing this less compressed information onto the model architecture itself.
本质上,两者的区别可归结为输入表示的粒度与主模型处理数据前实现的序列压缩程度之间的权衡。基于令牌的方法会先进行压缩,并通过 BPE 或 WordPiece 等算法尝试构建语义上有意义的单元,但这会导致模型依赖令牌化器的训练数据和词汇表,进而产生脆弱性和潜在偏见。字节级方法通过对原始字节流进行处理,优先保证通用性和鲁棒性,但这需要处理长得多的输入序列,从而将高效处理这种低压缩信息的负担转移到了模型架构本身。
3. Advantages of Byte-Level Representation
3. 字节级表示的优势
Opting for byte-level processing offers several distinct advantages over traditional subword tokenization methods, primarily stemming from its universality and fine granularity.
选择字节级处理相比传统子词令牌化方法具有若干显著优势,这些优势主要源于其通用性和精细的粒度。
3.1 Elimination of Out-of-Vocabulary (OOV) Issues
3.1 解决未登录词(OOV)问题
A fundamental problem with tokenizers based on fixed, learned vocabularies is their inability to handle words or symbols not encountered during their training phase.¹ While subword methods can often break down unknown words into known pieces, this is not always perfect, and sometimes requires resorting to a generic “unknown” () token, losing information. Byte-level models completely sidestep this issue. Because their vocabulary consists of all 256 possible byte values, any sequence of text, regardless of language, novelty, or domain (including proper nouns, technical jargon, code snippets, or even deliberately misspelled words), can be perfectly represented as a sequence of known bytes.¹ This “open-vocabulary” nature is a significant benefit for models intended for diverse, open-domain applications where encountering novel terms is expected.
基于固定习得词汇表的令牌化器存在一个根本性问题:无法处理训练阶段未见过的单词或符号。¹ 尽管子词方法通常能将未知单词拆分为已知子词,但这种处理并非总是完美的,有时还需使用通用的“未知”()令牌,导致信息丢失。而字节级模型则完全规避了这一问题。由于其词汇表包含所有 256 种可能的字节值,任何文本序列——无论语言、新颖性或领域(包括专有名词、技术术语、代码片段,甚至是故意拼写错误的单词)——都能完美地表示为已知字节序列。¹ 这种“开放词汇”特性对于面向多样化、开放域应用的模型而言是重大优势,因为这类应用中遇到新术语是常见情况。
3.2 Inherent Multilingual and Cross-lingual Capabilities
3.2 固有的多语言与跨语言能力
Subword tokenization presents challenges in multilingual contexts. Creating a single tokenizer that effectively serves many languages often requires massive vocabularies to cover diverse scripts and morphologies, and the resulting tokenization can still be suboptimal or biased against low-resource languages.¹ Segmentation choices that work well for one language may be inefficient or linguistically unnatural for another, leading to inconsistent compression rates and potentially higher costs for users of certain languages.²
子词令牌化在多语言场景中面临挑战。要构建一个能有效服务于多种语言的令牌化器,通常需要庞大的词汇表以覆盖多样的文字系统和形态结构,即便如此,最终的令牌化结果仍可能不够优化,或对低资源语言存在偏见。¹ 对某一种语言有效的分割方式,对另一种语言可能效率低下或不符合语言习惯,这会导致压缩率不一致,并可能给使用特定语言的用户带来更高的计算成本。²
Byte-level models, leveraging the universal nature of UTF-8 encoding, inherently overcome these limitations. The fixed 256-byte vocabulary is language-agnostic.⁵ A single byte-level model can, in principle, process text from any language encoded in UTF-8 without requiring language-specific tokenizers or vocabulary adjustments.⁵ This simplifies the development of truly multilingual systems. Empirical evidence supports this advantage: ByT5 demonstrates strong performance on multilingual benchmarks like XTREME ⁵, has been successfully applied to Bible translation for underrepresented languages ³⁵, and shows benefits in cross-lingual transfer, particularly for languages with limited data.³⁶ Similarly, the CANINE model was designed with multilingual capabilities in mind and showed strong results on multilingual QA.¹⁰ Newer models like BLT also emphasize improved multilingual handling.³⁰
字节级模型借助 UTF-8 编码的通用性,从本质上克服了这些局限。固定的 256 字节词汇表与语言无关。⁵ 理论上,一个字节级模型即可处理任何以 UTF-8 编码的语言文本,无需针对特定语言设计令牌化器或调整词汇表。⁵ 这简化了真正多语言系统的开发。实证证据支持这一优势:ByT5 在 XTREME 等多语言基准测试中表现优异 ⁵,已成功应用于小众语言的《圣经》翻译 ³⁵,并且在跨语言迁移(尤其是低资源语言的跨语言迁移)中展现出优势。³⁶ 类似地,CANINE 模型在设计时就考虑了多语言能力,在多语言问答任务中表现出色。¹⁰ BLT 等较新模型也着重提升了多语言处理能力。³⁰
3.3 Enhanced Robustness to Noise, Misspellings, and Variations
3.3 对噪声、拼写错误和变体的更强鲁棒性
Token-based models can be surprisingly brittle. Minor surface-level changes in the input text, such as typos, variations in capitalization, or common spelling errors, can lead to drastically different token sequences.¹ This occurs because the tokenizer might split a misspelled word differently or assign different tokens based on case, potentially confusing the downstream model even if the underlying meaning is largely preserved.
基于令牌的模型可能意外地脆弱。输入文本表面的微小变化(如拼写错误、大小写变体或常见拼写失误)都可能导致令牌序列发生巨大变化。¹ 原因在于,令牌化器可能会以不同方式分割拼写错误的单词,或根据大小写分配不同的令牌——即便文本的核心含义基本不变,也可能给下游模型造成困惑。
Byte-level models exhibit greater resilience to such perturbations. A small change like a single-character typo typically alters only one or a few bytes in the sequence. The surrounding byte context remains largely intact, potentially allowing the model to recognize the intended word or meaning despite the noise.² Research has shown that byte-level models like ByT5 are significantly more robust to various types of noise compared to their token-based counterparts (mT5) and perform better on tasks sensitive to spelling and pronunciation.⁵ Recent models like BLT explicitly demonstrate enhanced robustness to noisy inputs ³, and MrT5 aims to preserve this robustness while improving efficiency.² This makes byte-level approaches particularly attractive for processing real-world text, which is often messy and contains imperfections.
字节级模型对这类干扰表现出更强的抵抗力。单个字符拼写错误这类微小变化,通常只会改变序列中的一个或几个字节,周围的字节上下文基本保持完整——这使得模型即便在存在噪声的情况下,仍有可能识别出预期的单词或含义。² 研究表明,与基于令牌的对应模型(mT5)相比,ByT5 等字节级模型对各类噪声的鲁棒性显著更高,并且在对拼写和发音敏感的任务中表现更优。⁵ BLT 等近期模型明确展现出对噪声输入的更强鲁棒性 ³,而 MrT5 则旨在在保持这种鲁棒性的同时提升效率。² 这使得字节级方法在处理现实世界文本时极具吸引力——现实文本往往杂乱且存在缺陷。
3.4 Simplified Preprocessing Pipelines and Reduced Technical Debt
3.4 简化预处理流程并减少技术债务
Integrating tokenization into an NLP workflow adds complexity. It requires selecting or training a tokenizer, managing its vocabulary, ensuring consistency between training and deployment environments, and handling potential versioning issues.¹ This preprocessing step exists outside the main model’s end-to-end training and can become a source of errors or “technical debt”.
将令牌化集成到 NLP 工作流中会增加复杂度:需要选择或训练令牌化器、管理其词汇表、确保训练与部署环境的一致性,并处理潜在的版本问题。¹ 这一预处理步骤独立于主模型的端到端训练流程,可能成为错误或“技术债务”的来源。
Byte-level models eliminate this entire stage. They operate directly on raw UTF-8 encoded text, drastically simplifying the input pipeline.⁵ This reduction in system complexity is not only elegant but also reduces potential points of failure and makes models easier to deploy and maintain across different languages and platforms.
字节级模型则完全省去了这一环节。它们直接对原始 UTF-8 编码文本进行处理,大幅简化了输入流程。⁵ 系统复杂度的降低不仅在设计上更简洁,还减少了潜在的故障点,使得模型在不同语言和平台上的部署与维护更加容易。
These advantages collectively arise from the fundamental choice to operate at the most basic digital level of text representation — bytes. By avoiding the intermediate abstraction layer of a learned tokenizer, byte-level models gain universality (no OOV words, inherent multilingualism) and robustness to surface variations, while simplifying the overall system architecture.
这些优势共同源于一个根本性选择:在文本表示的最基础数字层级(字节)上进行处理。通过避开习得令牌化器这一中间抽象层,字节级模型获得了通用性(无未登录词、固有的多语言能力)和对表面变化的鲁棒性,同时简化了整体系统架构。
4. Challenges and Weaknesses of Byte-Level Transformers
4. 字节级 Transformer 的挑战与不足
Despite their compelling advantages, byte-level transformers face significant challenges, primarily related to computational efficiency and the potential difficulty in learning higher-level linguistic structures.
