让AI说“人话“:TypeChat.NET如何用强类型驯服大语言模型的“野性“
从自然语言到结构化代码,微软开源框架背后的黑科技揭秘
🎯 引言:当AI开始"听懂人话"时发生了什么?
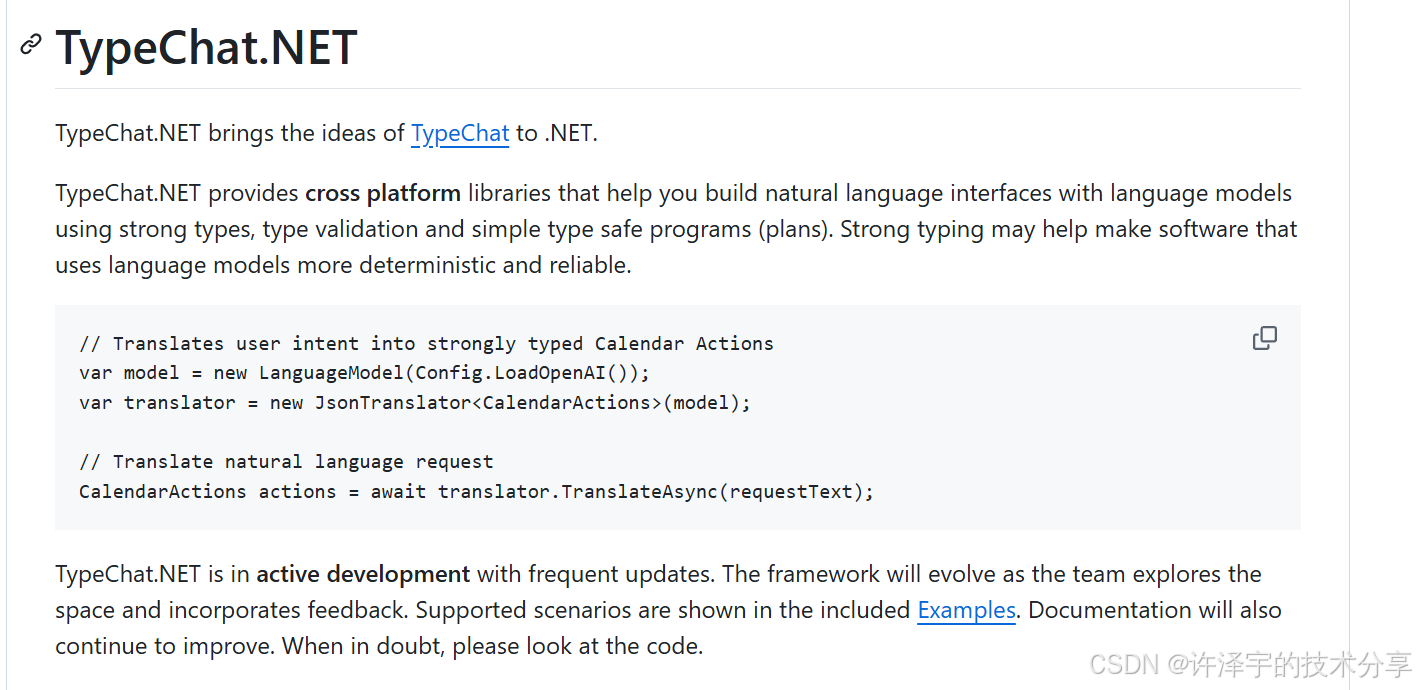
想象一下这样的场景:你走进咖啡厅,对着智能点餐系统说:"来杯大杯拿铁,少糖,加燕麦奶,要热的。"系统不仅准确理解了你的需求,还把订单转换成了结构化数据——饮品类型、尺寸、温度、配料,一个都没落下。这不是科幻电影,而是 TypeChat.NET 框架正在做的事情。
在 GPT-4 引领的大语言模型(LLM)时代,我们似乎已经习惯了 AI 的"智能对话"。但问题来了:AI 能听懂人话,开发者的代码却听不懂 AI 说的话。 大语言模型输出的是自由文本,而程序需要的是结构化数据。这道鸿沟,正是 TypeChat.NET 要填平的。
今天,我们就来深度剖析微软开源的 TypeChat.NET 框架,看看它如何用 C# 的强类型系统给 AI 套上"缰绳",让自然语言接口从"玩具"变成"生产力工具"。
📖 第一章:起源——为什么我们需要 TypeChat?
