【医学影像 AI】基于对抗学习的多层次密集传输知识蒸馏用于AP-ROP检测
更多内容请关注【医学影像 AI by youcans@Xidian 专栏】
【医学影像 AI】基于对抗学习的多层次密集传输知识蒸馏用于AP-ROP检测
- 0. 论文简介
- 0.1 基本信息
- 0.3 摘要
- 1. 引言
- 2. 相关工作
- 2.1 ROP的自动筛查
- 2.2 知识蒸馏
- 2.3 基于对抗学习的知识蒸馏
- 3. 方法
- 3.1. KD原理
- 3.2. 多级密集传递KD
- 3.3. 对抗学习在知识蒸馏中的应用
- 4. 实验
- 4.1 材料与实验设置
- 4.2 实验结果
- 4.3 验证性研究
- 4.3.1 对抗学习
- 4.3.2 损失函数
- 5. 讨论
- 5.1 验证
- 5.2 批量大小的影响
- 5.3 局限性和未来工作
- 6. 结论
- 7. 附录:混淆矩阵
- 8. 参考文献
0. 论文简介
0.1 基本信息
2023 年,深圳大学 雷柏英 ,深圳市眼科医院 张国明 等在 Medical Image Analysis 发表论文 “基于对抗学习的多层次密集传输知识蒸馏用于AP-ROP检测(Adversarial learning-based multi-level dense-transmission knowledge distillation for AP-ROP detection)”。
本研究的亮点在于:
- 我们设计了一种新颖的知识蒸馏(Knowledge Distillation, KD)模型,基于多层次密集传输的 TAKD网络(Teacher-Assistant Knowledge Distillation)和对抗学习机制(Adversarial Learning Mechanism),用于使用彩色眼底图像检测ROP(早产儿视网膜病变)和AP-ROP(急性进展性早产儿视网膜病变)。
- 在信息传输过程中,充分利用了上层和下层网络中最后特征提取层和输出层的特征。
- 采用对抗学习机制,迫使下层网络生成接近上层网络的特征。据我们所知,这是首个联合使用对抗学习和密集TAKD模型的框架。
论文下载: sciencedirect
引用格式:
Hai Xie, Yaling Liu, Haijun Lei, et al. Adversarial learning-based multi-level dense-transmission knowledge distillation for AP-ROP detection, Medical Image Analysis, Vol 84, February 2023, https://doi.org/10.1016/j.media.2022.102725
### 0.2 关键贡献
- 对抗学习:研究采用对抗学习技术来提高检测模型的鲁棒性和准确性。这种方法有助于训练模型更好地处理输入数据的变异性,这对于医学图像分析至关重要。
- 多级知识蒸馏:该方法利用多级知识蒸馏框架,使模型能够从不同层次的信息中学习。这增强了模型从训练数据到未见情况的泛化能力,特别是在医学诊断中尤为重要。
- 密集传输机制:该方法的密集传输机制确保信息在模型的不同层之间有效共享,从而提高了检测ROP的性能。
0.3 摘要
急性进展性早产儿视网膜病变(Aggressive Posterior Retinopathy of Prematurity, AP-ROP)是导致早产儿失明的主要原因。自动诊断方法已成为检测AP-ROP的重要工具。然而,现有的大多数自动诊断方法复杂度较高,这阻碍了检测设备的开发。因此,迫切需要一种具有高模仿能力的小型网络(学生网络),能够模仿具有良好诊断性能的大型网络(教师网络)。此外,如果由于教师网络和学生网络之间的差距过大而导致学生网络过小,诊断性能将会下降。
为了解决上述问题,我们提出了一种基于对抗学习的多层次密集知识蒸馏方法,用于检测AP-ROP。具体而言,预训练的教师网络通过密集传输模式训练多个中等规模网络(即教师助理网络)和一个学生网络,其中所有上层网络的知识都被传输到当前的下层网络。为了确保两个相邻网络能够充分蒸馏知识,采用对抗学习模块迫使下层网络生成与上层网络相似的特征。
大量实验表明,我们提出的方法能够实现从教师网络到学生网络的有效知识蒸馏。我们在私有数据集和公共数据集上取得了显著的知识蒸馏性能,这为设计实用的轻量级眼底疾病检测系统提供了新的思路。
提出了一种基于对抗学习的多层次密集知识蒸馏方法,旨在解决AP-ROP检测中复杂模型难以部署的问题。通过引入教师助理网络和对抗学习机制,该方法成功实现了从教师网络到学生网络的高效知识传递,为开发轻量级、高性能的眼底疾病检测系统提供了新的解决方案。
1. 引言
早产儿视网膜病变(Retinopathy of Prematurity, ROP)通常发生在早产儿中,是导致失明的主要原因(Brown et al., 2018)。ROP的特征是视网膜血管发育异常,病情进展迅速,如果不及时干预和治疗,会导致不可逆的视力损伤。正如(Campbell et al., 2020; Hutchinson, 2018)所述,世界卫生组织在2012年报告称,每年有1500万早产儿出生,其中相当一部分早产儿会出现一些生理功能障碍,包括由ROP引起的失明。如果轻度或中度ROP未得到干预,将会发展为急性进展性早产儿视网膜病变(Aggressive Posterior Retinopathy of Prematurity, AP-ROP),这是ROP中最严重的类型之一(Ahn et al., 2017)。根据(Sen et al., 2020),筛查是ROP管理的第一步。然而,不同地区或国家的筛查标准不同,且不同眼科医生对ROP的判断可能存在主观差异。准确识别ROP和AP-ROP对临床医生做出科学判断以及选择诊断和治疗方法具有重要意义。特别是,AP-ROP的发病率相对较低,许多眼科医生缺乏区分ROP和AP-ROP的经验。
