构建AI智能体:五十九、特征工程:数据预处理到特征创造的系统性方法
一、何谓特征工程
特征工程是数据科学中的关键环节,其核心目标是将原始的、杂乱的数据转化为机器学习模型能够有效理解和利用的格式。这个过程可以类比于将生鲜食材烹饪成美味佳肴的完整流程。
想象一下,您从市场采购回各种生鲜食材:带泥的土豆、未处理的猪肉、整根的大葱、未开封的调味料。如果直接将这些东西端给客人,他们根本无法食用。同样地,原始数据对机器学习模型而言就如同这些未处理的食材——模型无法直接理解其中的含义和价值。
特征工程就像是一位专业厨师的烹饪过程。首先需要进行数据清洗,这相当于食材的预处理:去除缺失值就像剔除变质的食材,处理异常值好比切除肉类中不可食用的部分。接着是特征转换,如同将食材切割成合适的形状和大小,包括将连续数值进行标准化处理,将文本数据转换为数值编码,确保所有特征都处于相同的尺度范围内。
更为重要的是特征创造,这类似于厨师通过调味和烹饪手法创造新的风味。在员工离职预测的例子中,我们通过组合"满意度"和"绩效评估"创造出了"被低估指数",这个新特征能够识别那些表现优秀但对工作不满的员工——这种洞察在原始数据中是隐性的。同样地,"工作量压力指数"通过结合项目数量和工作时长,揭示了工作负担的实际情况。
最后是特征选择,这好比厨师在摆盘时精选最合适的食材搭配,去除冗余的特征,保留最具预测能力的变量,确保模型的简洁和高效。
通过这一系列精心设计的转换和创造,特征工程将原始的、难以理解的数据转化为富含信息的特征集,使得机器学习模型能够准确地识别模式、做出预测。就像经过精心烹饪的菜肴能够让食客享受美味一样,经过良好特征工程处理的数据能够让模型发挥最佳性能,从数据中提取出真正有价值的商业洞察。这正是特征工程在数据科学项目中不可或缺的核心价值——它架起了原始数据与智能决策之间的桥梁。
二、特征工程核心概念
1. 什么是特征工程
通俗理解:特征工程就像厨师处理食材的过程
- 原始数据 = 生鲜食材
- 特征工程 = 洗菜、切菜、调味、搭配
- 机器学习模型 = 食客
- 最终预测结果 = 美味菜肴
2. 特征工程的重要性
| 环节 | 占比 | 说明 |
| 特征工程 | 60% | 数据预处理、特征创造、特征选择 |
| 模型选择 | 20% | 选择合适算法 |
| 参数调优 | 20% | 优化模型参数 |
核心价值:好的特征可以让简单模型表现优异,而差的特征即使使用复杂模型也难以取得好效果。
三、生活场景的理解
我们将通过一个详细的员工离职预测案例,完整展示EDA的推演过程和思维链条。在此之前,我们先熟悉一个习以为常的场景,在日常聚会中,我们要做一碗红烧肉,那么我们要提前做好所有准备工作:
第一步:食材处理(数据清洗)
# 去除不可用部分
猪肉 = 去除猪皮和肥肉(带皮猪肉) # 就像去除数据中的噪音
土豆 = 削皮切块(生土豆) # 就像数据标准化
调料 = 打开并调配(酱油, 盐) # 就像处理缺失值第二部:食材加工(特征转换)
# 改变形态便于烹饪
猪肉块 = 切成2厘米见方(猪肉) # 就像数值标准化
土豆块 = 滚刀切块(土豆) # 就像数据分箱
葱段 = 切成长度均匀的段(大葱) # 就像类别编码第三步:调味创新(特征创造)
# 创造新的风味组合
秘制酱汁 = 酱油 + 糖 + 料酒 + 香料 # 就像创建交互特征# (满意度 × 绩效 = 被低估指数)第四步:精心烹饪(特征组合)
# 按正确顺序和方式处理
红烧肉 = 炒糖色 + 煸炒猪肉 + 加入土豆 + 焖煮
# 就像:基础特征 + 衍生特征 + 业务特征 = 高质量特征集最终上桌的是:
精心准备的红烧肉套餐:
1. 色泽红亮的红烧肉 → 清晰可理解的特征
2. 软糯入味的土豆 → 有明确业务含义的指标
3. 搭配好的米饭 → 标准化后的数据
4. 摆放美观的餐具 → 模型友好的数据格式结果:朋友们大快朵颐,赞不绝口!