尽管字节级 Transformer 具有显著优势,但它们也面临重大挑战,这些挑战主要与计算效率以及学习高层级语言结构的潜在难度相关。
4.1 Increased Sequence Length
4.1 序列长度增加
The most immediate consequence of operating on bytes is a dramatic increase in sequence length compared to token-based approaches.¹ As previously noted, subword tokenization typically compresses text by a factor of around 4x or more relative to bytes.⁵ This means a byte-level model must process sequences that are substantially longer to cover the same amount of text. This has profound implications for the Transformer architecture, where the computational complexity of the self-attention mechanism scales quadratically with sequence length (O(n2)O(n^2)O(n2)), and the feed-forward layers scale linearly (O(n)O(n)O(n)).¹¹ Even if attention cost is not the primary bottleneck for very large models, the linear scaling of the large feed-forward networks still imposes a significant burden with longer sequences.³
基于字节进行处理最直接的后果是,与基于令牌的方法相比,序列长度大幅增加。¹ 如前所述,子词令牌化对文本的压缩率通常约为字节序列的 4 倍或更高。⁵ 这意味着,要处理相同数量的文本,字节级模型必须处理长得多的序列。这对 Transformer 架构产生了深远影响:自注意力机制的计算复杂度随序列长度呈二次方增长(O(n2)O(n^2)O(n2)),而前馈层的计算复杂度则呈线性增长(O(n)O(n)O(n))。¹¹ 即便对于超大型模型而言,注意力成本并非主要瓶颈,大型前馈网络的线性增长仍会给长序列处理带来沉重负担。³
4.2 Higher Computational Cost (FLOPs, Memory, Latency)
4.2 更高的计算成本(浮点运算、内存、延迟)
The increased sequence length directly translates into higher computational demands. Processing longer sequences requires significantly more floating-point operations (FLOPs) for both training and inference.¹ For instance, pre-training ByT5 was found to require approximately 1.2 times more FLOPs per forward pass than a parameter-matched mT5.² This increased computational load leads to slower training speeds (fewer sequences processed per second) ⁵ and higher inference latency.² The inference slowdown can be particularly pronounced for tasks involving long inputs or outputs; ByT5 was reported to be up to 10 times slower than mT5 on certain tasks ², and character models generally can be 4–6 times slower in translation scenarios.³⁷ Memory requirements also increase due to the need to store activations for longer sequences. This efficiency gap has historically been a major barrier to the widespread adoption of purely byte-level models.²
序列长度的增加直接导致计算需求上升。无论是训练还是推理,处理更长的序列都需要多得多的浮点运算(FLOPs)。¹ 例如,研究发现,在单次前向传播中,预训练 ByT5 所需的浮点运算量约为参数规模相当的 mT5 的 1.2 倍。² 这种计算负载的增加会导致训练速度变慢(每秒处理的序列数量减少)⁵ 和推理延迟升高。² 对于涉及长输入或长输出的任务,推理速度的下降尤为明显:有报告称,在某些任务中 ByT5 的速度比 mT5 慢高达 10 倍 ²,而在翻译场景中,字符级模型通常比令牌级模型慢 4-6 倍。³⁷ 此外,由于需要存储长序列的激活值,内存需求也会增加。从历史上看,这种效率差距一直是纯字节级模型广泛应用的主要障碍。²
4.3 Potential Difficulties in Capturing High-Level Semantic Units
4.3 捕获高层级语义单元的潜在难度
A more subtle challenge relates to how models learn meaning. Subword tokens, often corresponding to morphemes or common word parts, arguably provide a stronger initial semantic signal or inductive bias compared to individual bytes.¹⁴ Bytes themselves carry very little semantic information in isolation.⁴⁰ Consequently, byte-level models might need to expend more of their capacity and require more data to learn how to group bytes into meaningful linguistic units like words, prefixes, or suffixes, which token-based models get partially “for free” from the tokenizer.⁴ Some studies suggest that this fine granularity can make it harder for byte/character models to capture semantic relationships efficiently, potentially leading them to learn simpler statistical patterns initially (like unigram distributions) if not guided properly.⁴¹
一个更微妙的挑战与模型如何学习语义相关。子词令牌通常对应语素或常见的单词片段,相比单个字节,它们无疑能提供更强的初始语义信号或归纳偏置。¹⁴ 而单个字节本身几乎不携带任何语义信息。⁴⁰ 因此,字节级模型可能需要投入更多的模型容量,并需要更多的数据,才能学会将字节组合成有意义的语言单元(如单词、前缀或后缀)——而基于令牌的模型从令牌化器中就能“免费”获得部分这类单元。⁴ 一些研究表明,这种精细的粒度可能使字节/字符级模型更难高效捕获语义关系;如果没有适当引导,这些模型在初始阶段可能只会学习简单的统计模式(如单字分布)。⁴¹
However, this point is nuanced. Numerous studies demonstrate that byte-level models like ByT5 can achieve strong, even superior, performance on complex downstream tasks requiring deep semantic understanding, such as translation, summarization, and question answering.⁵ Furthermore, analyses suggest ByT5 learns to utilize both word-level and character-level information effectively.³⁷ Recent models like BLT report qualitative improvements in reasoning and generalization.³ Therefore, the challenge might not be an inherent inability to capture semantics, but rather a potential inefficiency in the learning process compared to models given the head start of subword tokens. The model needs sufficient capacity and data to learn these higher-level structures from the byte stream.
然而,这一问题存在细微差别。大量研究表明,ByT5 等字节级模型在需要深度语义理解的复杂下游任务(如翻译、摘要和问答)中能取得优异甚至更优的性能。⁵ 此外,分析显示 ByT5 能有效利用词级和字符级信息。³⁷ BLT 等近期模型还报告了在推理和泛化能力上的质性提升。³ 因此,挑战可能并非字节级模型“天生无法”捕获语义,而是与拥有子词令牌“先发优势”的模型相比,其学习过程可能存在效率差异。字节级模型需要足够的容量和数据,才能从字节流中学习到这些高层级结构。
4.4 Historical Scaling Limitations
4.4 历史上的缩放限制
The significant computational overhead associated with long byte sequences historically made it difficult to scale purely byte-level models to the sizes common for state-of-the-art tokenized models.³ This practical limitation spurred the development of architectural innovations specifically designed to mitigate the cost, such as the downsampling techniques in CANINE ⁹, the merging mechanism in MrT5 ², and the patching strategies in BLT and SpaceByte.³ The success of these techniques, particularly the recent demonstration of scaling BLT up to 8 billion parameters while matching tokenized model performance ³, indicates that this scaling barrier is being overcome.
从历史上看,长字节序列带来的巨大计算开销,使得纯字节级模型难以扩展到最先进令牌化模型的常见规模。³ 这一实际限制推动了针对性的架构创新开发,例如 CANINE 中的下采样技术 ⁹、MrT5 中的合并机制 ²,以及 BLT 和 SpaceByte 中的补丁策略 ³。这些技术的成功(尤其是近期 BLT 被扩展到 80 亿参数规模,同时性能与令牌化模型相当 ³)表明,这一缩放障碍正被逐步克服。
In essence, the predominant weakness of byte-level models revolves around computational efficiency. The lack of input compression compared to tokenizers leads to longer sequences and higher costs. This core issue has driven architectural innovation aimed at reducing the effective sequence length processed by the most computationally intensive parts of the model. While questions remain about the relative efficiency of learning high-level semantics from bytes versus tokens, the rapid progress in architectural solutions suggests the primary historical bottleneck of computational cost is being actively and successfully addressed.
本质上,字节级模型的主要不足围绕计算效率展开。与令牌化器相比,字节级模型缺乏输入压缩,导致序列更长、成本更高。这一核心问题推动了架构创新——这些创新旨在减少模型中计算密集型部分所处理的有效序列长度。尽管关于从字节学习高层级语义与从令牌学习的相对效率仍存在疑问,但架构解决方案的快速进展表明,计算成本这一历史上的主要瓶颈正得到积极且成功的解决。
5. Comparative Performance Analysis
5. 性能对比分析
Evaluating the performance of byte-level versus token-level transformers requires examining their behavior across a diverse range of NLP tasks and benchmarks. The results often reveal context-dependent strengths and weaknesses.
评估字节级与令牌级 Transformer 的性能,需要考察它们在各类 NLP 任务和基准测试中的表现。结果通常会揭示出两者在不同场景下的优势与不足。
5.1 Standard English Benchmarks (GLUE, SuperGLUE)
5.1 标准英语基准测试(GLUE、SuperGLUE)
On standard English natural language understanding benchmarks like GLUE and SuperGLUE, which consist primarily of classification tasks, the comparison between ByT5 and its token-based counterpart mT5 showed mixed results.⁵ ByT5 generally outperformed mT5 at smaller model sizes (Small and Base configurations). However, as model size increased (Large, XL, XXL), mT5 tended to gain an advantage.⁵ This suggests that for standard English tasks where tokenizers are typically well-optimized, the compression and potentially stronger initial semantic units provided by tokens might become more beneficial at very large model scales. Conversely, byte-level processing might offer better parameter efficiency at smaller scales for these tasks.
在 GLUE、SuperGLUE 等以分类任务为主的标准英语自然语言理解基准测试中,ByT5 与其基于令牌的对应模型 mT5 的对比结果呈现出混合特征。⁵ 在较小模型规模下(Small 和 Base 配置),ByT5 的性能通常优于 mT5;但随着模型规模增大(Large、XL、XXL),mT5 逐渐显现优势。⁵ 这表明,对于令牌化器通常已高度优化的标准英语任务,在超大规模模型场景下,令牌所提供的压缩能力和潜在更强的初始语义单元可能更具优势;相反,在较小模型规模下,字节级处理在这些任务中可能具有更优的参数效率。
5.2 Multilingual Benchmarks (XTREME)
5.2 多语言基准测试(XTREME)
Byte-level models demonstrate compelling advantages in multilingual settings. In the XTREME benchmark comparison, ByT5 consistently outperformed mT5 across all model sizes on the in-language multitask setting, which covers tasks like named entity recognition (WikiAnn NER), question answering (TyDiQA-GoldP, XQuAD, MLQA), natural language inference (XNLI), and paraphrase identification (PAWS-X).⁵ In the translate-train setting, ByT5 also generally performed better at smaller sizes, with mixed results at larger scales.⁵ Furthermore, the CANINE encoder outperformed a comparable mBERT model on the challenging multilingual TyDi QA benchmark, despite having fewer parameters.¹⁰ These results strongly support the hypothesis that the universal vocabulary and inherent ability to handle diverse scripts and morphologies make byte-level models particularly well-suited for multilingual understanding.⁵
字节级模型在多语言场景中展现出显著优势。在 XTREME 基准测试对比中,在“语言内多任务”场景下(涵盖命名实体识别(WikiAnn NER)、问答(TyDiQA-GoldP、XQuAD、MLQA)、自然语言推理(XNLI)、释义识别(PAWS-X)等任务),ByT5 在所有模型规模下的性能均持续优于 mT5。⁵ 在“翻译-训练”场景下,ByT5 在较小模型规模下通常表现更优,在较大规模下则结果混合。⁵ 此外,尽管 CANINE 编码器的参数数量更少,但在具有挑战性的多语言 TyDi QA 基准测试中,其性能仍优于参数规模相当的 mBERT 模型。¹⁰ 这些结果有力地支持了以下假设:字节级模型的通用词汇表及其处理多样文字系统和形态结构的固有能力,使其特别适合多语言理解任务。⁵
5.3 Generative Tasks (Summarization, QA)
5.3 生成式任务(摘要、问答)
Byte-level models have shown particular strength in generative tasks. ByT5 consistently outperformed mT5 across all model sizes on abstractive summarization (GEM-XSum) and abstractive question answering tasks requiring generation (TweetQA, DROP).⁵ Newer models like BLT report qualitative improvements in reasoning and long-tail generalization capabilities, which are crucial for high-quality generation.³ Additionally, research exploring multi-token prediction, tested with byte-level models, indicates potential for improving generative performance.⁴⁴ The fine-grained nature of byte-level representations might allow these models to generate text with more nuanced control or suffer less from the constraints imposed by fixed token boundaries.