图1 展示了ROP、AP-ROP和正常眼底图像的示例。从图1中可以看出,ROP和AP-ROP的外观和特征非常相似。一些常规ROP的特征在采集的图像中并不明显,这对眼科医生准确快速识别ROP和AP-ROP构成了巨大障碍。因此,计算机辅助诊断在帮助临床医生对ROP和AP-ROP进行客观评估方面变得尤为重要,这也引起了广泛关注(Campbell et al., 2020b; Redd et al., 2019)。然而,现有方法由于复杂度高而效率低下,无法为眼科医生提供快速反馈。临床上,快速筛查非常重要,因为它可以帮助医生从大量图像中快速识别出问题病例,从而减少工作量。

*图1. 正常ROP、AP-ROP和正常视网膜图像的示例。
正常ROP图像表现为轻微的边界嵴和分界线。
AP-ROP的外观表现为血管扩张、曲张和视网膜出血。
*
近年来,深度学习技术发展迅速,由于深度学习模型对硬件的高要求,计算机硬件也在不断升级。在实际应用中,深度学习模型通常需要具有较小的体积和较少的参数,以满足小存储和高速处理的需求。因此,一些小型模型被开发出来以满足小型设备或移动设备的部署需求(例如MobileNet系列(Howard et al., 2019; Howard et al., 2017; Sandler et al., 2018)和ShuffleNet(Ma et al., 2018; Zhang et al., 2018))。然而,由于深层高级特征的表示能力有限,这些小型模型不足以在所有任务中取得良好性能。为了解决这一问题,Hinton等人提出了知识蒸馏(Knowledge Distillation, KD)的概念(Hinton et al., 2015),其中整个深度学习网络由两个网络组成(即大型的教师网络和小型的学生网络),学生网络通过约束条件学习教师网络的特征表示。尽管现有的KD方法在将知识从教师网络传递到学生网络方面取得了巨大成功(Ju et al., 2021; Wang and Yoon, 2021),但大型教师网络并不总能取得良好效果。
根据(Mirzadeh et al., 2020),当教师网络和学生网络之间的规模差距较大时,KD方法并不总能表现良好(例如,教师网络规模较大或容量较大时,小型学生网络模仿教师网络特征表示的能力有限)。为了解决这一问题,(Mirzadeh et al., 2020)首次提出了教师助理知识蒸馏(Teacher Assistant Knowledge Distillation, TAKD)框架,该框架引入了中间模型作为教师助理(TA)网络,将教师网络的知识传递给学生网络,并填补教师网络和学生网络之间的差距,其中教师模型的知识被蒸馏到TA模型,学生模型仅模仿TA模型。然而,上层模型和下层模型之间的蒸馏误差会一直直接传递,这可能导致误差雪崩问题,进而使学生模型无法从教师模型中学到足够的信息。为了改进这一缺点,受DenseNet(Huang et al., 2017)在图像分类中取得优异性能的启发,Son等人设计了一种密集引导的KD模型(Son et al., 2021),该模型采用多个TA模型,并充分利用每一层级的学习知识,使学生模型能够学习所有前级模型,而不仅仅是父级网络。尽管(Son et al., 2021)取得了良好的分类性能,但该模型仍然遗漏了教师-学生网络对之间的一些重要特征信息。
为了解决上述问题和挑战,我们提出了一种新颖的KD模型,该模型包含一对教师-学生网络和多个TA网络。与(Son et al., 2021)类似,这些子网络的输出通过密集连接模式进行整合。不同之处在于,我们的模型不仅利用了所有子网络的输出层,还利用了所有子网络的最后特征提取层,以对齐和蒸馏从上层网络到下层网络的知识。特别是,采用对抗学习机制迫使下层网络生成与上层网络特征接近的特征,从而实现特征对齐,并补偿从上层网络到下层网络的知识蒸馏过程中的信息损失。大量实验表明,我们提出的框架能够有效指导学生网络从教师模型和TA模型中学习知识,适用于我们的私有ROP数据集和一个公共数据集,这确保了小型网络能够很好地模仿大型网络,并为使用彩色眼底图像设计眼底疾病计算机辅助诊断系统提供了新的思路。
总体而言,我们的主要贡献总结如下:
- 我们设计了一种基于多层次密集传输TAKD网络和对抗学习机制的新型KD模型,用于使用彩色眼底图像检测ROP和AP-ROP。
- 在信息传输过程中,充分利用了上层和下层网络的最后特征提取层和输出层的特征。
- 采用对抗学习机制迫使下层网络生成与上层网络接近的特征。据我们所知,这是首个联合使用对抗学习和密集TAKD模型的框架。
2. 相关工作
2.1 ROP的自动筛查
对于早产儿,ROP是导致失明的关键因素(Hellström等,2013)。如果能在早期发现并治疗ROP,将大大减轻家庭和社会的负担。对于眼科医生而言,不同的临床医生可能对同一病例存在主观差异,且全球眼科医生的经验普遍不足。因此,许多研究人员试图研究ROP的自动筛查系统,并提出了一些杰出的模型(Campbell等,2021;Gupta等,2019;Redd等,2019)。例如,Redd等提出了一种基于深度学习的系统来检测ROP中的加号疾病,并生成了1-9分的血管异常定量评估(Redd等,2019)。Brown等使用了两个卷积神经网络(CNNs)来完成ROP中加号疾病的自动诊断,其中一个CNN采用U-Net架构实现视网膜血管分割,另一个CNN采用Inception-v1结构预测输入图像的类别(Brown等,2018)。Taylor等利用深度算法以定量严重程度尺度监测ROP疾病进展(Taylor等,2019)。然而,这些模型由于复杂性较高,难以部署到小型设备上。
2.2 知识蒸馏