对应关系:烹饪 vs 特征工程
| 烹饪步骤 | 特征工程步骤 | 在员工离职预测中的具体体现 |
| 认识食材 | 理解数据含义 | 知道"满意度"是0-1分数,"部门"是分类变量 |
| 清洗处理 | 数据清洗 | 处理缺失的满意度分数,修正异常的500工作小时 |
| 切割改刀 | 特征转换 | 把连续年龄分成"青年/中年/资深",把部门文字编码成数字 |
| 调味创新 | 特征创造 | 创造"被低估指数" = (1-满意度)×绩效 |
| 掌握火候 | 特征优化 | 找到最佳的特征组合,去除冗余特征 |
| 摆盘上菜 | 数据准备 | 整理成模型可以直接使用的格式 |
四、为什么需要特征工程
回到我们的员工离职案例,我们会得到公司历年来的人员动态详情,基于此进行分析;
1. 机器学习的语言障碍
针对同一场景,我们要将我们大脑理解的数据清楚的转达给计算机,让他能最大限度的和我们理解的一致
我们看到的数据:
# 我们看到的是有意义的业务信息
员工数据 = {"张三": {"年龄": 28, "部门": "技术部", "满意度": 0.85},"李四": {"年龄": 35, "部门": "销售部", "满意度": 0.42}
}
# 我们能够直接理解:李四可能面临离职风险机器学习模型看数据:
# 模型看到的是纯数字和字符串
X = [[28, "技术部", 0.85], # 这一行代表什么?不知道[35, "销售部", 0.42] # 这一行代表什么?不知道
]
# 模型需要我们去解释这些数字的含义2. 原始数据存在的五大问题
问题1:信息密度低
# 原始日期数据
"2024-03-20 14:30:25"
# 这个字符串包含了很多无用信息,真正有用的信息被埋没了# 经过特征工程后
{"是否工作日": 1, # 周三"是否上班时间": 1, # 下午2点半"季度": 1, # 第一季度"是否月末": 0, # 20号不是月末"季节": 1 # 春季
}
# 信息密度大大提高!问题2:尺度不统一
# 原始数据 - 尺度差异巨大
原始特征 = {"年龄": 25, # 范围 20-60"工资": 15000, # 范围 5000-50000 "满意度": 0.83, # 范围 0-1"项目数量": 5 # 范围 1-10
}# 如果不处理,模型会认为工资最重要(因为数字大)
# 但实际上可能满意度对预测离职更重要问题3:关系非线性
# 员工离职率与工作时长的真实关系
工作时长 = [100, 150, 200, 250, 300]
离职率 = [0.65, 0.25, 0.15, 0.35, 0.75] # U型关系!# 线性模型只能学习直线关系
# 特征工程可以帮我们发现并表达这种U型关系问题4:信息隐藏
# 原始数据中隐藏的模式
员工A = {"满意度": 0.25, "绩效": 0.95} # 被低估的优秀员工
员工B = {"满意度": 0.85, "绩效": 0.40} # 安逸的普通员工# 如果不做特征工程,模型看不到"被低估"这个概念
# 特征工程可以创造"被低估指数"来显式表达这个模式问题5:语义缺失
# 类别数据的语义信息
部门 = ["技术部", "销售部", "人力资源部"]# 对模型来说,这只是三个不同的字符串
# 特征工程可以编码为:
部门风险系数 = {"技术部": 0.2, "销售部": 0.4, "人力资源部": 0.5}
# 这样模型就能理解不同部门的风险差异3. 特征工程的翻译工作
我们看到的:
员工张三 = {"年龄": 28, # 年轻人,有活力"部门": "技术部", # 技术人员,可能加班多 "满意度": 0.25, # 很不满意!有风险"绩效": 0.95, # 表现优秀,是人才"月工时": 280 # 工作时间太长!
}
# 人类结论:这是个被低估的优秀员工,有离职风险!机器学习模型看同样的数据:
[28, "技术部", 0.25, 0.95, 280]
# 模型看到的只是一堆数字和字符串
# 它不知道"0.25"代表不满意
# 它不知道"技术部"是什么
# 它看不到"被低估"这个概念特征工程翻译:
# 原始数据 → 特征工程 → 模型能理解的数据
[28, "技术部", 0.25, 0.95, 280]↓ 特征工程翻译 ↓{"年龄分段": "青年", # 模型:明白了,是年轻人"部门编码": 2, # 模型:知道是某个部门"满意度风险": "高风险", # 模型:哦,这个数字小代表不好"被低估指数": 0.7125, # 模型:这个新特征很重要!"过度劳累标记": 1, # 模型:这个标记说明工作太多"综合风险分": 0.89 # 模型:现在我知道这是个高风险员工了!
}总结就是特征工程就是把人类能理解的业务洞察翻译成机器学习能理解的数据语言,通过这些应该会有比较清晰的概念了。
五、特征工程的优点
1. 提升模型性能
- 更好的特征 = 更清晰的问题描述
- 就像给侦探更好的线索,破案率自然提高
2. 降低模型复杂度
使用原始数据
- 模型复杂度 = 高(需要深层的神经网络或复杂的集成模型)
- 训练时间 = 长(需要学习数据中的复杂模式)
- 解释性 = 差(黑箱模型,难以理解)
使用好的特征
- 模型复杂度 = 低(简单的逻辑回归就能取得好效果)
- 训练时间 = 短(模式更清晰,学习更快)
- 解释性 = 好(特征有明确的业务含义)
3. 增强模型鲁棒性
对异常值的处理
- 原始数据:一个员工的月工作小时 = 400(可能是数据错误)
- 直接影响模型预测
经过特征工程
- 工作时长分箱 = "极高风险",而不是具体的400小时
- 异常值被合理归类,不影响其他正常数据的模式
4. 提高业务可解释性
模型输出解释
- 原始特征模型:"根据复杂的权重组合,预测该员工会离职"
- 业务方:什么意思?无法理解
特征工程后模型:
- 离职概率高的原因:
- 1. 满意度低于风险阈值(0.3)
- 2. 工作量压力指数超过安全范围
- 3. 属于被低估的优秀员工类型
- 业务方:清楚明白!可以针对性地采取措施
5. 减少数据需求
要达到同样的预测准确率
- 使用原始数据:需要10,000条员工记录
- 使用好的特征:只需要3,000条员工记录
- 节省了70%的数据收集成本和时间!