字节级模型在生成式任务中表现出独特优势。在抽象摘要(GEM-XSum)和需要生成能力的抽象问答任务(TweetQA、DROP)中,ByT5 在所有模型规模下的性能均持续优于 mT5。⁵ BLT 等较新模型报告称,其在推理能力和长尾泛化能力上实现了质性提升,而这些能力对高质量生成至关重要。³ 此外,针对字节级模型开展的多令牌预测研究表明,该方向具有提升生成性能的潜力。⁴⁴ 字节级表示的精细粒度特性,可能使这些模型在生成文本时具备更细致的控制能力,或更少受到固定令牌边界的限制。
5.4 Machine Translation (MT)
5.4 机器翻译(MT)
In machine translation, ByT5 generally achieves competitive or superior BLEU scores compared to mT5, especially in low-resource scenarios where fine-tuning data is scarce.³⁷ It demonstrates a better ability to translate orthographically similar words and rare words accurately.³⁷ Its effectiveness has been leveraged for translating the Bible into underrepresented languages.³⁵ BLT also shows promise for low-resource MT.³ However, this performance comes at the cost of significantly slower training and inference speeds compared to token-based models ³⁷, making efficiency a major trade-off in practical MT deployment.
在机器翻译任务中,ByT5 的 BLEU 评分通常与 mT5 相当或更优,尤其在微调数据稀缺的低资源场景下表现突出。³⁷ 该模型在准确翻译拼写相似单词和稀有单词方面能力更强。³⁷ 其有效性已被应用于将《圣经》翻译为小众语言的任务中。³⁵ BLT 在低资源机器翻译任务中也展现出潜力。³ 然而,这种性能优势的代价是:与基于令牌的模型相比,ByT5 的训练和推理速度显著更慢 ³⁷,这使得效率成为实际机器翻译部署中的主要权衡因素。
5.5 Tasks Sensitive to Character/Byte Information
5.5 对字符/字节信息敏感的任务
Unsurprisingly, byte-level models excel on tasks that require explicit understanding or manipulation of character-level information. ByT5 demonstrated substantial improvements over mT5 on tasks like transliteration (Dakshina benchmark), grapheme-to-phoneme conversion (Sigmorphon G2P), and morphological inflection (Sigmorphon Morphology).⁵ BLT also exhibits enhanced character-level understanding, including orthography and phonology.³ Conversely, tokenized models often struggle with tasks like spelling or character manipulation because the relevant information is obscured by the tokenization process.²⁸ Byte-level models also show promise for tasks like spelling correction.³¹
不出所料,字节级模型在需要明确理解或操作字符级信息的任务中表现卓越。在音译(Dakshina 基准测试)、字形到音素转换(Sigmorphon G2P)、形态屈折变化(Sigmorphon Morphology)等任务中,ByT5 的性能相较于 mT5 有显著提升。⁵ BLT 在字符级理解(包括拼写规则和语音学)方面也表现出增强能力。³ 相反,基于令牌的模型在拼写或字符操作类任务中往往表现不佳,因为令牌化过程会掩盖相关的字符级信息。²⁸ 字节级模型在拼写纠正等任务中也展现出潜力。³¹
5.6 Robustness Benchmarks
5.6 鲁棒性基准测试
The enhanced robustness of byte-level models to noisy input is quantifiable. On a noisy version of the HellaSwag benchmark, BLT achieved 64.3% accuracy compared to 56.9% for the token-based Llama 3 model.³⁹ This empirically confirms the qualitative observations about ByT5’s robustness.⁵
字节级模型对噪声输入的增强鲁棒性可通过量化方式验证。在含噪声的 HellaSwag 基准测试中,BLT 的准确率达到 64.3%,而基于令牌的 Llama 3 模型准确率仅为 56.9%。³⁹ 这一结果从实证角度证实了此前关于 ByT5 鲁棒性的定性观察。⁵
5.7 Recent Model Comparisons (e.g., BLT vs Llama 3, SpaceByte vs Subword Transformers)
5.7 近期模型对比(如 BLT 与 Llama 3、SpaceByte 与子词 Transformer)
Recent advancements in byte-level architectures aim to close the efficiency gap while maintaining performance. The Byte Latent Transformer (BLT) has been shown to match the performance of strong tokenization-based models like Llama 3 at the 8B parameter scale, while requiring up to 50% fewer FLOPs during inference.³ SpaceByte, using dynamic patching aligned with word boundaries, roughly matched or even outperformed subword Transformer models (using SentencePiece) in compute-controlled experiments on English text, arXiv papers, and code datasets.¹⁵ These results indicate that the latest generation of byte-level models are not only catching up but potentially surpassing token-based models in terms of performance per unit of computation.
近期字节级架构的进展旨在缩小效率差距的同时保持性能。研究表明,在 80 亿参数规模下,字节潜在 Transformer(BLT)的性能可与 Llama 3 等高性能基于令牌的模型相当,且推理时所需的浮点运算量(FLOPs)减少了高达 50%。³ SpaceByte 采用与词边界对齐的动态补丁技术,在英语文本、arXiv 论文和代码数据集的计算控制实验中,其性能与基于子词的 Transformer 模型(使用 SentencePiece)大致相当,甚至更优。¹⁵ 这些结果表明,最新一代字节级模型不仅正在追赶基于令牌的模型,还可能在单位计算性能方面实现超越。
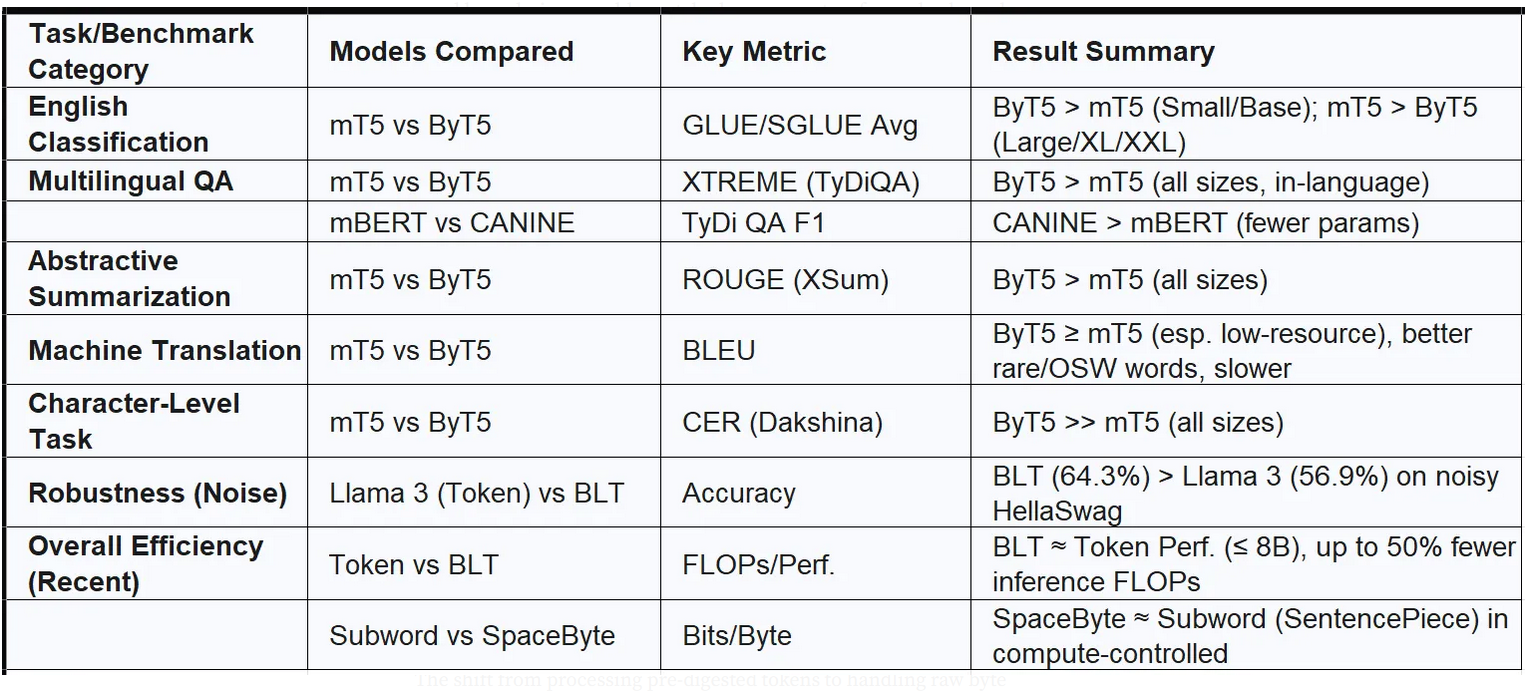
Table 1: Performance Summary on Key Tasks/Benchmarks
表 1:关键任务/基准测试性能摘要
The performance landscape is clearly multifaceted. Byte-level models demonstrate consistent strengths in scenarios demanding universality (multilingualism), robustness to noise and surface variations, and fine-grained character-level control. Token-based models have historically held an edge in efficiency and potentially on large-scale, clean, high-resource monolingual tasks, although recent byte-level innovations are challenging this status quo. The trend indicates that architectural improvements are steadily making byte-level models more competitive across a wider range of applications.
性能格局显然具有多面性。在对通用性(多语言能力)、噪声与表面变化鲁棒性、精细字符级控制有需求的场景中,字节级模型展现出持续优势。从历史上看,基于令牌的模型在效率方面,以及在大规模、数据清洁的高资源单语言任务中可能具有优势——但近期字节级模型的创新正挑战这一现状。趋势表明,架构改进正稳步提升字节级模型在更广泛应用场景中的竞争力。
6. Impact on Model Architecture and Training
6. 对模型架构与训练的影响
The shift from processing pre-digested tokens to handling raw byte sequences necessitates fundamental changes in how transformer models are designed and trained, primarily driven by the need to manage the increased sequence length and computational cost.