随着移动和便携式设备的普及,许多基于深度学习的应用倾向于开发小型化和对设备要求低的版本。这一需求推动了模型压缩研究的兴起(Buciluǎ等,2006;Deng等,2020),其中知识蒸馏(KD)是主要研究主题(Li等,2020b;Wang等,2019a;Zhao等,2020;Zhao等,2021)。KD的基本原理是将大型网络的知识提炼到小型网络中,使小型网络能够模仿大型网络,从而实现自身更强的特征表达能力。自Hinton等(2015)详细解释了KD的概念以来,许多KD模型被提出(Park等,2019;Wang等,2018,2019b;Yao和Sun,2020)。例如,Park等提出了关系KD模型,该模型结构化地转移输出之间的关系到个体输出本身(Park等,2019)。为了增强蒸馏能力,Yao等提出了密集跨层互蒸馏方法,以促进知识表示学习并提高转移知识的能力(Yao和Sun,2020)。Li等提出了半监督领域适应方法,以实现标注高效的心脏数据分割,其中学生网络可以通过设计的双教师模型同时从多种模态中学习标注目标数据、未标注目标数据和标注源数据(Li等,2020a)。此外,根据Mirzadeh等(2020)的研究,如果教师网络和学生网络之间的网络规模差距较大,学生网络的能力将会降低。因此,教师-助手网络(Mirzadeh等,2020;Son等,2021)被用作中间规模模型,以减少教师网络和学生网络之间的差距。
2.3 基于对抗学习的知识蒸馏
由于生成对抗网络(GANs)由Goodfellow等(2014)提出,各种GAN被设计用于解决不同的任务,如图像分割(Hu等,2020;Wang等,2019c),合成(He等,2021;Yang等,2019),分类(Tan等,2021;Xie等,2020)和领域适应(Li等,2020c;Mahmood等,2018)。在本文中,对抗学习被采用以促使低层网络生成与高层网络相似的特征。当KD模型从教师网络向学生网络转移知识时,特征信息的损失是不可避免的。因此,一些研究人员探索了使用对抗学习机制对齐教师网络和学生网络的特征空间(Kundu等,2019;Liu等,2020;Nguyen-Meidine等,2021;Wang等,2018),因为对抗学习策略可以促使学生网络生成接近教师网络的特征。例如,Shen等提出了一种集成模型,从多个预训练的教师网络中提取知识,其中对抗学习策略被用于对齐特征空间并引导学生网络恢复教师网络中的知识(Shen等,2019)。Zhang等利用对抗学习机制生成额外的发散样本,以增强转移知识的多样性,并进一步丰富为所设计的联合蒸馏阶段中多个分类器的预测(Zhang等,2021)。
3. 方法
为了实现计算机辅助诊断系统对ROP和AP-ROP的准确且快速筛查,本文提出了一种基于对抗学习和多级密集传递的新型KD模型。我们所提出方法的整体框架如图2所示。将在后续部分详细描述每个模块。
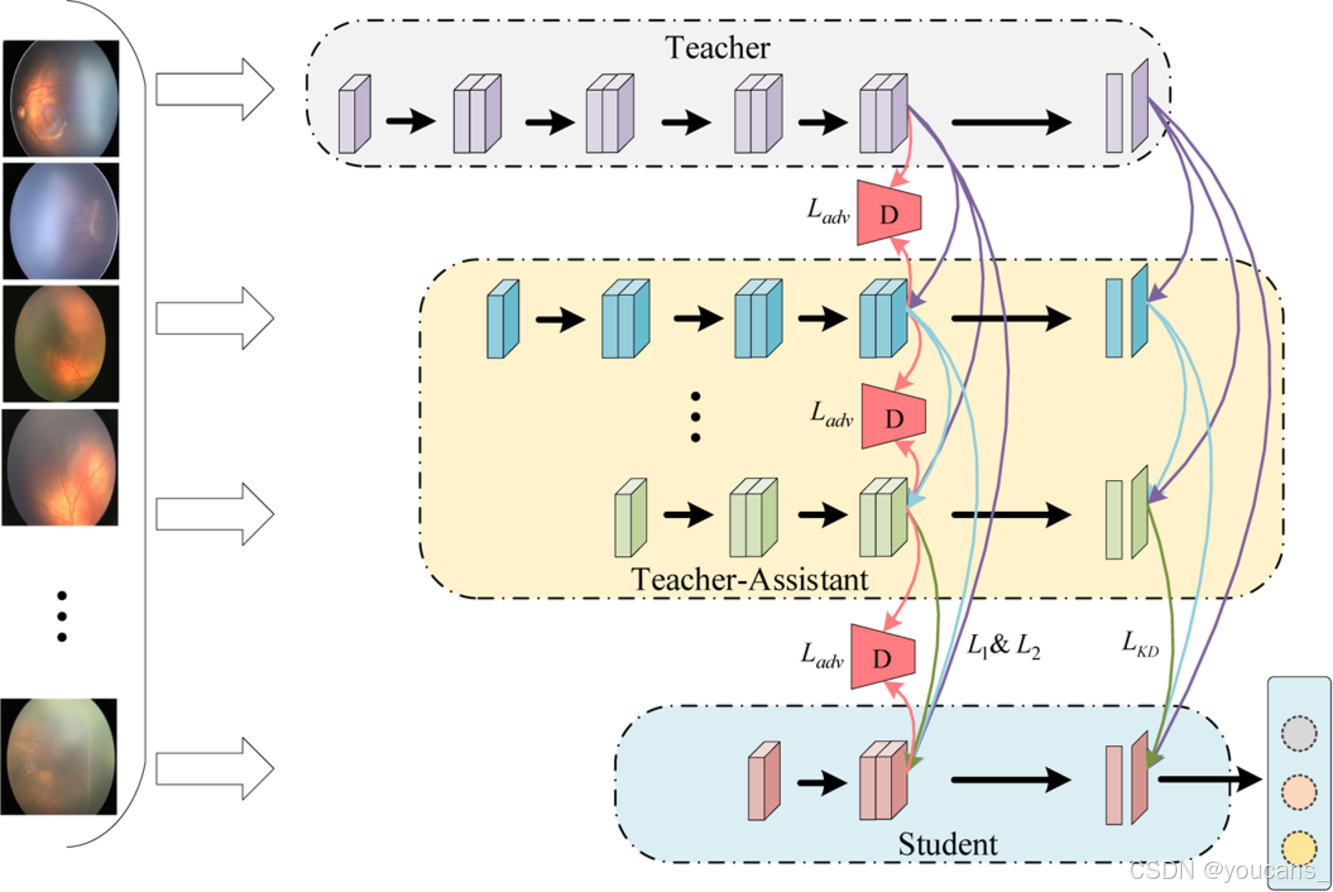
图2. 所提出方法的架构。
整个框架由一对教师-学生网络和多个教师-助手网络组成。大型教师网络的知识逐步提炼到小型网络中,多个教师-助手网络被用来从教师网络学习知识,以减少教师网络和学生网络之间的巨大差距。
为了避免信息损失过大,当前网络和所有前网络的输出层均通过KD损失计算,最后特征提取层的特征受到L1范数和L2范数的约束。
特别地,为了进一步减少特征信息损失,采用了对抗学习模块以对齐两个相邻网络的特征空间。
3.1. KD原理
KD的基本原理是,大型教师网络通过训练数据集实现良好的性能,而小型学生网络通过训练被设计为模仿教师网络的能力,从而高效地获得良好的性能,由于参数较少。正如Hinton等(2015)中的首次广泛描述,全连接层输出和logits(即softmax层输出)被用作教师网络和学生网络的学习知识。假设To和So分别表示教师网络和学生网络的输出logits,ytr表示真实标签。选择KL散度函数作为KD损失,定义为LKD。To和So的输出logits被计算以获得KD损失,可以表示为:
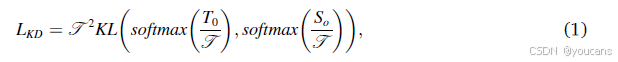
其中T是温度超参数,用于控制从教师网络和学生网络输出生成的软化信号。除了KD损失外,学生网络的输出和真实标签ytr还通过交叉熵损失进行计算,以监督生成的信息,定义为:

总体而言,最终的损失函数通过平衡参数λ集成,可以表示为:

3.2. 多级密集传递KD
如(Mirzadeh等,2020)所证明的,教师网络和学生网络之间的巨大差距可能导致学生网络从教师网络学习到的知识不足。如果我们希望设计一个足够小的网络以满足临床效率的要求,网络和教师网络之间存在巨大差距,这将导致学习能力大大降低。因此,预测性能不佳。为了解决这一问题,(Mirzadeh等,2020;Son等,2021)利用多个教师辅助网络作为中间规模的网络,从教师网络向学生网络传递知识。受此启发,我们提出了一种多级密集传递KD模型。在这个模型中,选择在ImageNet数据集上预训练的ResNet-34模型作为教师网络来训练我们的ROP数据,并获得训练好的 ResNet-34 模型,该模型可以传递给教师辅助网络和学生网络。如图2所示,当前网络可以通过密集传递模式从所有前网络中提取知识。数学定义如下。
我们定义教师辅助网络为TAi,i = 1, 2, … 位于教师网络T和学生网络S之间,损失表示为LTAi。因此,学生网络的损失可以表示为:

其中符号→表示从上一级网络传递知识的流程。如图2所示,每个网络的最后一层特征层的输出特征也被利用L1范数和L2范数来约束教师辅助网络和学生网络。上一级和下一级网络的特征分别表示为fup和flow。因此,特征约束的损失可以定义为L1 = |fup - flow|_1和L2 = ||fup - flow||_2。根据公式(3)整合损失后,学生网络的总损失可以总结如下:
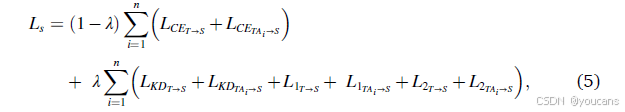
最后,多级密集传递基于的知识蒸馏流程可以总结在算法1中。

3.3. 对抗学习在知识蒸馏中的应用
在本文中,对抗学习机制应用于每个网络的最后一层特征提取层的特征中,强制教师辅助网络或学生网络生成与教师网络相似的特征,从而在知识蒸馏过程中进一步减少特征信息损失。如图2所示,判别器用于区分相邻两个网络之间上一级网络生成的特征是否为真特征。
所使用的判别器包括两个卷积层,卷积核大小设为1,一个自适应平均池化层,一个全连接层和一个Sigmoid层。我们提出判别器的结构如图3所示。我们定义j级判别器为Dj。相邻的两个网络分别表示为Netj和Netj+1,其中Netj被视为教师网络,Netj+1表示待训练的学生网络。因此,对抗损失函数可以表示为:
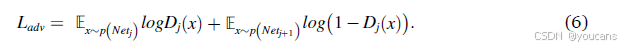
请注意,我们的判别器仅在两个相邻的网络之间使用,并未将密集连接策略应用于判别器中。
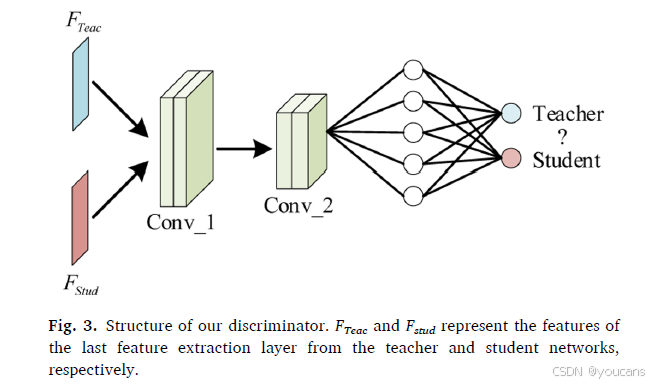
图3. 我们提出的判别器结构。FTeac和Fstud分别表示教师网络和学生网络的最后一层特征提取层的特征。
4. 实验
4.1 材料与实验设置
所使用的ROP数据集由深圳眼科医院使用RetCam3拍摄,采集时间跨度从2009年到2018年。该数据集包含13,508张彩色眼底图像,由三位专业眼科医生标注。我们舍弃了眼科医生观点不一致和质量较差的图像。最终,我们获得12,095张用于实验的图像,其中包括1698例AP-ROP、3898例常规ROP和6499例正常眼底图像。在实验中,我们采用5折交叉验证获得结果。此外,我们选择结果最接近均值的模型训练参数作为教师网络或教师辅助网络。特别地,我们使用该数据集进行两项任务:一项是检测ROP和正常眼底图像(即二分类任务),另一项是从正常眼底图像中分类AP-ROP和常规ROP(即三分类任务)。所有眼底图像均调整为224 × 224像素作为所用模型的输入。我们使用Pytorch库训练和测试所有模型。通过一个NVIDIA TITAN XP GPU加速训练和测试的速度。学生网络的优化器选择Adam,参数为betas = (0.9, 0.997),eps = 10e-8。判别器使用具有动量0.9和权重衰减5 × 10e-5的SGD作为优化器。学生网络和判别器网络的初始学习率分别设置为0.001,每30和20个epoch后分别乘以0.1。最大epoch设置为120,mini-batch的大小设置为32。我们采用准确率(Acc)、精确率(Pre)、召回率(Rec)和F1分数(F1)作为评估指标。
4.2 实验结果
在我们的实验中,有两个任务需要完成:任务1是检测ROP和正常图像,任务2是分类AP-ROP、常规ROP和正常图像。任务1可以帮助临床医生进行初步筛查。为了进一步判断患者所患ROP的严重程度,任务2可以帮助临床医生确定ROP的类别,以便及时实施最合适的治疗。我们主要采用残差结构构建小型网络。根据残差结构的数量,我们设计了18层、14层、10层、8层和6层的网络,其中6层的最小模型作为学生网络,其他网络作为教师辅助模型。详细结构信息见表1。
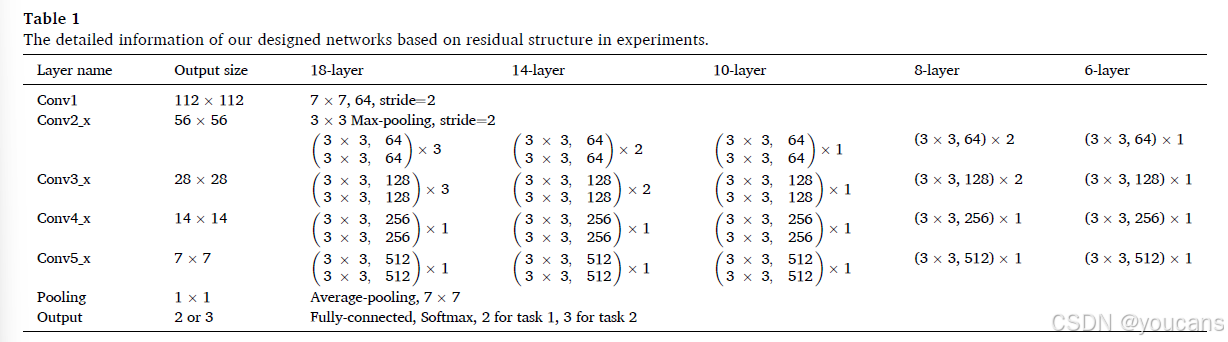
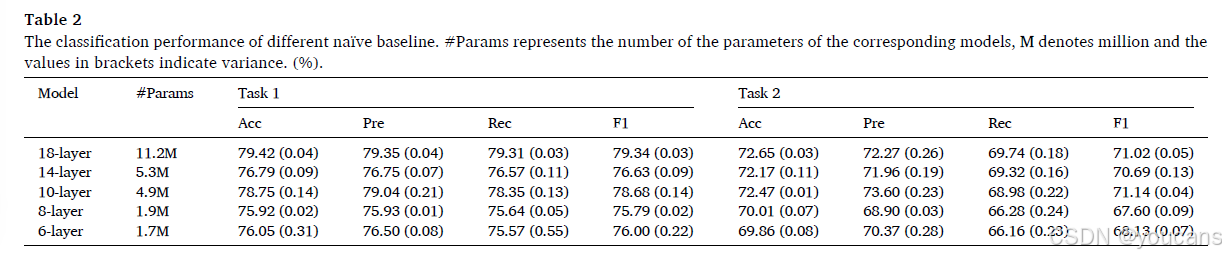
基于设计的网络架构,我们首先实现朴素基线以展示在不使用知识蒸馏的情况下提取特征的能力。实验结果见表2。从表2可以看出,所设计的朴素网络获得的结果并不理想。由于这些网络未使用大规模数据集的预训练参数,导致这些网络学习到的特征不足。
为了解决这一问题,KD算法是一个很好的解决方案,它可以将使用ImageNet预训练参数的大网络知识蒸馏到小型网络中。通过这种方式,分类性能可以得到提升。根据实验设置,选择在ImageNet上预训练的ResNet-34模型作为教师网络,TAi(i分别设置为18、14、10、8)表示教师辅助模型。然而,为了展示所设计模型的有效性,我们首先使用这些教师辅助模型作为学生网络进行实验,即Si(i = 18、14、10、8、6)代表直接从教师网络提取知识的学生网络。
任务1不同蒸馏网络的检测性能见表3,可以看出由于设计的对抗学习模块和损失函数,所获得的蒸馏结果非常理想,这将在后续的消融实验中得到验证。通过比较表2和表3,我们可以看到分类性能得到了显著提升。例如,6层残差网络的任务1和任务2的准确率分别提高了18.19%和22.48%。这些改进的结果得益于使用ImageNet数据集预训练参数的教师网络(ResNet-34)以及教师网络和学生网络之间的KD。
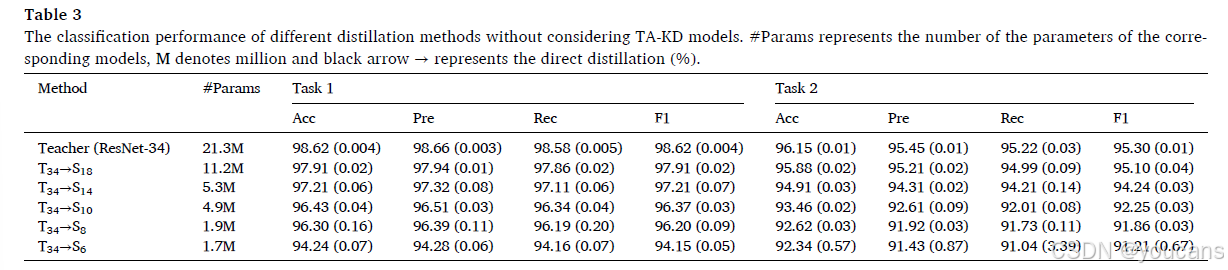
当网络规模缩小近11倍时,任务1和任务2的准确率分别下降了4.38%和3.81%。此外,随着学生网络规模的减小,预测性能减弱,这验证了(Mirzadeh et al., 2020)的观点,即教师网络和学生网络之间的差距越大,获得的蒸馏性能越差。为了证明教师辅助模型可以补偿由于教师网络和学生网络之间差距导致的性能下降,我们使用教师辅助模型作为中间规模模型,从教师网络蒸馏知识到学生网络。实验结果见表4,其中TAi(i = 18、14、10、8)表示相应的教师辅助网络的规模。参数数量与表3相同,因为仅训练学生网络,教师和TA模型提供最后一层特征提取层和输出logits的特征。从表4可以看出,通过在教师网络和学生网络之间设计教师辅助模型,所有评估指标均得到改善,这证明了(Mirzadeh et al., 2020)中的结论,即中间规模的TA模型可以更有效地从教师网络蒸馏知识到学生网络。由于使用TA模型减小了差距,任务1和任务2的分类性能可以进一步提升。
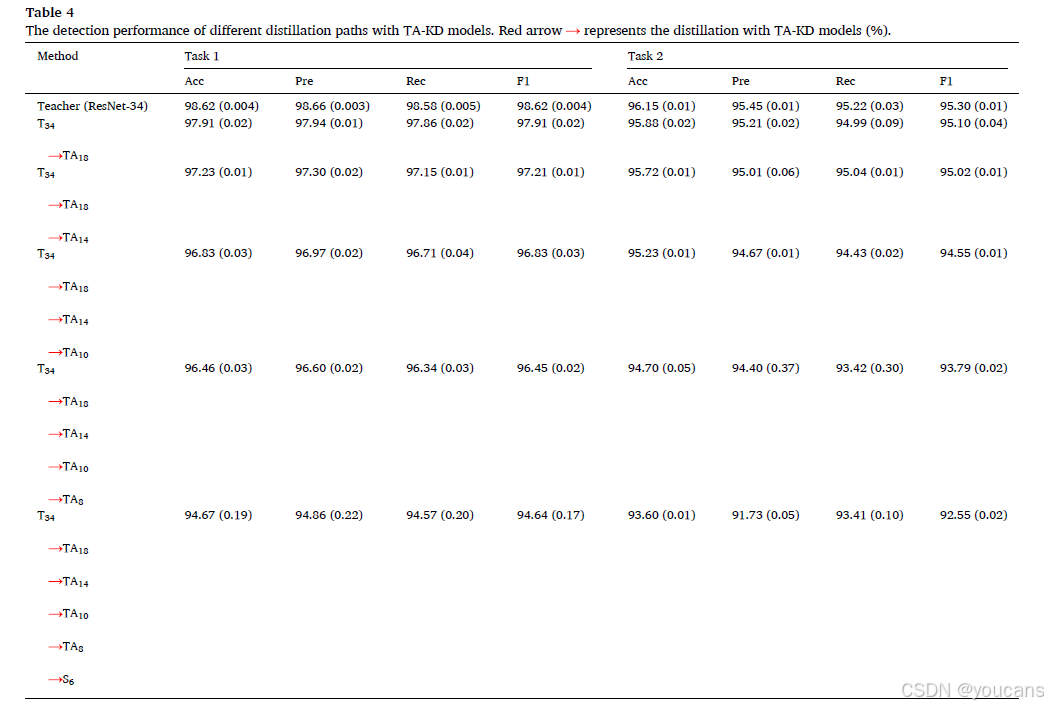
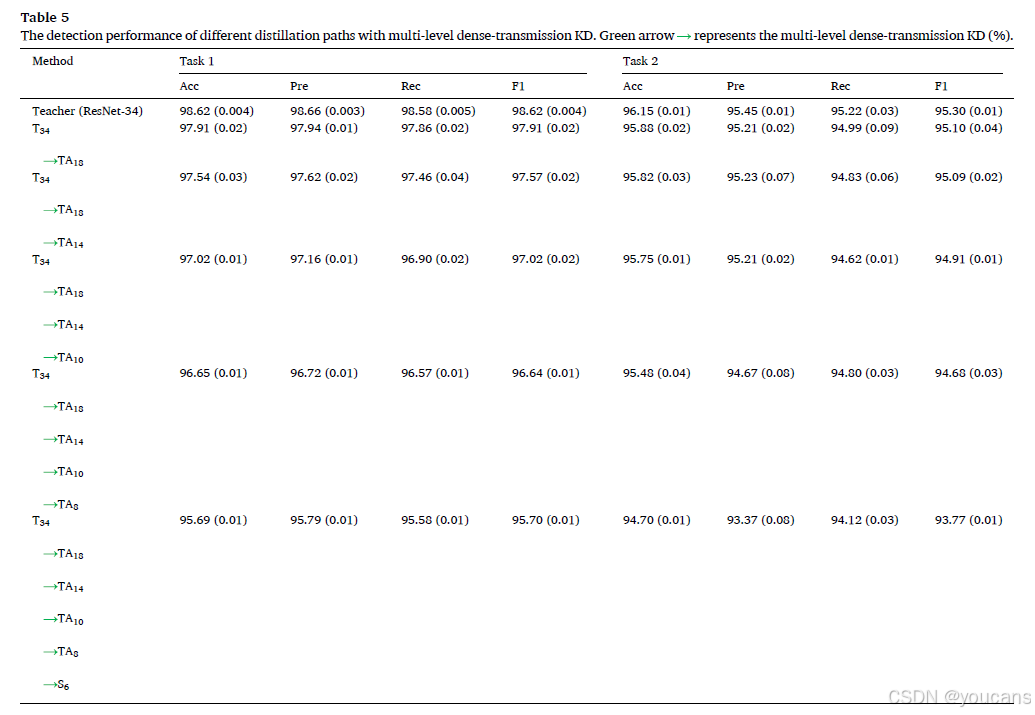
为了证明我们提出算法1的有效性,我们使用从最后一层特征提取层和输出logits的特征连接构建的不同教师辅助模型进行了一系列实验。实验结果见表5。我们可以看到,与仅使用单路径(即直接使用TA模型从教师网络蒸馏知识到学生网络)相比,多级密集传输KD设计的所有结果均有所提升。例如,“T34 TA18 TA14 TA10 TA8 S6”路径的任务1准确率比“T34 TA18 TA14 TA10 TA8 S6”路径高1.0%,任务2的准确率也有超过1个百分点的提升,这表明使用TA模型和多级密集传输的对抗学习模块可以减少特征信息的损失并提升整体分类性能。