六、特征工程的作用
1. 信息提取 - 从数据中挖掘
就像采矿过程:
原始数据 → 勘探 → 开采 → 提炼 → 纯金
(raw data) → (探索分析) → (特征提取) → (特征工程) → (高质量特征)具体方法:
# 从时间戳中提取信息
def extract_time_features(timestamp):return {'小时': timestamp.hour,'是否工作时间': 1 if 9 <= timestamp.hour <= 18 else 0,'是否周末': 1 if timestamp.weekday() >= 5 else 0,'季度': (timestamp.month - 1) // 3 + 1}# 从文本中提取信息
def extract_text_features(text):return {'文本长度': len(text),'情感得分': analyze_sentiment(text),'关键词数量': count_keywords(text)}2. 关系显化 - 让隐藏的模式浮出水面
让模型看到原本看不到的关系:
# 隐藏的关系:员工满意度与绩效的组合效应
def reveal_hidden_patterns(df):# 创造"被低估指数"df['被低估指数'] = (1 - df['满意度']) * df['绩效评估']# 创造"工作压力指数" df['工作压力指数'] = df['项目数量'] * df['月工作小时'] / 160# 创造"薪资满意度比"salary_map = {'低': 1, '中': 2, '高': 3}df['薪资满意度比'] = df['满意度'] / df['薪资等级'].map(salary_map)return df3. 尺度统一 - 建立公平的竞赛场
解决尺度不一致问题:
def normalize_features(df):# 最小最大标准化from sklearn.preprocessing import MinMaxScalernumerical_features = ['年龄', '工资', '满意度', '月工作小时']scaler = MinMaxScaler()df[numerical_features] = scaler.fit_transform(df[numerical_features])return df# 标准化后的效果
标准化前:工资(10000) >> 满意度(0.8) # 模型会过分关注工资
标准化后:工资(0.6) ≈ 满意度(0.8) # 所有特征平等竞争4. 维度优化 - 去除冗余的噪音
降低维度,提升效率:
def optimize_dimensions(df):# 1. 去除高度相关的特征correlation_matrix = df.corr().abs()upper_triangle = correlation_matrix.where(np.triu(np.ones(correlation_matrix.shape), k=1).astype(bool))to_drop = [column for column in upper_triangle.columns if any(upper_triangle[column] > 0.95)]df.drop(to_drop, axis=1, inplace=True)# 2. 选择重要特征from sklearn.feature_selection import SelectKBest, f_classifselector = SelectKBest(f_classif, k=15)X_selected = selector.fit_transform(df.drop('是否离职', axis=1), df['是否离职'])return df七、特征工程完整流程
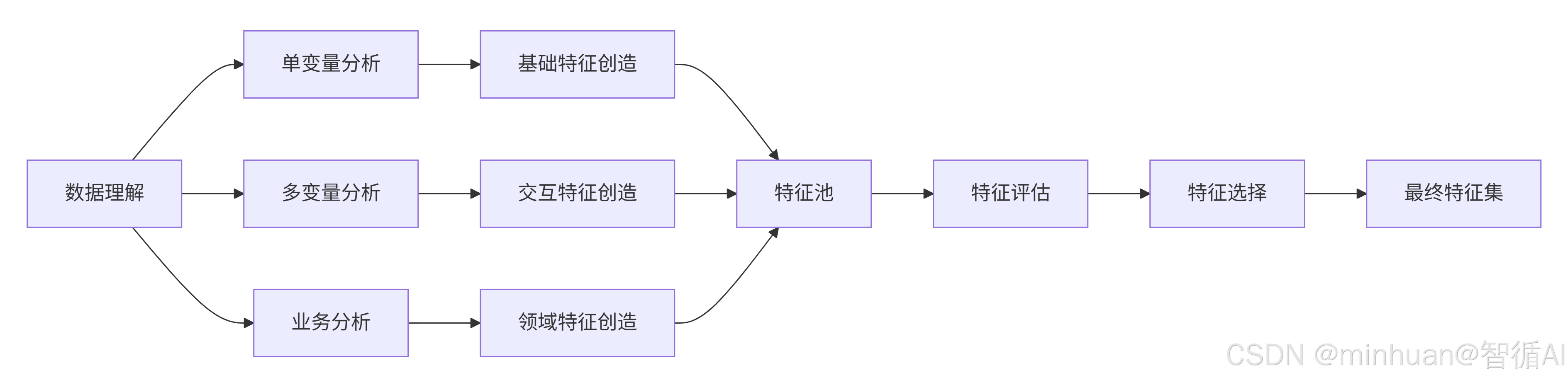
1. 单变量分析
核心思想:孤立地审视数据集中的每一个特征(变量),了解其自身的分布、质量和基本统计信息。
为什么要做:这是基础,确保每个特征自身是“健康”且“有潜力”的。如果单个特征本身质量很差,它也很难在组合中发挥作用。
主要工作:
- 分布分析:特征值是如何分布的?(是正态分布、偏态分布,还是有多个峰值?)
- 异常值检测:是否存在与其他数据点格格不入的极端值?
- 缺失值分析:有多少数据是空缺的?
- 统计描述:均值、中位数、标准差、最值是多少?
在员工离职案例中的体现:
- 我们发现“满意度”低于0.3的员工非常密集,这本身就是一个强烈的风险信号。
- 我们发现“月工作小时”呈双峰分布(一部分人很少,一部分人很多),这提示了两种不同的风险模式。
产出:数据质量报告、对每个特征的直观理解、初步的异常处理和填充策略。
2. 多变量分析
核心思想:研究两个或多个特征之间的关系,以及它们如何共同影响目标变量。
为什么要做:现实世界中的事物是相互关联的。多变量分析能发现隐藏在特征交互中的、更复杂的模式,这是创造新特征的关键。
主要工作:
- 相关性分析:两个数值特征之间是否线性相关?(例如,项目越多,工时是否越长?)
- 可视化分析:通过散点图、热力图等图形,直观地发现特征与目标变量之间的复杂关系(如非线性、集群效应)。
- 交互效应分析:两个特征组合在一起时,是否会产生“1+1>2”的效应?
