Ovis多模态大模型
依赖库安装
- 根据仓库的requriment.txt 安装
- pip uninstall -y ninja && pip install ninja
- 确保 echo $? 返回0
- MAX_JOBS=4 pip install flash-attn --no-build-isolation --no-binary :all: -v --use-pep517
模型架构
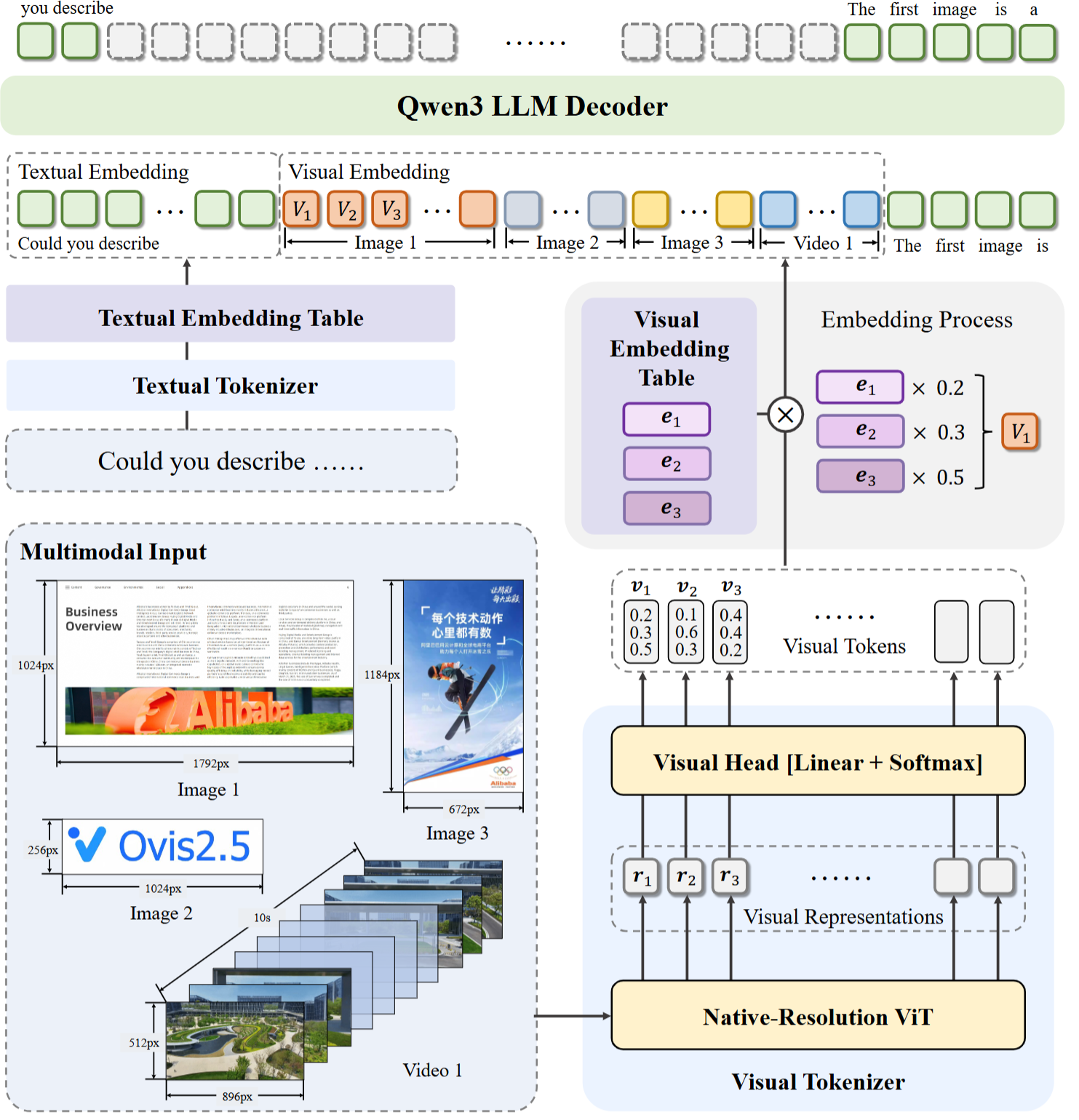
模型的核心架构创新在于加了一个VTE模块,通过结构化嵌入对齐,实现了视觉与语言模态的深度融合,其最显著的特色在于引入了原生分辨率视觉编码器和可切换的“思考模式”。
以一张1792x1024的图像为例:
- 图片经过vit的patch变成(1792/16)x (1024/16) ,然后再拉平变成7168x4096(假设是4086),这个向量代表着有7168个图像块,每个token用4096维描述。
- 每个图像块进过Linear生成一个“视觉词汇概率清单”,可以理解为为每个图像块贴上清单,最终变成 7168 1000,再通过softmax变成概率分布,类似“这个分块30%是直线,20%像红色”实现细粒度分布建模。(1000 个概率值,总和 = 1,每一个值代表一个视觉词汇概率)
- 假设视觉嵌入表是[1000 4096] (1000个视觉词汇,每个对应4096维度,与文本嵌入一致),使用如下伪代码计算
# 初始化一个4096维的"空向量"
final_embedding = [0, 0, ..., 0] # 共4096个0# 遍历1000个视觉词汇,按概率"混合"它们的嵌入向量
for i in 0 to 999:# 取出第i个视觉词汇的嵌入向量(4096维)word_emb = visual_embedding_table[i] #4096# 按概率P_i给这个向量"加权"(概率越高,贡献越大)weighted_emb = word_emb × P_i(标量)# 累加到最终向量中final_embedding = final_embedding + weighted_emb
重复计算最终得到了,最终得到<font style="color:rgb(0, 0, 0);">[7168, 4096]</font>的视觉嵌入向量,每个嵌入向量都融合了该分块对应的所有视觉词汇信息(按概率加权)
- VET(视觉嵌入表)需要训练
# 训练循环(每次输入一对"图像-文本"样本)
for (image, text) in 训练数据: # 步骤1:计算图像的视觉嵌入(通过ViT→VT→VET流程) visual_emb = image_to_visual_embedding(image) # [N, 4096],N为分块数 # 步骤2:计算文本的嵌入(通过LLM的文本Tokenizer) text_emb = text_to_text_embedding(text) # [M, 4096],M为文本token数 # 步骤3:计算跨模态损失(核心监督信号) loss = 0 # (a)对比损失:让匹配的图像-文本嵌入更接近,不匹配的更疏远loss += contrastive_loss(visual_emb, text_emb)# (b)生成损失:用视觉嵌入作为条件,监督LLM生成对应文本generated_text = llm.generate(visual_emb) loss += generation_loss(generated_text, text)# 步骤4:反向传播更新参数(包括VET)update_parameters(loss)# 调整VET的[1000, 4096]矩阵值
训练代码输出的保存路径解释