从处理预处理后的令牌转向处理原始字节序列,要求 Transformer 模型的设计与训练方式发生根本性变革——这主要是由管理更长序列长度和更高计算成本的需求所推动的。
6.1 Architectural Modifications
6.1 架构修改
Simply feeding much longer byte sequences into a standard Transformer designed for tokens is often computationally infeasible or inefficient.² Consequently, successful byte-level models incorporate specific architectural adaptations:
将长得多的字节序列直接输入为令牌设计的标准 Transformer,通常在计算上不可行或效率低下。² 因此,成功的字节级模型会纳入特定的架构调整:
-
Encoder-Decoder Ratios: The ByT5 model, lacking the large parameter budget typically allocated to token embeddings, compensates by using a “heavy” encoder architecture. It features an encoder depth three times that of the decoder (a 3:1 ratio), contrasting with the balanced (1:1) structure common in models like T5 and mT5. This reallocation allows the encoder more capacity to process the longer, less structured byte input.²
编解码器比例:ByT5 模型没有像传统模型那样将大量参数分配给令牌嵌入,而是通过“重型”编码器架构进行补偿。其编码器深度是解码器的 3 倍(比例为 3:1),这与 T5、mT5 等模型中常见的均衡(1:1)结构形成对比。这种参数重新分配使编码器拥有更强的能力,以处理更长、结构更松散的字节输入。² -
Downsampling/Upsampling: The CANINE encoder tackles efficiency by employing downsampling early in the architecture. It uses techniques like strided convolutions possibly combined with initial local attention blocks to reduce the sequence length significantly before the main deep transformer stack processes the information. An upsampling layer can then restore the sequence to its original length if needed for tasks requiring per-byte outputs.⁹ This approach aims to achieve processing speeds comparable to tokenized models despite the finer input granularity.⁹
下采样/上采样:CANINE 编码器通过在架构早期采用下采样技术解决效率问题。它使用步长卷积(可能结合初始局部注意力块)等技术,在主深度 Transformer 栈处理信息之前大幅缩短序列长度。若任务需要逐字节输出,后续的上采样层可将序列恢复到原始长度。⁹ 该方法旨在在输入粒度更精细的情况下,实现与令牌化模型相当的处理速度。⁹ -
Patching Mechanisms: More recent models introduce the concept of grouping contiguous bytes into “patches,” which then serve as the primary units of computation for the main (and most expensive) transformer layers. This effectively creates a hierarchical processing structure.
补丁机制:较新的模型引入了将连续字节分组为“补丁(patches)”的概念,这些补丁随后成为主(且计算成本最高的)Transformer 层的主要计算单元。这一设计有效构建了分层处理结构。-
Byte Latent Transformer (BLT): Implements dynamic patching where patch boundaries are determined based on the entropy (predictability) of the next byte. Less predictable byte sequences might form shorter patches, demanding more localized computation, while highly predictable sequences (like repeated characters) form longer patches.³ It uses separate lightweight encoder/decoder modules to map between bytes and latent patch representations, with a main latent transformer operating on these patches.³
字节潜在 Transformer(BLT):采用动态补丁机制,补丁边界根据下一个字节的熵(可预测性)确定。可预测性较低的字节序列可能形成较短的补丁(需要更多局部计算),而可预测性高的序列(如重复字符)则形成较长的补丁。³ 该模型使用独立的轻量级编解码器模块实现字节与潜在补丁表示之间的映射,主潜在 Transformer 则对这些补丁进行处理。³ -
SpaceByte: Uses multiscale modeling where larger “global” transformer blocks are applied only after specific “spacelike” bytes (most commonly space characters), effectively aligning patches with natural language boundaries like words.¹⁵ This dynamic, linguistically motivated patching proved crucial for its performance.¹⁵
SpaceByte:采用多尺度建模,仅在特定“类空格(spacelike)”字节(最常见的是空格字符)之后应用较大的“全局”Transformer 块,从而使补丁与单词等自然语言边界有效对齐。¹⁵ 这种基于语言特征的动态补丁机制被证实对其性能至关重要。¹⁵
-
-
Token Merging/Deletion: MrT5, designed as an efficient ByT5 variant, introduces a learned gating mechanism within the encoder. After a few initial layers process the full byte sequence to capture context, this gate dynamically identifies and removes (merges) less informative byte tokens, passing a shorter sequence to subsequent encoder layers and the decoder.² This significantly reduces computation in the deeper parts of the model.²
令牌合并/删除:MrT5 是 ByT5 的高效变体,其在编码器中引入了习得的门控机制。在最初几层处理完整字节序列以捕获上下文后,该门控机制会动态识别并删除(合并)信息含量较低的字节令牌,将较短的序列传递给后续的编码器层和解码器。² 这一设计大幅减少了模型深层部分的计算量。² -
Hashing: To avoid a large embedding table even for characters (Unicode contains many thousands), CANINE uses a character hashing technique. Each character’s Unicode codepoint is mapped to an embedding not via a direct lookup but by combining embeddings derived from multiple hash functions applied to the codepoint.⁹
哈希技术:即使对于字符(Unicode 包含数千个字符),为避免使用庞大的嵌入表,CANINE 采用了字符哈希技术。每个字符的 Unicode 码点并非通过直接查找映射到嵌入向量,而是通过组合“对码点应用多个哈希函数得到的嵌入向量”来实现映射。⁹
6.2 Parameter Allocation
6.2 参数分配
The choice between bytes and tokens significantly impacts how model parameters are distributed. Token-based models dedicate a substantial portion of their parameters to the input embedding matrix (mapping token IDs to vectors) and the final output projection layer (mapping hidden states back to token logits). For a model like Llama-3 8B with a 128k vocabulary, these components can account for roughly 13% of the total parameters.¹
选择字节还是令牌,对模型参数的分配方式有显著影响。基于令牌的模型会将大量参数分配给输入嵌入矩阵(将令牌 ID 映射到向量)和最终输出投影层(将隐藏状态映射回令牌对数概率)。以 Llama-3 8B 模型(词汇表大小为 12.8 万)为例,这些组件约占总参数的 13%。¹
Byte-level models, with their tiny fixed vocabularies (e.g., 256 bytes), require negligible parameters for embeddings and output projections.¹ This frees up a significant parameter budget, which is typically reinvested into the main processing components of the model. As seen with ByT5, these parameters may be used to increase the depth of the encoder ² or potentially the width (hidden size dmodeld_{model}dmodel, feed-forward dimension dffd_{ff}dff) of the transformer layers.⁵ This reallocation reflects a fundamental trade-off: token models rely partly on the “knowledge” compressed into the learned token vocabulary, while byte models rely more heavily on the raw computational power and capacity of the transformer layers themselves to interpret the uncompressed byte stream.
字节级模型的固定词汇表极小(如 256 个字节),因此其嵌入层和输出投影层所需的参数几乎可以忽略不计。¹ 这就节省出了大量参数预算,这些预算通常会重新分配给模型的主要处理组件。以 ByT5 为例,这些参数可能用于增加编码器的深度 ²,或可能用于扩大 Transformer 层的宽度(隐藏层大小 dmodeld_{model}dmodel、前馈网络维度 dffd_{ff}dff)。⁵ 这种参数重新分配反映了一种根本性权衡:基于令牌的模型部分依赖于“压缩到习得令牌词汇表中的知识”,而字节级模型则更依赖于 Transformer 层本身的原始计算能力和容量来解读未压缩的字节流。
6.3 Training Dynamics and Efficiency
6.3 训练动态与效率
Training byte-level models presents different dynamics:
训练字节级模型呈现出不同的动态特征:
-
FLOPs: Historically, achieving comparable performance often required more pre-training FLOPs for byte-level models than for parameter-matched token models, primarily due to processing longer sequences.² However, newer architectures like BLT and SpaceByte explicitly aim for FLOP parity or improvement by efficiently managing sequences through patching.³
浮点运算量(FLOPs):从历史数据来看,要达到相当的性能,字节级模型通常比参数规模匹配的令牌级模型需要更多的预训练浮点运算量——这主要是因为字节级模型需处理更长的序列。² 然而,BLT 和 SpaceByte 等较新架构通过补丁技术高效管理序列,明确致力于实现浮点运算量相当或更优的目标。³ -
Training Speed: Consequently, training throughput measured in sequences per second is generally lower for byte models.⁵
训练速度:因此,以“每秒处理序列数”衡量的训练吞吐量,字节级模型通常更低。⁵ -
Convergence: Fine-tuning dynamics can vary. Byte models might require more fine-tuning steps on some tasks when batch size is held constant in terms of tokens.⁵ However, on tasks where byte-level information is crucial (like transliteration), they might converge faster.⁵ There’s also evidence suggesting superior fine-tunability on out-of-distribution data (new languages or domains) compared to tokenizers that are not attuned to the new data.¹
收敛性:微调动态可能存在差异。当以令牌数量为基准保持批次大小时,字节级模型在某些任务上可能需要更多微调步骤。⁵ 但在字节级信息至关重要的任务(如音译)中,它们可能收敛更快。⁵ 还有证据表明,相较于未针对新数据调整的令牌化器,字节级模型在分布外数据(新语言或新领域)上的微调适应性更优。¹ -
Data Efficiency: The observation that ByT5 reached competitive performance with mT5 despite being pre-trained on significantly less data (4x less reported) hints that byte-level models might be more data-efficient learners in some contexts.⁵
数据效率:有观察发现,尽管 ByT5 的预训练数据量远少于 mT5(报告显示少 4 倍),但其性能仍能与 mT5 持平——这一现象暗示,在某些场景下,字节级模型可能是数据效率更高的学习者。⁵
6.4 Inference Efficiency Considerations
6.4 推理效率考量
Inference speed is often a critical factor for deployment:
推理速度通常是部署时的关键因素:
-
Latency: Byte-level models, especially earlier ones like ByT5, often exhibit higher inference latency due to longer sequences and potentially deeper architectures.² MrT5 was specifically designed to address this by dynamically shortening sequences during inference.²
延迟:字节级模型(尤其是 ByT5 等早期模型)由于序列更长且架构可能更深,通常表现出更高的推理延迟。² MrT5 的设计初衷就是通过在推理过程中动态缩短序列来解决这一问题。² -
Patching Benefits: Recent patching-based models offer improved inference efficiency. BLT allows for a trade-off: increasing the average patch size saves compute (as the expensive latent transformer runs less often), which can be reallocated to a larger latent transformer model while maintaining a fixed inference FLOP budget.³ SpaceByte’s dynamic patching also contributes to efficiency.¹⁵
补丁技术的优势:近期基于补丁的模型在推理效率上有所提升。BLT 支持一种权衡机制:增加平均补丁大小可节省计算资源(因为计算成本高的潜在 Transformer 运行频率降低),这些节省的资源可重新分配给更大规模的潜在 Transformer 模型,同时保持推理浮点运算量预算不变。³ SpaceByte 的动态补丁技术也对效率提升有贡献。¹⁵
Overall, adopting byte-level processing forces a rethinking of transformer architecture design, prioritizing the efficient management of long sequences. Innovations like downsampling, merging, and dynamic patching are key enablers. The parameter savings from eliminating large vocabularies are strategically reinvested into model capacity, highlighting a shift from reliance on explicit vocabulary knowledge towards implicit processing power within the model architecture. While historical efficiency concerns were significant, recent advancements suggest that byte-level models are rapidly becoming more computationally viable at scale.