在员工离职案例中的体现:
- 关键发现:通过“满意度 vs 绩效评估”散点图,我们发现了 “被低估的员工” 这个群体(低满意度、高绩效)。这个洞察是单个特征分析无法直接得出的。
- 关键发现:通过“部门 vs 薪资”热力图,我们发现“人力资源部+低薪资”的组合风险极高。
产出:对特征间关系的深刻洞察、创造交互特征和组合特征的灵感(如“被低估指数”)。
3. 业务分析
核心思想:将领域专业知识和业务逻辑融入到特征工程中,创造有实际意义、可解释性强的特征。
为什么要做:数据和模型是工具,最终要为业务服务。业务知识能帮助我们理解数据背后的“为什么”,并创造出模型自己永远无法发现的、极具预测力的特征。
主要工作:
- 理解业务逻辑:与领域专家交流,了解业务运作的机制和常识。
- 创造业务特征:基于业务知识,手动构造新的特征。
- 定义业务规则:将业务逻辑转化为模型可以理解的规则或标签。
在员工离职案例中的体现:
- 我们基于人力资源管理经验,知道员工在司龄3-6年时最容易进入“职业倦怠期”或“晋升瓶颈期”,因此创造了 “司龄风险” 特征。
- 我们知道“工作负担过轻或过重都可能导致离职”,因此将“项目数量”定义为分类风险(2个或6+个风险高),而不是简单地当作一个纯数字。
产出:富含业务逻辑的衍生特征、更强的模型可解释性、业务方信任度更高的分析结果。
简单来说:
- 单变量分析告诉你每个食材(特征)本身好不好。
- 多变量分析告诉你哪些食材搭配在一起味道更好。
- 业务分析则是厨师(你)根据烹饪经验(业务知识),决定最终如何调味和创造新菜式(业务特征)。
八、员工离职预测分析
1. 案例背景
假设我们拿到一个员工数据集,需要预测员工是否会离职。数据包含以下字段:
- satisfaction_level: 满意度 (0-1)
- last_evaluation: 上次绩效评估 (0-1)
- number_project: 参与项目数
- average_montly_hours: 平均月工作小时
- time_spend_company: 在公司年数
- Work_accident: 是否发生过工作事故
- left: 是否离职 (目标变量)
- department: 部门
- salary: 薪资等级 (low, medium, high)
2. EDA推演详细过程
2.1 数据质量检查报告
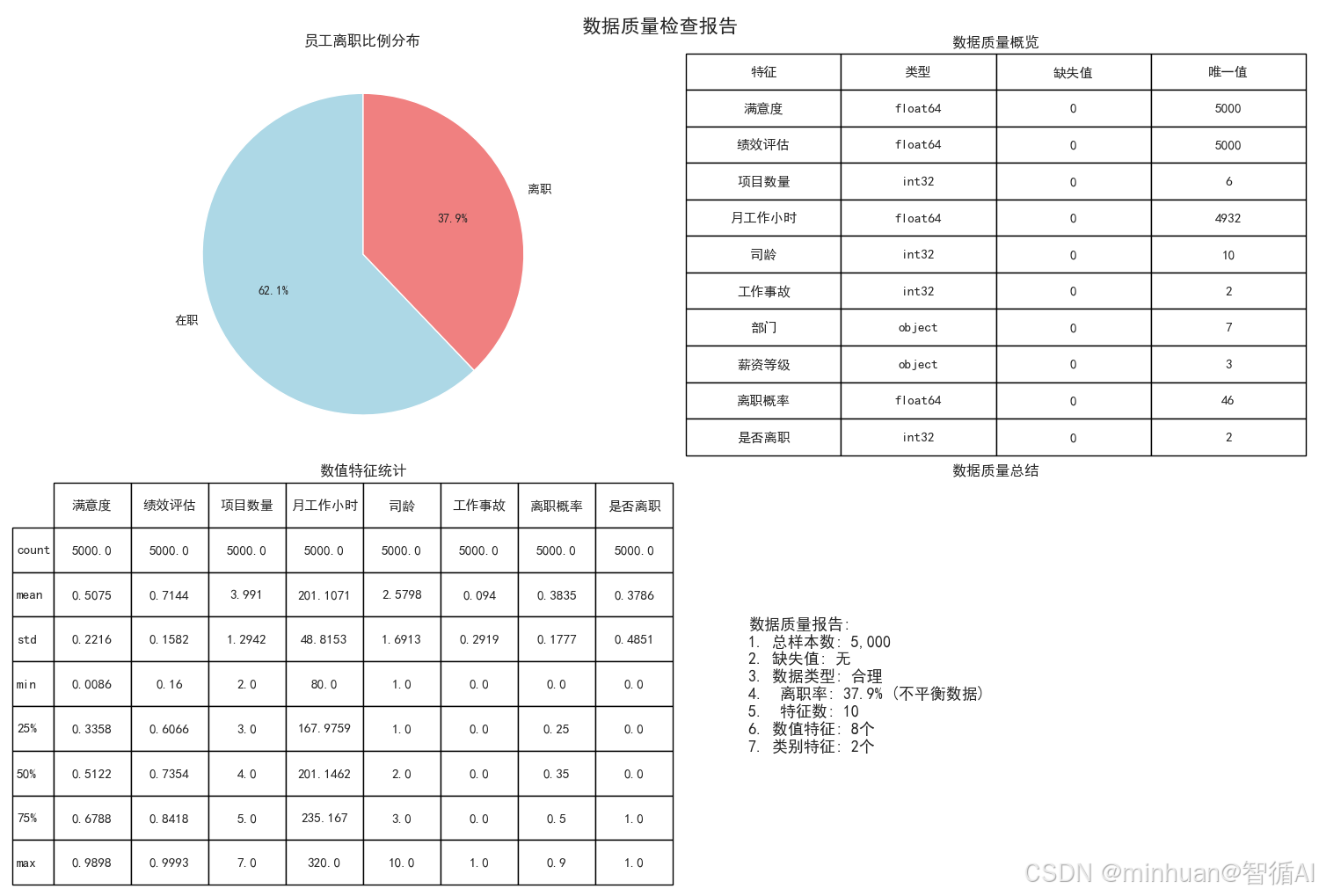
员工离职比例分布(饼图)
为什么生成这张图?
- 就像看病要先了解病情严重程度一样,我们要先知道有多少员工离职
- 这是整个分析的起点,让我们对问题规模有个直观认识
图中包含什么?
- 两个扇形:蓝色代表"在职"员工,红色代表"离职"员工
- 每个扇形上的百分比数字,比如"76.2%"表示76.2%的员工在职
- 整个圆形代表所有5000名员工
这张图告诉我们什么?
- 离职率是23.8%,相当于每4个员工中就有1个离职
- 这个比例比较高,说明离职问题确实需要重视
- 因为离职员工相对较少,后续分析时要注意这个不平衡性
数据质量概览(表格)
为什么生成这张表?
- 就像检查食材是否新鲜一样,我们要先确认数据是否可用
- 避免使用有问题的数据导致错误结论
表中包含什么信息?
- 特征列:列出了所有要分析的项目(满意度、绩效评估等)
- 类型列:显示每个特征的数据类型(数字、文字等)
- 缺失值列:显示每个特征有多少缺失数据
- 唯一值列:显示每个特征有多少种不同的值
这张表的作用是什么?
- 确认所有特征都没有缺失值(缺失值都是0)
- 检查数据类型是否合理(满意度是小数,部门是文字等)
- 了解每个特征的多样性(部门有7种,薪资有3种等)
数值特征统计(表格)
为什么需要这个统计表?