好的,您展示的这个目录结构非常典型,它是一个使用了 DeepSpeed ZeRO 优化的 Hugging Face Trainer 训练检查点(Checkpoint)。
这个目录不仅仅包含最终可供推理的模型,还包含了恢复训练所需的所有状态。这就是为什么文件看起来比预期的要多。
我们来逐一解析这些文件的作用,并将它们分为几类:
1. 模型核心文件 (Model Core)
这些是模型本身的权重和配置,是进行推理所必需的。
model-00001-of-00004.safetensors** 到 **model-00004-of-00004.safetensors:- 作用: 这是模型的核心权重文件。
.safetensors是一种更安全、更快速的权重存储格式,正逐渐取代传统的.bin文件。 - 为什么是4个文件: 因为您的模型较大,在保存时被分片 (Sharded) 成了4个部分。这有助于在内存有限的环境中加载和保存模型。
- 作用: 这是模型的核心权重文件。
model.safetensors.index.json:- 作用: 这是模型权重分片的索引文件。它是一个JSON映射,告诉Hugging Face的加载代码,模型的哪一部分(比如
llm.layers.10.attention.wq.weight)存储在哪一个.safetensors文件中。加载模型时,库会读取这个文件来正确地组合所有分片。
- 作用: 这是模型权重分片的索引文件。它是一个JSON映射,告诉Hugging Face的加载代码,模型的哪一部分(比如
config.json:- 作用: 模型架构的配置文件。它定义了模型的结构,例如隐藏层大小、层数、注意力头数等。加载模型时,会首先根据这个文件构建模型骨架,然后再填入权重。
2. 分词器与预处理器文件 (Tokenizer & Preprocessor)
这些文件定义了如何处理输入模型的文本和图像数据。
tokenizer.json:- 作用: “Fast” Tokenizer的核心文件,包含了词汇表、合并规则和所有分词逻辑,速度快且是自包含的。
tokenizer_config.json:- 作用: Tokenizer的配置文件,指定了特殊词元(如
[CLS],[SEP])的名称、模型最大长度等元数据。
- 作用: Tokenizer的配置文件,指定了特殊词元(如
vocab.json,merges.txt:- 作用: 这是传统BPE(Byte-Pair Encoding)分词器的词汇表和合并规则文件。即使有了
tokenizer.json,它们也常常被保留以兼容旧版加载逻辑。
- 作用: 这是传统BPE(Byte-Pair Encoding)分词器的词汇表和合并规则文件。即使有了
special_tokens_map.json:- 作用: 明确定义了特殊词元(如
unk_token,pad_token)与它们在词汇表中对应的字符串。
- 作用: 明确定义了特殊词元(如
added_tokens.json:- 作用: 如果您在训练中向分词器添加了新的、自定义的词元,它们会被记录在这里。
preprocessor_config.json:- 作用: 对于像Ovis这样的多模态模型,这个文件保存了图像预处理器(Image Processor)的配置,例如图像缩放尺寸、归一化所用的均值和标准差等。
3. 训练状态与检查点文件 (Training State & Checkpoint)
这些是为了能够中断后恢复训练而保存的文件,对于纯粹的推理来说是不必要的。
trainer_state.json:- 作用: 由
Trainer保存的训练状态。记录了当前的训练进度,比如当前的全局步数(global step)、所在的周期(epoch)、最佳模型的得分以及训练过程中的日志历史等。trainer.train(resume_from_checkpoint=True)就是靠它来恢复训练进度的。