1.1 大语言模型的"甜蜜陷阱"
自 ChatGPT 横空出世以来,开发者们都在思考一个问题:如何把 LLM 集成到实际应用中?最直观的做法是让模型返回 JSON,然后解析使用。听起来很美好,实际却有三个致命问题:
问题一:随机性的诅咒
LLM 是概率模型,同样的输入可能产生不同的输出。今天它返回 {"size": "large"},明天可能变成 {"size": "L"} 或者 {"sizeValue": "大杯"}。这种不确定性对生产环境来说就是噩梦。
问题二:Schema 的无力感
你可以在 Prompt 里写:"请返回符合这个 Schema 的 JSON",但 LLM 不会严格遵守。它可能漏掉必填字段、拼错属性名,甚至返回半截 JSON。就像你告诉一个人"请说标准普通话",但他还是会夹杂方言。
问题三:错误恢复的困境
传统程序遇到错误会抛异常,但 LLM 返回的"错误 JSON"该怎么办?重新请求?让用户重新输入?这些都不是优雅的解决方案。
1.2 TypeChat 的核心洞察
微软的工程师们在开发 TypeScript 版本的 TypeChat 时,有一个关键洞察:
如果我们把 LLM 看作"一个会犯错但能改正的程序员",那么最好的方式不是期待它第一次就写对,而是建立一个"验证-反馈-修复"的闭环。
这个思路听起来简单,但实现起来需要三个关键组件:
-
强类型 Schema:用编程语言的类型系统定义期望的数据结构
-
智能验证器:检查 LLM 返回的 JSON 是否符合 Schema
-
自动修复机制:将验证错误反馈给 LLM,让它自己改正
TypeChat.NET 把这套理念带到了 .NET 生态,并且做了更多本地化创新。
🏗️ 第二章:技术架构——三层抽象的艺术
2.1 核心层:Microsoft.TypeChat
这是框架的基石,提供了最核心的 JsonTranslator<T> 类。让我们先看一个最简单的例子:
// 定义你想要的数据结构
public class SentimentResult
{public string Sentiment { get; set; } // positive/negative/neutral
}// 三行代码搞定自然语言到强类型的转换
var model = new LanguageModel(Config.LoadOpenAI());
var translator = new JsonTranslator<SentimentResult>(model);
SentimentResult result = await translator.TranslateAsync("这部电影太烂了!");Console.WriteLine(result.Sentiment); // 输出: negative
看起来很魔法,但背后的流程非常清晰:
工作流程深度解析
Step 1: Schema 生成
JsonTranslator<T> 在初始化时,会自动把 C# 类型转换成 TypeScript Schema。为什么是 TypeScript?因为它能用最简洁的语法描述 JSON 结构,而且 GPT 系列模型对 TypeScript 的理解最好(毕竟训练数据里有海量的 TS 代码)。
// 自动生成的 Schema(简化版)
export interface SentimentResult {sentiment: "positive" | "negative" | "neutral";
}
Step 2: Prompt 构建
框架会构造一个精心设计的 Prompt,核心结构如下:
You are a service that translates user requests into JSON objects of type "SentimentResult" according to the following TypeScript definitions:[TypeScript Schema]The following is a user request:
"""
这部电影太烂了!
"""The following is the user request translated into a JSON object with 2 spaces of indentation and no properties with the value undefined:
注意这里的细节:
-
强调返回 JSON object,而不是随意文本
-
明确指定缩进(2空格),这能提高 JSON 解析成功率
-
禁止
undefined值,避免 JavaScript 和 JSON 的语义差异
Step 3: 验证与修复
这是 TypeChat 最精妙的部分。当 LLM 返回 JSON 后,框架会:
-
语法检查:能否正确解析成 JSON?
