Linux 线程概念与虚拟地址空间深度解析
前言:
在 Linux 系统编程中,线程与虚拟地址空间是理解程序并发执行和内存管理的核心。本文将围绕 Linux 线程概念与虚拟地址空间展开,用通俗易懂的语言梳理核心逻辑,清晰呈现技术细节,同时对代码案例添加详细注释,帮助大家快速掌握这两大知识点。
一、Linux 线程概念:从定义到实践
1.1 什么是线程?—— 进程内的 “执行分身”
简单来说,线程是进程内部的一条执行路线,更准确的定义是 “一个进程内部的控制序列”。我们可以从这几个角度理解线程:
- 所有进程至少有一个线程(主线程),就像一个公司至少有一个创始人在主导业务。
- 线程不能独立存在,必须依附于进程,它在进程的地址空间内运行,相当于在公司的 “办公场地” 里开展具体工作。
- 在 Linux 内核眼中,线程和进程都用
task_struct(PCB)表示,但线程的task_struct更 “轻量化”—— 因为它共享进程的大部分资源,不需要单独申请全套 “办公设备”。
如果把进程比作一个 “工厂”,那么虚拟地址空间就是工厂的 “厂区规划图”,线程就是工厂里的 “工人”:多个工人共享厂区的设备(进程资源),但各自有自己的工作流程(执行序列)。
1.2 分页式存储管理:虚拟地址空间的 “幕后推手”
为什么需要虚拟地址空间?要理解这个问题,我们得先看看 “没有虚拟内存” 的困境。
1.2.1 没有虚拟内存的 “痛点”
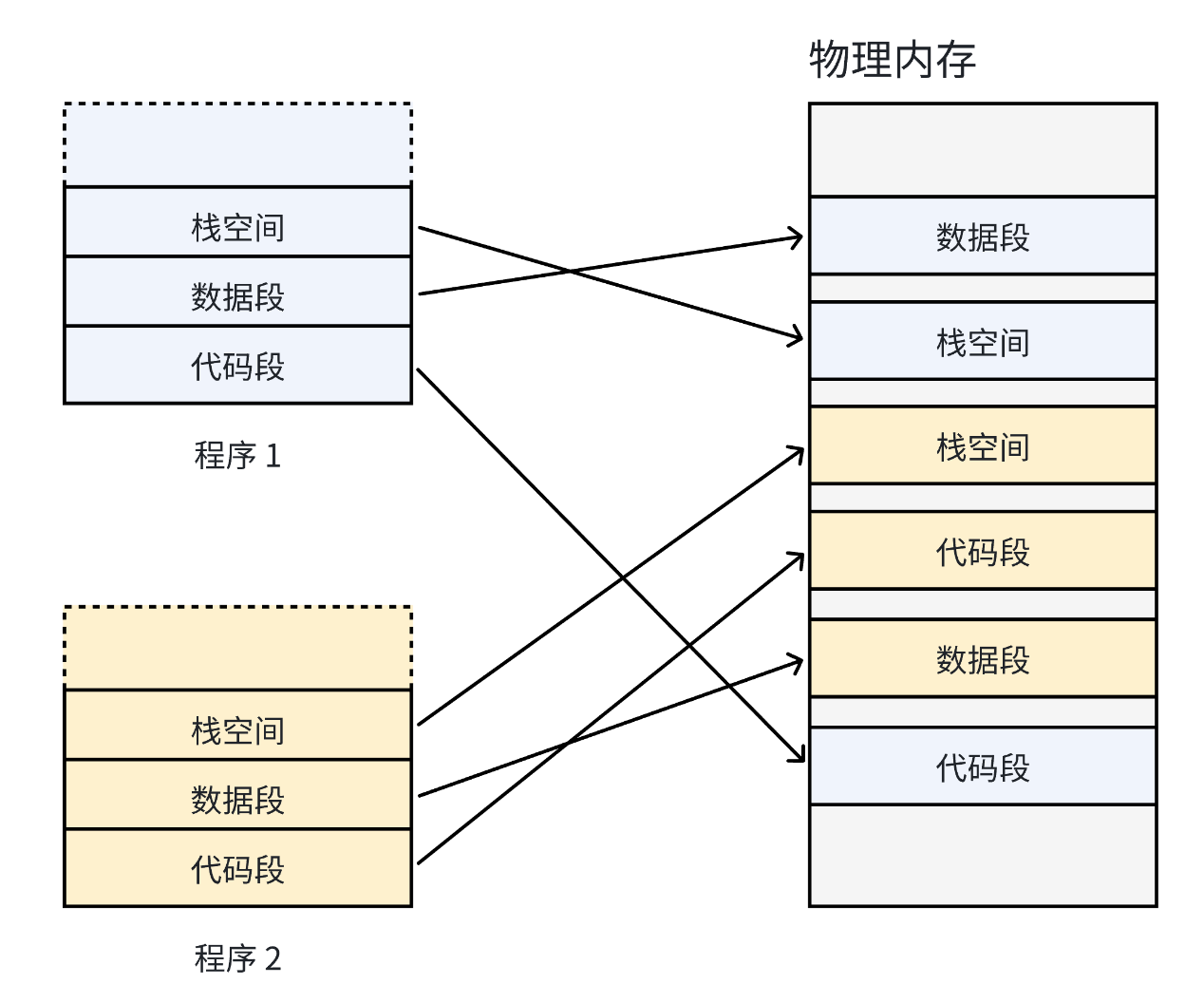
如果程序直接使用物理内存,每个程序的代码段、数据段、栈段都需要在物理内存中占据连续空间。但不同程序的大小不一样,运行一段时间后,物理内存会被分割成很多 “小碎片”—— 就像把一块蛋糕反复切小块,最后剩下的碎片凑不成一块完整的蛋糕,导致新程序无法加载。
1.2.2 虚拟内存 + 分页:解决碎片问题的 “神器”
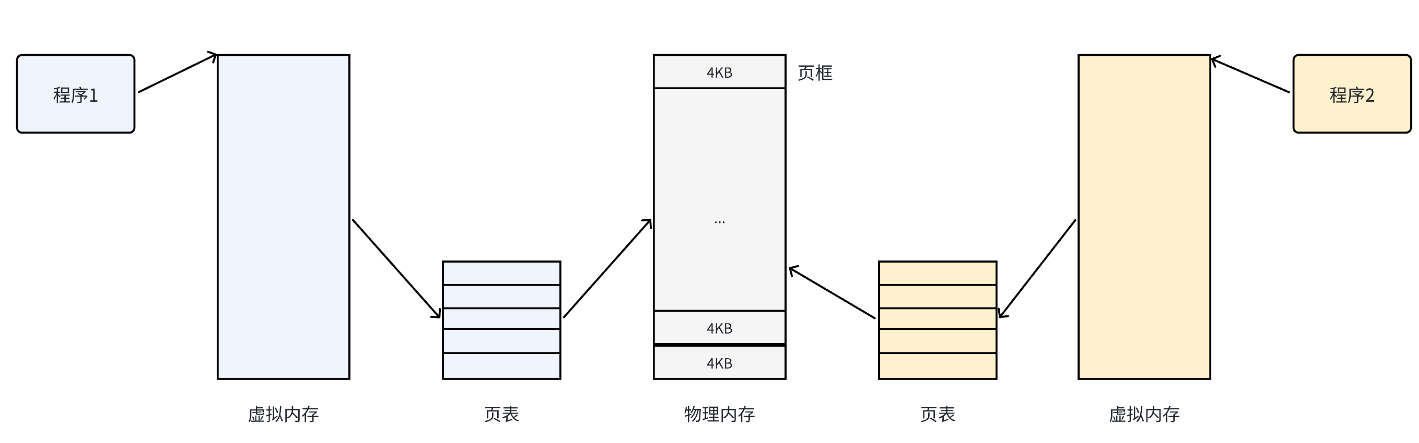
为了解决物理内存碎片问题,操作系统引入了虚拟地址空间和分页机制,核心逻辑可以总结为 “拆分成块、映射关联”:
- 拆分物理内存:把物理内存按固定大小分成 “页框”(比如 32 位系统常用 4KB),每个页框是一个独立的 “存储块”。
- 拆分虚拟地址空间:把进程的虚拟地址空间也按同样大小分成 “页”,每个页对应一个或多个页框。
- 建立映射关系:通过 “页表” 记录虚拟页和物理页框的对应关系,CPU 访问虚拟地址时,会先通过页表找到对应的物理页框,再访问实际内存。
举个例子:假设物理内存是一个 “仓库”,页框就是仓库里的 “货架”;虚拟地址空间是 “商品清单”,页就是清单上的 “商品类别”;页表就是 “货架与商品类别对应表”—— 我们按清单找商品时,先查对应表找到货架,再去货架取货。
1.2.3 物理内存管理:用struct page给 “货架” 贴标签
