【AF-CLIP】的提示方案代码分析
AF-CLIP提示(Prompt)部分的完整流程总结
流程:
输入:类别描述文本(如“without defect.”、“with defect.”),以及模型参数(如prompt长度等)
- 类别描述文本初始化
输入类别描述文本(如“without defect.”、“with defect.”)
–》1.用tokenizer将文本转为token序列。
–》2.将token序列保存为self.state_prompt_tokens。
–》初始化可学习的prompt向量self.state_prompt_embedding,长度为prompt_len,并设置为可训练参数。
–》【缺点1】:类别描述文本固定,表达能力有限,不能适应不同任务或数据分布。
# 输入类别描述文本与初始化prompt参数 开始#insert方法:函数没有返回值,初始化提示相关参数
#【1】正常类别的文本提示normal_cls_prompt 【2】异常类别文本提示anomaly_cls_prompt
#【3】提示token序列self.state_prompt_tokens 【4】tokenizer(文本分词器)【5】初始化device
#【6】prompt_len(提示长度)参数
#输入:args(包含prompt长度等参数),tokenizer(文本分词器),device(设备如cuda/cpu)
def insert(self, args, tokenizer, device):
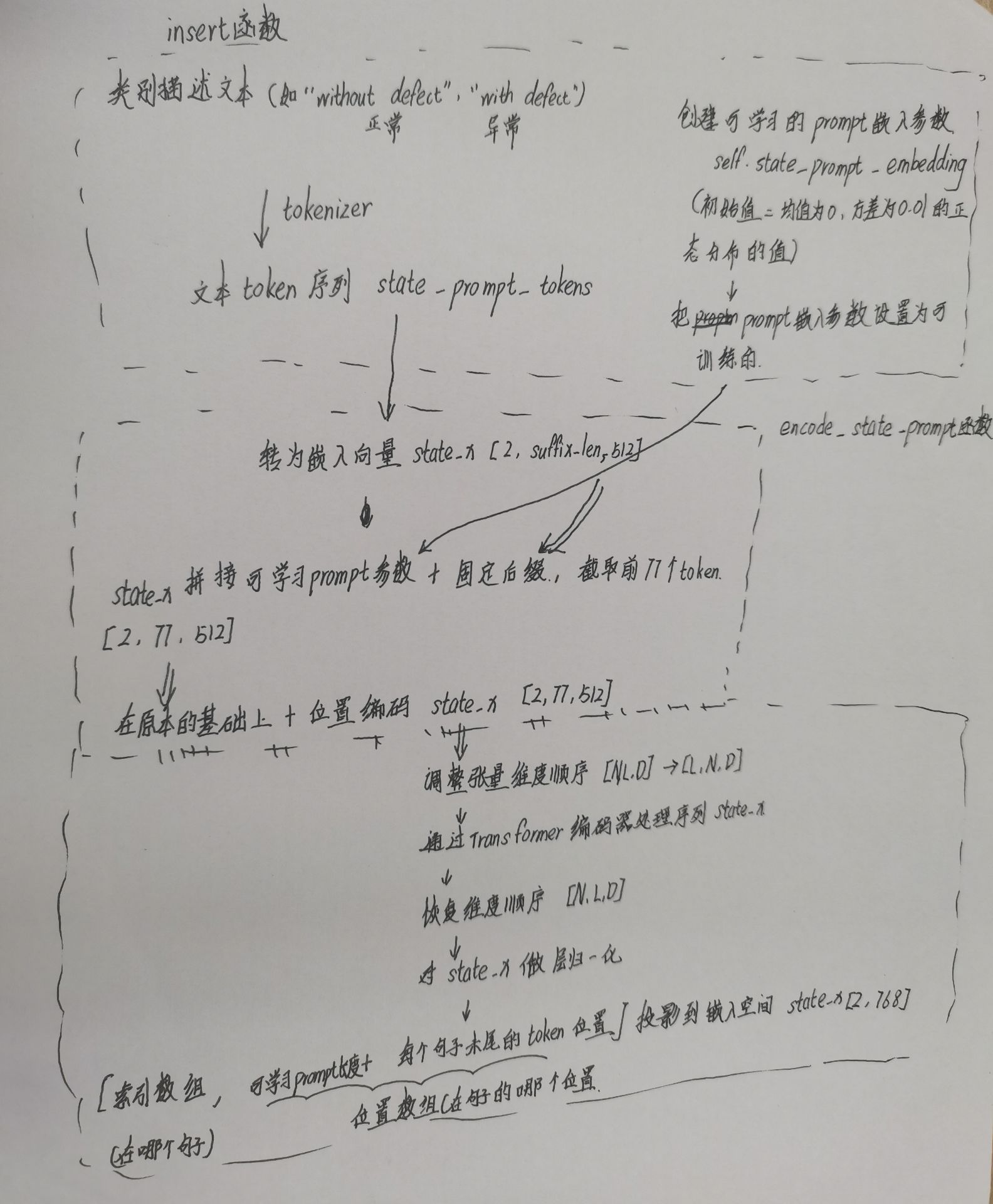
#输入:正常/异常类别的文本提示#定义正常类别的文本提示normal_cls_prompt = 格式化字符串【可以固定放一些词在前面或后面】“without defect.”self.normal_cls_prompt = f'without defect.'#定义异常类别文本提示anomaly_cls_prompt= 格式化字符串‘with defect.’self.anomaly_cls_prompt = f'with defect.'#1.把正常/异常类别的文本提示用 tokenizer 2.将文本-》token序列self.state_prompt_tokens,并转到指定设备例:["without defect."]→[12, 34, 56,...]self.state_prompt_tokens = tokenizer([self.normal_cls_prompt, self.anomaly_cls_prompt]).to(device)#初始化tokenizer(文本分词器),后续可直接用self.tokenizer处理文本self.tokenizer = tokenizer#初始化device(设备)对象self.device = device#从args对象里提取prompt_len(提示长度)参数,初始化为自己的self.prompt_len = args.prompt_len#3.创建可学习的prompt嵌入参数self.state_prompt_embedding
#用torch.empty来创建一个指定形状的张量,形状=(1,提示长度,嵌入维度大小),用这个张量来做可学习的prompt嵌入参数
#【token_embedding_dim.weight.shape[-1]表示分词嵌入(token_embedding)的权重形状(weight.shape)的最后一个维度(【-1】)表示嵌入维度的大小】self.state_prompt_embedding = nn.Parameter(torch.empty(1, args.prompt_len, self.token_embedding.weight.shape[-1]).to(device))#4.初始化prompt嵌入参数self.state_prompt_embedding
#在self.state_prompt_embedding里面填进 均值为0方差为0.01的正态分布的值,用作初始值nn.init.normal_(self.state_prompt_embedding, std=0.01)#5.把prompt嵌入参数设置为可训练的,requires_grad_(True)表示会通过反向传播记录这个张量的梯度,会更新这个参数self.state_prompt_embedding.requires_grad_(True)