-
类型验证:字段类型是否匹配?必填字段是否齐全?
-
约束检查:是否满足自定义验证规则?
如果验证失败,框架不会放弃,而是把错误信息发回给 LLM:
The JSON object is invalid for the following reason:
"""
Property 'sentiment' is required but was not found.
"""Please try again and return a valid JSON object.
LLM 会基于这个反馈生成新的 JSON,这个过程最多重复 MaxRepairAttempts 次(默认3次)。这就像一个耐心的老师在批改作业——不是直接打叉,而是指出错误让学生重新做。
2.2 代码层面的优雅设计
让我们深入 JsonTranslator<T> 的核心代码(简化版):
public class JsonTranslator<T>
{private readonly ILanguageModel _model; // 语言模型接口private IJsonTypeValidator<T> _validator; // 类型验证器private IConstraintsValidator<T>? _constraintsValidator; // 约束验证器public async Task<T> TranslateAsync(string request, CancellationToken cancelToken = default){Prompt prompt = CreateRequestPrompt(request);int repairAttempts = 0;while (true){// 1. 发送请求到 LLMstring responseText = await _model.CompleteAsync(prompt, cancelToken);// 2. 解析 JSONJsonResponse jsonResponse = JsonResponse.Parse(responseText);if (jsonResponse.HasCompleteJson){// 3. 验证类型Result<T> validationResult = _validator.Validate(jsonResponse.Json);if (validationResult.Success){// 4. 验证约束if (_constraintsValidator != null){validationResult = _constraintsValidator.Validate(validationResult.Value);}if (validationResult.Success){return validationResult.Value; // 成功!}}}// 5. 验证失败,尝试修复if (++repairAttempts > MaxRepairAttempts){throw new TypeChatException("无法生成有效 JSON");}// 6. 构建修复 Promptprompt.Append(CreateRepairPrompt(responseText, validationResult.Message));}}
}
这段代码体现了几个设计智慧:
1. 接口驱动的扩展性
ILanguageModel、IJsonTypeValidator、IConstraintsValidator 都是接口,你可以轻松替换实现。比如把 OpenAI 换成本地模型,或者添加自定义验证逻辑。
2. 事件驱动的可观测性
框架提供了 SendingPrompt、CompletionReceived、AttemptingRepair 等事件,让你能够监控整个翻译过程:
translator.SendingPrompt += prompt => Console.WriteLine($"发送: {prompt}");
translator.CompletionReceived += response => Console.WriteLine($"收到: {response}");
translator.AttemptingRepair += error => Console.WriteLine($"修复: {error}");
这在调试和生产监控中非常有用。
3. 渐进式的错误处理
注意那个 while(true) 循环?它不是死循环,而是一个状态机。每次迭代都在尝试让结果更接近正确,直到成功或达到最大重试次数。这种"渐进式改进"的思路比"一次成功或失败"更符合 LLM 的特性。
☕ 第三章:实战案例——咖啡店点单系统
理论讲完了,来点实战。我们以 TypeChat.NET 的 CoffeeShop 示例为蓝本,构建一个能听懂自然语言的点单系统。
3.1 Schema 设计:用类型约束"口语化输入"
首先定义订单的数据结构。这里的关键是使用 JsonVocab 特性 来约束字符串值:
// 购物车
public class Cart
{public CartItem[] Items { get; set; }
}// 抽象的购物车项(支持多态)
[JsonPolymorphic]
[JsonDerivedType(typeof(LatteDrinks), typeDiscriminator: nameof(LatteDrinks))]
[JsonDerivedType(typeof(EspressoDrinks), typeDiscriminator: nameof(EspressoDrinks))]
[JsonDerivedType(typeof(UnknownItem), typeDiscriminator: nameof(UnknownItem))]
public abstract class CartItem { }// 拿铁类饮品
public class LatteDrinks : CartItem
{[JsonVocab("cappuccino | flat white | latte | latte macchiato | mocha | chai latte")]public string Name { get; set; }public CoffeeTemperature? Temperature { get; set; }[Comment("默认尺寸是 Grande")]public CoffeeSize? Size { get; set; } = CoffeeSize.Grande;public int Quantity { get; set; } = 1;public DrinkOption[]? Options { get; set; }
}// 咖啡尺寸
[JsonConverter(typeof(JsonStringEnumConverter))]