此外,我们进行了t-SNE可视化,以比较使用三种蒸馏策略学习到的特征,如图4所示。结果仅来自四种路径,其中选择了14层、10层、8层和6层残差模块作为学生网络。由于上述四种路径满足多级密集传输KD机制的条件,我们可以观察到,与前两行相比,最后一行能够更好地分离不同类别并聚类相同类别。

图4. 三种知识蒸馏策略在任务1和任务2中不同蒸馏路径的t-SNE可视化结果。从上到下:不使用TA模型、使用TA模型和提出的方法。从左到右:选择14层、10层、8层和6层残差模块作为学生网络的蒸馏路径。
4.3 验证性研究
4.3.1 对抗学习
作为主要贡献,判别器是提升基线网络性能的重要模块,并进一步增强所有蒸馏路径。因此,我们进行了一项不整合判别器的比较实验,以证明对抗学习机制对多级网络的有效性。任务1和任务2的结果分别见表6和表7。此外,我们仅显示相邻网络的结果,因为对抗学习模块仅应用于相邻网络。
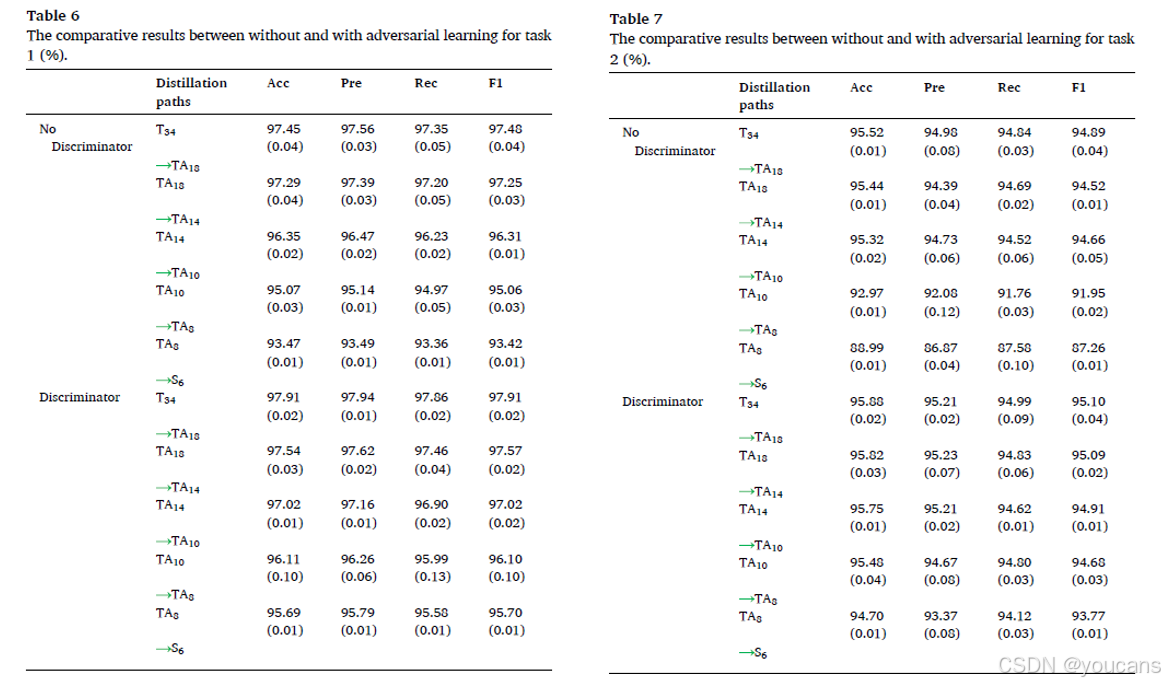
从表6和表7可以看出,大多数不使用对抗学习模块的蒸馏路径的结果比使用对抗学习模块的相应路径低0.5%以上。例如,对于任务1的蒸馏路径TA14 TA10,未设计判别器的准确率、精确率、召回率和F1分别是0.67%、0.69%、0.67%和0.71%低于设计判别器的路径TA14 TA10。对于任务2的蒸馏路径TA10 TA8,由于缺少判别器,准确率、精确率、召回率和F1分别降低了2.51%、2.59%、3.04%和2.73%。特别是对于具有6层残差模块的学生网络,删除设计的判别器后性能下降更为严重。例如,对于任务2的蒸馏路径TA8 S6,未判别器的准确率降低了5.71%。这些结果表明,对抗学习模块可以有效地使浅层网络学到的特征与相邻深层网络对齐,并减少从教师网络到学生网络蒸馏过程中的信息损失,特别是在教师网络和学生网络之间的差距较大时。
为了展示添加判别器后浅层网络的优异特征学习能力,我们进行了Grad-CAM可视化,使用从最后一层特征提取层学到的特征生成类激活图(CAM)。Grad-CAM可视化结果见图5。通过观察比较结果,我们可以发现,带有判别器的模型能够比没有判别器的模型更好地学习疾病特异性特征。例如,对于蒸馏路径T34→TA18,教师辅助网络可以从教师网络中学习到更多关于AP-ROP和常规ROP的信息,特别是带有判别器的网络能够学习到更精细的特征。然而,随着网络规模的减小,小规模网络的特征模仿能力减弱,与疾病类型相关的学到的信息也减少。尽管如此,与没有判别器的网络相比,带有判别器的网络可以学到更多有用的信息。例如,TA8 S6(图5的最后一列),使用没有对抗学习模块的提议模型无法学习到AP-ROP和常规ROP的一些病变特征。这一现象在所选的常规ROP眼底图像中更为明显,因为该眼底图像的病变特征模糊且对比度很低,导致学生网络无法学习到足够的特征并生成与教师网络提取特征相匹配的准确特征。
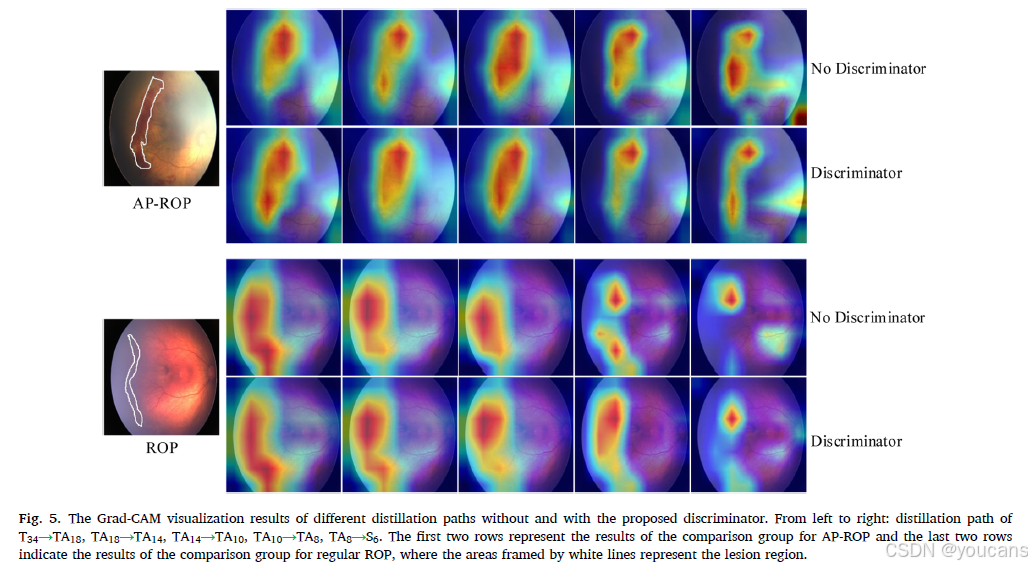
图5. 不同蒸馏路径在使用和未使用提议判别器情况下的Grad-CAM可视化结果。从左到右:蒸馏路径T34 TA18、TA18 TA14、TA14 TA10、TA10 TA8、TA8 S6。前两行表示AP-ROP比较组的结果,后两行表示常规ROP比较组的结果,其中用白色线条框出的区域代表病变区域。
4.3.2 损失函数
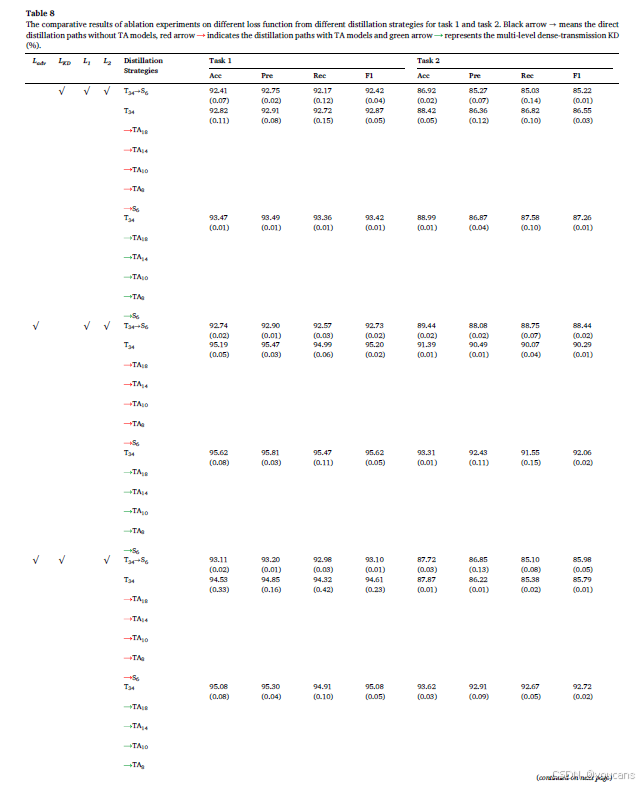
如第3节所述,使用了多个损失函数来优化训练过程。为了展示所使用损失函数对提升性能的有效性,我们使用具有6层残差结构的学生网络进行了一系列消融实验。实验结果见表8,其中符号“√”表示该损失函数在训练阶段被采用,蒸馏策略的定义与表3、表4和表5相同。
如表8所示,与所有损失函数在训练阶段都被采用的提议方法相比,当比较三种蒸馏策略中任一损失函数被移除时,任务1和任务2的所有分类结果均有所下降,尤其是在删除对抗损失和MSE损失时。例如,对于蒸馏路径T34→S6,不使用MSE损失函数的模型在任务1和任务2中的准确率分别比使用MSE损失函数的模型降低了超过10%。然而,对于任务1和任务2,设计的多级密集传输KD模型在是否使用MSE损失函数的情况下,准确率差异显著减小(即任务1和任务2的差异准确率分别为3.39%和6.32%)。此外,我们观察到,使用教师辅助模型作为中间规模模型的TA模型的性能优于不使用TA模型的模型,使用多级密集传输KD模型的性能优于仅使用TA模型的模型。这表明教师网络和学生网络之间存在差距。提出的多级密集传输KD模型可以有效缓解由于教师网络和学生网络之间差距较大而导致的KD过程中的信息损失。
5. 讨论
5.1 验证
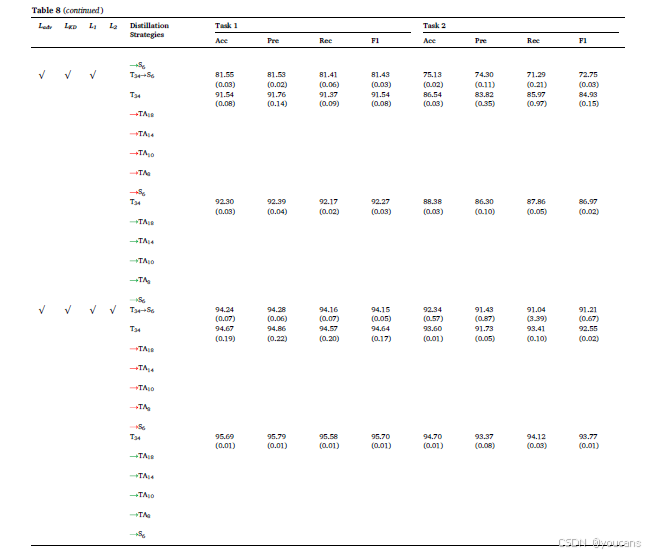
在本节中,我们在一个公开数据集上进行了一系列实验,以验证所提出模型的有效性。该公开数据集由多个医疗中心收集,称为DDR,用于实现糖尿病视网膜病变(DR)分级、病变分割和对象检测任务。根据 (Li et al., 2019) 的描述,DDR 包含来自147个医疗中心的9598名患者的13,673张彩色眼底图像。此外,收集的图像由42种类型的眼底相机在45°视场下拍摄。因此,原始图像的这些条件给DR识别带来了巨大的挑战。在我们的实验中,仅针对DR分级任务在DDR数据集上进行实验,以证明所提出模型设计的有效性。在 (Li et al., 2019) 中,DR的分级定义为六个类别:无DR、轻度DR、中度DR、重度DR、增殖性DR和无法分级。对于DDR数据集的分区,我们采用了与 (Li et al., 2019) 相同的设置,即50%用于训练,20%用于验证,30%用于测试。因此,训练、验证和测试数据集分别包含6835、2733和4105张图像。对于实验设置,所有图像均调整为224×224大小,批量大小设置为32。在训练过程中,输入图像通过颜色增强、随机翻转和旋转进行增强。根据 (Li et al., 2019) 的描述,验证集和测试集的结果均用于DR分级。因此,作为验证数据集,我们选择验证集的结果来验证所提出的蒸馏策略的有效性。