# 输入类别描述文本与初始化prompt参数 结束
- 拼接可学习prompt与token embedding
–》将可学习的prompt向量(self.state_prompt_embedding)复制2份(分别对应两类),与类别token embedding【即正常/异常的固定后缀】拼接,形成完整的输入序列。
–》拼接后长度裁剪为77(最大context长度)。
–》加上位置编码(positional embedding)。
–》【缺点2】:拼接方式简单,未考虑类别间的语义差异,且prompt长度固定,灵活性有限。
# 这个函数的功能为: """功能:编码文本提示,生成文本特征向量输入:self(包含模型参数和提示tokens)输出:state_x,形状为 [2, embed_dim],表示"正常"和"异常"两个类别的文本特征"""
def encode_state_prompt(self):# ============================================================================# 第1行:将文本token ID转换为嵌入向量# 输入:self.state_prompt_tokens,形状 [2, suffix_len],例如 [[101, 102], [101, 103]],表示"正常"和"异常"的后缀词ID# 其中2表示两个类别(正常/异常),suffix_len表示后缀词数量(如"defect"是1个词)# 操作:self.token_embedding() 是一个嵌入层(类似查表),将每个token ID映射为512维向量# .type(self.dtype) 将数据类型转换为模型统一类型(通常是float16或float32)# 输出:state_x,形状 [2, suffix_len, 512],例如 [[向量1, 向量2], [向量3, 向量4]]# 例子:假设token ID是 [101, 102],embedding后变成 [[0.1, 0.2, ..., 0.5], [0.3, 0.4, ..., 0.6]](512维)# ============================================================================state_x = self.token_embedding(self.state_prompt_tokens).type(self.dtype)# ============================================================================# 第2行:拼接可学习prompt和固定token embedding,并截取前77个token# 输入1:self.state_prompt_embedding,形状 [1, prompt_len, 512],可学习的提示向量,prompt_len=12# .repeat(2, 1, 1) 将其复制2份,变成 [2, 12, 512],分别用于"正常"和"异常"# 输入2:state_x,形状 [2, suffix_len, 512],上一步得到的固定后缀嵌入# 操作:torch.cat(..., dim=1) 在序列维度(dim=1)拼接,结果形状 [2, 12+suffix_len, 512]# [:, :77, :] 切片操作,只保留前77个token(CLIP文本编码器的最大长度限制)# 输出:state_x,形状 [2, 77, 512]# 例子:假设prompt_len=12, suffix_len=2,拼接后是14个token,但CLIP限制77个,这里取前77个# 结构:[可学习向量1-12, 固定词"defect"等,填充到77]# ============================================================================state_x = torch.cat([self.state_prompt_embedding.repeat(2, 1, 1), state_x], dim