public enum CoffeeSize
{Short,Tall,Grande,Venti
}// 配料选项
public class Milks : DrinkOption
{[JsonVocab("whole milk | two percent milk | nonfat milk | soy milk | almond milk | oat milk")]public string Name { get; set; }
}// 未识别项(兜底策略)
[Comment("用此类型表示无法识别的内容")]
public class UnknownItem : CartItem
{[Comment("未理解的文本")]public string Text { get; set; }
}
这个 Schema 有几个亮点:
1. JsonVocab:词汇表约束
[JsonVocab("...")] 特性告诉 LLM:"Name 字段只能是这些值之一"。这大大减少了模型的"创造力",避免它返回 "超大杯拿铁" 这种不在菜单上的东西。
2. Comment:语义提示
[Comment("...")] 会被转换成 TypeScript 注释,帮助 LLM 理解字段含义。比如 "默认尺寸是 Grande" 能让模型在用户没说尺寸时自动填充。
3. 多态设计:UnknownItem 兜底
现实中用户可能说出各种奇怪的东西("来杯心灵鸡汤"),UnknownItem 提供了一个优雅的降级方案——把无法理解的内容原样记录下来,而不是直接报错。
3.2 实际使用:从自然语言到结构化订单
public class CoffeeShopApp
{private readonly JsonTranslator<Cart> _translator;public CoffeeShopApp(){_translator = new JsonTranslator<Cart>(new LanguageModel(Config.LoadOpenAI()));_translator.MaxRepairAttempts = 3;}public async Task ProcessOrder(string userInput){// 魔法发生的地方Cart cart = await _translator.TranslateAsync(userInput);// 输出结构化订单Console.WriteLine(Json.Stringify(cart, indented: true));// 检查是否有未识别项foreach (var item in cart.Items.OfType<UnknownItem>()){Console.WriteLine($"⚠️ 未理解: {item.Text}");}}
}
测试一下效果:
输入: "我要两杯大杯热拿铁,一杯加燕麦奶,另一杯半糖加奶油"
输出:
{"items": [{"$type": "LatteDrinks","productName": "latte","temperature": "Hot","size": "Venti","quantity": 1,"options": [{"$type": "Milks","optionName": "oat milk"}]},{"$type": "LatteDrinks","productName": "latte","temperature": "Hot","size": "Venti","quantity": 1,"options": [{"$type": "Sweetners","optionName": "sugar","optionQuantity": { "$type": "StringQuantity", "amount": "regular" }},{"$type": "Toppings","optionName": "whipped cream"}]}]
}
注意看,模型不仅正确识别了:
-
两个独立的订单项(虽然都是拿铁)
-
尺寸映射("大杯" →
Venti) -
配料分类(燕麦奶是
Milks,奶油是Toppings) -
量词理解("半糖" →
regular量的糖)
3.3 背后的黑科技:TypeScript Schema 生成
当你定义好 C# 类后,JsonTranslator 会在运行时自动生成 TypeScript Schema。以 LatteDrinks 为例:
// 自动生成的 TypeScript Schema
export type LatteDrinks = {$type: "LatteDrinks";// cappuccino | flat white | latte | latte macchiato | mocha | chai latteproductName: "cappuccino" | "flat white" | "latte" | "latte macchiato" | "mocha" | "chai latte";temperature?: "Hot" | "Extra_Hot" | "Warm" | "Iced";// 默认尺寸是 Grandesize?: "Short" | "Tall" | "Grande" | "Venti";quantity: number;options?: DrinkOption[];
}export type DrinkOption = Milks | Sweetners | Toppings | ...;export type Milks = {$type: "Milks";// whole milk | two percent milk | nonfat milk | soy milk | almond milk | oat milkoptionName: "whole milk" | "two percent milk" | "nonfat milk" | "soy milk" | "almond milk" | "oat milk";
}
这个 Schema 会作为 System Prompt 的一部分发送给 LLM。注意几个细节:
-
联合类型(Union Types):
"Hot" | "Iced"这种语法明确限制了可选值 -
可选字段(Optional):
temperature?表示可不填 -
注释保留:C# 的
[Comment]特性被转换成了 TS 注释 -
多态标记:
$type字段用于区分不同的子类型
这种 Schema 对 GPT-4 来说非常友好,它在训练过程中见过大量类似的 TypeScript 定义。
🧮 第四章:进阶应用——从 JSON 翻译到程序合成
如果说 JsonTranslator 是 TypeChat.NET 的"初级魔法",那么 Microsoft.TypeChat.Program 就是"高级魔法"——它能把自然语言直接转换成可执行的程序。
4.1 什么是 JSON Program?