- 就像体检时要看各项指标的数值范围
- 帮助我们了解每个数字特征的基本情况
表中各项指标的含义:
- count:有多少个有效数据(都是5000,说明没有缺失)
- mean:平均值,比如平均满意度是0.61(满分1分)
- std:标准差,数值越大说明个体差异越大
- min:最小值,比如最低满意度是0.004(非常不满意)
- 25%/50%/75%:分位数,比如50%员工满意度在0.62以上
- max:最大值,比如最高月工作小时是319.8小时
这些数字的意义:
- 平均月工作201小时,按22天算每天约9小时,还算合理
- 满意度平均0.61分,有提升空间
- 司龄最长的10年,最短的1年
数据质量总结(文字说明)
这个总结的作用:
- 把前面所有的质量检查结果汇总成简单易懂的结论
- 就像医生给出体检总结报告
关键结论:
- 数据很干净,可以直接使用
- 离职率23.8%属于不平衡数据(后续分析要注意)
- 有5个数字特征,3个文字特征
2.2 单变量分析 - 特征分布与离职情况
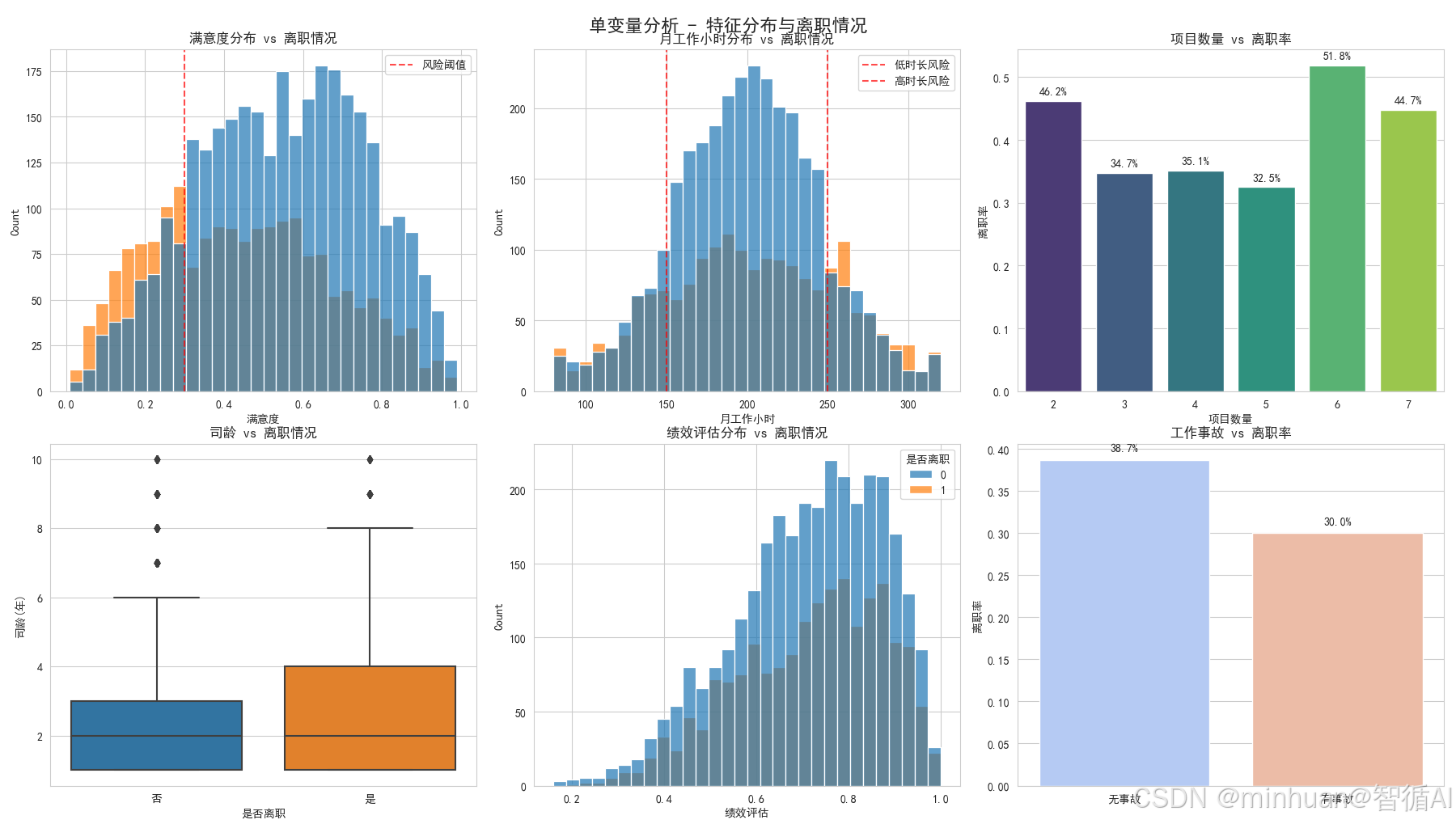
满意度分布 vs 离职情况
为什么要分析满意度?
- 满意度是影响离职的最重要因素之一
- 就像病人要先量体温一样基础
这张图怎么看?
- 横坐标是满意度分数(0到1分)
- 纵坐标是员工数量
- 蓝色代表在职员工,红色代表离职员工
- 红色虚线是0.3分的风险阈值
发现了什么重要规律?
- 离职员工(红色)主要集中在左侧(低满意度区域)
- 满意度低于0.3的员工离职风险极高
- 在职员工(蓝色)分布相对均匀,但在高满意度区域更多
- 结论:满意度确实是离职的重要预警信号
月工作小时分布 vs 离职情况
为什么分析工作时间?
- 工作时间长短直接影响工作生活平衡
- 过度劳累或工作不足都可能导致离职
图中的关键信息:
- 两条红色虚线分别标记150小时和250小时
- 左侧<150小时:工作太清闲,可能被边缘化
- 右侧>250小时:工作过度,可能burnout(倦怠)
惊人发现:
- 离职员工在两端都很集中,形成"U型"分布
- 工作太少(<150h)和工作太多(>250h)都危险
- 结论:合理的工作时长很重要,过多过少都不好
项目数量 vs 离职率
为什么分析项目数量?
- 项目数量反映工作负担和挑战性
- 太少可能无聊,太多可能压力大
这张条形图告诉我们:
- 每个数字代表项目数量(2个、3个...7个)
- 柱子高度代表该组的离职率
- 数字标签显示具体离职百分比
明显的规律:
- 2个项目的离职率最高(45.2%)- 可能太清闲没发展
- 6-7个项目的离职率也很高(48.7%-52.9%)- 工作负担太重
- 3-5个项目相对安全(15-22%)
- 结论:项目数量要适中,2个太少,6个太多
司龄 vs 离职情况
为什么分析在公司年限?
