【AI论文】ExGRPO:从经验中学习进行推理
摘要:基于可验证奖励的强化学习(RLVR,Reinforcement Learning from Verifiable Rewards)是提升大型语言模型推理能力的一种新兴范式。然而,标准的同策略(on-policy)训练在一次更新后便会丢弃展开(rollout)经验,导致计算效率低下和训练不稳定。尽管此前强化学习领域的研究已强调了重复利用过往经验的好处,但经验特性在塑造大型推理模型学习动态过程中所起的作用仍鲜有探索。在本文中,我们首次研究了何种因素使得推理经验具有价值,并确定展开过程的正确性和熵(entropy)是衡量经验价值的有效指标。基于这些见解,我们提出了ExGRPO(基于经验分组的相对策略优化,Experiential Group Relative Policy Optimization)框架,该框架对有价值的经验进行组织和优先级排序,并采用混合策略目标来平衡探索与经验利用。在五个骨干模型(参数规模为15亿至80亿)上进行的实验表明,ExGRPO在数学/通用基准测试中始终如一地提升了推理性能,相较于同策略RLVR,平均提升幅度达+3.5/7.6分。此外,在同策略方法失效的更强和更弱的模型上,ExGRPO均稳定了训练过程。这些结果凸显了,合理的经验管理是实现高效且可扩展的RLVR的关键要素。Huggingface链接:Paper page,论文链接:2510.02245
研究背景和目的
研究背景:
随着人工智能技术的快速发展,大型语言模型(LLMs)在各种复杂任务中展现出了强大的推理能力。然而,标准的强化学习从可验证奖励(RLVR)方法在提升这些模型的推理能力时,面临着计算效率低下和训练不稳定的问题。
传统RLVR方法在一次更新后丢弃了所有的探索经验,这不仅浪费了宝贵的计算资源,还限制了模型从先前成功探索中学习的能力。此外,经验特性在大型推理模型的学习动态中所起的作用尚未被充分探索。
研究目的:
本研究旨在通过提出一种名为ExGRPO(Experiential Group Relative Policy Optimization)的新框架,来解决上述问题。ExGRPO通过组织和管理有价值的经验,并采用混合策略目标来平衡探索与经验利用,从而提高RLVR的效率和稳定性。具体目标包括:
- 识别有价值的经验:通过分析经验的问题正确性和轨迹熵,确定哪些经验对模型学习最有价值。
- 有效的经验管理:设计一个经验回放缓冲区,将经验按正确性水平分类,并采用优先级采样策略,以优先选择来自中等难度问题和低熵轨迹的经验。
- 混合策略优化:在优化目标中结合当前策略的新探索和从经验回放缓冲区中选择的过去经验,以提高样本效率和训练稳定性。
研究方法
1. 经验特性分析:
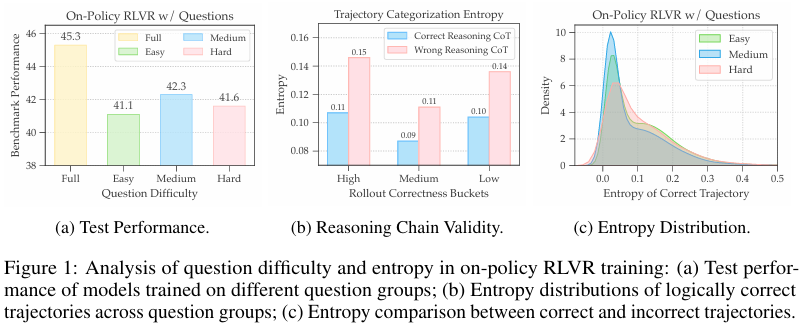
首先,研究通过对Qwen2.5-Math 7B模型在OpenR1-Math数据集上的训练,分析了问题难度和轨迹熵对经验价值的影响。
通过将问题按在线正确性分为简单、中等和困难三类,并比较不同类别问题的测试性能,发现中等难度问题的训练提供了最强的优化信号。同时,低熵轨迹通常意味着更高质量的推理链,从而作为选择经验的有效启发式方法。
2. ExGRPO框架设计:
ExGRPO框架分为两个主要阶段:经验管理和策略优化。
- 经验管理:
- 经验收集:在训练过程中收集模型对每个问题的成功轨迹。
- 经验分区:根据每个问题的最新正确性水平,将经验回放缓冲区划分为多个桶。
