超越CNN和Transformer!Mamba结合多模态统领图像任务!
多模态Mamba的研究正迎来爆发式进展!从ICASSP'2025的DepMamba到Visual Intelligence封面的FusionMamba,顶会顶刊成果频出,彻底打破了传统模型在跨模态融合与长序列处理中的效率瓶颈,已然成为AI领域的新风口。作为序列建模的革命性架构,Mamba凭借线性复杂度的长距离依赖建模能力,与多模态技术碰撞出创新火花,通过耦合状态空间、动态特征融合等机制,既保留各模态独立特性,又实现跨维度信息的深度交互,让医疗影像诊断、工业缺陷检测等场景的模型精度与推理速度同步跃升。
对研究者而言,动态模态融合机制、轻量化架构设计、垂直领域模态增强等方向都是绝佳的突破点,为此我整理了相关的前沿论文,顶会/顶刊论文+部分官方代码打包免费送,感兴趣的同学工种号 沃的顶会扫码回复 “多模态mamba” 领取。
Multimodal Mamba:Decoder-only Multimodal State Space Model via Quadratic to Linear Distillation
文章解析
文章提出mmMamba框架,通过渐进式蒸馏将现有多模态大语言模型转化为线性复杂度的解码器架构,在多个视觉语言基准测试中展现出有竞争力的性能和高效性。
创新点
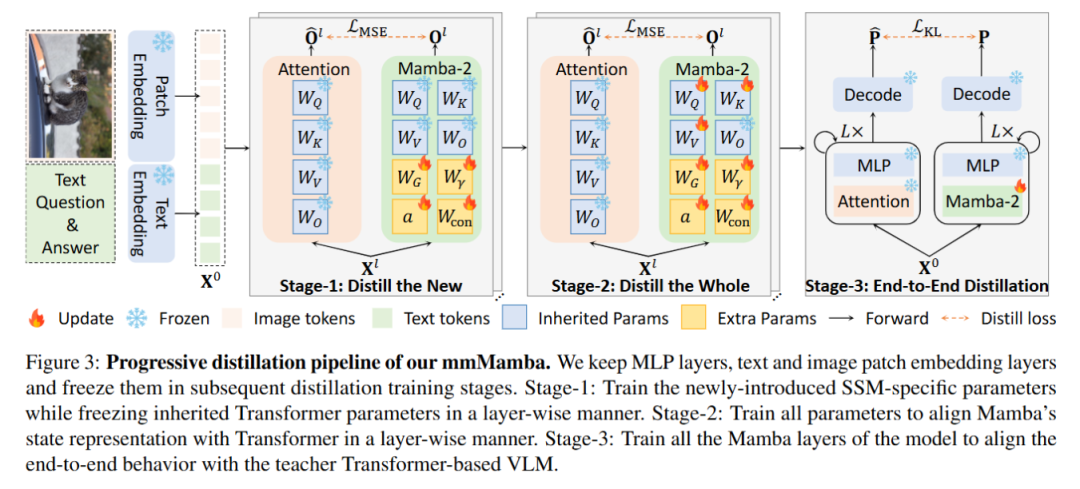
提出一种新颖的三阶段渐进式蒸馏方法,将二次复杂度模型知识转移到线性复杂度模型,无需依赖预训练的线性复杂度语言模型。
构建了两种解码器架构mmMamba-linear和mmMamba-hybrid,分别实现纯线性复杂度和灵活的性能-效率权衡。
实验结果表明,mmMamba在保持性能的同时,计算效率显著提高,在长序列建模上速度提升明显且节省GPU内存。
研究方法
通过参数继承和初始化策略,将预训练的Transformer模型转换为Mamba-2模型。
采用三阶段蒸馏策略,逐步优化Mamba-2模型的参数和行为。