传统的 JSON 只能表达数据,而 JSON Program 可以表达逻辑。它本质上是一个 领域特定语言(DSL),用 JSON 格式描述函数调用序列。
举个例子,假设用户说:"计算 (3 + 5) * 2 的平方根",我们希望生成这样的程序:
{"@steps": [{ "@func": "add", "@args": [3, 5] },{ "@func": "mul", "@args": [{ "@ref": 0 }, 2] },{ "@func": "sqrt", "@args": [{ "@ref": 1 }] }]
}
解释一下:
-
@steps: 按顺序执行的步骤数组 -
@func: 要调用的函数名 -
@args: 函数参数(可以是常量或引用) -
@ref: 引用前面步骤的结果({"@ref": 0}表示第0步的返回值)
这种设计的妙处在于:
-
可验证:可以检查函数名是否存在、参数类型是否匹配
-
可解释:能清楚看到执行流程
-
可优化:可以做死代码消除、常量折叠等优化
-
安全:沙箱化执行,不会有代码注入风险
4.2 数学计算器实战
让我们用 TypeChat.Program 构建一个自然语言数学计算器。
Step 1: 定义 API
[Comment("用于计算数学表达式的 API")]
public interface IMathAPI
{[Comment("x + y")]double add(double x, double y);[Comment("x - y")]double sub(double x, double y);[Comment("x * y")]double mul(double x, double y);[Comment("x / y")]double div(double x, double y);[Comment("平方根")]double sqrt(double x);[Comment("x 的 y 次方")]double power(double x, double y);
}// 实现类
public class MathAPI : IMathAPI
{public double add(double x, double y) => x + y;public double sub(double x, double y) => x - y;public double mul(double x, double y) => x * y;public double div(double x, double y) => x / y;public double sqrt(double x) => Math.Sqrt(x);public double power(double x, double y) => Math.Pow(x, y);
}
注意这里的 [Comment] 特性至关重要——它们会被转换成 API 文档,帮助 LLM 理解每个函数的作用。
Step 2: 创建 ProgramTranslator
public class MathApp
{private readonly ProgramTranslator<IMathAPI> _translator;private readonly Api<IMathAPI> _api;public MathApp(){_api = new MathAPI();_translator = new ProgramTranslator<IMathAPI>(new LanguageModel(Config.LoadOpenAI()),_api);_translator.MaxRepairAttempts = 3;}public async Task Calculate(string userInput){// 翻译成程序Program program = await _translator.TranslateAsync(userInput);// 打印程序(便于调试)program.Print("MathAPI");if (program.IsComplete){// 执行程序dynamic result = program.Run(_api);Console.WriteLine($"结果: {result}");}else{Console.WriteLine("⚠️ 无法完全理解请求");}}
}
Step 3: 测试效果
输入: "计算 ((10 + 5) * 3) 的平方根,然后把结果提升到 2 的幂次"
生成的 Program:
{"@steps": [{ "@func": "add", "@args": [10, 5] },{ "@func": "mul", "@args": [{ "@ref": 0 }, 3] },{ "@func": "sqrt", "@args": [{ "@ref": 1 }] },{ "@func": "power", "@args": [{ "@ref": 2 }, 2] }]
}
执行流程:
Step 0: add(10, 5) ==> 15
Step 1: mul(15, 3) ==> 45
Step 2: sqrt(45) ==> 6.708203932499369
Step 3: power(6.708203932499369, 2) ==> 45.0
结果: 45.0
4.3 程序验证与修复
ProgramTranslator 的强大之处在于它会对生成的程序进行 类型检查。如果 LLM 生成了无效程序(比如调用不存在的函数、参数类型不匹配),框架会把编译错误发回去让它改正。
4.4 编译器架构:从 AST 到执行
ProgramTranslator 的内部有两种执行引擎:
1. 解释器(Interpreter)
最轻量的执行方式,直接遍历 JSON AST。
2. 编译器(Compiler)
对于性能敏感场景,可以把 JSON Program 编译成 .NET 的 Lambda 表达式,性能接近手写代码。
🔌 第五章:Semantic Kernel 集成——站在巨人的肩膀上
TypeChat.NET 不是孤岛,它与微软的另一个 AI 框架 Semantic Kernel 深度集成。
5.1 什么是 Semantic Kernel?