实验结果见表9。在 (Li et al., 2019) 中,总体准确率(OA)、平均准确率(AA)和Kappa值被选为评估指标。除了上述指标外,我们还增加了F1分数(F1)来评估所提出的蒸馏策略。根据 (Li et al., 2019) 的报道,所展示的模型分别实现了82.84%、62.66%和74.38%的OA、AA和Kappa值。然而,我们使用预训练于ImageNet数据集的ResNet-34模型作为教师网络来训练DDR数据集,分别实现了84.08%、66.03%、75.43%和63.81%的OA、AA、Kappa和F1值。我们分析了使用包含颜色增强、随机翻转和随机旋转的数据增强方法可以提高分类性能的原因。从表9中可以看出,当知识从T34直接蒸馏到S6时,直接蒸馏策略会丢失大量信息,导致OA和Kappa分别下降6.11%和9.78%。通过观察蒸馏路径T34 TA18 TA14 TA10 TA8 S6,添加TA模型的蒸馏策略使OA、AA、Kappa和F1分别增加了0.59%、5.2%、1.14%和4.78%。结果表明,TA模型可以通过减少信息损失来提升分类性能,这也验证了 (Mirzadeh et al., 2020) 的观点。当蒸馏策略切换到带有对抗学习的多级密集蒸馏时,分类性能进一步提升。通过蒸馏路径T34 TA18 TA14 TA10 TA8 S6,我们可以看到,与T34→S6路径相比,OA、AA、Kappa和F1分别增加了2.31%、7.84%、3.84%和6.66%;与T34 TA18 TA14 TA10 TA8 S6路径相比,OA、AA、Kappa和F1分别增加了1.72%、2.64%、2.7%和1.88%。
为了直观地展示所提出的蒸馏策略对不同类别的改进,我们绘制了分别对应于蒸馏路径T34→S6、T34 TA18 TA14 TA10 TA8 S6和T34 TA18 TA14 TA10 TA8 S6的混淆矩阵,如图6所示。
通过观察混淆矩阵,使用TA模型的蒸馏策略可以显著提高重度和增殖性类别的准确率,从而提升整体分类性能。当使用带有对抗学习的多级密集蒸馏策略时,除了重度和增殖性类别,中度和无法分级类别也得到了改善。因此,这些结果验证了所提出的蒸馏策略的有效性。
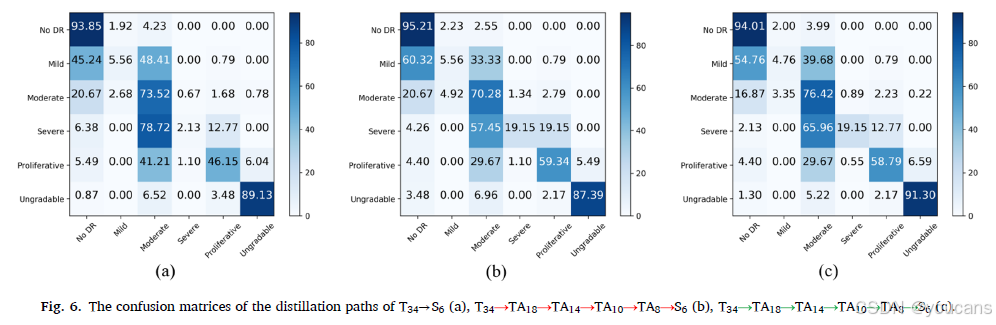
图6. 蒸馏路径T34→S6 (a)、T34 TA18 TA14 TA10 TA8 S6 (b)、T34 TA18 TA14 TA10 TA8 S6 © 的混淆矩阵。
5.2 批量大小的影响
不同的批量大小将影响整体分类性能。因此,我们实施了一对实验,通过设置不同的批量大小来选择合适的批量大小。实验结果见表10。在这些比较实验中,利用T34→S6、T34 TA18 TA14 TA10 TA8 S6和T34 TA18 TA14 TA10 TA8 S6的蒸馏路径结果来证明本文所用批量大小的可行性。在表10中,当批量大小设置为16或64时,整体性能低于批量大小设置为32的情况。例如,对于蒸馏路径T34 TA18 TA14 TA10 TA8 S6,批量大小=32的准确性分别比批量大小=64的准确性高出1.41%和0.05%。因此,在我们的实验中,我们将批量大小设置为32。

5.3 局限性和未来工作
尽管我们设计的教师-学生模型能够有效地将教师网络的知识传递给学生网络,并且在检测AP-ROP方面优于小型学生网络,取得了令人鼓舞的性能,但仍存在一些预测失败的例子,如图7所示。
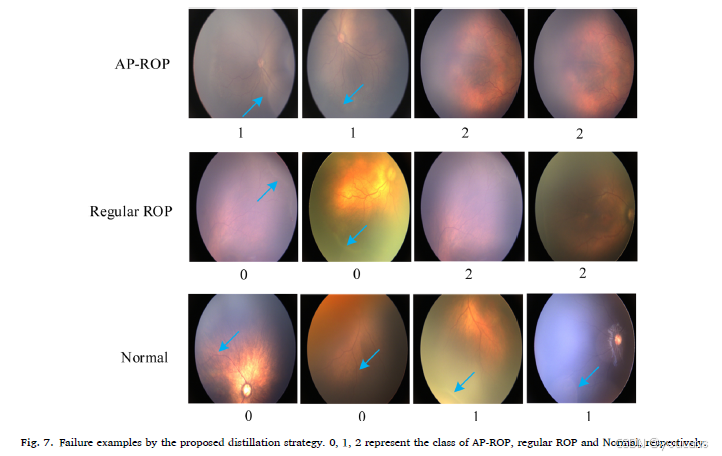
图7. 所提出的蒸馏策略的预测失败示例。0、1、2分别代表AP-ROP、常规ROP和正常类。
从图7可以看出,存在一些具有非判别特征的图像,这导致了错误分类。例如,第一行前两列的图像被认为是常规ROP,因为这些图像的特征与常规ROP的特征相似。通过第二行,我们可以看到AP-ROP和正常类别的特征与常规ROP相似,导致这些图像被错误地分类为常规ROP类型。此外,我们从包含常规ROP、APROP和正常类别的私人ROP数据集中挑选了100张图像,并请三位眼科医生进行鉴别。结果表明,这三类的平均准确率约为85%,低于本文提出方法的94.70%。这些结果表明,我们的方法不仅达到了令人满意的目标效果,而且比医生的速度更快。然而,本文仍存在一些局限性。例如,为了提取判别特征,我们采用了多个残差结构来构建TAKD模型和学生网络,导致参数仍然比几层的普通网络略多。教师网络仅使用ResNet-34模型将知识传递给浅层网络,导致教师网络的性能有限。此外,用于训练和测试本文方法的数据仅来自一个中心,数据量有限。为了解决上述局限性,我们在未来的工作中将做出以下努力。首先,应设计一些小型的普通网络以实现更高效的蒸馏。其次,应整合多个表现优异的教师以提高浅层网络的检测性能。第三,我们将从多个中心收集数据,并探索不同中心数据的特征,以增强我们所提出方法的泛化能力。
6. 结论
在本文中,我们提出了一种基于对抗学习的多级密集传输知识蒸馏模型,以避免由于教师网络和学生网络之间存在较大差距而在知识蒸馏过程中导致的信息丢失。具体而言,利用在ImageNet数据集上预训练的ResNet-34模型训练ROP数据,从而获得训练好的教师网络。不同大小的残差结构被用作中间大小的TA模型,而具有6层残差结构的网络被用作学生网络,以模拟教师网络的特征提取能力。特别是,设计了多级密集传输知识蒸馏机制,通过密集地将上层网络学到的特征信息传递到低层网络,从而补偿教师网络和学生网络之间的差距并减轻特征信息的丢失。此外,将对抗学习模块应用于相邻网络,以引导浅层网络生成接近深层网络特征的特征。因此,特征信息的丢失可以进一步减少。广泛的实验结果表明,设计的多级密集传输知识蒸馏和对抗学习模块可以使学生网络很好地模拟教师网络。
利益冲突声明
作者声明他们没有任何已知的 competing financial利益或个人关系,这些关系可能会影响本论文中报告的工作。
数据可用性声明
作者没有权限共享数据。
致谢