- 作用: 由
training_args.bin:- 作用: 序列化后的
TrainingArguments对象。保存了所有的训练参数,如学习率、批大小、优化器类型等。
- 作用: 序列化后的
scheduler.pt:- 作用: 学习率调度器(Learning Rate Scheduler)的状态。保存它能确保在恢复训练时,学习率能按照预定的策略继续下降,而不是重新开始。
rng_state_0.pth,rng_state_1.pth:- 作用: 保存了每个GPU(进程)上的随机数生成器(Random Number Generator)的状态。这对于保证训练的可复现性至关重要。恢复训练时,随机数状态也会被恢复,使得数据加载、dropout等随机过程和中断前完全一致。
4. DeepSpeed ZeRO 优化器状态文件
这些文件是DeepSpeed特有的,用于保存分布式训练下的优化器状态。
global_step1413/** 目录**:- 作用: 这是DeepSpeed保存其自身状态的地方。目录名通常对应全局步数。
bf16_zero_pp_rank_0_mp_rank_00_optim_states.pt和..._rank_1_...: 这些是核心的DeepSpeed文件。bf16: 表明训练时使用了bfloat16精度。zero: 表明使用了ZeRO(Zero Redundancy Optimizer)优化策略。rank_X: 表示这是第X个GPU/进程的状态。- 内容: 它们保存的是被分割后的优化器状态(如Adam优化器的动量和方差)。ZeRO的核心思想就是将这些状态分散到所有GPU上,以极大地节省显存。这些文件就是恢复训练时所必需的。
latest:- 作用: 一个简单的文本文件,里面通常只包含最新DeepSpeed状态目录的名称(例如,内容是 “global_step1413”)。DeepSpeed通过读取它来快速定位最新的优化器状态。
zero_to_fp32.py:- 作用: 这是一个非常重要的实用脚本!DeepSpeed保存的检查点是分片的(sharded),并且是针对其特定的分布式环境的。如果你想把这个检查点用于推理,或者在没有DeepSpeed的环境中加载它,你需要将这些分片的优化器状态合并成一个标准的、完整的模型权重文件(通常是
pytorch_model.bin)。这个脚本就是用来做这个转换的。 - 使用方法: 通常你可以在该目录下运行
python zero_to_fp32.py . <输出文件名.bin>来生成一个完整的模型文件。
- 作用: 这是一个非常重要的实用脚本!DeepSpeed保存的检查点是分片的(sharded),并且是针对其特定的分布式环境的。如果你想把这个检查点用于推理,或者在没有DeepSpeed的环境中加载它,你需要将这些分片的优化器状态合并成一个标准的、完整的模型权重文件(通常是
总结
- 用于推理: 如果你只想加载模型进行推理,你主要关心的是第1和第2类的文件。
Ovis.from_pretrained()会自动处理这些文件。 - 用于恢复训练: 如果你想从这个检查点继续训练,那么第3和第4类的文件就至关重要了。
Trainer和DeepSpeed会读取它们来恢复到和训练中断时一模一样的状态。 - 关键区别: 这个目录是一个训练过程中的快照,而不仅仅是最终模型。它包含了“大脑”(模型权重)和“记忆”(训练状态),以便随时可以“醒来”继续学习。
最上层VS最下层
这是一个非常核心且经典的问题!简短的回答是:通常情况下,放开最上层进行训练效果更好,也更高效。
下面我将详细解释为什么,并提供不同情况下的策略选择。
核心理念:大模型的知识分层