设计了纯线性和混合架构的模型变体,分别实现全线性复杂度和混合复杂度。
在多个视觉-语言基准上进行了广泛的实验验证,评估模型的性能和效率。
研究结论
mmMamba-linear在多个基准上表现优于现有的线性和二次复杂度模型,且参数更少。
mmMamba-hybrid通过混合架构显著提升了性能,接近教师模型HoVLE的表现。
在长上下文处理中,mmMamba-linear和mmMamba-hybrid分别实现了20.6倍和13.5倍的加速,并大幅减少了GPU内存使用。
ML-Mamba:EfficientMulti-Modal Large Language Model Utilizing Mamba-2
文章解析
文章提出ML-Mamba模型,利用Mamba-2解决多模态学习任务,通过实验验证其性能,探索了模型组件影响,为多模态大语言模型发展提供新思路。
创新点
提出ML-Mamba模型,将Mamba-2应用于多模态学习,相比基于Mamba的模型,推理性能和效果更优。
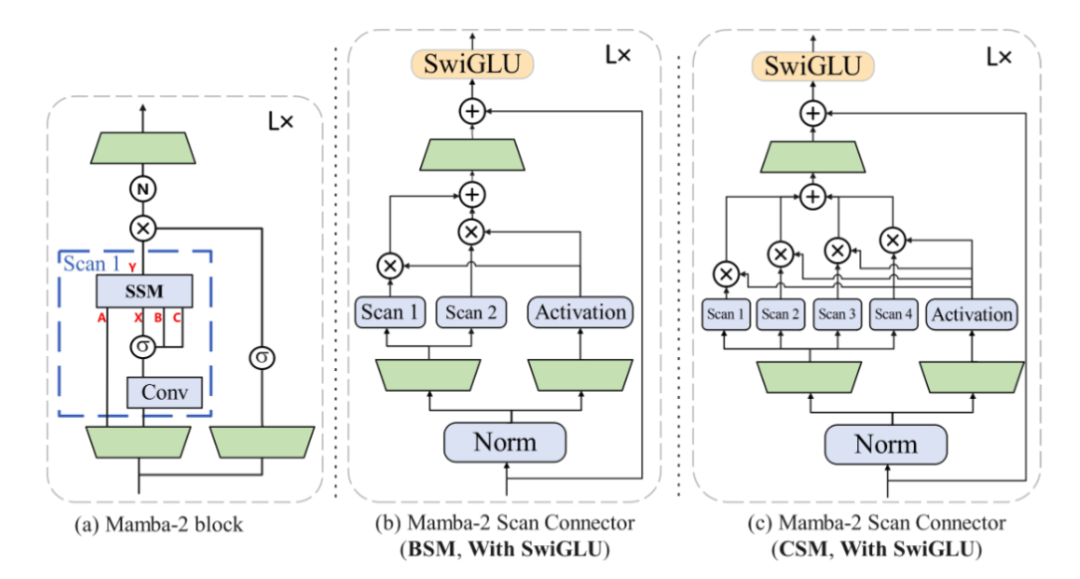
探索并提出Mamba-2 Scan Connector (MSC),增强模型对视觉信息的处理和特征表达能力。
基于线性计算复杂度的Mamba-2构建模型,解决现有多模态大语言模型效率瓶颈问题。
研究方法
采用预训练的Mamba-2语言模型作为基础,替换传统Transformer架构。
融合DINOv2和SigLIP作为视觉编码器,提取更丰富的视觉特征。
设计包含MVSS模块和SwiGLU模块的MSC,探索不同扫描机制处理视觉信息。
在多个多模态基准测试中评估模型,进行消融实验分析各组件影响。
研究结论
ML-Mamba在多模态基准测试中表现良好,证明了模型有效性和Mamba-2在多模态学习中的潜力。
模型解决了现有模型效率瓶颈,计算效率显著提高,在视觉错觉和空间关系判断任务中表现出色。
ML-Mamba存在依赖特定数据集、在移动设备运行有挑战等局限,未来需优化改进。