Linux 内核用struct page结构体描述每一个物理页框,相当于给每个 “货架” 贴了一张标签,记录货架的状态(是否被使用、是否脏数据等)。以下是struct page的核心字段及作用:
| 字段 | 作用 |
|---|---|
flags | 页框状态标志,比如 “是否锁定”“数据是否最新”,每一位代表一种状态,最多可记录 32 种状态 |
_mapcount | 引用计数,记录有多少页表项指向这个页框,当计数为 - 1 时,页框可被重新分配 |
virtual | 页框的内核虚拟地址,若为 NULL,说明该页框是 “高端内存”,需要动态映射才能访问 |
大家不用纠结struct page的复杂结构,只需记住:内核通过这个结构体 “掌控” 所有物理页框,知道哪些页框可用、哪些被占用。
1.2.4 页表:从 “单级” 到 “多级” 的优化
在 32 位系统中,虚拟地址空间是 4GB,若按 4KB 一页拆分,需要4GB/4KB=1048576个页表项,每个页表项占 4 字节,单级页表会占用1048576*4=4MB内存,且需要连续的物理页框 —— 这又回到了 “连续内存” 的老问题。
为了解决这个问题,Linux 引入了二级页表,把页表拆分成 “页目录表” 和 “页表” 两层:
- 页目录表:有 1024 个表项,每个表项指向一个页表的物理地址。
- 页表:每个页表也有 1024 个表项,每个表项指向物理页框地址。
这样一来,4GB 虚拟地址就被拆成 “10 位(页目录索引)+10 位(页表索引)+12 位(页内偏移)”:
- 前 10 位找页目录表中的表项,确定对应的页表。
- 中间 10 位找页表中的表项,确定对应的物理页框。
- 最后 12 位是页内偏移,确定在物理页框中的具体位置。
二级页表的优势在于 “按需分配”:程序不需要用到 4GB 全部空间,只需加载用到的页目录项和页表,比如一个 10MB 的程序,只需 3 个页表(1 个页表覆盖 4MB,10MB 向上取整为 12MB,12MB/4MB=3),大大节省了内存。
1.2.5 地址转换:TLB 加速 “查表” 过程
有了二级页表,地址转换需要两次查表(先查页目录,再查页表),这会降低 CPU 效率。为了解决这个问题,硬件引入了TLB(快表) —— 相当于页表的 “缓存”,存储最近使用的虚拟页与物理页框的映射关系。
地址转换的流程变成了这样:
- CPU 发送虚拟地址给 MMU(内存管理单元)。
- MMU 先查 TLB:如果有对应的映射(TLB 命中),直接获取物理地址,访问内存。
- 如果 TLB 没有对应的映射(TLB 未命中),MMU 再查二级页表,找到物理地址后,不仅访问内存,还会把映射关系存入 TLB,方便下次使用。
TLB 的存在就像 “图书馆的常用书书架”—— 常用的书不用去仓库(页表)找,直接从书架(TLB)拿,大大提高了效率。
1.2.6 缺页异常:内存 “不够用” 时的处理
当 MMU 查完 TLB 和页表,都没找到虚拟地址对应的物理页框时,就会触发缺页异常(Page Fault)。内核会通过Page Fault Handler(缺页中断处理器)处理,根据异常类型分为三类:
| 异常类型 | 原因 | 处理方式 |
|---|---|---|
| 硬缺页(Hard Page Fault) | 物理内存中没有对应的页,需要从磁盘加载(比如程序刚启动时,代码段还在磁盘) | 1. 分配物理页框;2. 从磁盘读取数据到页框;3. 建立虚拟页与页框的映射 |
| 软缺页(Soft Page Fault) | 物理内存中有对应的页,但当前线程没建立映射(比如多线程共享内存) | 直接建立虚拟页与已有物理页框的映射,不用读磁盘 |
| 无效缺页(Invalid Page Fault) | 访问了非法地址(比如空指针解引用、数组越界) | 触发段错误(Segment Fault),终止进程 |
比如我们双击一个未运行的程序,程序代码从磁盘加载到内存时触发的就是硬缺页;而两个线程共享一个全局变量时,第二个线程访问变量触发的就是软缺页。
1.3 线程的优势:为什么要用多线程?
相比多进程,线程的优势主要体现在 “轻量” 和 “高效”,具体可以总结为这几点:
- 创建成本低:创建线程只需新建一个
task_struct,并共享进程的地址空间,无需复制全套资源;而创建进程需要复制整个地址空间(写时拷贝虽优化了性能,但仍有开销)。 - 切换效率高:线程切换时,虚拟地址空间不变,无需刷新 TLB(快表);而进程切换需要切换虚拟地址空间,TLB 会被全部刷新,导致后续内存访问效率下降。
- 资源占用少:线程共享进程的代码段、数据段、文件描述符等,无需单独维护,内存占用远低于进程。
- 并发能力强:多线程能充分利用多 CPU 核心,比如计算密集型程序(如视频编码)用多线程,可让多个 CPU 核心同时工作;I/O 密集型程序(如下载文件)用多线程,可在等待 I/O 的同时执行其他任务。
1.4 线程的缺点:多线程不是 “银弹”
多线程虽好,但也有明显的缺点,需要我们在开发中规避:
- 性能损耗:如果计算密集型线程数量超过 CPU 核心数,线程会频繁切换,导致同步和调度开销增加,反而降低效率。
- 健壮性降低:线程共享进程资源,一个线程出错可能影响整个进程 —— 比如一个线程因 “除零错误” 崩溃,整个进程会被终止,所有线程也会跟着退出。
- 缺乏访问控制:进程是资源分配的基本单位,线程无法单独申请资源,比如一个线程调用
exit()会终止整个进程,而不是只终止自己。 - 编程难度高:多线程需要处理同步问题(如锁、信号量),容易出现死锁、数据竞争等 bug,调试难度远高于单线程。
1.5 线程异常:一个线程出错,整个进程 “买单”
线程是进程的 “执行分支”,当单个线程出现异常(如除零、野指针)时,会触发内核的信号机制,进而终止整个进程 —— 就像一个团队里有人犯了严重错误,导致整个项目失败。
比如在 C 语言中,若一个线程执行了int a = 1/0;,会触发SIGFPE(浮点异常)信号,内核会终止该线程所属的进程,进程内所有线程都会退出。
1.6 线程用途:哪些场景适合用多线程?