想象一下大模型就像一个知识金字塔:
- 最下层 (Bottom Layers / Embedding Layers): 这一层学习的是最基础、最通用的知识。比如,什么是单词,基本的语法结构,词与词之间的普遍关系(例如,“国王”和“女王”在语义空间中很近)。这些知识是语言的基石,几乎在所有领域都通用。
- 类比: 就像一个人学习字母、单词和基本语法。
- 中间层 (Middle Layers): 这一层学习的是更复杂的句法、语义和逻辑关系。它开始理解短语、句子和段落的含义,并进行一些简单的推理。这些知识仍然是相对通用的。
- 类比: 就像一个人开始理解句子、段落大意和基本的逻辑。
- 最上层 (Top Layers / Task-specific Layers): 这一层负责将底层和中间层提取的通用特征进行整合、提炼,并最终适配到具体的任务上。它学习的是如何组织语言,以特定的风格、格式或针对特定问题生成最终的答案。
- 类比: 就像一个学识渊博的人(已经掌握了语言和逻辑)在学习如何成为一名律师,他需要学习法律术语、案件分析的特定格式和辩论风格。
为什么优先训练最上层?
基于上述的知识分层理念,在注入特定领域知识时,我们优先训练最上层,原因如下:
- 效率最高,成本最低:
- 最上层的参数量相对于整个模型来说占比较小。只训练这部分,对计算资源(GPU显存、训练时间)的要求最低,可以更快地完成迭代。
- 保留通用知识,防止“灾难性遗忘” (Catastrophic Forgetting):
- 模型的底层和中层包含了海量预训练数据中学到的通用语言能力。如果放开这些层进行训练,它们可能会被你的小规模领域数据“带偏”,从而忘记了原有的通用知识。比如,一个微调于医疗领域的模型,可能会在回答历史问题时也带上医疗术语,这就是“灾难性遗忘”。冻结底层可以最大程度地保留这些宝贵的通用能力。
- 任务导向更明确:
- 领域知识的注入,本质上是让模型学会如何“运用”已有的知识来解决“新领域”的问题。这正合最上层“任务适配”的功能。你是在教模型如何用它已经懂的语言和逻辑,来谈论医学、法律或金融。
什么时候考虑训练更深层?
虽然训练最上层是首选,但在某些情况下,你可能需要放开更多的层:
- 领域差异巨大:
- 如果你的特定领域与模型的预训练数据差异非常大(例如,古文、代码、化学分子式、或者一种非常独特的方言),模型的底层可能无法很好地理解这个领域的基本“词汇”和“语法”。这时,你可能需要从上到下,逐渐解冻更多的层(Unfreeze more layers),并使用一个非常小的学习率(Lower learning rate)来微调,让模型的中下层也慢慢适应新领域的语言范式。
- 需要更深层次的语义理解:
- 如果你的任务不仅是改变说话风格,而是需要模型理解领域内全新的、复杂的逻辑关系(例如,在法律领域进行案件推理,而不仅仅是生成法律文书),那么只调整最上层可能不够。这时可以考虑解冻一部分中间层,让模型学习新的概念关联和推理模式。
总结与最佳实践
| 策略 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 只训练最上层 | 计算成本低、速度快、有效防止灾难性遗忘、保留通用能力。 | 对与预训练数据差异巨大的领域,效果可能有限。 | 绝大多数领域知识注入场景,如客服、金融、医疗问答,特定风格写作等。 |
| 训练最下层 | 几乎没有优点。 | 计算成本极高、极易发生灾难性遗忘、破坏模型基础语言能力。 | 几乎从不使用。 除非你要教模型一种全新的语言或符号系统,但这更像是从头预训练,而不是微调。 |
| 从上往下解冻多层 | 效果可能更深入,能适应差异较大的领域。 | 计算成本更高,调参更复杂,有灾难性遗忘的风险。 | 目标领域与预训练数据差异较大时,或需要深度逻辑推理时。 |