QT/C++中的哈希表

散列技术是在记录存储位置和它的关键字之间建立一个确定的对应关系f,存储位置 = f(关键字),使得每个关键字key对应一个存储位置f(key)。我们把这种对应关系f称为散列函数,又称为哈希函数。采用散列技术将基础存储在一块连续的存储空间中,这块连续的存储空间称为散列表或哈希表。
哈希函数的特点:相同的输入得到相同的输出,不同的输入得到不同的输出。
下面举个例子:输入一个西瓜通过哈希函数得到66的输出,再去数组66的这个地址,取到2.0这个值,这个数组就是哈希表。

哈希冲突及解决方法
哈希冲突是指不同的key通过同一哈希函数产生了相同的哈希位置。常见的解决方法有:
闭散列法(开放定址法):当发生冲突时,将数据存放到冲突位置的下一个空位置。 线性探测:从计算的哈希位置开始,往后找到第一个空闲的位置存放数据。 二次探测:通过哈希冲突次数的平方来向后查找新的位置。
开散列法(链地址法):在每个存放数据的地方开一个链表,多个键值索引到同一个地方时,将它们都放到该位置的链表里。
MD5算法
现有的减少哈希冲突成熟的算法有SHA-256,MD5
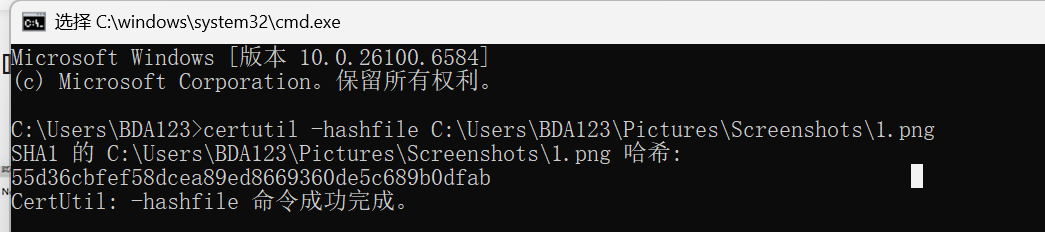
下载文件的过程中,有可能出现文件被破坏的时候,怎么验证是否和服务器的一致呢?
1.win+R打开命令行
2.输入:certutil -hashfile 文件名
3.对比这个哈希值和服务器上的是否一致
哈希表的应用场景
哈希表适用于那种查找性能要求高,数据元素之间无逻辑关系要求的情况。
C++/QT中哪些数据结构是属于哈希表呢?

1.C++标准库中的哈希表
std::unordered_map 和 std::unordered_set
std::unordered_map: 存储键值对,每个键唯一,通过键来快速查找值。
std::unordered_set: 只存储键,键唯一,通过键来快速检查存在性或者去重操作。
#include<unordered_map>
#include<unordered_set>
//创建哈希表
std::unordered_map<std::string,int>studentScores;
std::unordered_set<int>uniqueNumbers={1,2,3,4,5};
unordered_map的基本操作
//插入元素
studentScores["Alice"]=95;
studentScores["Bod"]=87;
studentScores.insert({"Charlie",92});
studentScores.emplace({"David",88});
//查找元素
auto it = studentScores.find("Alice");
if(it!=studentScores.end()){std::cout<<"score:"<<it->second<<std::endl;
}
//删除元素
studentScores.erase("Bob");
//遍历
for(const auto&[name,score]:studentScores ){std::cout<<name<<":"<<score<<std::endl;
}
2.QT中的哈希表类
QHash与QSet
QHash: 存储键值对,键唯一,通过键快速查找值。
QSet: 只存储键,键唯一,通过键快速检查存在性或者去重操作。
#include <QHash>
#include <QSet>QHash<QString, int> hash;
QSet<QString> set;
QHash的基本操作
QHash<QString,int>phoneBook;
//插入元素
phoneBook.inset("Alice",123456);
phoneBook["Bod"]=123457;
//查找元素
if(phoneBook.contain("Alice")){int number = phoneBook.value("Alice");
}
//遍历
QHashIterator<QString,int>i(phoneBook);
while(i.hasNext()){i.next();qDebug()<<i.key()<<":"<<i.value();
}
//使用C++11风格遍历
for(auto it = phoneBook.begin();it!=end();++it){qDebug()<<it.key()<<":"<<it.value();
}
3.关键知识点
哈希函数和相等比较
struct person{QString name;int age;bool operator==(const Person&Other)const{return name == other.name && age == other.age;}
};
//只要想把自定义类型当作 QHash 的 key,就必须得提供哈希函数
inline size_t qHash(const Person&person,size_t seed = 0){return qHash(person.name,seed)^person.age;
}
QHash<Person,QString>personData;
性能特性
平均时间复杂度:O(1)的插入、删除、查找
最坏的情况:O(n)哈希冲突严重时
内存占用:比QMap高
4.QHash VS QMapQHash QMap
底层实现 哈希表 红黑树
查找性能 O(1) O(log n)
内存占用 较高 较低
键的顺序 无序 按键排序
键类型要求 需要qHash和operator== 需要operator<
QHash<QString,int>hash;//需要快速查找,不关心顺序
QMap<QString,int>map;//需要有序遍历
5.多值哈希表QMultiHash
QMultiHash<QString, int> multiHash;
multiHash.insert("key", 1);
multiHash.insert("key", 2);
multiHash.insert("key", 3);// 获取所有值
QList<int> values = multiHash.values("key");
6.实际应用示例
缓存实现
template<typename Key, typename Value>
class SimpleCache {
private:QHash<Key, Value> cache;int maxSize;public:SimpleCache(int size = 100) : maxSize(size) {}void put(const Key& key, const Value& value) {if (cache.size() >= maxSize) {// 简单的淘汰策略:移除第一个元素cache.erase(cache.begin());}cache[key] = value;}bool get(const Key& key, Value& value) {auto it = cache.find(key);if (it != cache.end()) {value = it.value();return true;}return false;}
};
统计词频
QHash<QString, int> countWordFrequency(const QString& text) {QHash<QString, int> frequency;QStringList words = text.split(' ', Qt::SkipEmptyParts);for (const QString& word : words) {frequency[word.toLower()]++;}return frequency;
}
引用链接
『教程』哈希表是个啥?
关于哈希表,你该了解这些!
数据结构 Hash表(哈希表)
哈希表的实现、性能和使用场景