Semantic Kernel(简称 SK)是微软开源的 AI 编排框架,提供:
-
插件系统:把任意 C# 方法包装成 AI 可调用的"技能"
-
规划器(Planner):自动生成多步骤计划
-
记忆系统:向量数据库、语义搜索
-
多模型支持:统一的接口访问不同 LLM
5.2 插件程序翻译器
Microsoft.TypeChat.SemanticKernel 包提供了 PluginProgramTranslator,可以把 SK 插件转换成 TypeChat 可用的 API。
5.3 安全性考量
把 LLM 和文件系统连接起来听起来很酷,但也很危险。TypeChat + SK 提供了多层防护:
-
白名单机制
-
参数验证
-
资源限制
-
审计日志
🎭 第六章:高级特性——让 Schema 更智能
6.1 Vocabulary:约束 LLM 的"创造力"
通过 [JsonVocab] 特性和动态词汇表加载,可以精确控制 LLM 的输出范围。
6.2 Constraints Validator:业务规则验证
类型检查只能保证结构正确,但无法保证语义正确。约束验证器用于检查业务规则。
6.3 Hierarchical Schema:路由到子应用
大型应用通常有多个功能模块,不同的用户意图应该路由到不同的 Translator。
🤖 第七章:对话式 AI——带记忆的智能体
前面的例子都是"一问一答"式的交互,但真实的 AI 助手需要维护上下文、理解多轮对话。
7.1 对话式数据采集
通过 DialogHistory 维护对话历史,实现增量式数据收集。
7.2 增量式数据填充
用户每次只提供一部分数据,系统需要把它们合并起来。
7.3 上下文感知的消歧
通过在 Prompt 中注入上下文来解决代词指代问题。
🔬 第八章:性能与成本优化
在生产环境中,调用 LLM 的成本和延迟是不可忽视的问题。
8.1 Token 优化策略
-
Schema 压缩
-
Few-Shot 示例缓存
-
增量式 Schema
8.2 并行处理
当需要处理多个独立请求时,可以并行调用。
8.3 结果缓存
对于相同或相似的输入,可以缓存结果。
8.4 模型选择策略
不是所有任务都需要 GPT-4,可以根据任务复杂度动态选择模型。
🚀 第九章:生产环境最佳实践
9.1 错误处理与降级
完善的错误处理机制,包括重试、降级和友好的错误提示。
9.2 监控与可观测性
通过事件和指标收集,实现全面的系统监控。
9.3 A/B 测试框架
支持不同 Prompt 策略的 A/B 测试。
9.4 安全性检查
输入过滤、输出验证和数据脱敏。
🌟 第十章:应用场景与未来展望
10.1 典型应用场景
-
智能客服
-
企业数据查询
-
智能表单填写
-
会议记录转结构化任务
10.2 当前局限性
-
成本问题
-
延迟问题
-
确定性问题
-
领域知识问题
10.3 未来发展方向
-
本地小模型支持
-
流式处理
-
多模态输入
-
自动 Schema 优化
-
与 Agent 框架集成
🎓 第十一章:总结与思考
11.1 核心价值回顾
TypeChat.NET 的真正价值不在于它用了多么高深的技术,而在于它解决了一个关键矛盾:LLM 的灵活性与传统软件的确定性。
通过三个核心机制:
-
强类型 Schema:用编译器思维约束 AI
-
验证-反馈-修复循环:让 AI 从错误中学习
-
可扩展架构:提供足够的 Hook 点供定制
它让开发者能够:
-
✅ 用几十行代码实现原本需要数百行规则引擎的功能
-
✅ 让非技术用户也能与系统交互
-
✅ 在保持灵活性的同时不失控制
11.2 架构设计的启发
TypeChat 的设计哲学值得所有 AI 应用开发者借鉴:
1. 不要期待完美,而是建立纠错机制