根据线程的特性,主要有两类场景适合用多线程:
- 计算密集型应用:比如视频编码、数据加密,这类应用需要大量 CPU 计算,用多线程可将任务分配到多个 CPU 核心,提高执行速度。
- I/O 密集型应用:比如网络请求、文件读写,这类应用大部分时间在等待 I/O(如等待网络响应、磁盘读写),用多线程可在等待 I/O 的同时执行其他任务,提升程序响应速度。
生活中的例子也很常见:我们在电脑上 “一边写代码,一边下载开发工具”,就是多线程的体现 —— 写代码是一个线程,下载是另一个线程,两者并行执行。
二、Linux 进程 VS 线程:分清 “资源分配” 与 “调度” 的边界
很多人会混淆进程和线程,其实核心区别就一句话:进程是资源分配的基本单位,线程是调度的基本单位。下面我们从资源共享、独立资源、核心差异三个维度详细对比。
2.1 核心区别:资源分配 VS 调度
- 进程:操作系统给进程分配内存、文件描述符等资源,每个进程有独立的虚拟地址空间 —— 相当于给每个 “团队” 分配独立的 “办公场地” 和 “设备”。
- 线程:操作系统调度线程执行,多个线程共享进程的资源 —— 相当于 “团队” 里的 “成员”,共享办公场地和设备,各自执行不同任务。
2.2 线程的 “专属资源”:哪些东西是线程独有的?
虽然线程共享进程的大部分资源,但为了独立执行,线程也有自己的 “专属物品”:
- 线程 ID(TID):区分同一进程内不同线程的唯一标识。
- 寄存器集合:包括程序计数器(PC)、栈指针(SP)等,记录线程当前的执行状态,切换线程时需要保存和恢复这些寄存器的值。
- 线程栈:每个线程有独立的栈空间,用于存储局部变量、函数调用栈帧,避免线程间栈数据冲突。
errno:记录线程最近一次系统调用的错误码,因为多个线程可能同时调用系统调用,需要独立存储错误信息。- 信号屏蔽字:控制线程是否接收某些信号,比如线程 A 可以屏蔽
SIGINT(中断信号),而线程 B 不屏蔽。 - 调度优先级:线程的调度优先级可能不同,优先级高的线程更容易被 CPU 调度。
2.3 线程共享的 “进程资源”:哪些东西是线程共用的?