总体而言,采用字节级处理迫使研究者重新思考 Transformer 架构设计,将长序列的高效管理置于优先地位。下采样、合并和动态补丁等创新技术是关键推动因素。通过省去大型词汇表所节省的参数,被战略性地重新投入到模型容量中——这凸显了一种转变:从依赖“显式词汇知识”转向依赖“模型架构内的隐式处理能力”。尽管历史上的效率问题较为突出,但近期进展表明,字节级模型在大规模场景下的计算可行性正迅速提升。
7. Exemplar Byte-Level Transformer Models
7. 典型字节级 Transformer 模型
Several specific byte-level transformer models have been proposed, each with unique architectural features and contributions to the field. Examining these provides concrete examples of how the challenges of byte-level processing have been addressed.
目前已有多种特定的字节级 Transformer 模型被提出,每种模型都具有独特的架构特征,并为该领域做出了独特贡献。对这些模型进行分析,可为“字节级处理挑战如何被解决”提供具体案例。
7.1 ByT5
7.1 ByT5 模型
Concept: ByT5 was introduced as a direct byte-level, tokenizer-free counterpart to the multilingual token-based model mT5.² It operates directly on sequences of UTF-8 bytes, eliminating text preprocessing and subword tokenization.⁵
概念:ByT5 是作为多语言令牌级模型 mT5 的“直接字节级、无令牌化器”对应模型而提出的。² 它直接对 UTF-8 字节序列进行处理,省去了文本预处理和子词令牌化步骤。⁵
Architecture: It utilizes a standard Transformer encoder-decoder framework but incorporates several key modifications to handle byte sequences effectively ⁵:
架构:该模型采用标准 Transformer 编解码器框架,但为有效处理字节序列,纳入了多项关键修改 ⁵:
- A minimal vocabulary comprising the 256 UTF-8 byte values plus a few special tokens.
极小的词汇表,包含 256 个 UTF-8 字节值以及少量特殊令牌。 - A significantly “heavier” encoder relative to the decoder (3:1 depth ratio) to compensate for the parameter savings from the small vocabulary and provide more capacity for processing the raw byte input.
相对于解码器,编码器显著“更厚重”(深度比为 3:1)——这既是为了补偿因小词汇表节省的参数,也是为了提供更强的能力来处理原始字节输入。 - Adjusted hidden layer sizes (dmodeld_{model}dmodel) and feed-forward network dimensions (dffd_{ff}dff) compared to mT5 to maintain similar overall parameter counts.
与 mT5 相比,调整了隐藏层大小(dmodeld_{model}dmodel)和前馈网络维度(dffd_{ff}dff),以保持总体参数数量相近。 - During pre-training (using a span corruption objective similar to T5), it masks longer spans of bytes (mean length of 20 bytes) compared to the token spans masked in mT5.
在预训练阶段(采用与 T5 类似的跨度损坏目标函数),该模型对更长的字节跨度进行掩码(平均长度为 20 个字节),而 mT5 掩码的令牌跨度更短。
Key Findings/Performance: ByT5 demonstrated competitiveness with parameter-matched mT5 models across a range of tasks. It showed significant advantages in robustness to noise, performance on multilingual benchmarks (particularly XTREME in-language tasks), generative tasks (like XSum summarization and TweetQA), and tasks inherently sensitive to character or phonetic information (like Dakshina transliteration and Sigmorphon G2P/morphology).⁵ There were also indications of potentially better data efficiency.⁵ However, its primary drawback was computational cost, exhibiting significantly higher inference latency, especially on tasks with long sequences.²
关键发现/性能:在一系列任务中,ByT5 与参数规模匹配的 mT5 模型相比具有竞争力。它在以下方面展现出显著优势:对噪声的鲁棒性、多语言基准测试(尤其是 XTREME 语言内任务)性能、生成式任务(如 XSum 摘要和 TweetQA)性能,以及对字符或语音信息固有敏感的任务(如 Dakshina 音译和 Sigmorphon G2P/形态学任务)性能。⁵ 此外,有迹象表明其数据效率可能更优。⁵ 然而,其主要缺点是计算成本高,尤其在长序列任务中,推理延迟显著更高。²
7.2 CANINE (Character Architecture with No tokenization In Neural Encoders)
7.2 CANINE(神经编码器中无令牌化的字符架构)
Concept: CANINE is an efficient, tokenization-free encoder model designed to operate directly on character sequences (Unicode codepoints), though adaptable to bytes.⁹
概念:CANINE 是一种高效、无令牌化的编码器模型,设计用于直接处理字符序列(Unicode 码点),但也可适配字节序列。⁹
Architecture: Its architecture incorporates novel elements to manage character-level input efficiently ⁹:
架构:其架构纳入了新颖元素,以高效管理字符级输入 ⁹:
- Vocabulary-free character embedding using a hashing strategy, where multiple hash functions map each codepoint to combinations of embeddings, avoiding a huge lookup table for all Unicode characters.
采用哈希策略实现无词汇表字符嵌入:通过多个哈希函数将每个码点映射为嵌入向量的组合,从而避免为所有 Unicode 字符构建庞大的查找表。 - A downsampling mechanism early in the model: This typically involves a shallow local self-attention layer followed by strided convolutions to reduce the sequence length before feeding it into the main deep transformer stack.
模型早期的下采样机制:通常包括一个浅层局部自注意力层,随后是步长卷积——目的是在将序列输入主深度 Transformer 栈之前缩短序列长度。 - An optional upsampling layer to project the final representations back to the original sequence length if needed.
可选的上采样层:若任务需要,可将最终表示投影回原始序列长度。 - Pre-training uses Masked Language Modeling (MLM) and Next Sentence Prediction (NSP). The MLM objective could predict characters directly or, optionally, predict subword tokens corresponding to the masked character span, using subwords as a “soft inductive bias”.¹⁰
预训练采用掩码语言建模(MLM)和下一句预测(NSP)任务。MLM 目标函数可直接预测字符,或可选地预测与掩码字符跨度对应的子词令牌——将子词作为“软归纳偏置”。¹⁰
Key Findings/Performance: CANINE demonstrated strong performance, outperforming a comparable mBERT model on the multilingual TyDi QA benchmark while using approximately 28–30% fewer parameters.¹⁰ Its key contribution was showing that through techniques like hashing and downsampling, a character/byte-level encoder could achieve computational efficiency comparable to tokenized models despite the much finer input granularity.⁹
关键发现/性能:CANINE 表现出强劲性能——在多语言 TyDi QA 基准测试中,其性能优于参数规模相当的 mBERT 模型,同时参数数量减少了约 28%-30%。¹⁰ 其核心贡献在于证明:通过哈希和下采样等技术,尽管输入粒度精细得多,字符/字节级编码器仍能实现与令牌化模型相当的计算效率。⁹
7.3 Recent Innovations (Addressing Efficiency)
7.3 近期创新(针对效率问题)
Recognizing the efficiency limitations of earlier models like ByT5, recent research has focused on more sophisticated architectures:
鉴于 ByT5 等早期模型在效率上的局限性,近期研究聚焦于更复杂的架构:
Byte Latent Transformer (BLT):
字节潜在 Transformer(BLT):
- Concept: Aims to match or exceed the performance and scaling of tokenization-based LLMs while offering significant improvements in inference efficiency and robustness.³
概念:旨在匹配或超越基于令牌化的 LLM 的性能和缩放能力,同时大幅提升推理效率和鲁棒性。³ - Architecture: Features dynamic patching where byte sequences are segmented based on the entropy (predictability) of the next byte prediction.³ It uses a three-module structure: a lightweight local encoder (bytes-to-patches), an expensive latent transformer (operating on patches), and a lightweight local decoder (patches-to-bytes).³ It incorporates byte n-gram embeddings and cross-attention between the latent transformer and byte-level modules. Crucially, it has no fixed vocabulary for patches.³
架构:核心特征是动态补丁——根据下一个字节预测的熵(可预测性)对字节序列进行分割。³ 采用三模块结构:轻量级局部编码器(字节到补丁)、高计算成本的潜在 Transformer(处理补丁)、轻量级局部解码器(补丁到字节)。³ 整合了字节 n 元语法嵌入,以及潜在 Transformer 与字节级模块之间的交叉注意力机制。关键在于,其补丁没有固定词汇表。³ - Results: First model to demonstrate byte-level scaling matching tokenized models (like Llama 3) up to 8B parameters, achieving this with up to 50% fewer inference FLOPs.⁴ Shows better scaling properties for a fixed inference cost and improved robustness and character-level understanding.³
结果:首个实现“字节级缩放能力与令牌化模型(如 Llama 3)相当”的模型(参数规模达 80 亿),且推理浮点运算量减少高达 50%。⁴ 在固定推理成本下,其缩放特性更优,同时鲁棒性和字符级理解能力也有所提升。³
SpaceByte:
SpaceByte 模型:
- Concept: Designed to improve the performance of byte-level autoregressive models to match tokenized counterparts under fixed training compute budgets.¹⁵
概念:旨在在固定训练计算预算下,提升字节级自回归模型的性能,使其与令牌化模型相当。¹⁵ - Architecture: Employs multiscale modeling within a byte-level Transformer. It inserts larger “global” transformer blocks within the standard layers. These global blocks are applied dynamically only after specific “spacelike” bytes (most commonly the space character), effectively aligning the processing of higher-level information with word boundaries.¹⁵
架构:在字节级 Transformer 中采用多尺度建模。在标准层中插入较大的“全局”Transformer 块,这些全局块仅在特定“类空格”字节(最常见的是空格字符)之后动态应用——从而使高层信息处理与单词边界有效对齐。¹⁵ - Results: In compute-controlled experiments, SpaceByte significantly outperformed standard byte-level Transformers and the MegaByte architecture. It achieved performance roughly matching or exceeding a subword Transformer (using SentencePiece) on datasets including English text, arXiv papers, and code.¹⁵ The dynamic, boundary-aware patching was shown to be critical to its success.¹⁵
结果:在计算控制实验中,SpaceByte 的性能显著优于标准字节级 Transformer 和 MegaByte 架构。在英语文本、arXiv 论文和代码等数据集上,其性能与基于子词的 Transformer(使用 SentencePiece)大致相当,甚至更优。¹⁵ 研究表明,动态、边界感知的补丁机制是其成功的关键。¹⁵
MrT5 (MergeT5):
MrT5(MergeT5)模型:
- Concept: An efficiency-focused variant of ByT5 designed to reduce its high inference cost by dynamically shortening sequences.²
概念:ByT5 的效率优化变体,旨在通过动态缩短序列来降低其高昂的推理成本。² - Architecture: Integrates a learned token deletion/merging gate at a fixed, early encoder layer. This gate uses context from the initial layers to decide which byte tokens are less critical and can be removed. Deletion is soft during training (masking) and hard during inference (actual removal).²
架构:在编码器的固定早期层中整合了习得的令牌删除/合并门控。该门控利用初始层的上下文,判断哪些字节令牌重要性较低可被删除。训练阶段采用软删除(掩码),推理阶段采用硬删除(实际移除)。² - Results: Achieved significant reductions in inference runtime (up to ~45%) and sequence length (up to 75–80%) compared to ByT5, while maintaining comparable performance on downstream tasks like XNLI and TyDi QA, and preserving character-level task accuracy.²