LLM 会犯错,但它也能改错。与其花大力气防止错误,不如建立快速恢复的能力。
2. 用类型系统编码领域知识
强类型不仅是给编译器看的,也是给 AI 看的。Schema 就是一种"可执行的文档"。
3. 分层抽象,各司其职
JsonTranslator 负责翻译,Validator 负责验证,Constraints 负责业务规则。单一职责让系统更易维护。
4. 事件驱动的可观测性
在不侵入核心逻辑的前提下,通过事件让外部观察内部状态。这在调试和监控中极其重要。
11.3 给开发者的建议
如果你准备在项目中使用 TypeChat.NET,这里有一些实战建议:
✅ DO:
-
从简单场景开始(如情感分析、分类),逐步过渡到复杂场景
-
充分利用
[Comment]和[JsonVocab]特性,它们能显著提升准确率 -
监控 RepairAttempts 次数,如果频繁重试说明 Schema 设计有问题
-
在生产环境收集失败案例,用于优化 Prompt 和 Schema
❌ DON'T:
-
不要把所有逻辑都塞进一个巨大的 Schema,考虑拆分或使用层次化路由
-
不要忽视成本,预估好每月的 Token 消耗
-
不要完全信任 LLM 输出,关键业务加人工审核
-
不要在没有降级方案的情况下依赖 LLM
11.4 写在最后
TypeChat.NET 代表了一种趋势:**AI 正在从"黑盒魔法"变成"可控工具"**。它不是要取代传统编程,而是给传统编程插上自然语言的翅膀。
想象一下,未来的软件可能是这样的:
-
业务分析师用自然语言描述需求,系统自动生成数据模型
-
用户用口语提交工单,系统自动分类路由并提取关键信息
-
开发者说"把这个类改成单例模式",IDE 自动重构
这不是科幻,TypeChat 已经证明了这条路的可行性。而作为 .NET 开发者,我们很幸运能在这个变革的起点拥有如此优秀的工具。
📚 附录:快速上手指南
安装
dotnet add package Microsoft.TypeChat
dotnet add package Microsoft.TypeChat.Program
dotnet add package Microsoft.TypeChat.SemanticKernel
最小示例
using Microsoft.TypeChat;// 1. 定义数据结构
public class Order
{public string Product { get; set; }public int Quantity { get; set; }
}// 2. 配置 OpenAI
var config = new OpenAIConfig
{Endpoint = "https://api.openai.com/v1/chat/completions",ApiKey = "your-api-key",Model = "gpt-4"
};// 3. 创建翻译器
var model = new LanguageModel(config);
var translator = new JsonTranslator<Order>(model);// 4. 翻译自然语言
var order = await translator.TranslateAsync("我要买3个苹果");Console.WriteLine($"产品: {order.Product}, 数量: {order.Quantity}");
// 输出: 产品: 苹果, 数量: 3
资源链接
-
🔗 GitHub 仓库: https://github.com/microsoft/typechat.net
-
📖 官方文档: 查看 README.md 和示例代码
-
💬 社区讨论: GitHub Discussions
-
🐛 问题反馈: GitHub Issues