同一进程内的线程共享以下资源,这也是线程 “轻量化” 的关键:
- 虚拟地址空间:包括代码段(Text Segment)、数据段(Data Segment)、堆区,比如一个线程定义的全局变量,其他线程可以直接访问。
- 文件描述符表:进程打开的文件、网络连接等,所有线程都可以使用,比如线程 A 打开一个文件,线程 B 可以直接读写该文件。
- 信号处理方式:比如进程设置
SIGINT信号的处理函数为自定义函数,那么所有线程收到SIGINT时都会执行这个函数。 - 当前工作目录:进程的工作目录,线程执行文件操作时,默认基于这个目录查找文件。
- 用户 ID 和组 ID:进程的权限标识,线程执行操作时,使用的是进程的权限,比如进程是 root 权限,所有线程都有 root 权限。
2.4 进程与线程的关系:四种常见模型
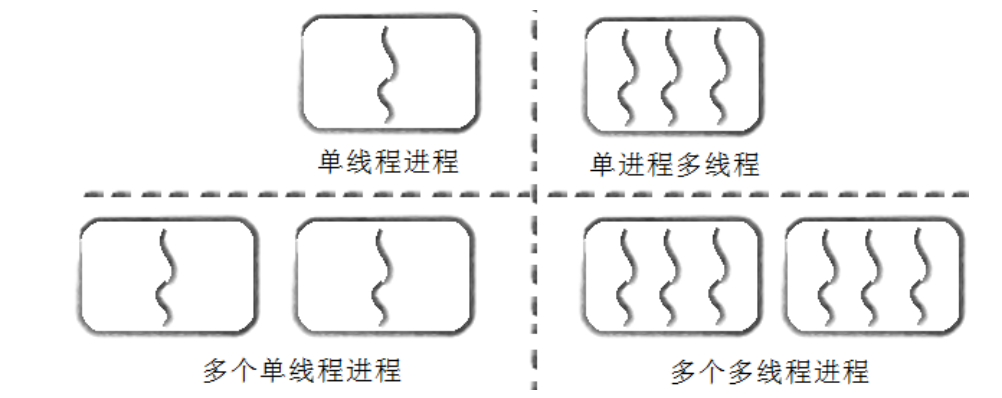
我们可以用 “进程 - 线程” 的数量关系,理解不同的程序运行模型:
- 单线程进程:一个进程只有一个线程,比如早期的 DOS 程序,同一时间只能执行一个任务。
- 单进程多线程:一个进程有多个线程,比如我们日常使用的浏览器,一个进程内有 “渲染线程”“网络线程”“UI 线程” 等,并行处理不同任务。
- 多个单线程进程:多个进程,每个进程只有一个线程,比如早期的 Web 服务器(如 Apache 的 prefork 模式),每个请求对应一个独立进程。
- 多个多线程进程:多个进程,每个进程有多个线程,比如分布式系统中的服务节点,每个节点是一个进程,进程内用多线程处理多个请求。
2.5 一个关键问题:之前学的 “单进程” 是什么?
其实我们之前学的 “单进程”,本质上是 “只有一个主线程的进程”—— 进程启动时,内核会创建一个task_struct(主线程的 PCB),执行main函数,这就是主线程。如果我们在进程中创建新线程,就是在这个进程的地址空间内新增执行序列。
三、Linux 线程控制:创建、终止、等待与分离
理解了线程的概念和与进程的区别后,我们需要掌握如何用代码控制线程。Linux 下主要通过POSIX 线程库(pthread 库) 实现线程控制,核心函数包括线程创建、终止、等待、分离。
3.1 POSIX 线程库:使用前的 “准备工作”
POSIX 线程库是一套标准的线程操作接口,大部分函数以pthread_开头,使用时需要注意:
- 引入头文件:
#include <pthread.h>。 - 编译链接:链接时需要加
-lpthread选项,比如gcc thread_demo.c -o thread_demo -lpthread,否则会提示 “未定义的引用”。 - 错误处理:pthread 函数出错时,不会设置全局变量
errno,而是直接返回错误码,比如pthread_create成功返回 0,失败返回非 0 值(如EAGAIN表示资源不足)。
3.2 线程创建:pthread_create
函数原型与参数
#include <pthread.h>// 创建一个新线程
// 参数1:thread - 输出参数,存储新线程的ID(pthread_t类型)
// 参数2:attr - 线程属性,NULL表示使用默认属性(如栈大小、调度优先级)
// 参数3:start_routine - 线程启动后执行的函数,返回值和参数都是void*
// 参数4:arg - 传给start_routine的参数,若不需要传参,设为NULL
// 返回值:成功返回0,失败返回错误码
int pthread_create(pthread_t *thread, const pthread_attr_t *attr, void *(*start_routine)(void*), void *arg);
代码示例:创建一个简单线程
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
#include <unistd.h>
#include <string.h>// 线程执行的函数:每隔1秒打印一次"我是子线程"
void *child_thread_func(void *arg) {while (1) {printf("我是子线程,线程ID:%lu\n", pthread_self()); // pthread_self()获取当前线程IDsleep(1);}return NULL; // 线程函数返回值,可被pthread_join获取
}int main() {pthread_t child_tid; // 存储子线程IDint ret;// 创建子线程:使用默认属性,传入child_thread_func,无参数ret = pthread_create(&child_tid, NULL, child_thread_func, NULL);if (ret != 0) {// 出错时,用strerror(ret)获取错误信息(注意不是strerror(errno))fprintf(stderr, "创建线程失败:%s\n", strerror(ret));exit(EXIT_FAILURE);}// 主线程:每隔1秒打印一次"我是主线程"while (1) {printf("我是主线程,子线程ID:%lu\n", child_tid);sleep(1);}return 0;
}
代码说明
- 编译运行:
gcc thread_create.c -o thread_create -lpthread,运行后会看到主线程和子线程交替打印信息。 - 线程 ID:
pthread_self()返回当前线程的 ID(pthread_t类型),这是线程库层面的 ID,用于线程库函数(如pthread_join);而内核中的线程 ID(LWP)需要用ps -aL查看(下文会讲)。 - 线程函数:
start_routine的返回值和参数都是void*,方便传递任意类型的数据,比如要传多个参数,可以封装成结构体指针传入。
3.3 线程终止:三种优雅结束线程的方式
线程终止有三种常见方式,需根据场景选择:
方式 1:从线程函数return
线程函数执行完return后,线程终止,返回值会被pthread_join获取(主线程return相当于调用exit,会终止整个进程)。