本工作部分得到了国家自然科学基金(项目编号:62106153, U22A2024, 82271103 和 62001302),中国博士后科学基金(项目编号:2021M692196),广东省基础与应用基础研究基金(项目编号:2020A1515110605, 2022A1515012326, 2021A1515011348 和 2020B121201001),深圳市重点医学学科建设基金(项目编号:SZXK038),广东省高水平临床重点专科深圳市专项资金(项目编号:SZGSP014),深港联合资助项目(项目编号:SGDX20190920110403741),深圳市基础研究项目(项目编号:JCYJ20190808145011259 和 JCYJ20220818095809021),深圳市科技计划项目(项目编号:JSGG20201102174200001),深圳市博士后创新成果资助计划(深圳市医学科学中心)的资助。
7. 附录:混淆矩阵
为了直观地展示所提出模型的优势,我们在表3、表4和表5中绘制了三种蒸馏策略的对比混淆矩阵,其中选择了6层残差结构作为学生网络。为了清晰地展示结果,我们将表3、表4和表5中的蒸馏策略分别定义为策略1、策略2和策略3,如图8所示。
我们可以清楚地观察到,与直接蒸馏模型和TA模型相比,所提出的方法在任务1和任务2上取得了明显的改进。实验结果表明,多级密集传输知识蒸馏模式可以在蒸馏过程中连续利用前序网络的知识,从而有效地避免信息丢失,并确保学生可以从教师网络中学习到足够的知识,从而使分类性能得到提升。
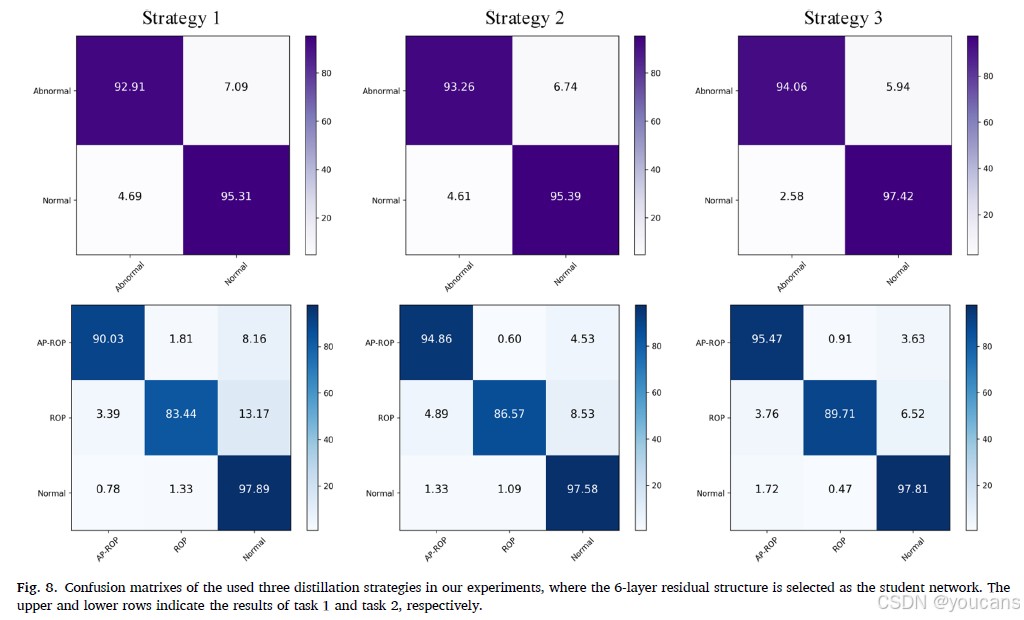
图8. 本实验中使用的三种蒸馏策略的混淆矩阵,其中选择了6层残差结构作为学生网络。上、下两行分别表示任务1和任务2的结果。
8. 参考文献
References
Ahn, Y., Hong, K., Yum, H., Lee, J., Kim, K., Youn, Y., Park, S., 2017. Characteristic
clinical features associated with aggressive posterior retinopathy of prematurity. Eye
31 (6), 924–930.
Brown, J.M., Campbell, J.P., Beers, A., Chang, K., Ostmo, S., Chan, R.P., Dy, J.,
Erdogmus, D., Ioannidis, S., Kalpathy-Cramer, J., 2018. Automated diagnosis of plus
disease in retinopathy of prematurity using deep convolutional neural networks.
JAMA ophthalmol 136 (7), 803–810.
Buciluǎ, C., Caruana, R., Niculescu-Mizil, A., 2006. Model compression. In: Proc.
SIGKDD, pp. 535–541.
Campbell, J.P., Chan, R.V.P., Ostmo, S., Anderson, J., Singh, P., Kalpathy-Cramer, J.,
Chiang, M.F., 2020. Analysis of the relationship between retinopathy of prematurity
zone, stage, extent and a deep learning-based vascular severity scale. Invest.
Ophthalmol. Vis. Sci 61 (7), 2193-2193.
Campbell, J.P., Kim, S.J., Brown, J.M., Ostmo, S., Chan, R.P., Kalpathy-Cramer, J.,
Chiang, M.F., Sonmez, K., Schelonka, R., Jonas, K., 2021. Evaluation of a Deep
Learning–Derived Quantitative Retinopathy of Prematurity Severity Scale.
Ophthalmol 128 (7), 1070–1076.
Deng, L., Li, G., Han, S., Shi, L., Xie, Y., 2020. Model compression and hardware
acceleration for neural networks: a comprehensive survey. Proc. IEEE 108 (4),
485–532.
Goodfellow, I.J., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S.,
Courville, A. and Bengio, Y. (2014). Generative adversarial networks. arXiv preprint
arXiv:1406.2661.
Gupta, K., Campbell, J.P., Taylor, S., Brown, J.M., Ostmo, S., Chan, R.P., Dy, J.,
Erdogmus, D., Ioannidis, S., Kalpathy-Cramer, J., 2019. A quantitative severity scale
for retinopathy of prematurity using deep learning to monitor disease regression
after treatment. JAMA ophthalmol 137 (9), 1029–1036.
He, K., Zhang, X., Ren, S., Sun, J., 2016. Deep residual learning for image recognition. In:
Proc. CVPR, pp. 770–778.