- 经验选择:在优化过程中,从经验回放缓冲区中按比例采样经验,并选择每个采样问题中熵最低的轨迹。
- 策略优化:
- 混合批次构建:结合当前策略生成的新轨迹和从经验回放缓冲区中选择的过去轨迹,构建混合批次。
- 联合优化目标:采用混合策略优化目标,结合当前策略的新探索和过去经验的利用,通过重要性采样校正分布偏移。
3. 优化机制:
- 策略塑造:为了保持探索性,对来自经验回放缓冲区的轨迹采用非线性变换进行策略塑造,放大低概率信号并抑制高概率信号。
- 延迟启动机制:为了避免在模型能力发展初期收集低质量轨迹,ExGRPO在初始训练阶段仅运行标准RLVR过程,待模型性能达到一定阈值后再激活经验回放。
研究结果
1. 性能提升:
在多个骨干模型(1.5B到8B参数)上的实验结果表明,ExGRPO在数学推理和泛化推理基准测试上均显著优于标准RLVR基线方法。
具体来说,在Qwen2.5-Math 7B模型上,ExGRPO在数学推理任务上平均提升了3.5分,在泛化推理任务上平均提升了7.6分。
2. 训练稳定性:
ExGRPO在训练过程中表现出了更高的稳定性。
例如,在Llama-3.1 8B基础模型上,标准RLVR方法因奖励信号不足而导致训练崩溃,而ExGRPO则能够稳定训练并取得显著的性能提升。
3. 经验管理效果:
通过详细的消融实验,验证了经验选择策略和策略塑造机制的有效性。去除问题选择或轨迹选择策略,或关闭策略塑造机制,均会导致模型性能下降。
这表明,ExGRPO通过精心管理经验,有效提升了模型的推理能力和训练稳定性。
研究局限
尽管ExGRPO在提升大型语言模型推理能力方面取得了显著进展,但仍存在以下局限:
- 经验价值的全面评估:
- 当前研究主要关注于可验证问题上的经验价值,对于更开放的任务(如创意写作),奖励往往是主观且密集的,如何评估这些任务中的经验价值仍是一个开放问题。
- 有价值失败经验的利用:
- ExGRPO框架主要关注于成功经验的利用,但“有价值的失败”经验(即包含有用训练信号的不正确路径)也可能对模型学习有帮助。如何有效利用这些失败经验,是未来研究的一个方向。
- 与其他RL算法的结合:
- ExGRPO基于相对策略优化(GRPO)目标构建,其与其他RL算法家族的交互尚未被探索。未来研究可以探索ExGRPO与其他RL算法的结合,以进一步提升模型性能。
未来研究方向
针对ExGRPO的局限性和当前研究的不足,未来工作可以从以下几个方面展开:
- 开放任务中的经验管理:
- 研究如何在更开放的任务中管理经验,特别是那些奖励主观且密集的任务。这可能需要开发新的经验评估指标和选择策略。
- 有价值失败经验的探索:
- 探索如何有效利用有价值的失败经验,以进一步提升模型的推理能力和鲁棒性。这可能需要引入新的奖励机制或学习策略。
- 跨RL算法的融合:
- 研究ExGRPO与其他RL算法的融合方法,以结合不同算法的优势,进一步提升模型性能。这可能需要开发新的优化目标或训练框架。
- 实际应用的探索:
- 将ExGRPO方法应用于实际场景中,如在线教育、智能客服等领域,探索其在实际应用中的效果和潜力。这需要考虑模型的实时性、可扩展性和用户体验等因素。
- 持续学习和自适应:
- 研究如何使模型能够持续学习新知识,并适应不断变化的环境和任务需求。这可能需要引入在线学习、迁移学习或元学习等技术。
通过上述研究方向的深入探索,ExGRPO有望在未来进一步提升大型语言模型的推理能力和训练效率,推动人工智能技术的发展和应用。