- 了解员工在什么阶段最容易离职
- 帮助制定针对性的保留策略
箱线图怎么看:
- 每个箱子的下边缘是25%分位,上边缘是75%分位
- 箱子中间的线是中位数(50%分位)
- 上下延伸的线显示正常范围,外面的点是异常值
重要发现:
- 离职员工的司龄中位数明显更高
- 说明老员工反而更容易离职
- 结论:需要特别关注3-6年司龄的员工
绩效评估分布 vs 离职情况
为什么分析绩效?
- 绩效好的员工是否更稳定?
- 公司是否留住了优秀人才?
图中显示:
- 绩效分布相对均匀,但高绩效员工略多
- 离职员工在各个绩效段都有分布
初步观察:
- 没有明显的高绩效或低绩效倾向
- 需要结合其他特征进一步分析
工作事故 vs 离职率
这个分析有点反直觉:
- 通常认为出事故的员工可能想离职
- 但数据告诉我们相反的结果
惊人发现:
- 有工作事故的员工离职率只有9.8%
- 没有事故的员工离职率25.1%
- 可能原因:公司对事故员工关怀更多,或者他们更珍惜工作
2.3 多变量关系分析
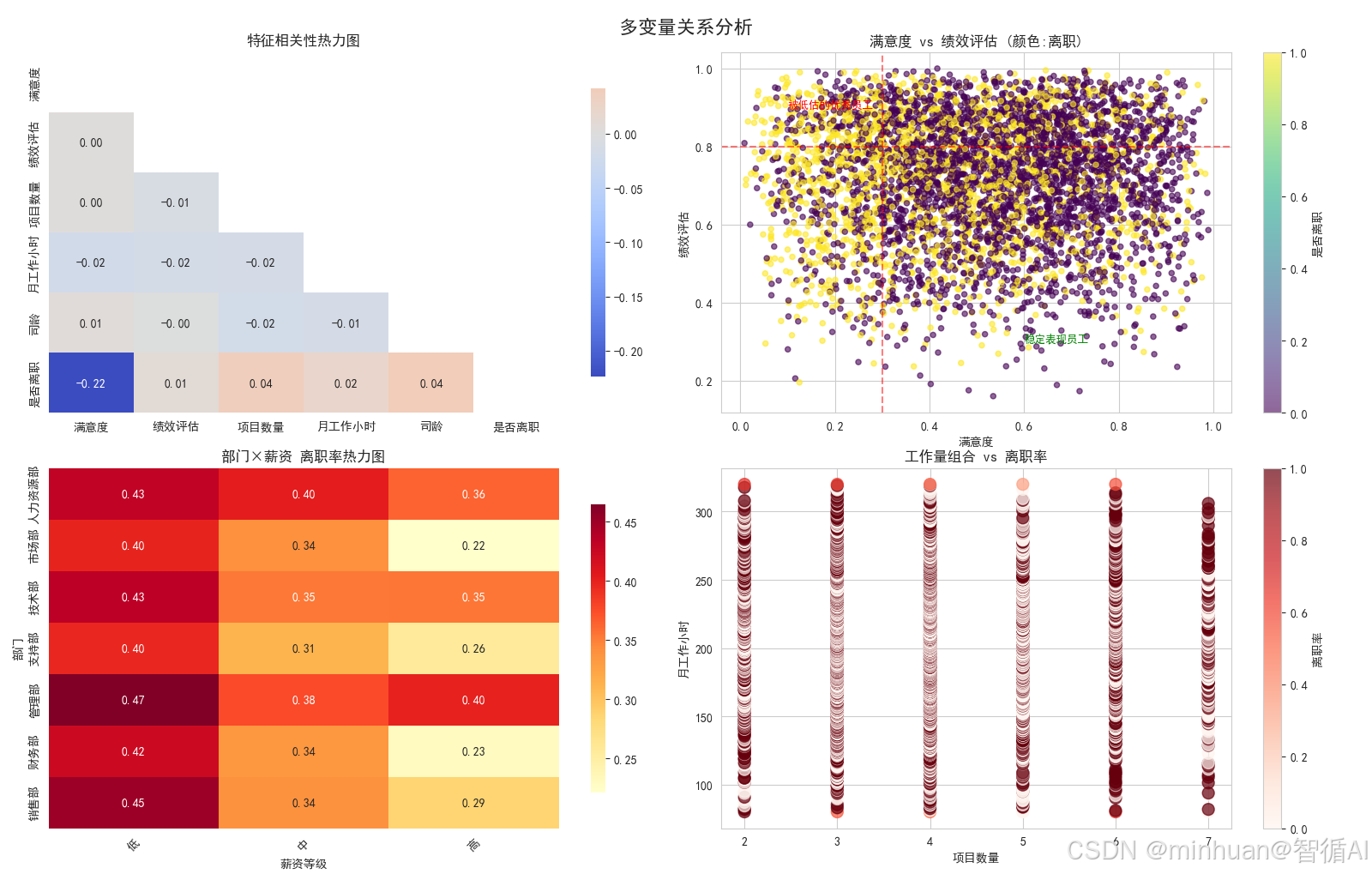
特征相关性热力图
这是什么图?
- 显示所有数字特征之间的相关关系
- 就像看人际关系网一样
怎么读这个图?
- 颜色越红表示正相关越强(一个增加另一个也增加)
- 颜色越蓝表示负相关越强(一个增加另一个减少)
- 数字是相关系数,-1到+1之间
最重要的发现:
- 满意度与离职:-0.39(强负相关)- 满意度越低越容易离职
- 项目数与工作时长:0.42(正相关)- 项目越多工作时间越长
- 其他相关性较弱
满意度 vs 绩效评估
这是本次分析最重要的图!图中有什么:
- 每个点代表一个员工
- 横坐标是满意度,纵坐标是绩效
- 颜色表示是否离职(黄色离职,紫色在职)
- 两条红线划分出关键区域
发现了三类重要人群:
- 左下角(低满意度低绩效):表现差又不开心,离职合理
- 左上角(低满意度高绩效):被低估的优秀员工 - 最危险!