He, W., Sun, Y., Yang, M., Ji, F., Li, C., Xu, R., 2021. Multi-goal multi-agent learning for
task-oriented dialogue with bidirectional teacher–student learning. Knowl-Based
Syst 213, 106667.
Hellstr¨om, A., Smith, L.E., Dammann, O., 2013. Retinopathy of prematurity. The lancet
382 (9902), 1445–1457.
Hinton, G., Vinyals, O. and Dean, J. (2015). Distilling the knowledge in a neural network.
arXiv preprint arXiv:1503.02531.
Howard, A., Sandler, M., Chu, G., Chen, L.-.C., Chen, B., Tan, M., Wang, W., Zhu, Y.,
Pang, R., Vasudevan, V., 2019. Searching for mobilenetv3. Proc. CVPR 1314–1324.
Howard, A.G., Zhu, M., Chen, B., Kalenichenko, D., Wang, W., Weyand, T., Andreetto, M.
and Adam, H. (2017). Mobilenets: Efficient convolutional neural networks for
mobile vision applications. arXiv preprint arXiv:1704.04861.
Hu, X., Guo, R., Chen, J., Li, H., Waldmannstetter, D., Zhao, Y., Li, B., Shi, K., Menze, B.,
2020. Coarse-to-fine adversarial networks and zone-based uncertainty analysis for
NK/T-cell lymphoma segmentation in CT/PET images. J. Biomed. Health. Inform 24
(9), 2599–2608.
Huang, G., Liu, Z., Van Der Maaten, L., Weinberger, K.Q., 2017. Densely connected
convolutional networks. In: Proc. CVPR, pp. 4700–4708.
Hutchinson, A.K., 2018. Retinopathy of prematurity revisited. JAMA ophthalmol 136
(12), 1389–1390.
Ju, L., Wang, X., Zhao, X., Lu, H., Mahapatra, D., Bonnington, P., Ge, Z., 2021. Synergic
Adversarial Label Learning for Grading Retinal Diseases via Knowledge Distillation
and Multi-task Learning. J. Biomed. Health. Inform. 25 (10), 3709–3720.
Kundu, J.N., Lakkakula, N., Babu, R.V., 2019. Um-adapt: unsupervised multi-task
adaptation using adversarial cross-task distillation. In: Proc. CVPR, pp. 1436–1445.
Li, T., Gao, Y., Wang, K., Guo, S., Liu, H., Kang, H., 2019. Diagnostic Assessment of Deep
Learning Algorithms for Diabetic Retinopathy Screening. Inform. Sci. 501, 511–522.
Li, K., Yu, L., Wang, S., Heng, P.-A., 2020a. Towards cross-modality medical image
segmentation with online mutual knowledge distillation. Proc. AAAI 34, 775–783.
Li, T., Li, J., Liu, Z., Zhang, C., 2020b. Few sample knowledge distillation for efficient
network compression. In: Proc. CVPR, pp. 14639–14647.
Li, X., Gu, Y., Dvornek, N., Staib, L.H., Ventola, P., Duncan, J.S., 2020c. Multi-site fMRI
analysis using privacy-preserving federated learning and domain adaptation: ABIDE
results. Med. Image Anal. 65, 101765.
Liu, Y., Shu, C., Wang, J., Shen, C., 2020. Structured knowledge distillation for dense
prediction. IEEE Trans. Pattern. Anal. Mach. Intell. https://doi.org/10.1109/
TPAMI.2020.3001940.
Ma, N., Zhang, X., Zheng, H.-.T., Sun, J., 2018. Shufflenet v2: practical guidelines for
efficient cnn architecture design. In: Proc. ECCV, pp. 116–131.
Mahmood, F., Chen, R., Durr, N.J., 2018. Unsupervised reverse domain adaptation for
synthetic medical images via adversarial training. IEEE Trans. Med. Imag. 37 (12),
2572–2581.
Mirzadeh, S.I., Farajtabar, M., Li, A., Levine, N., Matsukawa, A., Ghasemzadeh, H., 2020.
Improved knowledge distillation via teacher assistant. Proc. AAAI 34, 5191–5198.
Nguyen-Meidine, L.T., Belal, A., Kiran, M., Dolz, J., Blais-Morin, L.-A., Granger, E., 2021.
Unsupervised Multi-Target Domain Adaptation Through Knowledge Distillation. In:
Proc. IEEE Winter Conf. on Appl. of Comp. Vis, pp. 1339–1347.
Park, W., Kim, D., Lu, Y., Cho, M., 2019. Relational knowledge distillation. In: Proc.
CVPR, pp. 3967–3976.
Redd, T.K., Campbell, J.P., Brown, J.M., Kim, S.J., Ostmo, S., Chan, R.V.P., Dy, J.,
Erdogmus, D., Ioannidis, S., Kalpathy-Cramer, J., 2019. Evaluation of a deep
learning image assessment system for detecting severe retinopathy of prematurity.
Br. J. Ophthalmol. 103 (5), 580–584.
Sandler, M., Howard, A., Zhu, M., Zhmoginov, A., Chen, L.-C., 2018. Mobilenetv2:
inverted residuals and linear bottlenecks. In: Proc. CVPR, pp. 4510–4520.
Sen, P., Wu, W.-C., Chandra, P., Vinekar, A., Manchegowda, P.T., Bhende, P., 2020.
Retinopathy of prematurity treatment: Asian perspectives. Eye 34 (4), 632–642.
Shen, Z., He, Z., Xue, X., 2019. Meal: multi-model ensemble via adversarial learning.
Proc. AAAI 33, 4886–4893.
Son, W., Na, J., Hwang, W., 2021. Densely guided knowledge distillation using multiple
teacher assistants. In: Proc. ICCV, pp. 9395–9404.
Tan, C., Liu, J., Zhang, X., 2021. Improving knowledge distillation via an expressive
teacher. Knowl-Based Syst 218, 106837.
Taylor, S., Brown, J.M., Gupta, K., Campbell, J.P., Ostmo, S., Chan, R.P., Dy, J.,
Erdogmus, D., Ioannidis, S., Kim, S.J., 2019. Monitoring disease progression with a
quantitative severity scale for retinopathy of prematurity using deep learning. JAMA
ophthalmol 137 (9), 1022–1028.
Wang, J., Bao, W., Sun, L., Zhu, X., Cao, B., Philip, S.Y., 2019a. Private model
compression via knowledge distillation. Proc. AAAI 33, 1190–1197.
Wang, J., Gou, L., Zhang, W., Yang, H., Shen, H.-.W., 2019b. Deepvid: deep visual
interpretation and diagnosis for image classifiers via knowledge distillation. IEEE
Trans. Vis. Comp. Graph. 25 (6), 2168–2180.
Wang, L., Yoon, K.-J., 2021. Knowledge distillation and student-teacher learning for
visual intelligence: a review and new outlooks. IEEE Trans. Pattern. Anal. Mach.
Intell. 44 (6), 3048–3068.
Wang, S., Yu, L., Yang, X., Fu, C.-W., Heng, P.-A., 2019c. Patch-based output space
adversarial learning for joint optic disc and cup segmentation. IEEE Trans. Med.
Imag. 38 (11), 2485–2495.
Wang, X., Zhang, R., Sun, Y., Qi, J., 2018. KDGAN: knowledge Distillation with
Generative Adversarial Networks. NeurIPS 783–794.
Xie, H., Lei, H., Zeng, X., He, Y., Chen, G., Elazab, A., Yue, G., Wang, J., Zhang, G., Lei, B.,
2020. AMD-GAN: attention encoder and multi-branch structure based generative
adversarial networks for fundus disease detection from scanning laser
ophthalmoscopy images. Neural Netw 132, 477–490.
Yang, X., Lin, Y., Wang, Z., Li, X., Cheng, K.-T., 2019. Bi-modality medical image
synthesis using semi-supervised sequential generative adversarial networks.
J. Biomed. Health. Inform 24 (3), 855–865.
Yao, A., Sun, D., 2020. Knowledge transfer via dense cross-layer mutual-distillation.
Proc. ECCV 294–311.
Zhang, H., Hu, Z., Qin, W., Xu, M., Wang, M., 2021. Adversarial co-distillation learning
for image recognition. Pattern Recognit 111, 107659.
Zhang, X., Zhou, X., Lin, M., Sun, J., 2018. Shufflenet: an extremely efficient
convolutional neural network for mobile devices. In: Proc. CVPR, pp. 6848–6856.
Zhao, H., Sun, X., Dong, J., Chen, C., Dong, Z., 2020. Highlight every step: knowledge
distillation via collaborative teaching. IEEE Trans. Cybern. https://doi.org/10.1109/
TCYB.2020.3007506.
Zhao, R., Chen, X., Chen, Z., Li, S., 2021. Diagnosing glaucoma on imbalanced data with
self-ensemble dual-curriculum learning. Med. Image Anal. 75, 102295.
版权说明:
本文由 youcans@xidian 对论文 Adversarial learning-based multi-level dense-transmission knowledge distillation for AP-ROP detection 进行摘编和翻译。该论文版权属于原文期刊和作者,本译文只供研究学习使用。
youcans@xidian 作品,转载必须标注原文链接:
【医学影像 AI】基于对抗学习的多层次密集传输知识蒸馏用于AP-ROP检测(https://youcans.blog.csdn.net/article/details/146416459)
Crated:2025-10