2 It represents a practical approach to mitigating ByT5’s main limitation.
结果:与 ByT5 相比,在推理运行时间上实现了显著的降低(最高可达约 45%),在序列长度上也实现了显著的降低(最高可达 75%–80%),同时在诸如 XNLI 和 TyDi QA 等下游任务上保持了相当的性能,并且保留了字符级任务的准确性。²
2 它为缓解 ByT5 的主要局限性提供了一种切实可行的方法。
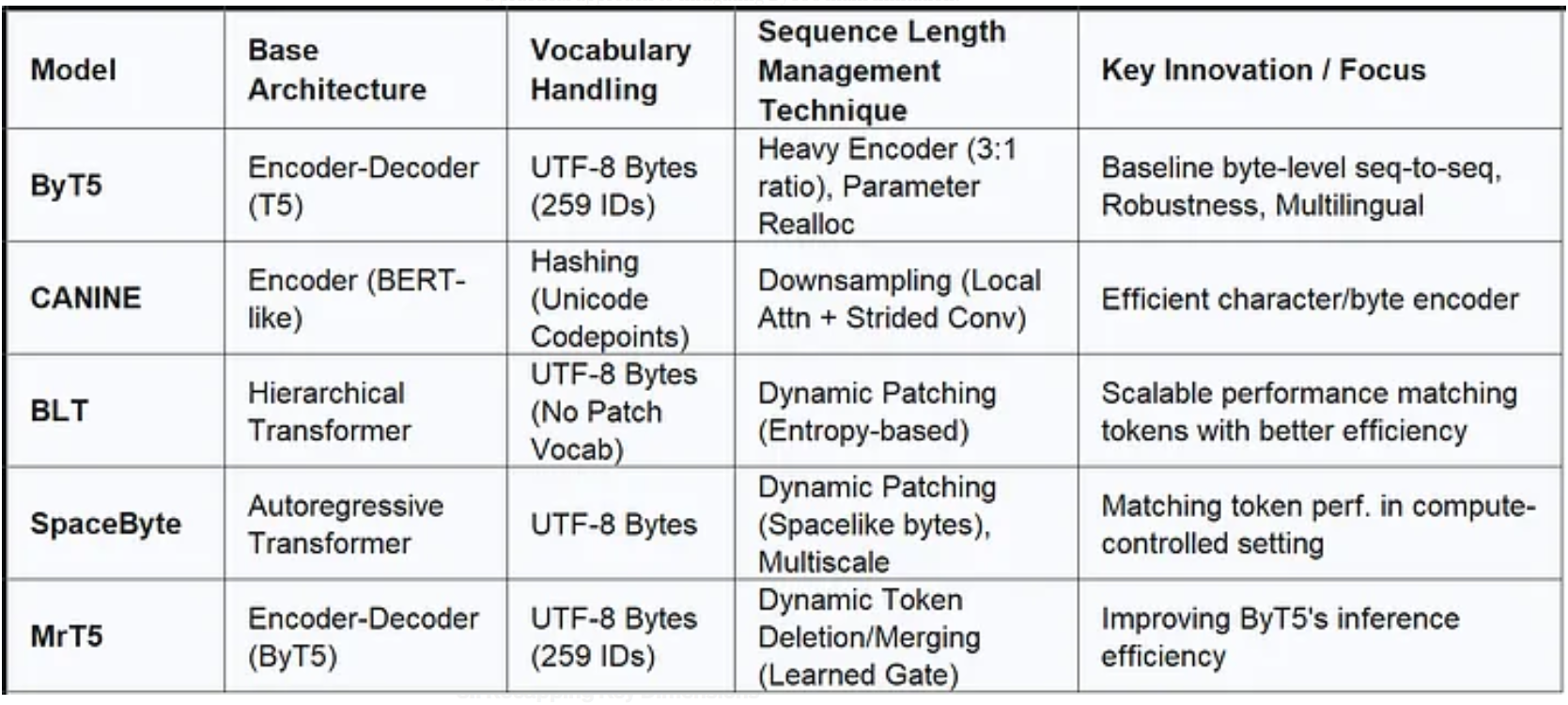
Table 2: Architectural Features of Key Byte-Level Models
表 2:主要字节级模型的架构特征
The progression from ByT5 and CANINE to the more recent models clearly illustrates the field’s focus. Having established the feasibility and benefits (like robustness and universality) of byte-level processing, the primary engineering challenge became overcoming the efficiency bottleneck. Advanced techniques like dynamic patching (BLT, SpaceByte) and merging (MrT5) represent sophisticated solutions that aim to retain the core advantages of operating on bytes while achieving computational costs that are competitive with, or even superior to, traditional token-based approaches. This evolution suggests a convergence towards practical and scalable byte-level architectures.
从 ByT5、CANINE 到近期模型的发展历程,清晰体现了该领域的研究重点。在证实字节级处理的可行性与优势(如鲁棒性和通用性)后,核心工程挑战转变为突破效率瓶颈。动态补丁(BLT、SpaceByte)和合并(MrT5)等先进技术,是极具创新性的解决方案:它们既致力于保留字节级处理的核心优势,又能将计算成本控制在与传统基于令牌(token)的方法相当甚至更优的水平。这一发展趋势表明,领域正朝着实用化、可扩展的字节级架构方向趋同。
8. Synthesizing the Trade-offs
8. 权衡取舍的综合分析
Choosing between byte-level and token-level transformers involves navigating a complex set of trade-offs related to vocabulary management, robustness, computational resources, and task suitability. Recent advancements have shifted the balance, making byte-level approaches increasingly viable alternatives.
在字节级 Transformer 与令牌级 Transformer 之间做选择时,需权衡一系列复杂因素,包括词汇表管理、鲁棒性、计算资源及任务适配性。近年来的技术进展已打破原有平衡,使字节级方法成为愈发可行的替代方案。
8.1 Recapping Key Dimensions
8.1 核心维度回顾
The fundamental differences and associated trade-offs can be summarized across several key dimensions:
二者的根本差异及相关权衡取舍,可从以下几个核心维度进行总结:
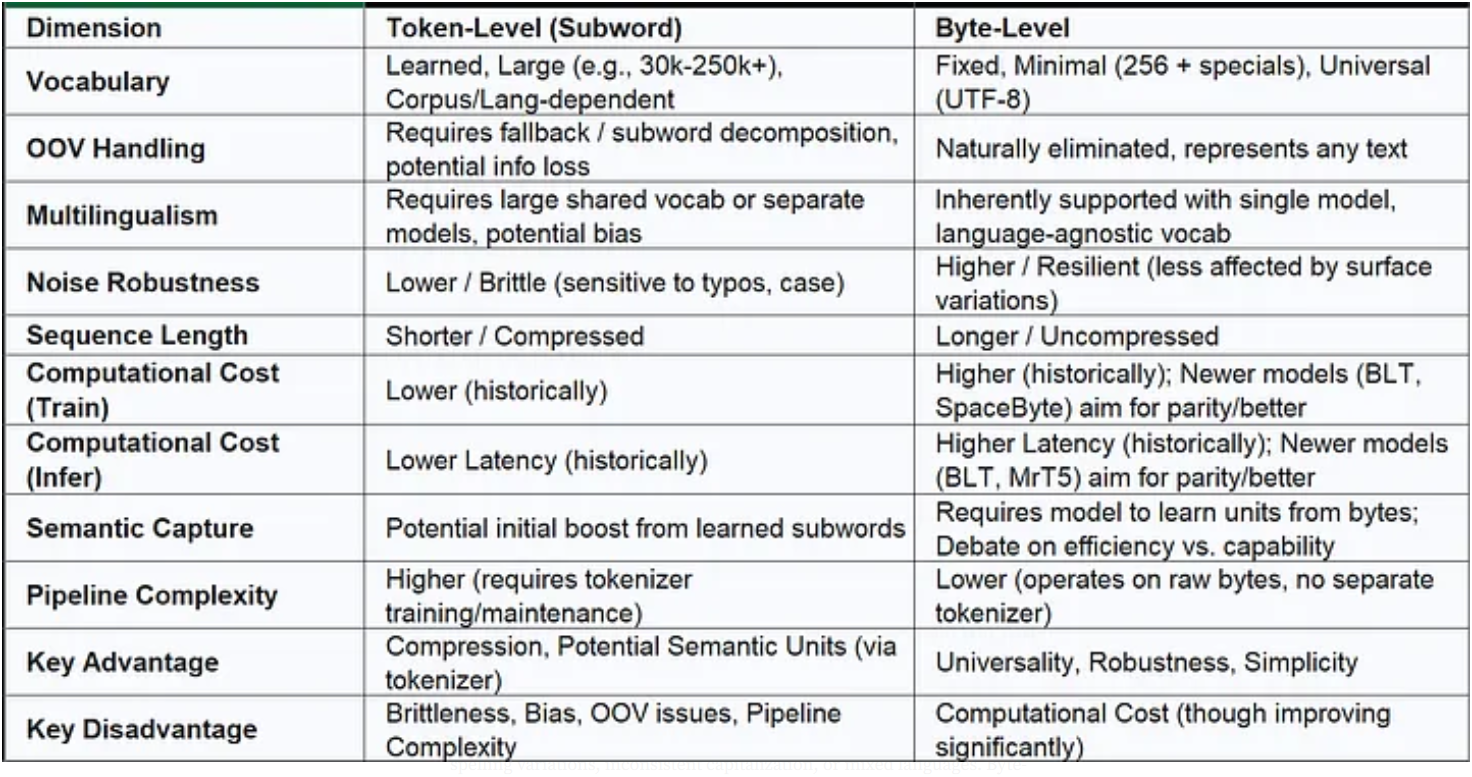
Table 3: Comparative Overview: Byte-Level vs. Token-Level Transformers
表 3:字节级 Transformer 与令牌级 Transformer 的对比概述
This table highlights the core tension: tokenizers provide compression and potentially useful semantic groupings upfront but introduce fragility and complexity. Byte-level processing offers universality and robustness by working with raw data but historically demanded higher computational resources — a disadvantage that recent architectural innovations are actively diminishing.