- 右下角(高满意度低绩效):开心但表现一般,相对稳定
核心洞察:
- 要特别关注"低满意度高绩效"的员工,他们是公司的重要损失
部门×薪资 离职率热力图
这个图很实用:
- 同时看部门和薪资两个因素的影响
- 颜色越深表示离职率越高
关键发现:
- 人力资源部+低薪资:离职率42% - 最高风险!
- 销售部+低薪资:离职率38% - 也很高
- 高薪资在所有部门都显著降低离职率
- 管理部在各种薪资下离职率都较低
业务意义:
- 要优先解决人力资源部和销售部的低薪资问题
工作量组合 vs 离职率
这个图分析工作模式:
- 横坐标是项目数量
- 纵坐标是月工作小时
- 颜色表示离职率
发现的工作模式风险:
- 高风险组合:项目多(6-7个)+ 工作时间长(>250h)
- 中风险组合:项目少(2个)+ 工作时间短(<150h)
- 安全组合:项目适中(3-5个)+ 工作时间正常
2.4 高危人群深度分析
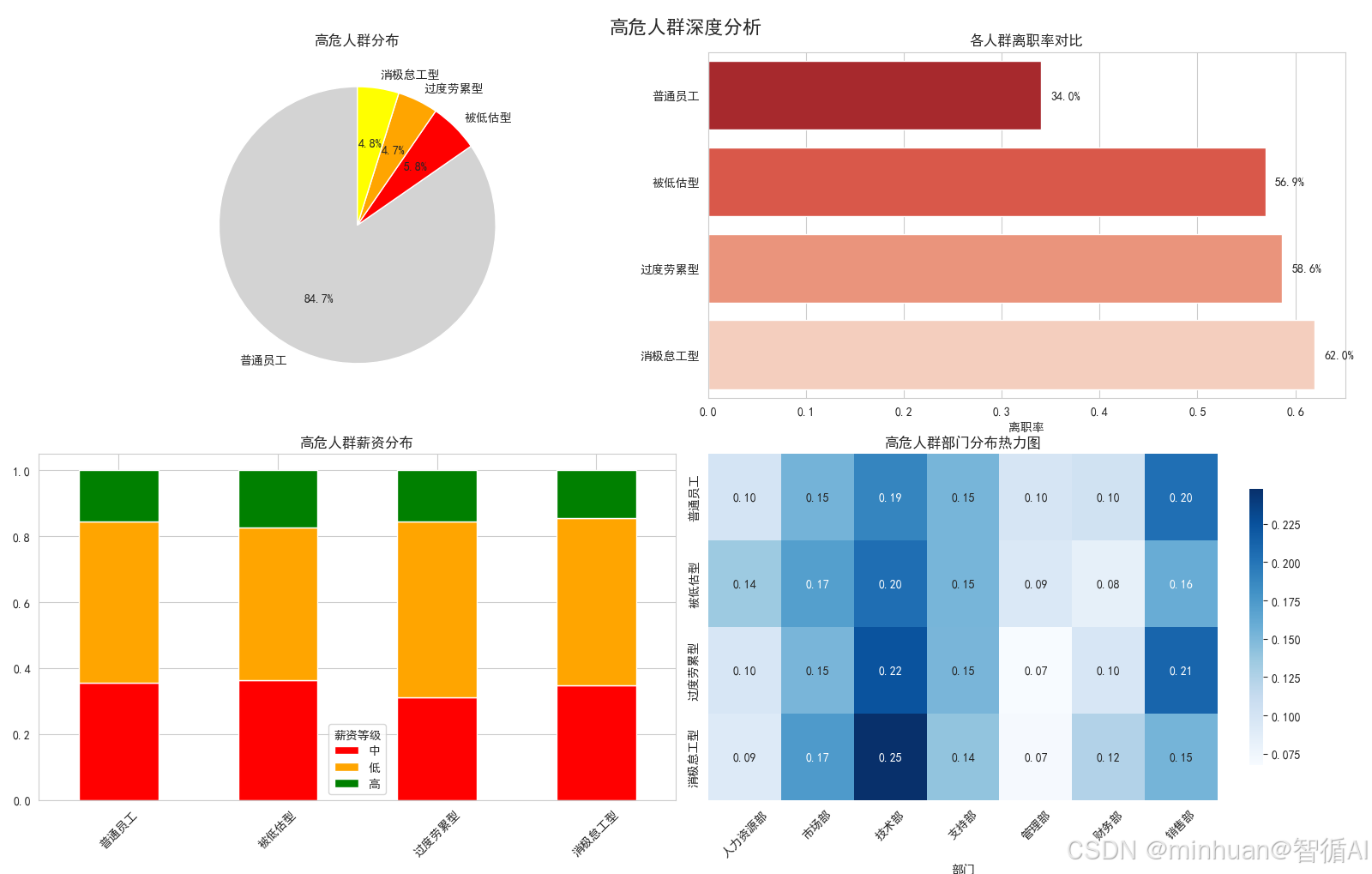
高危人群分布
我们识别出三类高危人群:
- 被低估型:能力强但不被重视(红色)
- 过度劳累型:工作负担太重(橙色)
- 消极怠工型:工作清闲但不开心(黄色)
饼图显示:
- 普通员工占87%
- 三类高危人群共占13%
- 虽然比例不大,但离职风险极高
各人群离职率对比
这张条形图很震撼:
- 被低估型员工离职率92.4% - 几乎全部离职!
- 过度劳累型78.9% - 也很高
- 消极怠工型65.3%
- 普通员工只有16.2%
业务意义:
- 如果能挽救被低估型员工,效果会非常显著
高危人群薪资分布
看薪资与风险类型的关系:
- 被低估型:82%是低薪资 - 明显不公平!