示例:
// 线程函数:执行完return后终止
void *thread_return(void *arg) {int *num = (int*)arg;printf("线程接收到的参数:%d\n", *num);int result = *num * 2; // 计算结果return (void*)&result; // 返回结果(注意:不能返回局部变量的地址!这里仅为示例,实际需用malloc或全局变量)
}
注意:线程函数return的指针不能指向局部变量 —— 线程终止后,局部变量会被销毁,其他线程访问该指针会导致 “野指针” 错误。若要返回数据,建议用malloc分配内存(后续需手动释放)或使用全局变量。
方式 2:调用pthread_exit终止自己
pthread_exit是线程主动终止自己的函数,相当于线程的 “自杀” 接口,参数是线程的返回值,用法与return类似。
函数原型:
#include <pthread.h>// 终止当前线程,参数value_ptr是线程的返回值
// 注意:value_ptr不能指向局部变量
void pthread_exit(void *value_ptr);
示例:
void *thread_exit(void *arg) {int *num = (int*)arg;int *result = (int*)malloc(sizeof(int)); // 用malloc分配内存,避免局部变量问题*result = *num * 3;printf("线程即将终止,返回结果:%d\n", *result);pthread_exit((void*)result); // 终止线程,返回result
}
方式 3:调用pthread_cancel终止其他线程
pthread_cancel可以让一个线程终止同一进程内的另一个线程,相当于 “杀死” 其他线程,参数是目标线程的 ID。
函数原型:
#include <pthread.h>// 终止thread指定的线程
// 返回值:成功返回0,失败返回错误码
int pthread_cancel(pthread_t thread);
示例:
#include <stdio.h>
#include <pthread.h>
#include <unistd.h>// 子线程:无限循环打印
void *thread_loop(void *arg) {while (1) {printf("子线程正在运行...\n");sleep(1);}return NULL;
}int main() {pthread_t tid;pthread_create(&tid, NULL, thread_loop, NULL);sleep(3); // 主线程等待3秒,让子线程运行一会儿int ret = pthread_cancel(tid); // 终止子线程if (ret != 0) {fprintf(stderr, "终止线程失败:%s\n", strerror(ret));return 1;}printf("子线程已被终止\n");return 0;
}
3.4 线程等待:pthread_join—— 回收线程资源
和进程需要wait回收僵尸进程一样,线程退出后也需要pthread_join回收资源(如线程栈、task_struct),否则会产生 “僵尸线程”,浪费系统资源。
函数原型与参数
#include <pthread.h>// 等待thread指定的线程终止,回收其资源
// 参数1:thread - 要等待的线程ID
// 参数2:value_ptr - 输出参数,存储线程的返回值(需根据线程终止方式判断返回值类型)
// 返回值:成功返回0,失败返回错误码
int pthread_join(pthread_t thread, void **value_ptr);
不同终止方式的返回值处理
pthread_join的value_ptr会根据线程的终止方式,存储不同的值:
- 线程通过
return终止:*value_ptr等于return的指针,比如线程return (void*)10,则*(int*)*value_ptr = 10。 - 线程通过
pthread_exit终止:*value_ptr等于pthread_exit的参数,比如pthread_exit((void*)20),则*(int*)*value_ptr = 20。 - 线程通过
pthread_cancel终止:*value_ptr等于PTHREAD_CANCELED(宏定义,本质是(void*)-1)。
代码示例:处理不同终止方式的线程
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
#include <unistd.h>
#include <string.h>// 方式1:return终止
void *thread_return(void *arg) {printf("线程1:通过return终止\n");int *result = (int*)malloc(sizeof(int));*result = 1;return (void*)result;
}// 方式2:pthread_exit终止
void *thread_exit(void *arg) {printf("线程2:通过pthread_exit终止\n");int *result = (int*)malloc(sizeof(int));*result = 2;pthread_exit((void*)result);
}// 方式3:被pthread_cancel终止
void *thread_cancel(void *arg) {printf("线程3:正在运行,等待被终止\n");while (1) {sleep(1); // 让线程有时间被cancel}return NULL;