该表凸显了核心矛盾:令牌器(tokenizer)虽能预先实现序列压缩并提供潜在有用的语义分组,却会导致模型脆弱性增加且流程复杂度上升;而字节级处理通过直接操作原始数据,具备通用性与鲁棒性,但在过去往往需要更多计算资源——不过这一劣势正通过近期的架构创新不断缓解。
8.2 Scenarios Favoring Byte-Level Transformers
8.2 适合字节级 Transformer 的场景
Based on their inherent strengths, byte-level models are particularly advantageous in several scenarios:
凭借自身固有优势,字节级模型在以下几种场景中表现尤为突出:
-
Highly Multilingual Applications: When a single model must handle numerous languages, especially low-resource languages where good tokenizers are unavailable or perform poorly. The universal byte vocabulary eliminates the need for massive, potentially biased multilingual tokenizers.5
高度多语言应用场景:当单个模型需处理多种语言(尤其是低资源语言)时——低资源语言往往缺乏优质令牌器,或现有令牌器性能较差。而通用的字节词汇表无需依赖庞大且可能存在偏见的多语言令牌器。5 -
Noisy or Informal Text: For processing text from sources like social media, user comments, or historical archives that contain frequent typos, spelling variations, inconsistent capitalization, or mixed languages. Byte-level models’ resilience to such noise is a major benefit.1
含噪声或非规范文本场景:适用于处理社交媒体、用户评论、历史档案等来源的文本——这类文本常包含拼写错误、拼写变体、大小写不一致或语言混杂问题。字节级模型对这类噪声的抗干扰能力是其核心优势之一。1 -
Character/Phonetic Sensitive Tasks: Applications requiring direct manipulation or understanding of character sequences, such as transliteration, grapheme-to-phoneme conversion, detailed morphological analysis, or robust spelling correction, strongly favor byte-level representations.3
字符/语音敏感任务场景:需直接处理或理解字符序列的应用(如音译、字形-语音转换、精细形态分析、高鲁棒性拼写纠错等),更倾向于采用字节级表示。3 -
Simplified Deployment/Reduced Technical Debt: In systems where minimizing preprocessing complexity, avoiding tokenizer versioning conflicts, and ensuring consistent handling of any input string are priorities.5
简化部署/降低技术债务场景:在以最小化预处理复杂度、避免令牌器版本冲突、确保所有输入字符串得到一致处理为优先目标的系统中,字节级模型优势显著。5 -
Emerging Domains or Languages: When applying models to new domains (e.g., specialized scientific fields, new codebases) or languages where suitable tokenizers have not been developed or are difficult to train effectively.1
新兴领域或语言场景:当模型需应用于新领域(如专业科学领域、新代码库)或新语言时——这些场景下,适配的令牌器尚未开发完成,或难以有效训练。1 -
Code Processing: The ability to handle any character sequence and potentially better robustness to syntactic variations might make byte-level models suitable for code generation and analysis, as suggested by strong results from SpaceByte on code datasets and improvements noted on fill-in-the-middle (FIM) tasks.15
代码处理场景:字节级模型能够处理任意字符序列,且对语法变体可能具备更强的鲁棒性,这使其适用于代码生成与分析任务。SpaceByte 在代码数据集上的优异表现,以及在中间填充(FIM)任务中体现的性能提升,均印证了这一点。15
8.3 Scenarios Favoring Token-Based Transformers
8.3 适合基于令牌的 Transformer 的场景
Despite the advances in byte-level models, token-based approaches might still be preferred in specific situations:
尽管字节级模型已取得显著进展,但在特定场景下,基于令牌的方法仍可能是更优选择:
-
High-Resource Monolingual Tasks with Stringent Efficiency Needs: In scenarios involving well-resourced languages like English, where high-quality tokenizers are readily available and minimizing latency or computational cost remains the absolute top priority. However, the efficiency gains of recent byte-level models like BLT challenge this assumption, requiring careful benchmarking for specific use cases.5
高资源单语言且对效率要求严苛的任务场景:适用于英语等资源丰富的语言场景——这类场景下,高质量令牌器易于获取,且最小化延迟或计算成本是首要目标。不过,BLT 等近期字节级模型在效率上的提升已对这一传统认知构成挑战,因此需针对具体用例进行细致的基准测试。5 -
Integration with Legacy Systems: When interoperability with existing infrastructure heavily relies on specific tokenization schemes and outputs.
遗留系统集成场景:当与现有基础设施的互操作性高度依赖特定令牌化方案及输出结果时,基于令牌的方法更具优势。 -
Resource-Constrained Environments (Historically): In edge devices or environments where the higher memory footprint associated with processing longer byte sequences was historically prohibitive. Patching and merging techniques may alleviate this constraint significantly.
资源受限环境场景(传统上):在边缘设备或资源受限环境中,处理较长字节序列所需的更大内存开销,在过去曾是字节级模型的主要障碍。不过,补丁(patching)与合并(merging)技术已能显著缓解这一限制。 -
Interpretability Focused on Tokens: If analysis requires understanding model behavior specifically in terms of learned subword units.
聚焦令牌可解释性的场景:若需从已学习的子词单元角度分析并理解模型行为,基于令牌的方法更适用。
The decision calculus is shifting. As the primary historical disadvantage of byte-level models — computational cost — is progressively mitigated by architectural innovation, their fundamental advantages in universality, robustness, and simplicity become increasingly compelling. The choice is less frequently about whether byte-level models can perform a task effectively, and more about whether the specific performance, efficiency, and complexity trade-offs align with the application’s requirements compared to the known limitations and potential biases of tokenizers.
决策考量的重心正不断变化。随着字节级模型的主要历史劣势——计算成本——通过架构创新逐步得到缓解,其在通用性、鲁棒性和简洁性方面的固有优势愈发凸显。如今,选择的核心已不再是“字节级模型能否有效完成任务”,而是对比“字节级模型在性能、效率、复杂度上的具体权衡”与“令牌器的已知局限性及潜在偏见”,判断哪一方更符合应用需求。
9. Conclusion and Future Directions
9. 结论与未来方向
The journey from traditional token-based transformers to the exploration and refinement of byte-level architectures represents a significant evolution in natural language processing. This analysis has highlighted the fundamental dichotomy: tokenizers provide essential sequence compression and potentially useful semantic shortcuts but introduce brittleness, language biases, and pipeline complexity.1 Byte-level models, conversely, offer inherent universality and robustness by operating directly on raw UTF-8 data, capable of processing any text in any language without OOV (out-of-vocabulary) issues or sensitivity to minor surface variations.5 However, this comes at the cost of significantly longer sequences, historically leading to prohibitive computational demands.2
从传统基于令牌的 Transformer,到探索并优化字节级架构,这一历程标志着自然语言处理领域的重大演进。本文分析凸显了二者的根本对立:令牌器虽能实现关键的序列压缩,并提供潜在有用的语义“捷径”,却会导致模型脆弱性、语言偏见及流程复杂度增加;1 相反,字节级模型通过直接操作原始 UTF-8 数据,具备与生俱来的通用性与鲁棒性,能够处理任意语言的任意文本,且无未登录词(OOV)问题,对文本表面的细微变体也不敏感;5 但代价是序列长度显著增加,这在过去导致其计算需求过高,难以实际应用。2
Performance comparisons reveal a nuanced picture. While large token-based models may have held an edge on some high-resource English benchmarks 5, byte-level models consistently demonstrate strengths in multilingual settings, processing noisy text, handling character-sensitive tasks, and often in generative capabilities.5
性能对比呈现出复杂的局面:尽管大型基于令牌的模型在部分高资源英语基准测试中可能仍占优势,5 但字节级模型在多语言场景、噪声文本处理、字符敏感任务中始终表现突出,且在生成能力上也常具优势。5
Crucially, the narrative is rapidly changing due to architectural innovation. Models like CANINE, ByT5, MrT5, SpaceByte, and BLT showcase increasingly sophisticated techniques — including downsampling, parameter reallocation, token merging, and dynamic patching — specifically designed to tackle the efficiency bottleneck of byte-level processing.2 Recent results suggest these efforts are bearing fruit, with models like BLT and SpaceByte achieving performance comparable or superior to strong token-based baselines, often with improved computational efficiency.3 This progress fuels the notion of a potential “token-free future” for language models.6
关键在于,架构创新正迅速改变这一格局。CANINE、ByT5、MrT5、SpaceByte、BLT 等模型展现了日益复杂的技术——包括下采样、参数重分配、令牌合并、动态补丁等——这些技术均专为解决字节级处理的效率瓶颈而设计。2 近期研究结果表明,这些努力已初见成效:BLT、SpaceByte 等模型的性能已达到或超越优秀的基于令牌的基准模型,且往往具备更优的计算效率。3 这一进展进一步支撑了“语言模型可能迎来无令牌未来”的观点。6
In conclusion, the choice between byte-level and token-level input representation is a critical design decision contingent on the specific application’s requirements regarding multilingualism, robustness, computational budget, and tolerance for pipeline complexity. While tokenizers enabled the initial scaling of transformers, the limitations they impose are significant. The demonstrated advantages of byte-level processing, coupled with accelerating progress in mitigating its computational costs, position it as a powerful and increasingly practical alternative poised for wider adoption. This shift promises simpler, more robust, and potentially more equitable language processing systems capable of handling the full diversity of text encountered in the real world.
综上,字节级与令牌级输入表示的选择,是一项关键设计决策,其取决于应用在多语言支持、鲁棒性、计算预算、流程复杂度容忍度等方面的具体需求。尽管令牌器推动了 Transformer 的早期规模化发展,但其局限性也十分显著。字节级处理的已证实优势,加之缓解其计算成本的技术进展不断加速,使其成为一种强大且日益实用的替代方案,有望得到更广泛的应用。这一转变预示着,未来将出现更简洁、更鲁棒、且可能更公平的语言处理系统,能够应对现实世界中文本的全部多样性。
Several avenues for future research remain open:
未来研究仍可围绕以下几个方向展开:
-
Continued Efficiency Optimization: Further refining architectural techniques (patching, merging, attention mechanisms) to minimize the training and inference costs of byte-level models.