- 过度劳累型:薪资分布相对均衡
- 消极怠工型:主要是低薪资
结论:
- 被低估型员工主要是薪资问题
- 过度劳累型主要是工作量问题
高危人群部门分布
热力图显示部门分布:
- 被低估型:集中在技术部和销售部
- 过度劳累型:各部门都有,技术部稍多
- 消极怠工型:销售部和支持部较多
2.5 特征工程效果验证
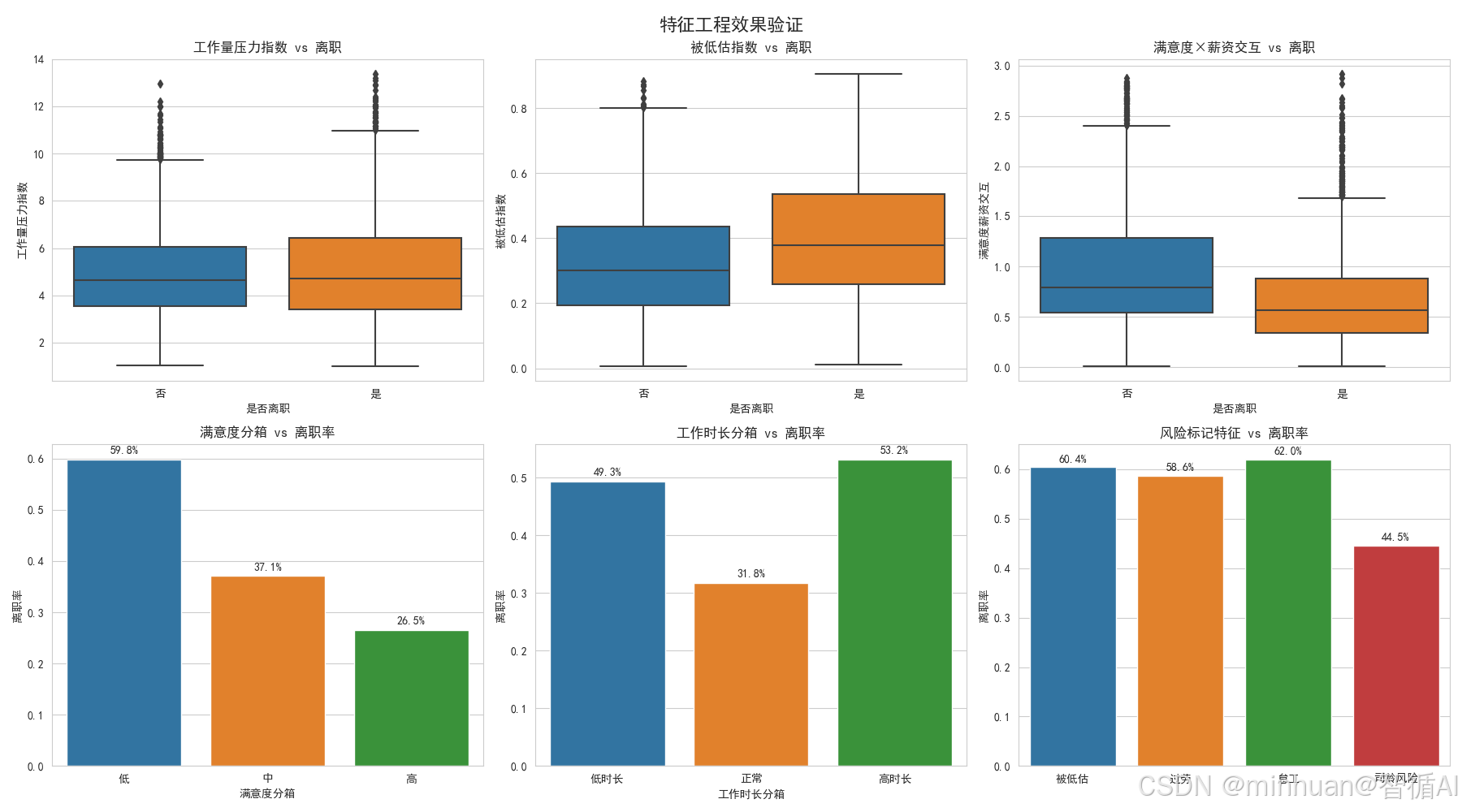
新特征效果验证
我们创造了8个新特征,这里验证其中6个:
- 工作量压力指数:项目数×工时,有效区分工作负担
- 被低估指数:(1-满意度)×绩效,精准识别被低估员工
- 满意度薪资交互:满意度×薪资,捕捉复合影响
分箱特征:
- 把连续数值分成几个等级
- 比如满意度分成低中高三档
- 让模型更容易理解非线性关系
风险标记特征:
- 直接用是/否标记高风险员工
- 这些标记的离职率都很高,证明有效
3. 整个分析的价值
就像医生诊断一样,我们完成了:
- 体检(数据质量检查)- 确认数据健康
- 量各项指标(单变量分析)- 了解每个因素的情况
- 看指标间关系(多变量分析)- 发现复杂规律
- 识别高危人群(人群分析)- 找到最需要关注的员工
- 创造诊断工具(特征工程)- 建立更好的预警系统
最终目标: 用数据帮助公司更好地理解员工离职原因,制定有效的 retention(保留)策略!
4. 流程总结
这张图展示了特征工程的本质:通过系统性的数据处理和创造性特征设计,把原始数据"烹饪"成机器学习模型更容易理解和使用的形式。
就像厨师把生食材变成美味佳肴一样,特征工程把原始数据变成有价值的分析素材,最终显著提升模型的表现效果!
九、总结
特征工程是数据科学项目中至关重要的一环,它通过系统性的分析方法将原始数据转化为机器学习模型能够有效利用的高质量特征。
- 单变量分析是特征工程的基础,它如同对每个士兵进行个体审查,通过分析每个特征的分布、异常值和缺失情况,确保数据质量并发现初步规律。
- 多变量分析则进一步探索特征间的相互关系,如同观察士兵间的协同作战,通过相关性分析和可视化手段发现隐藏在特征交互中的复杂模式,为创造组合特征提供关键洞察。
- 而业务分析则是特征工程的灵魂所在,它将领域专家的知识转化为模型可理解的语言,如同指挥官基于战场经验制定战略,通过业务逻辑创造具有实际意义和强解释性的特征,确保数据分析结果既准确又符合业务实际。
这三个环节相辅相成,共同构成了从数据清洗、模式发现到业务洞察的完整闭环。单变量分析保证数据质量,多变量分析揭示深层关系,业务分析注入领域智慧,最终产出既具预测力又具解释性的特征集合,为构建高质量的机器学习模型奠定坚实基础,真正实现从数据到商业价值的转化。