}int main() {pthread_t tid1, tid2, tid3;void *ret; // 存储线程返回值int res;// 等待线程1pthread_create(&tid1, NULL, thread_return, NULL);res = pthread_join(tid1, &ret);if (res == 0) {printf("线程1返回值:%d\n", *(int*)ret);free(ret); // 释放malloc的内存}// 等待线程2pthread_create(&tid2, NULL, thread_exit, NULL);res = pthread_join(tid2, &ret);if (res == 0) {printf("线程2返回值:%d\n", *(int*)ret);free(ret);}// 等待线程3pthread_create(&tid3, NULL, thread_cancel, NULL);sleep(1); // 等待1秒,再终止线程3pthread_cancel(tid3);res = pthread_join(tid3, &ret);if (res == 0) {if (ret == PTHREAD_CANCELED) {printf("线程3被pthread_cancel终止\n");}}return 0;
}
运行结果
线程1:通过return终止
线程1返回值:1
线程2:通过pthread_exit终止
线程2返回值:2
线程3:正在运行,等待被终止
线程3被pthread_cancel终止
3.5 线程分离:pthread_detach—— 自动回收资源
默认情况下,线程是 “可连接的(joinable)”,需要pthread_join回收资源。如果我们不关心线程的返回值,pthread_join会成为一种负担 —— 此时可以用pthread_detach将线程设为 “分离的(detached)”,线程终止后会自动回收资源,无需pthread_join。
函数原型
#include <pthread.h>// 将thread指定的线程设为分离状态
// 返回值:成功返回0,失败返回错误码
int pthread_detach(pthread_t thread);
两种分离方式
- 线程自己分离:在 thread 函数中调用
pthread_detach(pthread_self())。 - 其他线程分离:主线程或其他线程调用
pthread_detach(tid),其中tid是目标线程的 ID。
代码示例:线程自我分离
#include <stdio.h>
#include <pthread.h>
#include <unistd.h>
#include <string.h>void *detached_thread(void *arg) {// 线程自我分离:终止后自动回收资源int ret = pthread_detach(pthread_self());if (ret != 0) {fprintf(stderr, "线程分离失败:%s\n", strerror(ret));return NULL;}printf("分离线程正在运行...\n");sleep(2);printf("分离线程终止,资源会自动回收\n");return NULL;
}int main() {pthread_t tid;pthread_create(&tid, NULL, detached_thread, NULL);// 若此时调用pthread_join,会失败(因为线程已分离)sleep(3); // 等待线程终止int res = pthread_join(tid, NULL);if (res != 0) {fprintf(stderr, "pthread_join失败:%s\n", strerror(res)); // 会输出"无效的参数"}return 0;
}
运行结果
分离线程正在运行...
分离线程终止,资源会自动回收
pthread_join失败:Invalid argument
注意:线程的 “joinable” 和 “detached” 是互斥的,一个线程不能同时处于两种状态。如果线程已被分离,再调用pthread_join会失败。
四、线程 ID 与进程地址空间布局:看清线程的 “内存位置”
在 Linux 中,线程有两种 ID:线程库层面的pthread_t和内核层面的 LWP(轻量级进程 ID);同时,线程的栈位置也和主线程不同,这些细节对理解线程内存布局至关重要。
4.1 两种线程 ID:pthread_t与 LWP
很多人会混淆线程的两种 ID,我们可以用 “公司员工” 的比喻理解:
- LWP(Light Weight Process ID):内核给线程分配的 ID,相当于员工的 “工号”,在整个系统中唯一,内核通过 LWP 调度线程。
pthread_t:线程库(pthread 库)给线程分配的 ID,相当于员工的 “部门内编号”,仅在当前进程内唯一,线程库函数(如pthread_join)通过pthread_t操作线程。
如何查看 LWP?
用ps -aL命令可以查看线程的 LWP,其中:
PID:进程 ID,同一进程内的线程 PID 相同。LWP:线程的内核 ID,同一进程内的线程 LWP 不同。
示例:运行之前的 “主线程 + 子线程” 程序,用ps -aL | grep 程序名查看:
$ ps -aL | grep thread_create
2711838 2711838 pts/235 00:00:00 thread_create # PID=2711838,LWP=2711838(主线程)
2711838 2711839 pts/235 00:00:00 thread_create # PID=2711838,LWP=2711839(子线程)
可以看到,主线程的 LWP 和 PID 相同,子线程的 LWP 不同 —— 这也印证了 “Linux 线程是轻量级进程” 的特点。
pthread_t的本质
在 Linux 的 NPTL(原生 POSIX 线程库)实现中,pthread_t本质是一个指针,指向进程地址空间内的一个struct pthread结构体(线程控制块 TCB),该结构体存储了线程的栈地址、寄存器状态、调度优先级等信息。
比如pthread_self()返回的pthread_t值,打印出来是一个内存地址(如0x7f8b9c000b40),通过这个地址可以找到线程的所有信息。
4.2 进程地址空间布局:线程栈在哪里?