持续的效率优化:进一步完善架构技术(补丁、合并、注意力机制等),以最小化字节级模型的训练与推理成本。 -
Understanding Semantic Learning: Investigating more deeply how byte-level models construct high-level semantic understanding from raw bytes and whether this process can be made more explicit or efficient, potentially addressing concerns about slower learning of semantics compared to token models.41
语义学习机制的理解:深入研究字节级模型如何从原始字节中构建高层语义理解,以及能否使这一过程更透明或更高效——这可能有助于解决“字节级模型语义学习速度慢于令牌模型”的担忧。41 -
Optimal Patching/Merging Strategies: Exploring alternative criteria beyond entropy or simple boundaries (e.g., syntactic cues, learned segmenters) for dynamic sequence length management.
优化的补丁/合并策略:探索熵值或简单边界之外的其他标准(如语法线索、习得的分段器),用于动态序列长度管理。 -
Hybrid Models: Investigating architectures that explicitly combine byte/character-level processing with higher-level word or subword representations in a hierarchical manner.1
混合模型研究:探索以分层方式将字节/字符级处理与更高层的词或子词表示明确结合的架构。1 -
Scaling Behavior: Characterizing the performance and training dynamics of state-of-the-art byte-level architectures at extremely large scales (e.g., >100 billion parameters).
规模化行为分析:刻画最先进字节级架构在超大规模(如参数数量 > 1000 亿)下的性能与训练动态。 -
Evaluation Metrics: Developing evaluation methodologies that better capture the nuances and robustness advantages offered by byte-level models, which might be missed by standard token-based metrics.
评估指标构建:开发更能捕捉字节级模型细微优势与鲁棒性优势的评估方法——这些优势可能无法通过标准的基于令牌的评估指标体现。
Works cited
参考文献
- Hierarchical Autoregressive Transformers: Combining Byte- and Word-Level Processing for Robust, Adaptable Language Models — arXiv, accessed April 17, 2025, https://arxiv.org/html/2501.10322v2
- openreview.net, accessed April 17, 2025, https://openreview.net/pdf?id=VYWBMq1L7H
- Byte Latent Transformer: Patches Scale Better Than Tokens — arXiv, accessed April 17, 2025, https://arxiv.org/html/2412.09871v1
- Meta AI Introduces Byte Latent Transformer (BLT): A Tokenizer-Free Model — Reddit, accessed April 17, 2025, https://www.reddit.com/r/LocalLLaMA/comments/1heqv6s/meta_ai_introduces_byte_latent_transformer_blt_a/
- [2105.13626] ByT5: Towards a Token-Free Future with Pre-trained …, accessed April 17, 2025, https://ar5iv.labs.arxiv.org/html/2105.13626
- google-research/byt5 — GitHub, accessed April 17, 2025, https://github.com/google-research/byt5
- [2105.13626] ByT5: Towards a token-free future with pre-trained byte-to-byte models — arXiv, accessed April 17, 2025, https://arxiv.org/abs/2105.13626
- [2105.13626] ByT5: Towards a token-free future with pre-trained byte-to-byte models : r/MachineLearning — Reddit, accessed April 17, 2025, https://www.reddit.com/r/MachineLearning/comments/np3ysr/210513626_byt5_towards_a_tokenfree_future_with/
- Canine: Pre-training an Efficient Tokenization-Free Encoder for Language Representation, accessed April 17, 2025, https://direct.mit.edu/tacl/article/doi/10.1162/tacl_a_00448/109284/Canine-Pre-training-an-Efficient-Tokenization-Free
- arxiv.org, accessed April 17, 2025, https://arxiv.org/abs/2103.06874
- arXiv:2103.06874v4 [cs.CL] 18 May 2022, accessed April 17, 2025, https://arxiv.org/pdf/2103.06874
- google/canine-s at ca188d7 — Correct pre-training data — Hugging Face, accessed April 17, 2025, https://huggingface.co/google/canine-s/commit/ca188d781f6b8cac23c173df37134ca9de41b0b8
- Update model card · google/canine-s at 7886a04 — Hugging Face, accessed April 17, 2025, https://huggingface.co/google/canine-s/commit/7886a04fd5520e57cbd529a4faa9bd8667b22880
- Semantic Tokenizer for Enhanced Natural Language Processing — Hacker News, accessed April 17, 2025, https://news.ycombinator.com/item?id=35729586
- SpaceByte: Towards Deleting Tokenization from Large Language Modeling — arXiv, accessed April 17, 2025, https://arxiv.org/html/2404.14408v1
- accessed December 31, 1969, https://arxiv.org/pdf/2412.09871
- Slagle — 2024 — SpaceByte: Towards Deleting Tokenization … — arXiv, accessed April 17, 2025, https://arxiv.org/pdf/2404.14408
- From Characters to Words: Hierarchical Pre-trained Language Model for Open-vocabulary Language Understanding — ACL Anthology, accessed April 17, 2025, https://aclanthology.org/2023.acl-long.200.pdf
- Natural Language Processing • Tokenizer — aman.ai, accessed April 17, 2025, https://aman.ai/primers/ai/tokenizer/
- What are the differences between BPE and byte-level BPE? — Data Science Stack Exchange, accessed April 17, 2025, https://datascience.stackexchange.com/questions/126715/what-are-the-differences-between-bpe-and-byte-level-bpe
- What is Tokenization in NLP? Here’s All You Need To Know — Analytics Vidhya, accessed April 17, 2025, https://www.analyticsvidhya.com/blog/2020/05/what-is-tokenization-nlp/
- [D] SentencePiece, WordPiece, BPE… Which tokenizer is the best one? : r/MachineLearning, accessed April 17, 2025, https://www.reddit.com/r/MachineLearning/comments/rprmq3/d_sentencepiece_wordpiece_bpe_which_tokenizer_is/
- Summary of the tokenizers — Hugging Face, accessed April 17, 2025, https://huggingface.co/docs/transformers/tokenizer_summary
- BPE vs WordPiece Tokenization — when to use / which? — Data Science Stack Exchange, accessed April 17, 2025, https://datascience.stackexchange.com/questions/75304/bpe-vs-wordpiece-tokenization-when-to-use-which
- Quicktake: BPE, WordPiece, and SentencePiece — Yu.Z, accessed April 17, 2025, https://yuzhu.run/tokenizers/
- Training Multilingual Pre-trained Language Models with Byte-Level Subwords — ar5iv — arXiv, accessed April 17, 2025, https://ar5iv.labs.arxiv.org/html/2101.09469
- Difficulty in understanding the tokenizer used in Roberta model — Stack Overflow, accessed April 17, 2025, https://stackoverflow.com/questions/61134275/difficulty-in-understanding-the-tokenizer-used-in-roberta-model
- [D] Why are Byte Pair Encoding tokenizers preferred over character level ones in LLMs?, accessed April 17, 2025, https://www.reddit.com/r/MachineLearning/comments/1ax6xuh/d_why_are_byte_pair_encoding_tokenizers_preferred/
- arXiv:2210.07111v1 [cs.CL] 13 Oct 2022, accessed April 17, 2025, https://arxiv.org/pdf/2210.07111
- Byte Latent Transformer: Meta’s Dynamic Patching Innovation in NLP — Ajith’s AI Pulse, accessed April 17, 2025, https://ajithp.com/2024/12/15/metas-byte-latent-transformer-revolutionizing-natural-language-processing-with-dynamic-patching/
- Daily Papers — Hugging Face, accessed April 17, 2025, https://huggingface.co/papers?q=byte-level
- The Technical User’s Introduction to LLM Tokenization — Christopher Samiullah, accessed April 17, 2025, https://christophergs.com/blog/understanding-llm-tokenization
- Tokenization and Morphology in Multilingual Language Models: A~Comparative Analysis of mT5 and ByT5 — ResearchGate, accessed April 17, 2025, https://www.researchgate.net/publication/384938684_Tokenization_and_Morphology_in_Multilingual_Language_Models_AComparative_Analysis_of_mT5_and_ByT5
- Google AI Introduces ByT5: Pre-Trained Byte-to-Byte Models for NLP Tasks — MarkTechPost, accessed April 17, 2025, https://www.marktechpost.com/2021/06/08/google-ai-introduces-byt5-pre-trained-byte-to-byte-models-for-nlp-tasks/
- arXiv:2405.13350v2 [cs.CL] 30 May 2024, accessed April 17, 2025, https://arxiv.org/pdf/2405.13350
- Efficacy of ByT5 in Multilingual Translation of Biblical Texts for Underrepresented Languages — arXiv, accessed April 17, 2025, https://arxiv.org/html/2405.13350v2
- arxiv.org, accessed April 17, 2025, https://arxiv.org/abs/2302.14220
- Byte Latent Transformer: Patches Scale Better Than Tokens | Research — AI at Meta, accessed April 17, 2025, https://ai.meta.com/research/publications/byte-latent-transformer-patches-scale-better-than-tokens/
- Revolutionizing Language Models: The Byte Latent Transformer (BLT) — Datafloq, accessed April 17, 2025, https://datafloq.com/read/revolutionizing-language-models-byte-latent-transformer-blt/
- [D] How do byte-level language models work? : r/MachineLearning — Reddit, accessed April 17, 2025, https://www.reddit.com/r/MachineLearning/comments/175ns6h/d_how_do_bytelevel_language_models_work/
- An Analysis of Tokenization: Transformers under Markov Data — NIPS papers, accessed April 17, 2025, https://proceedings.neurips.cc/paper_files/paper/2024/file/724afcaae4ae92a9220a077ffe80088d-Paper-Conference.pdf
- [2412.09871] Byte Latent Transformer: Patches Scale Better Than Tokens — arXiv, accessed April 17, 2025, https://arxiv.org/abs/2412.09871
- (PDF) Byte Latent Transformer: Patches Scale Better Than Tokens — ResearchGate, accessed April 17, 2025, https://www.researchgate.net/publication/387078383_Byte_Latent_Transformer_Patches_Scale_Better_Than_Tokens
- Better & Faster Large Language Models via Multi-token Prediction — arXiv, accessed April 17, 2025, https://arxiv.org/pdf/2404.19737
- Byte Latent Transformer: Patches Scale Better Than Tokens | Hacker News, accessed April 17, 2025, https://news.ycombinator.com/item?id=42415122
Written by Greg Robison
via:
- A Comparative Analysis of Byte-Level and Token-Level Transformer Models in Natural Language Processing
https://gregrobison.medium.com/a-comparative-analysis-of-byte-level-and-token-level-transformer-models-in-natural-language-9fb4331b6acc