Linux 进程的虚拟地址空间从低地址到高地址分为以下几个区域(32 位系统):
- 代码段(Text Segment):存储程序的机器指令,只读。
- 数据段(Data Segment):存储已初始化的全局变量和静态变量。
- BSS 段(未初始化数据段):存储未初始化的全局变量和静态变量,程序启动时会被初始化为 0。
- 堆区(Heap):动态内存分配区域,用
malloc/free管理,从低地址向高地址增长。 - 共享区(Memory Mapping Segment):存储动态链接库、共享内存等,线程栈也位于此区域。
- 栈区(Stack):主线程的栈,从高地址向低地址增长,默认大小一般为 8MB。
主线程栈 VS 子线程栈的区别
- 主线程栈:位于地址空间的 “栈区”,从高地址向低地址动态增长,当栈溢出时(如递归过深),会触发栈保护机制,报段错误。
- 子线程栈:位于 “共享区”(而非主线程的栈区),由 pthread 库通过
mmap分配固定大小的内存(默认 8MB),不能动态增长 —— 如果子线程栈用尽(如局部数组过大),会直接触发段错误。
线程地址空间布局示意图
我们可以用一张图直观理解线程在进程地址空间中的位置(以 32 位系统为例):
高地址
+------------------------+
| 命令行参数与环境变量 |
+------------------------+
| 主线程栈(Stack) | ← 主线程栈,从高到低增长
+------------------------+
| |
| (未使用空间) |
| |
+------------------------+
| 共享区(mmap) | ← 子线程栈、动态库位于此
| - 子线程1栈 |
| - 子线程2栈 |
| - 动态链接库(如libc)|
+------------------------+
| 堆区(Heap) | ← 动态内存分配,从低到高增长
+------------------------+
| BSS段(未初始化数据)|
+------------------------+
| 数据段(已初始化数据)|
+------------------------+
| 代码段(Text) | ← 程序指令,只读
+------------------------+
低地址
从图中可以看到,子线程栈和主线程栈位于不同区域,这也是多个线程的栈数据不会冲突的原因。
4.3 线程局部存储(TLS):线程的 “全局变量”
有时候我们需要 “线程级别的全局变量”—— 即每个线程有独立的变量副本,其他线程无法访问,这就是线程局部存储(Thread Local Storage,TLS)。
在 C 语言中,用__thread关键字声明 TLS 变量,示例:
#include <stdio.h>
#include <pthread.h>
#include <unistd.h>// 线程局部存储变量:每个线程有独立副本
__thread int tls_var = 0;void *thread_func(void *arg) {int id = *(int*)arg;tls_var = id; // 每个线程设置自己的tls_varprintf("线程%d:tls_var = %d,地址 = %p\n", id, tls_var, &tls_var);sleep(1);printf("线程%d:tls_var = %d(未被其他线程修改)\n", id, tls_var);return NULL;
}int main() {pthread_t tid1, tid2;int id1 = 1, id2 = 2;pthread_create(&tid1, NULL, thread_func, &id1);pthread_create(&tid2, NULL, thread_func, &id2);pthread_join(tid1, NULL);pthread_join(tid2, NULL);return 0;
}
运行结果
线程1:tls_var = 1,地址 = 0x7f9a8c000b3c
线程2:tls_var = 2,地址 = 0x7f9a8b800b3c
线程1:tls_var = 1(未被其他线程修改)
线程2:tls_var = 2(未被其他线程修改)
可以看到,两个线程的tls_var地址不同,值也相互独立 —— 这就是 TLS 的作用,实现线程间数据隔离。
五、总结:核心知识点回顾
本文围绕 Linux 线程概念与虚拟地址空间展开,核心知识点可以总结为以下几点:
- 线程本质:进程内的执行序列,共享进程地址空间,用
task_struct表示,比进程更轻量化。 - 虚拟地址空间与分页:通过 “虚拟页 - 物理页框 - 页表” 的映射,解决物理内存碎片问题,二级页表和 TLB 优化地址转换效率。
- 进程与线程的区别:进程是资源分配单位,线程是调度单位;线程共享进程的地址空间、文件描述符等,独有线程栈、寄存器等。
- 线程控制:用 pthread 库的
pthread_create(创建)、pthread_exit(终止)、pthread_join(等待)、pthread_detach(分离)实现线程生命周期管理。 - 线程 ID 与内存布局:
pthread_t是线程库 ID(进程内唯一),LWP 是内核 ID(系统唯一);子线程栈位于共享区,主线程栈位于栈区,TLS 实现线程数据隔离。
掌握这些知识点,就能理解 Linux 并发编程的底层逻辑,为后续学习线程同步(锁、信号量)、线程安全等内容打下坚实基础。如果有疑问,欢迎在评论区交流!